Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Abstract: We introduce Youtu-LLM, a lightweight yet powerful LLM that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Youtu-LLM, a lightweight but powerful AI LLM with around 2 billion “parameters” (think of parameters as tiny knobs the model adjusts while learning). The big idea is to make a small model that can think, plan, and use tools like a smart helper or “agent,” without needing the huge size and cost of the biggest AI models. It’s designed to handle very long inputs (like book-length documents) and to solve complex tasks in math, coding, research, and everyday tool use.
What questions does the paper ask?
The authors ask a simple but important question: Can a small AI model be trained to plan, reason, and act like a helpful agent—without just copying bigger models? They focus on whether strong “agentic” skills (planning steps, checking work, using tools, reflecting on mistakes) can be built into a compact model during pre-training, instead of bolted on later.
How did they build and train the model?
A smaller model with a long memory
- The model uses a specialized attention design (called “Multi-Latent Attention”) that helps it remember and reason over very long inputs—up to 128,000 tokens (roughly a long book).
- It also uses a vocabulary tailored for STEM (science, technology, engineering, math) and coding, so it reads and writes math and code more efficiently.
- Translation: it’s like giving the model a bigger notebook and the right technical dictionary while keeping the computer memory and speed requirements small.
A step-by-step training curriculum
The team didn’t just fine-tune a small model to mimic big models. They pre-trained it “from scratch” on a huge amount of text—about 10–11 trillion tokens—using a curriculum that gradually shifts from simple to complex:
- Start with general commonsense language.
- Move to more challenging STEM topics and coding.
- Add “agentic” tasks that teach planning, tool use, and reflection.
Think of it like school: basic reading first, then advanced science and math, and finally practice doing full projects with planning and problem-solving.
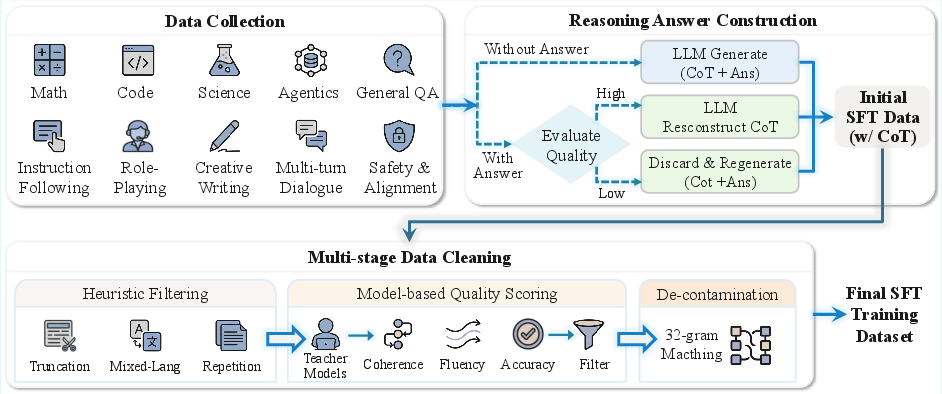
To keep the training data high-quality, they:
- Filtered out bad, repeated, or unsafe content.
- Used classifiers to label the topic and quality of text and kept only high-scoring data.
- De-duplicated and checked to avoid contamination from test sets.
Teaching with “trajectories” (step-by-step how-to data)
Besides regular text, they built about 200 billion tokens of special “trajectory” data. A trajectory is like a diary of how to solve a problem: the plan, the actions, the mistakes, the fixes, and the final answer. This helps the model learn not just what the answer is, but how to get there.
They created several kinds of trajectory data:
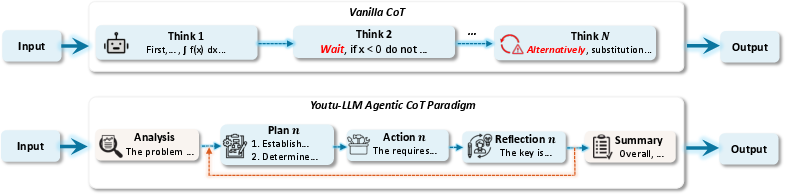
- Agentic-CoT (Chain of Thought with structure): Reasoning broken into clear phases:
- Analysis → Plan → Action → Reflection → Summary
- Math: Problems and solutions that show planning, calculation, checking, and explanation, covering skills from basic computation to higher-level reasoning.
- Code: Software tasks that include searching a codebase, editing files, running tests, fixing bugs, and learning from failures.
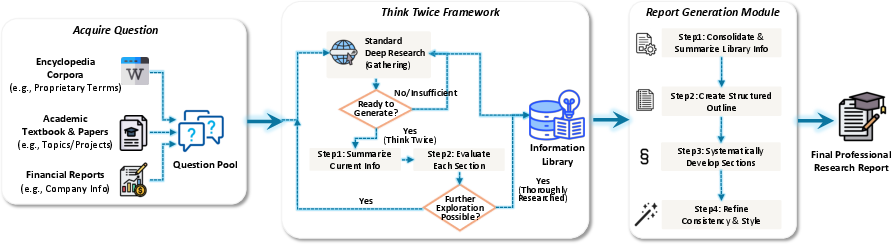
- Deep Research: Web-style research tasks, both:
- Closed-ended (multi-hop Q&A with checkable answers).
