JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion
Abstract: Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings. In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half. By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
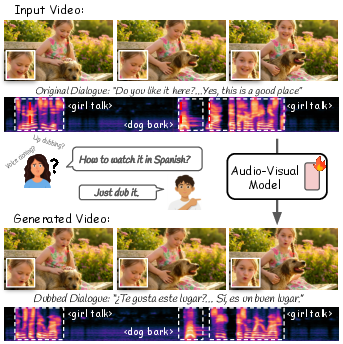
This paper is about making better dubbed videos—videos where someone’s speech is translated into another language while their lips, face, and voice still look and sound natural. The authors built a single AI model that edits both the sound and the video at the same time, so the new speech matches the person’s mouth movements and the scene around them. They call it “JUST-DUB-IT.”
Key Questions
The paper tries to answer:
- How can we translate a person’s speech in a video while keeping their face, lips, and voice feeling like the same person?
- How can we avoid awkward mistakes, like lips moving out of sync, speech lasting too long or too short, or background sounds not lining up with actions in the scene?
- Can a single AI model handle all parts of dubbing together (audio and video) instead of using many separate tools that often break in real-life situations?
How They Did It
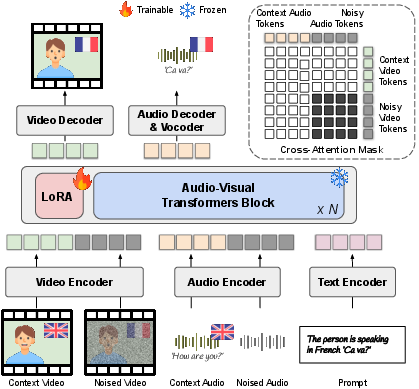
The team used a large “foundation model” that already understands both video and audio together. Then they lightly tuned it for dubbing using a small add-on called a LoRA.
Here are the main ideas, explained simply:
- A joint audio–video model: Think of it like an AI that “hears” and “sees” at the same time. It learns how speech sounds, how lips move, and what’s happening in the scene, all together.
- Diffusion model: Imagine starting with noisy, messy data and gradually cleaning it up step by step until it turns into a clear video and audio that match a given description. That’s how diffusion models create or edit content.
- LoRA (Low-Rank Adaptation): This is a tiny “steering wheel” added to a big AI. Instead of retraining the whole system, you add a small part that nudges the model to do dubbing well. It’s faster and needs less data.
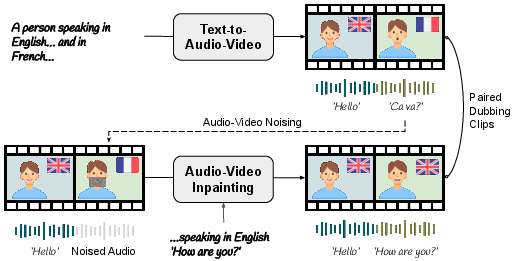
- Inpainting: Like fixing a hole in a photo, but for both lips in the video and the audio track. The model fills in the missing or changed parts so they match the new language while keeping the rest of the scene the same.
- Making training data with the model itself: Real videos of the same person saying the same thing in different languages don’t exist. So, they used the AI to make short videos where a person switches languages mid-clip (for example, English then French). Then they split the clip in half and “inpainted” the face and audio in each half to match the other language. This creates pairs that are perfect for teaching the model how to dub while keeping identity, timing, and context.
- Solving the identity vs. pronunciation problem: If you only focus on voice identity, pronunciation can sound wrong in the new language. If you only focus on correct pronunciation, the voice may stop sounding like the same person. Their trick is to condition the dubbing on a reference clip where the same person is already speaking the target language. This helps the AI keep both the person’s voice style and the correct language sounds.
- Preventing “cheating”: During training, they stop the model from peeking at clean parts of the audio or video while fixing noisy parts. In simple terms, they make sure the audio pays attention to the right video frames and the video listens to the right audio moments, so the model truly learns to synchronize lips and speech instead of copying.
