From Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Abstract: Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making “visual dubbing” better. Visual dubbing means changing the mouth movements in a video so they match new audio (like translating a movie into another language) without changing who the person is or the look of the scene. The authors introduce a system called X-Dub that treats dubbing as careful video editing, not as guessing missing parts, so it makes lip movements match speech more accurately and keeps the person’s identity and the scene looking natural—even with obstacles like hands covering the mouth or changing lighting.
Key Objectives and Questions
The paper focuses on three simple questions:
- How can we sync lips to new speech without messing up the person’s face or the background?
- How can we train a model when it’s impossible to collect perfect training pairs (two videos that are identical except for lip movements)?
- Can we design training so the model learns big-picture structure first, then lip movements, then fine details, to avoid conflicts?
Methods in Simple Terms
Think of the problem like this: most older methods “cover” the lower half of the face and try to fill it back in, guided by the audio. That’s called “inpainting.” It’s like erasing part of a photo and asking a program to redraw it from scraps. This can cause mistakes: weird mouth shapes, blurry edges, or the person looking slightly different.
X-Dub switches to an “editing” approach, which is more like using a smart video editor that sees the full original video and only tweaks the mouth area to match the new audio. The key idea is to give the model complete visual context (the whole video) so it doesn’t have to guess what’s missing.
Here’s how it works:
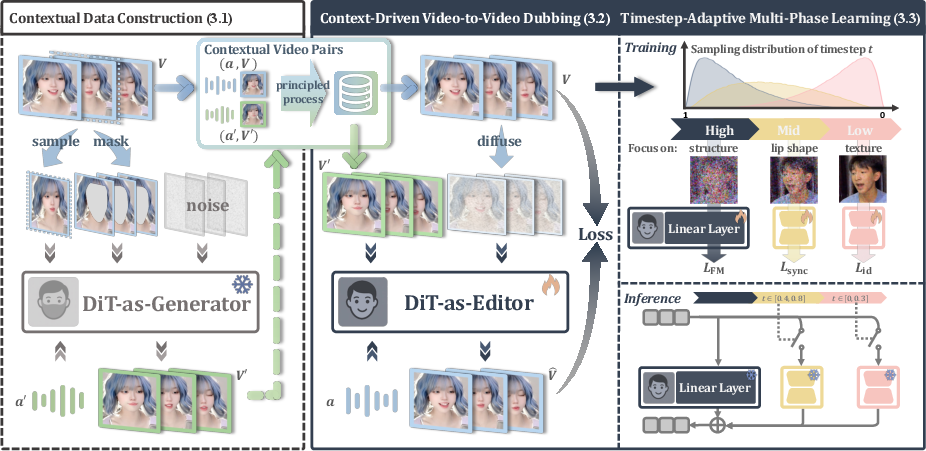
Step 1: Make practice pairs (the Generator)
- Problem: In real life, you can’t record two identical videos where only the lips differ. So the authors build a “generator” model to create “companion videos.”
- The generator takes a real video and a different audio clip and produces a new version where lip movements change while everything else stays the same (same person, pose, lighting, background).
- This gives the team “paired videos” that are aligned frame by frame: one with original lips, one with edited lips. Even if the generator isn’t perfect, it’s good enough for training the next step because the two videos match closely in everything except lip motion.
Analogy: It’s like making your own practice worksheets. Even if the worksheets aren’t perfect, they’re aligned and helpful for learning.
Step 2: Learn to edit using full context (the Editor)
- With these paired videos, the “editor” model learns to do dubbing directly: it sees the companion video and the target audio and learns to produce the target video (the version with correct lip sync and preserved identity).
- Because the editor gets complete, aligned video frames as context, it can focus on just the lip area—keeping the rest of the image unchanged. This reduces errors like identity drift or artifacts at mask boundaries.
Analogy: The editor is like a careful retoucher who has the original photo and a perfectly aligned reference—so they only adjust the mouth, not the whole face.
Training Trick: Learn in phases (timestep-adaptive multi-phase learning)
- The authors use a “diffusion” model (a kind of model that improves frames step by step, like slowly cleaning a noisy image).
