FlashSampling: Fast and Memory-Efficient Exact Sampling
Abstract: Sampling from a categorical distribution is mathematically simple, but in large-vocabulary decoding, it often triggers extra memory traffic and extra kernels after the LM head. We present FlashSampling, an exact sampling primitive that fuses sampling into the LM-head matmul and never materializes the logits tensor in HBM. The method is simple: compute logits tile-by-tile on chip, add Gumbel noise, keep only one maximizer per row and per vocabulary tile, and finish with a small reduction over tiles. The fused tiled kernel is exact because $\argmax$ decomposes over a partition; grouped variants for online and tensor-parallel settings are exact by hierarchical factorization of the categorical distribution. Across H100, H200, B200, and B300 GPUs, FlashSampling speeds up kernel-level decode workloads, and in end-to-end vLLM experiments, it reduces time per output token by up to $19%$ on the models we test. These results show that exact sampling, with no approximation, can be integrated into the matmul itself, turning a bandwidth-bound postprocessing step into a lightweight epilogue. Project Page: https://github.com/FlashSampling/FlashSampling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FlashSampling, a new way to pick the next word from a large list of choices when a LLM (like ChatGPT) is generating text. It makes this “picking” step both faster and more memory‑friendly by folding it directly into the model’s last math step, instead of doing it afterward as a separate job. Importantly, it still picks words exactly as the usual method would—no shortcuts or approximations.
What questions are the researchers trying to answer?
- Can we sample (pick) the next token from a huge vocabulary without first writing a huge table of scores (“logits”) to slow, off‑chip memory?
- Can we fuse sampling into the model’s final matrix multiplication (the LM head) so there’s no extra pass over those scores?
- Can we do this in a way that stays exact (i.e., gives the same results as traditional methods), works on multiple GPUs, and speeds up real systems?
How does it work? (Simple explanation with analogies)
Imagine you’re choosing a candy from a giant shelf with thousands of candies. Each candy has a score (how much the model “likes” it). Traditionally, you would:
- Write down all the scores on a big sheet (slow),
- Turn scores into probabilities,
- Roll a random number to pick a candy.
That big sheet is called the logits tensor, and writing/reading it is slow because it lives in large but slower memory (HBM on a GPU).
FlashSampling does something smarter:
- Instead of writing the whole sheet, it scans the shelf in small chunks (called tiles), right where the math is happening on the chip (fast, on‑chip memory).
- For each candy’s score, it adds a tiny dose of randomness (called Gumbel noise). Here’s the neat trick: if you add this specially chosen random noise to each score and then pick the biggest one, you get exactly the same result as sampling from the correct probability distribution. This is known as the “Gumbel‑Max trick.”
- In each chunk (tile), it keeps only the best candy (the local winner) and throws away the rest.
- At the very end, it looks at the few tile winners and picks the overall best. Because “the biggest of all numbers is also the biggest among the chunk winners,” this gives the same winner you’d have gotten by scanning everything at once.
Why this is faster:
- On‑chip memory is like a small, super‑fast notepad on your desk. Off‑chip HBM is like a big binder across the room. FlashSampling keeps almost everything on the notepad and only writes a tiny summary (one winner per chunk) to the binder.
- Fusing the sampling into the main math step avoids launching extra “sampler” programs and avoids multiple trips to the binder.
What about multiple GPUs?
- If the vocabulary is split across different GPUs, each GPU picks its local winner and a small “group score.” Then a tiny final step picks which GPU’s winner is the global winner. This avoids sending huge score lists between GPUs.
What did they find, and why is it important?
- It’s exact: FlashSampling produces the same distribution of choices as the standard method—no approximations, just a different (and clever) way of doing the same thing.
