Shared Latent Representation for Joint Text-to-Audio-Visual Synthesis
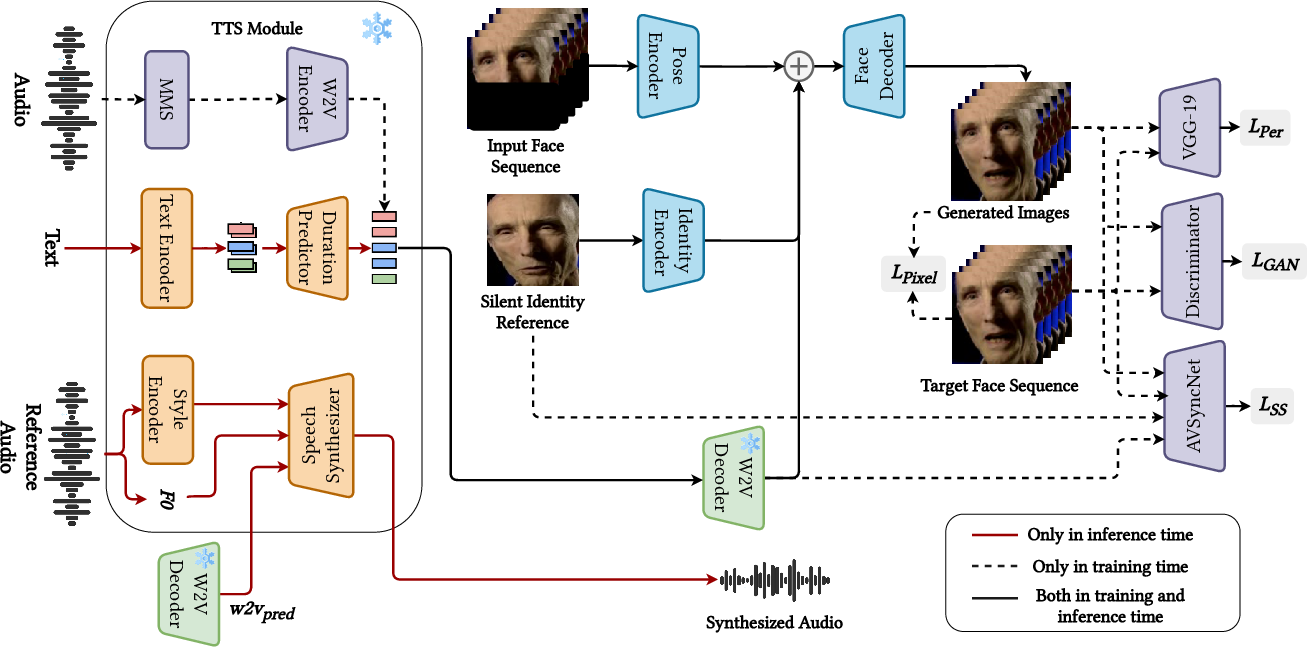
Abstract: We propose a text-to-talking-face synthesis framework leveraging latent speech representations from HierSpeech++. A Text-to-Vec module generates Wav2Vec2 embeddings from text, which jointly condition speech and face generation. To handle distribution shifts between clean and TTS-predicted features, we adopt a two-stage training: pretraining on Wav2Vec2 embeddings and finetuning on TTS outputs. This enables tight audio-visual alignment, preserves speaker identity, and produces natural, expressive speech and synchronized facial motion without ground-truth audio at inference. Experiments show that conditioning on TTS-predicted latent features outperforms cascaded pipelines, improving both lip-sync and visual realism.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of the Paper
What is this paper about?
This paper is about making a video of a person talking directly from text, while also creating the matching voice at the same time. Think of it like typing a script and getting both a natural-sounding voice and a realistic, lip-synced talking-face video as output—without needing any real recorded audio.
What questions are the researchers trying to answer?
- How can we turn text into both speech and a realistic talking-face video that stay perfectly in sync?
- Can we avoid common problems where the lips don’t match the voice when using computer-generated (TTS) audio?
- Is there a simple way to make the audio and video share the same “plan,” so they naturally align?