- Different steps specialize in different things:
- Early steps: learn the big picture (head pose, background, overall identity).
- Middle steps: focus on lip shape and movement to match speech.
- Late steps: refine textures and fine details (skin, teeth, subtle identity features).
- They add small specialist modules (called LoRA experts) that kick in at the right phase. This keeps learning stable and avoids the model “fighting with itself” over what to improve first.
Analogy: It’s like painting in layers: sketch the scene, draw the lips accurately, then polish the details.
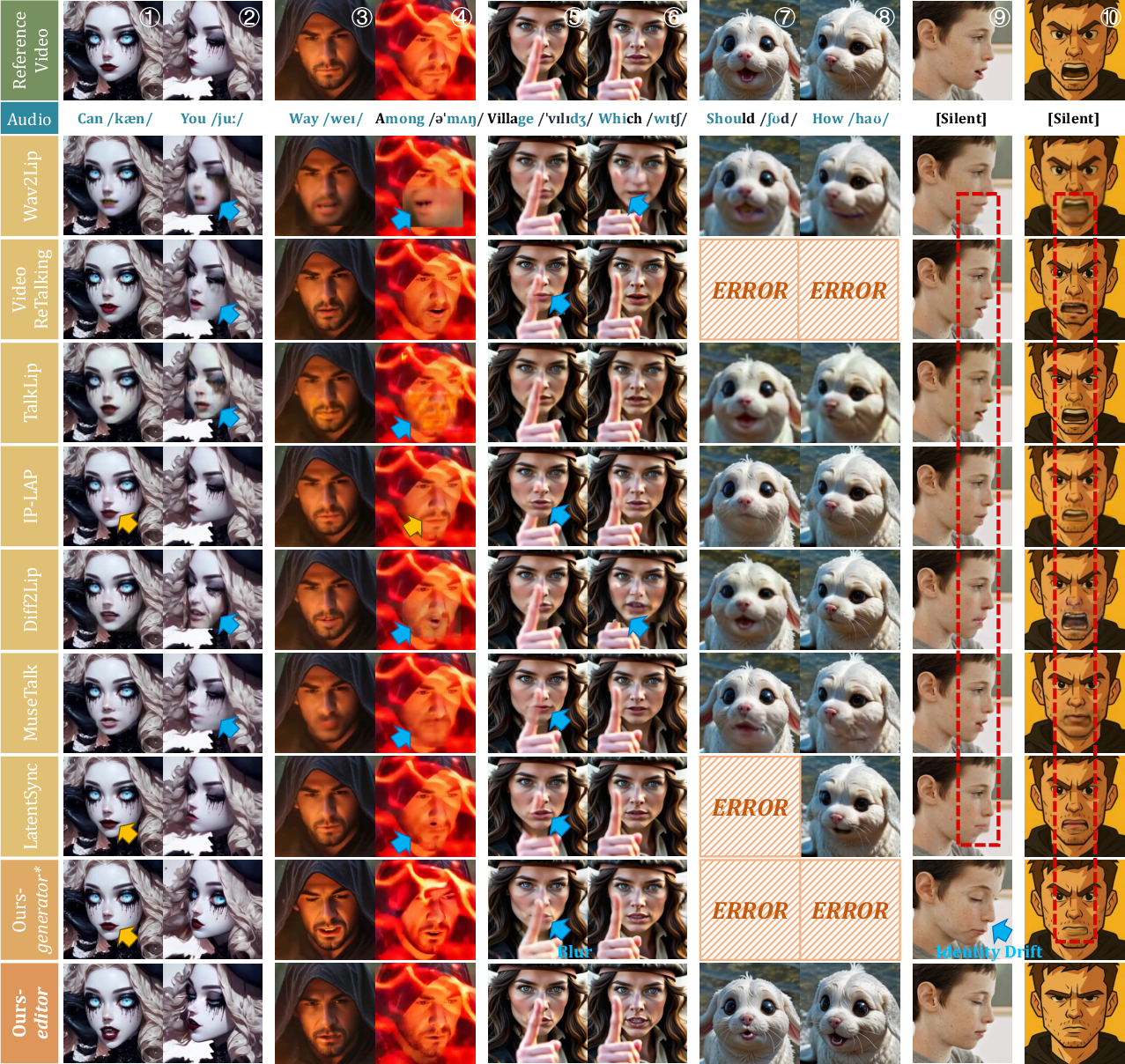
Main Findings and Why They’re Important
In tests on both a standard dataset (HDTF) and a new, tougher benchmark (ContextDubBench), X-Dub:
- Matches lips to speech more accurately than previous methods.