- It’s faster in practice:
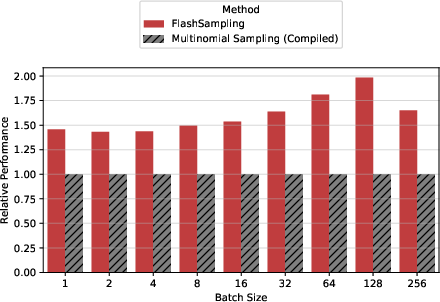
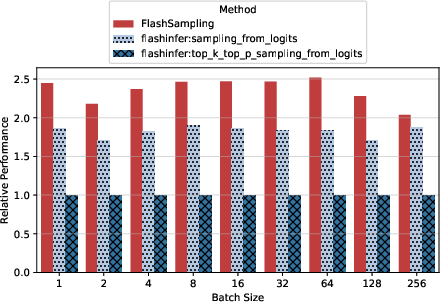
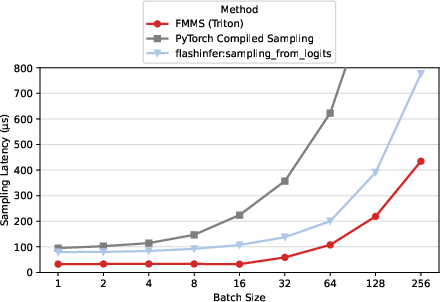
- On NVIDIA H100, H200, B200, and B300 GPUs, FlashSampling sped up the decoding kernel (the low‑level “pick the next token” work) compared to strong baselines.
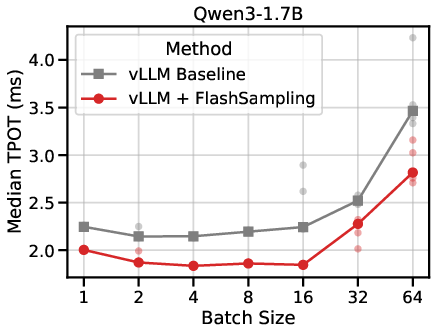
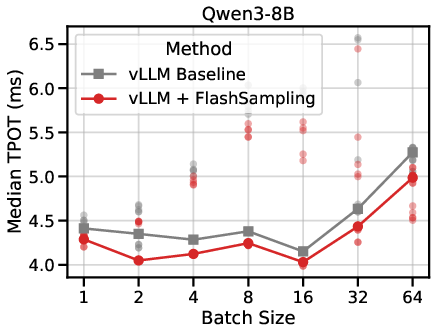
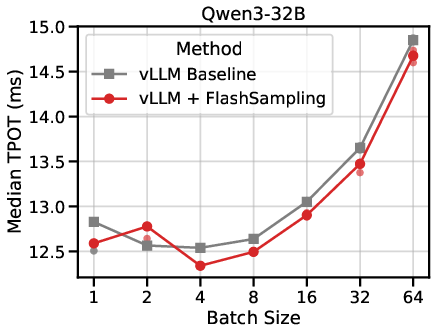
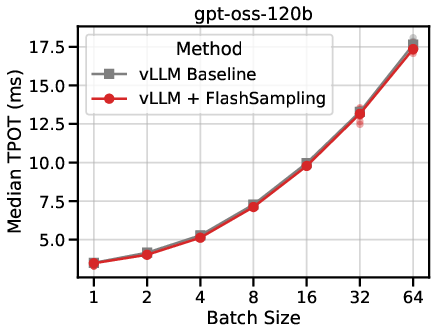
- Integrated into vLLM (a popular LLM serving stack), it reduced the time per output token by up to 19% on some models, especially when generating text one or a few tokens at a time (the common case in interactive use).
- Why it’s faster: The biggest gains don’t just come from writing fewer bytes. They mainly come from removing extra steps (kernels) and memory round‑trips that add overhead in the most time‑sensitive part of generation.
In short: FlashSampling turns sampling from a large, memory‑heavy afterthought into a light add‑on to the main computation, saving time without changing the results.
What could this change in the future?
- Faster responses from LLMs: When you chat with an AI, it picks one token at a time. Making that picking step faster speeds up the whole conversation.
- Better scaling: For very large vocabularies and multi‑GPU setups, FlashSampling cuts communication and memory costs by only sending tiny summaries, not massive score tables.
- A template for other speedups: Like FlashAttention did for attention layers, FlashSampling shows how “don’t write giant intermediate results to slow memory” can be a powerful idea. This could inspire similar fusions for other parts of AI models.