- Open-ended (writing reports). They used two ways:
- Forward: start with a question and research outward.
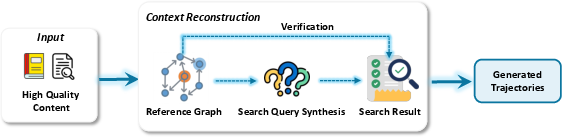
- Inverse: start from a trustworthy document (like a paper) and reconstruct the search path back to the sources.
- Tool-use and Planning: Multi-turn conversations where the model calls tools (like search, databases, spreadsheets) in the right order, with realistic complications (ambiguous requests, typos, etc.).
In short, the model doesn’t just see final answers—it practices the whole problem-solving process.
What did they find?
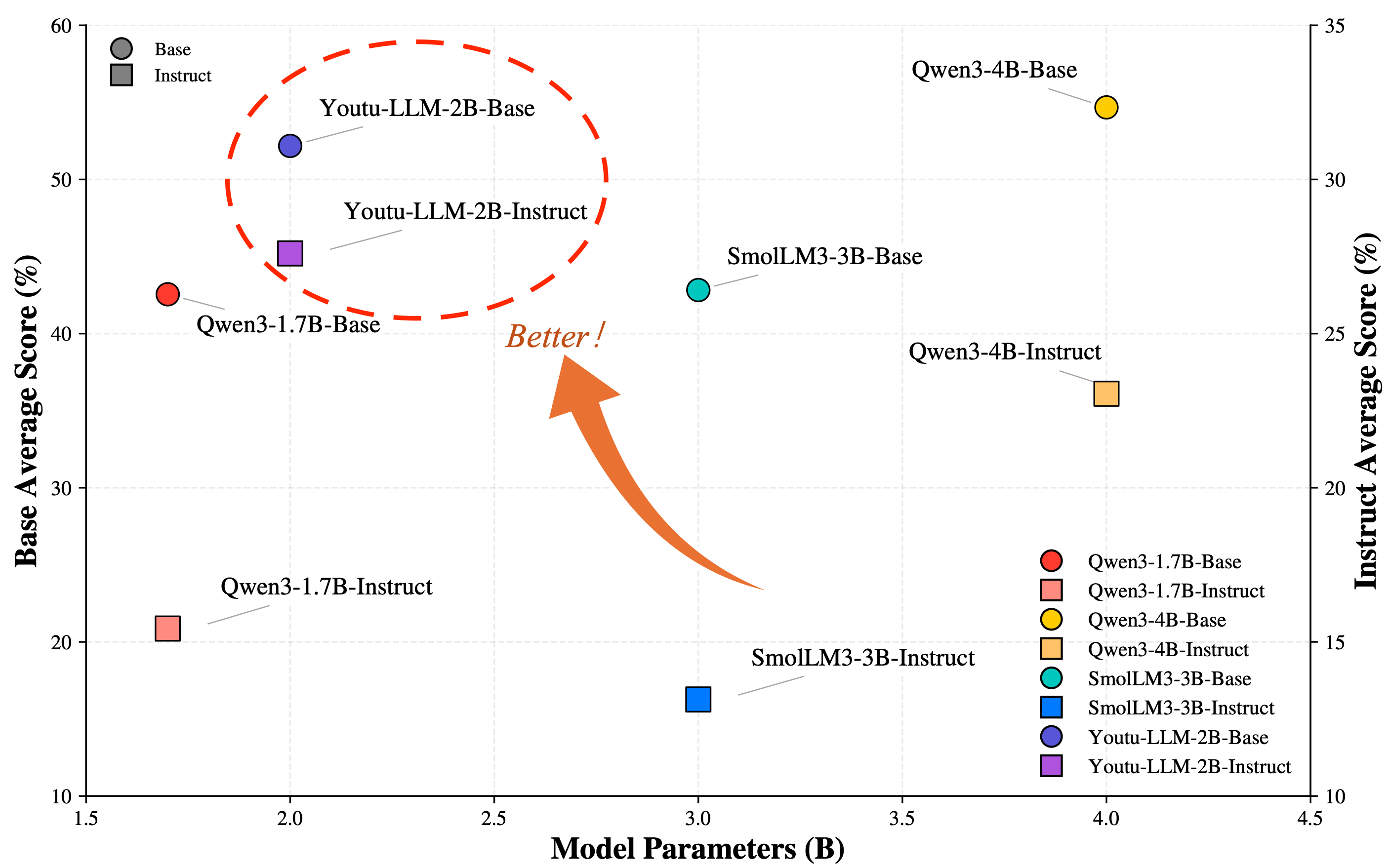
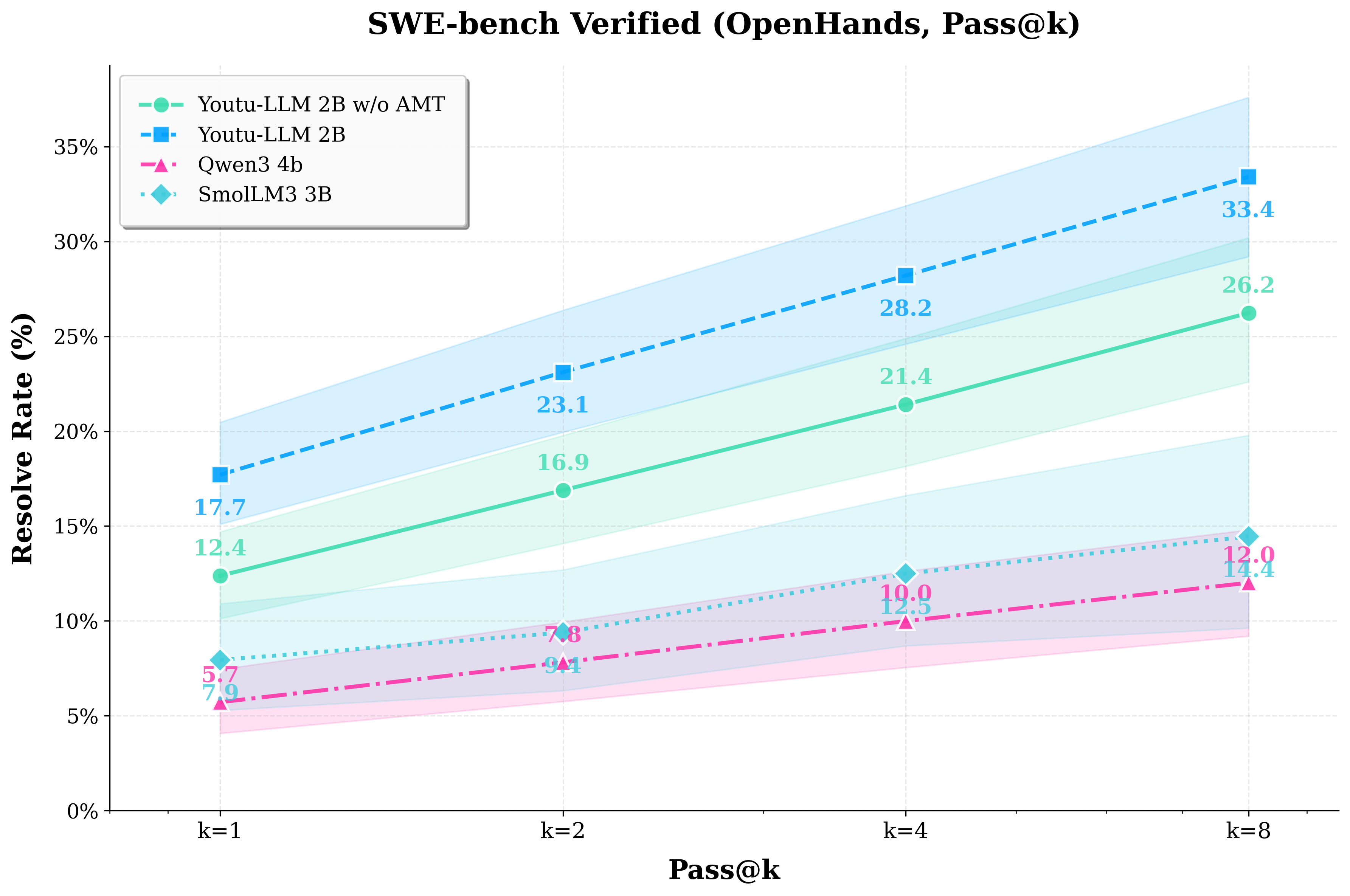
- For its size (under 2B parameters), Youtu-LLM reaches state-of-the-art results among small models.
- It scores competitively with larger models on general benchmarks.
- It clearly outperforms other small models on “agent” tasks that require planning, using tools, and reflecting.
- The main insight: If you inject agent-like learning signals early (during pre-training) and at scale, even small models can develop strong built-in agent skills.
Why this matters: It shows that smart training and data design can beat raw size—small models don’t have to be weak.
Why does this matter?
- Faster and cheaper: Small models are much easier to run on regular computers, phones, or edge devices. That means lower cost, less energy use, and broader access.
- Practical agents: You can get on-device helpers that plan, code, research, and use tools—without relying on massive cloud models.
- Better training approach: The paper suggests a shift in how we teach models—focus on high-quality, structured “how-to” data and a clear curriculum, not just bigger size or shallow imitation.
- Real-world impact: This can improve tutoring in math, automated coding assistance, deep web research for reports, and many everyday tasks that need planning and careful checking.
In simple terms: Youtu-LLM shows that a smaller, well-taught model can act like a capable, thoughtful assistant—making advanced AI more affordable, responsible, and widely useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues, missing details, and open questions that future researchers could act on.
- Architecture transparency: The paper does not specify the Multi-Latent Attention (MLA) mechanism, positional encoding/scaling strategy, attention pattern, vocabulary size, or embedding/FFN dimensions, making it hard to reproduce and assess why MLA yields long-context efficiency at 2B parameters.
- Long-context efficiency and stability: Claims of a 128k context window and “minimal memory footprint” are not supported with training/inference memory usage, throughput, latency, or stability metrics across varying context lengths; no comparison to baselines (e.g., sliding-window, blockwise/segment attention, or RoPE scaling variants).
- Long-context robustness: No evaluation on standardized long-context benchmarks (e.g., L-Eval, LongBench, Needle-in-a-Haystack variants, multi-document QA) to quantify degradation and state-tracking across 32k–128k tokens.
