daVinci-Dev: Agent-native Mid-training for Software Engineering
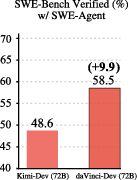
Abstract: Recently, the frontier of LLM capabilities has shifted from single-turn code generation to agentic software engineering-a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, agentic mid-training-mid-training (MT) on large-scale data that mirrors authentic agentic workflows-remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is agent-native data-supervision comprising two complementary types of trajectories: contextually-native trajectories that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and environmentally-native trajectories collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model's agentic capabilities on SWE-Bench Verified. We demonstrate our superiority over the previous open software engineering mid-training recipe Kimi-Dev under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve 56.1% and 58.5% resolution rates, respectively, which are ...

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This paper is about teaching LLMs to act more like helpful, independent software engineers. Instead of just writing a single piece of code when asked, the goal is for the model to work through real projects: find the right files, read and understand the code, make changes, run tests, and fix mistakes—much like a human developer.
The authors introduce “daVinci-Dev,” a training method that focuses on the middle stage of a model’s development (called mid-training). They create special training data that looks and feels like real software work, so the model learns the habits and step-by-step thinking needed to solve issues in big codebases.
Key Questions the Paper Tries to Answer
- How can we train LLMs to handle real software engineering tasks, not just single code snippets?
- What kind of training data best teaches models to work in multi-step, feedback-driven workflows (read code → edit → test → revise)?
- Can mid-training on realistic, large-scale “agent-like” data make models stronger than relying mainly on expensive post-training methods like reinforcement learning?
Methods and Approach (Explained Simply)
Think of training an LLM like teaching a new teammate to code. If you only show them finished files, they won’t learn how to get there. They need the process: searching for the right files, understanding the problem, making changes, and learning from test results. That’s what this paper focuses on.
- Mid-training (MT): This is a middle phase of training where the model learns domain-specific habits at scale (here, software engineering). It’s different from post-training, which is smaller, more targeted fine-tuning.
- Agent: A model that doesn’t just answer once—it takes actions step by step (like opening files, editing code, and running tests), observes what happens, and decides what to do next.
- Trajectories: These are “step-by-step stories” of an agent solving a problem, including each action and the feedback it gets (like test results or error messages).
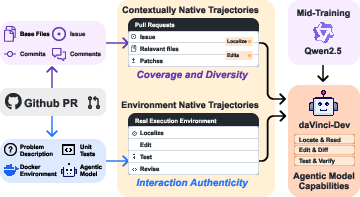
Two kinds of “agent-native” training data
The authors build two complementary types of data that match real development work:
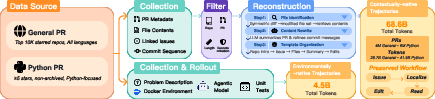
- Contextually-native trajectories (68.6 billion tokens):
- What they are: Reconstructed “workflows” from GitHub Pull Requests (PRs). A PR is a suggested change to a project that includes what changed and why.
- What they include: The problem description, relevant files (found by analyzing the PR), and the series of edits across commits, plus helpful summaries.
- Why it matters: It teaches the model the full context—how to find the right files and how edits relate to that context—like reading a complete recipe with steps.
- Environmentally-native trajectories (about 3.1 billion tokens, upsampled to ~4.5B effective):
- What they are: Real recorded agent sessions in executable environments (using Docker and actual unit tests) where the agent edits code and runs tests, seeing true error messages and results.
- Why it matters: It teaches the model to deal with real feedback—like practicing cooking in a real kitchen and reacting to what actually happens, not just reading instructions.
Together, this “agent-native” data helps the model learn both the big-picture workflow and the gritty details of fixing code with real tools and tests.
Main Findings and Why They’re Important
To introduce the results, here are the key outcomes the authors report:
- Strong performance on a tough benchmark:
- On SWE-Bench Verified (a respected test for agent-style coding), their models achieve:
- 56.1% resolution with a 32B model
- 58.5% resolution with a 72B model
- These results are state-of-the-art among open training recipes that use agent frameworks at these model sizes.
