MotionCrafter: Dense Geometry and Motion Reconstruction with a 4D VAE
Abstract: We introduce MotionCrafter, a video diffusion-based framework that jointly reconstructs 4D geometry and estimates dense motion from a monocular video. The core of our method is a novel joint representation of dense 3D point maps and 3D scene flows in a shared coordinate system, and a novel 4D VAE to effectively learn this representation. Unlike prior work that forces the 3D value and latents to align strictly with RGB VAE latents-despite their fundamentally different distributions-we show that such alignment is unnecessary and leads to suboptimal performance. Instead, we introduce a new data normalization and VAE training strategy that better transfers diffusion priors and greatly improves reconstruction quality. Extensive experiments across multiple datasets demonstrate that MotionCrafter achieves state-of-the-art performance in both geometry reconstruction and dense scene flow estimation, delivering 38.64% and 25.0% improvements in geometry and motion reconstruction, respectively, all without any post-optimization. Project page: https://ruijiezhu94.github.io/MotionCrafter_Page



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces MotionCrafter, a computer program that looks at a regular video from a single camera and figures out two things at the same time:
- what the 3D shape of the scene is (like a 3D map of everything you see), and
- how every point in that scene moves over time (like tiny arrows showing motion in 3D).
They call this “4D” because it’s 3D space plus time. MotionCrafter does this quickly in one pass and doesn’t need extra fine-tuning after it runs.
Goals: What questions did the researchers ask?
The researchers wanted to:
- Rebuild a detailed 3D map for every frame in a video using only one camera.
- Track how every visible point moves from one frame to the next in 3D.
- Do both tasks together, in a consistent way, so the model understands the whole scene over time.
- Use a strong “video brain” (a pre-trained video diffusion model) to help, without forcing the 3D data to behave exactly like normal images inside that model.
Methods: How did they do it?
They combined a few ideas into one system you can think of as “pins and arrows on a shared world map”:
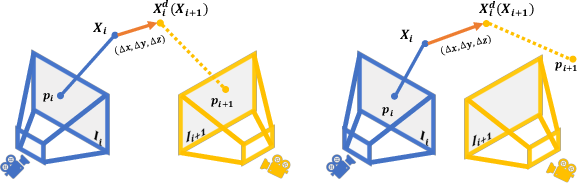
- World coordinate system: Instead of measuring things from the camera’s point of view (which moves), they fix a “world” point of view. In this fixed world:
- A “point map” is a 3D location for each pixel in the image, like placing a pin where that pixel’s 3D point is.
- “Scene flow” is a 3D motion vector for each pixel, like an arrow showing how that 3D point moves to the next frame.
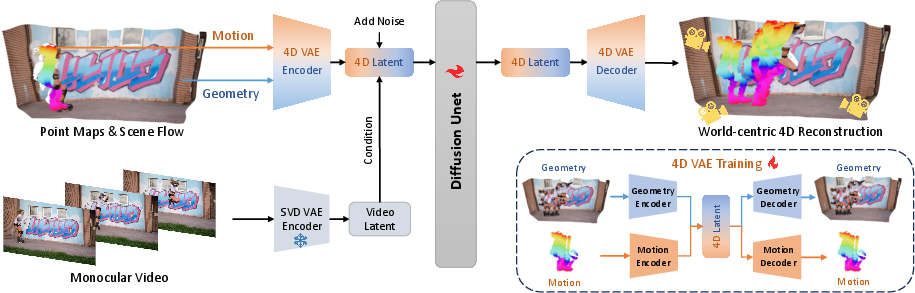
- 4D VAE (a smart compressor): A VAE (Variational Autoencoder) is like a zip tool for data—it compresses information into a small code and then can rebuild it. MotionCrafter has:
- A Geometry VAE to compress and reconstruct the 3D point maps.
- A Motion VAE to compress and reconstruct the 3D motion arrows (scene flow).
- Together, they make a single “4D latent” code that represents both shape and motion.