How does their method work? (Explained simply)
The big idea: Use one shared “secret plan” (a common hidden representation) to guide both the voice and the face.
- Imagine you’re directing a cartoon and a voice actor. If both of them follow the same script notes—where to pause, which words are stressed, the rhythm—everything lines up. In this paper, those shared notes are called “latent features.” They come from a model that understands speech patterns (called Wav2Vec2).
- A “Text-to-Vec” (TTV) tool learns to turn text into those speech-style notes (the latent features). These features then drive: 1) a Text-to-Speech model (HierSpeech++) to produce the voice, and 2) a video model to animate the face so the lips match the sound.
- Why this helps: Many older systems do this in two steps—first make the audio, then animate the face from that audio. Errors add up and lip-sync can suffer. Here, both audio and video follow the same shared plan from the start, so they stay in sync.
Two-step training (to handle “domain shift”)
“Domain shift” is when what you practice on is a bit different from what you use later. Here’s their fix:
- Step 1 (pretraining): Train the face-video model using clean, real speech features from Wav2Vec2. This teaches the model a strong connection between speech patterns and lip movements.
- Step 2 (finetuning): Train again using the features predicted by the Text-to-Vec tool (which are slightly “messier,” like real TTS output). This prepares the model for real use, when it won’t have perfect recorded audio—only text.
An everyday analogy: First practice singing with studio-quality backing tracks, then practice with a phone speaker so you’re ready for real-world conditions.
How the video model is built
- It’s based on a GAN (a type of AI that learns to generate realistic images).
- Instead of listening to audio directly, it takes the shared latent features (the “plan”) and combines them with visual information about the person’s face.
- They also use a “silent-face” preprocessing step: they slightly adjust the reference image to have a closed mouth. This avoids the model copying the original lip shape (a problem called “lip leaking”) and improves lip-sync.
Extra details (kept simple)
- The TTS backbone (HierSpeech++) uses layered speech information (like pronunciation, tone, rhythm) to create natural, expressive voice.
- The Text-to-Vec module predicts timing (durations) and pitch info so the voice and lip movements match.
- During inference (actual use), they only need text and a reference voice sample to mimic the speaking style—no real audio of the target speech is needed.
What did they find, and why does it matter?
Here are the key takeaways from their tests on a public dataset (LRS2):
- The videos look sharp and realistic: Their visual quality scores are close to the best among strong baseline methods.
- The lips match the voice well: Their method improves lip-sync, especially when using speech generated by TTS. This is important because many systems struggle when switching from real audio to synthetic audio.
- Identity is preserved: The face still looks like the same person, and the voice keeps the speaker’s style when a reference is provided.
- Speech quality is high: Their TTS produced very clear, understandable speech. In fact, its error rate in automatic transcription (WER) was even better than the real recordings in the dataset, likely because the TTS audio is cleaner.
Why this matters: If you want virtual avatars, dubbing, digital assistants, or educational tutors that talk, you need the lips and voice to match perfectly. Doing audio and video together from the same plan makes that much more reliable.
What could this change in the future?
- Simple, all-in-one pipelines: You can go straight from text to a synchronized talking video, without chaining multiple systems that might break or misalign.
- Better dubbing and avatars: More natural lip-sync in multiple languages and styles could improve accessibility, entertainment, and communication.
- Foundations for multimodal AI: Using a shared hidden representation to control different outputs (sound and video) can inspire new designs for other media, like gestures or full-body motion.
A few limitations to keep in mind:
- The system relies on high-quality shared features; performance might drop for very noisy inputs or completely new languages/styles.
- It focuses mainly on lip movements; subtle facial expressions beyond the mouth are not modeled as deeply.
Overall, this paper shows a practical way to make text-driven talking-face videos that sound natural and look believable, by making the audio and video follow the same shared plan from the start.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is framed to guide follow-up research and targeted experimentation.
- Generalization across languages and accents is untested: the approach is only evaluated on LRS2 (English); robustness to unseen languages, code-switching, strong accents, and multilingual text remains unknown.