Main Findings
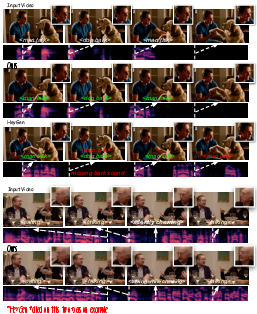
The authors tested their method on regular, clean videos and on tough, “in-the-wild” videos where people move a lot, turn their heads, get partly blocked, or do expressive things like laughing.
They found:
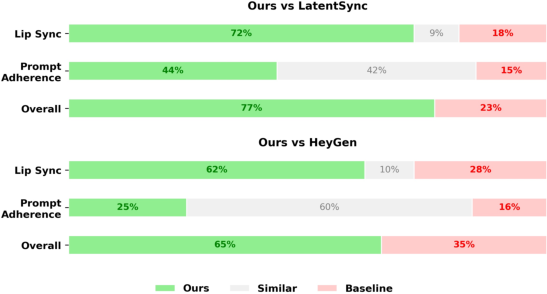
- Better lip sync and timing: The translated speech and mouth movements match well, even when the language takes more or less time to say the same sentence.
- Strong visual quality in tough conditions: The model works when faces aren’t straight at the camera, when the mouth is partly hidden, or even with stylized or non-human characters.
- Scene-aware sound: Background sounds (like a dog barking or a door slam) stay in the right places and match actions, instead of drifting out of sync.
- Fewer failures: Unlike many step-by-step pipelines that depend on perfect face detection or clean audio, the single model is more robust and keeps working on tricky videos.
- User preference: In a user study, people preferred the results from this method over popular baselines for lip sync, following the prompt, and overall quality.
Note: The paper shows many tests and metrics to back this up. In plain terms, their videos look and sound more natural, especially in challenging situations.
Why It Matters
- Better dubbing for real-world videos: This can make movies, online videos, and educational content easier to watch in many languages without the “off” feeling of mismatched lips or awkward timing.
- Simpler and more reliable tools: A single, joint model reduces the complexity of multiple specialized tools that often break in the wild.
- More natural experiences: Because audio and video are edited together, the model keeps the rhythm of the scene—pauses, laughs, and background sounds feel right.
- Limitations and future work: Sometimes the voice doesn’t perfectly match the original speaker’s identity. The authors suggest improving how the model separates “what is being said” from “who is saying it,” and extending to longer conversations.
In short, JUST-DUB-IT shows that treating dubbing as a combined audio–video generation task leads to more believable translations that keep the speaker’s identity, the scene’s timing, and the natural feel of the original video.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and unresolved questions that could guide future research:
- Data realism and circularity: Training pairs are fully synthetic and derived from the same (or similar) foundation model, risking domain overfitting and bias reinforcement; impact on real, diverse footage is not rigorously quantified.
- Lack of real paired bilingual ground truth: No evaluation on human-recorded, identity-consistent bilingual videos; a benchmark with controlled bilingual utterances is needed to validate duration/prosody handling and lip–audio alignment.
- Translation is out-of-scope: The method assumes accurate target-language transcripts at inference; integration with ASR/NMT, timing alignment, and uncertainty handling of imperfect transcripts remain open.
- Multi-speaker and diarization: The approach targets single-speaker segments; handling dialogues, overlaps, interruptions, off-screen speakers, and selective per-speaker dubbing (with spatial/visual control) is not addressed.
- Long-form and multi-shot consistency: Robustness across minutes-long content, scene cuts, shot changes, and global consistency of identity, timbre, and style over long durations is not evaluated.
- Language coverage and phonetic diversity: Generalization to low-resource, tonal (e.g., Mandarin), morphologically rich, or non-Indo-European languages with markedly different viseme inventories and coarticulation patterns is untested.
