LIMI: Less is More for Agency
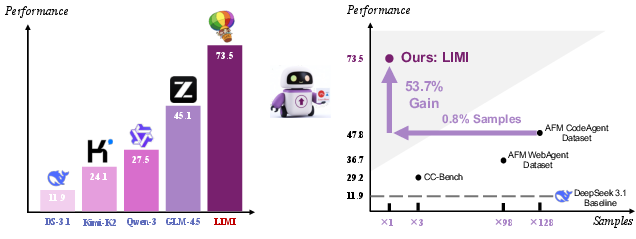
Abstract: We define Agency as the emergent capacity of AI systems to function as autonomous agents actively discovering problems, formulating hypotheses, and executing solutions through self-directed engagement with environments and tools. This fundamental capability marks the dawn of the Age of AI Agency, driven by a critical industry shift: the urgent need for AI systems that don't just think, but work. While current AI excels at reasoning and generating responses, industries demand autonomous agents that can execute tasks, operate tools, and drive real-world outcomes. As agentic intelligence becomes the defining characteristic separating cognitive systems from productive workers, efficiently cultivating machine autonomy becomes paramount. Current approaches assume that more data yields better agency, following traditional scaling laws from language modeling. We fundamentally challenge this paradigm. LIMI (Less Is More for Intelligent Agency) demonstrates that agency follows radically different development principles. Through strategic focus on collaborative software development and scientific research workflows, we show that sophisticated agentic intelligence can emerge from minimal but strategically curated demonstrations of autonomous behavior. Using only 78 carefully designed training samples, LIMI achieves 73.5% on comprehensive agency benchmarks, dramatically outperforming state-of-the-art models: Kimi-K2-Instruct (24.1%), DeepSeek-V3.1 (11.9%), Qwen3-235B-A22B-Instruct (27.5%), and GLM-4.5 (45.1%). Most strikingly, LIMI demonstrates 53.7% improvement over models trained on 10,000 samples-achieving superior agentic intelligence with 128 times fewer samples. Our findings establish the Agency Efficiency Principle: machine autonomy emerges not from data abundance but from strategic curation of high-quality agentic demonstrations.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LIMI, a new way to train AI systems to act like helpful, independent “workers,” not just chatty assistants. The authors call this skill “agency” — the ability for an AI to notice problems, make plans, use tools, and finish tasks on its own. The big idea is that you don’t need tons of training data to build this kind of AI. Instead, a small number of high-quality, carefully chosen examples can be enough. LIMI shows that “less is more” for training agent skills.
What questions does the paper try to answer?
The paper focuses on two simple but important questions:
- Do AIs need huge amounts of data to learn how to be independent and get real work done?
- Can we teach agency more efficiently by using a small set of excellent, realistic examples?
How did they do it?
To make this understandable, imagine teaching a smart teammate how to help with coding and research:
- Instead of giving them a giant textbook with 10,000 random examples, you give them 78 perfect mini-lessons that show the entire process: what the task is, how to think about it, which tools to use, what went wrong, and how to fix it.
Here’s the approach:
- They focused on two everyday “knowledge work” areas:
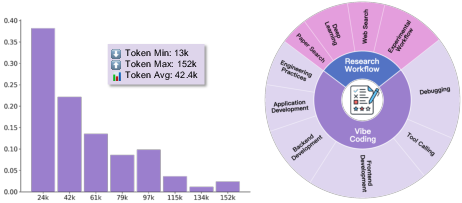
- Vibe Coding: collaborative software development where the AI helps read, write, and improve code, and works alongside humans.
- Research Workflows: science tasks like finding papers, analyzing data, and summarizing results.