- Dependence on reference audio for style/speaker identity at inference conflicts with pure text-to-AV goals; the minimal length/quality of reference audio and robustness to noisy/reverberant references are not characterized.
- No analysis of how duration prediction errors (from MAS/TTV) affect lip-sync; the paper does not quantify duration accuracy or its correlation with LSE-C/LSE-D.
- The two-stage adaptation addresses distribution shift qualitatively, but there is no quantitative characterization of the shift between clean W2V2 embeddings and TTS-predicted embeddings (e.g., statistics, MMD, calibration) nor ablations of alternative adaptation techniques (noise injection, adversarial/domain-invariant training, feature normalization, teacher–student distillation).
- End-to-end joint training of TTS and TFG is not explored; it is unknown whether backpropagating synchronization/visual losses into TTV/TTS improves alignment and expressiveness.
- The choice of latent representation is fixed (W2V2); no ablation compares alternative SSL speech features (HuBERT, WavLM, CPC, AV-HuBERT) or representation scales, nor their impact on alignment, identity, and visual realism.
- Visual expressiveness is limited to lips; there is no explicit modeling or control of subtle facial expressions, eye gaze, blinks, head pose, micro-expressions, or co-speech gestures, and no metrics to evaluate them.
- High-resolution and in-the-wild robustness are not evaluated; performance under extreme poses, occlusions, lighting changes, makeup, facial hair, and non-frontal views remains unknown.
- Long-form generation stability (temporal drift, cumulative misalignment over minutes) is not analyzed; no study of segment stitching, context caching, or periodic re-alignment to prevent drift.
- Real-time feasibility and efficiency are not reported: inference latency, FPS, memory footprint, and compute requirements for joint AV generation are unspecified.
- Fairness of comparisons under TTS domain shift is unclear: baselines are not retrained/adapted on TTS audio; a controlled study where baselines are trained with TTS or with the same latent features is missing.
- Human perceptual evaluations for video quality and AV coherence are absent; reliance on automated metrics may not reflect perceived realism or uncanny artifacts.
- Audio evaluation lacks prosody/expressiveness diagnostics (F0 RMSE/correlation, energy, duration RMSE, rhythm, ToBI/phoneme-level duration accuracy); WER/UTMOS/SECS alone do not capture naturalness of timing and emphasis.
- Synchronization assessment is narrow (LSE-C/LSE-D); complementary metrics (e.g., LMD, AV offset in ms, phoneme–viseme alignment accuracy, lip-reading-based intelligibility) and error analyses are not provided.
- Impact of the silent-face preprocessing on identity leakage and lip-sync is not ablated in this specific pipeline; sensitivity to the choice/quality of the silent image is unknown.
- Robustness to TTS imperfections is not tested: disfluent TTS, prosody exaggerations, speech rate extremes, phoneme confusions, and noisy TTS outputs may degrade AV alignment.
- Uncertainty in TTV predictions is not modeled; there is no mechanism to propagate or exploit uncertainty (e.g., stochastic sampling, confidence-aware conditioning) to improve robustness.
- Disentanglement between speaker identity, linguistic content, prosody, and visual identity is not measured; leakage between modalities (e.g., speaker prosody affecting facial identity) and controllability are unquantified.
- Control interfaces are limited: there is no phoneme-level or prosody-level user control (emphasis, speed, pause placement, speaking style tokens), nor text-only style control without reference audio.
- The approach is tied to a GAN-based TFG; transferability to diffusion-, NeRF-, and 3D-aware generators (and their potential benefits for realism and pose control) is untested.
- Cross-domain transfer (training on LRS2, testing on HDTF/MEAD/VoxCeleb2/LRS3) is not evaluated; data diversity and domain robustness remain open.
- AV latency tolerance is not reported (e.g., whether AV offset stays within ±40 ms); strategies for explicit latency control or post-hoc synchronization are absent.
- Failure modes and qualitative error taxonomy are missing (e.g., viseme confusions for bilabials, vowel rounding errors, occlusion-induced artifacts, frame flicker).
- Security and misuse mitigation are not addressed: no exploration of watermarking, provenance, or synthetic detection to reduce impersonation risks.