- Better than previous open methods with less mid-training data:
- Compared to Kimi-Dev (another open recipe), daVinci-Dev achieves higher scores using fewer mid-training tokens (73.1B vs. ~150B).
- This shows their data is more “information-dense” and closer to the real work the agent will do.
- General improvements beyond agent workflows:
- The trained models also do better on regular code generation (like HumanEval and EvalPlus) and on scientific reasoning tasks (like GPQA), suggesting the habits learned from realistic coding workflows improve overall reasoning.
- Synergy between the two data types:
- Mixing the two kinds of data works best: PR-based workflows provide breadth and context; environment-based trajectories add authentic, feedback-driven practice. Together, they lead to the strongest models.
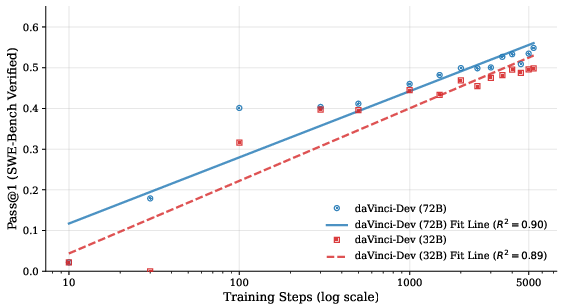
- Scaling looks promising:
- As training continues on this kind of data, performance steadily increases, which suggests more data and compute would bring further gains.
Implications and Potential Impact
- Teaching the “process,” not just the “answer”: By mid-training on realistic, agent-like data, models learn how to work through problems, not just write code once. That makes them more useful for real-world software engineering.
- More efficient development of code agents: Instead of relying mostly on costly reinforcement learning, strong mid-training can build solid foundations, making later fine-tuning easier and cheaper.
- Better tools for the community: The authors plan to open-source much of the data, recipes, and model checkpoints, which can help researchers and developers build better agent systems and explore this underused training stage.
- Broader reasoning benefits: The same step-by-step, feedback-aware thinking that helps in coding seems to carry over to scientific and general reasoning tasks, hinting at a wider impact beyond software.
In short, daVinci-Dev shows that training models in the middle phase with realistic, process-preserving data helps them act like capable software engineers—navigating projects, making edits, and learning from tests—while also improving their general reasoning skills.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated as concrete, actionable directions for future research.
- Ground-truth agent workflows: The contextually-native trajectories reconstruct developer behavior from PR diffs and metadata without actual human interaction logs; collect and compare against instrumented IDE/editor traces or developer telemetry to validate reconstruction fidelity.
- Role of LLM-generated enhancements: PR and commit summaries are produced by Qwen3-235B; perform ablations to quantify their impact, measure hallucination rates, and evaluate training with raw PR data vs. LLM-augmented text.
- Agent/scaffold bias in rollouts: Environmentally-native trajectories are produced by GLM-4.6 within SWE-Agent; replicate rollouts using multiple agents and scaffolds (e.g., OpenHands, MOpenHands, R2E-Gym) to test for learned biases and cross-scaffold generalization.
- Coverage and representativeness of executable environments: Only PRs that can be Dockerized with runnable tests are included; systematically measure coverage, characterize excluded PRs (e.g., missing tests, complex CI), and extend environments to include CI scripts, external services, databases, and non-Python build systems.
- Selection bias in PR filters: The Python subset restricts to 1–5 changed Python files and public repos with ≥5 stars; assess performance on larger, multi-file/multi-language PRs, low-star repos, and refactor-heavy PRs to understand generality.
- Language/tooling diversity: Evaluation is Python-centric (SWE-Bench Verified); benchmark on multi-language datasets and tasks (e.g., Java, JS, C/C++, Rust) with language-specific tooling, compilers, and package managers to validate cross-language efficacy.
