Flow4R: Unifying 4D Reconstruction and Tracking with Scene Flow
Abstract: Reconstructing and tracking dynamic 3D scenes remains a fundamental challenge in computer vision. Existing approaches often decouple geometry from motion: multi-view reconstruction methods assume static scenes, while dynamic tracking frameworks rely on explicit camera pose estimation or separate motion models. We propose Flow4R, a unified framework that treats camera-space scene flow as the central representation linking 3D structure, object motion, and camera motion. Flow4R predicts a minimal per-pixel property set-3D point position, scene flow, pose weight, and confidence-from two-view inputs using a Vision Transformer. This flow-centric formulation allows local geometry and bidirectional motion to be inferred symmetrically with a shared decoder in a single forward pass, without requiring explicit pose regressors or bundle adjustment. Trained jointly on static and dynamic datasets, Flow4R achieves state-of-the-art performance on 4D reconstruction and tracking tasks, demonstrating the effectiveness of the flow-central representation for spatiotemporal scene understanding.
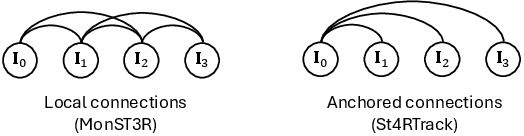

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper presents Flow4R, a smart computer vision system that can understand how a 3D scene changes over time using just two images. It does two big jobs at once:
- Rebuild the 3D shape of the scene (reconstruction).
- Follow how things move in the scene (tracking), including both the camera and objects.
Flow4R’s main idea is to focus on “scene flow,” which is like a map of how every point in the picture moves from one image to the next. By making scene flow the center of the problem, the system can figure out both the structure (where things are in 3D) and motion (how they move) together, instead of treating them separately.
What questions does the paper try to answer?
- How can we unify 3D reconstruction and motion tracking in one simple system?
- Can we avoid complicated, separate steps like estimating the camera’s position with a special module or doing heavy optimization after the fact?
- Can we make a model that works well on both static scenes (no moving objects) and dynamic scenes (moving objects), using the same idea?
- Can two images be enough to predict both 3D shape and motion reliably?
How does Flow4R work?
The core idea: scene flow
Think of scene flow as instructions for how each point in a scene moves between two pictures. Some of that motion comes from the camera moving; some comes from objects moving. Flow4R learns this movement in the camera’s space so it doesn’t depend on choosing a “world frame” (like saying the ground is fixed). That makes it flexible for different situations.
What the model predicts from two images
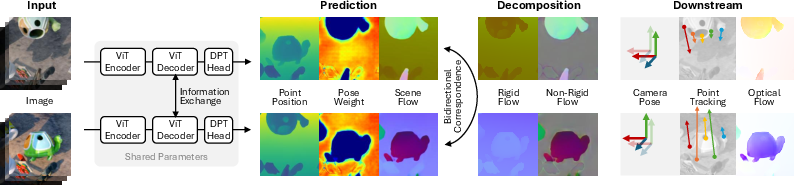
From a pair of images taken at different times or viewpoints, Flow4R predicts four things for every pixel:
- Point position (P): where this pixel’s point is in 3D.
- Scene flow (F): how that 3D point moves to the next image.
- Pose weight (W): how trustworthy that pixel is for figuring out the camera’s motion (e.g., stable, textured areas are more helpful).
- Confidence (C): how sure the model is about its prediction.
These four properties are a “minimal set” because they’re enough to calculate everything needed for 3D reconstruction, camera motion, object motion, and even optical flow (2D pixel movement), without extra special modules.
Splitting motion into camera vs. object motion
Imagine you have the movement of each point. Flow4R uses the pose weight map to focus on reliable pixels and solve the best camera motion that explains most of the scene. Then:
- Rigid motion (camera motion): the part of movement caused by the camera moving.
- Non-rigid motion (object motion): the leftover movement caused by objects themselves moving.
This is like saying: “Which parts of the image can we trust to figure out the camera’s move?” and then “What’s the extra movement that must be the objects?”
The model architecture
Flow4R uses a Vision Transformer (a type of neural network) that looks at two images at the same time and learns to match and reason about them. The two processing paths (one for each image) share the same parameters, making the design clean and symmetric. There’s no separate “camera pose regressor” head, and no slow bundle adjustment step after: everything is done in one forward pass.
Training strategy
Because real scene flow labels (ground truth) are rare, Flow4R trains with a mix of signals:
- Depth (to supervise 3D point positions).