- Ethical and bias analysis is missing: performance across demographics (gender, age, skin tone), language varieties, and accessibility considerations (e.g., for lip-reading users) are not studied.
- Data and training details critical to reproducibility are sparse (exact resolution, crop schemes, training schedules, hyperparameters, data preprocessing); pretrained models and code availability are not stated.
- Interaction between TTS prosody choices and visual expressiveness is not studied; it is unknown how prosodic modulations map to facial dynamics in the shared latent space.
- Handling of background noise/music and non-speech segments (laughter, breaths) in reference audio and generated outputs is not analyzed; non-speech visemes and pause modeling are unspecified.
- Evaluation under mismatched speaker–face pairings (voice-face incongruence) is only partially examined; subjective effects of such incongruence on perceived realism and trust are not measured.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s joint text-to-audio-visual synthesis with shared latent Wav2Vec2 features and the two-stage adaptation strategy.
- Industry (Media/Localization): Automated face dubbing and voiceover for training videos, ads, and social clips
- Tool/Product: A “Text-to-Avatar Dubbing” plugin for Adobe Premiere/DaVinci that ingests a script, a reference image, and optional style audio, then outputs a lip-synced talking head
- Workflow: Script →
TTV (Text-to-Vec)→ shared W2V2 latent features → speech + talking face generation → export - Assumptions/Dependencies: Rights to use identity and voice; sufficient GPU; high-quality
HierSpeech++TTS; good identity reference image
- Software (Developer Platforms): Cloud API for text-to-talking-head generation
- Tool/Product: “Text-to-AV” microservice (REST/SDK) offering synchronous audio-video generation conditioned on shared W2V2 features
- Workflow: POST text + identity image + optional style audio → returns MP4 with synchronized speech and facial motion
- Assumptions/Dependencies: GPU-backed inference; model weights/licensing; security and privacy controls
- Enterprise (Customer Support/Assistants): Conversational avatars for help centers and digital assistants that speak pre-written responses
- Tool/Product: Contact center integration where chat responses are converted to short speaking-head clips
- Workflow: Agent or bot text →
TTV→ speech + face output embedded in support portal - Assumptions/Dependencies: Content moderation; latency constraints; brand-safe identity assets
- Education (Instructional Content): Instructor avatars reading lesson text for MOOCs and corporate training
- Tool/Product: LMS plugin that produces explanatory clips from lesson scripts maintaining the instructor’s identity
- Workflow: Lesson text → style-conditioned TTS → aligned talking head → embed in LMS
- Assumptions/Dependencies: Instructor consent; style reference audio; clarity about synthetic media labeling
- Accessibility (Communication Aids): Generating lip-synced avatar videos from text for users with speech impairments
- Tool/Product: Assistive app that converts typed messages into a personalized speaking avatar
- Workflow: User text → shared latent features → speech + lip-synced face → quick-share video
- Assumptions/Dependencies: Ethical safeguards; optional voice/style cloning requires consent; limited non-lip expressions noted in the paper
- Content Creation (Social/Marketing): Rapid production of short, personalized talking-head clips from scripts
- Tool/Product: Mobile “Script-to-Face” app for creators; template library for different personas
- Workflow: Select persona → paste text → generate clip → publish
- Assumptions/Dependencies: Mobile inference offloaded to cloud; identity ownership; compute costs
- Localization QA (Quality Assurance): Lip-sync quality verification for TTS/localized content
- Tool/Product: “Lip-Sync QA” tool that stress-tests alignment using the model’s cross-test protocol (mismatched pairs) and SyncNet-based metrics
- Workflow: Batch generate and score clips; flag misalignment via LSE-C/D thresholds
- Assumptions/Dependencies: Access to metric models (e.g., SyncNet); dataset for benchmarking
- Research/Academia (Dataset Augmentation): Synthetic AV data generation for training/evaluating audio-visual speech recognition (AVSR) and lip-reading models
- Tool/Product: Data generation pipeline using the shared latent space to ensure tight audio-visual alignment
- Workflow: Text corpora → synthetic AV paired samples → train AVSR/lip-reading
- Assumptions/Dependencies: Data diversity beyond LRS2; ethical dataset use; documented synthesis provenance
- Software (Model Adaptation Kit): Adaptation of existing talking-face generators to TTS-predicted features
- Tool/Product: “TTS-to-TFG Adaptation Kit” implementing the paper’s two-stage training (pretrain on clean W2V2 features, finetune on TTS-predicted vectors)
- Workflow: Export W2V2 features from
HierSpeech++ TTV→ retrain TFG with staged losses (including stabilized sync → vanilla sync in finetune) - Assumptions/Dependencies: Access to pretrained W2V2 encoders; training compute; compatibility with existing TFG architectures
- Policy (Provenance & Labeling): Immediate labeling and metadata practices for synthetic AV content produced by the pipeline
- Tool/Product: Post-processing module to embed metadata (e.g., C2PA) and on-screen badges indicating synthetic content
- Workflow: Generate → embed provenance → publish with disclosure
- Assumptions/Dependencies: Organizational policy; tooling for metadata standards (C2PA/EDRM)
Long-Term Applications
These use cases will benefit from further research, scaling, real-time optimization, expanded expression modeling, and broader language/domain coverage.