- Video diffusion model (a smart cleaner): A diffusion model learns to turn noisy data into clean data step by step. MotionCrafter plugs its 4D latent code into a pre-trained video diffusion model (Stable Video Diffusion, or SVD) so it can use what the video model already knows about how scenes look and move over time.
- A key twist: Instead of forcing the 3D data to be scaled like normal RGB images inside the video model (which many other papers do), they “normalize” the 3D points in a more natural way: center everything and scale by the scene’s average size. This respects how 3D data actually behaves and, surprisingly, works better.
- Training approach:
- First, train the Geometry VAE to get good at shapes.
- Then, with the geometry frozen, train the Motion VAE to learn motion arrows using the geometry code.
- Finally, use the video diffusion model to polish and predict the 4D latent across whole videos. They trained mostly on synthetic datasets (computer-made scenes) because those have perfect 3D and motion labels.
Results: What did they find and why does it matter?
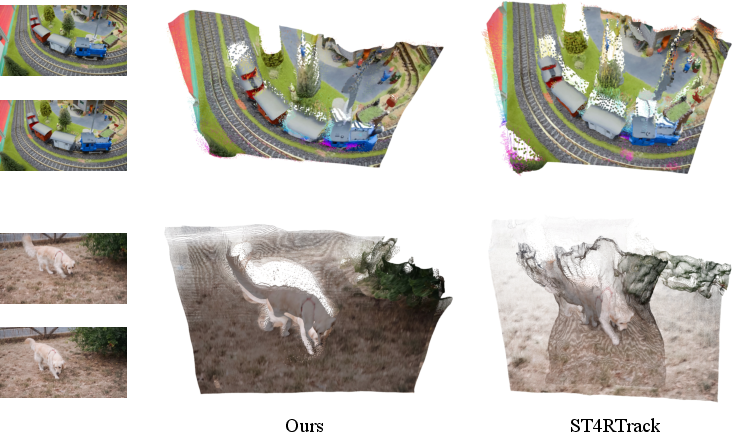
- Better accuracy without extra tuning: MotionCrafter beat previous methods on both 3D shape and 3D motion, even though it doesn’t do any post-optimization after running.
- Geometry (shape) improved by about 38.6% on average.
- Motion (scene flow) improved by about 25.0% on average.
- More stable over long videos: Because it models the whole video in the same “world” view, background points stay stable (no camera-induced fake motion), and moving objects have clearer, more consistent motion.
- Big takeaway: You don’t need to force 3D data to match image-like distributions inside a video diffusion model. Using a sensible 3D normalization (center and scale) and retraining the VAE works better. This challenges a common belief and opens the door for better 3D/4D learning with diffusion models.
Impact: Why is this useful?
- Practical uses: Robots, augmented reality (AR), virtual reality (VR), and video understanding all need to know where things are and how they move. MotionCrafter can provide both quickly from a single camera.
- Stronger world models: It helps build computer systems that understand and predict real-world scenes over time.
- Research direction: It suggests new ways to use powerful video diffusion models for geometry and motion, without bending 3D data to look like images. Future work could add more types of information (like camera settings, depth maps, or point tracks) to make the system even more versatile.
In short, MotionCrafter is like giving a computer the ability to build a detailed 3D map and draw motion arrows for every point in a video, all in a smart, consistent “world view,” and it does this faster and more accurately than earlier methods.
Knowledge Gaps
Identified Knowledge Gaps, Limitations, and Open Questions
Here are the key knowledge gaps, limitations, and open questions from the "MotionCrafter" paper that future researchers might consider exploring:
- Dataset Diversity: The study mainly relies on synthetic datasets for training data, particularly for motion tasks. Are there opportunities to test this framework on more diverse real-world datasets or improve dataset collection methods?
- Multi-modal Integration: The current focus is on dense geometry and motion reconstruction. How might the model be improved by integrating other geometric modalities such as camera parameters, depth maps, or novel views?
- Evaluation Metrics: Present assessments focus on geometry and motion metrics in the world coordinate system. Are there more comprehensive metrics that could be developed to assess the quality and real-world applicability of the reconstructions?
