- The paper introduces a novel framework that mines GitHub PR chains to capture long-horizon agency data in software engineering.
- It employs a sequential MDP formulation and principled reverse-instruction process to ensure high semantic fidelity and iterative refinement.
- Empirical results show significant data efficiency, with up to 47% improvement on benchmarks using only 239 training samples.
Unlocking Long-Horizon Agency via Chain-of-PRs: The daVinci-Agency Paradigm
Motivation and Background
Long-horizon autonomous workflows—especially within the domain of software engineering—pose fundamental challenges for LLM-based agents due to the scarcity of structured training data capturing authentic cross-stage dependencies and iterative refinement dynamics. Existing approaches either rely on synthetic environments or prohibitively costly manual annotation, both failing to model the real-world evolution inherent in practical engineering cycles. The daVinci-Agency framework introduces a paradigm shift by mining continuous Pull Request (PR) chains from GitHub repositories, thereby reconstructing task trajectories grounded in the natural evolution of features, bug fixes, and refinements within complex codebases.
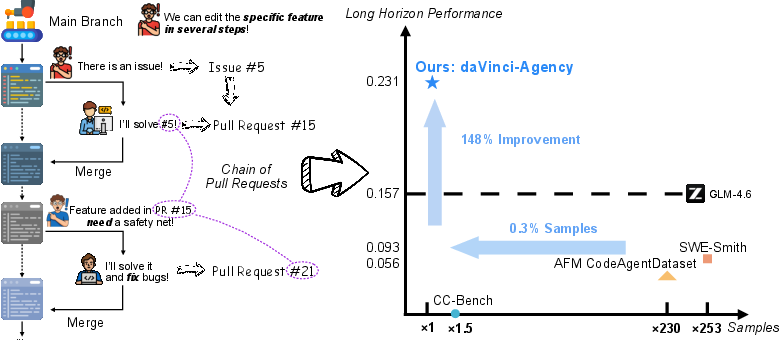
Figure 1: daVinci-Agency extracts causal supervision from multi-stage PR chains, enabling exceptional long-horizon agency with substantial performance gains from minimal training samples.
daVinci-Agency models the software engineering process as a sequential MDP involving an agent interacting with an evolving code environment. At each step, the agent observes the current repository state and executes reasoning messages and tool actions, constructing a trajectory τ={(oj,mj,tj)}j. Real-world repositories are treated as dynamic entities, with PRs encoding both natural language context and ground-truth code patches. Chains of PRs, denoted C={pr1,...,prk}, encapsulate semantic dependencies through explicit references and fixes, compelling agents to maintain long-term consistency and iterative refinement over extended horizons.
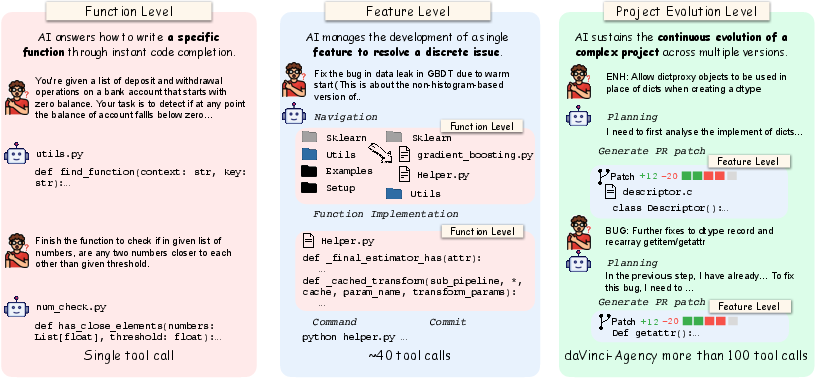
Figure 2: Task scope comparison: project-level evolution requires persistent agency beyond local feature resolution.
Data Sourcing and Synthesis Pipeline
The daVinci-Agency pipeline systematically constructs long-horizon scenarios via curated chains of PRs from nine representative, high-interactivity repositories spanning diverse stacks. Semantically dependent PRs are linked to form complex, non-contiguous evolutionary chains, preserving logical and temporal dependencies critical for robust long-horizon reasoning.
Queries for each stage are synthesized through a principled reverse-instruction process, deliberately omitting implementation specifics to enforce macroscopic planning and code localization skills. Rollouts in carefully engineered environments propagate file modifications stage-to-stage, ensuring continuity and enforcing state management constraints.
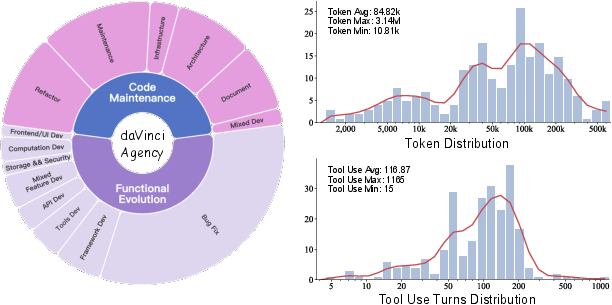
Figure 3: daVinci-Agency exhibits broad domain coverage and substantial complexity in trajectory length and tool utilization.