- STEM-oriented tokenizer effects: The “novel STEM-oriented vocabulary” is not analyzed for compression gains, error rates, or tokenization artifacts across domains/languages; missing ablations showing its contribution vs a standard tokenizer on math, code, and general tasks.
- Compute budget and environmental cost: Training on ~11T tokens (plus 200B agentic trajectories) is substantial; the paper does not report training FLOPs, hardware configuration, energy consumption, or cost—undermining claims of “lightweight practicality.”
- Curriculum schedule specifics: The “Commonsense–STEM–Agent” multi-stage strategy lacks concrete mixing ratios, stage lengths, sampling schedules, and annealing details; there are no ablations isolating the effect of stage order or mix.
- Agentic mid-training data mix: The proportioning of agentic data types (Agentic-CoT, Math, Code, Deep Research, Tool-use) during pre-training is unspecified; open question: what mix/ordering optimizes agentic performance vs generalization?
- Distillation vs from-scratch comparison: The claim that pre-training from scratch is superior to distillation lacks controlled comparisons to strong distilled baselines at 2B; missing experiments quantifying gains attributable to pre-training strategy.
- Effect of failed trajectories: While failed trajectories are reused, there are no ablations quantifying their net effect, optimal inclusion ratios, or mitigation strategies for error propagation across domains (code, DR, tool-use).
- Behavioral cloning vs exploration: No exploration of offline RL or DAgger-like corrections beyond single-step branching; open question: do modest on-policy updates or model-based planning improve agentic robustness over pure BC?
- Verification of synthetic data: Heavy reliance on LLM-generated and LLM-judged data introduces bias and hallucination risks; the paper lacks human-verified samples, inter-rater agreement, or audit results quantifying label/verification reliability.
- Data contamination and test leakage: Decontamination is described for STEM/code corpora, but not for the agentic trajectory datasets; the paper does not report overlap statistics with downstream benchmarks (e.g., SWE-bench, AgentBench, WebArena, math sets).
- Benchmark coverage and methodology: Figures reference “agentic benchmarks,” but the paper does not list the exact benchmarks, task versions, scoring scripts, or evaluation protocols; no statistical significance, variance, or seed sensitivity is reported.
- Generalization across scaffolds and tools: Code trajectories span multiple scaffolds but it’s unclear if performance depends on tool wrappers; open question: does Youtu-LLM generalize to truly unseen scaffolds/APIs or to dynamic tool schema changes?
- Verification of tool-use execution: Tool-use trajectories rely on adversarial User/Assistant synthesis with limited mention of actual API execution or sandboxing; the paper lacks a systematic verification pipeline showing tools were invoked with correct parameters and outputs.
- Open-ended DR quality assessment: For forward-generated reports, there is no rigorous evaluation framework (domain expert review, rubric, factuality/coverage metrics, or reference-based measures) to validate completeness and correctness; inverse synthesis fidelity is not quantified.
- Cross-domain citation reconstruction: The inverse DR pipeline exploits citation graphs in academia/legal domains; open question: can the approach generalize to domains lacking explicit citation structure (e.g., news, business intelligence, biomedical web content)?
- Atomic ability mapping validation: The math “atomic ability” taxonomy is proposed, but there is no diagnostic evaluation (probing tasks, capability-specific scores) verifying that training improved each atomic skill, nor analyses of inter-skill transfer.
- Agentic-CoT tag utility: The structured tags (<analysis>, <plan>, <action>, <reflection>, <summary>) are introduced without ablation showing they outperform vanilla CoT or other structured formats; dependence on tags at inference is unclear (are tags required?).
- Multilingual coverage: Training emphasizes English and Chinese; the paper does not report performance or coverage for other languages, nor whether the STEM-oriented tokenizer harms multilingual tokenization efficiency.
- Safety, alignment, and misuse: There is no discussion of instruction tuning, guardrails, or safety evaluations (prompt injection resistance, tool-use risk mitigation, jailbreak robustness), which is critical for agentic deployment.
- Reliability in interactive environments: The paper focuses on offline trajectories; open question: how stable are planning and reflection behaviors under non-stationary environments, partial observability, or adversarial web/UI changes?
- Real-world deployment constraints: Claims of suitability for “latency-sensitive” settings lack empirical measurements (end-to-end agent episode latency, memory per tool call, batching strategies) on commodity hardware.
- Availability and reproducibility: It is unclear whether the full training recipe, filters/classifiers, and agentic datasets (or a subset) will be released; without data and code, reproducibility and external validation remain limited.
- Token-per-parameter regime analysis: Training a 1.96B model on ≥10T tokens is extreme; the paper does not analyze under/overfitting dynamics, catastrophic forgetting risk during mid-training, or scaling laws guiding optimal token budgets for small models.
- Robustness to distribution shifts: There is no evaluation under shifts (new domains, unseen APIs, repository styles, math problem types) or stress tests (noisy inputs, ambiguous instructions, conflicting sources) to quantify agentic resilience.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities of Youtu-LLM (1.96B) and its data/methods, leveraging its 128k context, native planning/reflection, tool-use, and STEM/math/coding strengths.
- Software engineering “CI Patch Bot” for repo triage and repair (Sector: software)
- What it does: Localize failing tests, propose minimal patches, and auto-validate fixes in CI using bash-first toolflows, file_editor/sed edits, and targeted tests—aligned with the paper’s atomic coding capabilities and end-to-end trajectories.