- Accent, dialect, and code-switching: Preservation and control of accent/dialect across languages, intra-utterance code-switching, and cross-lingual accent transfer remain unexplored.
- Voice identity preservation: The paper acknowledges incomplete voice identity retention; methods for disentangling content vs. speaker timbre (e.g., explicit speaker embeddings, contrastive objectives, or identity-preserving losses) need study.
- Prosody and style control: Fine-grained control over prosody, emotion, speaking rate, emphasis, and style (and their alignment with facial expressions) is not provided or systematically evaluated.
- Environmental sound grounding metrics: Claims of co-evolution with scene events (e.g., dog bark timing) lack objective, event-level benchmarks and annotations for quantitative verification.
- Stereo/spatial audio and room acoustics: The method appears mono-centric; preserving and generating spatial cues, reverberation, and scene-consistent acoustics is unaddressed.
- Background music/sFX handling: Robustness to music, strong background SFX, and dynamic mixing (ducking/side-chaining) to avoid masking the dubbed speech is not measured.
- Robustness to extreme conditions: Systematic evaluation under heavy motion blur, low-light/high ISO noise, rolling shutter, extreme pose/self-occlusions, and very high frame rates/resolutions is incomplete.
- Multi-face frames and non-target selection: How the system behaves with multiple visible faces and how to target a specific speaker’s face without masks or detectors remains unclear.
- Non-human and stylized domains: Although qualitative results include non-human characters, quantitative robustness and identity consistency in stylized or animated content are not established.
- Modality-Isolated Cross-Attention ablation: No controlled ablation quantifies how the proposed cross-attention masking affects synchronization, leakage, and overall quality vs. alternatives.
- Latent-aware fine masking sensitivity: The effective latent mask threshold and dependence on specific VAE architectures are not analyzed; portability to other VAEs/backbones is unknown.
- Failure mode analysis: A taxonomy and frequency of errors (e.g., lip–audio drift, identity drift, phoneme–viseme mismatches, flicker, audio artifacts) is missing.
- Evaluation metric biases: Known SyncNet and FID/FVD limitations are acknowledged but not replaced; development of pose-robust, event-aware AV metrics and perceptual studies with statistical significance is needed.
- Efficiency and scalability: Inference latency, memory footprint, throughput, and feasibility for real-time or mobile deployment are not reported.
- Controllability and user guidance: Mechanisms for user-specified constraints (e.g., preserve specific audio segments, control speech rate, keep original interjections, or select translation strength) are not provided.
- Reproducibility and release: Model weights, training code, and synthetic dataset availability are unspecified; reproducibility and external validation may be hindered.
- Safety and misuse mitigation: Consent, watermarking/detectability, identity protection, bias/fairness impacts (e.g., ArcFace-based filtering biases), and content moderation are not addressed.
- Compatibility with newer AV backbones: Generalization of the LoRA strategy and masking design to alternative or future joint AV models (beyond LTX‑2) remains untested.
- Duration control guarantees: While duration alignment is qualitatively shown, explicit mechanisms/constraints and quantitative guarantees under large cross-lingual length disparities are not provided.
- Interaction with background speech: Distinguishing and preserving other voices in the scene (crowd chatter, side characters) vs. translating only the target speaker is not studied.
- Audio fidelity specifics: Effects on SNR, high-frequency detail, mouth noises, plosives/sibilants, clipping, and codec artifacts are not quantified; sample rate/channel format assumptions are unclear.
- Data filtering biases: Reliance on Whisper, ArcFace, and Qwen2-VL may encode demographic and linguistic biases; fairness audits across identities and languages are absent.