- Keeps the person’s identity more faithful (no “who is that?” effect).
- Shows higher visual quality and smoother motion over time.
- Is much more reliable in difficult scenarios (side profiles, hands or objects covering the mouth, dynamic lighting, stylized characters).
Highlight results:
- On the challenging ContextDubBench, the editor achieved a 96.36% success rate (many older methods were around 60–70%).
- Lip-sync consistency was clearly higher.
- Visual quality and identity similarity were stronger.
- User studies (people rating videos) preferred X-Dub for realism, lip sync, identity, and overall quality.
These results matter because real-world dubbing needs to work in messy situations, not just studio-perfect videos.
Implications and Impact
- Better multilingual dubbing: Films, shows, and online videos can be translated so the lips match the new language naturally, increasing immersion.
- More realistic avatars: Personalized avatars in games, virtual meetings, or educational tools can speak accurately without losing identity.
- Robust “in-the-wild” performance: Works on tricky footage with occlusions, changing lighting, or stylized visuals—important for social media and creative use.
- A new training strategy: The “self-bootstrapping” idea—using a generator to build paired training data for an editor—could help other video editing tasks where collecting perfect pairs is impossible.
- A stronger benchmark: ContextDubBench gives researchers a tougher, realistic testbed to evaluate future methods.
In short, X-Dub shows that treating dubbing as careful, context-rich editing—and teaching the model in smart phases—makes lip syncing more accurate, visuals more faithful, and real-world reliability much higher.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future work.
- Impact of synthetic-pair quality: The editor’s performance likely depends on the fidelity and alignment of the generator-produced companion videos, but the paper does not systematically quantify how specific artifact types (e.g., mouth-shape inaccuracies, identity blur, relighting mismatches) propagate to the editor or define minimum quality thresholds for usable pairs.
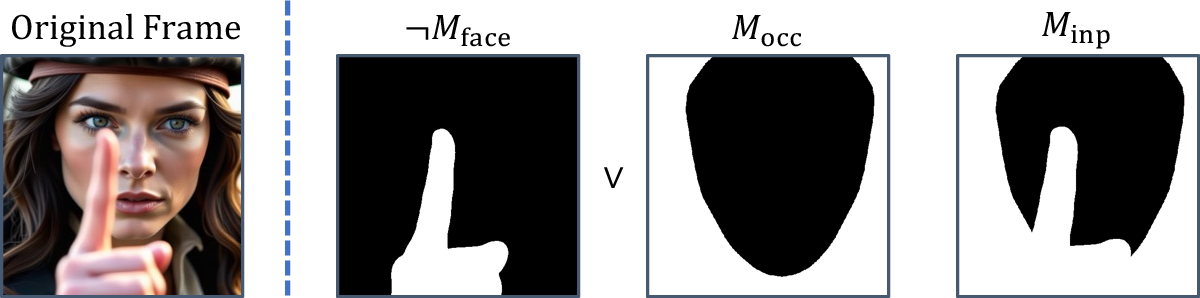
- Automated occlusion handling: The data creation pipeline “annotates and excludes facial occluders,” but it is unclear whether this is manual, semi-automatic, or fully automated. The scalability, reliability, and failure modes of occluder detection/annotation under diverse in-the-wild conditions are not evaluated.
- Cross-speaker dubbing: Companion audio is sampled from the same speaker to reduce conflicts, leaving open how the framework handles cross-speaker dubbing where timbre, accent, and speaking style differ (including cross-gender timbre shifts) without identity drift or uncanny mouth movements.