- Authenticity of reconstructed agent actions: The “search-and-replace”/diff formats may not faithfully mirror real tool APIs; compare with more granular tool-call logs (e.g., file search parameters, editor commands) to identify schema mismatches and their training impact.
- Failure vs. success trajectories: Non-passing rollouts are included without filtering; analyze negative transfer, propose curriculum schedules or weighting strategies (success vs. failure) and study their effect on convergence and robustness.
- Mixing strategy and sampling ratios: Trajectories are upsampled 3×; conduct detailed ablations on weighting, scheduling (e.g., staged mixing), and curriculum policies to optimize mid-training composition.
- Data quality and noise quantification: No quantitative quality metrics or confidence signals are reported for PR reconstructions and rollouts; develop automatic validators (e.g., patch applicability, edit consistency), noise estimation, and sample-level quality scoring.
- Decontamination scope and leakage risks: Decontamination is stated for SWE-Bench Verified; extend and document systematic decontamination for all external eval suites (HumanEval, EvalPlus, DS-1000, GPQA, SciBench), including the PR-derived corpora.
- Evaluation breadth and scaffold dependence: Results are reported under SWE-Agent with fixed settings; evaluate across multiple scaffolds and toolchains, and test transfer to different action spaces and observation formats.
- Metric coverage: Primary metric is Pass@1; include Pass@k, time-to-resolution, number of edits, test runs, tool-call efficiency, patch minimality, and robustness under stochasticity (varying temperature, tool outputs).
- Variance and stability: Averages across four runs are reported without error bars; report standard deviation, seed sensitivity, and perform robustness checks (e.g., flaky tests, environment nondeterminism).
- Sensitivity to step/context limits: Evaluation uses 100 steps and 128k context; ablate step limits, context truncation, and memory management strategies (e.g., retrieval, summarization) to determine sensitivity and optimal settings.
- Compute, cost, and energy transparency: Training budgets (GPU-hours, energy, cost), optimizer settings, token mixing schedules, and throughput are not detailed in the main text; provide full cost-performance scaling, efficiency metrics, and carbon accounting.
- Licensing, compliance, and privacy: Training on PR content raises license heterogeneity and privacy concerns; document license filtering, redistribution permissions, anonymization, and memorization audits.
- Generalization mechanisms beyond code: Scientific benchmark gains are modest and not explained; perform targeted studies on non-code agentic tasks (e.g., notebook-based data science, devops workflows) to identify which agentic patterns transfer.
- Interplay with RL: The recipe emphasizes MT+SFT without RL; run controlled studies on MT→SFT→RL sequencing, data re-use, and whether mid-training reduces RL sample complexity or improves stability.
- Cross-model portability: Experiments start from Qwen2.5-Base; evaluate portability to other families (Llama, Mistral, DeepSeek, CodeLlama) and code-specialized bases to quantify dependence on base model priors.
- Scaling frontiers: Scaling curves suggest unsaturated performance but are limited to ; extend scales with broader PR corpora, longer trajectories, larger action vocabularies, and richer environment interactions to test continued gains.
- Reproducibility of environment builds: Dependence on SWE-rebench-like process is noted; report the success rate of Docker reconstruction, prevalence of flaky tests, environment drift, and standardized procedures to ensure reproducibility.
- Manual test fixes: Some SWE-Bench test cases were manually fixed; enumerate these changes, quantify their effect on scores, and provide patched tests to ensure fair and reproducible comparisons.
- Missing or weak problem statements: Many PRs lack linked issues or have terse messages; evaluate the effect of absent/weak task descriptions and the quality of synthetic issue generation on training and evaluation.
- Edit locality vs. broader refactoring: The datasets emphasize changed files; add tasks involving large-scale refactoring, API changes, and multi-repo coordination to test broader engineering competencies.
- Tooling breadth: Actions focus on search, read, edit, test; incorporate debugging tools, static analysis, linters, formatters, profilers, performance tests, build orchestration, and deployment tasks to diversify interaction patterns.
