AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Abstract: LLMs based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AgencyBench, a big test that checks how well AI “agents” (smart programs powered by LLMs) can handle long, real-world tasks. Think of projects that take many steps, lots of back-and-forth, and use several apps and tools—like building a simple video game, making a website, or researching a company. The goal is to measure how good different AIs are at doing these kinds of jobs from start to finish, and to do it automatically without needing a human to help at every step.
What questions did the researchers ask?
They mainly wanted to know:
- Can we build a realistic, long, and varied benchmark (test) that feels like real work?
- Can the whole test run automatically, with no humans guiding the AI during the task?
- How do top commercial (closed-source) models compare to free (open-source) models?
- How do agents use tools, fix their mistakes after feedback, and manage resources like time and “tokens”?
- Do models perform better inside their “home” ecosystems (the tools and SDKs they were designed for)?
How did they do it?
They created AgencyBench, which includes:
- 6 types of abilities: game development, front-end (web pages), back-end (servers), code generation, research, and MCP tool use (a way for AIs to use many tools).
- 32 real-world scenarios with 138 tasks. Tasks are like levels that build on each other (what you do early affects later steps).
Each task includes:
- A query: what to do (like instructions).
- Deliverables: what to hand in (files, code, working features).
- Rubrics: the scoring rules (how it will be judged).
Why this is “long-horizon”:
- On average, each scenario takes about 90 tool uses, around 1 million “tokens,” and hours to run.
- Tokens are just pieces of text the AI reads or writes—like chunks of words. More tokens = more reading/thinking/writing.
How they evaluated the work automatically:
- A user simulation agent: a “pretend user” that checks the AI’s work and gives helpful feedback if it’s not good enough (like a teacher saying which parts missed the rubric).
- A Docker sandbox: a safe, isolated computer environment where the AI’s code runs for real. It can click buttons, render webpages, record videos, and take screenshots to see if things actually work.
- Scoring: either rule-based (exact checks, like “does this file exist?” or “does this button work?”) or LLM-as-judge (an AI grader for visuals and code quality when things are subjective).
- Everything is repeatable and automated: the agent works in a “workspace,” sends results to the sandbox, and the system scores them in an “eval-space.”
A simple example:
- Build a Gomoku (five-in-a-row) web game in steps: basic board → placing pieces → win detection → restart button → nicer visuals. The sandbox runs it, clicks around, records the screen, and judges whether the game behaves correctly.
What did they find?
Here are the key results in plain terms:
- Closed-source models beat open-source models overall.
- Average scores: closed-source about 48%, open-source about 32%.
- Even the best models still struggle with these long, real-world tasks—so this is hard.
- Feedback helps many models improve.
- When the “pretend user” gives feedback, some models fix mistakes quickly and boost their pass rates a lot; others barely improve.
- Resource use varies a lot.
- Some models use many tokens and turns to get good results (more “brute force” thinking), while others are faster and use fewer tokens but might score lower.
