Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training
Abstract: LLM agents have recently shown strong potential in domains such as automated coding, deep research, and graphical user interface manipulation. However, training them to succeed on long-horizon, domain-specialized tasks remains challenging. Current methods primarily fall into two categories. The first relies on dense human annotations through behavior cloning, which is prohibitively expensive for long-horizon tasks that can take days or months. The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories on domain-specialized tasks. We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering. Instead of requiring annotators to shadow every step, Apollo allows them to intervene only when the agent drifts from a promising trajectory, by providing prior knowledge, strategic advice, etc. This lightweight design makes it possible to sustain interactions for over 30 hours and produces valuable trajectories at a lower cost. Apollo then applies supervision control to filter out sub-optimal actions and prevent error propagation. Together, these components enable reliable and effective data collection in long-horizon environments. To demonstrate the effectiveness of Apollo, we evaluate it using InnovatorBench. Our experiments show that when applied to train the GLM-4.5 model on InnovatorBench, Apollo achieves more than a 50% improvement over the untrained baseline and a 28% improvement over a variant trained without human interaction. These results highlight the critical role of human-in-the-loop sampling and the robustness of Apollo's design in handling long-horizon, domain-specialized tasks.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Apollo, a new way to train AI “agents” (smart programs that can use tools, write code, browse the web, and make plans) to handle long, complicated tasks—things that might take many hours or even days. Apollo mixes occasional human guidance with smart filtering of the agent’s actions, so the agent learns from good steps and avoids copying mistakes. The goal is to collect high-quality training data without needing a human to supervise every single move.
Key Objectives
The authors ask three simple questions:
- How can we train AI agents for long, difficult tasks without spending huge amounts of time and money on full-time human supervision?
- Can humans guide the agent only when it starts going off track—and still get good results?
- If we filter out the agent’s bad or misleading actions during training, will it learn more reliably?