- Release scope and reproducibility: “Where permitted” leaves dataset/checkpoint availability ambiguous; specify exact artifacts, licenses, and versions to enable replication and downstream research.
- Effective token definition: The paper references “∼4.5B effective tokens” for trajectories; clearly define “effective tokens,” their computation (e.g., upsampling, packed sequences), and how they map to optimization steps.
- Failure mode taxonomy: No qualitative analysis of common failure modes is provided; produce error taxonomies (e.g., localization mistakes, brittle edits, test misinterpretation) and targeted data augmentations to address them.
Glossary
- Action–observation loop: The iterative structure where an agent takes an action and receives an observation, forming sequential pairs used to solve tasks. "sequential action-observation pairs "
- Agent-native data: Supervision data that preserves the full information flow and environment dynamics an agent experiences during deployment. "agent-native dataâsupervision comprising two complementary types of trajectories"
- Agent trajectory: The complete sequence of a task’s interactions, including actions, observations, and outcome. "This complete sequence is an agent trajectory "
- Agentic mid-training: An intermediate large-scale training stage on agent-like data to instill foundational agent behaviors before fine-tuning. "agentic mid-trainingâmid-training (MT) on large-scale data that mirrors authentic agentic workflowsâremains critically underexplored"
- Agentic scaffold: The agent framework and tooling that structure interactions (e.g., tools, steps) for solving software tasks. "under two post-training settings with an aligned base model and agentic scaffold"
- Agentic software engineering: A paradigm where models autonomously navigate, edit, and test complex repositories to resolve issues. "agentic software engineeringâa paradigm where models autonomously navigate, edit, and test complex repositories."
- Contextually-native trajectories: Reconstructed workflows that bundle localization, reading, and editing with full task context. "Contextually-native trajectories: This type of trajectory emphasizes coverage and diversity."
- Decontamination: The process of removing overlapping training data from evaluation sets to prevent leakage. "For decontamination, we remove all pull requests from repositories included in SWE-Bench Verified"
- Distribution mismatch: A gap between the static training data and the dynamic, feedback-rich deployment environment. "A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development."
- Docker image: A containerized snapshot of an environment used to reproduce repository states and run tests. "We build a Docker image for each task"
- Environmentally-native trajectories: Trajectories collected from real executable environments that capture authentic tool outputs and test feedback. "Environmentally-native trajectories: This type of trajectory prioritizes interaction authenticity while also considering quantity."
- Evaluation oracle: A mechanism (often a test suite) that determines task success or failure. "and is an evaluation oracle (typically a test suite)."
- Factorized approach: Training strategy that isolates and trains subskills separately, losing procedural context. "predominantly adopt a factorized approach: synthesizing isolated samples for atomic capabilities"
- Log-linear relationship: A scaling pattern where performance increases linearly with the logarithm of training steps or data. "We observe a robust log-linear relationship between training steps and Pass@1 performance"
- Mid-training (MT): An intermediate training stage shifting capability distribution using domain-specific corpora at scale. "Mid-training (MT) on domain-specific data has proven transformative for specializing LLMs"
- Observation generator: The component that produces observations in response to agent actions within a repository state. "receives an observation from an observation generator:"
- Pass@1: The probability or rate of solving a task on the first attempt. "and report Pass@1, averaged across 4 runs."
- Patch diffs: Textual representations of code changes showing added and removed lines in patches. "XML-like tags with traditional patch diffs"
- Post-training: The stage after pre/mid-training that aligns behavior via SFT and/or RL. "post-training: supervised fine-tuning (SFT) on curated trajectories"
- Pre-training: Large-scale next-token prediction on broad corpora to learn general language/code representations. "Pre-training. Large-scale next-token prediction on diverse corpora."