- Optical flow (2D movement in the image).
- Scene flow or 3D point tracks where available (movement in 3D).
- A clever, self-supervised trick to learn pose weights: it adjusts W so the camera motion solved from P and F matches the known camera motion when available.
It’s trained on datasets that include both static and dynamic scenes, synthetic and real, so it learns to handle many kinds of motion and geometry.
Handling video sequences
Flow4R processes videos by pairing later frames with a chosen “anchor” frame (e.g., the first frame), so everything stays in a consistent reference. It also aligns scale across pairs to keep 3D sizes consistent.
What did the researchers find?
- Flow4R achieves state-of-the-art or near state-of-the-art results on both 3D tracking and dynamic 3D reconstruction benchmarks.
- It performs very well across different datasets and motion types, often beating other methods that need extra modules or post-processing.
- Despite strong performance, Flow4R is relatively compact (fewer parameters than some baselines).
- An ablation study shows it works best when predicting the next-frame 3D positions directly (P to the next view/time), rather than predicting scene flow first and converting it. Predicting positions aligns better with how the final accuracy is measured.
Why this matters:
- It proves that making scene flow the central idea can simplify the pipeline and improve results.
- It shows you can predict camera motion without a special “pose head” by using learned pose weights and the flow.
Why is this important?
- Unifies tasks: Instead of building separate systems for 3D reconstruction and tracking, Flow4R does both with the same predictions.
- Flexibility: Because it predicts motion in camera space and learns which pixels to trust, it can adapt to different scenes, including tricky dynamic ones.
- Simplicity and speed: One forward pass, no heavy optimization afterwards, and fewer moving parts that can break.
- Practical impact: This helps robots, AR/VR, self-driving cars, and video editing tools better understand and interact with 3D scenes as they change over time.
What are the limitations and future directions?
- Scene flow labels are rare, so training relies on mixing different kinds of supervision; better data could help even more.
- The paper focuses on two images at a time; extending to many images together (multi-view) could further boost performance.
- Online tracking over long videos with tight memory and compute is still challenging and worth exploring.
In short
Flow4R shows that “everything flows” can be more than a saying—it can be a powerful way to understand the 3D world over time. By predicting a small set of per-pixel properties and centering on scene flow, it neatly ties together where things are and how they move, delivering strong results without complicated extra steps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what Flow4R leaves missing, uncertain, or unexplored, stated to guide concrete follow‑up research.
- Reliance on two-view inputs only:
- No empirical evidence that the formulation maintains consistency over long sequences without loop closure or global optimization; error accumulation and drift under anchored pairing are not quantified.
- How to extend the flow-centric formulation to true multi-view/streaming attention (VGGT-style) while retaining symmetry and efficiency remains untested.
- Metric scale and calibration:
- Reconstructions are scale-normalized (mean-norm normalization) and evaluations use global median scaling; handling of absolute metric scale in monocular settings without ground-truth intrinsics or depth is unresolved.
- The proposed focal length estimation assumes a single shared focal length () and known principal point ; robustness to unknown/unreliable intrinsics, anisotropic focal lengths, and lens distortion is not addressed.
- Camera model and real-world imaging:
- No treatment for radial/tangential distortion, rolling shutter, or non-pinhole cameras (e.g., fisheye/omnidirectional); impact on scene flow decomposition and pose recovery is unknown.
- Sensitivity to photometric changes, motion blur, exposure variations, and low-light imaging is not analyzed.
- Pose estimation via learned pose weights:
- The self-supervised pose weight map lacks quantitative validation (e.g., correlation with true static/background regions, depth/texture reliability).
- Failure modes when dynamic content dominates the image or when is mispredicted are not studied; no robust alternative (e.g., M-estimators/RANSAC) is explored for Eq. (2).
- Uncertainty from is not propagated into pose estimation; how to integrate calibrated confidence into remains open.
- Object motion modeling and decomposition:
- Decomposition into rigid (camera) and non-rigid (object) motion is per-pixel; there is no instance-level motion segmentation or grouping, and no object-level trajectory estimation.
- Handling multiple independently moving rigid bodies vs. deformable objects is not explicitly modeled; how to aggregate per-pixel flows into object-wise motions is left open.
- Sequence-level consistency and tracking:
- No explicit mechanism for loop closure, global trajectory consistency, or re-anchoring; robustness to long-term occlusions and re-appearance is not evaluated.