- Healthcare (Voice/Identity Preservation): Long-term communication aids for ALS and laryngectomy patients preserving personal voice and facial identity across languages
- Tool/Product: Clinical-grade avatar communicator
- Dependencies: Medical approvals; robust emotional and micro-expression modeling; language-generalization; privacy-by-design
- Robotics (Humanoid Agents): Synchronized speech with physical mouth actuation on robots
- Tool/Product: Edge-deployable
Text-to-AVmodule integrated with robot HRI stack - Dependencies: Real-time inference; hardware mouth models; low-latency shared latent decoding; on-device optimization
- Tool/Product: Edge-deployable
- Media/Entertainment (Production Dubbing): Studio-grade multilingual dubbing that preserves actor identity, voice timbre, and emotional nuance
- Tool/Product: “Studio Dubbing Suite” integrating emotional control, head/eye/gesture synthesis, and timeline tools
- Dependencies: Expressive control beyond lips (emotions, micro-expressions, head pose, gaze); NeRF/3D face integration; union agreements and consent
- AR/VR (Telepresence): Real-time, multilingual telepresence avatars in immersive environments
- Tool/Product: XR avatar engine with low-latency text-to-AV pipeline
- Dependencies: Real-time TTS and AV synthesis; network QoS; cross-device rendering; privacy safeguards
- Education (Global Course Translation): Automated lecture translation with identity-accurate avatars and preserved speaker style
- Tool/Product: “FaceDubbing++ for Education” integrated with machine translation and style conditioning
- Dependencies: High-quality speech translation; accent/style transfer; cultural localization guidelines
- Finance/Retail (Digital Advisors): Branch kiosks and websites featuring compliant, branded advisors speaking regulatory scripts
- Tool/Product: “Compliant Avatar” platform with audit trails and disclosures
- Dependencies: Regulatory compliance; unambiguous synthetic labeling; secure identity management
- Public Sector (Civic Information): Multilingual public service announcements voiced by recognizable officials with consent
- Tool/Product: Government AV synthesizer with provenance and archiving
- Dependencies: Strong provenance/watermarking; policy frameworks; accessibility and misinformation safeguards
- Security (Synthetic Media Governance): Watermarking and detection co-design for AV content produced from shared latent spaces
- Tool/Product: Dual pipeline—generator embeds robust watermarks; detector verifies provenance
- Dependencies: Standardization (C2PA-like for AV); resilient, content-preserving watermarks; cross-platform validators
- Gaming/Interactive Storytelling: NPCs that speak dynamically generated text with synchronized facial motion and controllable emotion
- Tool/Product: Game engine plugin for real-time
Text-to-AVwith emotion sliders and persona presets - Dependencies: Latency budgets; expressive control APIs; youth-safety content filters
- Tool/Product: Game engine plugin for real-time
- Software (On-Device/Edge Inference): Private, offline text-to-talking-face on consumer devices
- Tool/Product: Optimized models (quantized/pruned) for mobile/edge chips
- Dependencies: Model compression; hardware-accelerated inference; secure storage for identity assets
- Accessibility (Enhanced Lip-Reading Content): Optimized lip movements to improve lip-reading usability beyond standard video
- Tool/Product: “Lip-Readable Avatar” mode that accentuates phoneme clarity
- Dependencies: Studies with lip-reading communities; ethical design to avoid misleading realism; refined viseme modeling
- Research/Standards (Benchmarking & Ethics): Community benchmarks for joint text-to-AV generation with fairness, bias, and consent protocols
- Tool/Product: Public datasets and standardized metrics for audio-visual alignment, identity preservation, and emotional fidelity
- Dependencies: Multilingual, demographically diverse data; governance boards; reproducibility kits
Notes on Feasibility and Dependencies
- Technical:
- The approach relies on high-quality
HierSpeech++TTS andWav2Vec2latent features; performance may drop with noisy inputs or unseen languages. - Two-stage training (clean W2V2 pretrain → TTS-predicted finetune) is key to mitigating domain shift; re-using this adaptation in new domains is recommended.