- Resolution rates: The fraction of issues successfully resolved by a model or agent. "achieve 56.1\% and 58.5\% resolution rates"
- Rollouts: Recorded action–observation sequences generated by running an agent in an environment. "we generate up to 4 rollouts, recording the complete action-observation sequences"
- Supervised fine-tuning (SFT): Training on demonstration trajectories to teach specific behaviors. "post-training: supervised fine-tuning (SFT) on curated trajectories"
- SWE-Agent: An agentic framework used to evaluate and operate models on software engineering tasks. "We evaluate on SWE-Bench Verified using SWE-Agent (temperature 0, 128k context and 100 steps)"
- SWE-Bench Verified: A benchmark of executable software engineering tasks for evaluating agentic code models. "We verify the modelâs agentic capabilities on SWE-Bench Verified."
- Symmetric diffs: Diffs aggregated across commits to identify modified files and reconstruct changes over time. "analyzing symmetric diffs across all commits"
- Tool invocations: Calls to external tools (e.g., search, tests, linters) made by an agent during problem solving. "tool invocations, test executions, runtime errors"
- Upsample: To increase a dataset’s sampling frequency or weight during training. "We upsample during training."
- Zero-shot: Performing a task without task-specific fine-tuning or SFT. "In the zero-shot setting (top section), training on environmentally-native trajectories alone yields 47.1\% (72B)."
Practical Applications
Practical Applications of daVinci-Dev: Agent-Native Mid-Training for Software Engineering
The paper introduces a mid-training recipe and data design (contextually-native PR reconstructions and environmentally-native agent rollouts) that measurably improves repository-level software engineering agents. Below are actionable applications derived from its methods, datasets, and findings, grouped by time horizon and linked to sectors, with assumptions and dependencies noted.
Immediate Applications
These can be piloted or deployed now with current tooling (e.g., SWE-Agent scaffolds, Dockerized CI, Qwen2.5-based models, released datasets/checkpoints).
- Software/DevTools: Repository-level triage and repair assistants
- Use case: Bug localization, minimal patch proposals, and test-driven verification in CI pipelines.
- Sector: Software.
- Product/workflow: “CI Repair Bot” that (i) reproduces failing tests, (ii) localizes files, (iii) proposes diffs, (iv) runs tests in sandbox, (v) opens PRs tagged “AI-suggested”.
- Assumptions/dependencies: Reasonable unit test coverage; reproducible builds via Docker; permissions to run tool calls (search, edit, test); human-in-the-loop code review; licensing compliance for model/data use; long-context inference budget.
- Development velocity tools for maintainers and teams
- Use case: PR summarization, commit message enrichment, review hinting, and change-impact analysis using reconstructed PR trajectories.
- Sector: Software, Open-source.
- Product/workflow: “PR Copilot” integrated with GitHub/GitLab that generates PR intent summaries, commit rationales, and risk hotspots; auto-suggests reviewers and test cases.
- Assumptions/dependencies: Access to PR metadata and base files; guardrails to avoid hallucinated claims; org policy alignment on AI-assisted reviews.
- Failure analysis and test debug assistants
- Use case: Automatic parsing of flaky or failing CI jobs; proposing hypotheses and edits; re-running targeted tests.
- Sector: Software, DevOps (AIOps).
- Product/workflow: “CI Failure Coach” sidebar in CI dashboards that links logs to code and proposes stepwise fix sequences; automated bisecting of commits.
- Assumptions/dependencies: Structured logs and deterministic test execution; dockerized runners; access to code and test suites.
- Codebase onboarding and navigation tutors
- Use case: New developer onboarding via replayable trajectories that show how issues were discovered, context gathered, and edits applied.
- Sector: Software, Education (developer training).
- Product/workflow: “Trajectory Replay” plug-in for IDEs that maps from issue → files → diffs → tests, with generated explanations per commit.
- Assumptions/dependencies: Availability of PR history and code; acceptable logging of agent actions; integration with IDEs.
