Scaling Agents via Continual Pre-training
Abstract: LLMs have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Scaling Agents via Continual Pre-training”
1. What is this paper about?
This paper is about teaching LLMs to act more like smart assistants (called “agents”) that can plan, search the web, use tools, and solve complex tasks step by step. The authors introduce a new way to train these agents, called Agentic Continual Pre-training (Agentic CPT), and build a model named AgentFounder. Their goal is to make agents better at real-world research tasks—like searching, reading, reasoning, and deciding what to do next—without needing expensive online tools during training.
2. What questions are the authors trying to answer?
In simple terms, they ask:
- Why do many open-source “agent” models still struggle compared to the best commercial ones?
- Can we build a stronger “foundation” for agent behavior before the usual fine-tuning step?
- How can we create huge, useful training data for agents without paying for lots of online searches and APIs?
- Does this new training method actually make agents better across many tests?
3. How did they do it? (Methods, explained simply)
Think of training an agent like training a student detective:
- Pre-training = reading a lot of books to learn general knowledge.
- Post-training (SFT/RL) = coaching the detective with step-by-step examples and feedback.
- This paper adds a new middle step: Agentic Continual Pre-training (Agentic CPT) = tons of practice on detective-style tasks before coaching. This builds the “habit” of planning, using tools wisely, and making decisions.
Here’s what they did:
- Built AgentFounder starting from an existing model (Qwen3 series).
- Added a new training stage (Agentic CPT) between pre-training and post-training.
- Created massive agent-style training data offline (no API calls) using two clever data-making methods.
Below are the core ideas, with simple analogies.
- Key idea: Next-token prediction
- The model trains by “guessing the next word” over long, agent-like texts (plans, steps, decisions), so these patterns become natural.