- Current limitations include subtle facial expressions beyond lip movements; emotion/gesture control will improve user experience and applicability.
- The approach relies on high-quality
- Legal/Ethical:
- Identity and voice cloning require explicit consent; provenance and labeling should be standard practice.
- Sector-specific regulations (healthcare, finance, public sector) necessitate compliance reviews, disclosures, and robust audit trails.
- Operational:
- GPU compute and latency constraints influence real-time and high-volume deployments.
- Multilingual support depends on training corpora breadth and robust duration/phoneme alignment across languages.
By coupling text, speech, and facial synthesis in a shared latent space and training the face generator to TTS-predicted features, the paper’s method enables stronger lip–speech synchronization and identity preservation—immediately useful for production pipelines, and a foundation for richer, real-time, multilingual, and emotionally expressive avatar systems in the long term.
Glossary
- Ablation study: A controlled analysis where components of a system are removed or altered to assess their impact on performance. "Ablation study evaluating the impact of the proposed training strategy."
- Adversarial loss: A loss used in GAN training where a discriminator guides a generator to produce realistic outputs. "Adversarial loss~\cite{goodfellow2014generative}: A discriminator network is used to compute adversarial loss based on its output, guiding the model toward generating realistic outputs."
- Audio-visual alignment: The temporal and semantic coherence between audio and video streams. "This enables tight audio-visual alignment, preserves speaker identity, and produces natural, expressive speech and synchronized facial motion without ground-truth audio at inference."
- Cascaded pipelines: Sequential systems where outputs of one model feed into another, often accumulating errors across stages. "conditioning on TTS-predicted latent features outperforms cascaded pipelines, improving both lip-sync and visual realism."
- Conditional variational autoencoder: A VAE conditioned on auxiliary inputs (e.g., text) to control generated outputs. "and aligns them with text through a conditional variational autoencoder architecture."
- CSIM: Cosine similarity between embeddings, used here for identity preservation in generated faces. "For identity preservation, measured by CSIM, we obtain the best score together with Diff2Lip."
- Cross-test evaluation: Testing with intentionally mismatched audio-video pairs to assess robustness. "We further conduct a cross-test evaluation to assess the models under more challenging conditions, where audio and video are randomly paired, in contrast to the matched (GT) pairs used in Table \ref{tab:TFG_quantitative_results}."
- Domain shift: A change in data distribution between training and deployment domains that degrades performance. "these methods are prone to domain shift and error accumulation, as the talking-face model is not trained on TTS-generated audio."
- Distribution shift: Differences in statistical properties between two sets of features or data regimes. "To handle distribution shifts between clean and TTS-predicted features, we adopt a two-stage training: pretraining on Wav2Vec2 embeddings and finetuning on TTS outputs."
- Duration predictor: A model component that predicts alignment/duration between text units and acoustic frames. "and a duration predictor that learns text-to-W2V2 alignment via monotonic alignment search (MAS)."
