Human3R: Everyone Everywhere All at Once
Abstract: We present Human3R, a unified, feed-forward framework for online 4D human-scene reconstruction, in the world frame, from casually captured monocular videos. Unlike previous approaches that rely on multi-stage pipelines, iterative contact-aware refinement between humans and scenes, and heavy dependencies, e.g., human detection, depth estimation, and SLAM pre-processing, Human3R jointly recovers global multi-person SMPL-X bodies ("everyone"), dense 3D scene ("everywhere"), and camera trajectories in a single forward pass ("all-at-once"). Our method builds upon the 4D online reconstruction model CUT3R, and uses parameter-efficient visual prompt tuning, to strive to preserve CUT3R's rich spatiotemporal priors, while enabling direct readout of multiple SMPL-X bodies. Human3R is a unified model that eliminates heavy dependencies and iterative refinement. After being trained on the relatively small-scale synthetic dataset BEDLAM for just one day on one GPU, it achieves superior performance with remarkable efficiency: it reconstructs multiple humans in a one-shot manner, along with 3D scenes, in one stage, at real-time speed (15 FPS) with a low memory footprint (8 GB). Extensive experiments demonstrate that Human3R delivers state-of-the-art or competitive performance across tasks, including global human motion estimation, local human mesh recovery, video depth estimation, and camera pose estimation, with a single unified model. We hope that Human3R will serve as a simple yet strong baseline, be easily extended for downstream applications.Code available in https://fanegg.github.io/Human3R




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Human3R, a fast, all-in-one system that watches a normal video (from a single camera) and, in real time, builds a 4D picture of what’s happening. 4D here means 3D space plus time. With each new frame, Human3R:
- Reconstructs the 3D shape and motion of all people in the scene
- Rebuilds the 3D geometry of the surroundings (the room, furniture, etc.)
- Estimates where the camera is and how it’s moving
It does all of this at once, without needing lots of separate tools or slow, multi-step processing.
What questions does the paper ask?
The paper aims to answer:
- Can we build a single, simple model that reconstructs people, the scene, and the camera together, frame by frame, in real time?
- Can this work from just a regular video (one camera), without extra information like precomputed depth or pre-run tracking?
- Can we train it quickly and efficiently, and still get top performance?
How does it work? (Methods, explained simply)
Think of Human3R like a smart “video-to-3D” engine with memory:
- It builds on a strong base model called CUT3R. CUT3R already knows how to turn video frames into 3D points (a “point cloud,” like a cloud of tiny dots in space) and track the camera’s motion. It does this online (as the video plays) and remembers what it has seen so far.
- Human3R adds “human awareness” to CUT3R using a light-touch technique called visual prompt tuning. Instead of retraining the whole big model, it attaches small “prompts” that help the model recognize and reconstruct humans.
- How does it find people? It looks for the head in the image (the head is a strong clue for where a person is). These “head tokens” act like anchors or starting points. From there, it reconstructs the full body.
- To get better details of human pose (how the body is bent or stretched) and shape, Human3R brings in extra human-specific features from another model (Multi-HMR). You can imagine this as combining a “world-aware model” (CUT3R) with a “human-expert model” (Multi-HMR) so you get the best of both.
- Under the hood, the model uses “tokens” (small chunks of image information) and “attention” (a way for the model to focus on the most relevant parts, like how you focus your eyes on what matters). The human prompts:
- Self-attend to the image tokens to gather full-body information
- Cross-attend to the model’s memory of the scene so the people are placed correctly in 3D
- Tracking and segmentation:
- Segmentation: it can mark which pixels belong to people.
- Tracking: it follows the same person across frames by matching their “human token” features, like matching fingerprints over time. A fair matching algorithm decides the best person-to-person connections between frames.
- Handling long videos:
- Models with memory can “forget” earlier frames in very long videos. Human3R uses a test-time adaptation trick (TTT3R) to update its memory on the fly and occasionally “reset” it, keeping performance strong over long sequences.
Key terms explained in everyday language
- 4D reconstruction: building a moving 3D scene over time (3D + time).
- Point cloud: a set of 3D dots that represent surfaces in the scene.
- SMPL-X: a detailed digital mannequin of a human body with joints and a shape that can bend and move realistically.
- World frame vs camera frame: world frame is a fixed global map; camera frame is what the camera sees relative to itself.
- Visual prompt tuning: teaching a big model a new skill by adding small hints, without changing most of the model.
- Tokens and attention: tokens are like small pieces of image info; attention helps the model focus on what matters.
What did they find, and why is it important?
- All-at-once reconstruction: Human3R successfully reconstructs multiple people, the full 3D scene, and the camera’s motion in a single forward pass (no multi-stage pipeline), online, in real time (around 15 frames per second), using only ~8 GB of GPU memory.
- Efficiency: It reaches strong performance after just one day of training on a single GPU, using a relatively small synthetic dataset (BEDLAM).