- Prosody and expressive non-lip edits: The method focuses on lip movements while preserving pose and other facial cues, but audio-driven changes in cheeks, jaw, and subtle expressions (prosody, emphasis, emotion, singing vibrato) are not explicitly modeled or evaluated; potential trade-offs between strict preservation and natural expressivity remain unaddressed.
- Teeth and tongue realism: There is no targeted modeling, supervision, or evaluation for teeth/tongue visibility and dynamics, which are critical for realism and intelligibility, especially for open-mouth phonemes and singing.
- Long-form stability: Training and data construction rely on 25-frame segments linked into 77-frame sequences; the stability, drift, and boundary artifacts over minute-long or hour-long videos, as well as streaming scenarios, are not characterized.
- Real-time performance and compute: The DiT backbone and contextual concatenation likely incur significant memory and latency costs. The paper does not report inference throughput (fps), resource requirements, or feasibility for real-time dubbing on consumer hardware.
- Robustness to fast motion and extreme poses: Although challenging scenarios are shown qualitatively, there is no targeted stress-test or metric suite focusing on rapid head motion, extreme side profiles, motion blur, and camera shake.
- Non-human or stylized domains: The paper claims robustness to stylized or non-human characters, but does not quantify domain coverage, training exposure to such content, or characterize failure cases across different stylization levels and art styles.
- Fairness and demographic bias: There is no analysis of performance across age, skin tones, facial hair, makeup, or cultural attire. Potential biases inherited from training data and their impact on lip sync and identity fidelity are unexamined.
- Multilingual and accent diversity: While six languages are reported, there is no breakdown by language, accent, speaking rate, or phoneme inventories to assess phoneme-to-viseme mapping accuracy and generalization across linguistic diversity.
- Noisy audio and reverberation: Robustness to real-world audio artifacts (background noise, reverb, compression, clipping) is not studied; Whisper features are used, but comparative analysis with other audio encoders or noise-robust training is missing.
- Reliance on
SyncNetfor lip-sync supervision: The approach depends on SyncNet confidence as both a training signal and metric; the sensitivity of training outcomes to SyncNet errors, language coverage, and domain shift is not explored. - Context dependence at inference: The editor edits lips based on full-reference frames without explicit spatial masks; failure cases where editing leaks beyond the mouth region (e.g., chin/cheek artifacts) or conflicts with occlusions/lighting changes are not cataloged.
- Ethical safeguards and misuse mitigation: The paper does not address detection, watermarking, consent, or provenance mechanisms to curb misuse (e.g., deepfakes), nor propose policy or technical safeguards in deployment settings.
- Loss-function choices: Flow-matching is adopted, but the paper does not compare against alternative diffusion objectives (e.g., noise prediction, consistency models) for dubbing-specific stability, lip precision, or texture fidelity.
- Timestep scheduling sensitivity: The multi-phase training uses fixed timestep ranges and hand-chosen
αshifts; sensitivity analyses, automatic schedule learning (e.g., curriculum via validation signals), or generalization to different DiT architectures are not provided. - 3D VAE compression artifacts: The effect of latent compression on identity details, fine mouth textures, and temporal consistency is not evaluated; it remains unclear how codec choices and compression rates affect dubbing realism.
- Evaluation limits without ground-truth pairs: Since ideal pairs do not exist in the real world, metrics like FID/FVD and SyncNet only partially reflect dubbing quality. User studies are small-scale; stronger task-specific metrics (e.g., phoneme-level visual intelligibility, human lip-reading accuracy) are missing.
- Domain shift from 3D-rendered pairs: Synthetic 3D-rendered data are used to supplement training, but the impact of domain gap on real footage performance and potential overfitting to rendered artifacts are not assessed.
- Reproducibility of data construction: Key steps (e.g., occluder handling, relighting augmentation, extended generator training) are described at a high level; reproducibility, required annotations, and pipeline failure modes are not fully documented.
- Audio-driven head/jaw coupling: The framework preserves head pose and global motion, but audio-driven micro head/jaw movements that accompany speech are not modeled; the trade-off between strict preservation and natural speech-coupled motion is not analyzed.