- Potential tools/products/workflows: GitHub/GitLab apps; pre-commit bots; “branch-and-test” workflow mirroring the paper’s critical action branching for Editing/Testing; SWE-gym-style sandboxes for validation.
- Assumptions/dependencies: Access to build/test environments; adequate test coverage; security sandboxing; repository languages supported; governance on write-access.
- Codebase exploration and fault localization assistant (Sector: software)
- What it does: Repository-wide search/navigation, variable/function tracing, and environment comprehension to speed up bug triage and onboarding.
- Potential tools/products/workflows: IDE extensions (VS Code/JetBrains) for “proactive exploration and localization,” grep/ctags/LSP integrations, repository-level embeddings optional.
- Assumptions/dependencies: Repo graph/indexing; permissioned code access; scalable file-system tooling.
- Data science “Notebook Agent” (Sector: software/data)
- What it does: Plan–execute–reflect loops to clean data, write analysis code, run cells, interpret errors, and revise—consistent with the agentic code trajectories and self-reflection capabilities.
- Potential tools/products/workflows: Jupyter plugin; pandas/matplotlib tool adapters; bash/conda env control; dataset cards auto-generation.
- Assumptions/dependencies: Containerized compute; data privacy constraints; deterministic environment management.
- Deep research assistant for analysts and investigators (Sector: finance, policy, legal, enterprise research)
- What it does: Multi-hop QA and report generation with “think twice” breadth checks; closed-ended verification with citations; open-ended synthesis using forward and inverse trajectory patterns.
- Potential tools/products/workflows: “Deep Research Workbench” with web search, browser, citation extraction, and fact-check modules; inverse synthesis for citation-grounded dossiers.
- Assumptions/dependencies: Reliable search APIs; content licensing; robust citation verification; up-to-date knowledge sources.
- Long-context document analysis and state tracking (Sector: legal, compliance, enterprise)
- What it does: Ingest and reason over entire contracts/policies/procurement packages (up to 128k tokens), track definitions and obligations, and produce structured summaries and checklists.
- Potential tools/products/workflows: Contract assistant; compliance checklist generator; multi-document threading with long-context windows to reduce RAG complexity.
- Assumptions/dependencies: Efficient long-context inference (KV cache optimization); data security and access controls; domain-specific templates.
- STEM tutoring and assessment with Agentic-CoT (Sector: education)
- What it does: Stepwise coaching with Analysis–Plan–Action–Reflection–Summary; covers “atomic abilities” in math for concept mastery, computation, theorem application, and error diagnosis.
- Potential tools/products/workflows: “STEM Tutor” apps; autograders; practice generators that tag steps with Agentic-CoT structure; competition-level reasoning drills.
- Assumptions/dependencies: Human-in-the-loop oversight for correctness; curriculum alignment; content safety for minors.
- Customer support agent with tool-use (Sector: services/CRM)
- What it does: Plan–act–reflect loops for retrieving tickets, updating CRM, scheduling, and knowledge lookup via MCP/APIs; small model keeps latency low and costs manageable.
- Potential tools/products/workflows: “Edge Agent SDK” with prebuilt CRM/email/calendar connectors; workflow orchestration via a tool graph.
- Assumptions/dependencies: Tool/API coverage and authentication; PII handling; audit logging; fallback escalation paths.
- Literature triage and citation checking assistant (Sector: academia)
- What it does: Reverse search from a draft/paper to reconstruct and verify citation paths (inverse trajectory synthesis), flag weak references, and suggest replacements.
- Potential tools/products/workflows: “Citation Verifier” for institutional repositories; search on open corpora (Crossref/Semantic Scholar).
- Assumptions/dependencies: Access to metadata/full text; paywall restrictions; correct citation graph extraction.
- Data quality filtering and domain balancing pipeline (Sector: AI/ML)
- What it does: Reproduce the paper’s domain/quality classifier to score/filter corpora and upsample critical domains (STEM/code) for better sample efficiency.
- Potential tools/products/workflows: “Corpus Filter & Curator” using small LLM classifiers; MinHash/LSH dedupe; Aho–Corasick decontamination.
- Assumptions/dependencies: Labeled seed set with high agreement; robust decontamination lists; scalable data infra.
- Agentic-CoT prompt and logging standard (Sector: software, education, research)
- What it does: Adopt the five-phase XML-style schema to standardize plans, actions, reflections, and summaries for auditability and training data capture.
- Potential tools/products/workflows: “Agentic-CoT SDK” for apps to log trajectories; analytics for failure modes; replay and critique tooling.
- Assumptions/dependencies: App integration to capture steps; privacy terms; developers adopt the schema.
- Trajectory-based training and evaluation practices (Sector: AI/ML)
- What it does: Use branching around critical actions to reuse failed trajectories safely; add trajectory-level critiques; scale code/research trajectories for mid-training.
- Potential tools/products/workflows: “Trajectory Studio” to generate/verify/branch trajectories; plug into continual pre-training or alignment.
- Assumptions/dependencies: Sandboxed environments; compute budget; guardrails for failure propagation.
- Personal knowledge management on-device (Sector: consumer/daily life)
- What it does: Summarize, link, and reflect over long email threads, notes, and PDFs within 128k context; plan todos and follow-up actions.