- Accuracy across tasks:
- Local human mesh recovery (per-frame body pose/shape): Human3R is competitive or better than strong one-stage baselines.
- Global human motion (world coordinates over time): It beats several online baselines on long, dynamic sequences, with lower errors in where people are and how they move.
- Camera pose estimation and video depth (generic 3D tasks): It slightly improves on strong 3D reconstruction baselines, showing that adding human reasoning also helps scene understanding.
- Fewer dependencies: Unlike many previous systems, Human3R doesn’t rely on separate tools like pre-run human detection, SLAM preprocessing, or external depth estimators. This makes it simpler, faster, and easier to deploy.
Why it matters: A unified, fast model makes it practical to use 4D human-scene understanding in everyday applications, without building and maintaining complicated pipelines.
What could this change? (Implications)
Human3R could help power:
- AR/VR: making more realistic and responsive experiences by understanding people and spaces in 3D instantly.
- Robotics and autonomous systems: letting robots or vehicles understand human motion and the environment to move safely and interact smoothly.
- Sports, health, and animation: analyzing movement, creating realistic characters, and providing feedback in real time.
- Education and research: a simple, strong baseline that others can adapt to new tasks.
Limitations and future ideas:
- If the head isn’t visible, detection can struggle. Using more body cues could help.
- The current body model doesn’t include clothing or appearance; future versions could add rich visual details.
- It can serve as a fast starting point for slower, optimization-based methods to fine-tune accuracy when needed.
- The approach could extend to other moving objects (animals, vehicles) with full 6D poses.
In short, Human3R shows that with smart prompting and a strong base model, you can build a fast, unified system that understands people and their surroundings from a single video, opening doors to many real-world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and can guide future research:
- Reliance on head-based queries: Performance degrades when heads are occluded, truncated, far away, or out-of-frame. How to replace or augment head queries with multi-keypoint or dense, pixel-aligned person queries that are robust to occlusion, scale changes, and unusual viewpoints (e.g., top-down, egocentric)?
- Missing explicit contact and physics: No explicit contact detection, collision handling, or dynamics priors are used; foot-skate and body-scene penetration are not analyzed. Can lightweight, differentiable contact losses (e.g., SDF-based collisions) or motion priors be integrated without sacrificing real-time speed?
- Scene output limited to pointmaps: The scene is reconstructed as dense pointmaps without meshing, semantics, or object-level structure. How to produce temporally consistent, loop-closed meshes and object-level reconstructions suitable for downstream interaction, planning, and simulation?
- Identity and shape consistency over time: There is no explicit per-person persistent latent or constraints to keep body shape consistent across long sequences; potential identity switches and shape drift are not evaluated. How to enforce temporal shape consistency and identity re-identification across long occlusions and state resets?
- Tracking and segmentation evaluation is missing: The proposed training-free segmentation and token-based tracking lack quantitative evaluation (e.g., mIoU for masks; HOTA/MOTA/MOTP/IDF1 for tracking). What is their accuracy, failure modes, and scalability to crowded scenes?
- Long-sequence stability and state management: The method requires TTT3R and periodic state resets (every ~100 frames), with unspecified chunk-alignment details and potential continuity breaks. Can learned memory compression, loop-closure, or bounded-optimal state updates remove resets while preserving accuracy and continuity?
- Metric scale reliability and drift: Although the model is “metric,” pose evaluation uses Sim(3) alignment and does not quantify absolute scale drift over long sequences, especially under dynamic scenes. How stable is the recovered metric scale and focal length over minutes-hours and zoom events?
- Intrinsics recovery and lens models: Intrinsics are computed via a Weiszfeld-based procedure assuming a pinhole model; robustness to rolling shutter, radial/tangential distortion, and time-varying intrinsics (e.g., smartphone zoom) is untested. How to extend to realistic lens/distortion models and validate accuracy under zoom and distortion?
- Domain gap from synthetic training: Fine-tuning uses BEDLAM (synthetic) with limited scene diversity; systematic analysis of synthetic-to-real generalization is missing. Which domain adaptation strategies (style transfer, self-training, test-time adaptation beyond state updates) most effectively close the gap on real, in-the-wild videos?
- Robustness to diverse capture conditions: The impact of motion blur, low light, overexposure, rolling shutter, low frame rates, dropped frames, and extreme FOVs is not studied. What preprocessing or robust training improves performance in adverse conditions?
- Crowded scenes and scalability with people count: Runtime and accuracy scaling with the number of people, heavy occlusions, and dense crowds are not quantified. What are practical limits on the number of simultaneous people and how can token/query allocation be optimized under crowding?
- Detailed hands and face: Although SMPL-X is used, detailed hand and face pose/expressions are neither evaluated nor optimized, and may be weak given CUT3R’s scene-centric priors. What additional priors or losses (e.g., hand/face keypoint or photometric cues) are needed for high-fidelity extremities?
- No clothing, hair, or appearance modeling: Human geometry is restricted to SMPL-X proxy meshes; clothing/hair dynamics and appearance are not reconstructed. How to anchor 3D Gaussian Splatting or neural radiance textures to SMPL(-X) while preserving real-time constraints?
