Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
Abstract: Enabling LLMs to effectively utilize tools in multi-turn interactions is essential for building capable autonomous agents. However, acquiring diverse and realistic multi-turn tool-use data remains a significant challenge. In this work, we propose a novel text-based paradigm. We observe that textual corpora naturally contain rich, multi-step problem-solving experiences, which can serve as an untapped, scalable, and authentic data source for multi-turn tool-use tasks. Based on this insight, we introduce GEM, a data synthesis pipeline that enables the generation and extraction of multi-turn tool-use trajectories from text corpora through a four-stage process: relevance filtering, workflow & tool extraction, trajectory grounding, and complexity refinement. To reduce the computational cost, we further train a specialized Trajectory Synthesizer via supervised fine-tuning. This model distills the complex generation pipeline into an efficient, end-to-end trajectory generator. Experiments demonstrate that our GEM-32B achieve a 16.5% improvement on the BFCL V3 Multi-turn benchmark. Our models partially surpass the performance of models trained on τ - bench (Airline and Retail) in-domain data, highlighting the superior generalization capability derived from our text-based synthesis paradigm. Notably, our Trajectory Synthesizer matches the quality of the full pipeline while significantly reducing inference latency and costs.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Explanation of “Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text”
What is this paper about?
This paper shows a new way to teach AI assistants (like smart chatbots) how to use tools over many back-and-forth messages with a user. Instead of hand-building fake training conversations or relying on a fixed set of apps and APIs, the authors turn everyday text from the internet (like how-to guides or step-by-step instructions) into realistic training conversations. They call their method GEM.
What questions are the researchers asking?
They focus on three simple questions:
- Can we skip collecting huge sets of pre-made tools and still create good training data for AI assistants?
- Can regular text (like “how to file a claim” or “how to edit a photo”) be turned into full, realistic, multi-step conversations where an AI uses tools?
- Will this text-based training help AIs perform better on tough tests and generalize to new topics?
How did they do it? (Methods in everyday language)
Think of teaching an AI to follow a recipe: you need the steps (workflow), the kitchen tools (APIs), and a conversation where the cook (assistant) and the learner (user) talk through the process.
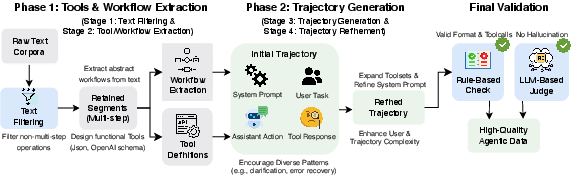
The GEM pipeline has four main stages. Here’s the idea:
- First, the researchers scan lots of text to find pieces that look like step-by-step guides. Imagine spotting “First do this, then that…” sections.
- Next, they turn those steps into a clear plan (a workflow) and design simple “tools” (like app actions) the AI could use, such as “search_items” or “edit_image.” These tools are described like buttons with specific inputs.
- Then, they generate a full conversation: a system message with rules, user questions (sometimes unclear or tricky), assistant replies that call the right tools with the right inputs, and tool results (what the tool returns).
- Finally, they make the conversations more realistic and challenging by adding details: clarifying missing info, handling mistakes, following rules, making longer, more complex sequences, and checking that nothing is made up.
To keep the data high quality, they use:
- Rule checks (like “does this tool call match the tool definition?”).
- An AI judge that looks for hallucinations (made-up details not supported by the conversation).
Because this full pipeline can be slow and costly, they also train a special model called a Trajectory Synthesizer. It learns to go directly from text to a finished conversation, end-to-end, much faster and cheaper—like a student who has learned the entire process and can now do it by themselves.
What did they find, and why does it matter?
The results show strong gains:
- On a tough benchmark (BFCL V3 for multi-turn tool use), their 32B model trained with GEM data improved by about 16 percentage points, even beating some larger or proprietary models.
- On another realistic test (-bench) in the Airline and Retail domains, their models—trained on out-of-domain text (not made specifically for airlines or retail)—performed as well as or better than models trained on in-domain data. This means their approach generalizes well to new areas.
- The Trajectory Synthesizer (the fast, end-to-end version) produced training data close in quality to the full, more expensive pipeline, while cutting time and costs.