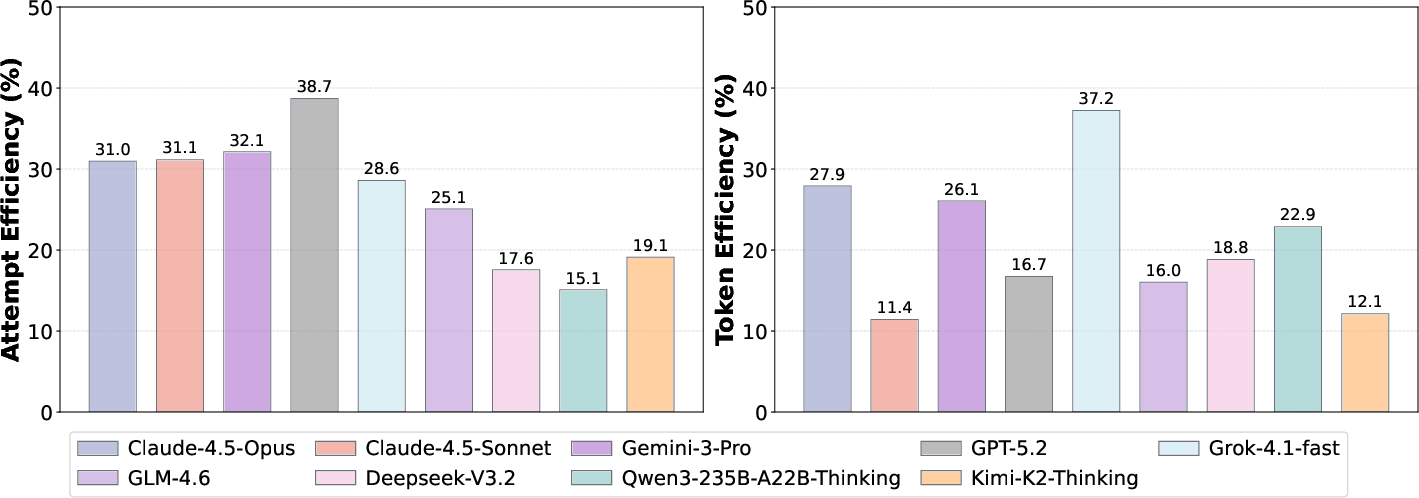
- Efficiency trade-offs:
- One model did best per attempt (needed fewer retries to succeed), while another did best per token (more cost-efficient).
- Some models generated tons of text (high token use) without getting better scores—so more isn’t always better.
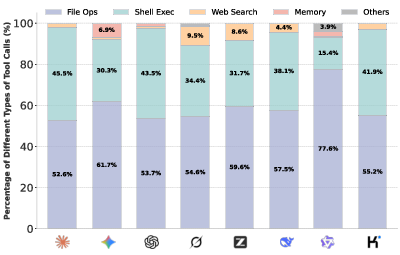
- Tool-use styles differ by model (“personalities”):
- Some prefer shell/terminal commands (system-level actions).
- Some rely on file operations and memory tools (organizing long-term context).
- Others depend more on web search.
- “Home-field advantage” is real:
- Models often perform better when used with their own company’s agent frameworks/SDKs.
- Open-source models can perform better or worse depending on the agent framework they run in.
Why does this matter?
- Real-world readiness: Many current AIs are good at short tasks, but long, multi-step projects are a different challenge. AgencyBench shows where they still fail—and how to improve.
- Better design of AI agents: It’s not just the model that matters; the tools, prompts, and framework around it can change performance a lot. Co-optimizing the model and the agent framework is key.
- Less human labor: Because this benchmark runs automatically, researchers and companies can test agents at scale without humans guiding every step.
- Clear goals for improvement: The results highlight areas to focus on—like using fewer tokens, getting better at self-correction, and choosing the right tools.
- Community resource: The benchmark and tools are released so others can test their own agents and push the field forward.
In short, AgencyBench is like an advanced, realistic “final exam” for AI agents. It shows that long, real-world tasks are still tough, measures which models handle them best, and points the way to building more reliable, efficient agents in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete future work:
- Coverage beyond software-centric digital tasks: the benchmark omits embodied agents, robotics, physical-world interaction, and non-code economic workflows (e.g., operations planning, supply-chain optimization, finance/trading, customer support).
- Limited domain diversity within software: tasks skew toward web/game/frontend/backend stacks (HTML/CSS/JS, shell); minimal coverage of other ecosystems (mobile apps, data engineering/ETL, ML/AI pipelines, DevOps, CI/CD, cloud configuration, database admin, security auditing).
- Language, locale, and accessibility gaps: no multilingual tasks, localization challenges, or accessibility requirements (e.g., WCAG compliance, screen-reader compatibility) included in the scenarios or rubrics.
- Reproducibility under external data drift: tasks relying on web search are vulnerable to content changes, link rot, rate limits, and time-of-day effects; no protocol for snapshotting, caching, or offline corpora to ensure stable evaluation.