Methods and Approach
Think of the agent’s work like a long hike:
- The agent takes a step (an “action”), looks around (an “observation”), and decides the next step. Over time, this becomes a “trajectory” (the full path the agent took).
- Long hikes are hard to remember, so the agent uses “summarization” (like writing neat notes of earlier steps) to keep important details in memory without overflowing its “context” (the amount it can remember at once).
- Apollo adds a coach (a human) who checks in from time to time—only when needed.
Here’s how Apollo works:
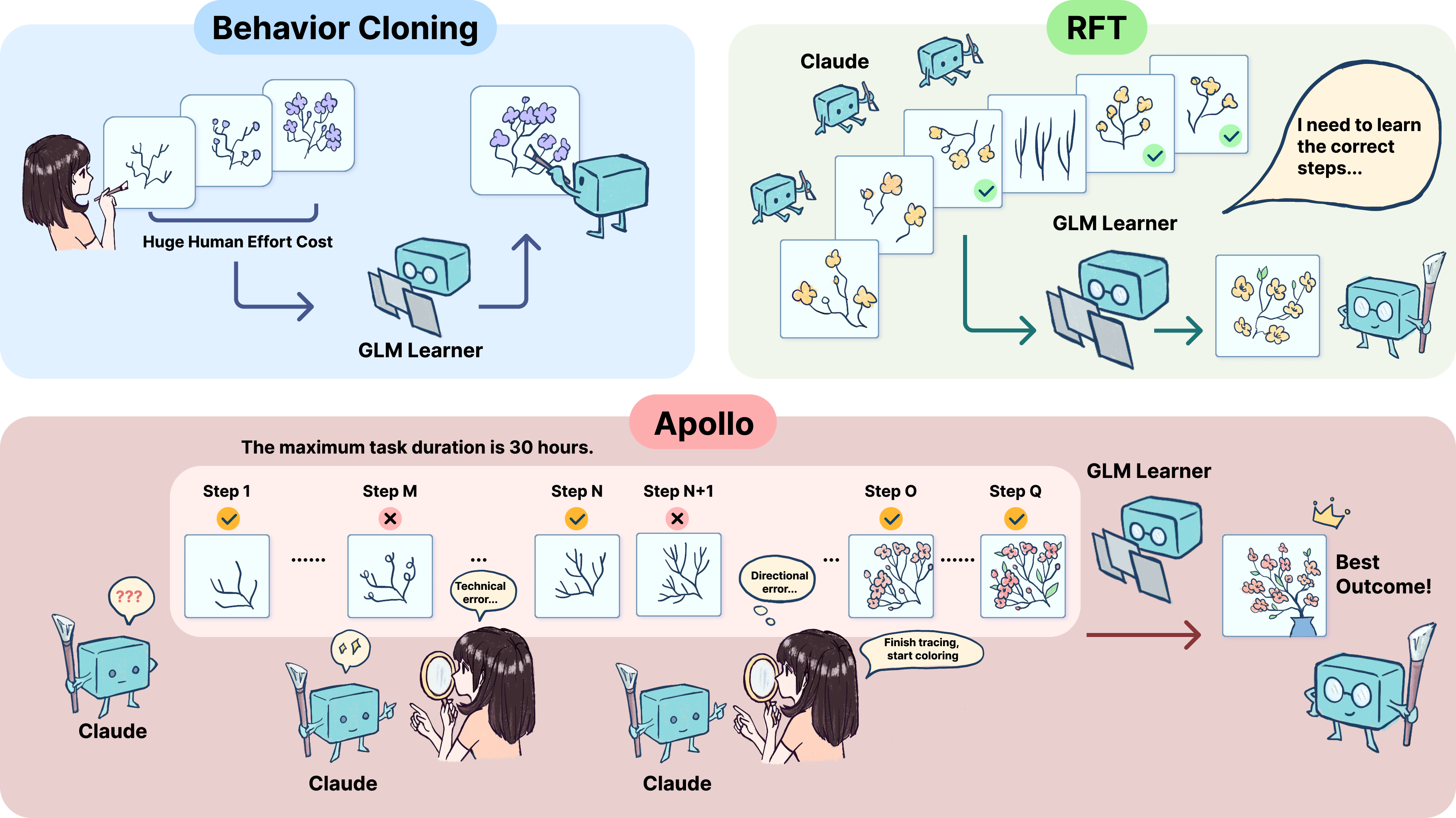
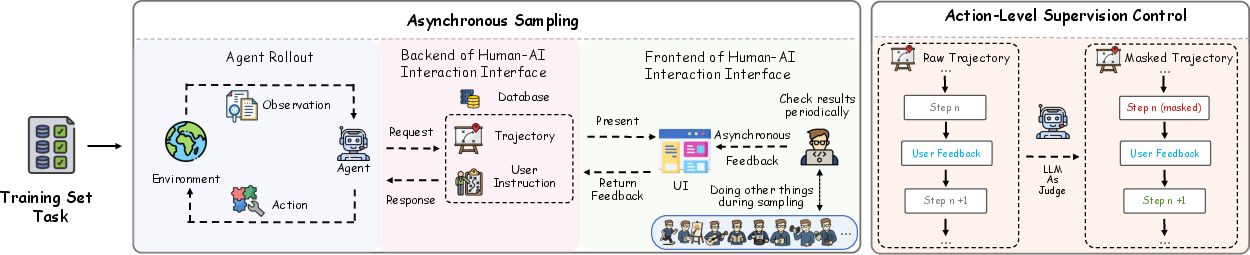
- Human–AI Interaction Interface: A simple dashboard lets a human see the agent’s progress (what files it changed, what commands it ran, what it searched) and send advice when necessary. This reduces mental effort and makes long sessions practical.
- Asynchronous Guidance: Instead of following the agent constantly, the human intervenes only when the agent drifts away from a good plan. For example, pointing out a mistake, sharing a strategy, or reminding the agent how a tool works. This is “asynchronous” because the human and agent don’t have to be active at the same exact time.
- Action-Level Filtering (Masking): When building training data, Apollo “masks” (ignores) parts of the agent’s actions that are clearly wrong or conflict with the plan or feedback. This prevents the agent from learning bad habits. Imagine training a basketball player: you keep the good shots for practice and skip the wild, off-target throws.
Technical terms explained simply:
- Trajectory: The full record of what the agent did and saw over time.
- ReAct: A loop where the agent thinks (“reasoning”) and then acts, step by step.
- Summarization: Turning long histories into compact notes the agent can still use.
- Masking: During training, only the good actions count; bad actions are ignored so they don’t teach the agent the wrong thing.
- Long-horizon tasks: Activities that require many steps and a long time to finish (e.g., a full research project with data collection, coding, training, and evaluation).
The team tests Apollo on InnovatorBench, a set of realistic AI research tasks (like collecting and cleaning data, designing training losses, building scaffolds, and running experiments). They train an open-source model (GLM-4.5) with Apollo and compare results to other models and versions without human interaction or without masking.
