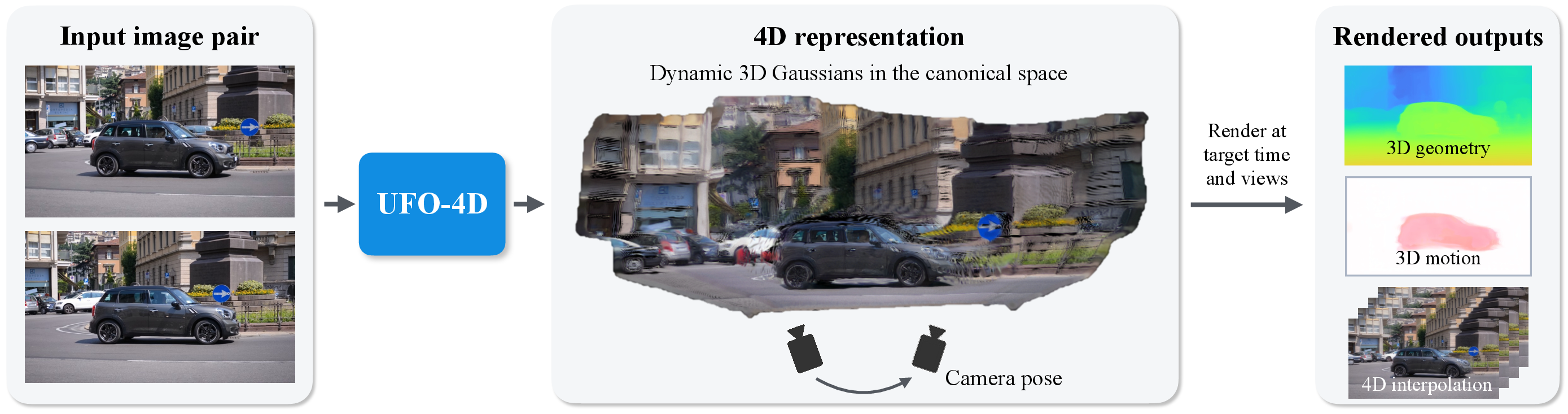
UFO-4D: Unposed Feedforward 4D Reconstruction from Two Images
Abstract: Dense 4D reconstruction from unposed images remains a critical challenge, with current methods relying on slow test-time optimization or fragmented, task-specific feedforward models. We introduce UFO-4D, a unified feedforward framework to reconstruct a dense, explicit 4D representation from just a pair of unposed images. UFO-4D directly estimates dynamic 3D Gaussian Splats, enabling the joint and consistent estimation of 3D geometry, 3D motion, and camera pose in a feedforward manner. Our core insight is that differentiably rendering multiple signals from a single Dynamic 3D Gaussian representation offers major training advantages. This approach enables a self-supervised image synthesis loss while tightly coupling appearance, depth, and motion. Since all modalities share the same geometric primitives, supervising one inherently regularizes and improves the others. This synergy overcomes data scarcity, allowing UFO-4D to outperform prior work by up to 3 times in joint geometry, motion, and camera pose estimation. Our representation also enables high-fidelity 4D interpolation across novel views and time. Please visit our project page for visual results: https://ufo-4d.github.io/






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a fast computer vision method called UFO-4D that can understand a moving 3D scene (including time, or “4D”) from just two ordinary photos taken with unknown camera positions. In one quick step, it figures out the 3D shape of things, how they’re moving, and where the camera was for each photo. It can also “fill in” what the scene would look like from new viewpoints or at times between the two photos.
What questions did the researchers ask?
They focused on three simple questions:
- Can we rebuild a detailed 3D scene that changes over time using only two pictures?
- Can we do this fast, without slow, extra steps during testing?
- Can we get better results by using one shared scene representation for everything (appearance, depth, and motion) so that learning one helps the others?
How did they do it? (In everyday language)
Think of the scene as being made of many soft, colored “puffballs” of fog in 3D space. Each puffball has:
- A 3D position (where it is)
- A size and shape
- A color that changes with viewing direction
- An opacity (how see-through it is)
- A velocity (which way it’s moving in 3D)
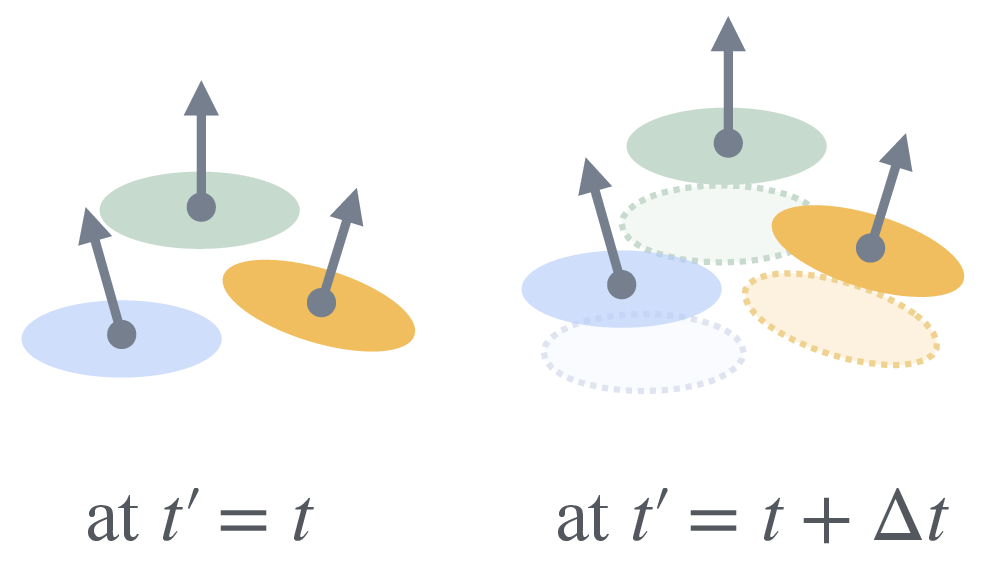
These puffballs are called “3D Gaussians.” Because they also move over time, the paper calls them “Dynamic 3D Gaussians.”