- Identity persistence for tracked 3D points across long sequences and through occlusions is not studied; no visibility modeling or occlusion-aware losses are described.
- Data supervision and scarcity:
- Authors note scene-flow supervision scarcity; the effectiveness of semi/self-supervised training (e.g., photometric consistency, cycle consistency, self-training on unlabeled videos) is not explored.
- Sensitivity to the composition of training datasets (synthetic vs. real; static vs. dynamic) and domain shift is not ablated.
- Confidence map usage:
- The confidence map is used only for training losses; how to calibrate and exploit it at inference (e.g., uncertainty-aware fusion, outlier rejection, quality control) is unspecified.
- Intrinsics and extrinsics availability during training:
- Several losses (e.g., rigid motion loss ) require ground-truth camera poses and intrinsics; training when such metadata is unavailable or noisy is not addressed.
- Robustness to wide baselines and texture-poor scenes:
- While is intended to down-weight unreliable pixels, quantitative robustness under very wide baselines, low-texture/reflective surfaces, and repetitive patterns is not reported.
- Scalability and efficiency:
- Inference/runtime and memory footprints are not reported; feasibility for online deployment or resource-constrained settings is acknowledged as open but not analyzed.
- Trade-offs between input resolution, accuracy, and throughput are not characterized.
- Failure analysis and error budgeting
Glossary
- Anchor view: A designated reference image used to normalize scale and anchor tracking across pairs. "we can align the scale of predictions using the anchor view."
- Anchored connections: A pairing strategy that links subsequent frames to an anchor frame for consistent tracking without post-optimization. "we adopt anchored connections following St4Track."
- Average Percentage of 3D Points within Delta (APD3D): A tracking accuracy metric measuring the percentage of 3D points within a distance threshold. "we adopt the Average Percentage of 3D Points within Delta (APD3D) metric for 3D point tracking evaluation."
- Back-projecting: Converting image depth and camera parameters into 3D points in camera coordinates. "With ground-truth point map $\bar{\mathbf{P}$ obtained by back-projecting the ground-truth depth map with camera intrinsics, we supervise the predicted point map in a confidence-weighted way:"
- Bundle adjustment: An iterative joint optimization of camera poses and 3D points using multi-view constraints. "without requiring explicit pose regressors or bundle adjustment."
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) used for projection and back-projection. "Given ground-truth camera intrinsics, the depth of an input view, and its relative pose to another view, we can compute a so-called rigid flow"
- Camera-space: A coordinate system defined by the camera’s viewpoint in which geometry and motion are represented. "camera-space scene flow as the central representation linking 3D structure, object motion, and camera motion."
- Canonical model: A fixed reference shape used to track non-rigid deformations of a dynamic object. "employs a canonical model to represent the dynamic object and tracks non-rigid deformations through a warp field."
- Cross-attention: An attention mechanism enabling feature interaction between different inputs (e.g., views). "a two-view transformer with cross-attention can effectively match two images and reconstruct a scene cohesively."
- DPT head: A specific decoder head architecture (Dense Prediction Transformer) for dense predictions. "In the second stage, we train the model with a DPT head for 100 epochs on images at resolution 512 with random aspect ratios."
- Ego-motion: The motion of the camera itself relative to the scene. "allowing for persistent tracking even through significant camera ego-motion or temporary occlusions."
- End-Point Error (EPE): A metric measuring the average Euclidean distance error between predicted and ground-truth vectors (e.g., flow). "using both APD3D and End-Point Error (EPE) metrics."
- Feedforward inference: Producing outputs in a single forward network pass without iterative optimization. "exhibiting high consistency via a single step of feedforward inference."
- Global attention: Attention across all input views to aggregate multi-view information consistently. "handling multiple views jointly through global attention across all input images."
- Optical center: The principal point of the camera used in projection models. "where $\hat{\mathbf{p}^i$ and are the image coordinates of pixel and optical center;"
- Optical flow: The 2D motion field of pixels between images, often used for correspondence supervision. "When ground-truth optical flow or 2D point tracking are available, we apply the 2D motion loss to "
- Pixel-aligned pointmaps: Dense 3D point representations aligned per pixel across images. "It directly regresses pixel-aligned pointmaps for two input views in a shared coordinate frame,"
- Pose graph: A graph structure connecting frames via relative poses for global consistency. "constructs pairs within local windows and uses post-optimization to arrange pairs in a pose graph."
- Pose head: A dedicated network output branch that directly predicts camera pose parameters. "without explicit pose heads or bundle adjustment."