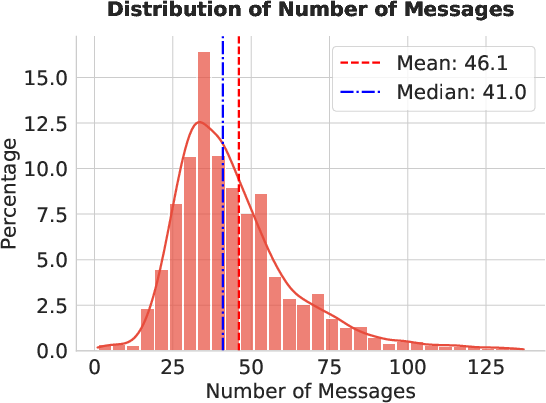
Their dataset is also notably rich:
- Conversations are long (around 46 messages on average).
- They involve many tool calls (about 16 per conversation).
- They often use multiple tools (around 9 different tools per conversation).
This depth helps AIs practice real-world behaviors: asking for missing info, sticking to rules, fixing errors, and planning multi-step tasks.
Why is this important?
- It unlocks a huge, realistic source of training data from ordinary text on the internet—no need to hand-build giant tool libraries first.
- It helps AI assistants learn more general, transferable skills for using tools across different domains, not just one specific area.
- It makes training cheaper and faster thanks to the Trajectory Synthesizer, which can mass-produce high-quality training conversations from text.
In simple terms: this work turns everyday “how-to” text into practice conversations that teach AI assistants how to think, ask, follow rules, and use tools over many steps—just like a careful, helpful human would.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Lack of executability: Generated tools and trajectories are not executed in a real or simulated environment; no evaluation of whether tool calls actually succeed against real APIs or a sandboxed environment.
- Unmeasured accuracy of workflow/tool extraction (Stage 2): No quantitative metrics (precision/recall, human adjudication) on how correctly the pipeline maps raw text into structured workflows and tool schemas.
- Validation reliability is unquantified: The LLM-based judge for hallucination detection has no reported precision/recall or agreement with human judges; robustness and failure modes are unknown.
- Grounding beyond parameters is not verified: Validation checks ensure parameter values are “present in context” but do not verify semantic consistency (e.g., state transitions, constraint adherence, referential integrity).
- Possible benchmark contamination: The paper does not analyze overlap between synthesized data and test benchmarks (BFCL V3, τ²-bench), leaving contamination risk and unfair advantages unaddressed.
- Dataset size confounds across baselines: GEM fine-tunes on 10K trajectories while some baselines use 50K; there are no controlled experiments with matched data sizes and identical training setups.
- Scalability and data-efficiency curves missing: No analysis of performance as a function of synthesized data volume, diversity, or refinement depth; cost–benefit trade-offs are not quantified.
- Limited domain/language coverage: Evaluation focuses on English web corpora and two domains (Airline, Retail); multilingual, low-resource, and specialized domains (e.g., healthcare, law, industrial ops) remain untested.
- Safety, ethics, and privacy not addressed: No content safety filters, PII detection, or toxicity/harm mitigation; ethical risks from extracting and amplifying unsafe procedures are not discussed.
- Licensing/legal compliance unclear: The legality of deriving tool definitions and trajectories from web text (e.g., Ultra-FineWeb, WikiHow) and releasing derived datasets is not analyzed.
- Simulated tool outputs may lack realism: There is no comparison of simulated outputs against real API responses or logs to assess realism and downstream impact on agent learning.
- Dialogue length realism and practical impact: Average 46 turns per trajectory may be unnatural for many tasks; effects on agent latency, memory footprint, and deployment viability are not measured.
- Missing multimodal tool-use: The pipeline and evaluations are text-only; integration and assessment of image, audio, GUI, or sensor tools are absent.
- Robustness to adversarial/malicious users: Although trajectories include ambiguity and error recovery, there is no systematic evaluation against adversarial inputs, social engineering, or policy-violating requests.
- Single-pass generation vs multi-agent simulation: The choice trades realism for efficiency, but there is no comparative study quantifying differences in fidelity, error patterns, and downstream performance.
- Refinement stage lacks formal complexity metrics: “Complexity” is increased qualitatively; no standardized measures (e.g., branching factor, dependency depth, error-recovery frequency) or calibration against real task distributions.