Main Findings
Apollo shows strong improvements:
- Big performance gains: Training GLM-4.5 with Apollo led to over 50% improvement versus the original model and 28% better than a version trained without human guidance.
- Better patience and planning: Apollo waits appropriately for long processes (like model training) instead of stopping too early, and it adapts its strategy based on real feedback.
- Filtering helps: Masking bad actions dramatically improves results in areas like Loss Design (turning a very low score into much higher performance), showing that not learning mistakes matters.
- Human guidance matters: The version trained without human input often learned less useful strategies and performed worse—human-in-the-loop guidance helped the agent handle tricky, real-world tasks.
- Longer-lasting improvements: Apollo keeps improving over more hours, while models without masking or guidance hit a “performance ceiling” early.
Why It’s Important
Training AI agents for long, complex tasks is hard because:
- Full-time human supervision is too expensive,
- Positive results are rare when the agent explores on its own,
- Mistakes can spread if the agent learns from noisy or wrong actions.
Apollo tackles all three problems: occasional human advice keeps the agent on track, and action-level filtering stops the spread of errors. This makes training more efficient and the agent more reliable for real research tasks.
Implications and Impact
Apollo points to a practical future where:
- AI agents can act like junior researchers or assistants, handling multi-day projects with minimal human oversight.
- Human experts can guide many agents at once, stepping in only when needed, reducing cost and effort.
- Better training pipelines produce agents that remember, reason, and adapt over long time spans.
Long term, this could transform how scientific and engineering work is done—AI agents could manage complex workflows, while humans set goals, provide strategic insight, and correct course when necessary. The authors expect future work to scale Apollo to more fields, use richer expert feedback, and even support multi-agent collaboration across domains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain or unexplored in the paper, framed to guide concrete follow-up research.
- Annotation economics and scalability: No quantification of annotator time per task, intervention frequency, or total person-hours; no cost–benefit analysis vs dense annotation or purely outcome-driven methods.
- Inter-annotator variability: No study of expertise effects, inter-annotator agreement, or protocols to harmonize guidance quality across annotators.
- Robustness to erroneous or adversarial guidance: No experiments injecting incorrect, inconsistent, or noisy human advice; lacks fail-safes or recovery strategies when human input is wrong.
- Intervention policy: Human-triggered “when to intervene” is ad hoc; no algorithmic drift-detection criteria, uncertainty metrics, or learned policies for triggering guidance.
- Masking criteria validity: The symbolic and LLM-based masking rules are informal; no reported precision/recall on identifying harmful actions, nor analysis of masking false positives/negatives.
- Impact of masking on exploration and credit assignment: Unclear whether masking suppresses useful exploratory steps; no study of trade-offs between pruning errors and preserving exploration diversity.
- LLM-based masking reliability: No calibration, agreement studies, or error analysis for LLM judges used to detect contradictions with user inputs or environment state.
- Missing comparison to PRM/RL credit assignment: No head-to-head against process reward modeling, GRPO, or other step-level credit assignment techniques under long-horizon sparsity.
- Reasoning token removal: Effects of stripping reasoning (process) tokens from trajectories are not evaluated; unclear whether training on actions only limits transferable reasoning skills.
- Summarization operator Σ: Under-specified summarization method; no ablation across summarization strategies, compression ratios, or their effects on retention of critical state and performance.
- Long-context efficiency: No measurement of compute/memory overheads for 100k–128k token contexts; no comparison to retrieval, memory modules, or streaming attention as alternatives.
- UI efficacy and cognitive load: Claims of lower cognitive load lack user studies; no metrics on time-to-locate context, error recovery time, or annotation throughput with/without the interface.
- Asynchronous latency and reliability: No evaluation of how delayed or batched user inputs affect agent performance; robustness under network latencies or intermittent availability is unknown.
- Generalization beyond InnovatorBench: Results limited to AI research tasks in ResearchGym; no tests on other long-horizon domains (e.g., GUI, robotics, data engineering, scientific workflows).
- Environment external validity: ResearchGym’s 42-tool action set may not reflect OS variability, network failures, real GUIs, or flaky environments; robustness to real-world execution noise untested.
- Baseline comparability and fairness: Closed-source model scores are imported rather than re-run with identical scaffolds/time budgets; no standardized time/eval budgets across all baselines.
- Statistical rigor: No confidence intervals, task-level variance, or multiple seeds; lack of significance testing for reported gains and ablations.