- Internal model activation and SFT bootstrapping using open agent-native corpora
- Use case: Fine-tune or mid-train enterprise models on contextually-native PR data and environmentally-native rollouts to boost agentic coding in private repos.
- Sector: Software, Enterprise IT, Finance, Healthcare (internal tools).
- Product/workflow: “Agent-Native Fine-Tuning Kit” using the paper’s open datasets, templates, and MT/SFT configs to align base models with internal codebases.
- Assumptions/dependencies: Data governance approvals for mixing open corpora with internal code; secure training infrastructure; decontamination to avoid leakage.
- Automated API deprecation and dependency update helpers (human-in-the-loop)
- Use case: Suggest code edits for library upgrades based on multi-commit PR patterns learned from contextually-native trajectories.
- Sector: Software.
- Product/workflow: “Deprecation Assistant” that scans for deprecated APIs, proposes batched diffs, and runs regression tests.
- Assumptions/dependencies: Adequate test coverage; migration guides; ability to run large-context analysis across the repo.
- Repository state reproducers for bug reproduction
- Use case: On-demand sandbox creation reproducing historical PR states to validate fixes and re-run tests.
- Sector: Software, QA.
- Product/workflow: “PR-to-Docker” builder (using SWE-rebench-like pipelines) that reconstructs environment at chosen commits for deterministic reproduction.
- Assumptions/dependencies: Access to historical commits, pinned dependency manifests, deterministic build chain.
- Academic research enablement on agentic workflows
- Use case: Study scaling laws for agent-native mid-training, effect of feedback-rich trajectories, and data mixture composition.
- Sector: Academia (ML, SE).
- Product/workflow: Reproducible experiments with the released datasets/checkpoints; ablations on PR-only vs. rollout mixes; curriculum scheduling.
- Assumptions/dependencies: Compute resources for MT/SFT; adherence to dataset licenses; standardized scaffolds (SWE-Agent).
- Governance and compliance workflows around AI-assisted code changes
- Use case: Audit trails and provenance for AI-generated diffs; license and PII checks for PR-derived training data.
- Sector: Policy, Legal, Compliance.
- Product/workflow: “AI Change Ledger” that logs agent actions, environment outputs, and review outcomes; automated OSS license compliance checks.
- Assumptions/dependencies: Policy frameworks for AI-produced code; tooling for SBOMs and license scanning; secure artifact retention.
- Education: stepwise learning resources using PR reconstructions
- Use case: Teaching test-driven development and debugging via real-world, stepwise PRs.
- Sector: Education.
- Product/workflow: Interactive coursework where students navigate issue → localization → edits → tests, with model-generated guidance.
- Assumptions/dependencies: Curated PR tasks appropriate for instruction; sandboxed environments.
Long-Term Applications
These require additional research, scaling, validation, and/or organizational and regulatory evolution.
- Autonomously maintained repositories with guarded merge policies
- Use case: Agents continuously address issues, update dependencies, refactor code, and maintain quality gates.
- Sector: Software, Enterprise IT.
- Product/workflow: “Self-Healing Repo” where agents plan, implement, and test multi-PR roadmaps; merge gated by policy, proofs, or structured reviews.
- Assumptions/dependencies: Stronger reliability and calibration; formal or statistical guarantees; robust rollback and blast-radius controls; richer tests and property checks.
- Organization-scale vulnerability remediation and compliance upkeep
- Use case: Fleet-wide detection and patching of security issues and policy violations across microservices and monorepos.
- Sector: Software, Finance, Healthcare, Government.
- Product/workflow: “Compliance Agent Mesh” coordinating repo-level agents with centralized risk scoring and sign-off workflow.
- Assumptions/dependencies: Enterprise-grade identity, logging, and approvals; SBOM integration; vulnerability scanners; sector-specific compliance (e.g., SOC2, HIPAA).
- Cross-domain agent-native mid-training beyond code (data engineering, MLOps, ops/SRE)
- Use case: Agents that execute action–observation loops in ETL pipelines, notebook-driven science, CI/CD, incident response (playbooks), or cloud ops.