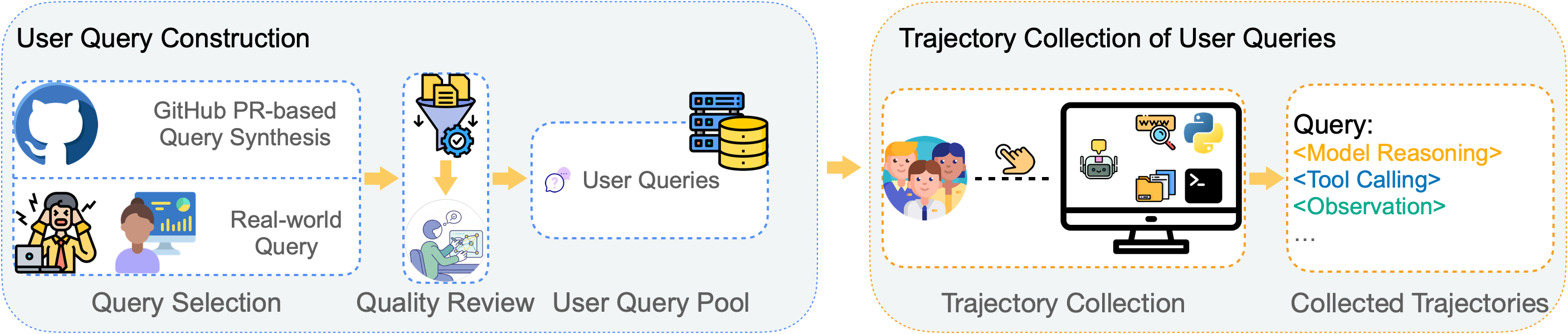
- They built a “query pool” of 78 tasks:
- 60 came from real developer and researcher needs.
- 18 were created from real GitHub pull requests (PRs), using an advanced AI to turn code changes into realistic requests (for example, “update this feature,” “fix this bug,” or “optimize this function”).
- They recorded complete “trajectories” (think of full conversation logs) for each task:
- Model reasoning: the AI’s step-by-step thinking and planning.
- Tool use: the AI calling tools (like code runners, search, or data analysis).
- Environment feedback: results that come back, plus human messages, which help the AI adjust.
- They used an environment called SII CLI (a command-line workspace) to let the AI actually use tools and work through tasks like a real collaborator.
- They tested performance on AgencyBench (a benchmark for agent skills) and other coding/tool-use benchmarks, using metrics like:
- FTFC: how complete the first attempt is.
- SR@3: success rate within 3 rounds of back-and-forth.
- RC@3: how many chances are left when the task is finished (a sign of efficiency).
What did they find, and why does it matter?
Here are the main results:
- With only 78 training examples, LIMI scored 73.5% on AgencyBench — beating big-name models trained in more traditional ways (for example, GLM-4.5 at 45.1%, Kimi-K2-Instruct at 24.1%, and others).
- LIMI did better than a model trained on 10,000 samples, using 128 times less data. That’s a huge efficiency win.
- LIMI also did well on general coding and tool-use tests, showing that it wasn’t just memorizing the training tasks — it could generalize.
Why this matters:
- It challenges the common belief that “more data is always better.”
- It suggests that when teaching an AI to work (not just talk), the quality and realism of examples matter much more than sheer quantity.
- It points toward a future where we can build strong, practical AIs without massive, expensive datasets.
What’s the bigger impact?
If LIMI’s “less-is-more” approach holds up, it could change how we build working AIs:
- Faster and cheaper training: Teams won’t need enormous datasets — they can focus on collecting a small number of excellent, real-world examples.
- Better real-world performance: AIs can learn how people actually work — planning, using tools, and fixing mistakes — making them more useful at jobs like coding, data analysis, and research.
- A shift from “thinking AI” to “working AI”: Instead of just answering questions, future AIs could be trusted to carry out tasks, collaborate with humans, and deliver results.
In short, LIMI shows that smart, careful teaching can beat brute-force training. For building helpful, autonomous AI agents, the right examples matter more than lots of examples.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open issues that remain unresolved and could guide future research:
- External validity beyond two domains: The training and evaluation focus primarily on vibe coding and research workflows; transfer to other agentic domains (e.g., robotic control, enterprise workflows, healthcare, legal, education, customer ops, UI automation, multi-modal environments) remains untested.
- Dependence on a proprietary teacher (GPT-5): Query synthesis and trajectory collection rely on GPT-5; reproducibility, accessibility, and potential teacher–student leakage effects are not controlled or quantified. An open-source replication without GPT-5 is needed.
- Risk of benchmark contamination and format overfitting: No deduplication/near-duplicate analysis or format-level overlap checks between curated trajectories and AgencyBench/generalization benchmarks are reported; train–test leakage and protocol mimicry remain open concerns.
- Limited scaling characterization: The “Agency Efficiency Principle” is supported at a single small sample regime (78 samples) without a dose–response curve (e.g., 20/40/80/160/320 curated samples) to quantify marginal returns or saturation dynamics.