- Data leakage risk: Training tasks were “aligned” with InnovatorBench; no verification of strict disjointness, dataset/code overlap, or shared frameworks that could inflate test performance.
- Dataset transparency: Missing details on number of trajectories, steps per trajectory, token counts, intervention density, and distribution of guidance types (strategic vs technical).
- Guidance taxonomy and effectiveness: No categorization of feedback types and their relative impact; no ablation on guidance timing, granularity, or frequency.
- Human-dependence after training: No measurement of how much the trained agent’s performance depends on human guidance artifacts (e.g., <real_user> tags) or whether it truly internalizes strategies.
- Distribution shift from tags: Training includes special <real_user> tags, but inference lacks them; no analysis of performance drop or mitigation (e.g., tag-free training variants).
- Negative transfer and domain failures: Apollo underperforms baselines in some domains (e.g., Data Augmentation in tables); failure mode analysis is absent.
- Hyperparameter sensitivity: No ablations for upsampling ratios (7×/10×), masking thresholds, or learning rate schedules; unclear which settings drive gains.
- Resource/energy footprint: No reporting of compute costs for 16+ hour rollouts and long-context SFT; no energy or throughput metrics to assess practical deployment.
- Multi-annotator and multi-agent settings: Single-annotator assumptions; no methods for conflict resolution, turn-taking, or collaborative guidance at scale.
- Safety, privacy, and IP: No discussion on safeguarding proprietary knowledge in human guidance, logging policies, or preventing unsafe actions during long unattended runs.
- Tool/action set extensibility: No mechanism for dynamic tool discovery or adaptation when tools change or fail; portability to new tool APIs is untested.
- Evaluation protocol details: “Last submission before time T” metric may bias results; no alternatives (e.g., area under performance-time curve) or analysis of evaluation frequency effects.
- Long-horizon limits: Claims of 30h+ supervision are anecdotal; no tests on week-long/month-long tasks, persistent state management, or recovery from system restarts.
- Reproducibility: Code, datasets, and masking rules are not fully specified for replication; missing versioned releases, seeds, and environment snapshots.
These gaps point to concrete next steps: formalize and validate masking, quantify annotation dynamics and UI benefits, broaden domain evaluations, introduce principled intervention policies, compare against strong PRM/RL baselines, and strengthen reproducibility and statistical rigor.
Practical Applications
Immediate Applications
The following applications can be deployed with existing LLMs, tool-use scaffolds, and the human–AI interaction interface described in the paper. They leverage Apollo’s asynchronous guidance, action-level supervision control (masking), and long-context summarization.
- Human-in-the-loop long-horizon code agents for ML/data engineering
- Sectors: software, data engineering, AI/ML ops
- What it does: Automates multi-hour/day tasks like pipeline refactoring, dataset curation, training orchestration, and experiment logging. Human experts intervene only when the agent drifts, reducing oversight costs while improving reliability.
- Tools/products/workflows: Apollo-style sampling integrated with ACI/OpenHands/SWE-Agent; “Action Masking SDK” to filter error-prone actions; ResearchGym-like environments; LLaMA-Factory or similar training infrastructure; vLLM for inference.
- Assumptions/dependencies: Access to tool-enabled environments (terminal, file ops, web, search); human SMEs available for periodic guidance; robust logging; sufficient context window or summarization; compute resources for long runs.
- Research assistants for academic labs (computational experiments)
- Sectors: academia, scientific computing
- What it does: Assists in end-to-end research workflows (data collection, filtering, augmentation, loss/scaffold design) over hours/days; PI/RA adds strategic guidance asynchronously; action masking prevents harmful or unproductive steps.
- Tools/products/workflows: Apollo interface dashboard (trajectory visualization, environment status); InnovatorBench-like task templates; summarization operator to manage 100k-token contexts; training with masked loss for SFT.
- Assumptions/dependencies: Clear experimental protocols; sandboxed compute; consistent artifact tracking; evaluation scripts external to agent workspace; lab-specific tool integrations.
- ETL/data pipeline remediation with safety gating
- Sectors: data operations, analytics platforms
- What it does: Agents monitor, diagnose, and repair broken ETL jobs; humans inject prior knowledge or policy constraints only when needed; action-level masking blocks destructive edits or unverified changes.
- Tools/products/workflows: Integration with workflow schedulers (Airflow, Dagster); Apollo backend to buffer human inputs; symbolic rules for error-message masking; LLM-based contradiction checks vs. user guidance.
