LTX-2: Efficient Joint Audio-Visual Foundation Model
Abstract: Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LTX-2, a computer model that can make short videos and their matching sounds from a text prompt—for example, “a boy kicks a soccer ball on a rainy street, cars whoosh by, and he shouts ‘Goal!’.” Unlike many past models that only made silent videos or separate audio, LTX-2 makes both together, in sync, so lips match speech, actions match sound effects, and the mood fits the scene.
What questions are the researchers trying to answer?
- Can we build one model that makes video and sound at the same time so they line up perfectly?
- Can it understand complex, multilingual text prompts well enough to produce clear speech and rich soundscapes (like footsteps, wind, and background noise)?
- Can it do all this fast and efficiently, without needing huge amounts of computing power?
- Can we give users better control over how strongly the text and the other modality (audio or video) influence each other during generation?
How does LTX-2 work? (Explained simply)
Think of LTX-2 like a two-person band that composes together:
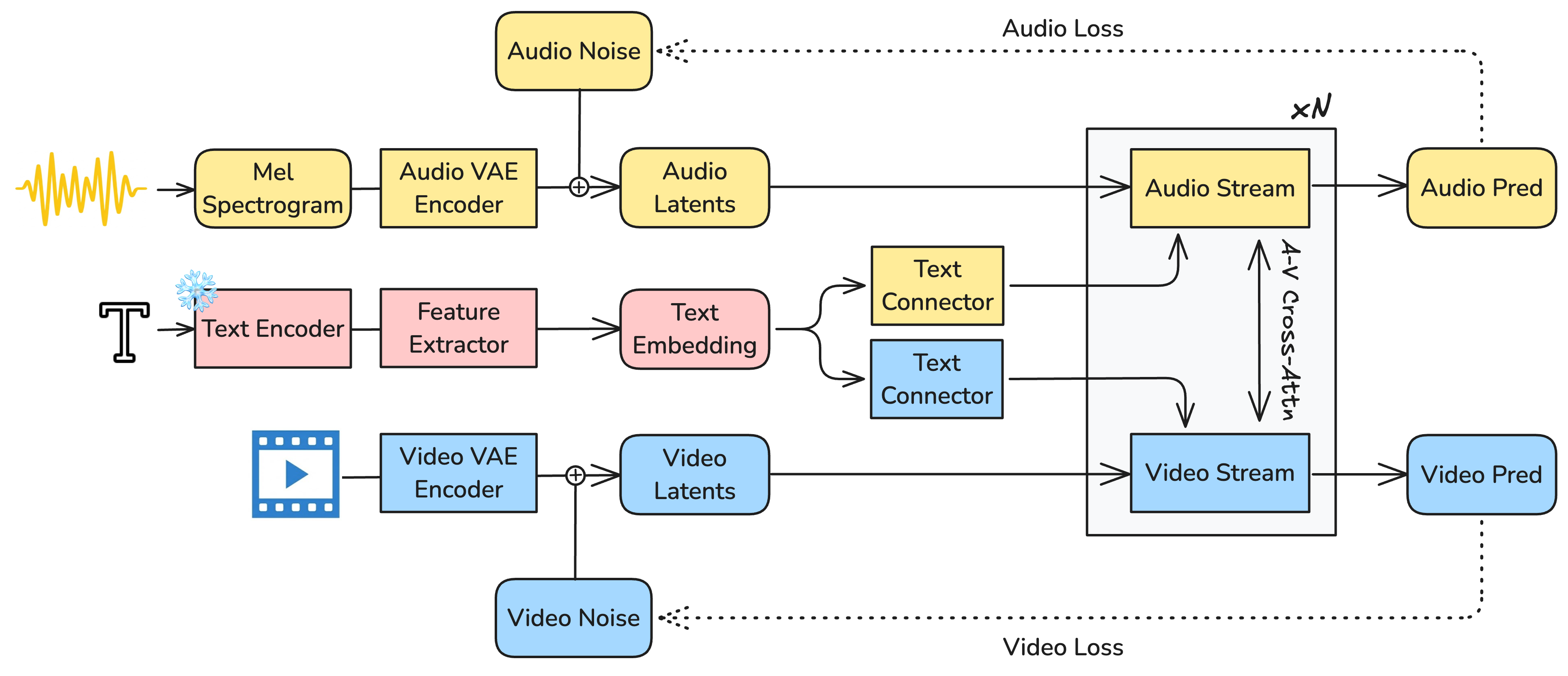
- Two specialized “musicians” (streams): one focuses on video, the other on audio. The video “musician” is bigger because visuals are more complex; the audio one is smaller but skilled at timing and sound detail.