Overall, FlashSampling is a simple, elegant change—add random noise and keep only the best per chunk—that preserves exact behavior and delivers real speedups in modern LLM systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain, missing, or unexplored, to guide future research and engineering work:
- Top-k/Top-p integration is not implemented or benchmarked end-to-end:
- While theoretical compatibility with Gumbel-Top-k is stated and a top-k-then-top-p strategy is suggested, there is no fused implementation, accuracy analysis vs. standard top-p, or performance measurement across realistic decode settings.
- Distributed/tensor-parallel variant lacks empirical validation:
- The paper gives a theoretical “grouped”/sharded design that avoids O(V) all-gathers, but reports no end-to-end multi-GPU/multi-node benchmarks, NCCL communication traces, or determinism tests under tensor parallelism.
- Determinism across different partitions/shardings is not fully specified:
- Pathwise reproducibility with counter-based RNG is described for fused tiles, but it is unclear how to guarantee identical outcomes across different tilings/shardings (grouped variants are exact in distribution, not necessarily pathwise). A concrete, implementable scheme for shard-agnostic determinism is missing.
- CuBLAS/cuBLASLt/CUTLASS epilogue integration is absent:
- The fused Triton GEMM shows lower matmul efficiency at larger batch sizes; there is no prototype using vendor libraries (e.g., cuBLASLt epilogues or EVT CUTLASS fusion) to preserve cuBLAS matmul performance while keeping sampling fused.
- Quantization and low-precision support is untested:
- No experiments with FP8/INT8 (or mixed-precision) LM-heads, nor analysis of numerical stability and exactness under quantization, structured sparsity, or Blackwell FP8 pathways.
- RNG generation cost and quality are not characterized:
- The overhead of on-chip Gumbel generation, vectorization strategies, and its impact on occupancy/throughput are not profiled; there is no cross-platform (e.g., different GPU vendors) assessment of RNG quality and reproducibility.
- Extreme-logit and masking edge cases are not stress-tested:
- Numerical stability under very large/small logits, heavy masking (including rows with nearly all −∞), or dynamic per-step logit processors (e.g., presence/frequency penalties, temperature schedules) is not quantified.
- Candidate buffer sizing and memory pressure are not analyzed:
- The second-stage buffer stores one (score, index) per row per tile; its size, register/shared-memory trade-offs, occupancy impacts, and tuning of tile sizes across B, V, and D are not systematically explored.
- Portability beyond NVIDIA GPUs is untested:
- Although Triton is platform-agnostic, there are no results on AMD (ROCm) or Intel GPUs, nor discussion of required kernel adaptations or expected performance deltas due to differing memory hierarchies.
- End-to-end multi-GPU systems results are missing:
- No evaluation with tensor- and pipeline-parallel deployments (single-node multi-GPU or multi-node), continuous batching under heterogeneous sequence lengths, or interaction with NCCL scheduling and overlap.
- Latency distribution and tail behavior are not reported:
- Results focus on medians; P95/P99 latency, variance under bursty loads, and sensitivity to dynamic batching policies (e.g., vLLM’s continuous batching) are not provided.
- Interaction with speculative decoding is unaddressed:
- Speculative methods often need logits for accept/reject or reranking; it is unclear how to reuse/avoid rematerialization in verification steps or integrate fused sampling into speculative pipelines.
- Multi-sample and beam search are not supported or evaluated:
- Generating n>1 candidates per step (for reranking/diverse sampling/beam search) is not implemented; the fused kernel changes and performance/communication impacts remain open.
- Throughput-centric metrics under high concurrency are limited:
- The paper emphasizes time per output token (TPOT); aggregate tokens/s throughput, GPU utilization under high-QPS serving, and interactions with KV-cache/attention kernels are not comprehensively studied.
- Incomplete ablations of where speedups come from:
- The cost model argues kernel fusion (not raw HBM savings) drives gains, but there is no controlled ablation isolating contributions from (i) avoiding logits write/read, (ii) removing kernel launches, (iii) better cache locality, and (iv) candidate-buffer design.
- Integration with other fused kernels and schedulers is open:
- How FlashSampling composes with other IO-aware fusions (e.g., fused MLP/activation or persistent kernels), Triton/TVM scheduling, and model-level megakernel strategies is not explored.
- Energy efficiency and power draw are not measured:
- No reporting on energy/token or performance-per-watt, which is relevant for deployment trade-offs.