Here’s the idea:
- Input: Two images and simple camera info (like focal length).
- Output:
- A cloud of moving puffballs that explain what’s in the scene.
- The relative camera pose (where the second camera was compared to the first).
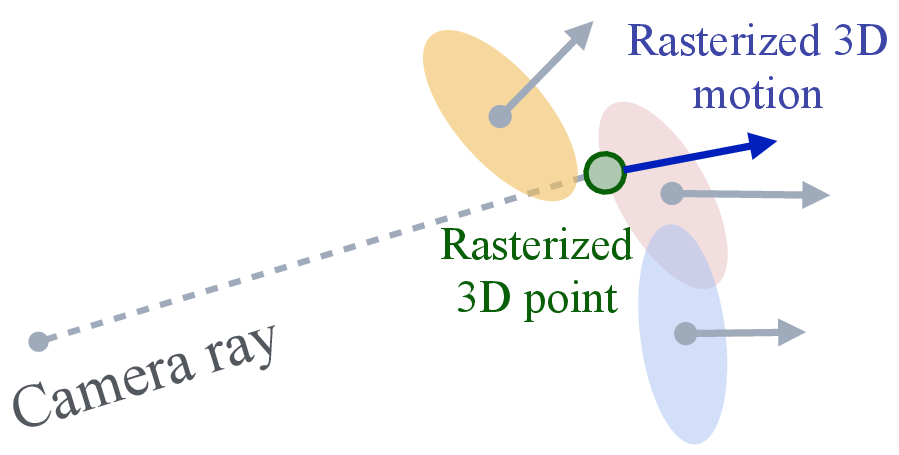
To “see” what the puffballs look like from a camera, the method “renders” them, like drawing semi-transparent stickers layered front-to-back (this is called alpha blending). The same rendering trick can produce:
- A color image (what the camera would see)
- A depth map (how far away each pixel is)
- A motion map (how each point moves in 3D, also called “scene flow”)
Because rendering is differentiable (the computer can measure how a tiny change in a puffball changes the final image), the system can learn by comparing its rendered image to the real input images. This is called “self-supervision”: the model teaches itself by trying to recreate what it sees. When ground-truth labels are available (like depth or motion from a dataset), it also uses them (supervised learning).
Two helpful analogies:
- Differentiable rendering: Imagine tweaking a drawing and instantly seeing how the final picture changes; then adjust the drawing to better match the original photo.
- Shared representation: Since the same puffballs create both the picture and the depth/motion, making the picture more accurate usually improves depth and motion too.
Bonus: The model learns opacity like “confidence.” In areas with occlusions (something blocking the view), it learns to give more weight to the puffballs that best explain what’s actually visible.
What did they find and why is it important?
Main results:
- Accuracy: UFO-4D beats previous methods on multiple benchmarks for 3D shape (depth/point accuracy), 3D motion (scene flow), and camera pose. On some motion tasks, it reduces error by about 3× compared to others.
- Speed: It works in a single, feedforward pass (no slow extra optimization), making it practical for real-time or interactive use.