- Scalability and Real-world Application: Despite state-of-the-art performance, how well does the framework scale to very large real-world datasets, and what changes might be needed to do so effectively?
- Optimization and Efficiency: The lack of a need for post-optimization is a claimed benefit. However, could there be scenarios where post-optimization or hybrid models improve efficiency or quality?
- Scene Complexity: The complexity and scenarios simulated with current datasets may not fully replicate all real-world challenges. How might the approach handle scenarios with extreme occlusions or rapid dynamic changes?
- Motion Patterns: Is the model's ability to learn motion patterns in dynamic environments universally applicable across different types of dynamic scenes?
Future research could expand on these unresolved areas to further develop the framework and explore its boundaries in dynamic scene recreation and analysis.
Glossary
- 3D Gaussian Splatting (3D-GS): A fast 3D representation and rendering approach that uses Gaussian primitives and rasterization instead of expensive ray sampling. "3D Gaussian Splatting (3D-GS)~\cite{kerbl20233d} avoids expensive sampling using a rasterization-based rendering pipeline."
- 4D VAE: A variational autoencoder tailored to jointly encode 3D geometry over time (4D) into a latent representation for diffusion-based prediction. "and a novel 4D VAE to effectively learn this representation."
- APD (Average Percent of Points within Delta): A metric that measures the fraction of points whose errors fall within a specified threshold. "Average Percent of Points within Delta (APD), where the subscript of APD denotes the inlier threshold in the metric scale."
- as-static-as-possible assumption: A regularization prior that encourages non-moving scene regions to have near-zero estimated motion. "following the as-static-as-possible assumption."
- canonical normalization: A normalization scheme that centers 3D coordinates by their mean and scales by mean distance to achieve scale invariance. "we instead apply canonical normalization to each sequence of world-coordinate point maps:"
- cost volumes: 3D tensors of matching costs used in correspondence estimation across disparities or motion. "Without the need to build cost volumes~\cite{teed2021raft} or establish dense correspondence~\cite{sucar2025dynamic} in pixel space"
- denoising diffusion: A generative modeling paradigm that iteratively removes noise to recover data samples. "supports both the deterministic and denoising diffusion paradigms."
- Diffusion Unet: The U-Net architecture inside a diffusion model responsible for predicting denoised latents. "Within the Diffusion Unet, we leverage the pretrained VAE from SVD (Stable Video Diffusion) to encode video latents as conditional inputs"
- EDM pre-conditioning: A training strategy from Elucidated Diffusion Models that conditions noise and targets for improved diffusion training. "in employing EDM~\cite{karras2022elucidating} pre-conditioning, our framework supports both the deterministic and denoising diffusion paradigms."
- End Point Error (EPE): The Euclidean distance between predicted and ground-truth motion vectors, used to evaluate flow accuracy. "We compute the End Point Error (EPE) and the Average Percent of Points within Delta (APD)"
- feed-forward manner: Performing inference in a single pass without iterative per-scene optimization. "in a feed-forward manner, without any post-optimization."
- KullbackâLeibler (KL) divergence: An information-theoretic measure used in VAEs to regularize latent distributions toward a prior. "Here we also tried using KullbackâLeibler (KL) divergence loss~\cite{kullback1951information} to constrain the distribution of the latent to a standard Gaussian distribution, but found that it led to a significant drop in VAE performance."