- LLM-as-judge bias and calibration: judges are proprietary models (Claude-4-Sonnet, Gemini-2.5-pro), potentially introducing bias toward certain output styles; no ablation across judges, cross-judge agreement analysis, or calibration to human panels beyond a small 50-task sample.
- Judge–model entanglement: some tested models belong to the same vendor families as the judges; fairness risks remain unquantified (e.g., whether Claude judges favor Claude-produced outputs).
- Limited validation scale for judging reliability: the Kappa=0.93 result is reported on only 50 held-out tasks; no confidence intervals, domain-specific breakdowns, or stress tests (adversarial, borderline cases).
- User simulation realism: feedback reveals exact failed rubrics and reasons—more informative than typical human feedback—potentially inflating performance; no study of noisier, partial, or contradictory feedback, nor of feedback styles reflecting heterogeneous user preferences.
- Single user simulation model: feedback is generated by Claude-4-Sonnet at temperature 0.0; no exploration of alternative simulators, ensembles, persona diversity, or how simulator choice affects outcomes.
- Interaction depth restrictions: Pass@k is reported only for k ∈ {1,2}; long-horizon tasks often require many iterations—no analysis beyond 2 rounds or of diminishing returns curves.
- Ambiguities in metric definitions: the Att formula and K (max feedback rounds) are imprecisely specified; no sensitivity analysis for pass thresholds (60%), alternative scoring scales, or rubric weighting strategies.
- Statistical rigor and repeatability: results appear single-run with temperature=0.7; no seeds, variance estimates, confidence intervals, or significance testing across repeated trials and scaffolds.
- Token/context fairness: average 1M-token rollouts may exceed some models’ context windows; no control for truncation strategies, external memory mechanisms, or standardized memory scaffolding to ensure fair comparison.
- Scaffold-induced bias: a “home-field advantage” is shown, but the paper does not standardize tool semantics, prompt formats, or memory APIs across scaffolds; disentangling model capability from scaffold optimization remains unresolved.
- Tool-suite transparency: the exact tool set, interfaces, and constraints are not fully enumerated; unclear how tool definitions, error handling, and side-effects influence outcomes or bias certain strategies (shell-heavy vs. file-memory-heavy).
- Robustness to tool failures: no experiments with faulty tools, degraded network, permission errors, rate limits, or sandbox resource caps; agents’ resilience to real-world execution brittleness is untested.
- Safety and misuse resilience: beyond container isolation, the benchmark does not test prompt injection defenses, tool-output sanitization, escalation control, or harmful action prevention metrics.
- Economic cost modeling: efficiency metrics omit real-dollar API costs, energy usage, latency distributions, and throughput; no Pareto analyses balancing performance vs. monetary or environmental costs.
- Long-term memory and continuity: scenarios are multi-task but scoped per scenario; there is no evaluation of cross-scenario memory persistence, lifelong learning, or project continuity over days/weeks.
- Multi-agent collaboration: only single-agent settings are evaluated; coordination, role specialization, and communication among agent teams are unassessed.
- Generalization across time and updates: models, tools, and websites evolve rapidly; the benchmark lacks protocols for periodic re-evaluation and longitudinal tracking to measure robustness to ecosystem drift.
- Dataset construction biases: tasks were curated by 20 experts with unanimous consensus criteria, potentially biasing toward their preferences and coding styles; no diversity audit of task sources, frameworks, or difficulty calibrations.
- Programming language and platform diversity: heavy emphasis on web stacks; minimal coverage of compiled languages (Rust/Go/C++), mobile (Android/iOS), Windows/macOS specifics, cross-browser differences, or GPU/accelerator-dependent tasks.
- Evaluation granularity: a single 0–10 rubric score collapses nuanced failure modes; no submetric breakdowns (planning quality, code robustness, test coverage, UI correctness, performance, security) or standardized error taxonomy.
- Correlation with other benchmarks: no cross-benchmark validation to see if AgencyBench scores predict performance on OSWorld, SWE-Bench, UltraHorizon, Toolathlon, etc.; external validity remains an open question.