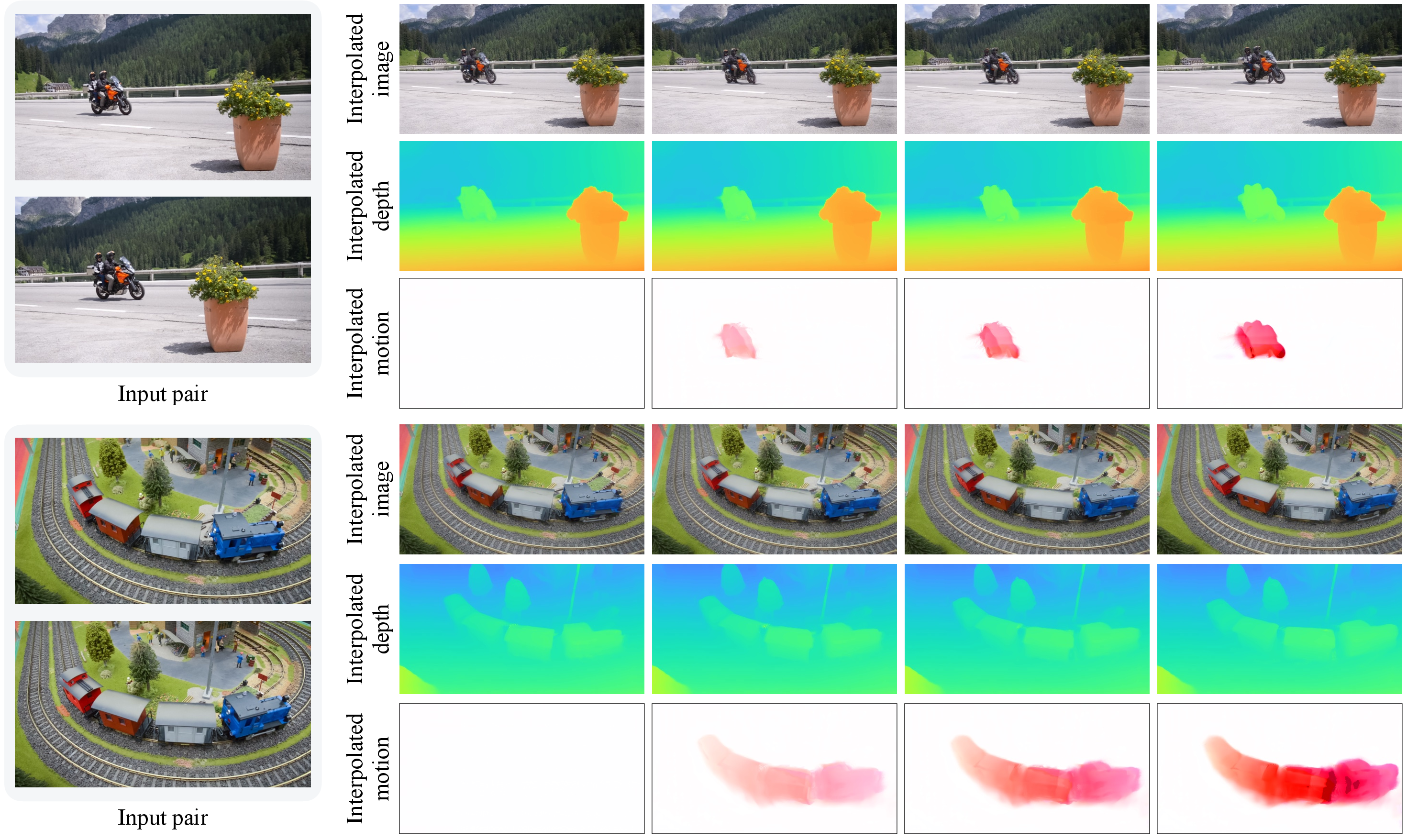
- Versatility: With the puffball scene, the method can render new viewpoints and times between the two images—this is 4D interpolation. It can also produce 2D optical flow (pixel motion), segment moving objects, and more, all from the same representation.
Why it matters:
- Many systems—like robots, self-driving cars, AR/VR, and creative AI—need quick, reliable understanding of what’s in front of a camera and how it’s moving. Doing this from just two images, without knowing the camera positions, is very useful in everyday situations.
- The shared 4D representation ties together appearance, depth, and motion so that learning one improves the others. This helps especially when labeled training data is limited.
What could this change?
Potential impact:
- Robotics and autonomous driving: Faster, more robust scene understanding with fewer input requirements (only two images).
- AR/VR and 3D content creation: Easily generate views from new angles and times for immersive experiences.
- Video and 4D generative AI: Provide a strong “structure-and-motion” backbone for producing consistent dynamic 3D scenes.
Looking ahead:
- Extending to longer video sequences while keeping memory use low.
- Handling complex motions (not just straight-line moves) and changing lighting more naturally.
In short, UFO-4D shows that a unified, explicit 4D “puffball” model can learn from just two images to produce high-quality 3D shape, motion, and camera pose—quickly—and even create realistic views at new times and angles.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains uncertain, missing, or unexplored, framed to guide concrete future investigations:
- Two-frame limitation: How to extend the method beyond two images to long sequences without linear growth in Gaussians, memory blow-up, or drift in pose/geometry/motion over time.
- Temporal consistency across >2 frames: Absent mechanisms for maintaining temporal correspondences, identities, or cycle consistency across multiple frames; no long-term tracking evaluation.
- Linear motion assumption: The model assumes per-Gaussian constant-velocity motion between frames; it does not model acceleration, rotations, or non-linear/deformable motions (e.g., articulated bodies), nor time-varying covariance/color.
- Photometric constancy: Training relies on photometric reconstruction with implicit constant-brightness assumptions; robustness to illumination changes, exposure differences, specularities, cast shadows, and view- or time-dependent appearance is not quantified.
- Unknown robustness to camera intrinsics: The method requires intrinsics at test time but does not study sensitivity to intrinsics errors, unknown intrinsics, lens distortions, or rolling-shutter effects.
- Scale ambiguity: Depth/scene-flow metrics use per-image median scaling; the ability to recover metric scale from two frames remains unresolved and unquantified.