- Sector: Data, MLOps, Cloud/DevOps, Scientific computing.
- Product/workflow: “Agent-Native Ops Models” trained on action logs, runbooks, tickets, and environment feedback (metrics, alerts, traces).
- Assumptions/dependencies: High-quality telemetry and tool APIs; safe sandboxes; evaluation oracles (e.g., canary tests); stronger safety/rollback rules.
- Safety-critical software engineering with formal methods integration
- Use case: Agents co-design and verify changes for domains like automotive, aerospace, medical devices.
- Sector: Healthcare, Automotive, Robotics, Energy.
- Product/workflow: “Verified Code Agent” combining agent-native MT with formal specs, model checking, and HIL/SIL tests.
- Assumptions/dependencies: Formal specifications; certifiable toolchains; regulatory approvals; traceable proofs of correctness.
- Test synthesis and specification induction at scale
- Use case: Automated generation of missing unit/integration/property tests and inferred module-level contracts.
- Sector: Software, QA.
- Product/workflow: “Spec & Test Generator” that observes edit→test→revise loops and proposes new tests to expand coverage and lock in behavior.
- Assumptions/dependencies: Ground-truth oracles for correctness; flaky-test mitigation; cost-aware test selection; alignment to coding standards.
- Agent-native IDEs and developer environments
- Use case: Development environments that natively expose tool feedback streams (build, test, runtime) to agents and humans for shared control.
- Sector: Software.
- Product/workflow: “Agent-First IDE” where action–observation loops are first-class, supporting multi-step plans, replay, and explainable decisions.
- Assumptions/dependencies: IDE APIs and permissioned tool execution; low-latency long-context inference; UX for joint control.
- Standardized governance, evaluation, and procurement frameworks for code agents
- Use case: Sector-wide standards for telemetry, data provenance, auditability, and evaluation of autonomous code changes.
- Sector: Policy, Standards bodies, Enterprise procurement.
- Product/workflow: “Agent Evaluation Suite” plus policy templates (risk tiers, required tests, approval workflows, SLAs, liability allocation).
- Assumptions/dependencies: Multi-stakeholder consensus; public benchmarks for end-to-end tasks; legal clarity on AI-contributed code.
- MT-as-a-service and trajectory telemetry ecosystems
- Use case: Services that (i) instrument agent workflows, (ii) collect environment-native trajectories, and (iii) produce domain-specialized mid-trained models.
- Sector: AI infrastructure, Platform providers.
- Product/workflow: “Agent Telemetry SDK” + “Domain MT Service” that turns customer action logs into safe, privacy-preserving MT corpora.
- Assumptions/dependencies: Robust anonymization/PII stripping; customer data governance; efficient long-context training.
- Large-scale legacy modernization and API ecosystem transitions
- Use case: Automated multi-repo refactors, framework migrations, or monolith-to-microservices transformations with iterative testing.
- Sector: Software, Enterprise IT.
- Product/workflow: “Modernization Planner Agent” that proposes phased changes, opens coordinated PRs, and validates with integration tests.
- Assumptions/dependencies: Extensive integration tests; cross-repo orchestration; change-management policies; staged rollouts and canarying.
Notes on feasibility across applications:
- Data and compute: Mid-training benefits increase with token scale and model capacity; organizations need access to GPUs and long-context inference.
- Tests as oracles: High-quality, fast test suites are pivotal; where absent, adoption requires test authoring or alternative oracles (property tests, monitors).
- Security and compliance: Sandbox execution, least-privilege access, audit trails, and license compliance are required for production use.
- Human-in-the-loop: For most near-term deployments, maintain human review and gated merges; gradually automate as reliability improves.
- Licensing and privacy: Mining PRs at scale must respect repository licenses and remove PII; internal deployments must segregate proprietary code.
Collections
Sign up for free to add this paper to one or more collections.