- The paper introduces JAM-Flow, a unified framework that jointly synthesizes facial motion and speech using flow matching and a multi-modal diffusion transformer.
- It employs dual-stream diffusion with joint attention layers, scalable rotary positional embeddings, and modality-specific masking for robust cross-modal alignment.
- Experiments on standard datasets show competitive performance in talking head generation and text-to-speech, with an emergent capability for automated video dubbing.
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
This paper introduces JAM-Flow, a novel framework for the joint synthesis of facial motion and speech. The framework addresses the limitations of existing approaches that typically handle talking head generation and text-to-speech (TTS) as separate tasks, despite the inherent connection between facial movements and spoken language. JAM-Flow leverages flow matching and a custom Multi-Modal Diffusion Transformer (MM-DiT) architecture to enable simultaneous generation and conditioning of both audio and facial motion. The model supports various input configurations, including text, reference audio, and reference motion, facilitating tasks such as talking head generation from text, audio-driven animation, and cross-modal reconstruction within a single, unified model.
Methodological Details
JAM-Flow employs a dual-stream diffusion architecture composed of an Audio-DiT and a Motion-DiT, which are partially fused via joint attention blocks (Figure 1). The Motion-DiT generates expression embeddings that control lip motion, while the Audio-DiT generates mel-spectrograms using conditional flow matching. To facilitate cross-modal interactions, the authors introduce joint attention layers between the audio and motion streams. Scaled rotary positional embeddings (RoPE) are applied to align temporal semantics between modalities. Furthermore, a carefully designed attention masking strategy is adopted to promote modality-specific learning while ensuring coherent cross-modal alignment.
## Implementation and Training
The training procedure involves two stages. In the first stage, the pretrained Audio-DiT from F5-TTS is frozen, and the Motion-DiT is trained from scratch with joint attention layers inserted. In the second stage, both DiTs are jointly trained using shared joint attention blocks, allowing for mutual refinement of representations. The model is trained on the CelebV-Dub dataset, and experiments are conducted on NVIDIA RTX 6000 Ada GPUs.
Experimental Results and Analysis
The paper presents quantitative evaluations of the proposed model on several tasks, including talking head generation, TTS, and automated video dubbing. For talking head generation, the model is evaluated on the HDTF dataset using metrics such as FID, FVD, LSE-C, and LSE-D, achieving competitive performance compared to state-of-the-art methods. For TTS, the model is evaluated on the LibriSpeech-PC test-clean benchmark using WER and SIM-o, with a slight degradation in performance attributed to the characteristics of the training dataset. The model also demonstrates an emergent capability for automated video dubbing, generating speech that aligns well with lip movements in given videos. Ablation studies are conducted to assess the impact of design choices, such as the number of joint attention blocks, motion attention masking, and Audio-DiT finetuning.
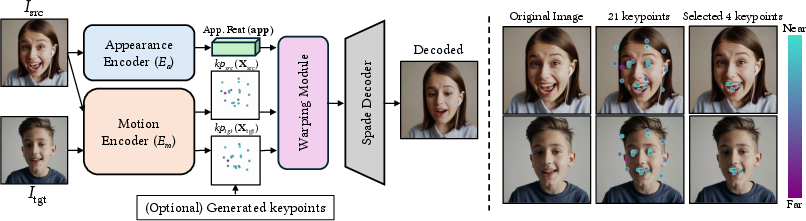
Figure 2: Mouth-related expression keypoint analysis using the LivePortrait framework.
Qualitative results demonstrate the model's strong performance across various settings involving joint audio-video generation. The model generates lip motion that aligns well with given audio, synthesizes speech with high temporal consistency in automated video dubbing scenarios, and adapts to the speaker's lip motion when modifying text while keeping the input video fixed. The model can also be used to re-dub videos using different speakers' voices while preserving the original lip motion.
Discussion and Ethical Considerations
The authors highlight the importance of partial joint attention and localized temporal masking for stable and coherent multimodal generation. They also observe that the generated speech often reflects emotional cues from facial motion, suggesting implicit alignment of emotion across modalities. The model's versatility in supporting diverse input configurations within a single framework is emphasized as a major strength. The ethical considerations associated with the model are addressed, including the potential for misuse to generate deceptive content or amplify biases, with a proposed mitigation strategy involving robust watermarking techniques and restricted access for academic use under ethical guidelines.
Conclusion
The paper concludes by presenting a unified flow-matching-based architecture for joint speech and facial motion generation, capable of handling diverse conditioning inputs. The model combines modality-specific DiT modules with selectively applied joint attention, aligned positional embeddings, and attention masking, enabling coherent multimodal synthesis without separate pipelines. Experimental results demonstrate competitive performance across talking head and TTS tasks, as well as flexible and compositional inference scenarios. The authors acknowledge limitations related to data and compute resources and propose future directions involving more curated datasets and stronger video diffusion models.