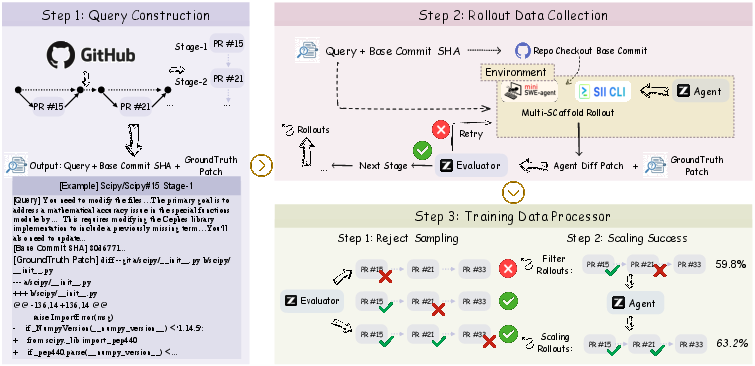
Figure 4: PR chain mining and task chain construction pipeline, providing verifiable state evolution signals as supervision.
Rigorous rejection sampling, employing high semantic fidelity thresholds (s≥0.8), ensures trajectory quality and precludes regression due to low-fidelity rollouts. Only samples achieving functional equivalence under strict evaluation are admitted for training.
Models fine-tuned on daVinci-Agency, notably GLM-4.6, demonstrate significant gains across all major agentic benchmarks, including SWE-bench, Toolathlon, DS-1000, and τ2-Bench. Remarkably, training on only 239 daVinci-Agency samples yields a relative 47% improvement on Toolathlon and achieves average scores superior to baselines trained on datasets orders of magnitude larger.
These robust improvements are not attributable to teacher distillation but rather to the intrinsic optimization afforded by structured, real-world evolutionary trajectories. The multi-PR chain explicitly imparts meta-skills such as task decomposition, long-term consistency, and iterative refinement—capabilities unattainable through synthetic single-feature trajectories or outcome-supervised environments.

Figure 5: Case study—daVinci-Agency enables stable planning and error correction, while baselines suffer from goal drift and escapism.
Efficiency and Generalization Analysis
Long-horizon internalization translates directly to efficiency: fine-tuned agents consume significantly fewer tokens and tool invocations to solve complex tasks, resulting in higher “intelligence per token,” essential for maximizing context window utilization. Qwen3-32B and GLM-4.6 exhibit up to 25.8% reduction in tool use and hundreds of thousands fewer tokens per trajectory, without compromising solution quality.
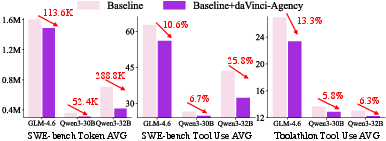
Figure 6: Token and tool use efficiency dramatically improves for daVinci-Agency–fine-tuned models, indicating high skill internalization.
daVinci-Agency generalizes across architecture types (dense, MoE) and scales, consistently boosting agentic performance, including on smaller Qwen3-8B. Training trajectory length scaling further enhances robustness, with extended PR chains yielding up to 8% performance gain and unlocking latent agentic potential.
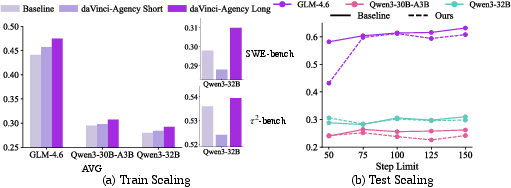
Figure 7: Training horizon scaling and inference budget sensitivity—performance increases as trajectory length and tool call budget are extended.
Practical and Theoretical Implications
The retrospective mining of PR chains establishes a scalable, verifiable paradigm for data construction, enabling agents to master persistent, goal-directed workflows intrinsic to real-world software development. The strong numerical results empirically validate that complex long-horizon skills are best imparted via structured, evolutionary data. This insight extends beyond software engineering, providing a blueprint for constructing agentic datasets in domains where iterative refinement and goal persistence are paramount.
From a theoretical perspective, the identification and exploitation of scaling laws—longer trajectory lengths and more ample inference budgets correlate with improved performance—offers an actionable path for continuous progress in long-horizon agentic modeling. Data synthesis methods privileging evolutionary context and causal dependency structure are poised to supersede outcome-only distillation and annotation-based paradigms.
Conclusion
daVinci-Agency demonstrates that principled, evolution-grounded data synthesis is the decisive factor for unlocking long-horizon agency in autonomous code agents. By extracting structured supervision from continuous chains of PRs, daVinci-Agency enables data-efficient and scalable agent training, substantially advancing capacity for persistent planning, error correction, and consistency. Empirical findings suggest further gains may be realized by extending chain length and trajectory horizon, charting a clear course for future research in long-horizon agent architectures and data paradigms.