- Dynamic non-human objects: The method assumes humans as the primary dynamic entities; moving vehicles, carried objects, and articulated props are not modeled and may degrade reconstruction. How to extend to multi-category dynamic reconstruction with 6D poses and articulated kinematics?
- Missing uncertainty estimates: The model does not output calibrated uncertainties for human pose, depth, or camera pose. How can uncertainty be estimated and propagated to downstream tasks (e.g., safe control, optimization-based refinement)?
- Evaluation gaps for camera intrinsics and pose: Intrinsics are predicted per frame, but there is no benchmark for intrinsics accuracy and temporal stability; ATE is reported after Sim(3) alignment, masking scale errors. Can new metrics isolate focal length stability, rolling shutter effects, and pose scale drift?
- Temporal smoothness vs. responsiveness trade-off: The effect of state updates (TTT3R) on short-term jitter versus long-term drift is not dissected. What are principled update rules or learned schedulers that balance stability and responsiveness?
- Integration with loop closure/SLAM: The method avoids SLAM dependencies but also forfeits loop closure and global consistency in long runs. Can lightweight loop-closure cues or scene-graph constraints be integrated without reintroducing heavy preprocessing?
- Failure analysis and ablations: Sensitivity to head-detection threshold τ, image resolution, backbone size (scaling laws), and human-prior encoder choices are only partially explored. A thorough sensitivity and failure-mode study is needed to guide practitioners.
- Resource constraints and deployment: Real-time results are reported on a 48 GB GPU; performance on edge/embedded hardware (mobile SoCs, Jetson) and latency under high-resolution inputs are not characterized. What quantization/pruning or architectural changes enable deployment on resource-constrained platforms?
- Fairness and population coverage: SMPL-X shape priors (10D) may poorly capture children, elderly, mobility aids, or atypical body shapes; impact on accuracy and bias is not studied. How to broaden coverage and evaluate fairness across demographics and assistive devices?
- Multi-sensor fusion: IMU, depth, GNSS, or multi-view inputs are not leveraged, though they could stabilize scale, gravity alignment, and reduce drift. What minimal-sensor additions yield the largest robustness gains without sacrificing simplicity?
- Gravity and global frame definition: The “world” frame is arbitrary and may not be gravity-aligned; no explicit gravity estimator or constraint is used. How to recover gravity-consistent world frames (e.g., with a monocular gravity prior, learned gravity head, or IMU) for robotics applications?
- Scene semantics and affordances: The system lacks semantic labels, affordances, and object categories, limiting human-scene interaction reasoning. Can joint semantic segmentation and affordance estimation improve human motion plausibility and contact reasoning?
- Self-supervision at test time: Apart from state updates, no self-supervised photometric/geometry consistency is used at test time. Can scalable, low-overhead TTA losses (e.g., multi-view reprojection, cycle-consistency) further boost long-sequence performance?
- Benchmark coverage: Many key scenarios remain untested (egocentric footage, outdoor large-scale scenes, mirrors/reflective surfaces, glass/transparencies). Establishing comprehensive benchmarks for these settings would clarify current limits and spur progress.
Practical Applications
Immediate Applications
Below are actionable, deployment-ready uses that leverage Human3R’s real-time, unified 4D human–scene reconstruction from monocular RGB video (15 FPS, ~8 GB GPU), multi-person SMPL-X meshes, camera trajectories, dense point clouds, and built-in segmentation/tracking.
- AR occlusion and spatial anchoring (software, AR/VR)
- What: Real-time occlusion, shadowing, and physics-aware placement of virtual content using metric-scale scene point clouds, camera pose, and multi-person meshes.
- Tool/Product/Workflow: Unity/Unreal plugin consuming Human3R streams for occlusion masks and match-move; live AR previews on a laptop with a webcam or a single RGB mobile camera.
- Assumptions/Dependencies: GPU-capable device; visible heads for reliable multi-person initialization; performance may vary under heavy occlusion/poor lighting; privacy consent required.
- Markerless motion capture for previz and indie production (media/entertainment)
- What: Rapid capture of multi-actor body motion without suits; export SMPL-X sequences to Blender/Maya for retargeting.
- Tool/Product/Workflow: Desktop app recording monocular video, exporting .fbx/.pkl with joint angles; quick previs on set.
- Assumptions/Dependencies: SMPL-X is a proxy (no clothing/appearance); head visibility needed; accuracy sufficient for previs but not high-end VFX final shots.
- Human-aware navigation and obstacle avoidance (robotics)
- What: Feed robot planners with real-time human trajectories and dense scene maps for collision avoidance and path planning in dynamic environments.
- Tool/Product/Workflow: ROS node publishing SMPL-X root trajectories, joint states, scene point clouds, and camera pose; integrate with costmaps and planners (e.g., Nav2/MoveIt).