- Potential tools/products/workflows: Desktop/mobile assistants with offline mode; calendar/task integrations.
- Assumptions/dependencies: Efficient quantization/inference on laptops/edge GPUs; local indexing; user consent.
- Spreadsheet and SQL tool-use agent (Sector: daily life, SMB operations)
- What it does: Text2SQL, table cleanup, and multi-step spreadsheet operations using tool graphs with dependency chains.
- Potential tools/products/workflows: “ExcelAgent” add-in; BI connectors with verifiable queries and rollbacks.
- Assumptions/dependencies: Safe execution sandboxes; schema discovery; human review before commits.
Long-Term Applications
These opportunities are plausible extensions that require further research, scaling, domain adaptation, or systems integration beyond the paper’s current scope.
- Autonomous software maintenance at scale (Sector: software)
- What it could do: Continuous repo health monitoring, multi-issue triage, prioritized planning, large refactors with test generation and migration across repositories.
- Potential tools/products/workflows: “AutoMaintainer” orchestrating agent swarms; cross-repo dependency graphs; self-play for patch planning.
- Assumptions/dependencies: Reliable test or spec oracles; sophisticated change impact analysis; enterprise approval workflows.
- Embodied agents for robotics and IoT (Sector: robotics, manufacturing)
- What it could do: Plan–act–reflect loops for task decomposition and tool-use paired with perception/action; long-horizon state tracking for assembly or inspection.
- Potential tools/products/workflows: Edge-deployable controller with MLA-based long-context memory; ROS/MQTT adapters; safety layers.
- Assumptions/dependencies: Robust grounding to sensors/actuators; real-time constraints; safety certification; sim-to-real transfer.
- Clinical evidence synthesis and workload automation (Sector: healthcare)
- What it could do: Deep research across guidelines, trials, and patient records with verifiable citations; tool-use for EHR queries, scheduling, and registry updates.
- Potential tools/products/workflows: “Clinical Research Copilot” and “Care Workflow Agent” with audit trails and structured outputs.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); medical safety validation; domain fine-tuning; bias mitigation.
- Autonomous due diligence and risk intelligence (Sector: finance, compliance)
- What it could do: Multi-hop reports on entities/supply chains with inverse synthesis for citation-backed findings; scenario modeling in notebooks.
- Potential tools/products/workflows: “Risk Research Agent” with KYC/AML tool adapters; report templates; change detection alerts.
- Assumptions/dependencies: High-quality, licensed data sources; robust factuality controls; model governance and auditability.
- At-scale personalized STEM education (Sector: education)
- What it could do: Mastery-based paths with atomic ability diagnostics; scaffolded planning and reflection; auto-generated assessments and tutoring dialogs.
- Potential tools/products/workflows: “Atomic Skills Tutor” platform; teacher dashboards; content marketplaces tagged with Agentic-CoT phases.
- Assumptions/dependencies: Longitudinal outcome studies; accessibility and fairness; district-level integrations; content curation.
- Scientific discovery assistants (Sector: academia, R&D)
- What it could do: Plan literature searches, propose methods, set up code/data pipelines, and critique results with transparent trajectories and citations.
- Potential tools/products/workflows: “Discovery Agent” for lab notebooks; reproducibility checkers; inverse-synthesis over high-impact papers.
- Assumptions/dependencies: Domain pretraining; lab tool integrations; reproducibility oracles; IP considerations.
- Policy analysis and regulatory drafting with provenance (Sector: policy/government)
- What it could do: Synthesize stakeholder input, precedent, and evidence into draft language with explicit, inspectable analysis–plan–action–reflection logs.
- Potential tools/products/workflows: “Policy Workbench” with public records search, citation graphs, and deliberation trails.
- Assumptions/dependencies: Public data access; transparency mandates; institutional review; mitigation of political/coverage bias.
- Tool graph ecosystems and marketplaces (Sector: software platforms)
- What it could do: Standardized dependency-aware tool graphs (APIs, MCPs, protocols) discoverable and composable by agents, with quality and safety ratings.
- Potential tools/products/workflows: “Tool Graph Registry” and validators; simulation-based verification; negative-sample expansion for robustness.
- Assumptions/dependencies: Interoperability standards; security/permissioning; reputation and versioning.
- Multilingual expansion and domain transfers (Sector: global enterprise)
- What it could do: Extend agentic pretraining beyond English/Chinese to low-resource languages and specialized verticals (law, pharma manufacturing).
- Potential tools/products/workflows: Curriculum schedules for language/domain mix; cross-lingual tool-use; translation-aware Agentic-CoT.
- Assumptions/dependencies: Data availability and decontamination; culturally appropriate evaluation; domain experts for verification.
- Retrieval-minimal long-context workflows (Sector: AI/ML, enterprise)
- What it could do: Use 128k native windows to reduce reliance on complex RAG stacks for many document-centric tasks, with simpler stateful sessions.
- Potential tools/products/workflows: “Long-Context Sessions” with KV cache paging; session memory governance; hybrid selective retrieval.
- Assumptions/dependencies: Memory/cost optimizations; latency constraints; persistence and privacy of long contexts.
- Safety, audit, and red-teaming of agentic systems (Sector: AI governance)
- What it could do: Use Agentic-CoT structure to systematically probe, log, and adjudicate risky plans/actions; trajectory-level critiques for safety tuning.