- Pose regressor: A network component trained to predict camera pose from images. "without requiring explicit pose regressors or bundle adjustment."
- Pose weight map: A per-pixel weighting indicating reliable regions for estimating camera pose. "using a pose weight map that describes the spatial distribution of reliable static pixels."
- Rigid flow: The motion field induced purely by camera movement assuming a static scene. "we can compute a so-called rigid flow to directly supervise the predicted scene flow, since they coincide for static scenes."
- Rigid transformation: A 3D transformation consisting of rotation and translation (no scaling or deformation). "we can estimate a rigid transformation from the predicted scene flow, using a pose weight map"
- RGB-D: Data modality combining color (RGB) with depth information. "However, it relies on RGB-D input and is highly sensitive to initialization."
- Scene flow: The 3D motion field of points between views/timestamps, encompassing camera and object motion. "scene flow as the central representation linking 3D structure, object motion, and camera motion."
- Self-attention: An attention mechanism relating elements within the same input (e.g., pixels across an image). "Recent advances in 3D reconstruction have seen the emergence of multi-view, self-attention-based transformers."
- SE(3): The Lie group of 3D rigid body motions (rotation and translation). "\hat{\mathrm{T} = \arg\min_{\mathrm{T} \in SE(3)} \sum{HW}_{i=1} \mathbf{W}i | \mathbf{P}i_{vt} - \mathrm{T} \mathbf{P}i |_2 ."
- Stop-gradient: A training operation that prevents gradients from flowing through a tensor. "sg(\cdot) stops gradient backpropagation so that is not optimized by this term."
- Structure-from-Motion (SfM): A pipeline reconstructing 3D structure and camera poses from images. "Classical Structure-from-Motion methods~\cite{schonberger2016colmap, moulon2016openmvg,sweeney2015theia,pan2024glomap} typically rely on a modular three-stage pipeline,"
- Two-view transformer: A transformer architecture operating on pairs of images to infer geometry and motion. "a two-view transformer framework that formulates 4D perception entirely in terms of scene flow."
- Vision Transformer: A transformer architecture adapted for image inputs and vision tasks. "Flow4R predicts a minimal per-pixel property set---3D point position, scene flow, pose weight, and confidence---from two-view inputs using a Vision Transformer."
- Warp field: A deformation field describing non-rigid motion of a dynamic object. "tracks non-rigid deformations through a warp field."
- Weighted least-squares: A least-squares optimization where each data point contributes with a weight. "we can decompose the camera movement by solving the weighted least-squares equation:"
- World coordinates: A global coordinate system used for evaluation and alignment across frames/datasets. "we follow St4RTrack~\cite{st4rtrack2025} to conduct evaluation in world coordinates using the WorldTrack~\cite{st4rtrack2025} benchmark."
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now (often offline or near–real-time on GPUs), along with relevant sectors, potential tools/workflows, and feasibility notes.
- Software/Dev Tools: Flow-centric 4D reconstruction and tracking SDK
- Sectors: Software, Robotics, VFX, AR/VR
- What: A developer library wrapping Flow4R’s per-pixel outputs (point map P, scene flow F, pose weight W, confidence C) into APIs for “4D from two views” (camera/object motion, depth, optical flow, focal length).
- Tools/workflows: ROS2 node for robots; Python/C++ API; Unity/Unreal plugins; export to USD/glTF/Nerfstudio formats; Blender/Nuke tracking plugin for postproduction.
- Assumptions/dependencies: Two synchronized views or frame pairs; known intrinsics (or focal length solved as in paper; assumes known optical center and equal axes); GPU needed for performance; scale remains up-to-an-unknown factor unless external cues provided.
- Postproduction & VFX: Fast shot solving and markerless motion tracking from pairwise frames
- Sectors: Media/Entertainment
- What: Replace/augment camera solvers and marker-based mocap with flow-centric tracking; robust to dynamic actors without masking (W down-weights moving regions).
- Workflows: Anchor-frame pipeline (pair other frames to an anchor, anchor-based scale alignment), export world-space tracks for CG integration, motion-aware stabilization.
- Assumptions/dependencies: Offline or near–real-time inference; pair selection strategy; generalization to studio lighting; no regulatory barriers.
- AR/VR Prototyping: Dynamic occlusion and stable anchoring without explicit pose regressors
- Sectors: AR/VR, Mobile
- What: Compute 3D geometry and motion from two frames to drive occlusion, world locking, and spatial anchors in scenes with people/objects moving.