- Multi-person scenes: The method and benchmark focus on single-subject talking videos; behavior in multi-face or group scenes (speaker identification, selective editing, identity interference) is not addressed.
- Background/body coherence: Beyond facial regions, audio-driven synchronization of subtle body motion (e.g., breathing, neck/throat movement) and its coherence with edited lips is not measured or modeled.
- Learned spatial localization: The editor relies on attention across concatenated frames; exploring learned spatial masks or segmentation-guided editing (to confine changes strictly to speech-relevant regions) remains an open direction.
- Robustness to compression and streaming artifacts: Performance under common video delivery artifacts (low bitrate, heavy compression, packet loss) is not reported.
- Occlusion-specific metrics: Although occlusion scenarios are considered, there are no occlusion-focused quantitative metrics or benchmarks to isolate and measure performance under varied occluder types and dynamics.
Practical Applications
Overview
Based on the paper’s self-bootstrapping, context-rich visual dubbing framework (X-Dub), the following applications translate its findings and methods into practical deployments across industry, academia, policy, and daily life. The list is grouped by deployment horizon and highlights sectors, possible tools/products/workflows, and feasibility constraints.
Immediate Applications
- High-fidelity multilingual dubbing for film/TV/OTT
- Sector: Media & Entertainment
- What: Replace the mask-inpainting pipeline with context-rich video-to-video lip editing for accurate multilingual dubbing; improved identity preservation and robustness to occlusions, lighting changes, and profiles.
- Tools/products/workflows:
- “X-Dub Studio” as a post-production service or SaaS
- NLE plugins for Adobe Premiere/After Effects and DaVinci Resolve
- Batch dubbing pipelines for OTT platforms (script → TTS/voice actor audio → X-Dub editor → QC via SyncNet/CLIP/ArcFace → delivery)
- Dependencies/assumptions:
- GPU compute for diffusion-based inference
- Licensed use of likeness; actor/performer consent and union rules
- High-quality audio (voice actor or TTS) and robust speech segmentation
- Current throughput best suited for offline post-production rather than live use
- Automated ADR/VO fix-ups and last‑minute script changes
- Sector: Media & Entertainment; News & Broadcast
- What: Align existing footage to updated audio (correct mispronunciations, time constraints, or legal changes) with precise lip edits while preserving context (lighting/occlusions).
- Tools/products/workflows:
- “ADR Assistant” plugin that swaps new VO while maintaining identity and scene continuity
- Dependencies/assumptions:
- Clean dialogue audio aligned to the intended timing; editorial sign-off
- GPU availability in finishing suites
- Marketing/ad localization at scale
- Sector: Advertising & Marketing
- What: Localize ad creative to multiple languages with natural lip sync and brand/identity fidelity using the same footage.
- Tools/products/workflows:
- Batch localization service integrated into ad ops (CMS ↔ dubbing API ↔ QA metrics dashboard)
- Dependencies/assumptions:
- Brand approvals; actor likeness rights across markets
- Integration with TTS providers for consistent voice identity
- E-learning and corporate training localization
- Sector: Education; Enterprise L&D
- What: Convert training videos into multiple languages with lifelike lip alignment—improving engagement and reducing re-shoots.
- Tools/products/workflows:
- LMS integration: content ingestion → TTS/voice over → X-Dub → automated QC → publish
- Dependencies/assumptions:
- Stable corporate compute or managed service
- QA gates to ensure terminology and brand guidelines compliance
- VTuber/animation and game cutscene lip-sync enhancement
- Sector: Gaming; Creator Economy
- What: Robust lip edits for stylized characters and synthetic footage, improving VTuber streams and cutscenes.
- Tools/products/workflows:
- Plug-ins for animation/VTuber studios; post-process cinematic videos
- Dependencies/assumptions:
- Domain fit: robust even for stylized subjects but may need finetuning for specific art styles
- GPU resource availability
- Accessibility: Lip-readable video variants
- Sector: Accessibility; Public Sector; Education
- What: Create lip-readable versions of videos with highly accurate articulation to assist people who rely on lip reading.