- Pose generalization: Pose accuracy is reported on short-baseline datasets; performance under large baselines, extreme parallax, or large viewpoint changes is not evaluated.
- Efficiency and resource usage: The paper omits inference-time speed, memory footprint, and scalability with image size and number of Gaussians; practical constraints for real-time or mobile deployment remain unknown.
- Gaussian count tied to pixels: One Gaussian per input pixel (per image) can be redundant; strategies for adaptive Gaussian selection, pruning, or merging (and their impact on accuracy/speed) are not explored.
- Gaussian scale/overlap control: Large, overlapping Gaussians harm performance in textureless regions (e.g., Bonn); there is no principled regularization or selection mechanism to constrain covariance sizes or overlap.
- Differentiable rasterization at occlusions: Depth ordering changes and alpha compositing introduce non-smooth gradients at occlusion boundaries; training stability and gradient quality in these regions are not analyzed.
- Bias in blended geometry/motion: Rendering points and motion via alpha-blended Gaussian centers can bias geometry near depth discontinuities; quantitative analysis of depth/motion accuracy at edges is missing.
- Opacity as confidence: While opacity emerges as a confidence-like weight, its calibration, reliability, and utility for uncertainty-aware downstream tasks (e.g., pose estimation, planning) are not evaluated.
- Failure modes: Beyond a brief note on “floaters,” there is no systematic characterization of common failure cases (e.g., motion blur, low light, thin structures, topological changes, non-rigid fluids/cloth).
- Domain generalization: Training uses a 10% subset of Stereo4D plus synthetic data; generalization to broader real-world domains (e.g., handheld videos, challenging outdoor/indoor scenes), and the impact of training set composition, are only partially studied.
- Evaluation gaps for 2D tasks: Although optical flow is derivable from scene flow, no quantitative optical-flow benchmarks are reported; the quality of 2D projections (flow, segmentation) remains unvalidated.
- Novel view/time synthesis: 4D interpolation is shown qualitatively on DAVIS; there is no quantitative evaluation of novel-view/time rendering fidelity or comparisons to video/4D synthesis baselines.
- Handling of large time gaps: The model is tuned for short time intervals; robustness to larger time gaps, variable frame rates, or irregular time sampling is not assessed.
- Ambiguity resolution: The method benefits from coupling losses via a shared representation, but it lacks explicit geometric constraints (e.g., forward–backward flow consistency, rigidity priors) that could regularize ambiguous regions.
- Pose token behavior: The learnable pose token is not ablated; its role in convergence and generalization, and whether it encodes dataset biases, is unclear.
- Non-Lambertian and dynamic reflectance: Spherical harmonics capture view dependence, but time-dependent reflectance (e.g., changing materials, flickering lights) is not modeled or studied.
- Camera models and distortions: The pipeline assumes pinhole intrinsics without explicit distortion/rolling shutter models; incorporating and evaluating more realistic camera models is left open.
- Quantization of SH/color and capacity: The number of SH coefficients k and trade-offs between appearance fidelity and geometry accuracy are not detailed or ablated.
- Comparative fairness: Some baselines use different training data/recipes; while an architectural ablation is provided, broader, controlled comparisons (including test-time optimization methods) on both quality and runtime are incomplete.
- Reproducibility details: Training on varying aspect ratios and multiple datasets is mentioned, but detailed hyperparameters for all heads, loss weights, and data preprocessing are not fully enumerated for replication.
Practical Applications
Overview
The paper presents UFO-4D, a unified, feedforward method that reconstructs a dense, explicit 4D scene (geometry, motion, and relative camera pose) from just two unposed images. It predicts Dynamic 3D Gaussian Splatting (D-3DGS) primitives and differentiably renders appearance, depth/pointmaps, and scene flow at arbitrary views and times. The model enables fast, pose-free 4D understanding and high-fidelity spatio-temporal interpolation, outperforming prior work on multiple benchmarks.
Below are practical applications that derive from these capabilities.
Immediate Applications
The following applications can be prototyped or deployed with current capabilities (two images + camera intrinsics, short time interval, and GPU-accelerated inference).
- 3D-aware motion perception for mobile robots and drones
- Sectors: Robotics, Logistics
- What it does: From two camera frames, produce relative pose, dense depth, and scene flow to segment moving obstacles and estimate short-horizon dynamics for local planning.
- Tools/products/workflows: ROS2 node exposing depth/scene-flow/pose; integration as a motion prior in VIO/SLAM; onboard micro-drone perception aid.
- Assumptions/dependencies: Known intrinsics; short time gaps; moderate texture; linear-motion approximation between frames.
- Dynamic object segmentation and depth for ADAS dashcams
- Sectors: Automotive, Insurance
- What it does: Distinguish moving vehicles/pedestrians from background and estimate their 3D motion from successive monocular frames.
- Tools/products/workflows: Perception module plug-in for existing ADAS stacks; offline crash-reconstruction aid for adjusters.
- Assumptions/dependencies: Variable lighting and fast ego-motion may require domain adaptation; scale recovery may need priors.