- Release of baseline rollouts: while the toolkit is released, it is unclear whether full baseline rollouts, artifacts, and logs are provided to enable apples-to-apples replication and error analysis.
- Fairness to models with different tool-use “personalities”: the observed tool preferences may reflect inductive biases; there is no controlled experiment isolating whether these strategies are adaptive or merely artifacts of the scaffold and prompts.
- Ethical and legal data considerations: web research tasks may ingest copyrighted or sensitive content; licensing compliance and data provenance controls for evaluation artifacts are not discussed.
- Scaling the pipeline: the evaluation requires hours and millions of tokens per scenario; scalability to large test suites, CI pipelines, and budget-constrained labs is unaddressed, as are strategies for task subsetting or dynamic difficulty scaling.
Practical Applications
Immediate Applications
The following applications can be deployed with the benchmark and tooling described in the paper, assuming access to supported model APIs and standard DevOps environments.
- Industry: Vendor evaluation and procurement for agentic systems
- What: Use AgencyBench and its metrics (S_avg, Pass@k, Att, token efficiency) to compare agent vendors and models for long-horizon workflows (e.g., coding assistants, RPA agents).
- Sectors: Software, enterprise IT, procurement, finance/operations.
- Tools/workflows: AgencyBench toolkit + Docker sandbox + user simulation agent; integrate evaluation dashboards; set SLAs tied to Pass@k and efficiency.
- Assumptions/dependencies: API access to candidate models; compute budget for ~1M-token/hrs-scale runs; reproducible Docker environment.
- Industry: CI/CD regression testing for agentic products
- What: Add AgencyBench scenarios as gated tests to catch regressions when updating models, prompts, or tools in agent-based apps.
- Sectors: Software QA, DevTools, platform engineering.
- Tools/workflows: GitHub Actions/GitLab CI with Docker sandbox; automated rubric scoring; LLM-as-judge for UI/game tasks.
- Assumptions/dependencies: Stable sandbox runners (headful UI support), test quotas for LLM judges; cost controls.
- Industry: Scaffold selection and “ecosystem synergy” optimization
- What: A/B test agent frameworks (e.g., Claude-Agent-SDK, OpenAI-Agents-SDK, custom) to exploit the “home-field advantage” effect.
- Sectors: Agent framework vendors, product teams.
- Tools/workflows: Swap scaffolds on the same tasks, pick best-performing pairings; document “approved scaffold/model” matrices.
- Assumptions/dependencies: Availability/licensing of SDKs; compatibility with enterprise toolchains.
- Industry: Cost-performance planning and routing
- What: Route workloads by efficiency—e.g., use Grok-4.1-Fast for cost-sensitive, GPT-5.2 for highest success per attempt; set budgets via E_att and E_tok.
- Sectors: FinOps, platform operations, cloud cost management.
- Tools/workflows: Cost dashboards integrating token consumption and attempt counts; policy-based model selection.
- Assumptions/dependencies: Transparent pricing and token accounting; stable latency/throughput.
- Industry/IT Security: Safe autonomous code execution
- What: Adopt the isolated Docker sandbox for agents that write/run code, protecting hosts and enforcing least-privilege policies.
- Sectors: Cybersecurity, DevSecOps, internal IT.
- Tools/workflows: Containerized execution with restricted networking; artifact capture for audits.
- Assumptions/dependencies: Container orchestration (Kubernetes, Nomad); compliance with internal security policies.
- Software QA: Automated evaluation of visual and interactive deliverables
- What: Use LLM-as-judge + sandbox to evaluate front-end layouts, game behavior, or UI flows without manual testers.
- Sectors: Software testing, game studios, web agencies.
- Tools/workflows: Scripted UI interactions, screenshot/video capture, rubric-driven scoring.
- Assumptions/dependencies: Reliability of LLM judges; rubric design quality; GPU/vision model access if needed.
- Product management: KPI setting and triage
- What: Define product KPIs mirroring AgencyBench metrics and use user-simulation feedback loops to prioritize failure cases.
- Sectors: Product & program management.
- Tools/workflows: Issue pipelines labeled by failing rubrics; pass thresholds for release gates.