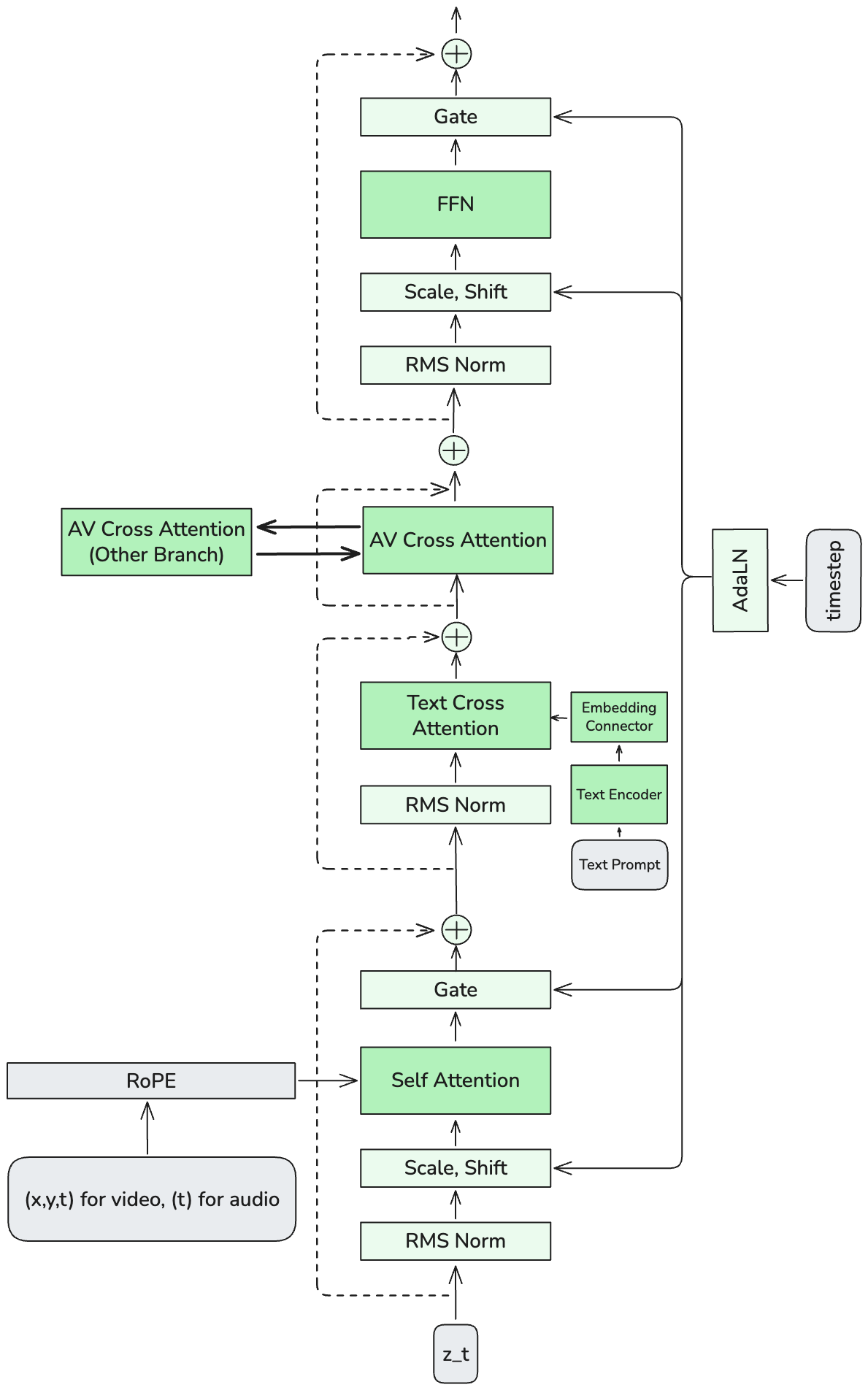
- They “listen” to each other constantly: layers called cross-attention let the video side look at the audio side and vice versa, so footsteps match steps, lips match words, and explosions boom at the right moment.
- They keep time with a shared “metronome”: special timing clues help both sides line up perfectly in time.
Under the hood, three big ideas make this possible:
- Compact building blocks (like zipping files)
- Raw video and audio are too large to handle directly. So each is compressed into a small, smart “latent” form using separate compressors called VAEs: one for video, one for audio. This keeps what matters and tosses what doesn’t, so the model works faster.