- AR “3D live photo” and parallax effects from two photos
- Sectors: Consumer Software, Social Media
- What it does: Generate dynamic 3D portraits and parallax “dolly” shots, with motion-aware depth and object separation for cinematic effects.
- Tools/products/workflows: Mobile SDK; filters for Instagram/TikTok/Snap; on-device Gaussian-asset export (.splat/.ply with SH).
- Assumptions/dependencies: Two images of the same scene in quick succession; rolling-shutter and exposure changes can affect quality.
- View and time interpolation for video editing and VFX
- Sectors: Media/Entertainment, Software
- What it does: Frame interpolation, novel-view rendering, motion-consistent rotoscoping from only two input frames; fast match-moving via feedforward pose + depth.
- Tools/products/workflows: Plugins for Adobe After Effects/Premiere, Nuke, Blender, Unreal; WebGL viewers for D-3DGS.
- Assumptions/dependencies: Short intervals; strong occlusions/textureless regions may need manual cleanup; GPU rasterization required.
- Lightweight 3D product visuals for e-commerce
- Sectors: Retail/E-commerce, Marketing
- What it does: From two product photos, produce depth-based “3D look” or short dynamic turntable-like effects (or static 3D in zero-motion cases).
- Tools/products/workflows: Web service that converts photo pairs to splat-based viewers; storefront embed with client-side rendering.
- Assumptions/dependencies: Static scenes preferred; consistent lighting; monoplanar backgrounds help quality.
- Construction and industrial inspection overlays
- Sectors: AEC (Architecture/Engineering/Construction), Manufacturing
- What it does: Quick relative measurements, motion of components, and depth overlays from two images (e.g., check part displacement or conveyor flow).
- Tools/products/workflows: Field app to capture two images and visualize 3D/flow overlays; PDF/HTML reports.
- Assumptions/dependencies: Relative (not absolute) scale unless a known scale marker is present; line-of-sight and texture needed.
- Semi-automatic rotoscoping and moving-object masks
- Sectors: Media/Entertainment, Education
- What it does: Motion-aware masks and depth mattes from two frames to rapidly initialize editing pipelines.
- Tools/products/workflows: NLE plugin exporting masks/alpha mattes; integration with diffusion-based inpainting for edits.
- Assumptions/dependencies: Performance can degrade on fine, low-contrast edges; manual refinement may still be needed.
- Dataset bootstrapping for 3D/4D research
- Sectors: Academia, R&D (Software/AI)
- What it does: Produce pseudo-labels (depth, scene flow, pose) from two unposed images to augment training data across tasks with consistent 4D signals.
- Tools/products/workflows: PyTorch/Colab package; batch processing pipelines for video datasets; exporters to common formats.
- Assumptions/dependencies: Quality depends on domain match (trained on Stereo4D/POA/VKITTI2); advisable to filter uncertain outputs (e.g., via learned opacity as confidence).
- Bandwidth-aware visual communication (microcodecs)
- Sectors: Networking/Streaming, Edge Computing
- What it does: Transmit two key frames + compact D-3DGS to reconstruct intermediate frames/views on the receiver, reducing bandwidth for short clips.
- Tools/products/workflows: Experimental codec module that packages Gaussian parameters and SH coefficients; receiver-side splat renderer.
- Assumptions/dependencies: Requires standardization and runtime guarantees; benefits mainly for short segments with moderate motion.
- Map initialization and dynamic-scene filtering for SLAM
- Sectors: Robotics, AR
- What it does: Provide fast feedforward pose and depth to initialize SLAM and remove dynamic objects using scene flow masks.
- Tools/products/workflows: Front-end module for ORB-SLAM, TartanVO, or NeRF-in-the-loop pipelines.
- Assumptions/dependencies: Two-frame-only assumptions limit long-term consistency; short baseline works best.
Long-Term Applications
These applications require additional research, longer sequences, scaling, hardware acceleration, domain adaptation, or standardization to achieve robust deployment.
- Live 4D perception on AR glasses and mobile devices
- Sectors: AR/VR, Consumer Electronics
- What it could do: Real-time 4D mapping and dynamic occlusion handling from sliding two-frame windows on-device; persistent dynamic assets.
- Tools/products/workflows: Dedicated splatting accelerators; memory-compact Gaussian representations; streaming pipelines.
- Assumptions/dependencies: Power/latency constraints; need compact, persistent scene representation and non-linear motion modeling.
- Primary motion and depth engine in autonomous vehicles
- Sectors: Automotive
- What it could do: Serve as a low-latency, learned “motion head” fused with LiDAR/radar to enhance short-horizon planning and tracking.
- Tools/products/workflows: Multi-camera fusion; robustness-certified perception stack; hardware acceleration.
- Assumptions/dependencies: Safety certification; robustness to adverse weather, nighttime, very high-speed scenarios; scale ambiguity resolution.
- Conditioning and supervision for 4D generative models
- Sectors: Creative AI, Media/Entertainment
- What it could do: Provide consistent 3D/4D conditioning for video diffusion or NeRF-like generators; stabilize multi-view, multi-frame content.
- Tools/products/workflows: Adapters from D-3DGS to latent conditions; training with splat-rendered photometric losses.