- Assumptions/dependencies: Version-controlled environments; test/staging pipelines; observability/alerts; logged agent actions for auditability.
- Long-run GUI/RPA automation with escalation-on-drift
- Sectors: enterprise RPA, IT operations
- What it does: Agents perform repetitive desktop/web workflows over long horizons (e.g., batch form processing, report compilation), escalating to human supervisors when strategic errors or novel states emerge.
- Tools/products/workflows: OpenHands-like toolsets; trajectory and state visualization; asynchronous user channels; error masking for failed tool invocations.
- Assumptions/dependencies: Stable UIs or robust selectors; policy-compliant credentials; non-disruptive async feedback loops.
- Quant research backtesting workloads with human oversight
- Sectors: finance (research, risk)
- What it does: Sets up extended backtests, feature engineering, stress tests; risk managers provide high-level corrections (e.g., data hygiene, lookahead bias) only when drift occurs; masks actions contradicting risk rules.
- Tools/products/workflows: Apollo interface atop quant toolchains; pre-approved libraries; audit logs of trajectories and masked actions; periodic checkpoints for evaluation.
- Assumptions/dependencies: Regulated sandbox; data compliance; formal risk constraints encoded as rules for masking; sufficient compute.
- Clinical research data management (non-clinical, ops-focused)
- Sectors: healthcare (research operations, registries)
- What it does: Cleans registry data, harmonizes schemas, prepares analyses over long intervals; clinicians/data stewards intervene asynchronously; masking enforces safety (e.g., no schema drops without backups).
- Tools/products/workflows: Apollo-style workflows integrated with EHR extract tools; symbolic masking for dangerous operations; summary records for audits and reproducibility.
- Assumptions/dependencies: Strict data governance; de-identified or research-approved datasets; sandbox environments separate from production EHR.
- Policy analysis evidence synthesis (extended horizon)
- Sectors: public policy, government analytics
- What it does: Agents conduct multi-day literature/search syntheses with periodic analyst oversight; mask steps that violate source credibility or policy constraints; maintain transparent, reproducible trajectories.
- Tools/products/workflows: ResearchGym-like web tools; credibility filters; Apollo conversation backend for asynchronous expert comments; versioned outputs and references.
- Assumptions/dependencies: Access to licensed content or open sources; agreed evidence standards; audit-friendly logging.
- Capstone/project tutoring and lab course support
- Sectors: education (higher ed, professional training)
- What it does: Students run agents to manage multi-week projects (data collection, model training, evaluation); instructors intervene on drift and provide strategic guidance; masking prevents propagation of poor practices.
- Tools/products/workflows: Course-specific Apollo dashboards; structured rubrics encoded as masks/heuristics; scaffolded tasks aligned with InnovatorBench categories.
- Assumptions/dependencies: Institutional compute; clear grading/evaluation criteria; oversight capacity; privacy-compliant logging.
Long-Term Applications
These applications require further research, scaling, safety validation, and/or domain-specific integration. They extend Apollo’s methods to more sensitive or complex environments, multi-agent systems, and broader sectors.
- Autonomous “AI intern” programs at scale
- Sectors: industry R&D, enterprise innovation hubs
- What it does: Deploy cohorts of research agents that operate for days/weeks under asynchronous human leadership; action-level gating enforces organizational standards; agents transfer strategies across unfamiliar frameworks (as observed with task generalization).
- Tools/products/workflows: “Apollo Studio” for team-level oversight; agent orchestration across multiple hosts; transferable reasoning libraries; compliance/gov modules.
- Assumptions/dependencies: Mature safety assessments; robust escalation protocols; standardized tool ecosystems; sustained human bandwidth for strategic guidance.
- Safety-critical operations copilots (with rigorous guardrails)
- Sectors: healthcare (clinical decision support), energy (grid ops), transportation
- What it does: Agents assist long-horizon monitoring/optimization; humans intercede on strategic shifts; masking enforces strict guardrails to prevent unsafe actions.
- Tools/products/workflows: Certified masking policies; formal verification layers for action gating; real-time status dashboards; incident response integration.
- Assumptions/dependencies: Regulatory approvals; extensive testing; domain-specific formal safety models; redundancy and failover design.
- Multi-agent collaborative research ecosystems
- Sectors: academia, enterprise R&D
- What it does: Multiple agents coordinate across tasks (data prep, modeling, evaluation) with shared summaries and cross-agent masks; humans provide high-level steering rather than step-by-step control.