- Later, a “vocoder” turns the audio’s compact form back into a realistic stereo waveform (like turning sheet music into a performance).
- A guided cleaning process (diffusion)
- The model starts from noisy “static” and gradually cleans it into a video and a soundtrack that match the prompt—like developing a photo from grainy fuzz until it’s clear.
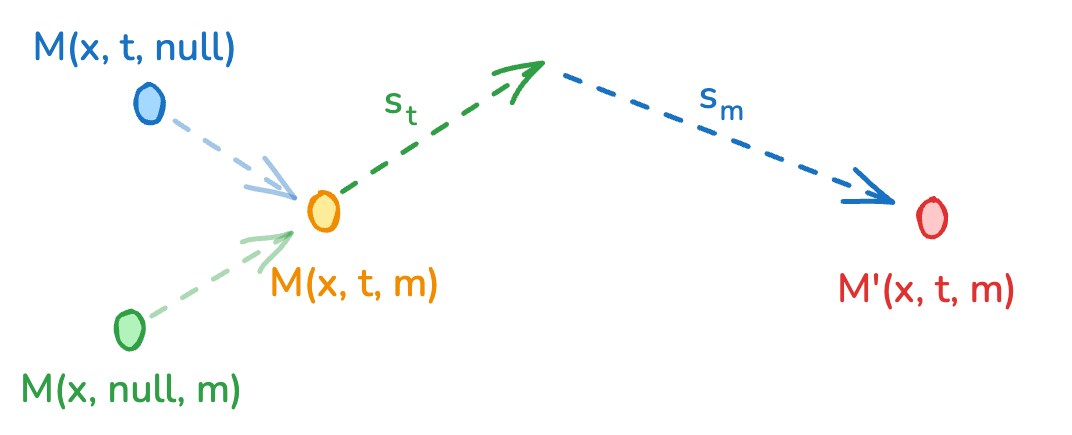
- A steering control called guidance tells the model “follow the text more” or “follow the other modality more.” LTX-2 adds a new twist: separate knobs for how strongly to follow the text and how strongly to follow the other stream, which helps keep sound and picture tightly aligned.
- Strong language understanding (for better speech and prompts)
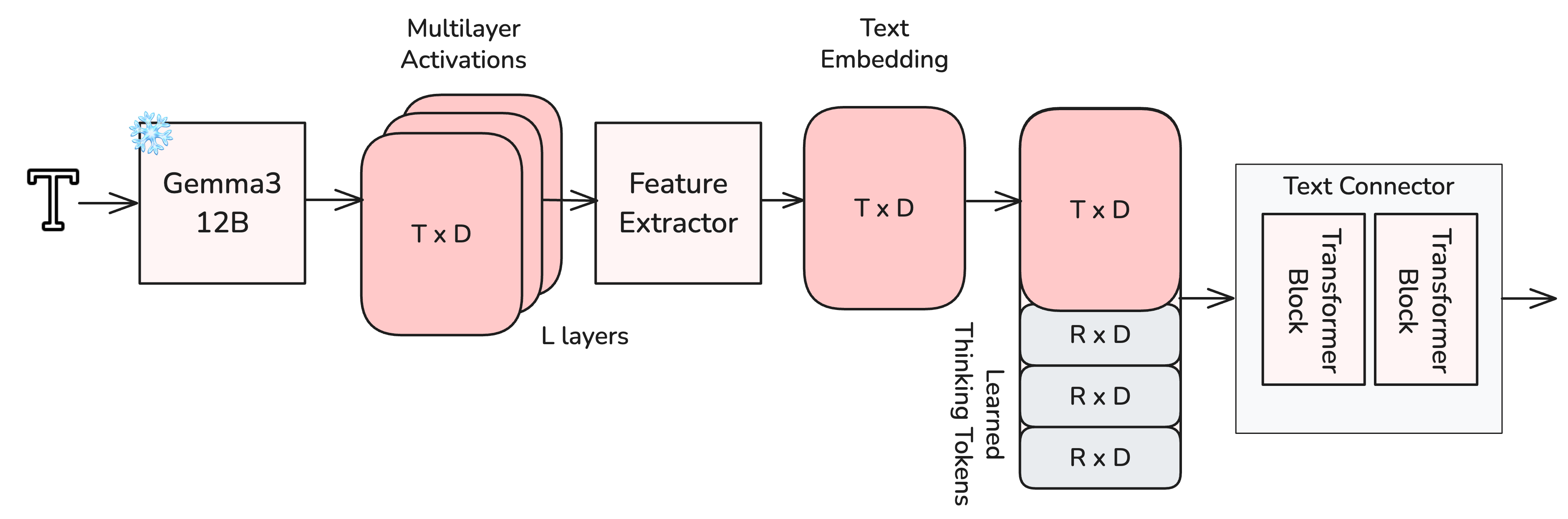
- The model uses a powerful multilingual text encoder so it can understand prompts in many languages.