- Potential tools/products/workflows: “Agent Safety Evaluator” with step tagging, failure replay, and correction proposals.
- Assumptions/dependencies: Standardized metrics for agent safety; human oversight; secure logging infrastructure.
Notes on Cross-Cutting Assumptions and Dependencies
- Licensing and access: Use within the terms of the released models/datasets; verify commercial usage rights for tools and corpora.
- Compute and deployment: Achieving low-latency, long-context inference on edge or modest servers may require quantization, KV cache optimizations, and streaming attention.
- Tool/API availability: Agent utility depends on stable, authenticated access to enterprise tools, data lakes, search, and code execution sandboxes.
- Data privacy and security: Many high-value use cases are sensitive (EHRs, financial records); isolation, audit, and differential privacy may be required.
- Evaluation and reliability: Incorporate verifiable oracles (tests, citations, constraints) and human-in-the-loop for high-stakes decisions.
- Domain adaptation: For regulated or specialized domains, expect targeted fine-tuning and additional high-quality trajectory data aligned with domain norms.
Glossary
- 13-gram duplicate detection: A heuristic method that flags near-duplicate text by matching overlapping sequences of 13 tokens. "We included several heuristic rules such as 13-gram duplicate detection, toxicity scoring, and code keyword filtering."
- Action space: The set of all possible actions an agent can take in an environment. "pure behavioral cloning (BC) may lead to premature collapse of the action space"
- Agent framework: A structured software architecture for building and running autonomous agents. "most existing mathematical agents are adapted from general-purpose agent frameworks"
- Agentic benchmarks: Evaluation tasks designed to measure agent-like abilities such as planning, tool use, and reflection. "reasoning-oriented models have achieved phenomenal performance on challenging agentic benchmarks"
- Agentic-CoT: A structured chain-of-thought format decomposed into phases like Analysis, Plan, Action, Reflection, and Summary. "we propose a structured thinking paradigm called Agentic-CoT and construct a corresponding dataset."
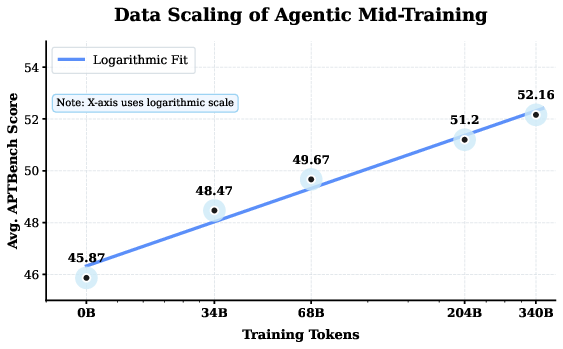
- Agentic mid-training: A dedicated training phase focused on agent behaviors (planning, reflection, tool-use) using curated trajectory data. "Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories"
- Agentic pre-training: Injecting agent-oriented signals early and systematically during pre-training to internalize agent capabilities. "agentic pre-training can unlock agent potential in lightweight LLMs"
- AhoâCorasick algorithm: A linear-time string-matching algorithm using a trie and failure links to find multiple patterns simultaneously. "we introduced the AhoâCorasick algorithm~\citep{aho1975efficient} to benchmark and decontaminate the STEM and code corpus"
- Annealing stage: A training phase where conditions (e.g., difficulty, distribution) are gradually adjusted to improve learning stability. "For trajectory synthesis, we apply problems used during the annealing stage as queries"
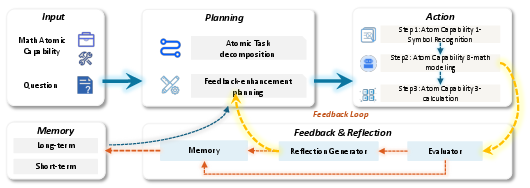
- Atomic ability taxonomy: A structured classification of minimal, irreducible skills that compose complex reasoning. "Atomic ability taxonomy for mathematical reasoning and its correspondence to agent modules."
- Atomic Thinking: A methodology that decomposes reasoning into independent atomic abilities and analyzes their interactions. "The Atomic Thinking \citep{kuang2025atomic} systematically decouples the atomic abilities involved in mathematical reasoning"
- Behavioral cloning (BC): Supervised imitation learning that copies expert trajectories; prone to action-space collapse without exploration. "pure behavioral cloning (BC) may lead to premature collapse of the action space"
- Chain-of-thought (CoT): Natural-language reasoning traces that make intermediate steps explicit. "including chain-of-thought (CoT)~\citep{wei2022chain}"
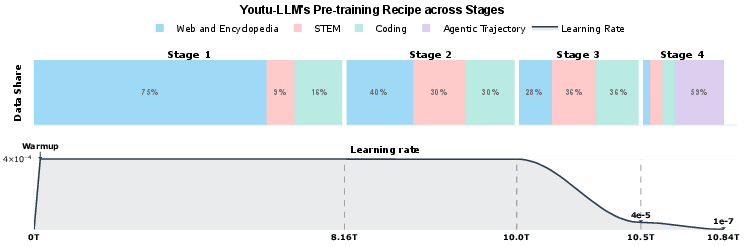
- Commonsense-STEM-Agent Curriculum: A multi-stage data curriculum that shifts from commonsense to STEM to agentic tasks to build cognitive skills. "Principled \"Commonsense-STEM-Agent\" Curriculum We curated a massive corpus of approximately 11T tokens"
- Context window: The maximum number of tokens a model can attend to in a single input. "Youtu-LLM supports a 128k context window."