- F0: The fundamental frequency of speech, corresponding to perceived pitch. "The TTV module is a variational autoencoder similar to VITS~\cite{kim2021conditional}, trained to synthesize W2V2 embeddings and F0 from text."
- FID: Fréchet Inception Distance, a metric for visual realism comparing feature distributions of real and generated images. "To assess visual quality, we report SSIM~\cite{wang2004image}, PSNR, and FID~\cite{heusel2017gans}."
- Feature fusion techniques: Methods for combining heterogeneous features (e.g., text and audio) into a unified representation. "or by using feature fusion techniques to incorporate text-enriched features into TFG~\cite{diao2025ft2tf}."
- GAN-based: Refers to models using Generative Adversarial Networks for synthesis. "We use the GAN-based~\cite{goodfellow2014generative} talking face generation model presented in \cite{yaman2024audiodriventalkingfacegeneration}."
- Hierarchical latent representations: Multi-level abstract features capturing different aspects (semantic to acoustic) of speech. "HierSpeech++ leverages hierarchical latent representations derived from the self-supervised speech model Wav2Vec2"
- HierSpeech++: A hierarchical TTS model aligning linguistic, acoustic, and prosodic features for expressive speech. "HierSpeech++ is a hierarchical speech synthesis model that combines linguistic, acoustic, and prosodic representations to generate natural and expressive speech."
- Identity reference image: A still image used to preserve a subject’s identity in generated talking-face sequences. "The original model includes two image encoders responsible for processing the identity reference image and the input face sequence to generate embeddings"
- Latent speech representations: Compressed, learned features of speech used as conditioning or shared spaces. "We propose a text-to-talking-face synthesis framework leveraging latent speech representations from HierSpeech++."
- LMD (Mouth Landmark Distance): A metric measuring distance between predicted and ground-truth mouth landmarks. "For audioâlip synchronization, we use mouth landmark distance (LMD)~\cite{chen2019hierarchical} and LSE-C {paper_content} LSE-D~\cite{chung2017out,prajwal2020lip}."
- LRS2: A large-scale audio-visual speech dataset used for training and evaluation. "We train our talking face generation model on the LRS2 training set and evaluate it on the LRS2 test set."
- LSE-C: SyncNet-based lip-sync confidence score assessing audio-visual synchrony. "For audioâlip synchronization, we use mouth landmark distance (LMD)~\cite{chen2019hierarchical} and LSE-C {paper_content} LSE-D~\cite{chung2017out,prajwal2020lip}."
- LSE-D: SyncNet-based lip-sync distance score assessing audio-visual synchrony. "For audioâlip synchronization, we use mouth landmark distance (LMD)~\cite{chen2019hierarchical} and LSE-C {paper_content} LSE-D~\cite{chung2017out,prajwal2020lip}."
- Lip leaking problem: Unwanted leakage of mouth shapes or speech cues from identity images that harms lip-sync. "In \cite{yaman2024audio}, it was also observed that the identity reference can occasionally harm training stability and the modelâs lip-sync performance due to the lip leaking problem."
- Lip-sync loss: A loss encouraging alignment between generated lip motion and audio. "we employ vanilla lip-sync loss~\cite{prajwal2020lip} instead."
- MAS (Monotonic Alignment Search): An algorithm enforcing monotonic text-to-speech alignment during training. "via monotonic alignment search (MAS)."
- Mel-spectrograms: Time–frequency representations of audio commonly used in TTS. "Unlike conventional TTS systems that operate on mel-spectrograms, HierSpeech++ leverages hierarchical latent representations"
- Perceptual loss: A feature-space loss using a pretrained network to encourage perceptual similarity. "Perceptual loss~\cite{johnson2016perceptual}: We adopt a pretrained VGG-19 model~\cite{simonyan2014very} to extract features from both the generated and GT faces, and compute the L2 distance between them."
- Pixel reconstruction loss: A pixel-space loss (e.g., L1) to preserve fine visual details. "Pixel reconstruction loss: We compute the L1 distance between the generated and GT faces in pixel space, which helps preserve fine visual details."