- Assumptions/Dependencies: Edge GPU on robot; environment-specific tuning; limited robustness with fully occluded heads; safety validation needed before autonomous operation.
- Industrial safety monitoring and near-miss analytics (manufacturing/occupational safety)
- What: Detect unsafe proximities and trajectories around machinery; generate incident reports and heatmaps.
- Tool/Product/Workflow: Plant analytics dashboard that ingests Human3R outputs, computes human–machine distances, tracks recurrent risk zones.
- Assumptions/Dependencies: Camera placement covering critical areas; privacy and labor policy compliance; accuracy depends on occlusion and scene clutter.
- Retail foot-traffic and behavior mapping (retail/analytics)
- What: Multi-person trajectory estimation, dwell-time analysis, and interaction zones (e.g., shelf engagement) from monocular ceiling cams.
- Tool/Product/Workflow: Store analytics service producing occupancy heatmaps and route funnels; integration with BI tools.
- Assumptions/Dependencies: Legal consent and signage; head visibility for robust person initialization; calibration-free but layout alignment needed for floorplan overlays.
- Smart fitness and coaching (consumer health/fitness)
- What: Real-time joint-angle estimation and repetition counting; range-of-motion assessment in living rooms from a single camera.
- Tool/Product/Workflow: Companion app using SMPL-X outputs for rep counting and posture cues; export sessions to coaches.
- Assumptions/Dependencies: Non-clinical accuracy; camera placement guidance; no medical claims; adequate lighting and head visibility.
- Telepresence avatars for video conferencing (communications/software)
- What: Convert webcam streams into 3D body animations for virtual avatars; use camera trajectory to stabilize and render consistent views.
- Tool/Product/Workflow: Plugin for conferencing platforms that maps SMPL-X to avatar rigs; match-move overlays.
- Assumptions/Dependencies: GPU resources; background complexity can affect scene estimation; appearance not modeled (clothing/face realism).
- Camera stabilization, match-moving, and CG integration (post-production software)
- What: Use estimated camera trajectory and scene point maps to stabilize shaky videos, perform accurate match-move, and insert CG elements.
- Tool/Product/Workflow: NLE/VFX plugin that reads Human3R outputs; automatic track solving without traditional SLAM in dynamic scenes.
- Assumptions/Dependencies: Accuracy depends on scene texture and motion; occlusions and fast motion can degrade pose estimation.
- Academic dataset bootstrapping for 3D vision and human motion (academia)
- What: Auto-annotate public monocular videos with 3D bodies, scene point clouds, and camera poses; human-in-the-loop correction for high-quality datasets.
- Tool/Product/Workflow: Annotation pipeline with confidence scores, active learning loops to prioritize frames for manual review.
- Assumptions/Dependencies: Synthetic training priors may bias outputs; QA required for research-grade labels; ethical/legal checks for data sources.
- Urban micro-mobility and pedestrian behavior studies with existing CCTV (policy/urban planning)
- What: Extract trajectories, crossing times, and near-miss events for crosswalks and sidewalks to inform interventions.
- Tool/Product/Workflow: City analytics dashboard ingesting Human3R outputs to produce metrics and time-of-day heatmaps.
- Assumptions/Dependencies: Governance and privacy frameworks; scene-to-map alignment; performance depends on camera height and crowd density.
- Sports training analysis (sports technology)
- What: Estimate joint kinematics for form feedback in running, weightlifting, or yoga using a phone.
- Tool/Product/Workflow: Mobile app offering repetition feedback and qualitative form cues, exporting sessions to coaches.
- Assumptions/Dependencies: Not for clinical diagnosis; consistent framing; sport-specific validation recommended.
- XR games with dynamic occlusion and physics (gaming/software)
- What: Real-time interaction between players and virtual objects using human pose and scene geometry.
- Tool/Product/Workflow: Game SDK that queries collision volumes from SMPL-X and scene point clouds.
- Assumptions/Dependencies: Device GPU; latency constraints; testing across diverse lighting and backgrounds.
Long-Term Applications
Below are applications that require further research, scaling, validation, or productization beyond the current capability or scope (e.g., stronger priors, contact modeling, clothing/appearance, mobile deployment, regulatory clearances).
- Humanoid policy learning and imitation at scale (robotics)
- What: Train locomotion and manipulation policies from monocular demonstrations with global trajectories and 6D poses.
- Tool/Product/Workflow: Large curated video datasets processed by Human3R, combined with contact/force inference and simulation alignment.
- Assumptions/Dependencies: Accurate contact modeling, robustness to occlusion, domain gap mitigation; simulation-to-real transfer.
- Pedestrian intent prediction for ADAS/AV (automotive)
- What: Predict pedestrian trajectories and intent from dashcams in dynamic urban scenes.
- Tool/Product/Workflow: AV perception module ingesting global human motion; risk assessment for braking/steering.
- Assumptions/Dependencies: Reliability under occlusion/weather/night; safety certification; integration with multi-sensor stacks.