- Handling of failure modes and fallbacks is unspecified:
- Behavior when all tokens are masked (no finite logits), or when numerical issues produce NaNs/Infs during Gumbel transforms, lacks a documented fallback policy.
- Auto-tuning and adaptivity are not provided:
- There is no mechanism to adapt tile sizes, precision, or to fall back to materialized sampling when batch sizes grow and cuBLAS is preferable; a policy for switching paths dynamically is missing.
- Vocabulary scaling beyond ~150k is not shown:
- While the approach should scale, there are no measurements at 500k–1M vocab sizes, nor analysis of tile-reduction overheads and kernel occupancy at extreme V.
- Grammar/structured constraints support is only sketched:
- The paper notes masking via −∞, but does not benchmark complex grammar constraints (e.g., incremental automata-based restrictions) or their per-step overhead inside the epilogue.
- Distributional fidelity tests are limited:
- Correctness evaluation includes a chi-squared test on 5,000 draws and one downstream task; more rigorous, high-sample statistical tests across varied V, temperature, and masking regimes are not reported.
- KV-cache and LM-head weight streaming interplay is not detailed:
- The effect of LM-head weight layout (streaming, prefetching, compression) and cache behaviors (L2/L1/register pressure) on FlashSampling performance isn’t quantified.
- Software packaging and integration paths are undeveloped:
- There is no guidance or artifacts for integrating into cuBLASLt epilogues, TensorRT-LLM, vLLM at scale (multi-node), or autotuning frameworks, nor API contracts for RNG seeds, masks, and custom logits processors.
- Security/robustness considerations for on-chip RNG are unexamined:
- While likely low risk, potential side effects (e.g., cross-stream RNG state contamination, reproducibility under preemption, or MIG partitioning) are not discussed.
Practical Applications
Immediate Applications
Below is a set of actionable use cases that can be deployed with today’s tooling and hardware, leveraging the paper’s fused, exact Gumbel-Max sampling in the LM-head epilogue, online/grouped variants, and reduced inter-GPU communication.
- Faster LLM serving in production APIs and chatbots
- Sector: software/cloud inference, developer tools, customer support, search, creative assistants
- What: Replace materialized-logits sampling with FlashSampling in serving stacks (e.g., vLLM, TensorRT-LLM, custom Triton/CUTLASS epilogues) to reduce time per output token (TPOT) and end-to-end latency (reported up to ~19% on some models).
- Tools/workflows:
- Integrate Triton FlashSampling kernels as LM-head epilogues.
- Add a “FlashSampling” path to vLLM, OpenAI-style inference servers, and in-house inference engines.
- Use counter-based RNG (e.g., Philox) for deterministic/reproducible sampling in CI/regression tests.
- Assumptions/dependencies:
- GPU inference on Hopper/Blackwell-class hardware or similar with sufficient on-chip memory and support for custom kernels.
- Models with standard linear LM-heads; greatest gains for small batch sizes (decode regime).
- For top-p, adopt top-k-first-then-top-p logic on reduced candidates (as widely used in practice).
- Reduced cost and higher throughput for cloud providers
- Sector: cloud/infra, MLOps, FinOps
- What: Increase requests-per-GPU and reduce serving costs by eliminating post-GEMM sampling kernels and logits round-trips; improve bandwidth utilization in memory-bound decode paths.
- Tools/workflows:
- Benchmark with roofline and TPOT metrics before/after FlashSampling integration.
- Roll out canary deployments with continuous batching to validate p50/p95 latency improvements.
- Assumptions/dependencies:
- Benefits scale best when the LM head is a detectable bottleneck; attention/FFN-dominated models will see smaller gains.
- Requires ops readiness for upgrading inference containers and kernel dependencies (Triton/CUDA versions).
- Lower interconnect traffic in multi-GPU tensor-parallel setups
- Sector: cloud/infra, HPC, large-model serving
- What: Use the grouped/distributed variant to avoid all-gather of full logits; communicate only small per-shard summaries (local sample + log-mass), reducing communication to O(#shards) vs O(vocab).
- Tools/workflows:
- Integrate shard-local FlashSampling into TP pipelines; finalize selection with a small cross-rank reduction.
