- The paper introduces WorldForge, a training-free framework that guides pre-trained video diffusion models for precise trajectory control in 3D/4D scene generation.
- It integrates three modules – Intra-Step Recursive Refinement, Flow-Gated Latent Fusion, and Dual-Path Self-Corrective Guidance – to decouple motion, enforce spatial coherence, and correct trajectory drift without retraining.
- Empirical results on static and dynamic benchmarks show improved fidelity, reduced artifacts, and state-of-the-art performance in novel view synthesis.
WorldForge: Training-Free 3D/4D Generation in Video Diffusion Models via Inference-Time Guidance
Introduction
WorldForge introduces a training-free, inference-time framework for controllable 3D and 4D scene generation using pre-trained video diffusion models (VDMs). The method addresses the persistent limitations of VDMs in spatial intelligence tasks, specifically their lack of precise trajectory control, geometric consistency, and disentanglement of scene and camera motion. Unlike prior approaches that require retraining or fine-tuning—often at the expense of pretrained priors and computational efficiency—WorldForge leverages the latent world priors of large-scale VDMs through a synergistic set of guidance mechanisms, enabling plug-and-play trajectory control and high-fidelity synthesis.

Figure 1: WorldForge leverages a pre-trained video diffusion model for monocular 3D scene generation and dynamic 4D scene re-rendering, supporting precise camera trajectory control and high-quality outputs.
Framework Overview
WorldForge operates in a warp-and-repaint paradigm, integrating three core modules:
- Intra-Step Recursive Refinement (IRR): Embeds a micro-scale predictor-corrector loop at each denoising step, injecting trajectory-aligned latent signals derived from depth-based warping.
- Flow-Gated Latent Fusion (FLF): Decouples motion and appearance features in the VAE latent space, selectively injecting trajectory cues into motion-relevant channels using optical flow similarity metrics.
- Dual-Path Self-Corrective Guidance (DSG): Dynamically balances guided and unguided denoising paths, adaptively correcting trajectory drift and suppressing artifacts from noisy or misaligned structural signals.
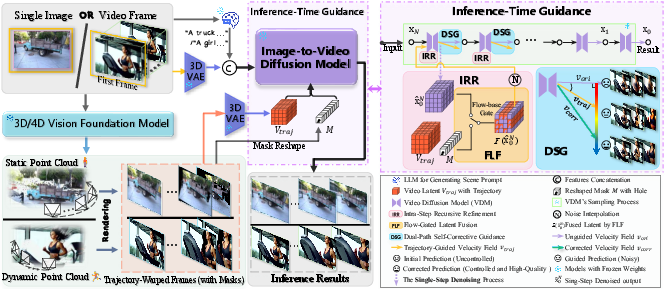
Figure 2: The pipeline reconstructs a scene point cloud from input images, warps it along a user-specified trajectory, and injects trajectory control via IRR, FLF, and DSG for high-quality synthesis without retraining.
Technical Contributions
Intra-Step Recursive Refinement (IRR)
IRR modifies the intermediate denoised sample x0^ at each diffusion step by fusing it with trajectory latents Ztraj (obtained from depth-based warping) in observable regions, controlled by a binary mask M. This ensures that trajectory constraints are injected at every step, maintaining fine-grained alignment with the target camera path. The fusion is noise-schedule-weighted, preserving stochasticity while enforcing trajectory adherence.
Flow-Gated Latent Fusion (FLF)
FLF addresses the entanglement of motion and appearance in VAE latents. By computing per-channel optical flow between predicted and reference latents, FLF scores each channel for motion relevance using normalized metrics (M-EPE, M-AE, Fl-all). Only channels above a dynamic threshold receive trajectory guidance, preventing degradation of appearance details and enabling precise viewpoint manipulation.
Dual-Path Self-Corrective Guidance (DSG)
DSG introduces two concurrent denoising paths: a guided path (trajectory-conditioned) and an unguided path (model prior). The correction signal is computed as a cosine-weighted interpolation between their velocity fields, amplifying corrections when the paths diverge and reducing them when they agree. This mechanism mitigates off-manifold drift and artifact propagation, balancing trajectory control with perceptual fidelity.
Empirical Evaluation
WorldForge is evaluated on static 3D and dynamic 4D benchmarks, including LLFF, Tanks and Temples, and MipNeRF 360, as well as diverse real-world and synthetic scenes. The framework is tested on Wan2.1 and SVD backbones, demonstrating model-agnostic transferability.