- PSNR: Peak Signal-to-Noise Ratio, a metric for image reconstruction quality. "To assess visual quality, we report SSIM~\cite{wang2004image}, PSNR, and FID~\cite{heusel2017gans}."
- Prosodic representations: Features capturing rhythm, stress, and intonation (prosody) of speech. "HierSpeech++ is a hierarchical speech synthesis model that combines linguistic, acoustic, and prosodic representations to generate natural and expressive speech."
- Resemblyzer: A toolkit for computing speaker embeddings and cosine similarities. "speaker embedding cosine similarity (SECS) using Resemblyzer~\footnote{https://github.com/resemble-ai/Resemblyzer} for speaker identity preservation assessments"
- SECS: Speaker Embedding Cosine Similarity, measuring preservation of speaker identity. "speaker embedding cosine similarity (SECS) using Resemblyzer~\footnote{https://github.com/resemble-ai/Resemblyzer} for speaker identity preservation assessments"
- Self-supervised speech model: A speech model trained without labels to learn generic representations. "derived from the self-supervised speech model Wav2Vec2 (W2V2)~\cite{baevski2020wav2vec}"
- Silent-face image: A preprocessed identity image with a neutral, closed mouth to prevent lip leakage. "generate a silent-face image, representing a face with a stable, closed mouth."
- SSIM: Structural Similarity Index, a perceptual metric for image quality. "To assess visual quality, we report SSIM~\cite{wang2004image}, PSNR, and FID~\cite{heusel2017gans}."
- Stabilized synchronization loss: A refined lip-sync loss that improves stability and synchronization quality. "Following \cite{yaman2024audio}, we use the stabilized synchronization loss, which outperforms vanilla lip-sync loss~\cite{prajwal2020lip} and other lip-sync learning methods."
- Style conditioning: Conditioning generation on reference style attributes such as speaker identity. "Reference audio is used for style conditioning, including speaker identity, while the hierarchical speech synthesizer generates the waveform."
- SyncNet: A network that extracts audio-visual features to evaluate lip-sync. "LSE-C and LSE-D rely on the SyncNet model~\cite{chung2017out} to extract audioâvisual features and compute confidence and distance, respectively."
- Talking face generation (TFG): The task of synthesizing a face video that lip-syncs to speech. "Traditional talking face generation (TFG) models trained on ground-truth audio often suffer from temporal misalignment"
- Text-to-audio-visual synthesis: Generating both speech audio and corresponding video directly from text. "we present the first joint text-to-audio-visual synthesis for face dubbing."
- Text-to-Vec (TTV): A module that predicts latent speech features from text. "We leverage a Text-to-Vec (TTV) module to generate intermediate latent speech features directly from text."
- Text-to-Speech (TTS): Synthesizing speech audio from text input. "we used Hierspeech++~\cite{lee2025hierspeech++} as the TTS backbone"
- Two-stage training strategy: Training in two phases (pretrain, then finetune) to adapt to different feature distributions. "We propose a two-stage training strategy for our talking-face generation model to ensure tight synchronization with TTS-generated speech."
- UTMOS: A learned MOS estimator for perceived speech naturalness. "and UTMOS~\cite{saeki2022utmos} for perceived naturalness."
- Variational autoencoder (VAE): A generative model that learns latent distributions for reconstruction and sampling. "The TTV module is a variational autoencoder similar to VITS~\cite{kim2021conditional}"
- VGG-19: A deep CNN architecture often used for perceptual feature extraction. "We adopt a pretrained VGG-19 model~\cite{simonyan2014very}"
- Wav2Vec2 (W2V2): A self-supervised speech representation model used to provide latent features. "Wav2Vec2 (W2V2)~\cite{baevski2020wav2vec}"
- Whisper Large-v3: An automatic speech recognition model used for intelligibility evaluation. "we measure the word error rate (WER) using Whisper Large-v3~\footnote{https://huggingface.co/openai/whisper-large-v3}"
- Word Error Rate (WER): A standard ASR metric measuring transcription errors. "we measure the word error rate (WER) using Whisper Large-v3~\footnote{https://huggingface.co/openai/whisper-large-v3}"
Collections
Sign up for free to add this paper to one or more collections.