- Generalization across diverse corpora is weakly demonstrated: Only Ultra-FineWeb and WikiHow are tested; broader sources (technical manuals, code repos, logs, enterprise wikis) and their effects on generalization remain unexplored.
- Reproducibility gaps: Full prompts (appendix is truncated), code, seeds, and hardware details are missing; reliance on specific proprietary teacher models (GLM-4.6) limits replicability.
- Narrow benchmark coverage: Beyond BFCL V3 and τ²-bench, other agentic benchmarks (ACEBench, VitaBench, ToolBench variants, real customer-service logs) are not used to triangulate capability.
- Long-context limits not characterized: Performance and memory scaling for contexts substantially longer than 46 turns, or across different context window sizes, is not analyzed.
- Compositionality and concurrency evaluation missing: Parallel tool calls, conditional branches, retries, and exception handling are discussed but not measured with targeted diagnostics.
- Schema vs semantic correctness: Verification enforces OpenAI-format compliance, but does not ensure that parameter types, constraints, and business rules match the source text or domain norms.
- Curriculum and selection strategies unstudied: No investigation into active data selection, curriculum learning, or difficulty scheduling to improve sample efficiency and coverage.
- Absence of RLHF or online learning: The work relies on SFT; the benefits of RLHF, offline RL, or online learning in tool-use environments are not explored.
- No end-to-end deployment studies: There is no evidence of utility in production-like systems (tool latency, error recovery in live environments, user satisfaction).
- Human evaluation of trajectory naturalness: No human assessments of conversation quality, instruction-following, or alignment with realistic user behavior.
- Corpus-induced biases unmeasured: Potential demographic, cultural, and domain biases in text sources and their impact on tool-use behavior are not quantified.
- Cost reporting is incomplete: Wall-clock generation time, GPU-hours, and inference costs for the pipeline vs. the synthesizer are not provided; latency improvements are not numerically substantiated.
- Stage‑1 filtering/classifier quality unknown: The classifier that detects procedural segments has no reported precision/recall or error analysis; the asserted 14% procedural prevalence may be biased.
- Tool ecosystem alignment: Compatibility with existing API ecosystems (e.g., OpenAPI/Swagger), error codes, pagination, auth flows, and rate limits is not modeled or evaluated.
Glossary
- ACEBench: A benchmark designed to evaluate multi-turn tool-use capabilities of LLM agents across different settings. "ACEBench~\citep{chen2025acebench} evaluates multi-turn tool-use capability from three perspectives: normal, special, and agent."
- Agentic: Pertaining to autonomous agent behavior, including perceiving, reasoning, acting, and tool use. "we introduce GEM, an agentic synthesis pipeline designed to automatically extract and generate multi-turn tool-use trajectories directly from large-scale text corpora."
- AST-based checks: Validation using Abstract Syntax Trees to assess structural and semantic correctness of function calls. "using AST-based checks to measure the accuracy and compositionality (e.g., parallel calls) of model-generated function invocations."
- Avg@4: An evaluation metric averaging performance over up to four attempts. "We employ GPT-4.1 as the user simulator Following the original experimental setting and report performance using the Avg@4 and Pass@4 metrics."
- BFCL (Berkeley Function Calling Leaderboard): A benchmark evaluating LLM function-calling accuracy and robustness across domains and languages. "The Berkeley Function Calling Leaderboard (BFCL)~\citep{patilberkeley} provides a large-scale, syntax- and semantics-aware evaluation of function calling across diverse domains and programming languages, using AST-based checks to measure the accuracy and compositionality (e.g., parallel calls) of model-generated function invocations."
- Compositionality: The capability to correctly combine multiple function calls or reasoning steps (e.g., parallel calls). "using AST-based checks to measure the accuracy and compositionality (e.g., parallel calls) of model-generated function invocations."
- Dual-control environments: Evaluation settings where both the user and the agent can invoke tools, increasing interaction complexity. "-bench~\citep{barres2025tau} further extends this line by introducing dual-control environments where both the agent and the user can invoke tools"
- End-to-end trajectory generator: A model that produces complete multi-turn tool-use trajectories in one pass without separate staged components. "This model distills the complex generation pipeline into an efficient, end-to-end trajectory generator."
- Function-calling traces: Verified sequences of tool/API invocations produced by or for training agents. "synthesizes verified function-calling traces with high complexity and diversity."