- Tools/products/workflows:
- “Accessible Dub” pipeline: closed captions/TTS → precise lip edit → distribution
- Dependencies/assumptions:
- Careful QA to ensure phoneme-level articulation quality for target languages
- Ethical disclosure and user expectations management
- Robust dubbing QC and vendor evaluation
- Sector: Media QA; Procurement; R&D
- What: Adopt ContextDubBench as a standardized evaluation set; integrate SyncNet/ArcFace/CLIP/LPIPS/NIQE/BRISQUE/HyperIQA into automated QC.
- Tools/products/workflows:
- “Dubbing QA Dashboard” with pass/fail thresholds per content type
- Benchmarking during vendor selection and model regression testing
- Dependencies/assumptions:
- Agreement on metric thresholds by stakeholders
- Dataset extensions for domain-specific content
- Synthetic data generation for research
- Sector: Academia; AI R&D
- What: Use the generator to produce paired, lip-varied companions for training/evaluating models in lip reading, audiovisual alignment, and disentangled representation learning.
- Tools/products/workflows:
- Data augmentation pipelines for AV models (paired samples with controlled lip variation)
- Dependencies/assumptions:
- Compute for large-scale generation; IRB/ethics for human subjects data where applicable
- General-purpose video editing: local lip-only edits without masks
- Sector: Software Tools; Post-production
- What: Use mask-free, context-driven editing to correct only mouth regions while preserving scene continuity.
- Tools/products/workflows:
- “Lip Precision Slider” and “Texture Fidelity Slider” UI built on timestep-adaptive LoRA experts for fine editing control
- Dependencies/assumptions:
- Editor integration and user training; compute requirements
Long-Term Applications
- Real-time, on-device visual dubbing for live translation
- Sector: Communications; Enterprise; Education; Government
- What: Live video conferencing with translated audio and synchronized lip movements (reduced cognitive dissonance).
- Tools/products/workflows:
- Streaming inference stack with low-latency DiT variants; edge accelerators
- Dependencies/assumptions:
- Significant model compression/optimization; latency <150 ms round-trip
- Robust diarization and face tracking for multi-speaker meetings
- Network stability and privacy/compliance assurances
- Customer service avatars and social robots with natural mouth movements
- Sector: Retail; Banking; Hospitality; Robotics/HRI
- What: Real-time TTS-driven digital humans or robots with lifelike lip sync across languages.
- Tools/products/workflows:
- On-device lightweight editor integrated with TTS; controllable expression via multi-phase LoRA controls
- Dependencies/assumptions:
- Hardware accelerators (NPUs/GPUs) on kiosks/robots
- Safety, privacy, and local language support
- AR/VR telepresence and digital twins
- Sector: XR; Enterprise Collaboration; Training
- What: Telepresence with accurate, context-consistent lip edits in immersive environments; digital human employees for training or demos.
- Tools/products/workflows:
- XR SDKs with integrated lip editing; joint control over lips, expressions, and gaze
- Dependencies/assumptions:
- High frame-rate, low-latency inference; synchronization with 3D or neural rendering pipelines
- Multi-speaker and scene-level dubbing
- Sector: Media & Entertainment; Education
- What: Extend editor to multi-speaker scenes, automatically diarize and lip-edit multiple faces in dynamic shots.
- Tools/products/workflows:
- “Scene Dubbing Orchestrator” that binds diarization/tracking → per-face editing → compositing
- Dependencies/assumptions:
- Reliable multi-face tracking; diarization and shot-boundary handling
- Additional training on multi-speaker datasets
- Expressive, controllable audiovisual editing beyond lips
- Sector: Media Tools; Gaming; XR
- What: Expand timestep-adaptive multi-phase training to control prosody, emotion, micro-expressions, and texture stylization.
- Tools/products/workflows:
- “Phase-aware Expression Controls” in NLEs for creative direction (e.g., dial-in smile intensity or style)
- Dependencies/assumptions:
- Extended training with expression labels; user interfaces for intuitive control
- Compliance, provenance, and watermarking policies and tools
- Sector: Policy & Governance; Media Standards; Legal
- What: Use ContextDubBench-like protocols to define acceptance tests for broadcast; integrate watermarking and C2PA provenance for AI-dubbed media.