- Assumptions/dependencies: Cross-functional agreement on rubrics; data retention for audits.
- Academia: Reproducible evaluation bed for new agent algorithms
- What: Use the 32 scenarios/138 tasks to benchmark planning, memory, and self-correction methods at 1M-token scales.
- Sectors: AI research, HCI, software engineering.
- Tools/workflows: Open benchmark and scripts; ablation studies on tools and feedback policies.
- Assumptions/dependencies: Compute/time availability; adherence to benchmark protocols.
- Academia/Industry: Toolchain design informed by model tool-use preferences
- What: Configure tool permissions and UI affordances aligned with model tendencies (e.g., shell tools for GPT-5.2, memory tools for Gemini).
- Sectors: DevTools, platform engineering.
- Tools/workflows: Tool whitelists/quotas; logging and monitoring for tool-call patterns.
- Assumptions/dependencies: Accurate capture of tool invocations; governance for high-risk tools.
- Policy/Governance: Comparable reporting standard for agentic performance
- What: Require vendors to report standardized metrics (Pass@k, Att, token usage) for procurement or risk assessments.
- Sectors: Government IT, regulated industries.
- Tools/workflows: Policy templates referencing AgencyBench metrics and sandbox constraints.
- Assumptions/dependencies: Stakeholder buy-in; update cadence for evolving models.
- Education: Safe, hands-on labs for long-horizon agent development
- What: Use the sandbox and tasks in courses teaching agent planning, tool use, and evaluation.
- Sectors: Higher education, coding bootcamps.
- Tools/workflows: Classroom Docker stacks; rubric-based grading; reflective reports on failures.
- Assumptions/dependencies: Campus compute; instructor familiarity with LLM evaluation.
- Daily life/Power users: Safe execution of AI-generated scripts
- What: Run AI-proposed scripts within a local container before adopting them on the host.
- Sectors: Individual developers, hobbyists.
- Tools/workflows: Desktop Docker + minimal rubric scripts; manual review of artifacts.
- Assumptions/dependencies: Basic container literacy; lightweight evaluation prompts.
- Cloud/Platform: Benchmark-as-a-service offerings
- What: Provide managed AgencyBench runs for customers to evaluate their agents/models.
- Sectors: Cloud providers, MLOps vendors.
- Tools/workflows: Multi-tenant sandbox orchestration; cost projection and benchmark reports.
- Assumptions/dependencies: Multi-model API brokering; billing integration.
Long-Term Applications
These applications require further research, domain adaptation, or ecosystem development before broad deployment.
- Cross-domain autonomous research assistants with closed-loop feedback
- What: Extend user-simulation + rubric pipelines to domains like legal, scientific, or healthcare literature reviews.
- Sectors: Healthcare, legal, pharma R&D.
- Tools/products: Domain-specific rubrics and evaluators; PHI/PII-safe sandboxes; audit trails.
- Assumptions/dependencies: Expert-authored rubrics; safety and compliance constraints; judge reliability in high-stakes domains.
- Regulatory certification for autonomous agents
- What: Use containerized, rubric-based evaluations as part of certification for agent safety/capability before deployment in critical systems.
- Sectors: Government, critical infrastructure, finance.
- Tools/products: Standardized test suites; third-party auditing infrastructure.
- Assumptions/dependencies: Policy consensus; standards bodies; mechanisms to manage model updates and re-certification.
- RL/training with rubric-derived signals for self-correction
- What: Convert rubric scores and user-sim feedback into training signals (e.g., RLHF/RLAIF) for more efficient, self-correcting agents.
- Sectors: Foundation model labs, startups.
- Tools/products: Data pipelines for rollouts; reward modeling; safe RL frameworks.
- Assumptions/dependencies: Access to training stacks; avoidance of reward hacking; compute costs.
- Interoperability standards for agentic scaffolds and tools
- What: Standardize tool schemas and memory APIs to reduce scaffold sensitivity and improve portability across ecosystems.
- Sectors: Agent framework vendors, open-source communities.