- Two-stage Agentic CPT (like moving from medium to marathon distance)
- Stage 1: 200 billion tokens, 32K context length (shorter documents).
- Stage 2: 100 billion tokens, 128K context length (much longer documents).
- Why? Agents often need long-horizon planning, so long-context practice matters.
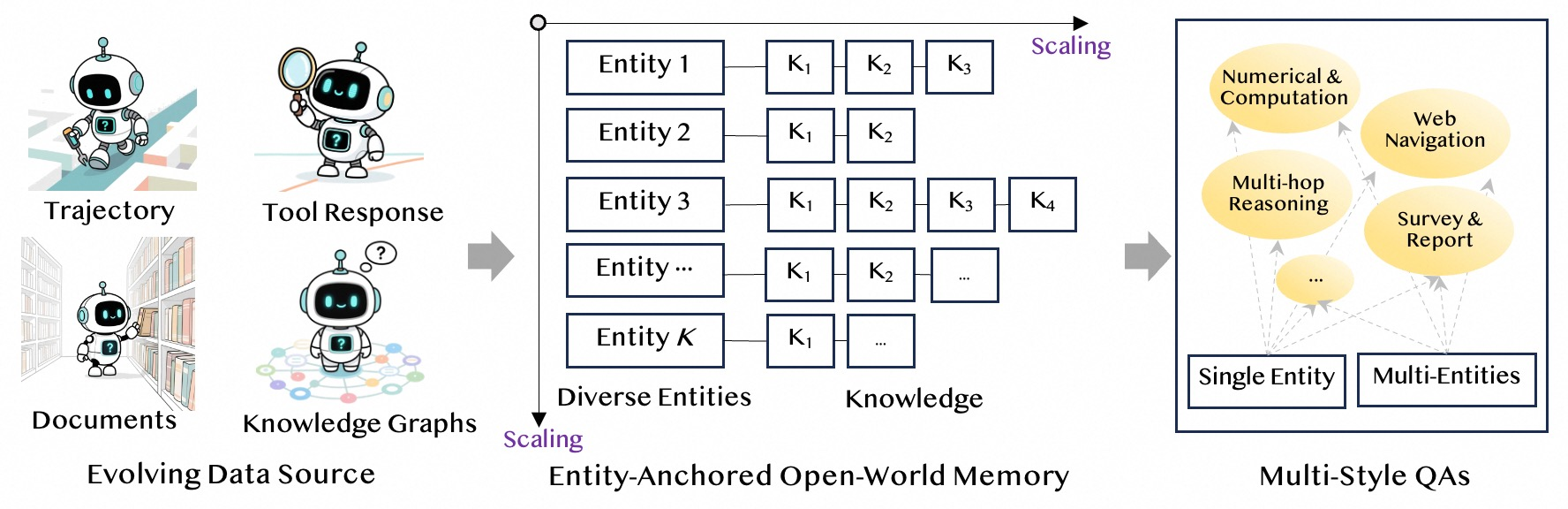
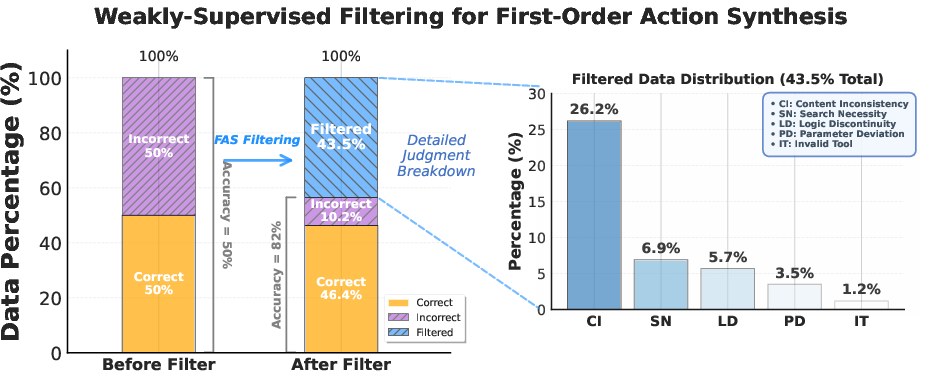
- Method 1: First-order Action Synthesis (FAS) — building practice problems without online tools
- Step A: Build an “open-world memory” from many sources (like web text). Organize knowledge by “entities” (e.g., Paris) and store lots of related facts.
- Step B: Turn that memory into many kinds of questions (factual, multi-hop, numerical, synthesis). This creates realistic research problems.
- Step C: Planning action synthesis. For each question, have the model write a plan and the first step it would take (e.g., which tool to call), but do not actually call any tools. Use multiple styles of questions to get diverse plans.
- Step D: Reasoning action synthesis. Have the model:
- First, break the problem into sub-questions and propose a draft answer using its internal knowledge.
- Then, “refine” the answer using the relevant facts from the memory.
- Quality check (reject sampling): An LLM “judge” checks whether the plans and reasoning align with the known facts. Bad samples are thrown away.
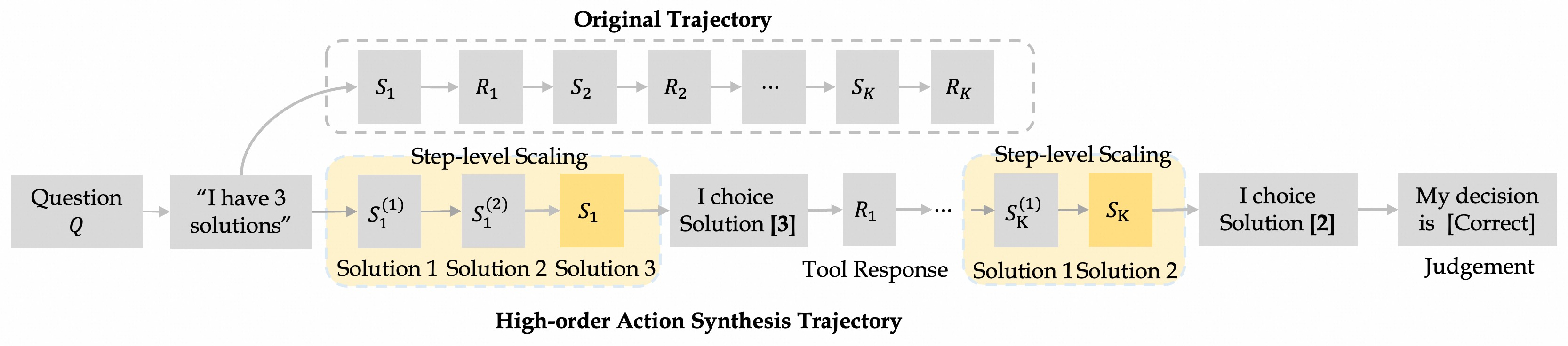
- Method 2: High-order Action Synthesis (HAS) — turning real agent attempts into decision lessons
- Real training often produces lots of partial or imperfect “trajectories” (records of step-by-step actions). Instead of throwing them away, the authors reuse them smartly.
- At each step in a trajectory, they generate several reasonable alternative options (like a choose-your-own-adventure). They don’t run these options; they just write them down.
- They then package each step as: context → multiple options → pick one → see the real outcome → mark if the overall attempt eventually succeeded or not.
- This trains the model to make better decisions at each step, not just to copy entire past trajectories.