Glossary
- ArcFace: A deep face recognition model used to measure identity similarity in videos. "identity preservation (ID-SIM, ArcFace~\cite{deng2019arcface})"
- Asymmetric Cross-Modal Interaction (ATI): A design strategy that aligns audio and visual modalities by allowing asymmetric information flow between them. "Asymmetric Cross-Modal Interaction (ATI)"
- Asymmetric Dual-Stream Diffusion Transformer: A diffusion transformer architecture with separate streams for audio and video to handle differing information densities. "LTX-2 employs an Asymmetric Dual-Stream Diffusion Transformer (DiT) that processes decoupled latent inputs:"
- Audio-Visual Foundation Models: Large pretrained models that jointly generate and edit synchronized audio and video content. "Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content"
- Bidirectional cross-attention: Attention layers that enable mutual conditioning between audio and video tokens to maintain alignment. "enforcing tight temporal alignment through bidirectional cross-attention layers that allow each modality to continuously condition the other"
- Cross-modal leakage: Undesired information transfer between modalities during attention, which can cause misalignment or artifacts. "a global attention mechanism in an in-context setting often results in cross-modal leakage"
- Diffusion Transformers (DiTs): Transformer-based architectures that perform denoising for generative diffusion modeling. "Diffusion Transformers (DiTs)~\cite{low2025ovi, zhang2025uniavgen, Peebles2022DiT, ltx2}"
- ERes2Net: A neural network for speaker verification used to compute voice similarity metrics. "voice similarity (V-SIM, ERes2Net~\cite{zhou2021eres2net})"
- Flow Matching: A training approach for diffusion models that learns a velocity field to transport noise to data distributions. "trained using Flow Matching (specifically Rectified Flow)"
- Fréchet Inception Distance (FID): A metric that quantifies visual fidelity of generated images or frames compared to real data. "Visual fidelity (FID~\cite{fid})"
- Fréchet Video Distance (FVD): A metric that assesses temporal coherence and quality of generated video sequences. "temporal coherence (FVD~\cite{fvd})"
- IC-LoRA (In-Context LoRA): A fine-tuning paradigm that adds low-rank adapters for context-driven generation without updating base model weights. "Inspired by the In-Context LoRA (IC-LoRA) paradigm~\cite{lhhuang2024iclora}"
- Inpainting: Regenerating masked regions (audio or video) conditioned on surrounding context to produce coherent edits. "we employ inpainting to create counterfactual pairs"
- Int-Corr: A measure of temporal intensity consistency in audio based on correlation of energy envelopes. "temporal intensity consistency (Int-Corr, Pearson correlation of RMS audio envelopes~\cite{chung2024t})"
- Latent-Aware Fine Masking: A masking technique that extends beyond pixel regions to cover latent representations affected by encoder receptive fields. "We implement Latent-Aware Fine Masking"
- Lip Augmentation: Data augmentation prompting exaggerated articulation to increase visual distinctiveness of lip motion. "Lip Augmentation via Phonetic Diversity"
- Lip Landmark Distance (LMD): A metric that quantifies differences in lip landmark positions between reference and generated videos. "The Lip Landmark Distance (LMD) measures structural deviation between reference and generated lip landmarks:"
- LoRA (Low-Rank Adaptation): A method that inserts trainable low-rank matrices into attention layers to adapt pretrained models efficiently. "We adopt a Low-Rank Adaptation (LoRA) approach"
- Modality-Isolated Cross-Attention: An attention masking strategy that restricts cross-modal interactions to prevent signal leakage during denoising. "Modality-Isolated Cross-Attention"
- Mouth Aspect Ratio (MAR): A measure of mouth openness computed from lip landmarks, used to assess articulation diversity. "The Mouth Aspect Ratio (MAR) at frame t is defined as:"
- Paralinguistic: Non-verbal vocal elements (e.g., laughter, sighs) that convey meaning and must be modeled alongside speech. "paralinguistic elements (e.g., laughter, sighs, breathing)"
- Pearson correlation of RMS audio envelopes: A statistical measure of similarity between energy envelopes of audio signals, used for Int-Corr. "Pearson correlation of RMS audio envelopes~\cite{chung2024t}"
- Positional encoding: Token embeddings that encode spatial and temporal positions to align context and target streams. "Context-Aligned Multimodal Positional Encoding."