- Assumptions/dependencies: Bridging domain gaps; training cost; joint optimization with generative backbones.
- Dynamic digital twins from sparse cameras
- Sectors: Smart Infrastructure, Energy, Manufacturing
- What it could do: Update the state of assets (machines, conveyors, valves) from sparse camera pairs; derive kinematic states via scene flow.
- Tools/products/workflows: SCADA integration; temporal graph of Gaussian primitives; anomaly detection on motion fields.
- Assumptions/dependencies: Multi-time/long-sequence consistency; occlusions and reappearing objects; non-linear motion models.
- Telepresence and free-viewpoint communications
- Sectors: Communications, Collaboration Tools
- What it could do: Two webcams or dual-lens phones reconstruct dynamic 3D assets for free-viewpoint telepresence and viewpoint changes at the receiver.
- Tools/products/workflows: End-to-end 4D streaming stack; D-3DGS compression; depth-aware audio-visual sync.
- Assumptions/dependencies: Real-time constraints; privacy and provenance; calibration and exposure control.
- Medical and biomedical motion analysis from minimal frames
- Sectors: Healthcare
- What it could do: Estimate organ/tissue motion from two endoscopy/ultrasound frames for navigation, registration, or motion compensation.
- Tools/products/workflows: Domain-adapted training; integration with surgical navigation systems.
- Assumptions/dependencies: Major domain shift; need robust clinical validation and regulatory approval; specialized intrinsics and photometric models.
- Environmental monitoring and ecology
- Sectors: Public Sector, Conservation
- What it could do: Reconstruct wildlife or debris motion from sparse trail-cam captures; quick 3D motion analysis during disasters from limited imagery.
- Tools/products/workflows: Field-deployable pipelines; automated confidence filtering via opacity maps.
- Assumptions/dependencies: Scale/metric ambiguity; variable intrinsics; occlusions and large time gaps.
- Edge video analytics with 4D feature offloading
- Sectors: IoT, Smart Cities
- What it could do: Cameras compute compact 4D splats and only upload high-confidence dynamic elements, reducing uplink while keeping actionable signals.
- Tools/products/workflows: On-camera accelerators; event-triggered uploads; server-side re-rendering and analytics.
- Assumptions/dependencies: Efficient embedded rasterizers; power budgets; security.
- Standards, governance, and provenance for synthesized views/times
- Sectors: Policy/Standards, Media
- What it could do: Define disclosure, watermarking, and provenance for 4D view/time synthesis to mitigate misuse; establish eval suites for dynamic 4D perception.
- Tools/products/workflows: Content authenticity pipelines (e.g., C2PA extensions for 4DGS); public benchmarks and stress tests.
- Assumptions/dependencies: Cross-industry coordination; legal frameworks for synthetic viewpoints and reconstructed evidence.
- Consumer 4D capture and display (holographic/compute-light-field)
- Sectors: Consumer Electronics, Retail
- What it could do: Create 4D keepsakes or holographic prints from a couple of shots; render on future light-field or holographic displays.
- Tools/products/workflows: Capture guidance and UX; 4D print pipelines; standard splat formats for display drivers.
- Assumptions/dependencies: Display ecosystem maturity; capture ergonomics; storage and standardization.
Key Assumptions and Dependencies Affecting Feasibility
- Input requirements: Two images of the same scene with known intrinsics; best for short time intervals.
- Model assumptions: Linear motion and approximate brightness constancy between frames; may underperform with non-linear dynamics, rolling shutter, or strong illumination changes.
- Scene properties: Textureless areas and heavy occlusions can degrade accuracy; learned opacity helps but is not foolproof.
- Scale ambiguity: Without additional cues, outputs are typically up to scale; metric measurements require priors (e.g., object size, IMU, stereo baseline).
- Compute: Differentiable rasterization and SH rendering benefit from GPU acceleration; embedded/real-time use may need hardware support.
- Domain gap: Training on Stereo4D/POA/VKITTI2 implies adaptation for specialized domains (medical, nighttime driving, underwater, etc.).
- Data governance: View/time synthesis can create plausible-yet-synthetic content; applications in forensics/insurance require provenance and uncertainty reporting.
These considerations help determine whether an application is immediately deployable or should be slated for longer-term research and development.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit point-based graphics representation that rasterizes 3D Gaussian primitives to render images or attributes. Example: "we then follow the standard alpha-blending pipeline from 3DGS~\citep{Kerbl:2023:3DG, Luiten:2024:D3D}."
- 4D interpolation: Interpolating across both time and viewpoint in a dynamic scene representation. Example: "Our representation also enables high-fidelity 4D interpolation across novel views and time."
- Absolute Relative Error (Abs. Rel.): A depth error metric measuring the relative deviation between predicted and ground-truth depth values. Example: "For depth, we report standard depth metrics, absolute relative error (Abs.~Rel.) and percentage of inlier points ()."
- Absolute Trajectory Error (ATE): A camera pose metric quantifying accumulated drift in estimated trajectory compared to ground-truth. Example: "We report standard metrics, ATE and RPE translation () and rotation () for pose estimation..."