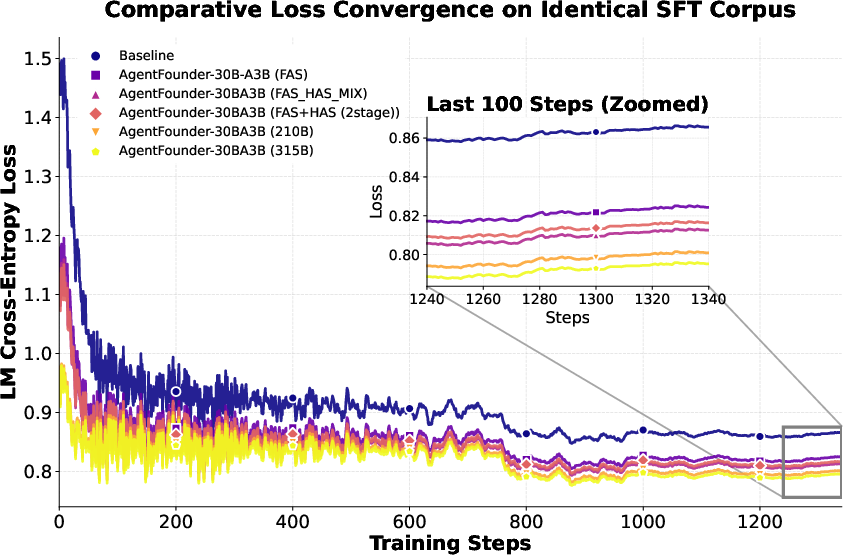
- Post-training (briefly)
- After Agentic CPT, they still do standard fine-tuning (SFT) with different data mixes to polish behavior.
- Tools used during evaluation (not during offline data-building)
- Search, Visit (read web pages), Google Scholar (papers), Python (code), File Parser. These simulate real agent workflows.
4. What did they find, and why is it important?
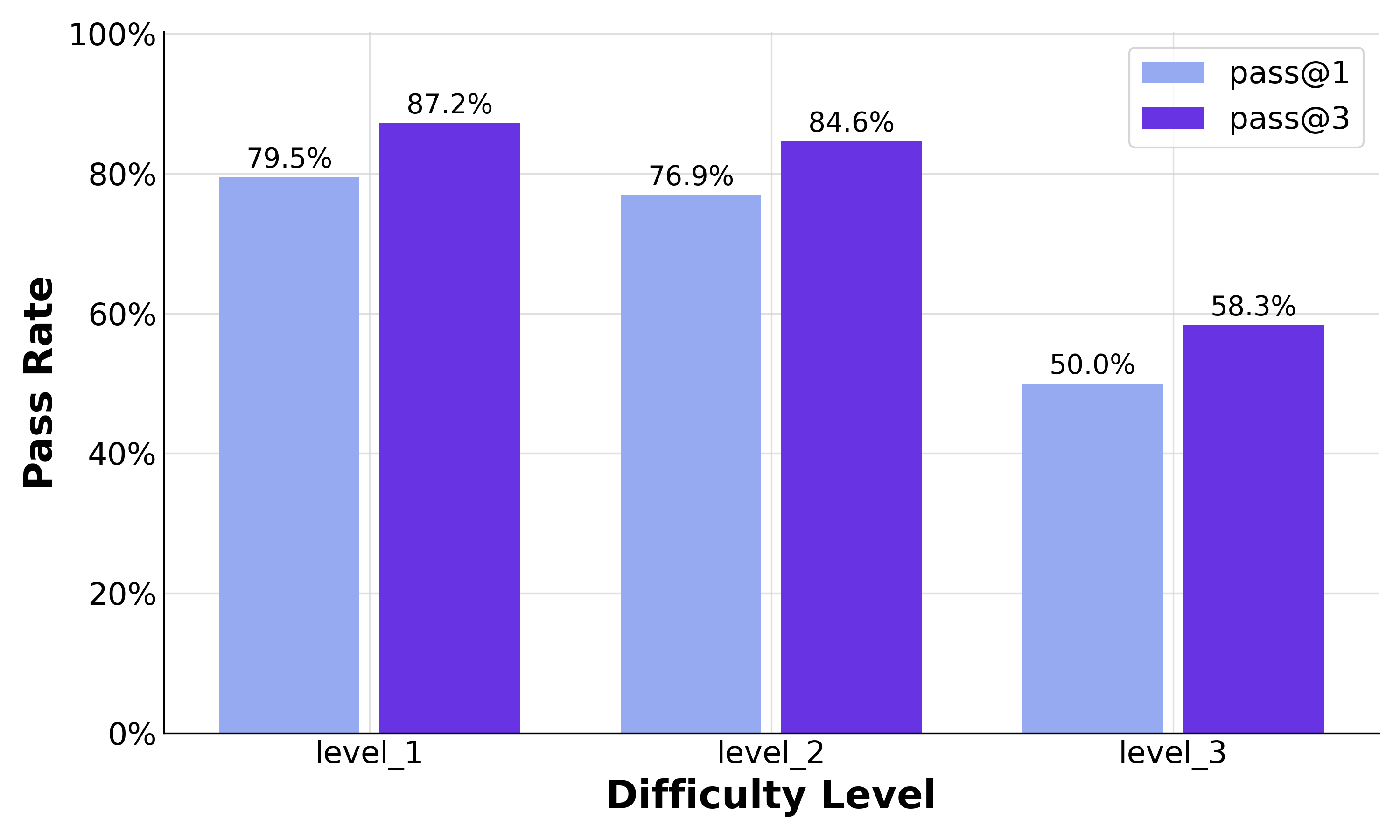
Main results (in plain English):
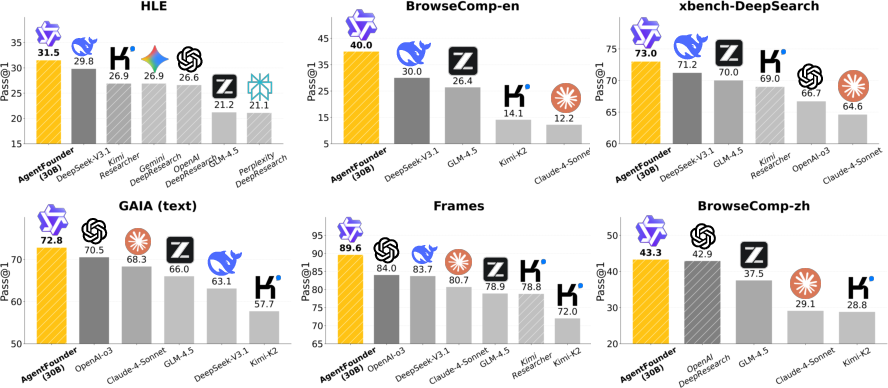