- Prosody leakage: Unwanted transfer of rhythm and intonation patterns from the source language into the target during dubbing. "resulting in prosody leakage"
- Quality–Diversity (QD) score: A composite metric that multiplies LMD and MAR diversity to evaluate both quality and variation in lip motion. "Finally, the Quality--Diversity (QD) score is defined as:"
- Rectified Flow: A variant of Flow Matching that learns straight trajectories between noise and data distributions. "Rectified Flow"
- SyncNet: A model that estimates the temporal offset between lip movements and speech to assess audiovisual synchronization. "Temporal offset between lip movements and speech (SyncNet~\cite{syncnet})"
- Twin-backbone: An architectural design with parallel networks (for audio and video) that process modalities separately but interact. "twin-backbone designs"
- Variational Autoencoder (VAE): A generative encoder–decoder used to compress video frames and audio into latent tokens. "audio is encoded into 1D tokens via a separate 1D VAE"
- Velocity field: The vector field predicted by Flow Matching that transports samples from noise to data along a probability path. "The model is optimized to predict the velocity field that drives this transformation"
- Video DiTs: Diffusion Transformers specialized for video editing and generation tasks. "directly edit videos using Video DiTs"
- Viseme: The visual counterpart of a phoneme; different phonemes can share similar lip shapes leading to ambiguity. "ambiguity of visemes, where different phonemes may share similar lip shapes"
- Whisper: An ASR model used to compute word error rate (WER) for linguistic accuracy evaluation. "Linguistic accuracy (WER, Whisper~\cite{opeaniwhisper})"
- Word Error Rate (WER): A standard metric for evaluating transcription or translation accuracy of speech. "Linguistic accuracy (WER, Whisper~\cite{opeaniwhisper})"
- Zero-shot Voice Cloning: Generating a synthetic voice that matches a target speaker’s identity without speaker-specific training data. "Zero-shot Voice Cloning"
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s joint audio–visual diffusion approach, lightweight LoRA fine-tuning, synthetic paired data generation, and attention/masking innovations into existing workflows and products.
- Media localization and post-production (sector: entertainment, streaming, advertising)
- Use case: One-click multilingual dubbing for films, shows, user-generated content, and commercials that preserves identity, lip sync, and environmental audio timing without brittle multi-stage pipelines.
- Tools/products/workflows:
- “AV Dubbing” plugins for Adobe Premiere Pro, DaVinci Resolve, and CapCut.
- A batch SaaS/API that accepts source video + translated transcript, runs joint AV diffusion, and returns a mastered track.
- Built-in QC using MAR/LMD/FVD/AV-sync metrics and a human-in-the-loop approval step.
- Assumptions/dependencies: High-quality ASR and machine translation to produce the detailed text prompt; access to an audio–video foundation model (e.g., LTX‑2) and GPU compute; licensing and consent for identity preservation; current voice identity may not be perfect in edge cases.
- Creator economy and social media localization (sector: software, media)
- Use case: Creators publish the same short-form video in multiple languages while keeping the original persona, expressions, and background sounds intact.
- Tools/products/workflows: Mobile app with “Dub to X languages” and automatic timing alignment; integration with TikTok/YouTube/Instagram upload flows.
- Assumptions/dependencies: Efficient on-device or cloud inference; language support; moderation and consent controls to prevent misuse.
- Corporate training and communications (sector: enterprise, compliance)
- Use case: Localize training modules, compliance briefings, and internal announcements with accurate lip sync and environmental audio preservation (e.g., demonstrations with tool noises).
- Tools/products/workflows: Internal localization platform with batch processing, role-based approvals, and audit trails; subtitles + dubbed video bundles.
- Assumptions/dependencies: Data privacy and employee consent; transcription/translation integration; GPU resources.
- Education and MOOCs (sector: education)
- Use case: Lip-synced lecture translation that maintains instructor identity and pacing; language-learning materials that show clear visemes aligned with target phonemes.