- latent space: A compact, learned representation space where geometry and motion are encoded for generation or prediction. "encode the above 4D representation into a latent space effectively"
- max normalization: Rescaling data to a fixed range (e.g., [-1, 1]) based on maximum absolute values. "unlike the max normalization to commonly used in existing geometric diffusion models"
- monocular video: A video captured from a single camera viewpoint, lacking stereo or multi-view depth cues. "Given a monocular video as input"
- multi-view geometry: The geometric principles and constraints arising from multiple views of a scene used for reconstruction and correspondence. "both relying on pixel correspondence in multi-view geometry~\cite{hartley2003multiple}"
- Neural Radiance Fields (NeRFs): Neural volumetric models that represent scenes with view-dependent radiance for photorealistic rendering. "With the development of neural radiance fields (NeRFs)~\cite{mildenhall2020nerf}"
- optical flow: The dense 2D motion field of pixel displacements between consecutive frames. "Early works define point correspondences as optical flow estimation in pixel space"
- permutation-equivariant architecture: A model design whose outputs transform consistently with permutations of the input sequence. "builds a permutation-equivariant architecture on top of VGGT~\cite{wang2025vggt} for static and dynamic 3D reconstruction."
- point map: An image-aligned map where each pixel stores a 3D point in a chosen coordinate system. "simultaneously predicts dense point map and scene flow"
- post-optimization: Iterative, per-scene refinement steps applied after initial predictions to improve quality. "without requiring any post-optimization."
- rasterization-based rendering pipeline: A rendering approach that converts geometry to screen-space fragments without volumetric sampling. "3D Gaussian Splatting (3D-GS)~\cite{kerbl20233d} avoids expensive sampling using a rasterization-based rendering pipeline."
- score distillation sampling (SDS): A technique that distills gradients from a diffusion model’s score to optimize scene or object representations. "Inspired by score distillation sampling (SDS)~\cite{pooledreamfusion}"
- spatiotemporal consistency: Coherence of predictions across space and time, crucial for stable video-based reconstructions. "the video generator inherently models spatiotemporal consistency across multiple frames"
- Stable Video Diffusion (SVD): A pre-trained video diffusion model used to provide strong visual-temporal priors. "we leverage the pretrained VAE from SVD (Stable Video Diffusion) to encode video latents as conditional inputs"
- time-dependent NeRFs: Extensions of NeRFs that model dynamic scenes by incorporating temporal variation. "many time-dependent NeRFs~\cite{park2021nerfies,du2021neural,li2021neural,pumarola2021d,fridovich2023k,cao2023hexplane,li2023dynibar} fit deformable 3D representations to dynamic scenes."
- VAE (Variational Autoencoder): A probabilistic autoencoder that learns a latent distribution for efficient encoding/decoding of data. "we first train a novel 4D VAE (bottom-right), consisting of a Geometry VAE and a Motion VAE."
- volumetric rendering: Rendering by integrating radiance and density along rays through a volume, often computationally expensive. "However, these approaches suffer from the expensive volumetric rendering, making them less practical for real-world applications."
- world coordinate system: A global reference frame in which all frames’ geometry and motion are represented consistently. "both are defined in the world coordinate system."
- world-centric 4D representation: A representation that encodes geometry and motion in a shared global frame rather than per-camera coordinates. "We achieve this by proposing a world-centric 4D representation"
- zero-shot testing: Evaluating a model on datasets it was not trained on, without task-specific fine-tuning. "we perform zero-shot testing on three unseen dynamic scene datasets"
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging MotionCrafter’s feed-forward, world-centric 4D geometry and dense motion reconstruction from monocular videos. Each item includes sectors, potential tools/workflows, and key assumptions or dependencies.
- Monocular video-to-4D for post-production and VFX (Media/Entertainment)
- Tools/Workflows: Blender/Nuke/After Effects plug‑in to turn a single camera take into volumetric point maps and motion (scene flow) for motion-aware compositing, relighting, clean plate creation, object removal/insertion.
- Assumptions/Dependencies: GPU acceleration for offline processing; non-metric scale unless calibrated; challenging materials (specular/translucent) and heavy motion blur may require manual cleanup.
- AR occlusion and physics from a single camera feed (Software/AR-VR)
- Tools/Workflows: SDKs or Unity/Unreal plug‑ins to feed world-centric point maps and scene flow into ARKit/ARCore-based apps for correct occlusion, collision detection, and simple physical interactions.
- Assumptions/Dependencies: Requires integration with mobile pipelines; absolute scale must be inferred (e.g., via known object size or device AR sensors); consistent lighting and moderate motion improve robustness.