- Their 30B-parameter model, AgentFounder-30B, reached state-of-the-art results on many benchmarks for web research and reasoning:
- BrowseComp-en: 39.9% (very strong for open-source)
- BrowseComp-zh: 43.3%
- GAIA (text-only): 72.8%
- HLE (Humanity’s Last Exam): 31.5% Pass@1
- Xbench-DeepSearch: 73.0%
- AcademicBrowse: 75.3%
- Frames: 89.6%
- On several tests, it beats all other open-source agents and even rivals or surpasses some commercial systems.
- It still uses tools well (search, code, etc.), showing it didn’t lose general abilities.
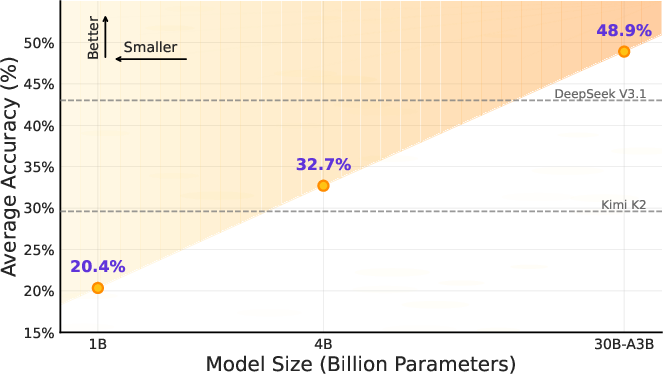
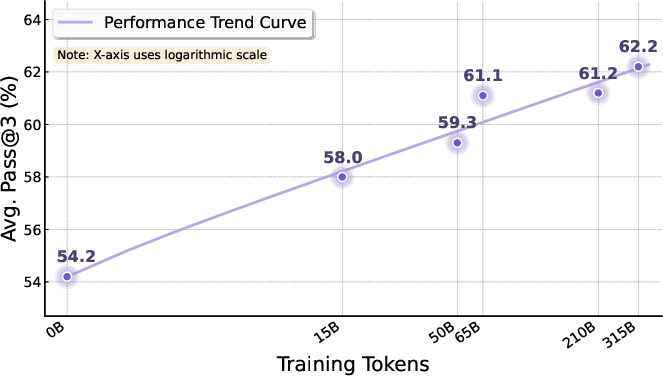
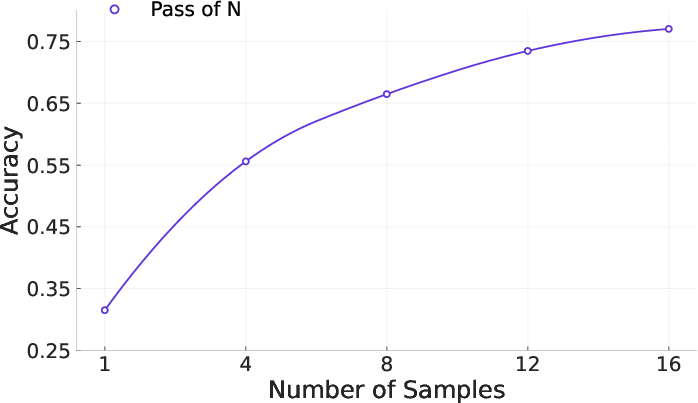
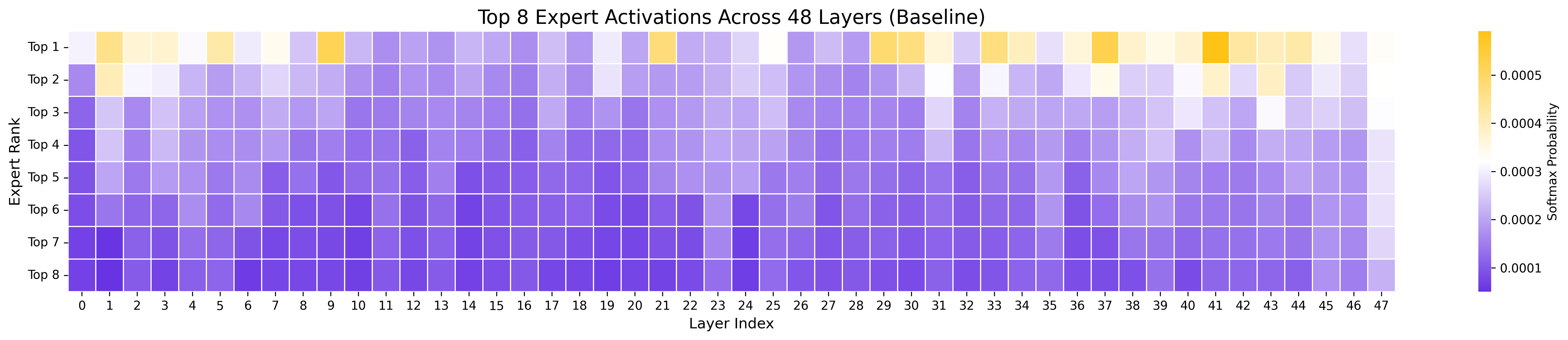
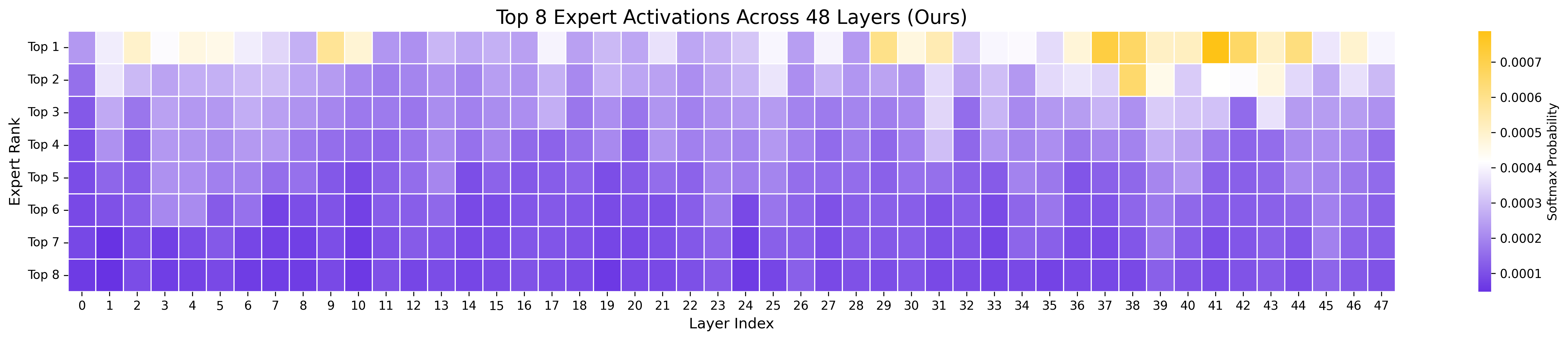
- Scaling helps: More agentic CPT data generally led to steady improvements (a “scaling law” trend).
- One gap: On the Chinese BrowseComp test, it’s strong but not top (likely due to less Chinese data and search tool biases).
Why it matters:
- The bottleneck wasn’t just post-training; it was starting from models that weren’t “agent-shaped.”