- Continual pre-training: Ongoing pre-training on new or specialized data after initial pre-training to extend capabilities. "trajectory-based training and continual pre-training on structured interaction data have shown promise"
- Critical Actions: Key steps (e.g., Editing, Testing) that largely determine success or failure of a trajectory. "We identify Editing and Testing as Critical Actions that determine problem-solving success."
- Deep Research (DR): Autonomous, multi-step knowledge discovery involving search, verification, and synthesis into reports. "Deep Research (DR) has emerged as a pivotal application scenario for autonomous agents"
- Dense Multi-Latent Attention (MLA): An attention architecture that leverages multiple latent mechanisms within a dense model to support long-context reasoning efficiently. "Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary"
- Decontamination: Removal of test-set or benchmark content from training data to prevent evaluation leakage. "After deduplication, filtering and decontamination, we retained 8.7T raw tokens."
- Docker environment: A containerized, reproducible software setup used to run and test code reliably. "the high cost of constructing complete Docker environments and corresponding test suites"
- End-to-end code agent trajectories: Complete recorded sequences of planning, editing, testing, and verification steps in coding tasks. "end-to-end agent trajectories, which encompass issue-resolving tasks in software engineering scenarios"
- Fault localization: Identifying the specific files, functions, or lines that cause failures in a system. "such as fault localization and refactoring"
- Forward trajectory synthesis: Generating process data by simulating the agent’s steps forward from the query to the final report. "Forward Trajectory Synthesis."
- Heuristic rule-based filtering: Data filtering using handcrafted rules rather than learned models. "then performed heuristic rule-based filtering"
- Inverse trajectory synthesis: Reconstructing trajectories backward from verified final outputs to ensure high quality and factual grounding. "Inverse Trajectory Synthesis."
- LLM-as-a-judge: Using a LLM to score or evaluate data along dimensions like accuracy and clarity. "we further apply an LLM-as-a-judge approach to score each QA instance"
- Long-horizon: Tasks requiring many sequential steps, prolonged context, and sustained state tracking. "making it ideal for long-horizon agent and reasoning tasks."
- Long-tail repositories: Diverse, less-common codebases that broaden generalization beyond popular projects. "using a wide variety of long-tail repositories through verifiable static tasks"
- MinHash-LSH: A technique that combines MinHash signatures with locality-sensitive hashing for efficient near-duplicate detection. "MinHash-LSH-based~\citep{Broder1997OnTR,HarPeled2012ApproximateNN} deduplication"
- Parameterâperformance scaling: The relationship between model size (parameters) and achieved performance on benchmarks. "Parameterâperformance scaling of base and instruct models on agentic benchmarks."
- Planning--action--reflection loop: An iterative agent workflow that plans steps, executes them, and reflects to adjust strategy. "We adopt a classical planning--action--reflection loop in our agent design"
- Search API: A programmatic interface for querying web or document search engines during trajectories. "we employ multiple agent frameworks (, Youtu-Agent \citep{youtu-agent-2025}, WebDancer \citep{Wu2025WebDancerTA}) and search APIs during the generation process."
- State-of-the-art (SOTA): The best-known performance level on a task at the current time. "it significantly surpasses existing SOTA baselines"
- STEM-oriented vocabulary: A tokenizer vocabulary tailored to science, technology, engineering, and mathematics terms. "with a novel STEM-oriented vocabulary"
- Static evaluation: Assessing correctness using non-executable checks (e.g., matching, refactoring) instead of running tests. "require static evaluation rather than dynamic testing"
- Test dataset leakage: Inclusion of evaluation examples in training data that inflates reported performance. "minimizing the risk of test dataset leakage."
- Tool graph: A graph capturing tools and their dependency relations for planning multi-step tool calls. "We performed verifiable checks and parameter corrections on the above atomic skill library to ensure the completeness of each tool, finally generating a tool graph."
- Tool-use: Invoking external tools (APIs, shells, protocols) within an agent’s trajectory to achieve goals. "across diverse domains such as mathematics, coding, deep research, and general tool use."
- Toxicity scoring: Scoring text for harmful or offensive content to filter training data. "13-gram duplicate detection, toxicity scoring, and code keyword filtering."
- Tokenizer design: The methodology for constructing tokenization schemes and vocabularies that affect model efficiency and capability. "innovations in tokenizer design, data allocation, and multi-stage learning"
- Trajectory-based training: Training that uses recorded sequences of steps, actions, and feedback to teach agent behaviors. "trajectory-based training and continual pre-training on structured interaction data have shown promise"
- Trajectory branching: Expanding datasets by creating alternative paths at key decision points within trajectories. "Trajectory branching strategy for code agent trajectories."
- Up-sampling: Increasing the sampling rate of selected data to emphasize it during training. "we up-sampled certain high-quality STEM and code data."
- XML-style tags: Markup tags resembling XML used to segment and label phases of reasoning. "each encapsulated within its own XML-style tag"
Collections
Sign up for free to add this paper to one or more collections.