- Tools/products/workflows:
- Compliance audit suite using benchmark metrics; automated disclosure insertion
- Dependencies/assumptions:
- Industry consensus on thresholds and disclosures; regulatory clarity
- Reliable, tamper-resistant watermarking at scale
- Low-resource language dubbing and public sector communications
- Sector: Public Sector; NGOs; Global Health
- What: Pair high-quality multilingual TTS with context-rich dubbing to produce localized content for underserved languages.
- Tools/products/workflows:
- Government/NGO content pipelines for education and health messaging
- Dependencies/assumptions:
- TTS availability for low-resource languages; cultural/phonetic QA
- Funding for compute and deployment
- Forensics and deepfake detection R&D
- Sector: Security; Media Forensics; Academia
- What: Use challenging, high-realism outputs and ContextDubBench to stress-test detection systems and develop countermeasures.
- Tools/products/workflows:
- Detector benchmarking suites; adversarial evaluation protocols
- Dependencies/assumptions:
- Access to high-fidelity generated samples; cross-institution collaboration
- Evolving threat landscape requiring continuous updates
- Generalized self-bootstrapping for other video-to-video tasks
- Sector: Computer Vision; Post-production; Advertising
- What: Apply the “self-bootstrapping paired data” strategy to tasks lacking real aligned pairs (e.g., expression transfer, clothing/logo swaps, product placement, scene relighting).
- Tools/products/workflows:
- Synthetic-pair generators tailored to each task; phase-aware editors for targeted edits
- Dependencies/assumptions:
- Domain-specific generation quality must be adequate to serve as “contextual conditioners”
- Additional metrics and benchmarks for new tasks
Cross-Cutting Assumptions and Dependencies
- Compute and latency: Diffusion-Transformer inference is GPU-intensive; immediate use is best suited to offline/batch workflows; real-time applications require significant optimization and possibly hardware acceleration.
- Audio quality and alignment: Success depends on clean, well-segmented speech and (for some workflows) accurate timing; TTS quality strongly affects perceived realism.
- Rights, consent, and ethics: Use of an individual’s likeness requires explicit permission; clear disclosure and provenance measures should be standard, especially in broadcast/public contexts.
- Domain adaptation: Extreme stylization, very low light, or heavy occlusions may require fine-tuning and curated contextual pair generation specific to the target domain.
- Integration: Effective deployment often requires tying X-Dub to TTS, diarization, NLEs, MAM/CMS, and QA dashboards; procurement teams should adopt benchmark-driven acceptance tests (e.g., ContextDubBench metrics).
- Language and phoneme coverage: For uncommon phonemes or low-resource languages, additional training data and phonetic QA may be necessary to guarantee lip-readable articulation.
Glossary
- 3D Morphable Models (3DMMs): Parametric 3D face models used to represent and fit facial geometry and appearance. Example: "3D Morphable Models (3DMMs)"
- 3D spatio-temporal self-attention: Attention applied jointly over spatial and temporal dimensions to model video dependencies. Example: "3D spatio-temporal self-attention"
- 3D VAE: A variational autoencoder that encodes/decodes video volumes in space and time. Example: "3D VAE for video compression"
- ArcFace: A face-recognition loss/model producing highly discriminative identity embeddings via angular margins. Example: "ArcFace"
- AV-HuBERT: A self-supervised audio-visual representation model used for speech and lip-related tasks. Example: "AV-HuBERT"
- Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE): A no-reference image quality metric measuring natural scene statistics. Example: "BRISQUE"
- CLIP: A multimodal model aligning images and text in a shared embedding space. Example: "CLIP"
- CLIP score (CLIPS): A semantic similarity metric derived from CLIP embeddings between generation and reference. Example: "CLIP score (CLIPS)"
- Conditional dropout: Randomly dropping conditional inputs during training to improve robustness and generalization. Example: "Conditional dropout (50\%)"
- ContextDubBench: A benchmark dataset for evaluating visual dubbing in diverse, challenging scenarios. Example: "ContextDubBench"
- Cosine similarity (CSIM): Identity metric measuring the cosine of the angle between embedding vectors. Example: "cosine similarity of ArcFace embeddings (CSIM)"