- By adding Agentic CPT, the model enters post-training already good at planning, reasoning, and tool-thinking, making later fine-tuning easier and more effective.
- Their offline data methods (FAS/HAS) avoid costly APIs, so the approach is scalable and practical.
Note on “Pass@1”: This is the percent of questions the model gets right on its first try.
5. Why is this important? What could it lead to?
- Better research assistants: Models can plan, search, read, reason, and write trustworthy answers for complex tasks (from school research to expert-level reports).
- Safer and more reliable agents: Step-by-step decision training helps agents stay consistent even when the web is noisy or misleading.
- Cheaper training: Creating huge, useful datasets without online API calls could help many teams build strong agents.
- A new blueprint: Agentic CPT could become a standard middle stage for training future agents—like giving them a “driver’s ed” course before they hit real roads.
In short, the paper shows that if you first teach a model to “think and act like an agent” through large-scale, offline practice, it becomes much better at real-world research tasks later. This could speed up progress toward helpful, trustworthy, general-purpose AI agents.
Knowledge Gaps
Below is a concise, action-oriented list of knowledge gaps, limitations, and open questions left unresolved by the paper; each item is specific to enable follow-up research.
- Data provenance and contamination: No audit demonstrating that synthesized questions or reused trajectories do not overlap with evaluation sets (e.g., BrowseComp, GAIA), leaving leakage risks and the true generalization of gains uncertain.
- LLM-as-judge reliability: The rejection sampling and knowledge-alignment verification rely on an LLM judge, but there is no calibration against human labels or external verifiers, nor sensitivity analysis to judge choice, prompting, or thresholds.
- Circularity and bias propagation: Both data synthesis (FAS/HAS) and judging are done by LLMs, raising risks of style overfitting and bias reinforcement; no experiments quantify how this affects downstream robustness or diversity of reasoning.