- Tools/products/workflows: Cross-agent context summarization; entropy-adaptive branching; advantage attribution; human steering panels for goal re-alignment.
- Assumptions/dependencies: Reliable agent-to-agent communication; consistent ontology for shared state; conflict resolution mechanisms; orchestration middleware.
- Audited compliance workflows with action-level accountability
- Sectors: finance (compliance), public administration
- What it does: Agents execute policy workflows over long horizons while masking non-compliant actions; auditors review trajectories with embedded human annotations and environment states for transparency.
- Tools/products/workflows: Audit trail generators; compliance rule engines integrated into masking; secure storage of interaction logs; policy versioning.
- Assumptions/dependencies: Accepted evidentiary standards; data retention policies; secure, tamper-evident logging; regulatory buy-in.
- Robotics and embodied agents for extended missions
- Sectors: robotics, logistics, manufacturing
- What it does: Adapt Apollo’s asynchronous guidance and action filtering to embodied agents operating for hours/days (maintenance checks, inspections, warehouse tasks); humans intercede when strategy must change.
- Tools/products/workflows: Tool/action abstraction for robot APIs; state summarization from multimodal sensors; safety masks tied to physical constraints.
- Assumptions/dependencies: High-fidelity simulators for training; robust perception-to-action mapping; certified safety envelopes; latency-tolerant HAI channels.
- Continuous improvement loops for enterprise AI systems
- Sectors: software platforms, SaaS
- What it does: Use action-level masking and asynchronous sampling to continuously curate high-quality trajectories for SFT/RL across product features; reduce error propagation and model drift over long deployments.
- Tools/products/workflows: “Apollo Trainer” pipelines; rejection/masking hybrids; offline evaluation suites; telemetry-driven summarization updates.
- Assumptions/dependencies: Data governance; cost of large-scale finetuning; monitoring of rare positive trajectories; scalable storage/backends.
- Large-scale evidence synthesis and living reviews
- Sectors: healthcare policy, climate science, social science
- What it does: Maintain living reviews with agent-driven updates; human experts provide strategic corrections when new evidence emerges; mask contradictory or low-quality additions.
- Tools/products/workflows: Living review platforms; automated citation management; quality scoring integrated into masks; version-controlled summaries.
- Assumptions/dependencies: Access to updated corpora; consensus quality criteria; sustained expert oversight; reproducibility infrastructure.
- Personalized long-horizon digital stewards
- Sectors: consumer tech, productivity
- What it does: Agents manage long-running personal tasks (tax prep, home server maintenance, photo/knowledge organization) with asynchronous user feedback; masks block risky system operations.
- Tools/products/workflows: Consumer-grade Apollo UI; safe system tools; backup/rollback protocols; privacy-preserving logs.
- Assumptions/dependencies: Device permissions and sandboxing; user education; robust local summarization; cost-effective compute.
Cross-cutting assumptions and dependencies
- Quality of summarization: Long-context management must preserve key state, intermediate results, and error reflections, or agents may lose coherence.
- Human availability and expertise: Even asynchronous oversight demands planned touchpoints and domain knowledge.
- Tool-access scaffolding: Reliable tool invocation (command, file, parse, web search/browse) and observability are crucial.
- Safety and compliance: Action masking rules need to encode domain constraints and be testable; audit trails must be maintained.
- Compute and cost: Long-horizon rollouts and large-context SFT require significant resources; scheduling and queuing systems must handle 10–30h tasks.
- Environment fidelity: ResearchGym-like environments or real systems must expose structured observations and support asynchronous execution without disrupting agent planning.
Glossary
- Action-Level Data Filtering: Filtering or excluding specific actions from trajectories to improve training quality. "We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering."
- Action-Level Supervision Control Mechanism: A training mechanism that masks unreliable actions to stabilize optimization and prevent error propagation. "We introduce an action-level supervision control mechanism that masks unreliable actions, stabilizes optimization, and prevents error propagation in finetuning."
- Advantage Attribution: An RL technique that assigns credit to actions by estimating their relative advantage. "and ARPO builds on that with advantage attribution and entropy-adaptive branching."