- Robotics perception module for occlusion‑aware navigation (Robotics)
- Tools/Workflows: ROS/Isaac nodes that consume monocular camera streams and output 4D point maps plus scene flow to improve obstacle tracking, path planning, and dynamic object avoidance (e.g., warehouse robots, indoor drones).
- Assumptions/Dependencies: Edge compute constraints; real‑time performance may require model distillation/quantization; world coordinate anchored to first frame (no absolute metric without calibration).
- Autonomous driving research and dataset labeling (Transportation/AI)
- Tools/Workflows: Offline pipeline to convert dashcam videos into dense 4D labels (point maps + scene flow) for training perception models or evaluating multi‑object tracking; synthetic-to-real augmentation.
- Assumptions/Dependencies: Generalization from synthetic training data; broadcast lens distortion and rolling shutter need pre-processing; external cues for metric scale (e.g., road lane width).
- Sports analytics from broadcast footage (Media/Sports)
- Tools/Workflows: 4D reconstruction of player and ball trajectories for coaching, highlights, and strategy visualization; integration with telestration tools.
- Assumptions/Dependencies: Moving cameras require stabilization; occlusions/multi-person tracking can benefit from combining with trackers; field scale inferred from known geometry.
- Industrial inspection and asset measurement with drones/handheld cameras (Manufacturing/Energy)
- Tools/Workflows: Convert inspection video to 3D surfaces and track motion (vibration, deflection) for anomaly detection; CAD/BIM overlay for context.
- Assumptions/Dependencies: Textureless or reflective surfaces may degrade geometry; metric calibration is needed for measurements; controlled capture helps accuracy.
- Video stabilization and motion‑aware filtering (Software)
- Tools/Workflows: Use scene flow to separate camera vs. object motion, improving stabilization, deblurring, or background subtraction.
- Assumptions/Dependencies: Integration into existing video processing pipelines; performance depends on motion magnitude and occlusion handling.
- Education and interactive demos of 3D motion (Education)
- Tools/Workflows: Classroom tools to visualize 3D motion vectors and geometry from lab videos (e.g., physics experiments), including overlays of scene flow and point maps.
- Assumptions/Dependencies: Requires desktop GPU; no metric scale unless calibrated; curated examples recommended.
- Data tooling for ML: automatic 4D labels (Software/AI)
- Tools/Workflows: Batch processing service (cloud/on‑prem) to produce dense geometry and scene flow from raw videos; dataset curation UI for quality control.
- Assumptions/Dependencies: Storage throughput; annotation QA; interoperability with existing ML data formats (e.g., KITTI-like formats).
- Safety analytics in facilities (Security/Industrial Safety)
- Tools/Workflows: 3D tracking of people/objects from monocular CCTV for hazard detection (forklifts, spills, unsecured loads); map dynamic zones of risk via scene flow.
- Assumptions/Dependencies: Privacy compliance and governance; camera placement and lighting; non-metric scale unless calibrated; multi-camera fusion could improve robustness.
Long-Term Applications
These use cases require further research, scaling, or engineering to meet performance, robustness, or regulatory needs.
- Real-time 4D perception on edge devices (Robotics/Autonomous Vehicles)
- Products/Workflows: Embedded 4D perception stack replacing or complementing LiDAR for occlusion-aware planning and dynamic object tracking.
- Assumptions/Dependencies: Hardware acceleration (GPU/DSP/NPU), model compression, strict latency budgets, domain robustness (weather/night), metric scale estimation.
- Consumer-grade volumetric telepresence from a single webcam (AR/VR/Communications)
- Products/Workflows: Live holoportation pipeline producing world-centric geometry and motion for avatars in VR/AR with occlusion awareness and realistic dynamics.
- Assumptions/Dependencies: Low-latency encoding/streaming; compression of 4D data; multi-view synthesis from monocular inputs; privacy controls.