- First-step quality hypothesis: The claim that first-step planning quality correlates with final success is not empirically validated (no correlation statistics, causal tests, or ablations showing performance impact when perturbing first steps).
- Step-level credit assignment: HAS labels “correct/incorrect” using only trajectory-level success J, not per-step counterfactual outcomes; it remains unclear whether the method teaches causally effective decisions versus merely imitating the original path.
- Option-set construction in HAS: Alternative actions per step are generated without tool execution; there is no evidence these options are feasible or discriminative in real environments, nor evaluation of how N (number of options) or their diversity impacts learning.
- Decision tokenization artifact: The “I will choose option n_k” pattern may teach positional selection rather than reasoning-based choice; no tests compare with formats that force semantic justification or pairwise preference modeling.
- Offline tool-free synthesis–online tool gap: FAS/HAS never execute tools during data generation; the mismatch to real tool latency, failures, HTML variability, and rate limits is unmeasured and may limit transfer to deployment conditions.
- Tool robustness and security: No systematic evaluation of prompt injection, malicious content, CAPTCHA, robots.txt, redirections, or adversarial pages; SEAL-0 coverage is narrow and does not reflect diverse, realistic web threats.
- Faithfulness and citation integrity: Benchmarks emphasize Pass@1; there is no audit of citation correctness, quote-level fidelity, or source attribution standards for long-form outputs (e.g., DeepResearch Bench).
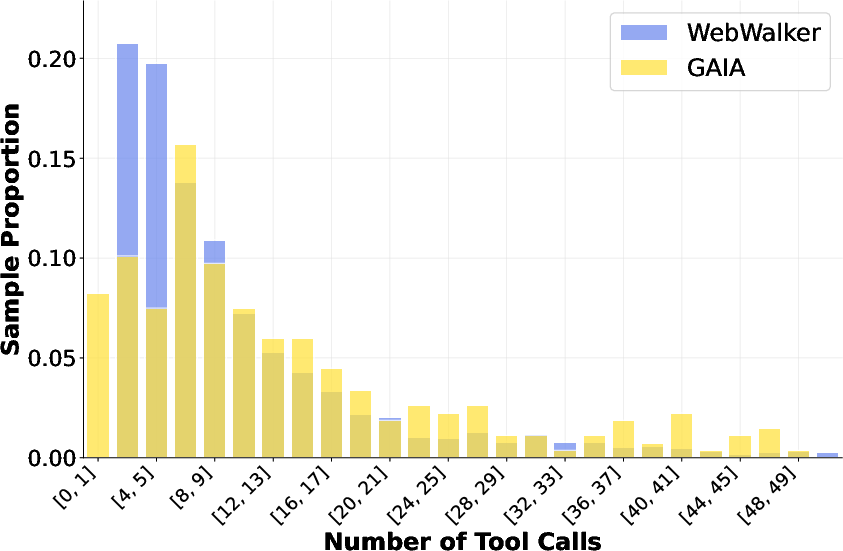
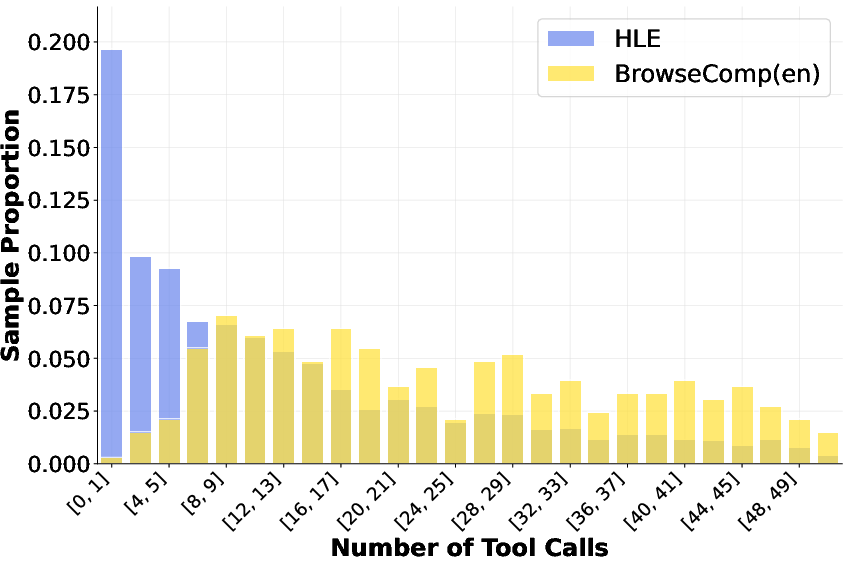
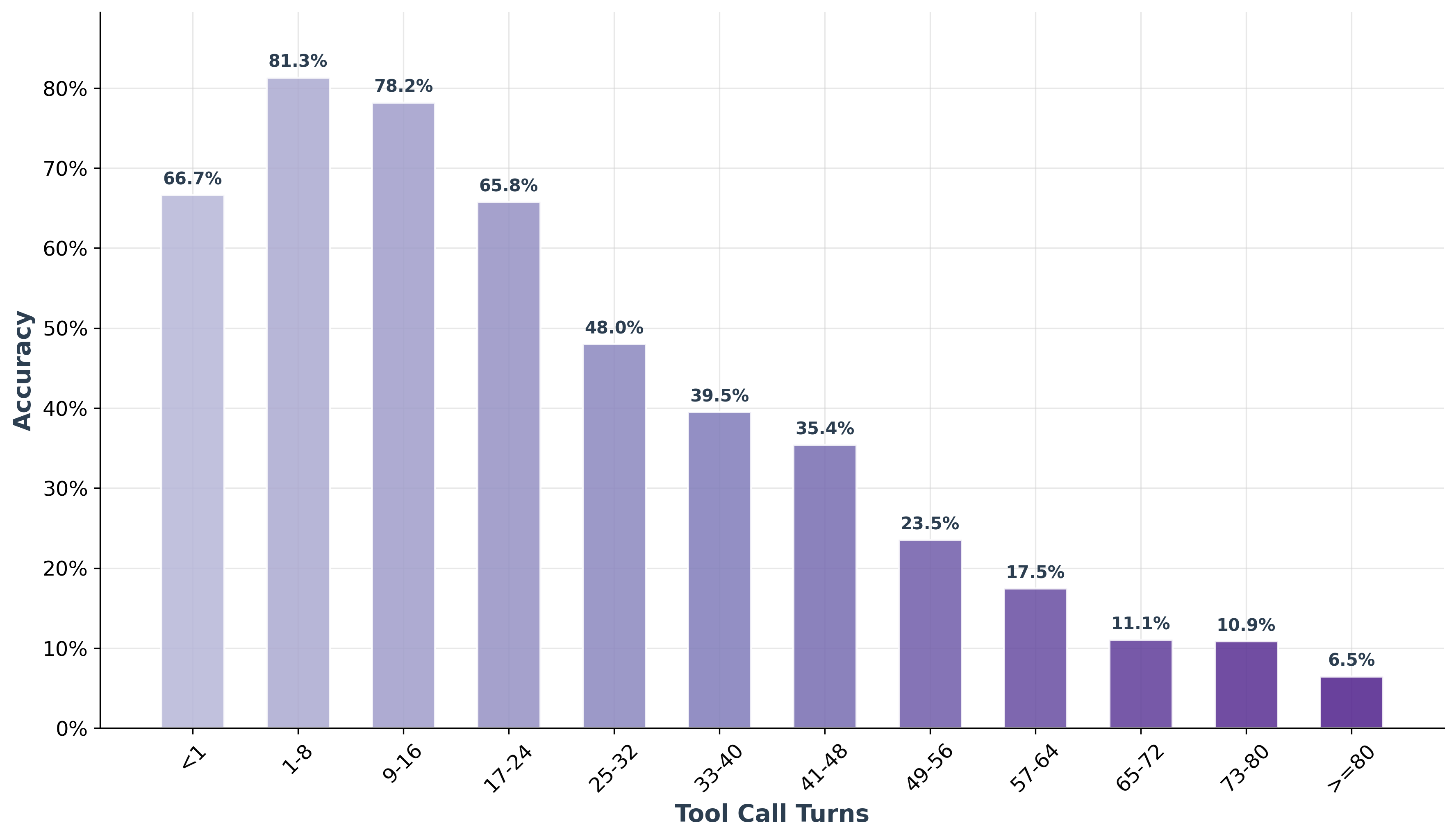
- Efficiency and cost: The agent allows up to 128 tool calls but provides no analysis of efficiency, latency, or cost-performance trade-offs; no comparison under constrained budgets typical of real deployments.