- Tools/workflows: Plug-in to AR engines (Unity/Unreal, AR Foundation) for “dynamic occlusion from two frames”; anchor-to-frame update via pose decomposition; confidence-weighted fusion.
- Assumptions/dependencies: Tethered GPU or edge GPU advisable; two-view pairing; device intrinsics; latency may limit live consumer deployments now.
- Robotics R&D: Dynamic-SLAM front-end without bundle adjustment
- Sectors: Robotics, Drones, Mobile Manipulation
- What: Use predicted P/F/W to derive camera pose and separate rigid vs. non-rigid motion for navigation/planning in dynamic environments.
- Tools/workflows: Replace/augment classical VO front-end; integrate with existing back-ends (factor graphs) for loop closure; anchored sequence processing for longer runs; dynamic obstacle detection via F_t.
- Assumptions/dependencies: Real-time constraints; robustness in low-texture/reflective scenes aided by W/C; absolute scale still ambiguous without extra sensors (IMU/barometer/wheel odometry/LiDAR).
- AEC/Mapping & Digital Twins: “Scan-while-occupied” capture
- Sectors: Construction, Facility Management, Smart Buildings
- What: Fast 3D reconstruction of spaces even with moving workers/visitors; down-weighting dynamics via W and explicit non-rigid motion decomposition.
- Tools/workflows: Handheld camera scans; anchor-based sequential processing; export to BIM/IFC; change detection for moving objects.
- Assumptions/dependencies: Mostly offline processing; limited absolute scale unless fused with known distances; coverage gaps if frames lack overlap.
- Sports & Biomechanics: World-coordinate 3D point tracking from broadcast/handheld footage
- Sectors: Sports Analytics, Health & Fitness
- What: Track ball/athlete objects and camera motion jointly from two frames; produce world-aligned trajectories (APD-validated).
- Tools/workflows: Ingest pairs from broadcast feeds; anchor-based batch processing; provide 3D tracks for coaching and analytics.
- Assumptions/dependencies: Camera intrinsics may need estimation (focal length solver); camera rolling shutter not modeled; scale requires field measurements.
- UAV/Inspection & Asset Monitoring: Rapid 4D analysis post-flight
- Sectors: Energy, Infrastructure, Utilities
- What: Reconstruct structures and record dynamic elements (e.g., rotating blades, moving vehicles) from pairs; distinguish camera vs. object motion.
- Tools/workflows: Post-flight batch processing; detect non-rigid motion anomalies; report 3D tracks and change maps.
- Assumptions/dependencies: Lighting/reflective surfaces may reduce confidence; requires overlap; absolute scale via GPS/altimeter recommended.
- Surveillance & Safety Analytics (privacy-aware prototypes)
- Sectors: Security, Occupational Safety
- What: World-coordinate tracking of people/vehicles while maintaining explainability via W and C (which pixels contributed to localization).
- Tools/workflows: Fixed camera pairs; anchored sequences; geofencing and near-miss reconstructions; privacy by on-premise processing and track aggregation.
- Assumptions/dependencies: Regulatory compliance (GDPR/CCPA); camera calibration; ethics review for deployments.
- Education/Academia: Dataset bootstrapping and research tooling
- Sectors: Education, Academia
- What: Generate pseudo-labels for depth/flow/pose weights; teach unified 4D geometry via a compact model; benchmark dynamic SLAM variants.
- Tools/workflows: Synthetic-to-real curriculum; ablation-friendly APIs to switch supervision (3D/2D motion, rigid) and to visualize P/F/W/C.
- Assumptions/dependencies: Compute availability; dataset licenses; reproducibility.
- Camera Calibration Aid for In-the-Wild Footage
- Sectors: Media, Forensics, Research
- What: Estimate focal length from predicted P and image coordinates as described; useful for archival or crowd-sourced video where intrinsics are unknown.
- Tools/workflows: Batch solver integrated into ingest pipeline; flag frames with ill-conditioned solutions via C (confidence).
- Assumptions/dependencies: Assumes known optical center and square pixels; estimates are up-to-scale; degenerate scenes (planar) can be ill-posed.
Long-Term Applications
These use cases require further research, scaling, optimization, or regulatory clearance before broad deployment.
- Real-Time On-Device 4D Perception for AR Glasses and Phones
- Sectors: AR/VR, Mobile Hardware
- What: Millisecond-latency scene reconstruction and tracking on-device powered by optimized transformers or dedicated accelerators.