- Tools/products: Open specifications; conformance suites derived from AgencyBench.
- Assumptions/dependencies: Cross-vendor collaboration; backwards compatibility.
- Enterprise “RPA 2.0” for long-horizon multi-app workflows
- What: Agents execute end-to-end processes across UIs and APIs (e.g., finance close, claims processing) with sandboxed dry-runs and rubric gates.
- Sectors: Finance, insurance, operations.
- Tools/products: Secure UI automation with visual verification; compliance logging; escalation workflows.
- Assumptions/dependencies: Integration with legacy systems; privacy/governance controls; high-quality task rubrics.
- Adaptive agentic IDEs and model routing within developer tools
- What: IDEs dynamically choose model+scaffold combos based on task type and historical efficiency signals.
- Sectors: DevTools, software engineering.
- Tools/products: Telemetry-informed router; per-task capability profiles; cost/performance dashboards.
- Assumptions/dependencies: Fine-grained telemetry; consent and privacy; stable model behavior across versions.
- Education: Long-horizon project tutors with formative feedback
- What: Agents guide students through semester-long projects with rubric-aligned feedback loops and sandboxed code execution.
- Sectors: Higher education, MOOCs.
- Tools/products: Curriculum-aligned rubrics; plagiarism detection; student privacy safeguards.
- Assumptions/dependencies: Reliable LLM-as-judge in pedagogical settings; instructor oversight.
- Government digital services: AI case management
- What: Evaluate and deploy agents for multi-step citizen workflows (applications, benefits) with Pass@k targets and sandboxed prototyping.
- Sectors: Public sector, social services.
- Tools/products: Policy-specific rubrics; secure data enclaves; appeal and human-in-the-loop mechanisms.
- Assumptions/dependencies: Legal frameworks; data sovereignty; bias and fairness audits.
- Robotics/Embodied agents (extension)
- What: Adapt the methodology to embodied tasks via simulated environments and vision-based judges before real-world trials.
- Sectors: Robotics, logistics, manufacturing.
- Tools/products: Simulator integration (Gazebo/Isaac); sensor-rich rubric evaluators.
- Assumptions/dependencies: High-fidelity simulators; safety validation for sim-to-real transfer.
- Sustainable AI and green reporting
- What: Use efficiency metrics (E_tok/E_att) to set carbon and cost budgets for agent deployments; report “efficiency scores” in ESG reporting.
- Sectors: Large enterprises, sustainability offices.
- Tools/products: Token/energy tracking; carbon accounting integrations.
- Assumptions/dependencies: Accurate energy metering; standard conversion factors for model usage.
- Sector-specific benchmark derivations (finance, healthcare, education)
- What: Curate task libraries with industry rubrics (e.g., KYC onboarding, clinical note pipelines, curriculum design) evaluated via the same pipeline.
- Sectors: Finance, healthcare, education.
- Tools/products: Domain datasets and evaluators; compliance wrappers (HIPAA/GDPR).
- Assumptions/dependencies: Domain expert input; guardrails for sensitive content; rigorous human validation.
- Open benchmarking and leaderboards for agent frameworks
- What: Public leaderboards comparing frameworks across long-horizon tasks to drive best practices and transparency.
- Sectors: Open-source, research, vendors.
- Tools/products: Continuous evaluation infra; dataset/version governance.
- Assumptions/dependencies: Community maintenance; reproducibility standards; funding for hosting.
- Productized “synthetic user” for acceptance testing
- What: Commercialize the user-simulation agent as a plug-in for product teams to generate consistent, rubric-based feedback during UAT.
- Sectors: SaaS, internal tools.
- Tools/products: Configurable feedback modules; integration with test management suites.
- Assumptions/dependencies: Domain-specific prompt tuning; reliability guarantees for subjectivity-sensitive tasks.