- Lack of ablations on what “strategic curation” means: No principled, reproducible selection policy is formalized or ablated (e.g., by task type, trajectory length, tool diversity, error-recovery events, or collaboration patterns). The contributions of each curation dimension remain unclear.
- Insufficient controls against cherry-picking: From thousands of synthesized PR queries, only 18 were selected. The selection criteria and their impact on performance are not rigorously evaluated against random or stratified selections.
- No analysis of trajectory quality vs. length: With average trajectories of ~42.4k tokens (up to 152k), the relative importance of depth/length vs. content quality is not disentangled. It remains unknown whether shorter, higher-signal trajectories could achieve similar performance.
- Compute- and token-level efficiency not reported: “Less data” is argued by sample count, but total training tokens, FLOPs, wall-clock time, and energy usage (including GPT-5 synthesis/collection cost) are not reported, hindering a fair efficiency comparison to large SFT baselines.
- Statistical robustness and variance: Results are presented without multiple seeds, confidence intervals, or significance tests; sensitivity to initialization and data ordering is unknown.
- Cross-model generality is under-tested: LIMI is evaluated with GLM-4.5 and GLM-4.5-Air, but not adapted to other popular model families (e.g., Llama, Qwen, Mixtral). Whether the efficiency gains transfer architecturally remains open.
- Generalization across tools and environments: Training and most evaluation are closely tied to SII CLI. Portability to other agent frameworks (e.g., LangChain/AutoGen/MetaGPT) and heterogeneous tool APIs is unassessed.
- Long-horizon autonomy not convincingly tested: AgencyBench is evaluated with R = 3 rounds. Capabilities over much longer horizons (dozens/hundreds of turns), session memory, and cross-session persistence remain unmeasured.
- Robustness to tool errors and adversarial conditions: No experiments investigate resilience to flaky tools, API schema drift, missing permissions, latency, adversarial prompts, or misleading observations.
- Human-in-the-loop confounding: Trajectories are collected via human–GPT-5 collaboration; the impact of human interventions (e.g., clarifications, steering, corrections) on learning is not isolated. Purely model-generated vs. human-assisted trajectories are not contrasted.
- Error and failure-mode analysis: There is no qualitative/quantitative breakdown of where LIMI fails (e.g., planning errors, tool selection mistakes, state tracking issues, mis-specification handling), limiting actionable insights for improvement.
- Safety and security considerations for autonomous tool use: The work does not analyze or mitigate risks such as destructive commands, data exfiltration, privilege escalation, or unsafe code execution when operating tools in realistic environments.
- Alignment and preference trade-offs: The effect of LIMI fine-tuning on broader alignment/safety behaviors (e.g., refusal, honesty, harmlessness) is not measured; potential regressions are unknown.
- Catastrophic forgetting and capability trade-offs: While some generalization benchmarks are reported, broader capability retention (e.g., reasoning, knowledge QA, math, multilingual) is not measured; possible performance regressions remain unexamined.
- Multilingual and cross-cultural generalization: All experiments appear English-centric; transfer to other languages and culturally diverse contexts is unexplored.
- Licensing and ethical use of training materials: The use of GitHub PRs and GPT-5 outputs raises unresolved questions about licenses, contributor consent, and dataset redistribution rights; a compliance audit is needed.
- Reproducibility of the data pipeline: Inter-annotator agreement, acceptance rates, quality rubrics, and detailed curation logs are not reported; end-to-end reproducibility of the pipeline in new domains is unclear.
- Curriculum/active learning comparisons: The proposed curation strategy is not compared to standard active learning, difficulty-aware sampling, self-play, or curriculum learning baselines that might also yield data efficiency.
- Parameter-efficient tuning alternatives: Only full fine-tuning is explored. Whether PEFT methods (e.g., LoRA, adapters) with curated data can match performance with lower compute remains open.
- Multi-agent and collaborative dynamics: Although “collaborative problem-solving” is emphasized, multi-agent (agent–agent) collaboration, role specialization, and coordination protocols are not evaluated.
- Memory and state abstraction: No analysis of how LIMI handles stateful contexts, maintains plans across long interactions, or constructs external memory; explicit memory mechanisms vs. emergent behaviors are not compared.