- It also adds “thinking tokens,” which are like extra scratch-paper notes the model writes to itself to better understand tricky details (names, accents, emotions) before creating the final audio and video.
To generate high-resolution results efficiently, LTX-2:
- First creates a lower-resolution version to set up the scene and timing.
- Then scales up and refines in tiles (like drawing a big poster one square at a time) so it fits in memory while staying seamless.
What did they find, and why does it matter?
The authors report that LTX-2:
- Produces videos with matching, expressive audio: not just speech, but background sounds, foley (like footsteps and door clicks), ambience, and emotion that fit the scene.
- Keeps audio and video tightly synchronized: lips match words, actions match sounds, and timing is precise.
- Runs very fast compared to some popular systems: in one test setup, their model took about 1.22 seconds per step versus 22.30 seconds for a strong video-only baseline—showing big efficiency gains.
- Handles longer clips than many others: up to about 20 seconds with synced stereo audio.
- Stays competitive on video quality alone: the visual side still ranks highly on standard video benchmarks, even though the model is doing both audio and video together.
- Is open-source: the code and model weights are publicly available, which helps the research and creator communities build on it.
These results matter because synchronized sound makes videos feel real and useful. A model that can create both at once, quickly and well, unlocks far more practical and creative possibilities than silent video alone.
What is the impact of this research?
If used responsibly, LTX-2 could:
- Empower creators and small teams to make rich, sound-on videos quickly.
- Help education and accessibility (for example, dubbing content into different languages or adding clear audio cues).
- Support new tools for filmmaking, game design, and social media.
But it also raises concerns:
- Realistic synthetic media can be misused (e.g., deceptive content). The authors stress responsible use, transparency about generated media, and safety measures.
- Like any AI, it can reflect biases in its training data.
- It isn’t a “reasoning” system, so complex storytelling still depends on good prompts or external planning tools.
In short, LTX-2 shows that fast, high-quality, text-driven audio-plus-video generation is possible in a single, unified model. That’s a big step toward more immersive, accessible, and controllable media creation tools.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper leaves the following issues missing, uncertain, or unexplored:
- Dataset transparency and bias: No disclosure of dataset scale, source composition, licensing, language/dialect distribution, or audio category balance (speech/music/foley/ambient), making it hard to assess biases, coverage, and legal reproducibility.
- Captioning pipeline validity: The new audiovisual captioner’s architecture, accuracy, error rates (e.g., dialogue transcription WER/CER, sound event labeling precision/recall), and quality control are not reported; its impact on model performance and bias is unquantified.
- Objective evaluation gaps: Absence of standardized quantitative metrics for audio (e.g., FAD/FAD-KD, PESQ, STOI, SI-SDR), visual quality (e.g., FVD, CLIPSIM, LPIPS), and cross-modal alignment (e.g., lip-sync LSE-C/LSE-D/SyncNet, event-level AV alignment), limiting reproducibility and comparability beyond internal human preferences.
- Lip-sync and event alignment quantification: No rigorous measurement of mouth–audio alignment and time-locked foley accuracy under varied motion, occlusion, and frame rates.
- Generalization to editing workflows: Claims of supporting V2A and A2V are not evaluated; missing protocols, performance metrics, and failure analyses for conditioning on existing video or audio inputs.
- Long-duration robustness: Beyond the reported ~20-second limit, there is no exploration of strategies to mitigate temporal drift (e.g., streaming generation, recurrent memory, hierarchical/chunked latent conditioning) or evaluation on multi-scene narratives.
- Multilingual coverage and phonetic accuracy: No benchmark breakdown across languages/dialects (including code-switching, rare phonemes, non-Latin scripts), nor controllable parameters for accent, prosody, and pronunciation; error rates and alignment differences by language remain unknown.
- Multi-speaker attribution and diarization: No mechanism or evaluation for speaker tracking, turn-taking, or identity consistency; open need for speaker embeddings/diarization and metrics for attribution correctness.
- Controllability of audio components: Lack of explicit controls and evaluations for balancing speech vs. music vs. foley, loudness normalization, dynamic range, and mix/mastering quality; no API-level guidance for fine-grained audio composition.