Glossary
- Agentic capabilities: Distinct categories of skills an autonomous agent is evaluated on (e.g., game, frontend, backend, code, research, MCP). "evaluating 6 core agentic capabilities across 32 real-world scenarios"
- Agentic scaffold: A structured tool suite and interaction framework that enables agents to operate and generate rollouts in a controlled environment. "we utilize the agentic scaffold described in \Cref{para:scaffold}"
- Attempt Efficiency (E_att): A resource-normalized metric that divides average score by the number of attempts to measure success per interaction. "We denote as average tokens used per scenario and compute Attempt Efficiency () and Token Efficiency () to normalize performance against resource costs"
- Average Attempts (Att): The average number of feedback-driven iterations required per scenario/task, indicating autonomy and self-correction ability. "Metric: Average Attempts ()"
- Average Score (S_Avg): The rubric-based percentage score averaged across tasks, reflecting overall capability. "Metric: Average Score ()"
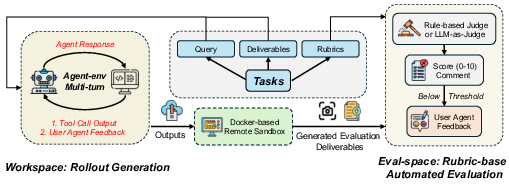
- Docker-based remote sandbox: An isolated containerized environment that simulates UI and system interactions to evaluate agent deliverables safely and reproducibly. "a Docker-based remote sandbox, which emulates human-computer operations (e.g., UI rendering, mouse/keyboard inputs) to produce visual evaluation artifacts."
- Ecosystem Synergy: The performance boost observed when a model runs within its native or specially optimized agent framework. "Experimental results reveal a significant `Ecosystem Synergy' effect"
- Eval-space: The local evaluation environment where artifacts are automatically scored via executable scripts. "These artifacts are subsequently transferred to a local eval-space, where the evaluation process is completed automatically using executable scripts without human intervention."
- Home-field advantage: The phenomenon where models perform best in their native ecosystems or optimized frameworks. "highlight a `home-field advantage', where models achieve peak performance when paired with their native or specifically optimized frameworks."
- Kappa score: A statistical measure of inter-rater agreement used to validate alignment between human and LLM judges. "The results showed a Kappa score of 0.93 between the human and LLM judge scores, demonstrating the reliability of the evaluation."
- LLM-as-judge: Using a LLM to evaluate outputs against rubrics, including textual and visual criteria. "we employ an LLM-as-judge."
- MCP tool use: The capability of agents to utilize tools defined in the Model Context Protocol ecosystem for realistic operations. "It evaluates 6 core agentic capabilities: game development, front-end development, back-end development, code generation, research, and MCP tool use."
- Multimodal judging system: An evaluation setup combining text-based and vision-based LLM judges to assess code quality and visual behavior. "Specifically for game and frontend scenarios, we implement a multimodal judging system:"
- Parametric memory: Knowledge encoded within a model’s parameters rather than external sources. "appearing to offload knowledge retrieval to external sources rather than relying on internal parametric memory."
- Pass@k: The fraction of tasks that reach the success threshold within k feedback rounds. "Metric: Pass Rate ()"
- Rollout: The recorded trajectory of states, actions, tool calls, and feedback during task execution. "We denote their individual rollouts as , , ... ."
- Rubric-based assessment: Scoring based on predefined criteria that define task success, applied to visual and functional outputs. "visual and functional rubric-based assessment."
- Rule-based evaluation: Deterministic checks and assertions derived from rubrics for tasks with objective ground truth. "we employ rule-based evaluation."
- Token Efficiency (E_tok): A resource-normalized metric that divides average score by tokens consumed to measure effectiveness per token. "We denote as average tokens used per scenario and compute Attempt Efficiency () and Token Efficiency () to normalize performance against resource costs"
- Tool invocation patterns: The distribution and preferences of tool usage (e.g., shell, file ops, web search) across different models. "Tool Invocation Patterns Across Models."
- User simulation agent: An automated agent that provides iterative feedback on unmet rubrics to mimic human-in-the-loop guidance. "We implement a user simulation agent, responsible for providing feedback to the task executing agent, enabling targeted improvements based on task execution."
Collections
Sign up for free to add this paper to one or more collections.