- Continuous digital twins of dynamic facilities (Energy/Smart Buildings/Manufacturing)
- Products/Workflows: Persistent, automatically updated 4D twins from monocular camera networks capturing surface deformation, moving machinery, and human flow.
- Assumptions/Dependencies: Long-term reliability, camera network management, integration with CAD/BIM/IoT, metric calibration, change detection at scale.
- World models for decision-making agents (AI/RL)
- Products/Workflows: Use unified 4D latents (geometry + motion) as structured inputs to train planning agents; improved long-horizon prediction and interaction modeling.
- Assumptions/Dependencies: Data pipelines, sim-to-real transfer, interpretability and safety validation; standardized 4D benchmarks.
- Clinical motion analysis without markers (Healthcare)
- Products/Workflows: Gait, rehab, respiratory/chest motion monitoring using monocular cameras in clinics or at home; early detection of musculoskeletal issues via scene flow patterns.
- Assumptions/Dependencies: Clinical validation and regulatory approval; metric calibration for measurement; handling of occlusions/clothing; fairness and bias assessment.
- Insurance and forensic accident reconstruction (Finance/Legal)
- Products/Workflows: Turn dashcam/phone video into 4D reconstructions of collisions, measuring trajectories and impact dynamics to support claims and investigations.
- Assumptions/Dependencies: Evidentiary standards, admissibility, metric calibration, handling extreme motion/blur; chain-of-custody and data integrity.
- City-scale traffic and crowd dynamics for policy (Public Policy/Urban Planning)
- Products/Workflows: Aggregate 4D reconstructions from camera networks to analyze flows, near-misses, and safety interventions.
- Assumptions/Dependencies: Privacy-preserving pipelines; governance frameworks; scalable storage/compute; heterogeneous camera hardware standardization.
- Live volumetric experiences and interactive stages (Media/Entertainment)
- Products/Workflows: Real-time shows/games with volumetric characters/environments driven by monocular inputs; dynamic occlusion and physics.
- Assumptions/Dependencies: Low-latency inference; artistic tool integration; high-quality temporal consistency under fast motions.
- Manipulation and dynamics-aware planning (Robotics)
- Products/Workflows: Use scene flow to estimate object dynamics (slip, deformation) and improve grasping, pushing, and assembly strategies.
- Assumptions/Dependencies: Domain-specific finetuning on manipulation datasets; integration with tactile feedback; robustness to clutter and occlusion.
- Environmental monitoring from remote cameras (Climate/Environment)
- Products/Workflows: 4D tracking of glacier movement, river surface flow, landslides; early warning systems leveraging dense scene flow.
- Assumptions/Dependencies: Long-term deployments with variable lighting/weather; metric calibration; ruggedized systems; model robustness to natural textures.
- Standards and governance for 4D world‑centric reconstruction (Policy/Standards)
- Products/Workflows: Benchmark suites and best practices for dense geometry + motion estimation; privacy and ethics guidelines for video-based 4D analytics.
- Assumptions/Dependencies: Cross-sector collaboration; public datasets with annotations; evaluation protocols for world-space metrics and scale alignment.
Cross-cutting assumptions and dependencies
- Metric scale: MotionCrafter outputs world-centric geometry anchored to the first frame; absolute metric scale typically requires external cues (calibration, known object sizes, or sensor fusion).
- Domain shift: The core training relied heavily on synthetic datasets; robust generalization may require finetuning or domain adaptation for specific environments.
- Compute and latency: Immediate deployments are best suited to offline or near-real-time scenarios; edge real-time use cases require optimization and hardware acceleration.
- Privacy and compliance: Several applications involve people and public spaces; adherence to local laws, consent, and anonymization is essential.
- Integration: Tooling and productization require SDKs/APIs, plugins (ROS, Unity/Unreal, NLEs), and standard data formats for point maps and scene flow.
- Failure modes: Fast motion, heavy occlusion, reflective/translucent surfaces, and severe motion blur can degrade results; pipeline fallback strategies (e.g., multi-sensor fusion) improve robustness.
Collections
Sign up for free to add this paper to one or more collections.