- Tools/products/workflows: LMS plugin enabling “generate dubbed tracks” per lecture; curriculum authoring tools that leverage lip augmentation for clearer articulation.
- Assumptions/dependencies: Accurate transcripts/translations; rights to modify content; validation of linguistic accuracy.
- Accessible communication and comprehension aids (sector: accessibility, public sector)
- Use case: For viewers who rely on lip movements, produce lip-synced target-language videos to improve comprehension beyond subtitles alone.
- Tools/products/workflows: Accessibility mode in players that switches to target-language lip motion; bundled captions/subtitles with timing-preserved background audio.
- Assumptions/dependencies: Community and regulatory guidance; content labeling to indicate synthetic edits.
- Marketing and A/B testing across regions (sector: marketing, retail)
- Use case: Localize spokesperson or influencer videos into multiple languages while preserving timing-dependent brand cues (e.g., product sounds, reactions).
- Tools/products/workflows: Campaign localization pipeline with automatic asset dub, per-market variants, and measurement dashboards.
- Assumptions/dependencies: Brand voice governance and approvals; guardrails against impersonation.
- Synthetic data generation for multimodal research (sector: academia, R&D)
- Use case: Generate identity-consistent bilingual AV pairs with language switches to train/evaluate multimodal models.
- Tools/products/workflows: Open-source scripts for language-switch video generation, latent-aware fine masking, and paired inpainting; metrics toolkits (MAR, LMD, FVD, SyncNet).
- Assumptions/dependencies: Foundation model access; responsible data curation; disclosure of synthetic provenance.
- Model components adoption in other AV editors (sector: software, ML tooling)
- Use case: Improve robustness of inpainting/editing systems using:
- Latent-aware fine masking to prevent motion leakage.
- Modality-isolated cross-attention to avoid cross-modal guidance noise.
- Context-aligned positional encoding for stronger alignment.
- Tools/products/workflows: Drop-in library modules for AV transformer stacks and training pipelines; LoRA adapters shipped as “language packs.”
- Assumptions/dependencies: Compatible architectures and training hooks; validation on target domains.
- QC and compliance toolkits for dubbed media (sector: policy, platform governance)
- Use case: Standardize quality checks and provenance:
- Automated AV-sync and timing consistency checks.
- Identity-preservation scores.
- Edit provenance logging and optional watermarking.
- Tools/products/workflows: Platform-side ingestion checks; dashboards for auditors; integration with content management systems.
- Assumptions/dependencies: Agreement on thresholds/metrics; legal compliance for watermarking and edit disclosure.
Long-Term Applications
The following applications require further research, scaling, or engineering (e.g., low-latency inference, stronger voice identity preservation, longer temporal contexts, broader language coverage) before widespread deployment.
- Real-time cross-language dubbing in video conferencing (sector: enterprise, communications)
- Use case: Live meetings where participants hear and see speakers dubbed into their language with synced lip motion and co-evolving environmental sounds.
- Tools/products/workflows: Low-latency AV diffusion with streaming inputs; rapid ASR/MT; integration into Zoom/Teams/Meet.
- Assumptions/dependencies: Significant latency reduction; on-the-fly LoRA conditioning; scalable GPU/edge hardware; privacy and consent management.
- Broadcast and live events localization (sector: media, sports)
- Use case: Live sports, news, and events localized while preserving ambient crowd noise, reactions, and timing.
- Tools/products/workflows: Edge inference clusters; broadcaster control rooms with AV-dubbing orchestration; synchronization with captioning/subtitling pipelines.
- Assumptions/dependencies: Reliability under high motion/occlusion; robust failure handling and human oversight.
- Interactive entertainment and games (sector: gaming, XR)
- Use case: NPCs dynamically switch languages with accurate lip sync and scene-aware audio effects; cross-market localization without re-recording.
- Tools/products/workflows: Game engine plugins (Unreal/Unity) for runtime AV dubbing; asset authoring with LoRA language/style packs.