- Audio fidelity ceilings: The audio latent at 16 kHz and 24 kHz output may limit high-frequency content and music fidelity; no experiments at 44.1/48 kHz or higher bandwidth settings, nor assessment of perceptual artifacts introduced by the audio VAE/vocoder.
- Spatial audio and scene grounding: Stereo is supported, but there is no exploration of 3D/binaural/ambisonic audio or quantitative tests linking visual source location/motion to interaural cues (ITD/ILD), reverberation, and sound propagation consistent with the scene geometry.
- Cross-modal attention design choices: The restriction to temporal 1D RoPE in cross-attention is not ablated against alternatives (e.g., learned temporal aligners, explicit event tokens, spatialized audio features); impact on alignment quality and failure modes remains unclear.
- Cross-modality AdaLN gating: No ablation or analysis of cross-modality AdaLN (placement, parameterization, timestep conditioning strategies) and its contribution to alignment, stability, and convergence.
- Asymmetric dual-stream capacity: No ablations on audio/video parameter ratios, number/location of cross-attention layers, or training-time allocation to determine minimal capacity needed for audio without sacrificing visual quality (or vice versa).
- Thinking tokens and text connector: Missing details on number, initialization, and behavior of thinking tokens; no ablations comparing connector depths, token counts, and multi-layer feature extractor variants vs. using final-layer LLM embeddings.
- Modality-aware CFG behavior: No theoretical or empirical analysis of distribution shift induced by dual guidance (s_t, s_m), guidance schedules across sampling steps, adaptive guidance based on cross-attention signals, or risks of overguidance/mode collapse.
- Training regimen disclosure: Progressive joint training details (stages, losses, curriculum, optimizer settings, batch sizes, LR schedules, compute budget) are omitted, hindering reproducibility and clarity on stability aids (e.g., EMA, gradient clipping, noise schedules).
- Efficiency comparability: The 18× speed claim uses sec/step on a single-step Euler solver and different model setups; total end-to-end sampling steps, solver choices, memory footprint, energy consumption, and latency on varied hardware are not reported, making cross-model comparisons ambiguous.
- Multi-scale/tiled refinement artifacts: No quantitative assessment of tile seams, temporal flicker, or audio–video drift introduced by tiled high-res refinement; tile sizes/overlaps and blending strategies are unspecified.
- Vocoder failure modes: No analysis of vocoder artifacts (e.g., phasiness, pre-echo), robustness across content types (speech vs. music), and stereo consistency metrics; impact of doubled channels vs. alternative architectures remains untested.
- Out-of-distribution robustness: No stress tests on unusual or conflicting audiovisual prompts (e.g., impossible causal couplings), fast motion, extreme lighting, heavy occlusions, or nonstandard frame rates.
- Safety and provenance tooling: No implemented watermarking, content provenance, or synthetic detection mechanisms; bias auditing across visual and auditory modalities and mitigation strategies are not presented.
- Data and code reproducibility: While weights and code are public, the training dataset and captioner are not; end-to-end reproduction and third-party validation of reported results are therefore infeasible without additional releases.
Glossary
- AdaLN: Adaptive Layer Normalization whose scale/shift are conditioned (e.g., on timesteps or another modality). "cross-modality AdaLN for shared timestep conditioning."
- Asymmetric dual-stream transformer: A two-branch transformer with different capacities per modality (e.g., wider for video, narrower for audio). "LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream"
- Audio-Visual Cross-Attention: An attention module that lets audio and video tokens attend to each other to exchange information. "Audio-Visual Cross-Attention for inter-modal exchange"
- Bidirectional cross-attention: Cross-attention applied in both directions so each modality conditions on the other. "coupled through bidirectional audio-video cross-attention layers"
- Bimodal CFG: A two-term extension of classifier-free guidance that separately scales text and cross-modal guidance signals. "a novel Bimodal CFG scheme that allows for independent control over cross-modal guidance scales"
- Causal attention: Unidirectional attention where each token only attends to past tokens in the sequence. "decoder-only architecture employs causal (unidirectional) attention"
- Causal VAE: A variational autoencoder with causal/temporal structure tailored for sequential data. "Raw video and audio signals are encoded into modality-specific latent tokens via causal VAEs"
- Classifier-Free Guidance (CFG): A sampling technique that boosts conditioning without an external classifier by contrasting conditional vs. unconditional model outputs. "we employ a multimodal extension of Classifier-free Guidance (CFG)"
- Cross-modal guidance: A guidance term during sampling that steers one modality using the other modality’s features. "a cross-modal guidance term scaled by "
- Cross-modality AdaLN: AdaLN where one modality’s normalization parameters are conditioned on the other modality. "cross-modality AdaLN for timestep conditioning"
- Decoupled latent representations: Using separate latent spaces for different modalities rather than a shared latent space. "Decoupled Latent Representations."