- Clinical gait analysis and telerehabilitation (healthcare)
- What: Remote assessment of mobility impairments, ROM metrics, and therapy progress without wearables.
- Tool/Product/Workflow: Telehealth platform providing clinician dashboards and standardized metrics.
- Assumptions/Dependencies: Clinical-grade validation, regulatory approvals (e.g., FDA/CE), improved per-joint accuracy and robustness, privacy-by-design.
- Privacy-preserving, on-device inference on smartphones (consumer/software)
- What: Run Human3R locally for home/office scenarios to avoid streaming raw video.
- Tool/Product/Workflow: Compressed models with hardware acceleration (NNAPI/Core ML) and energy-aware scheduling.
- Assumptions/Dependencies: Model distillation/quantization, mobile GPU/NPU support; performance vs. accuracy trade-offs.
- Building digital twins with occupancy-driven energy optimization (energy/buildings)
- What: Integrate real-time occupancy and motion patterns to optimize HVAC, lighting, and space utilization.
- Tool/Product/Workflow: BMS integration using occupancy maps from Human3R, predictive control algorithms.
- Assumptions/Dependencies: Long-term reliability; privacy compliance; calibration to floor plans; cross-season generalization.
- Human–object interaction and physics-aware reconstruction (robotics/AR/VR)
- What: Extend to contact-aware bodies and clothed avatars, enabling precise manipulation and realistic simulation.
- Tool/Product/Workflow: 3D Gaussian Splatting (3DGS) anchored on SMPL; contact inference; scene semantics.
- Assumptions/Dependencies: New models/datasets for clothing, contact, and forces; increased compute; combined optimization + feed-forward pipelines.
- Multispecies and multi-entity reconstruction (wildlife/transport)
- What: Reconstruct animals, cyclists, and vehicles with full 6D poses from monocular video.
- Tool/Product/Workflow: Domain-specific priors and token detectors; annotated datasets; tailored body models.
- Assumptions/Dependencies: Training data scarcity; new parametric models; domain adaptation.
- High-fidelity volumetric telepresence (communications/media)
- What: Photoreal avatars with clothing, facial expressions, and appearance, driven by monocular streams.
- Tool/Product/Workflow: Hybrid pipeline merging Human3R kinematics with neural radiance/3DGS appearance models.
- Assumptions/Dependencies: Multi-view augmentation or learned priors for appearance; bandwidth/compute constraints; privacy safeguards.
- Policy frameworks for ethical 3D pose capture in public spaces (policy/governance)
- What: Standards for consent, data minimization, retention, and risk assessment for 3D reconstruction from CCTV/bodycams.
- Tool/Product/Workflow: Guidelines, DPIA templates, audit checklists; privacy-preserving default settings in products.
- Assumptions/Dependencies: Stakeholder engagement; local regulations; technical mitigations (e.g., on-device processing, anonymization).
- Insurance and legal incident reconstruction (finance/legal)
- What: Reconstruct human trajectories and camera motion from security video to support claim analysis and forensics.
- Tool/Product/Workflow: Expert toolchain with uncertainty quantification, chain-of-custody logs, and court-admissible reports.
- Assumptions/Dependencies: Accuracy validation; explainability; evidentiary standards; handling of occlusions and scene ambiguity.
- Video compression via 4D parametric representations (software/communications)
- What: Reduce bitrate by transmitting human/body parameters and sparse scene geometry rather than raw pixels.
- Tool/Product/Workflow: Codec research integrating SMPL-X and pointmap streams; decoder-side rendering.
- Assumptions/Dependencies: Robust reconstruction at the receiver; standardization; quality vs. bitrate trade-offs.
- Workplace ergonomics and risk assessment (occupational health)
- What: Quantify posture risk (e.g., lifting angles) over time to inform interventions and training.
- Tool/Product/Workflow: Analytics platform with benchmarked ergonomic scores derived from SMPL-X joints.
- Assumptions/Dependencies: Validation against gold-standard motion capture; occlusion handling; worker privacy safeguards.
- Smart home fall detection with 3D context (consumer/elder care)
- What: Detect falls and risky movements using global pose and scene geometry rather than 2D cues.
- Tool/Product/Workflow: On-device inference with privacy; alerting system integrated with caregivers.
- Assumptions/Dependencies: Reliability across homes; headless detection improvements; regulatory considerations for medical notifications.
Notes on feasibility constraints across applications:
- Current limitations: reliance on head visibility for robust multi-person prompts; SMPL-X proxy meshes do not model clothing/appearance; accuracy can drop in heavy occlusions and long sequences without TTT3R; synthetic training domain (BEDLAM) may introduce bias.
- Compute: Real-time 15 FPS reported with ~8 GB GPU; mobile/embedded deployment likely requires compression/optimization.
- Governance: Privacy, consent, storage, and purpose limitation must be addressed for public/corporate deployments.
- Calibration: The system estimates camera intrinsics/pose; aligning outputs to floorplans or CAD models may require minimal additional mapping steps.