- Domain drift and maintenance: How LIMI adapts when tools, APIs, or repository structures evolve (lifelong learning and continual fine-tuning) is untested.
- Benchmark coverage and realism: AgencyBench task diversity and ecological validity in real enterprise settings (security constraints, legacy systems, compliance workflows) are not demonstrated or stress-tested.
- Fairness of baseline comparisons: Hyperparameter tuning parity, training-token normalization, and environment access parity across compared baselines (especially large SFT datasets) are not rigorously controlled or disclosed.
- Minimal set discovery: The claim that 78 samples suffice is not supported with minimal-cover analyses (e.g., set cover over skills/tool schemas) to characterize the smallest effective subset and its skill coverage.
- Release timing and completeness: The paper references future release of synthetic queries and trajectories; until then, independent verification and community extension are blocked.
- Theory of agency efficiency: The “Agency Efficiency Principle” is asserted empirically but lacks a formal model (e.g., sample complexity bounds, task–skill graphs, or information-theoretic arguments) explaining why and when minimal curated trajectories suffice.
Practical Applications
Overview
The paper proposes LIMI (Less Is More for Intelligent Agency), showing that high-performing autonomous agents can be trained with a small, strategically curated set of multi-turn trajectories (78 samples) focused on collaborative software development (“vibe coding”) and scientific research workflows. It introduces: (i) a query synthesis pipeline using GitHub PRs; (ii) a trajectory capture protocol in a tool-rich CLI environment (SII CLI) that logs reasoning, tool calls, and observations end-to-end; and (iii) evidence for a data-efficiency principle (“Agency Efficiency Principle”) where carefully chosen agentic demonstrations outperform large-scale datasets for cultivating agency. LIMI outperforms strong SOTA baselines on AgencyBench and generalization benchmarks.
Below are practical applications derived from these findings and methods.
Immediate Applications
The following items can be deployed now with available tools (e.g., SII CLI, AgencyBench, open-source datasets/models), moderate engineering, and standard MLOps practices.
- Enterprise “few-demo” agent fine-tuning for software teams (Sector: software/DevOps)
- Use case: Rapidly tailor a foundation model to an organization’s codebase and workflows by curating 50–150 high-quality agentic trajectories (issue triage, bug-fixes, refactors, test generation) and fine-tuning via a supervised framework (e.g., slime).
- Tools/products/workflows: “LIMI-style SFT kit” for agentic coding assistants; trajectory recorder; internal demo library; SII CLI integration for tool orchestration.
- Dependencies/assumptions: Access to a capable base model with tool-use; curated demos from senior engineers; integration with developer tools (GitHub/GitLab, CI, package managers); privacy/compliance controls for internal code.
- PR-derived query synthesis for triage, review, and testing (Sector: software/DevOps)
- Use case: Transform GitHub PRs into actionable agent tasks (generate review checklists, test plans, risk summaries, regression checks) to accelerate reviews and reduce defects.
- Tools/products/workflows: PR-to-query synthesizer; automated test generation; “agent-in-the-loop” review workflow in CI.
- Dependencies/assumptions: Stable access to PR data; base LLM with strong reasoning; licensing/IP guardrails (PR content).
- Trajectory capture and replay in IDE/CLI (Sector: software)
- Use case: Record multi-turn agent sessions (reasoning, tool calls, logs) during debugging, optimization, and feature development to create reusable training data and reproducible “agentic playbooks.”
- Tools/products/workflows: IDE plugin/CLI “Trajectory Recorder”; replay tools for post-mortem analysis; data pipeline to SFT.
- Dependencies/assumptions: Developer adoption; storage/security of logs; consistent tool-call schemas across environments.
- AgencyBench-driven acceptance testing of agents (Sector: software, AI vendors)
- Use case: Pre-deployment audits for agentic assistants with FTFC, SR@R, RC@R metrics; compare vendors/models; track model regressions.
- Tools/products/workflows: AgencyBench test suites; automated evaluation harness; release gates tied to agentic KPIs.
- Dependencies/assumptions: Benchmark relevance to target workflows; Rounds configuration; consistent environment access.
- Research workflow agents for labs (Sector: academia, scientific software)
- Use case: Agents that plan literature searches, retrieve datasets, run analyses, compare baselines, and maintain reproducible notebooks—mirroring the paper’s trajectories.