- Alpha-blending: A compositing technique that blends contributions of overlapping primitives using their opacities along a ray. Example: "we then follow the standard alpha-blending pipeline from 3DGS~\citep{Kerbl:2023:3DG, Luiten:2024:D3D}."
- Backpropagation: The process of propagating gradients through a computational graph to enable end-to-end learning. Example: "supervision signals from rendered images, point maps, and flow maps to be backpropagated through the rasterizer..."
- Bundle adjustment: A nonlinear optimization that jointly refines camera poses and 3D structure using reprojection errors. Example: "Canonical approaches... rely on a well-established pipeline based on projective geometry, such as feature extraction, triangulation, bundle adjustment, \etc."
- Canonical camera coordinate: A reference camera coordinate frame to which 3D predictions are aligned. Example: "ground truth pointmap defined at the canonical camera coordinate."
- Canonical space: A fixed coordinate system used as the reference frame for dynamic reconstruction. Example: "All of the Gaussians and the relative camera pose are defined in the coordinate of first image , which serves as the canonical space."
- Camera intrinsics: Parameters (e.g., focal length, principal point) that define the internal geometry of a camera. Example: "given two images and their camera intrinsics, \ourmethod{} directly predicts the relative camera pose..."
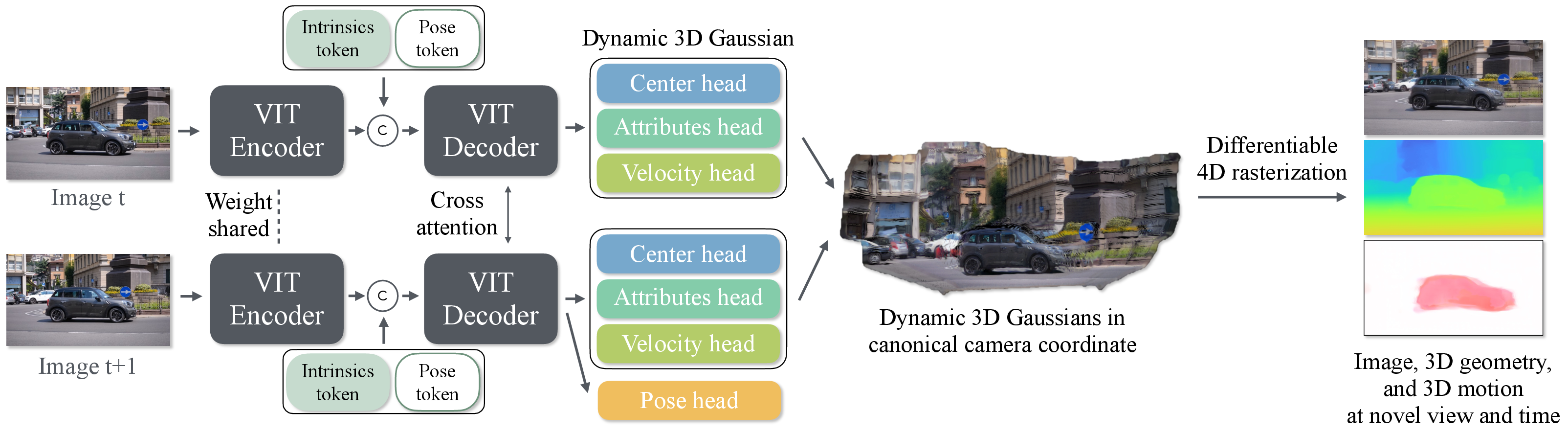
- Cross-attention: An attention mechanism that aligns and integrates information between token sets from different inputs. Example: "cross-attention layers within each attention block are responsible for matching and integrating information between the two input images..."
- Domain gap: The discrepancy between synthetic training data distributions and real-world data distributions. Example: "Synthetic datasets~\citep{Zheng:2023:POA} provide dense, pixel-perfect supervision, yet they often suffer from a significant domain gap and a lack of diversity."
- DPT (Dense Prediction Transformer): A transformer-based architecture specialized for dense prediction tasks. Example: "These heads use a DPT-based architecture~\citep{Ranftl:2021:DPT} with different output channel dimensions."
- Dynamic 3D Gaussian Splatting (D-3DGS): A spatio-temporal extension of 3DGS where Gaussians carry motion and time-varying attributes. Example: "Dynamic 3D Gaussian Splatting (D-3DGS), in a single forward pass."
- Edge-aware smoothness loss: A regularization encouraging smooth geometric or motion fields while respecting image edges. Example: "based on an edge-aware smoothness loss \citep{Godard:2017:UMD,Godard:2019:DIS}."
- End-to-end: Training a pipeline holistically so gradients flow through all components without separate stages. Example: "Even the whole pipeline can be end-to-end~\citep{Weinzaepfel:2023:CRO,Wang:2024:DUS,Wang:2025:vgg,...} when networks learn strong priors from large-scale data."
- End-Point Error (EPE): The Euclidean distance between predicted and ground-truth vectors (e.g., flow, points). Example: "We report end-point error (EPE) for pointmap accuracy..."