- Pair with NCCL collectives over small payloads; instrument network counters to confirm reductions.
- Assumptions/dependencies:
- Tensor-parallel LM-head sharding in place; frameworks (vLLM, DeepSpeed, Megatron-like) must expose sharded logits hooks.
- Correct masking/bias/temperature handling per shard (zero-mass shards are skipped exactly).
- On-device and edge inference with tighter memory budgets
- Sector: mobile/edge AI, embedded devices, robotics
- What: Reduce HBM traffic by fusing sampling into the matmul epilogue and keeping logits on-chip; improve token latency for local assistants, real-time agents, and embedded copilots.
- Tools/workflows:
- Deploy Triton or vendor-provided fused epilogues in TensorRT or ONNX Runtime EPs where available.
- Align RNG indexing with device constraints for reproducibility.
- Assumptions/dependencies:
- Edge accelerators must support custom epilogues and have sufficient SRAM/register capacity for tiled processing.
- Model sizes and vocabularies compatible with device memory and latency targets.
- Real-time decision systems with large categorical outputs
- Sector: recommender systems, ads ranking, routing, operations research, some RL inference
- What: Embed FlashSampling into the final linear layer to sample from very large catalogs/action spaces (exact Gumbel-Max) without materializing logits, reducing latency in live serving.
- Tools/workflows:
- Replace softmax-prefix pipelines with online Gumbel-Max reductions in the epilogue of the last projection.
- Use the online (streaming) variant when memory is limited, maintaining running log-masses and a single candidate.
- Assumptions/dependencies:
- The action or item distribution is derived from a (possibly masked/bias/temperature-transformed) linear projection.
- If policies require differentiable sampling during training, Gumbel-Softmax (relaxation) is separate; FlashSampling targets inference-time exact sampling.
- Safety- and compliance-sensitive deployments requiring exactness
- Sector: healthcare, finance, legal, public sector
- What: Retain exact sampling semantics (no approximations) to ensure statistical fidelity of outputs while reducing latency and memory traffic.
- Tools/workflows:
- Use deterministic RNG seeding for auditability and reproducible runs.
- Validate with chi-squared tests or bootstrap accuracy checks as in the paper’s correctness section.
- Assumptions/dependencies:
- Sampling policy must remain unchanged (e.g., same temperature/masking); nucleus sampling should be applied after a top-k reduction when needed.
- Library and framework enhancements
- Sector: AI software ecosystem
- What: Upstream a fused “sample epilogue” to CUTLASS/cuBLASLt, Triton templates, PyTorch custom ops, and FlashInfer plugins so users adopt via version upgrades.
- Tools/workflows:
- Provide drop-in APIs mirroring existing sampler signatures; expose toggles for grouped/distributed/online modes.
- Add kernel tests for exactness and RNG determinism; include perf CI on target GPUs.
- Assumptions/dependencies:
- Vendor libraries must accept new epilogue hooks; maintenance and ABI stability across CUDA versions.
- Energy and cost reporting for “Green AI” KPIs
- Sector: policy/compliance within organizations, sustainability reporting
- What: Use measured reductions in kernel time and HBM traffic to report lower energy per token and cost per request.
- Tools/workflows:
- Integrate energy telemetry (e.g., NVML, data center meters) with inference runs pre-/post-FlashSampling.
- Assumptions/dependencies:
- Benefits depend on workload mix (decode-bound vs compute-bound); energy savings must be measured at system level, not inferred solely from kernel timing.
Long-Term Applications
These opportunities require further research, ecosystem changes, or hardware/software co-design to reach production scale.
- Vendor-supported GEMM epilogues for exact sampling
- Sector: semiconductor/hardware vendors, systems software
- What: Add first-class Gumbel-Max epilogues to cuBLASLt/CUTLASS, TensorRT-LLM, and compiler stacks (e.g., TVM/Mosaic) for portable performance with minimal code changes.
- Potential tools/products: “GEMM+Sample” epilogue APIs; auto-tuning for tile sizes; RNG hardware acceleration.
- Assumptions/dependencies:
- Vendor prioritization and ABI support; extensive cross-architecture validation.