- Tools/products/workflows: SII CLI integration for data retrieval/analysis; “lab notebook” trajectory logs; dataset/model registries.
- Dependencies/assumptions: Access to scientific tooling/data APIs; guardrails for provenance and reproducibility; IRB/ethics for data use.
- Data-efficient alignment for startups and SMEs (Sector: software, finance, analytics)
- Use case: Align general LLMs to domain-specific style guides, compliance patterns, and toolchains using a small curated demo set; reduce training cost and time.
- Tools/products/workflows: LIMI-style curation playbook; SFT pipelines; lightweight evaluation against AgencyBench variants tailored to the domain.
- Dependencies/assumptions: Availability of domain experts for demo curation; base model license terms; internal evaluation data.
- Course-specific agentic teaching assistants (Sector: education)
- Use case: Build small demo sets for programming/data-science courses so agents guide labs, scaffold problem-solving, and check work; capture trajectories to improve future sessions.
- Tools/products/workflows: Curriculum-aligned demo packs; classroom CLI/IDE integration; analytics dashboards of student-agent interactions.
- Dependencies/assumptions: Instructor curation; campus compute; academic integrity policies and clear use guidelines.
- Tool-use audit logging and safety monitoring (Sector: compliance/policy)
- Use case: Use standardized trajectory schemas to audit agent tool calls, detect risky actions, and support forensic analyses.
- Tools/products/workflows: “Agentic Audit Logger” exporting reasoning/tool-call/observation triplets; policy rules for red flags.
- Dependencies/assumptions: Clear schemas; storage governance; explainability practices; incident response workflows.
- Personal coding and research copilots with curated demos (Sector: daily life, prosumer software)
- Use case: Hobbyists and independent researchers collect a handful of demonstrations tailored to their projects to fine-tune personal agents that understand their stack and habits.
- Tools/products/workflows: Easy-to-use trajectory capture; local SFT scripts; model cards describing limits/safety.
- Dependencies/assumptions: Base model availability on local or cloud; basic CLI/IDE integration; user data consent.
- Benchmarking and replication programs for labs and vendors (Sector: academia, AI industry)
- Use case: Adopt the paper’s datasets, models, and benchmarking practices to calibrate agentic capabilities; publish standardized results.
- Tools/products/workflows: Shared datasets/models; AgencyBench-centered leaderboards; replication reports.
- Dependencies/assumptions: Open-source access; reproducible environments; transparent reporting.
Long-Term Applications
These require further research, scaling, integration, safety validation, or standardization before widespread use.
- Few-demo agent training in high-stakes domains (Sector: healthcare, finance, robotics, energy)
- Use case: Train workflow agents for EHR navigation, claims adjudication, lab procedures, robotic assembly, grid diagnostics using small sets of expert demonstrations.
- Tools/products/workflows: Domain tool adapters; validated agency metrics; safety layers (verification, human-in-the-loop).
- Dependencies/assumptions: Regulatory approval; robust fail-safes; comprehensive domain coverage; bias and error mitigation.
- Standardization of agentic trajectory schemas and a “demonstration marketplace” (Sector: software, education)
- Use case: Establish common formats for reasoning/tool-call/observation logs; enable exchange of high-quality demos across organizations and curricula.
- Tools/products/workflows: Open standards; curation portals; quality-rating systems for demos.
- Dependencies/assumptions: Community consensus; licensing/IP clarity; privacy-preserving sharing.
- Autonomous development pipelines with guarded autonomy (Sector: software/DevOps)
- Use case: Agents that open PRs, write tests, conduct canary deployments, and revert/repair—under policy constraints and multi-stage approvals.
- Tools/products/workflows: “Agent PR Manager”; staged gates; formal verification for critical changes.
- Dependencies/assumptions: Mature verification; risk scoring; organizational buy-in; robust rollback strategies.
- Agentic lab automation and experiment co-design (Sector: biotech, materials science)
- Use case: Agents control instruments, design experiments, analyze results, and iterate based on observations—encoded as trajectories for reproducibility.
- Tools/products/workflows: Instrument drivers; digital twin simulators; audit trails; automated lab notebooks.
- Dependencies/assumptions: Safe hardware interfaces; rigorous validation; lab accreditation; data governance.