- Graph-structured function paths: Workflow representations where tool calls form a graph, enabling complex multi-tool planning. "MagNet~\citep{yin2025magnet} represents multi-tool workflows as graph-structured function paths and converts them into multi-turn conversations with executable calls."
- Hallucinations: Model outputs that are not grounded in context or evidence, often fabricated details or parameters. "we employ an LLM-based judge (Qwen3-32B in this paper) to detect and eliminate hallucinations."
- In-domain data: Training data drawn from the same domain as the evaluation environment. "models trained on -bench (Airline and Retail) in-domain data"
- LLM-based judge: A LLM used to assess and filter generated data for quality and grounding. "we employ an LLM-based judge (Qwen3-32B in this paper) to detect and eliminate hallucinations."
- MCP servers: Servers implementing the Model Context Protocol used to expose tools/APIs for agent use. "TOUCAN~\citep{xu2025toucan} crawls MCP servers and synthesizing 1.5M of tool-use data."
- Non-autoregressive framework: A generation approach that produces entire sequences (e.g., dialogues) in a single step rather than token by token. "ToolACE-MT~\citep{zeng2025toolace} adopts a non-autoregressive framework that drafts entire dialogues in one shot and refines them via iterative editing and verification."
- OpenAI format: The standardized function/tool definition format used by OpenAI for function calling. "a tool defined in the standard OpenAI format"
- OpenAI schema standards: The schema specification for defining tools/functions and parameters for LLM function calling. "in accordance with OpenAI schema standards"
- Out-of-domain training data: Data sourced from domains different from those used in evaluation, testing generalization. "out-of-domain training data generated through our paradigm achieve performance on -bench that is comparable to models trained on -bench in-domain data"
- Pass@4: The probability that at least one of up to four attempts successfully solves the task. "report performance using the Avg@4 and Pass@4 metrics."
- Rule-based verification: Deterministic checks enforcing structural and schema correctness of generated trajectories and tool calls. "The trajectory filtering process integrates rule-based verification with LLM-based assessments to ensure high-quality outputs."
- Supervised fine-tuning (SFT): Training an LLM on labeled examples to adapt it to specific tasks or formats. "Only those trajectories that successfully pass both validation stages are retained as the final set $T_{\text{final}$ for use in supervised fine-tuning (SFT)."
- System prompt: A fixed instruction that sets global rules and behavior for the assistant throughout a conversation. "System Prompt : Clear domain-specific rules extracted from the source text, establishing guidelines the assistant must follow throughout the conversation."
- tau-bench: A benchmark simulating real-world user–agent tool interactions in specific domains. "-bench~\citep{yao2024tau} emulates dynamic conversations between a simulated user and a tool-augmented agent in domain-specific scenarios"
- tau2-bench: An extension of tau-bench introducing dual-control settings where both users and agents invoke tools. "-bench~\citep{barres2025tau} further extends this line by introducing dual-control environments where both the agent and the user can invoke tools"
- Tool-augmented agent: An LLM-based agent equipped to call external tools or APIs during interaction. "-bench~\citep{yao2024tau} emulates dynamic conversations between a simulated user and a tool-augmented agent in domain-specific scenarios"
- Tool-call chains: Sequences of dependent tool invocations within a trajectory to accomplish complex tasks. "ensuring the inclusion of non-trivial tool-call chains."
- Trajectory grounding: Ensuring that tool calls and parameters are anchored in the source text and dialogue context. "relevance filtering, workflow {paper_content} tool extraction, trajectory grounding, and complexity refinement."
- Trajectory Synthesizer: A model trained to convert raw text directly into tool definitions and multi-turn trajectories. "we further train a specialized Trajectory Synthesizer via supervised fine-tuning."
- Ultra-FineWeb: A large-scale web text corpus used for pretraining and data synthesis. "We source the training data from Ultra-FineWeb~\citep{wang2025ultra} and employ GLM-4.6 to generate 10K synthetic trajectories."
- User simulator: An automated system (often an LLM) that generates user messages to evaluate agent performance. "We employ GPT-4.1 as the user simulator"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the GEM pipeline and Trajectory Synthesizer to turn existing text corpora into multi-turn, tool-use training data and workflows.