- Persistent kernels and scheduling integration with continuous batching.
- Hardware co-design: RNG and Gumbel units in tensor cores
- Sector: hardware/accelerator design
- What: Introduce microarchitectural support for counter-based RNG and Gumbel transforms in GEMM epilogues to minimize latency and register pressure.
- Potential products: Next-gen GPU blocks offering “sample-ready” tensor cores; firmware-configurable epilogues.
- Assumptions/dependencies:
- ISA and microcode changes; clear security model for RNG; silicon lead times.
- Fully fused top-p (nucleus) and advanced decoding within matmul
- Sector: software ecosystems, LLM research
- What: Move beyond top-k-then-top-p to a single-pass nucleus selection or other adaptive truncation inside or immediately after the epilogue without materializing logits.
- Potential workflows: Epilogue-level approximate CDF estimation + exact finalization over a small candidate set; layered selection algorithms co-designed with FlashSampling.
- Assumptions/dependencies:
- New algorithms that avoid global sorts/prefix sums over V while retaining exactness or provable bounds.
- Extensive correctness testing to match existing decoding semantics.
- Generalization to beam search, contrastive decoding, and constrained grammars
- Sector: LLM decoding research, applied AI
- What: Extend tile-wise reduction and grouped-factorization to support beam candidates, contrastive objectives, and complex grammar constraints with minimal HBM writes.
- Potential tools: Beam-aware epilogues maintaining per-beam tile maxima; grammar-aware masking fused pre-perturbation.
- Assumptions/dependencies:
- Maintaining exactness for multi-candidate objectives; managing state growth in on-chip memory.
- Split- and federated-inference communication minimization
- Sector: edge/cloud, telecom
- What: Use grouped/distributed FlashSampling to reduce cross-device communication when vocabularies are sharded across heterogeneous nodes (e.g., edge-cloud split inference).
- Potential workflows: Shard-local sampling with small-metadata uplinks; policy selection at aggregator; privacy-preserving sampling without exposing logits.
- Assumptions/dependencies:
- Consistent RNG/indexing across devices; robust handling of zero-mass shards and intermittent links.
- Large-categorical sampling beyond LLMs
- Sector: vision/audio tokenizers, generative compression, discrete diffusion, structured prediction
- What: Apply fused Gumbel-Max to other models with very large discrete output spaces (e.g., codebook tokenizers, discrete diffusion steps), avoiding full logits materialization.
- Potential tools: Library primitives for “final-layer fused sampling” in JAX/PyTorch; plugin heads for VQ-VAE/VQGAN-like models.
- Assumptions/dependencies:
- Existence of linear final projections or amenable transforms; domain-specific masking/truncation needs.
- Training-time synergies: fast sampling for RL/IL and negative sampling
- Sector: RL systems, large-scale training
- What: While FlashSampling targets inference, similar epilogues could accelerate frequent sampling in rollout or negative-sampling steps (exact at inference, relaxed for backprop where needed).
- Potential workflows: Action selection via exact Gumbel-Max in the forward pass; Gumbel-Softmax relaxation for gradient flow; hybrid training/inference kernels.
- Assumptions/dependencies:
- Clear separation of exact vs differentiable paths; compiler support for mixing epilogues in training graphs.
- Speculative decoding + vocabulary pruning co-design
- Sector: LLM optimization research, production inference
- What: Combine speculative decoding, vocab trimming, and FlashSampling to shrink candidate sets earlier and fuse exact sampling for remaining tokens, maximizing end-to-end gains.
- Potential workflows: Draft model proposes restricted vocab; FlashSampling runs exact selection on remaining tiles; dynamic group sizes per token.
- Assumptions/dependencies:
- Robust coordination of draft/target models; correctness under dynamic support changes; scheduling overheads kept low.
- Security and privacy hardening via reduced memory footprint
- Sector: security, compliance
- What: Explore whether avoiding HBM materialization of logits mitigates certain memory-snooping or snapshot risks in multi-tenant settings; formalize threat models.
- Potential tools: Memory forensics and side-channel analyses comparing materialized vs fused paths.
- Assumptions/dependencies:
- Real security benefits must be empirically demonstrated; GPU isolation and virtualization layers vary by cloud.