- Cross-attention: An attention mechanism that conditions one sequence (e.g., video tokens) on another (e.g., audio). Example: "cross-attention"
- Diffusion Transformer (DiT): A transformer architecture adapted for diffusion-based generative modeling of images/videos. Example: "Diffusion Transformer (DiT)"
- DWPose: A pose/landmark estimation method used here to obtain face and lip masks. Example: "DWPose"
- Flow-matching loss: A training objective aligning the model’s velocity field with a target transport flow in generative models. Example: "flow-matching loss"
- Frechet Inception Distance (FID): Distributional distance between generated and real images computed via Inception features. Example: "FID "
- Frechet Video Distance (FVD): A video analog of FID assessing spatiotemporal quality of generations. Example: "FVD "
- GANs: Generative Adversarial Networks; adversarially trained generative models for synthesis. Example: "GANs"
- HyperIQA: A deep no-reference image quality assessment metric. Example: "HyperIQA"
- Identity drift: Undesired change of a subject’s identity appearance across frames or generations. Example: "identity drift"
- Inpainting: Filling in or synthesizing missing image/video regions using surrounding context. Example: "inpainting"
- Landmark distance (LMD): A lip-sync metric measuring distance between predicted and reference facial landmarks. Example: "landmark distance (LMD)"
- Latent diffusion: Performing diffusion in a compressed latent space (e.g., via a VAE) rather than pixel space. Example: "latent diffusion paradigm"
- logit-normal: A probability distribution obtained by applying a logistic function to a normal variable; used for timestep sampling. Example: "logit-normal"
- LoRA: Low-Rank Adaptation; lightweight fine-tuning via low-rank adapters added to transformer layers. Example: "LoRA"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual distance metric correlating with human judgments. Example: "LPIPS"
- Mean Opinion Scores (MOS): Human-rated subjective quality scores on a Likert scale. Example: "Mean Opinion Scores (MOS)"
- NIQE: Natural Image Quality Evaluator; a no-reference image quality metric. Example: "NIQE"
- No-reference perceptual quality metrics: Image/video quality measures that do not require a ground-truth reference. Example: "no-reference perceptual quality metrics"
- Patchifying: Converting inputs into non-overlapping patches before transformer processing. Example: "Patchifying"
- PSNR: Peak Signal-to-Noise Ratio; a distortion-based image quality metric. Example: "PSNR"
- Relighting: Adjusting lighting in images/videos while preserving scene/identity. Example: "relighting"
- Self-attention: Mechanism allowing tokens within a sequence to attend to each other. Example: "self-attention"
- Self-bootstrapping: A paradigm where a model generates its own training data to improve downstream performance. Example: "self-bootstrapping"
- Self-reconstruction: Training by reconstructing inputs from masked/noised versions without paired ground truth. Example: "self-reconstruction"
- Single-step denoising: Approximating a diffusion reverse step with a single denoising update during training. Example: "single-step denoising"
- Spatiotemporal dynamics: Joint spatial and temporal patterns in video, such as motion and lighting changes. Example: "spatiotemporal dynamics"
- SSIM: Structural Similarity Index Measure; a reference-based image quality metric. Example: "SSIM"
- SyncNet: A model for measuring audio-visual synchronization between speech and lip motion. Example: "SyncNet"
- Timestep-adaptive multi-phase learning: Training strategy assigning different objectives to distinct diffusion noise levels/timesteps. Example: "timestep-adaptive multi-phase learning"
- Timestep sampling distribution: The probability distribution used to sample diffusion timesteps during training. Example: "timestep sampling distribution"
- Token sequence modeling: Modeling sequences of patch tokens with transformers for image/video generation. Example: "token sequence modeling"
- Video-to-video editing: Modifying specific aspects of an input video while preserving its overall content and identity. Example: "video-to-video editing"
- Whisper: An automatic speech recognition model used to extract audio features as conditioning. Example: "Whisper"
Collections
Sign up for free to add this paper to one or more collections.