- Edge/on-device agent training with curated demos (Sector: mobile/IoT)
- Use case: Private, on-device agents trained from user’s own trajectories (home automation, personal analytics) with minimal compute footprints.
- Tools/products/workflows: Compact model architectures; on-device SFT; privacy-preserving logging.
- Dependencies/assumptions: Hardware acceleration; energy constraints; secure local storage.
- Regulatory benchmarks and procurement standards for agentic AI (Sector: policy/government)
- Use case: AgencyBench-like metrics incorporated into certification, audits, and RFPs; “agentic competence” thresholds specified for public-sector deployments.
- Tools/products/workflows: Compliance test suites; third-party audit services; reporting templates.
- Dependencies/assumptions: Policy consensus; domain-specific adaptations; fairness and safety criteria.
- Enterprise “Agent OS” for tool orchestration (Sector: IT/software)
- Use case: Unified CLI/SDK connecting diverse enterprise tools (code repos, ETL, ticketing, monitoring) with standardized trajectory logging and execution policies.
- Tools/products/workflows: Policy engine; role-based access; observability; cross-tool adapters.
- Dependencies/assumptions: Vendor integrations; security hardening; RBAC; change management.
- Agentic RPA 2.0 with few-shot workflow learning (Sector: retail, finance, energy, operations)
- Use case: Replace brittle rule-based RPA with agents trained on a small set of annotated process demonstrations; resilient to changes via reasoning and tool-use.
- Tools/products/workflows: Process demo capture; alignment pipelines; guardrails for financial/operational risk.
- Dependencies/assumptions: Process stability; exception handling; auditability; compliance adherence.
- Human–AI teaming curricula and practice guides (Sector: education, HR/L&D)
- Use case: Train workers and students to design, curate, and collaborate with agentic systems; embed trajectory-based reflection and continuous improvement.
- Tools/products/workflows: Teaming frameworks; co-creation workshops; evaluation rubrics tied to agency metrics.
- Dependencies/assumptions: Institutional adoption; pedagogical validation; inclusivity considerations.
- Sustainable AI programs emphasizing data-efficient training (Sector: energy, ESG/policy)
- Use case: Corporate ESG strategies adopting LIMI-like training to reduce compute and emissions while improving agent performance; public reporting on efficiency gains.
- Tools/products/workflows: Efficiency dashboards; carbon accounting for training runs; data-efficiency KPIs.
- Dependencies/assumptions: Reliable emissions measurements; governance; stakeholder buy-in.
Notes on Feasibility and Key Assumptions
- Data quality over quantity: Success hinges on expert-curated, high-signal trajectories capturing realistic multi-step behaviors; weak demos can degrade outcomes.
- Tooling ecosystem: Many applications depend on SII CLI-like environments (or equivalents) with robust tool adapters and precise logging of reasoning/tool calls/observations.
- Base model capability: Requires a competent foundation model with strong reasoning and tool-use; licensing and deployment constraints apply.
- Domain transfer: Current evidence is strongest in software and research workflows; high-stakes domains need additional validation, safety layers, and regulatory compliance.
- Privacy/IP: Trajectory capture (especially with PR content and internal data) must respect organizational policies, licenses, and data protection regulations.
- Safety/governance: Guardrails (policy engines, audits, human-in-the-loop) are necessary when agents execute actions with operational or compliance impact.
Glossary
- AFM-CodeAgent-SFT-Dataset: A supervised fine-tuning dataset focused on training agentic models for code-related tasks. "AFM-CodeAgent-SFT-Dataset~\footnote{\url{https://huggingface.co/datasets/PersonalAILab/AFM-WebAgent-SFT-Dataset}"
- AFM-WebAgent-SFT-Dataset: A supervised fine-tuning dataset for web agent tasks and tool-use interactions. "AFM-WebAgent-SFT-Dataset~\footnote{\url{https://huggingface.co/datasets/PersonalAILab/AFM-WebAgent-SFT-Dataset}"
- Agency: The emergent capacity of AI systems to act autonomously—discovering problems, forming hypotheses, and executing solutions through self-directed interaction with environments and tools. "We define Agency as the emergent capacity of AI systems to function as autonomous agents—actively discovering problems, formulating hypotheses, and executing solutions through self-directed engagement with environments and tools."