- Standardization and benchmarking for “exact fused sampling”
- Sector: benchmarking consortia, open-source
- What: Establish benchmarks, conformance tests (exactness under masks/temperature), and API standards for fused sampling operators across frameworks.
- Potential tools: MLPerf-like microbenchmarks for decode TPOT; conformance harness with chi-squared tests and paired bootstrap comparisons.
- Assumptions/dependencies:
- Community alignment and maintenance; coverage across diverse hardware/backends.
Glossary
- all-gather: A collective communication operation that concatenates data from all processes/ranks and distributes the result to each. "an all-gather concatenates the full logits before sampling,"
- arithmetic intensity: The ratio of computational operations to data movement (FLOPs per byte), used to analyze performance bounds. "An optimistic lower bound on arithmetic intensity is therefore"
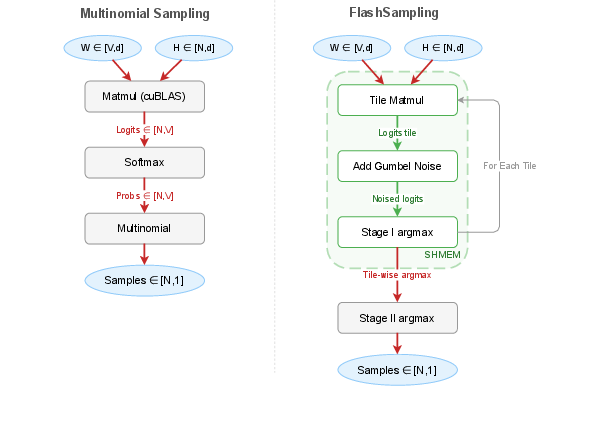
- argmax: The index of the maximum value in a set, often used to select the most likely outcome. "the fused tiled kernel is exact because decomposes over a partition;"
- autoregressive decoding: Sequential token generation where each step conditions on previously generated tokens. "Modern LLM serving stacks invoke sampling repeatedly during autoregressive decoding,"
- BF16: Brain floating point (bfloat16), a 16-bit floating-point format used for efficient ML computation. "For a BF16 baseline that materializes logits,"
- categorical distribution: A discrete probability distribution over a finite set of outcomes. "Sampling from a categorical distribution is mathematically simple,"
- chi-squared goodness-of-fit test: A statistical test comparing observed frequencies to expected frequencies under a target distribution. "we compare samples from FlashSampling to the reference PyTorch implementation using a chi-squared goodness-of-fit test on 5,000 samples,"
- counter-based RNG: A random number generator where outputs are a deterministic function of a counter and key, enabling reproducibility and parallelism. "using a counter-based RNG (e.g.\ Philox)"
- cuBLAS: NVIDIA’s CUDA-optimized BLAS library for high-performance linear algebra on GPUs. "Logits are also materialized using cuBLAS."
- decode regime: The inference setting emphasizing token-by-token generation, typically with small batch sizes. "Decode regime."
- epilogue (matmul epilogue): The post-matrix-multiplication phase where fused operations (e.g., sampling) are applied before writing results to memory. "fuses sampling into the matmul epilogue,"
- GEMM: General Matrix-Matrix Multiplication, a core linear algebra operation. "GEMM: compute logits and write to HBM"
- Group-Gumbel-Max: A hierarchical sampling method that factors the categorical distribution into groups, sampling a group then within-group exactly. "Group-Gumbel-Max: Hierarchical Exact Sampling"
- GSM8K: A benchmark dataset of grade-school math problems used to evaluate reasoning. "We run FlashSampling on 1,319 questions from the GSM8K dataset"
- Gumbel-Max trick: An exact sampling method that selects the argmax of logits perturbed by i.i.d. Gumbel noise. "The classical Gumbel-Max trick states that exact categorical sampling can be performed by adding i.i.d.\ Gumbel noise and taking an :"
- Gumbel-Top-k: An extension enabling sampling without replacement by taking the top-k of Gumbel-perturbed logits. "The trick extends to sampling without replacement via the Gumbel-Top- method"
- Gumbel(0,1): The standard Gumbel distribution with location 0 and scale 1, used for perturbation in Gumbel-Max. "i.i.d.\ ."