- Agent-Computer Interface (ACI): An interface enabling agents to interact with and manipulate software repositories and computer environments. "SWE-agent introduced the Agent-Computer Interface (ACI) to support repository navigation and patching;"
- Agentic Training: Training approaches focused on agents performing sequences of actions in environments, often with RL or SFT. "both supervised fine-tuning (SFT) and reinforcement learning (RL) in agentic training encounter a huge challenge in the rollout process,"
- ARPO: A reinforcement learning method incorporating structured advantages and branching strategies for agent training. "and ARPO builds on that with advantage attribution and entropy-adaptive branching."
- Asynchronous Command Execution: Executing commands without blocking, enabling parallel or long-running tasks in agent environments. "ResearchGym is a control and execution platform that supports asynchronous command execution and multi-computer control,"
- Asynchronous Human Guidance: Human feedback provided intermittently without continuous oversight during agent rollouts. "a sampling framework that integrates asynchronous human guidance with action-level data filtering."
- Asynchronous Sampling Algorithm: A rollout strategy where agents and annotators interact asynchronously to collect data efficiently. "Asynchronous Sampling Algorithm"
- Behavior Cloning: Supervised learning that imitates expert actions to train agents. "The first relies on behavior cloning with human annotators, in which human experts provide dense supervision"
- Chain-of-Thought (CoT) Synthesis: Generating rationales used for training or inference to improve reasoning. "ultimately causing the failure of the LLM-based Chain-of-Thought (CoT) synthesis method."
- Cosine Annealing: A learning rate scheduling technique that follows a cosine curve to improve optimization. "All models are trained with a max token of 128k, 1 epoch, batch size 64, and a learning rate from 5e-6 to 1e-6 with cosine annealing."
- Credit Assignment: Allocating credit to actions or steps based on outcomes to guide learning. "Apollo differs by using asynchronous high-level guidance and selective credit assignment at the step level,"
- DeepResearcher: A system for multi-tool research rollouts under uncertain outcomes. "Tool-STAR, DeepResearcher, and ToRL explore rollouts in multi-tool invocation settings under uncertain outcomes,"
- Entropy-Adaptive Branching: Adjusting exploration branching based on entropy to stabilize RL training. "ARPO builds on that with advantage attribution and entropy-adaptive branching."
- GLM-4.5: A specific LLM used as a base or baseline in experiments. "We use GLM-4.5 as our base model."
- GRPO: Group Relative Policy Optimization; an RL algorithm that optimizes policies using group-relative rewards. "or group relative policy optimization (GRPO), etc"
- Human–AI Interaction: Designing interactions and interfaces for effective collaboration between humans and AI agents. "We design the first human–AI interaction interface for long-horizon task sampling,"
- Human–Agent Training Infrastructure: Systems enabling scalable, transparent human guidance during long-duration agent training. "We propose a human–agent training infrastructure that enables fine-grained, long-duration (30h+) asynchronous supervision,"
- Human-in-the-Loop Sampling: Data collection where humans provide ongoing feedback during agent rollouts. "These gains highlight both the necessity of high-quality human-in-the-loop sampling"
- InnovatorBench: A benchmark evaluating end-to-end research capabilities of LLM agents under realistic constraints. "To evaluate our approach, we adopt InnovatorBench"
- LLaMA-Factory: A training framework for LLMs supporting templates and multi-turn finetuning. "within established training frameworks, such as LLaMA-Factory"
- Long Context Management: Techniques to handle trajectories exceeding model context length by summarizing earlier segments. "Long Context Management"
- Long-Horizon Tasks: Tasks requiring extended sequences of actions and reasoning over hours or days. "the research focus is increasingly shifting toward long-horizon, high-difficulty, and domain-specialized tasks"
- Loss Masking: Excluding certain outputs from contributing to loss to prevent learning from bad actions. "it just uses the model to rollout with rejection sampling via loss masking."
- Markov Decision Process (MDP): A formal framework representing states, actions, transitions, and rewards for decision-making. "We formalize the agent's interaction with the environment as a Markov Decision Process (MDP)"
- OpenHands: A toolset enabling general computer-use agents with lightweight capabilities. "OpenHands demonstrated that a lightweight but general toolset can enable broad computer-use agents."