- Assumptions/dependencies: Real-time constraints; consistency across animation styles; rights for voice and character identity.
- Social robots and digital humans (sector: robotics, customer service)
- Use case: Humanoid robots and digital assistants speak multiple languages with visually accurate mouth motions and paralinguistic cues grounded in context.
- Tools/products/workflows: Embedded AV generation modules; multimodal controllers for gestures and audio events; hardware-integrated lip-actuation mapping.
- Assumptions/dependencies: On-device inference or efficient streaming; safety and reliability in human–robot interaction.
- Film restoration and automated ADR (sector: entertainment)
- Use case: Automatically repair dialogue timing mismatches, re-synchronize ADR to on-set performance, or adapt lines post-edit while preserving realism.
- Tools/products/workflows: Studio-grade pipelines with long-context AV models; versioning/rollback; detailed provenance.
- Assumptions/dependencies: Longer temporal memory; precise identity/style disentanglement; legal/union considerations.
- Healthcare communications and telemedicine (sector: healthcare)
- Use case: Localize patient education videos and remote consults into a patient’s language while maintaining expressive, empathetic delivery.
- Tools/products/workflows: Hospital-approved platforms with audit trails; clinician review; medical terminology MT.
- Assumptions/dependencies: Clinical accuracy and liability; privacy/security compliance (HIPAA/GDPR); bias and fairness oversight.
- Edge/on-device AV dubbing (sector: mobile, embedded)
- Use case: Private, low-latency dubbing on phones or AR glasses for travel, accessibility, and field work.
- Tools/products/workflows: Model distillation/quantization; hardware acceleration; energy-aware scheduling.
- Assumptions/dependencies: Efficient architectures; battery and thermal constraints; local LLMs.
- Platform governance and regulation (sector: policy, compliance)
- Use case: Standards for consent, disclosure, and watermarking of identity-preserving dubbing; tools for detection and provenance verification.
- Tools/products/workflows: Platform-side detection models tuned to joint AV edits; standardized metadata schemas; user-facing edit disclosures.
- Assumptions/dependencies: Multi-stakeholder agreement; evolving legislation; technical watermark robustness.
- General multimodal editing beyond dubbing (sector: software, R&D)
- Use case: Holistic scene-aware editing—adding or re-timing non-speech events (laughter, footsteps), adjusting pacing, or modifying expressions alongside audio.
- Tools/products/workflows: AV “editing IDE” integrating in-context LoRA, cross-modal masking, and flow-matching; long-context models for conversations.
- Assumptions/dependencies: Extended temporal modeling; robust alignment under complex occlusions; creative controls for editors.
- Standardized evaluation suites for AV dubbing (sector: academia, platforms)
- Use case: Community benchmarks that measure temporal-semantic coherence, identity preservation, viseme quality, and AV sync across languages and conditions.
- Tools/products/workflows: Open datasets of language-switch videos; reproducible metric toolchains (MAR/LMD/FVD/SyncNet, intensity correlation); leaderboards.
- Assumptions/dependencies: Shared data and metric definitions; ethical sourcing and labeling; ongoing maintenance.
Notes on cross-cutting assumptions and dependencies
- Translation and transcription quality: The model relies on detailed text conditioning; robust ASR/MT is essential.
- Identity and voice style: Current voice identity preservation is not perfect; further disentanglement and/or explicit identity supervision will improve fidelity.
- Compute and scalability: High-quality joint AV diffusion is GPU-intensive; real-time scenarios require architectural and systems advances.
- Licensing and consent: Using identity-preserving dubbing demands explicit consent and rights management; platforms need watermarking and provenance.
- Safety and misuse: Strong moderation, detection tools, and disclosure practices are required to mitigate impersonation and deceptive content risks.
- Domain variability: Performance can vary with non-frontal views, occlusions, stylized/non-human subjects; testing and guardrails are needed for edge cases.
Collections
Sign up for free to add this paper to one or more collections.