- Dependencies: Model compression/distillation; hardware acceleration; power/thermal budgets; robust handling of rolling shutter and motion blur.
- Autonomous Driving Front-Ends with Unified Geometry/Motion
- Sectors: Automotive
- What: Replace separate depth, optical flow, and ego-motion stacks with a flow-centric front-end; robust to dynamic actors without explicit masking.
- Dependencies: Multi-camera integration; safety certification; extreme corner-case robustness; fusion with LiDAR/IMU and map priors; explainability tooling.
- Markerless Clinical Tracking and 3D Endoscopy
- Sectors: Healthcare
- What: 4D tracking of surgical tools/anatomy from stereo/monocular endoscopes for guidance and AR overlays.
- Dependencies: Sterile real-time systems; regulatory approvals; tissue deformation modeling; domain adaptation to challenging illumination/specularities.
- Factory Cobots and Human-Robot Collaboration in Dynamic Spaces
- Sectors: Industrial Automation
- What: Safety-aware perception that separates camera/object motion in crowded factory floors to improve path planning and human intention prediction.
- Dependencies: Real-time latency guarantees; ISO safety standards; robust tracking through occlusions; multi-sensor fusion.
- City-Scale Dynamic Digital Twins and Traffic Management
- Sectors: Smart Cities, Transportation
- What: Continuous 4D updates of infrastructure and traffic with flow-centric processing from camera grids.
- Dependencies: Scalable multi-view streaming (VGGT-style extensions); privacy-preserving aggregation; edge-cloud orchestration; cross-camera calibration.
- Insurance, Forensics, and Accident Reconstruction from Consumer Video
- Sectors: Finance/Insurance, Public Safety
- What: Automatically reconstruct incident scenes and trajectories from few frames to aid claims and investigations.
- Dependencies: Legal admissibility; bias/fairness audits; handling unknown intrinsics and scale; uncertainty quantification using C.
- Dynamic NeRF/GS Integration for Editable 4D Content
- Sectors: Graphics, Gaming, Digital Content
- What: Use P/F/W as priors to guide dynamic neural radiance fields or Gaussian splatting, enabling editable, relightable 4D assets.
- Dependencies: Differentiable coupling of flow and radiance fields; consistent long-horizon tracking; memory-efficient training.
- Consumer 3D Video and “Motion Portraits”
- Sectors: Consumer Apps, Social Media
- What: Create 3D-aware effects and dynamic depth videos from short clips, with accurate occlusion and motion decomposition.
- Dependencies: Mobile inference optimization; UX for pair selection or auto-pairing; battery life constraints.
- Domain-Specific 4D Tools for Agriculture and Wildlife
- Sectors: Agriculture, Environmental Monitoring
- What: Track plant growth or animal motion with minimal camera setups, separating camera drift from subject motion.
- Dependencies: Robustness to outdoor conditions (wind, lighting); long-range occlusions; power-constrained edge devices.
- Standards and Policy Frameworks for 4D Tracking and Scene Flow
- Sectors: Policy, Standards Bodies
- What: Define metrics, benchmark protocols, and privacy guidelines for scene-flow-based tracking and reconstruction.
- Dependencies: Cross-industry consortiums; dataset governance; standardized uncertainty reporting (using C) and interpretability (W maps).
- Hardware Acceleration and Co-Design
- Sectors: Semiconductors, Edge AI
- What: ASICs/NPUs optimized for two-view transformer inference and flow decomposition (SE(3) solvers, projection units).
- Dependencies: Stable model architectures; software–hardware APIs; market demand across AR/robotics.
Cross-Cutting Assumptions and Dependencies
- Two-view inputs are central; longer sequences require anchored-pair workflows or multi-view extensions.
- Camera intrinsics: focal length can be estimated as in the paper, but assumes known optical center and square pixels; degenerate geometries affect calibration.
- Scale ambiguity persists without external cues (IMU, LiDAR, known baselines); absolute-scale use cases must integrate additional sensors.
- Generalization depends on training data domain; reflective/textureless/low-light scenes may rely on confidence down-weighting but still degrade performance.
- Compute constraints: current models (hundreds of millions of parameters) may need compression for edge/real-time deployment.
- Legal/ethical considerations for tracking (privacy laws, consent, bias audits) apply to surveillance, automotive, healthcare, and insurance scenarios.
Collections
Sign up for free to add this paper to one or more collections.