- Decoder-only LLMs: Autoregressive LLMs composed solely of a decoder stack (no encoder). "decoder-only LLMs typically employ causal attention"
- Diffusion Transformer (DiT): A transformer backbone used for diffusion models operating in latent space. "an asymmetric dual-stream Diffusion Transformer (DiT) architecture"
- Foley: Sound effects that replicate real-world noises to match on-screen actions. "complete with natural background and foley elements"
- Gemma3-12B: A 12B-parameter multilingual LLM used here for text conditioning. "Our conditioning pipeline uses Gemma3-12B~\cite{team2025gemma} as a backbone"
- HiFi-GAN: A GAN-based neural vocoder architecture for high-fidelity waveform synthesis. "we utilize a vocoder based on the HiFi-GAN~\cite{kong2020hifi} architecture"
- Latent diffusion transformers: Diffusion models that operate on compressed latent representations using transformer networks. "large-scale latent diffusion transformers"
- Latent tokens: Compressed vectors representing audio or video after VAE encoding. "latent tokens produced by modality-specific VAEs"
- Latent upscaler: A module that increases the spatial resolution of latent features before final decoding. "The base latents are then processed by a dedicated latent upscaler."
- Mel-spectrogram: A time–frequency representation of audio using the mel scale. "We compute a mel-spectrogram for each channel"
- Modality-aware Classifier-Free Guidance (modality-CFG): CFG variant that enables independent guidance control per modality. "introduce a modality-aware classifier-free guidance (modality-CFG) mechanism"
- Modality-specific VAEs: Separate VAEs tailored for each modality (audio and video). "The model consists of three primary components: (i) modality-specific VAEs"
- Multi-scale, multi-tile inference: Generating at lower scale then upscaling and refining overlapping tiles to reach high resolution efficiently. "we employ a multi-scale, multi-tile inference strategy"
- Rectified Flow: A formulation of diffusion as continuous flow that reduces sampling steps and improves efficiency. "Subsequent advances in Rectified Flow~\cite{lipman2022flow} have further optimized these models"
- RMS normalization: A normalization technique that scales activations by their root-mean-square. "RMS normalization layers are interleaved between the main operations"
- Rotary Positional Embeddings (RoPE): A positional encoding that rotates query/key vectors to inject position information. "The model employs rotary positional embeddings (RoPE) to encode temporal and spatial structure."
- Spatiotemporal causal VAE: A VAE that models both spatial and temporal structure with causal dynamics. "Video latents are obtained from a spatiotemporal causal VAE encoder."
- Thinking tokens: Learnable extra tokens added to text embeddings to carry global/contextual information before conditioning. "It incorporates a learnable set of thinking tokens"
- Tiled Refinement: Refining overlapping latent tiles independently to add high-frequency details before blending. "Tiled Refinement: To achieve 1080p fidelity, the upscaled latents are partitioned into overlapping spatial and temporal tiles."
- Timestep conditioning: Conditioning network layers on the diffusion step index to control denoising behavior. "cross-modality AdaLN for timestep conditioning"
- Unimodal generation: Generation within a single modality considered independently of others. "without degrading the unimodal generation quality of either stream"
- Vocoder: A neural model that converts spectrogram-like features back into a time-domain waveform. "followed by a neural vocoder that reconstructs a 24~kHz waveform"
Practical Applications
Overview
Based on the LTX-2 paper’s findings and innovations (asymmetric dual-stream AV diffusion transformer, modality-aware CFG, decoupled audio/video VAEs, thinking-token text conditioning, 1080p tiled inference, multilingual speech, stereo 24 kHz audio, and open weights/code), the following are practical applications across industry, academia, policy, and daily life. Each item includes sector linkages, plausible tools/workflows, and feasibility notes.
Immediate Applications
- Synchronized foley and ambience for existing videos (V2A)
- Sectors: media/entertainment, advertising, creator economy, game studios (cutscenes), education
- What: Add realistic background, foley, and environmental audio to silent or rough-cut videos with sub-frame temporal alignment.
- Tools/workflows: NLE plugins for Premiere/DaVinci/Final Cut (“Auto Foley,” “Auto Ambience”), batch post-production tools for indie studios, API endpoints for V2A.