- Agency Efficiency Principle: A proposed principle stating that machine autonomy emerges from strategically curated, high-quality demonstrations rather than large-scale data. "Our findings establish the Agency Efficiency Principle: machine autonomy emerges not from data abundance but from strategic curation of high-quality agentic demonstrations."
- AgencyBench: A benchmark designed to evaluate agentic capabilities in collaborative, tool-using scenarios across coding and research tasks. "We evaluate all models on AgencyBench~\citep{li2025agencybench}, a comprehensive evaluation benchmark specifically designed for assessing agentic capabilities in collaborative scenarios."
- Agentic intelligence: The capability of AI systems to perform autonomous, multi-step, tool-using, and collaborative tasks effectively. "we show that sophisticated agentic intelligence can emerge from minimal but strategically curated demonstrations of autonomous behavior."
- Agentic LLMs: LLMs enhanced to reason, act, and interact autonomously as agents. "The emergence of agentic LLMs--systems that can reason, act, and interact autonomously~\cite{locke1987social}--represents a paradigm shift from passive AI assistants to proactive intelligent agents~\citep{LLM-based-agent,rise-LLM-agent}."
- CLI environment: A command-line interface context that integrates tools and logging to support agentic model execution and trajectory capture. "Several command line interface (CLI) environments are available for agentic model, including Claude Code\footnote{https://github.com/anthropics/claude-code}, Gemini CLI\footnote{https://github.com/google-gemini/gemini-cli}, and SII CLI \citep{sii-cli-2025}."
- DeepSeek-V3.1: A foundation model baseline used for comparison in agentic and generalization benchmarks. "DeepSeek-V3.1 (11.9\%)"
- DS-1000: A benchmark suite for data science and code generation evaluations. "DS-1000~\citep{ds1000} for data science and code generation tasks"
- Ecological validity: The extent to which experiments and data reflect real-world contexts and behaviors. "ensuring that our training demonstrations capture authentic patterns of agentic behavior while maintaining ecological validity;"
- evalplus-humaneval: An enhanced code generation benchmark derived from HumanEval for evaluating program synthesis. "evalplus-humaneval and evalplus-mbpp~\citep{evalperf,evalplus}"
- evalplus-mbpp: An enhanced benchmark derived from MBPP for evaluating code generation on programming problems. "evalplus-humaneval and evalplus-mbpp~\citep{evalperf,evalplus}"
- First-Turn Functional Completeness (FTFC): A metric measuring how completely the initial agent response implements required functionality. "Effectiveness metrics include: (1) First-Turn Functional Completeness (FTFC), measuring the percentage of requirements correctly implemented in the initial response;"
- GitHub PR-based Query Synthesis: A method that uses real pull requests and LLMs to synthesize authentic agentic queries from software development contexts. "\paragraph{GitHub PR-based Query Synthesis} To systematically expand our query pool while maintaining authenticity and real-world relevance, we develop a pipeline for synthesizing additional queries from GitHub Pull Requests (PRs) using GPT-5 \citep{GPT-5-System-Card}."
- GLM-4.5: A LLM used as a strong baseline and fine-tuning target for agentic training. "Using only 78 carefully designed training samples, LIMI achieves 73.5\% on AgencyBench, dramatically outperforming state-of-the-art models: Kimi-K2-Instruct (24.1\%), DeepSeek-V3.1 (11.9\%), Qwen3-235B-A22B-Instruct (27.5\%), and GLM-4.5 (45.1\%)."
- GLM-4.5-Air: A smaller-scale variant of GLM used to evaluate scalability of the LIMI approach. "GLM-4.5-Air \citep{zeng2025glm}"
- GPT-5: An advanced LLM used to synthesize queries from GitHub pull requests. "using GPT-5 \citep{GPT-5-System-Card}"
- Kimi-K2-Instruct: A foundation model baseline for agentic and coding benchmark comparisons. "Kimi-K2-Instruct (24.1\%)"
- LIMA: A methodology showing effective model alignment using a small number of curated examples. "LIMA~\cite{zhou2023lima} achieved effective model alignment with only 1,000 carefully curated examples,"
- LIMI: The proposed approach “Less Is More for Intelligent Agency,” emphasizing strategic data curation for training agentic models. "We introduce LIMI (Less Is More for Intelligent Agency), which demonstrates that agency follows radically different development principles from traditional scaling approaches."