- Enterprise “doc-to-trajectory” data generation for agent training
- Sectors: customer service, retail, travel/airlines, logistics, IT operations
- Tools/products/workflows: GEM pipeline to ingest SOPs/manuals/tickets, extract workflows and OpenAI tool schemas, generate multi-turn dialogues; integrate with LLaMA-Factory for fine-tuning; deploy the Trajectory Synthesizer for low-cost, end-to-end generation
- Assumptions/dependencies: access to internal documentation; data privacy and rights clearance; adequate compute; light domain expert review for high-stakes content
- Automatic API/schema extraction from manuals and policy docs
- Sectors: software development, DevOps, platform engineering
- Tools/products/workflows: “API schema generator” that converts procedural text into validated function definitions (OpenAI schema); developer workflow to bootstrap tool instrumentation
- Assumptions/dependencies: source texts explicitly describe operations/parameters; human-in-the-loop verification for correctness and safety
- Policy-grounded compliance assistants (training-only) for regulated domains
- Sectors: healthcare administration, finance back-office, HR
- Tools/products/workflows: synthesize dialogues that emphasize rule adherence (clarifications, refusals, error recovery); train agents on realistic multi-turn patterns without executing real transactions
- Assumptions/dependencies: conservative deployment (advisory mode); mapping and validation of policy constraints; organizational approval
- Customer-support simulation datasets to harden agent behavior
- Sectors: e-commerce, telecom, travel/airlines, retail
- Tools/products/workflows: generate long-context, error-prone, dual-control-style conversations; use BFCL-like checks and GEM validation to stress-test function calling
- Assumptions/dependencies: domain-relevant corpora; evaluation harnesses aligned with production KPIs (task success, tool correctness)
- Runtime argument-grounding guardrails for agents
- Sectors: software platforms, agent ops
- Tools/products/workflows: integrate the LLM-based judge from GEM’s validation to check tool-call parameters are grounded in the dialogue context; attach rule-based structural checks
- Assumptions/dependencies: acceptable latency overhead; monitoring for false positives/negatives; fallback policies
- Education: turn textbooks and how-to guides into interactive lab dialogues
- Sectors: EdTech, higher education
- Tools/products/workflows: “Text-to-Lab Tutor” that synthesizes multi-turn interactions invoking calculators, plotting tools, coding notebooks; supports error recovery and clarifications to teach procedural problem solving
- Assumptions/dependencies: availability of tool plugins (e.g., Jupyter, MATLAB, graders); educational content rights; low-stakes evaluation first
- IT operations assistants trained from runbooks
- Sectors: IT/SRE, cloud operations
- Tools/products/workflows: generate multi-turn guided workflows from incident runbooks; “Runbook Agent Trainer” to fine-tune internal assistants on escalation, rollback, and verification steps
- Assumptions/dependencies: up-to-date runbooks; mapping to safe, read-only tools initially; change-management policies
- Rapid prototyping with MCP/tool ecosystems
- Sectors: developer tooling, platform integrators
- Tools/products/workflows: use GEM to bootstrap tool schemas and dialogues against MCP servers or mock tools; accelerate agent POCs
- Assumptions/dependencies: later replacement of mocks with production connectors; security reviews
- Domain-specific benchmark creation and QA
- Sectors: ML evaluation, MLOps
- Tools/products/workflows: derive multi-turn, BFCL-style domain tests from corpora; track accuracy across miss-parameter/miss-function/long-context categories; institute regression dashboards
- Assumptions/dependencies: benchmark representativeness; maintenance process to refresh tests with new policies/tools
- Multilingual and localization-ready agent training data
- Sectors: global products, localization
- Tools/products/workflows: generate trajectories from target-language corpora to train region-specific agents; maintain tool schemas consistently across locales
- Assumptions/dependencies: multilingual LLMs; locale-specific compliance and terminology validation
Long-Term Applications
The following use cases require further research, scaling, integration with real systems, stronger safety guarantees, and/or standardization before full deployment.