- Multilingual generalization: Performance drops on BrowseComp-zh are noted, but there is no systematic multilingual evaluation (beyond Chinese), data balancing strategy, or analysis of search engine bias effects across languages/scripts.
- Temporal robustness: No time-split evaluation or “freshness” analysis to test resilience to news drift and changing web content; unclear how CPT and memory construction handle outdated or evolving facts.
- Long-context utilization: While Stage 2 trains with 128K context, there is no targeted evaluation isolating long-horizon planning or context utilization (e.g., controlled tasks with required context lengths), nor ablations on context-window size.
- Scaling laws claims: The paper mentions “promising scaling law behaviors” but provides no explicit scaling exponents, fit quality, or disentanglement of model size vs. data volume vs. context length contributions.
- FAS vs. HAS attribution: RQ4 is posed, but there is no clear, controlled ablation quantifying the marginal gains of FAS versus HAS across benchmarks and data sizes, nor how their mixture ratios affect performance.
- Post-training paradigm generality: The paper evaluates SFT variants (A/B/C), but does not systematically test RL or preference-based optimization pipelines on the Agentic CPT base to substantiate claims of broad adaptability.
- Agentic alignment measurement: “Agentic alignment” is conceptually defined but not operationalized as a metric; no benchmark directly measures alignment to expert trajectories, recovery from tool failures, or consistency under environment shifts.
- Safety and misuse: No evaluation of potentially harmful tool use, privacy violations (PII exposure), or compliance under risky tasks; no alignment safeguards or red-teaming results are reported.
- Reusability of suboptimal trajectories: HAS reuses “discarded” trajectories, but there is no analysis of how noise or systematic errors in these trajectories affect learning, nor of denoising strategies beyond final J.
- General tool-use transfer: Only five core tools are used; zero-shot transfer to unseen tools, API schema variation, or domain-specific toolchains (e.g., finance, bioinformatics) remains untested.
- Domain transfer beyond web research: Claims of general-purpose agent potential are not supported by evaluations in code-heavy tasks, robotics, interactive APIs with side effects, or multi-modal retrieval.
- Mechanistic understanding: No interpretability or representation-level analysis demonstrates that CPT instills durable “agentic inductive biases” distinct from SFT/RL effects; the causal mechanism remains speculative.
- Catastrophic forgetting and general NLP abilities: Large-scale Agentic CPT may affect general instruction-following, safety, and language understanding; there is no broad-spectrum NLP evaluation post-CPT to assess regressions.
- Reproducibility and openness: Critical details on data mixture ratios, filtering pipelines, prompts for synthesis/judging, and compute budgets are insufficient for exact replication; code/data release status is unclear.
- Ethical/legal data use: The use of CommonCrawl, historical tool logs, and discarded trajectories raises licensing and consent questions; there is no discussion of dataset licensing compliance, PII redaction, or data governance.
- Benchmark comparability: Many baselines use reported scores under differing toolsets/environments; the extent to which results are comparable under a standardized sandbox (identical tools, quotas, and time) is not verified.
- Robust evaluation of reasoning structure: Beyond accuracy, there is no probe of reasoning diversity, brittleness to paraphrase, or performance under controlled perturbations (e.g., misleading distractors, partial evidence).
- Human evaluation: For long-form outputs (e.g., research reports), there is no human study on coherence, coverage, credibility, or usefulness, limiting claims about practical research assistance quality.
Collections
Sign up for free to add this paper to one or more collections.