- LIMI-Air: The variant of LIMI corresponding to fine-tuning the GLM-4.5-Air model on the curated dataset. "For clarity, we refer to models fine-tuned with our curated dataset as LIMI (corresponding to fine-tuning GLM-4.5) and LIMI-Air (corresponding to fine-tuning GLM-4.5-Air)."
- LIMO: A methodology demonstrating that complex reasoning can emerge from a small, strategically selected set of training samples. "LIMO~\cite{ye2025limo} demonstrated that complex mathematical reasoning can emerge from just 817 strategically selected training samples,"
- Long-Horizon Tasks: Tasks requiring extended multi-step interaction, planning, and tool use across prolonged sequences. "\subsection{Long-Horizon Tasks and Agentic Complexity}"
- Model reasoning: The internal reasoning outputs from the agent capturing understanding, analysis, planning, and decisions. "Model reasoning () captures the agentic model's reasoning output demonstrating understanding, analysis, planning, and decision-making processes."
- Model tool calling: Structured invocations by the model to external tools or environments to complete subtasks. "Model tool calling () represents structured tool invocations executed by the model to interact with external environments and accomplish specific subtasks."
- Pass@4: A tool-use metric defined as the fraction of four independent runs that succeed; commonly used in benchmark evaluations. "Pass~$\hat{$~4} accuracy on tau2-bench-airline and tau2-bench-retail, which is defined as the fraction of 4 independent runs that succeed, to measure tool-use success rates;"
- Qwen3-235B-A22B-Instruct: A large-scale instruction-tuned model used as a baseline in comparisons. "Qwen3-235B-A22B-Instruct (27.5\%)"
- Remaining Chances (RC@R): An efficiency metric calculating the average number of unused interaction rounds upon successful completion. "Efficiency metrics include: (3) Remaining Chances (RC@R), calculating the average number of unused rounds when queries are successfully completed, measuring computational efficiency."
- Research Workflows: Complex, multi-step scientific tasks including literature search, experiment design, and data analysis. "Research workflows encompass scenarios where agents navigate complex scientific processes, including literature search, data analysis, experiment design, and insight generation."
- SciCode: A benchmark for evaluating scientific computing capabilities of models. "SciCode~\citep{SciCode} for scientific computing applications."
- SII CLI: A command-line environment integrating tools and logging to support realistic human–AI collaboration and trajectory collection. "We select SII CLI as our execution environment based on several critical advantages: (1) comprehensive tool integration that supports both vibe coding and research workflows,"
- slime framework: A training framework used for supervised fine-tuning of LLMs with consistent configurations. "All fine-tuning experiments are conducted using the slime framework~\footnote{\url{https://github.com/THUDM/slime}, which provides robust and efficient infrastructure for supervised fine-tuning of LLMs."
- Success Rate (SR@R): An effectiveness metric measuring the proportion of tasks successfully completed within R interaction rounds. "Success Rate (SR@R), representing the percentage of queries successfully completed within R allocated rounds."
- tau2-bench-airline: A tool-use benchmark evaluating agent performance in airline-related tasks. "tau2-bench-airline and tau2-bench-retail~\citep{taubench,tau2bench} for tool use capabilities,"
- tau2-bench-retail: A tool-use benchmark assessing agent performance in retail-related tasks. "tau2-bench-airline and tau2-bench-retail~\citep{taubench,tau2bench} for tool use capabilities,"
- Tool orchestration: Coordinating multiple tools and systems in sequence to achieve complex task objectives. "Tool orchestration becomes essential as real-world agentic tasks require coordinated use of multiple systems with integrated result processing."
- Trajectory: The full sequence of interactions (reasoning, tool calls, observations) generated during task execution. "The trajectory captures the subsequent collaborative trajectory following the initial query."
- Unified diff patch token count: A quantitative filter on pull-request changes based on the tokenized size of diff patches. "We filter PRs based on the unified diff patch token count (below 1,200 tokens) and exclude PRs that only modify Markdown files,"
- Vibe Coding: A collaborative software development paradigm where agents work alongside humans across rich, context-aware environments and tool ecosystems. "Vibe coding represents collaborative software development where LLMs or agents work alongside human developers in natural, context-rich environments."
Collections
Sign up for free to add this paper to one or more collections.