- Epipolar geometry: The geometric constraints governing correspondences between two calibrated views of a static scene. Example: "these methods specifically target static scenes that satisfy the epipolar geometry constraint."
- Feedforward: Inference without iterative optimization or test-time refinement; one pass through the network. Example: "We introduce \ourmethod{}, a unified feedforward framework to reconstruct a dense, explicit 4D representation..."
- Ill-posed problem: A problem lacking a unique or stable solution given limited observations. Example: "Recovering dense 4D information from limited 2D inputs, however, is an inherently ill-posed problem."
- LPIPS: A learned perceptual image patch similarity metric used for photometric supervision. Example: "LPIPS~\citep{LPIPS} loss between input images ( and ) and respective rasterized images..."
- MLP: A multi-layer perceptron neural network used for regression tasks (e.g., pose). Example: "The pose head, a 3-layer MLP, predicts the relative camera pose comprising a translation and quaternion ."
- Multi-view geometry: The study and algorithms for reconstructing 3D from multiple views using geometric constraints. Example: "The field of 3D reconstruction of static scenes, such as multi-view geometry~\citep{Ding:2022:TMV,Zhang:2023:GMV,Bae:2022:MVD}..."
- Novel view synthesis: Rendering images from viewpoints not present in the input data. Example: "Concurrent works are primarily designed for novel view synthesis and require camera poses at test time..."
- Occlusion and disocclusion: Visibility changes where surfaces become hidden or newly visible across time or viewpoints. Example: "this rasterization process naturally handles occlusion and disocclusion."
- Opacity: A per-primitive blending weight controlling contribution along a ray. Example: "and is the opacity computed from the projected 2D Gaussian."
- Optical flow: The 2D motion field of pixels between images induced by 3D motion and camera movement. Example: "motion (scene flow, optical flow)."
- Photometric loss: A reconstruction loss comparing rendered and observed images (e.g., MSE, perceptual). Example: "L_\text{photo} = \textstyle\sum_{u \in {t, t+1} \big( {\text{mse}(\hat{\mathbf{I}u, \mathbf{I}_u) + w{\text{lpips} \text{lpips}(\hat{\mathbf{I}_u, \mathbf{I}_u)} \big)"
- Pointcloud: A set of 3D points representing scene geometry, often lacking explicit connectivity. Example: "While these feedforward methods generate per-frame pointclouds, they lack temporal correspondence..."
- Pointmap: A dense per-pixel 3D point prediction aligned to a camera coordinate frame. Example: "render not only color images but also dense pointmaps and scene flow at any intermediate time ."
- Projective geometry: The mathematical framework for camera imaging and perspective projection. Example: "pipeline based on projective geometry, such as feature extraction, triangulation, bundle adjustment, \etc."
- Quaternion rotation: A 4D rotation representation used to parameterize Gaussian covariance orientation. Example: "covariance matrix parameterized by quaternion rotation ..."
- RANSAC: A robust estimation method using random sampling and consensus to fit models in the presence of outliers. Example: "which obtain pose via a PnP solver~\citep{Lepetit:2009:PNP} with RANSAC~\citep{Fischler:1981:RSC}..."
- Relative Pose Error (RPE): A pose metric measuring frame-to-frame translation and rotation errors. Example: "We report standard metrics, ATE and RPE translation () and rotation ()..."
- Scene flow: The 3D motion field of points in a scene across time. Example: "including depth, scene flow, and optical flow, all from the same underlying model."
- Self-supervised: Learning from intrinsic consistency (e.g., image synthesis) without dense external labels. Example: "enables a self-supervised image synthesis loss while tightly coupling appearance, depth, and motion."
- Simultaneous Localization and Mapping (SLAM): Estimating both camera trajectory and a map of the environment. Example: "simultaneous localization and mapping (SLAM)~\citep{Lipson:2024:DPV,Teed:2021:DRO,Zhu:2024:NSL}..."
- Spatio-temporal interpolation: Joint interpolation over space and time to synthesize intermediate states. Example: "4D spatio-temporal interpolation of image, depth, and motion as a new application of the feedforward output."
- Spherical harmonics: A basis for representing view-dependent color on the surface of a sphere. Example: "view-dependent color represented by spherical harmonics in each color channel ..."
- Structure from Motion (SfM): Recovering camera motion and 3D scene structure from image sequences. Example: "structure from motion (SfM)~\citep{Pan:2024:GSF,Lindenberger:2021:PPS,Wang:2024:VSV}..."
- Temporal correspondence: Consistent matching of points across time enabling motion understanding. Example: "they lack temporal correspondence, limiting their application to motion understanding tasks."
- Test-time optimization: Per-scene iterative fitting performed during inference rather than training. Example: "dynamic scene reconstruction has traditionally centered on slow, test-time optimization pipelines"
- Triangulation: Estimating 3D point positions from multiple 2D observations under camera models. Example: "such as feature extraction, triangulation, bundle adjustment, \etc."
- Vision Transformer (ViT): A transformer architecture processing image tokens for vision tasks. Example: "The encoded tokens are concatenated with an intrinsic token and a pose token and then fed into a ViT-based decoder."
Collections
Sign up for free to add this paper to one or more collections.