Glossary
- 3D Gaussian Splatting (3DGS): A rendering and representation technique that models 3D geometry/appearance using Gaussian primitives, enabling fast, view-consistent reconstruction. "Extending the framework with 3DGS anchored on SMPL would enable richer, more holistic reconstructions."
- 4D reconstruction foundation model: A large pretrained model that encodes spatiotemporal (3D+time) priors to reconstruct scenes and dynamics across video streams. "Our key idea is to leverage the strong spatiotemporal priors learned by a 4D reconstruction foundation model~\citep{cut3r}."
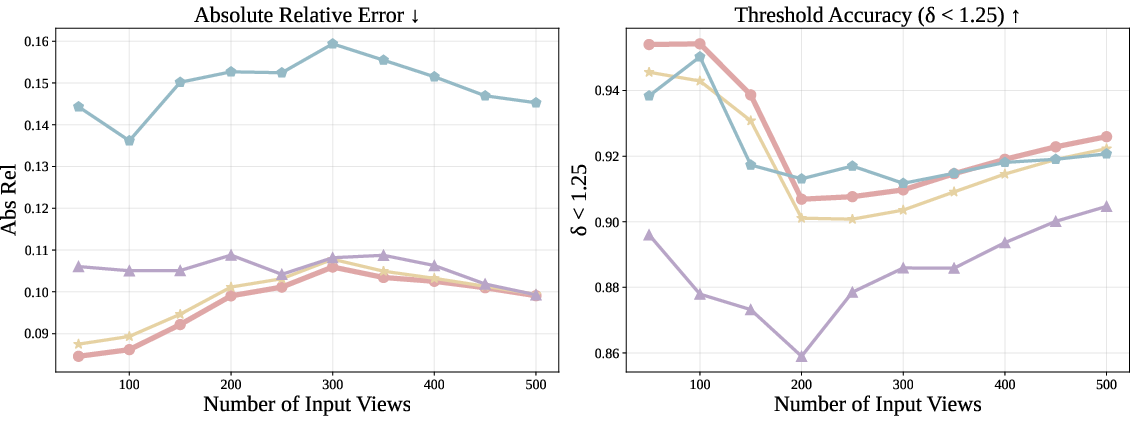
- Absolute Relative Error: A depth evaluation metric measuring the ratio of absolute error to ground-truth depth, averaged over pixels. "We use Absolute Relative Error and $\delta\textless1.25$ (percentage of predicted depths within a 1.25-factor of true depth) as metrics."
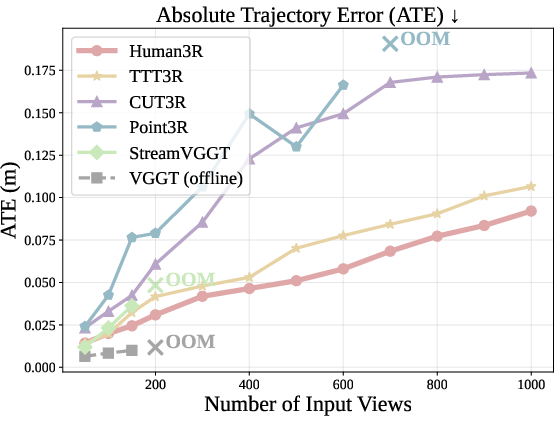
- Absolute Translation Error (ATE): A trajectory metric quantifying translational deviation of estimated camera poses from ground truth (often after similarity alignment). "We report the Absolute Translation Error (ATE) after applying the Sim(3) alignment~\citep{umeyama} on the estimated camera trajectory to the ground-truth."
- all-at-once: A unified approach that jointly predicts multiple components (humans, scene, camera) in a single forward pass without multi-stage refinement. "We introduce , an all-at-once model for 4D human-scene reconstruction."
- axis-angle rotations: A rotation parameterization where a 3D rotation is defined by an axis and an angle about that axis. "local human pose (relative axis-angle rotations) "
- BEDLAM: A synthetic, multi-human dataset with scene depth, camera poses, and SMPL-X meshes used for training/finetuning. "BEDLAM~\citep{BEDLAM} serves as our training data, which is small-scale yet high-quality, with 6k sequences featuring 3D scene depth, camera poses, and SMPL-X meshes of multiple persons in the world coordinates."
- bottom-up multi-person SMPL-X regressor: A method that infers multiple human bodies directly from the full image without relying on person detection/cropping. "With a bottom-up multi-person SMPL-X regressor, our model can reconstruct multiple persons in a single forward pass."
- camera extrinsic pose: The camera’s position and orientation in the world coordinate frame (rotation and translation). "the camera extrinsic pose $\bT_t \in \mathbb{R}^{3 \times 4}$"
- camera intrinsics: The internal calibration parameters of the camera (e.g., focal length, principal point). "Multi-HMR~\citep{Multi-HMR} eliminates the need for off-the-shelf human detectors, but still requires ground-truth camera intrinsics."