- Assumptions/dependencies: GPU-backed inference (server-side), content moderation for inputs/outputs, editorial QA for multi-speaker segments due to potential speaker assignment confusion.
- Rapid previsualization with sound (T2AV)
- Sectors: film/TV, advertising, product teams, education content studios
- What: Generate short storyboard/animatic clips with synchronized audio directly from text prompts for pitch, planning, and iteration.
- Tools/workflows: “Pitch pack” generators producing 10–20 s clips at 720p–1080p with ambience/music; PM tools that attach AV prototypes to briefs.
- Assumptions/dependencies: 20 s duration limit; complex narratives may need LLM-driven prompt sequencing; compute costs per iteration.
- Multilingual micro-explainers and training snippets
- Sectors: education, enterprise L&D, NGOs
- What: Short explainers (e.g., safety procedures, product intros) with narration and matching lip/motion cues, across supported languages.
- Tools/workflows: “One-pager to video” tools; LMS integrations; template libraries with adjustable guidance knobs for stronger text or AV alignment via modality-aware CFG.
- Assumptions/dependencies: Language coverage varies; target dialects may degrade; compliance review for regulated topics.
- Social and marketing content with coherent soundscapes
- Sectors: creator economy, SMB marketing, e-commerce
- What: Generate ads/reels/posts with consistent sound design (music, ambience, spot effects) aligned to visual events and emotions.
- Tools/workflows: Web studios for T2AV generation; presets for “product unboxings,” “fashion B-roll,” “food sizzle” with audio themes.
- Assumptions/dependencies: Brand safety filters; music licensing if mixing external tracks; short-form (<20 s) focus.
- A2V “podcast-to-B-roll” or “voice-to-visuals” prototyping
- Sectors: media, publishing, education
- What: Use spoken clips (interviews, lectures) to drive B-roll video that visually contextualizes the audio content.
- Tools/workflows: Audio segment import + A2V timeline; adjustable cross-modal CFG to prioritize audio-driven visuals; batch generation for segments.
- Assumptions/dependencies: Faithfulness depends on caption/LLM prompt quality; identity preservation not guaranteed; editorial oversight required.
- Game and XR prototyping: auto-foley for cutscenes and trailers
- Sectors: gaming, XR
- What: Quickly sonify pre-rendered cutscenes/trailers with time-aligned foley and ambience; create mood-setting AV teasers.
- Tools/workflows: V2A batch tools; shot-by-shot generation at 1080p using tiled inference; fine control with CFG sliders.
- Assumptions/dependencies: Not a replacement for final interactive audio pipelines; stereo (not spatial/binaural); temporal scope per shot.
- Accessibility and localization helpers (first steps)
- Sectors: public sector, education, media localization
- What: Generate dubbed audio tracks for existing videos in target languages; create alternate AV versions for different audiences.
- Tools/workflows: Input: video + translated script prompt; Output: aligned target-language narration with ambience. Optional: use an LLM-based describer to author narration text, then V2A to render voiceover with ambient sound.
- Assumptions/dependencies: Lip motion in the original video will not perfectly match new language; A2V re-animation would be needed for full lip sync (see long-term). Language coverage and accent control vary.
- Research baseline for joint AV generation
- Sectors: academia, R&D labs
- What: Open weights for studying cross-modal attention, modality-aware CFG, thinking-token conditioning, and AV evaluation protocols.
- Tools/workflows: Ablation suites; visualization of attention maps for interpretability; integration with existing T2V/T2A benchmarks and AV datasets.
- Assumptions/dependencies: Reproducibility requires consistent vocoder and text-encoder settings; dataset licensing for any retraining.
- Synthetic AV datasets for perception research
- Sectors: academia, robotics/perception research
- What: Generate diverse, synchronized AV clips for training and testing audio-visual models (e.g., event localization, AV correspondence).
- Tools/workflows: Programmatic prompt libraries; controlled scene parameters; automatic labeling via known prompts/timecodes.
- Assumptions/dependencies: Domain gap to real-world data; stereo (not spatial); bias transfer from training data.
- Developer integrations and creative tooling
- Sectors: software/devtools
- What: SDKs/APIs for T2AV/V2A/A2V; UI “knobs” for cross-modal guidance; tiled 1080p inference for longer/denser scenes.
- Tools/workflows: Cloud inference microservices; queue-based batch processing; presets for s_t/s_m CFG weights per use case.
- Assumptions/dependencies: Compute scaling; caching; content filters; usage metering.