- HBM (High Bandwidth Memory): A high-throughput off-chip memory used in GPUs; access is slower than on-chip memory. "never materializes the logits tensor in HBM."
- hierarchical factorization: Decomposing a distribution into nested components (e.g., group selection then within-group sampling) for exact sampling. "hierarchical factorization of the categorical distribution."
- i.i.d.: Independent and identically distributed, a key assumption for random variables in many algorithms. "We denote i.i.d.\ standard Gumbel variables by ."
- LM-head: The final linear projection layer mapping hidden states to vocabulary logits in LLMs. "At decode time, the LM-head projection already streams a large weight matrix from HBM."
- log-mass: The log of the total probability mass within a group, i.e., log-sum-exp over group logits. "its group log-mass ."
- logits: Unnormalized scores (pre-softmax) output by a model. "Materializing the resulting logits tensor,"
- matmul: Matrix multiplication; in this context, the LM-head matrix-vector or matrix-matrix computation. "can be integrated into the matmul itself,"
- max-stability: A property of Gumbel distributions where maxima of Gumbel-perturbed variables preserve distributional form. "Gumbel max-stability under grouping"
- memory-bandwidth bound: A performance regime where data movement, not computation, limits throughput. "this projection is typically memory-bandwidth bound."
- Mixture-of-Experts (MoE): An architecture that routes inputs to a subset of specialized expert networks. "Qwen3-235B-A22B MoE."
- multinomial sampling: Drawing an outcome from a categorical distribution based on its probability mass function. "Conventional multinomial sampling (left) materializes the full logits tensor in HBM"
- nucleus sampling (top-p): A truncation strategy that samples from the smallest set of tokens with cumulative probability at least p. "Top- (nucleus):"
- on-chip memory: Fast, small-capacity memory on the GPU (registers and SRAM) used to avoid costly HBM traffic. "On-chip memory (registers, SRAM) is orders of magnitude faster than HBM"
- ops:byte ratio: A hardware metric (peak operations per second divided by memory bandwidth) indicating the compute vs. bandwidth balance. "The ops:byte ratio (peak compute / bandwidth) contextualizes the crossover between bandwidth- and compute-limited regimes,"
- paired bootstrap test: A statistical method for comparing two systems by resampling paired outcomes to estimate significance. "This difference is not statistically significant (p=0.776), according to a paired bootstrap test."
- Philox: A counter-based GPU-friendly pseudo-random number generator ensuring reproducible parallel streams. "using a counter-based RNG (e.g.\ Philox)"
- prefix sum: The cumulative sum of a sequence, used in sampling-by-search over cumulative probabilities. "No softmax, no normalization constant, and no prefix sum are required"
- prefix-sum sampling: Sampling by computing cumulative probabilities (CDF) and searching for a threshold. "softmax followed by prefix-sum sampling:"
- roofline: A performance model/plot relating arithmetic intensity to achieved performance relative to hardware ceilings. "Roofline Analysis and Bandwidth Utilization"
- sharded (vocabulary sharding): Partitioning the vocabulary across multiple devices/ranks for tensor parallelism. "the vocabulary is sharded across ranks,"
- softmax: The exponential normalization transforming logits into probabilities. "exact sampling does not require an explicit softmax."
- SRAM: Static random-access memory on chip, faster but smaller than HBM. "On-chip memory (registers, SRAM) is orders of magnitude faster than HBM"
- tensor-parallel: A model-parallelism strategy that splits tensors (e.g., vocabulary) across devices to distribute computation. "tensor-parallel settings"
- tile (vocabulary tile): A contiguous chunk of the vocabulary processed locally before a final reduction. "vocabulary tile"
- top-k: Truncation to the k highest-scoring tokens prior to sampling. "Top-:"
- TPOT (time per output token): A latency metric measuring average time to generate each token during inference. "We benchmark TPOT"
- Triton: A GPU programming system for writing high-performance kernels in Python-like code. "All benchmarks use the open-source FlashSampling Triton implementation"
- vLLM: A high-performance LLM inference engine with continuous batching and optimized kernels. "end-to-end vLLM experiments,"
Collections
Sign up for free to add this paper to one or more collections.