- Outcome-Driven Sampling: Generating data based on final outcomes rather than dense step-level supervision. "The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories"
- PC-Agent: A method relying on human-annotated rollouts and action-level feedback for training. "Some approaches rely heavily on human-annotated rollouts, such as PC-Agent"
- Process Reward Modeling: Supervisory signals provided at intermediate steps to guide agent behavior. "such as PC-Agent or process reward modeling, where annotators provide action-level feedback or trajectory validation;"
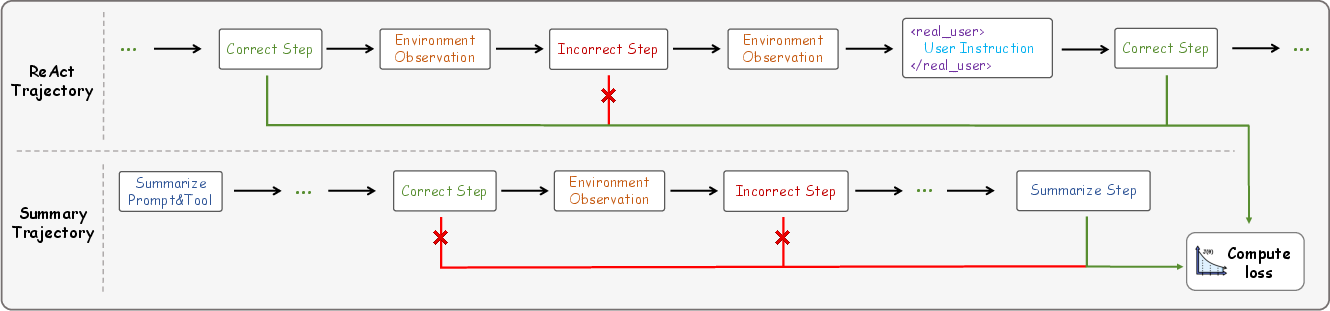
- ReAct: A paradigm that interleaves reasoning and acting within trajectories. "To structure trajectories, we adopt the ReAct paradigm, which interleaves reasoning and acting in a unified loop."
- Rejection Sampling Fine-Tuning (RFT): Filtering sampled trajectories to retain only high-quality ones for finetuning. "use this credit in rejection sampling fine-tuning (RFT)"
- ResearchGym: A rollout and testing environment enabling asynchronous multi-computer experiments. "We use ResearchGym as our rollout and testing environment."
- ShareGPT Format: A data format used to store multimodal data for later training or sharing. "save multimodal data in ShareGPT format"
- Summarization Operator: The function that compresses earlier trajectory segments into a structured summary. "The summarization operator Σ(·) preserves the key knowledge, important intermediate results, environment or file states, and critical errors or reflections,"
- Summarization Trajectory: A trajectory record that captures summarized context and the last action for training. "Since the number of summarization trajectories is always one less than the number of ReAct trajectories,"
- Symbolic Masking: Rule-based masking of actions (e.g., those producing explicit error messages). "The process contains both symbolic masking and LLM-based masking."
- SWE-Agent: A code-agent framework supporting repository navigation and patching. "SWE-agent introduced the Agent-Computer Interface (ACI) to support repository navigation and patching;"
- SWE-Dev: A dataset extension approach that scales training data via trajectory augmentation. "Extensions such as SWE-Dev scale data through trajectory augmentation."
- SWE-RL: Reinforcement learning for software engineering tasks using real-world issue histories. "SWE-RL leveraged reinforcement learning from real-world issue and pull request histories;"
- Test-Time Scaling: Evaluating performance as available inference time increases. "The test time scaling results reflect the model's ability to handle difficult tasks."
- Tool Invocation: Executing tools or APIs as discrete actions within an agent’s policy. "an action a_t ∈ A corresponds to a tool invocation."
- Tool-STAR: A system exploring multi-tool rollouts under uncertain outcomes. "Tool-STAR, DeepResearcher, and ToRL explore rollouts in multi-tool invocation settings under uncertain outcomes,"
- ToRL: A method for tool-use reinforcement learning under uncertain outcomes. "Tool-STAR, DeepResearcher, and ToRL explore rollouts in multi-tool invocation settings under uncertain outcomes,"
- Trajectory Augmentation: Expanding datasets by transforming or augmenting recorded agent trajectories. "Extensions such as SWE-Dev scale data through trajectory augmentation."
- Upsampling: Increasing the frequency of certain samples to balance datasets during training. "we upsample the ReAct trajectories 7 times and the summarization trajectory 10 times."
- VerL: A framework or training system referenced for hybrid or multi-turn workflows. "such as LLaMA-Factory or VerL"
- vLLM: A high-throughput inference library for LLMs. "while the model is still importing the vLLM library"
Collections
Sign up for free to add this paper to one or more collections.