Long-Term Applications
- End-to-end dubbing with lip reanimation (audio-driven video)
- Sectors: media localization, film/TV, education
- What: Maintain original actor identity while re-synthesizing mouth and facial motion to match target-language speech; consistent ambience.
- Dependencies/assumptions: Identity-preserving A2V with face-specific controls; rights and ethical consent; speaker attribution robustness; higher-resolution facial modeling.
- Long-form content (> minutes) with cross-scene coherence
- Sectors: media, education, enterprise comms
- What: Multi-shot narratives with consistent characters, settings, and evolving soundscapes; integrated scene planning and continuity.
- Dependencies/assumptions: Memory and planning modules (LLMs/agents), scene stitching, audio continuity, mitigation of temporal drift beyond 20 s, scalable training/inference.
- Real-time or live interactive AV co-creation
- Sectors: streaming, virtual events, live support/assistants
- What: Near-live T2AV performance (e.g., virtual hosts, avatars) responding to prompts or audience inputs with synchronized visuals and speech.
- Dependencies/assumptions: Further sampling step reduction (e.g., rectified flow advances), model distillation/quantization, streaming inference, latency budgets, robust safety gating.
- Spatial/binaural audio and 3D-aware video for AR/VR
- Sectors: XR, gaming, simulation
- What: Generate visuals with consistent spatial audio (binaural/ambisonics) aligned to scene geometry and movement.
- Dependencies/assumptions: Extend audio VAE/vocoder to multi-channel spatial formats; integrate 3D scene understanding; head-tracked sound rendering.
- Audio-visual simulation for robotics and embodied AI
- Sectors: robotics, autonomous systems
- What: Train AV perception and event detection with physics-consistent audio-visual scenes (e.g., collisions, material interactions).
- Dependencies/assumptions: Tighter physical grounding and material property controls; domain adaptation; procedural scenario generation.
- Personalized content at scale (dynamic ads, training, wellness)
- Sectors: advertising, HR/L&D, healthcare/wellness
- What: Tailor short AV clips (language, tone, imagery, ambience) to users or cohorts; therapeutic scenes (e.g., relaxation environments).
- Dependencies/assumptions: Preference modeling and guardrails; clinical validation for wellness; consent and privacy compliance.
- On-device or edge deployments
- Sectors: mobile, embedded systems, creative hardware
- What: Lightweight versions for mobile creation apps and in-studio preview devices.
- Dependencies/assumptions: Model compression/distillation; memory-aware VAEs/vocoders; hardware acceleration; reduced quality acceptance.
- Content provenance and detection ecosystems
- Sectors: policy, platforms, cybersecurity
- What: Standardized watermarking and provenance for joint AV content; adversarially robust detection of synthetic AV.
- Dependencies/assumptions: Coordination with C2PA/content credentials; robust audio+video watermarking; platform-level enforcement.
- Low-resource language support and accent control
- Sectors: education, government services, media localization
- What: High-quality T2AV in underrepresented languages/dialects; culturally faithful dubbing and narration.
- Dependencies/assumptions: Targeted data collection; bias mitigation; phonetic coverage; community review.
- Tooling for controllable AV generation
- Sectors: software, creative suites
- What: Fine-grained controls over foley type, microphone perspective, reverberation, and scene acoustics; per-object sound binding.
- Dependencies/assumptions: Conditioning schemas and UI design; disentangled latent controls; training with structured AV annotations.
Key Assumptions and Dependencies (cross-cutting)
- Compute and latency: The 19B dual-stream model requires GPU acceleration; while per-step is fast, total latency depends on step count and resolution. Real-time use cases require further step reductions, distillation, or specialized solvers.
- Temporal scope: High-quality synchronization is demonstrated for clips up to ~20 s; longer durations risk drift without additional planning and continuity mechanisms.
- Language and speakers: Performance varies across underrepresented languages/dialects; multi-speaker scenes may confuse speaker assignment.
- Audio format: Current pipeline reconstructs stereo at 24 kHz; professional workflows may require 48 kHz or spatial formats (future extensions needed).
- Ethical/legal: Rights and consent for likeness and voices; watermarking/provenance; platform and regulatory policies for synthetic media disclosure.
- Integration: For dubbing/localization and accessibility, best results come from pairing LTX-2 with upstream LLMs for script generation/adaptation and downstream NLE workflows for editorial control.
- Data bias: Outputs may reflect biases in training data; careful prompt design and post-edit review remain necessary.
Collections
Sign up for free to add this paper to one or more collections.