Figure 3: WorldForge produces more consistent scene content under novel viewpoints compared to SOTA methods, with improved image detail, trajectory accuracy, and structural plausibility.

Figure 4: On human-centric scenes, WorldForge maintains stationarity and plausibility, outperforming baselines that introduce artifacts or fail to reconstruct fine details.

Figure 5: WorldForge synthesizes ultra-wide 360∘ orbit views from a single outdoor image, supporting object-centric trajectories and high visual quality.

Figure 6: In 4D trajectory-controlled re-rendering, WorldForge avoids implausible artifacts and reconstructs realistic content along the target path, outperforming training-intensive baselines.

Figure 7: The method enables advanced video effects, including camera freezing, stabilization, and content editing, broadening its practical scope.
Ablation and Robustness
Ablation studies confirm the complementary effects of IRR, FLF, and DSG. Removing any component degrades trajectory adherence, visual fidelity, or artifact suppression. The framework demonstrates robustness to different depth estimation models (VGGT, UniDepth, Mega-SaM, DepthCrafter), leveraging VDM priors to self-correct warping errors and fill missing regions.

Figure 8: Component ablation shows that IRR, FLF, and DSG are all necessary for optimal fidelity and control.

Figure 9: Guidance transfers seamlessly to compact U-Net-based SVD models, achieving SOTA performance in content quality and trajectory consistency.
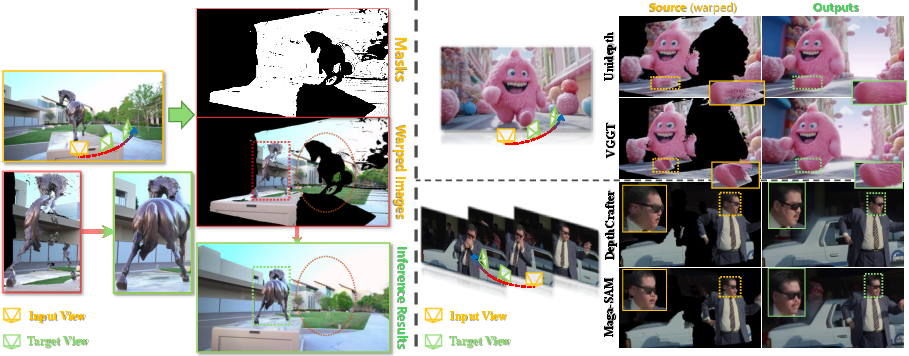
Figure 10: WorldForge reliably compensates for depth estimation noise, producing realistic results across various depth models.
Numerical Results and Claims
WorldForge achieves superior FID, CLIP similarity, FVD, and trajectory metrics (ATE, RPE-T, RPE-R) compared to both training-based and training-free SOTA baselines. The method is training-free, incurring zero training cost and only a moderate inference-time overhead (~40–50% over base model inference). Notably, it matches or surpasses training-intensive pipelines in both static and dynamic settings, and its guidance strategy is architecture-independent.
Implications and Future Directions
WorldForge establishes a new paradigm for controllable video synthesis, demonstrating that inference-time guidance can unlock the latent spatial intelligence of large-scale VDMs without retraining. This approach is broadly applicable to tasks requiring structured spatial reasoning, such as novel view synthesis, free-viewpoint rendering, and dynamic scene reconstruction. The framework's robustness to depth estimation and backbone architecture suggests strong generalization potential.
Limitations include reduced control over small objects and fine details, and failure cases under extremely poor depth estimation. Future work should explore fine-grained control mechanisms and integration with more powerful generative backbones.
Conclusion
WorldForge presents a unified, training-free framework for trajectory-controllable 3D/4D generation in video diffusion models. By integrating IRR, FLF, and DSG at inference time, it achieves precise trajectory control, high visual fidelity, and strong generalization, outperforming existing methods without retraining. The approach advances the practical deployment of VDMs in spatial intelligence tasks and opens avenues for further research in plug-and-play generative control and emergent world modeling.