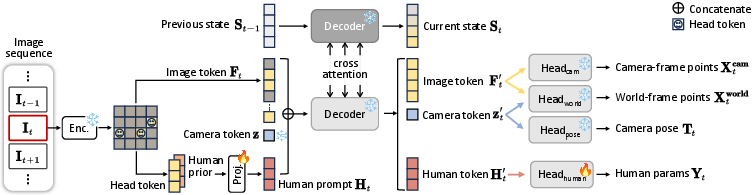
- camera token: A learned token used by the model to capture image-level ego motion and inform camera pose estimation. "The camera token, designed to capture the image-level ego motion related to the scene, is prepended to the image tokens and is initialized as a learnable parameter ."
- canonical point cloud: A point cloud representation aligned to a canonical frame or format for consistent processing across frames. "the canonical point cloud $\bX_t \in \mathbb{R}^{W\times H \times 3}$."
- catastrophic forgetting: The tendency of a model with recurrent state to forget earlier information when processing long sequences. "TTT3R~\cite{ttt3r} introduces a closed-form state transition rule as a training-free intervention to mitigate the catastrophic forgetting observed in CUT3R."
- confidence-aware 3D regression loss: A loss function that weights 3D prediction errors by estimated confidence, improving robustness. "we apply a confidence-aware 3D regression loss $\mathcal{L}_{\text{pointmap}$ to the metric-scale pointmaps"
- cross-attention: An attention mechanism where queries attend to keys/values from a different token set or memory (e.g., scene state). "and cross-attend with the scene state to retrieve temporally consistent human tokens within the 3D scene context."
- DensePose: A method that maps image pixels to the surface of a human body, providing dense correspondences for fitting meshes. "HAMSt3R~\citep{hamst3r}, for example, jointly reconstructs the scene and DensePose~\citep{densepose} from multi-view images in a feed-forward manner"
- dense prediction head: A network module that outputs per-pixel (dense) predictions such as depth or point maps. "After the state-token interaction, the corresponding pixel-aligned metric scale (i.e, meters) 3D pointmaps ... are extracted via dense prediction head~\citep{dpt}:"
- DINOv2: A self-supervised Vision Transformer pretraining method producing strong image features. "Multi-HMR, for example, finetunes DINOv2~\citep{dinov2} on synthetic datasets~\citep{BEDLAM,AGORA}"
- dustbin: An additional row/column in an assignment matrix allowing unmatched detections to be explicitly assigned to a “no match” bin. "by appending a new row and column dustbin with a threshold, so that unmatched human tokens are explicitly assigned to it."
- ego motion: The motion of the camera relative to the surrounding scene. "designed to capture the image-level ego motion related to the scene"
- fast weight: A rapidly updated memory/state parameter enabling online adaptation in recurrent models. "we adopt TTT3R~\citep{ttt3r}, which parameterizes the state $\bS$ as a fast weight"
- feed-forward: A non-iterative inference pipeline that computes outputs directly without optimization loops. "We present , a unified, feed-forward framework for online 4D human-scene reconstruction"
- global optimization: Solving for multiple variables jointly over an entire sequence or dataset to minimize a global objective. "Existing methods for joint human-scene 3D reconstruction typically perform global optimization over camera poses"
- global human motion: Human motion represented in the world coordinate system including global trajectory and orientation. "Prior global human motion estimators typically follow one of two strategies"
- human head tokens: Image feature tokens corresponding to patches containing the human head keypoint, used as anchors for body reconstruction. "we detect the human head tokens from CUT3R's image feature"
- human mesh recovery (HMR): Inferring parametric human body meshes (e.g., SMPL/SMPL-X) from images or video. "Previous works on human mesh recovery (HMR) primarily focus on estimating the pose and shape parameters of a parametric body model"
- Mean Root Position Error (MRPE): The average error between predicted and ground-truth pelvis/root positions, used to assess spatial localization quality. "We use the Mean Root Position Error (MRPE)~\citep{Multi-HMR} between the predicted and ground-truth pelvis locations"
- metric-scale: Predictions expressed in true physical units (e.g., meters), enabling absolute measurements rather than relative ones. "pixel-aligned metric scale (i.e, meters) 3D pointmaps"
- monocular videos: Video captured from a single camera/viewpoint, without multi-view synchronization. "from casually captured monocular videos."