- Universal text-to-agent platform (GEM Studio) at web scale
- Sectors: SaaS platforms, ML tooling
- Tools/products/workflows: end-to-end service that ingests large heterogeneous corpora, auto-extracts workflows/tools, generates complex multi-turn datasets, and fine-tunes generalist agents
- Assumptions/dependencies: large-scale data pipelines; robust deduplication/quality controls; governance and auditability
- Auto-instrumentation: from text to bound, executable tools
- Sectors: software integration, enterprise IT
- Tools/products/workflows: generate API wrappers, parameter contracts, and bindings to live systems directly from documentation; semi-automatic wiring into agent runtimes
- Assumptions/dependencies: strong codegen reliability; human-in-the-loop approval; secrets management, RBAC, and secure endpoints
- Continual compliance agents for dynamic regulations
- Sectors: healthcare (claims, prior auth), finance (KYC/AML), energy (grid ops), public sector
- Tools/products/workflows: continuous ingestion of updated policies to refresh tool schemas and dialogues; change-aware retraining; policy drift detection
- Assumptions/dependencies: legal audits; model risk management; documented exception handling and escalation paths
- Healthcare administration automation (end-to-end)
- Sectors: healthcare administration, payers/providers
- Tools/products/workflows: agents that execute multi-step claims, reimbursement, scheduling using FHIR/HL7/EHR connectors; robust error recovery and clarifications
- Assumptions/dependencies: PHI privacy (HIPAA), integration testing with real systems, high accuracy thresholds, human oversight for adverse cases
- Robotics and embodied agents trained from manuals
- Sectors: robotics, manufacturing, field service
- Tools/products/workflows: convert maintenance/service manuals into executable procedural plans; simulate tool-use; bridge to perception/action policies
- Assumptions/dependencies: mapping language steps to sensorimotor actions; sim-to-real transfer; safety certification
- Adaptive lab tutors across disciplines
- Sectors: EdTech, STEM education
- Tools/products/workflows: integrate with domain tools (MATLAB, CAD, JupyterHub, chemistry simulators) for hands-on multi-turn workflows; individualized error recovery paths
- Assumptions/dependencies: licenses for proprietary tools; rigorous pedagogy studies; accessibility compliance
- Dual-control customer-service agents (tau2-style) in production
- Sectors: contact centers, retail, travel, telecom
- Tools/products/workflows: agents that coordinate tool use with customers, guide user actions, and enforce policies; real-time monitoring and outcome tracking
- Assumptions/dependencies: robust tool ecosystems; user guidance UX; reliability under ambiguity; escalation policies
- Enterprise knowledge-to-workflow operating system
- Sectors: enterprise KM, process mining
- Tools/products/workflows: automatically discover, standardize, and version internal workflows; unify tool schemas and agent behaviors; “agent OS” for internal processes
- Assumptions/dependencies: data governance; taxonomy/ontology alignment; change management across teams
- Open standards for text-derived tool schemas and trajectory formats
- Sectors: software standards bodies, research consortia
- Tools/products/workflows: community specifications for function schemas, trajectory structure, validation protocols, and benchmark suites
- Assumptions/dependencies: multi-stakeholder coordination; interoperability testing; security and safety clauses
- Safety and robustness frameworks grounded in GEM-style validation
- Sectors: ML safety, agent reliability
- Tools/products/workflows: standardized argument-grounding checks, hallucination filters, and structural verifiers integrated into agent runtimes; audit trails and explainability
- Assumptions/dependencies: accepted metrics for real-world success; calibration of judges; performance/latency trade-offs
- Energy operations assistants
- Sectors: energy, utilities
- Tools/products/workflows: derive SOPs (SCADA/EMS) into agent workflows; controlled tool calls for monitoring and incident response; multi-turn error-handling patterns
- Assumptions/dependencies: high safety thresholds; secure integrations; regulator approvals
- Finance back-office automation (reconciliation, KYC/AML)
- Sectors: finance, fintech
- Tools/products/workflows: agents executing complex, multi-step workflows across disparate systems; compliance logs and auditability
- Assumptions/dependencies: strict governance; explainability requirements; integration tests in non-production before rollout
Notes on overarching assumptions and dependencies:
- Data quality and rights: legality of processing text corpora (internal and public), privacy constraints, de-identification where needed.
- Model capabilities and cost: strong teacher models for initial synthesis, adequate compute, efficient distillation via the Trajectory Synthesizer.
- Domain validation: expert-in-the-loop for safety-critical sectors; alignment of synthesized tools to real-world systems and constraints.
- Simulation-to-production gap: differences between simulated tool outputs and live system behavior; need for gradual, staged integration and monitoring.
- Security and safety: strict guardrails on tool invocation, parameter grounding, RBAC, and incident response policies.
Collections
Sign up for free to add this paper to one or more collections.