- MPJPE: Mean Per-Joint Position Error; average Euclidean error over 3D joints. "mean per-joint position error (MPJPE)"
- multi-view images: Images of the same scene captured from different viewpoints/cameras. "either from multi-view images~\citep{hsfm,hamst3r,humancalib}"
- optimal transport: A mathematical framework for computing the minimal-cost mapping between distributions; used for tracklet assignment. "The assignment with dustbin $\overline{\bA}$ can be solved by optimal transport~\citep{optimal_transport}"
- optical flow: Dense per-pixel motion field between consecutive frames, used for tracking or motion estimation. "optical flow~\citep{TRACE}"
- PA-MPJPE: Procrustes-Aligned MPJPE; MPJPE after similarity (scale/rotation/translation) alignment. "Procrustes-aligned per-joint position error (PA-MPJPE)"
- pixel shuffle: An upsampling operation that rearranges feature channels to increase spatial resolution. "using pixel shuffle~\citep{pixelshuffle} to produce a pixel-aligned dense mask"
- pixel-aligned point clouds: 3D points aligned per pixel in the image, linking image locations to 3D coordinates. "pixel-aligned point clouds in the world coordinate system"
- pixel-aligned point maps (pointmaps): Per-pixel 3D point predictions in camera/world frames. "metric-scale point maps (pixel-aligned point clouds in the world coordinate system)"
- Procrustes alignment: A similarity transform (scale, rotation, translation) used to align shapes/poses before error computation. "Procrustes-aligned per-joint position error (PA-MPJPE)"
- recurrent reconstruction: Sequential, stateful reconstruction where a persistent memory is updated as new frames arrive. "CUT3R performs recurrent reconstruction of metric-scale point maps ... maintaining a fixed-size memory state"
- reprojection loss: A loss measuring discrepancy between 3D predictions projected to 2D and observed image features/keypoints. "and reprojection loss $\mathcal{L}_{\text{reproj.}$"
- RNN-based methods: Approaches using recurrent neural networks or recurrent states to model temporal sequences. "This is a common issue for RNN-based methods~\citep{spann3r,MUSt3R,LONG3R,Point3R}"
- Root Translation Error (RTE): A trajectory metric (often in %) measuring translation error of the root after alignment, normalized by displacement. "we additionally report the root translation error (RTE, in \%) after rigid alignment (without scaling), normalized by the total displacement."
- SE(3): The group of 3D rigid motions (rotation and translation). "and global human root transformation $\bP = [\bR\mid t] \in \mathrm{SE}(3)$"
- Sim(3) alignment: Alignment using a similarity transform (scale+rotation+translation) often applied to trajectories. "after applying the Sim(3) alignment~\citep{umeyama}"
- Sinkhorn algorithm: An iterative method to solve entropic regularized optimal transport problems efficiently. "The assignment with dustbin $\overline{\bA}$ can be solved by optimal transport ... with the Sinkhorn algorithm~\citep{sinkhorn}"
- SLAM (Simultaneous Localization and Mapping): Algorithms that jointly estimate camera pose and map the environment. "With SLAM (Simultaneous Localization and Mapping)~\citep{SLAM}, world-frame camera poses can be estimated"
- SO(3): The group of 3D rotations. "global orientation $\bR\in \mathrm{SO}(3)$"
- spatiotemporal priors: Learned knowledge about spatial and temporal structure in dynamic scenes, aiding robust reconstruction. "leverage the strong spatiotemporal priors~\citep{Feat2GS,ThinkingInSpace,VLM3R}"
- Test-Time Training (TTT): Adapting the model during inference using self-supervised signals to improve generalization. "This Test-Time Training (TTT)~\citep{ttt} procedure adaptively encodes the current observation into the memory state"
- transformer decoders: Attention-based modules processing token sequences with cross/self-attention to update states and make predictions. "This bidirectional state-token interaction is implemented using two interconnected transformer decoders~\citep{dust3r,croco,crocov2}."
- tracklet: A short temporal sequence of associated detections used to maintain identity over time. "We maintain a human token tracklet~\citep{PHALP} indexed by "
- ViT (Vision Transformer): A transformer model applied to images by tokenizing patches. "through the ViT image tokenizer~\citep{vit}: $\bF_t = \mathrm{Encoder}(\bI_t)$"
- ViT-DINO: Vision Transformer features obtained from DINO self-supervised training, often used as powerful priors. "Multi-HMR~\citep{Multi-HMR} ViT-DINO feature"
- Visual Prompt Tuning (VPT): A parameter-efficient technique that prepends learnable prompts to inputs while keeping the backbone frozen. "We finetune CUT3R via visual prompt tuning (VPT)~\citep{vpt}, with minimal learnable parameters prepended into the input space"
- Weiszfeld algorithms: Iterative methods for computing geometric medians; used here to solve camera intrinsics from point maps. "the camera intrinsic $\bC_t$ is solved using Weiszfeld~\citep{weiszfeld} algorithms with predicted pointmaps"
- world coordinate system: A global reference frame in which cameras, scenes, and humans are expressed. "pixel-aligned point clouds in the world coordinate system"
- world frame: The global coordinate frame used to express poses and trajectories consistently across time. "We present , a unified, feed-forward framework for online 4D human-scene reconstruction, in the world frame"
- ZoeDepth: A learned metric depth estimator used to obtain absolute-scale depth from images. "estimating metric depth via ZoeDepth~\cite{zoedepth}"
- associative recall: Retrieving stored information from memory by matching current cues, supporting long-sequence consistency. "use the spatial average of the attention values as a closed-form update rule for online associative recall in test time"
Collections
Sign up for free to add this paper to one or more collections.