UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions
Abstract: Due to the lack of effective cross-modal modeling, existing open-source audio-video generation methods often exhibit compromised lip synchronization and insufficient semantic consistency. To mitigate these drawbacks, we propose UniAVGen, a unified framework for joint audio and video generation. UniAVGen is anchored in a dual-branch joint synthesis architecture, incorporating two parallel Diffusion Transformers (DiTs) to build a cohesive cross-modal latent space. At its heart lies an Asymmetric Cross-Modal Interaction mechanism, which enables bidirectional, temporally aligned cross-attention, thus ensuring precise spatiotemporal synchronization and semantic consistency. Furthermore, this cross-modal interaction is augmented by a Face-Aware Modulation module, which dynamically prioritizes salient regions in the interaction process. To enhance generative fidelity during inference, we additionally introduce Modality-Aware Classifier-Free Guidance, a novel strategy that explicitly amplifies cross-modal correlation signals. Notably, UniAVGen's robust joint synthesis design enables seamless unification of pivotal audio-video tasks within a single model, such as joint audio-video generation and continuation, video-to-audio dubbing, and audio-driven video synthesis. Comprehensive experiments validate that, with far fewer training samples (1.3M vs. 30.1M), UniAVGen delivers overall advantages in audio-video synchronization, timbre consistency, and emotion consistency.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UniAVGen, a single AI model that can create both video and matching audio at the same time. It focuses on people talking, making sure voices, lip movements, and emotions are in sync. The goal is to fix common problems where the voice doesn’t match the mouth or the mood of the video.
What questions are the researchers trying to answer?
To make the paper easier to understand, here are the main questions they set out to solve:
- How can we make audio (speech) and video (lip movements and expressions) line up perfectly while being generated together?
- How do we keep the voice consistent with the person’s look and identity (like timbre and emotion)?
- Can one model handle several related tasks (like dubbing a silent video or making video from a voice) without needing separate systems?
- Can we get strong results even with much less training data than other models?
How does the method work?
Think of UniAVGen as two artists working side by side—one paints the video, the other composes the audio. They constantly talk to each other, share clues, and focus on the parts that matter most (like the face).
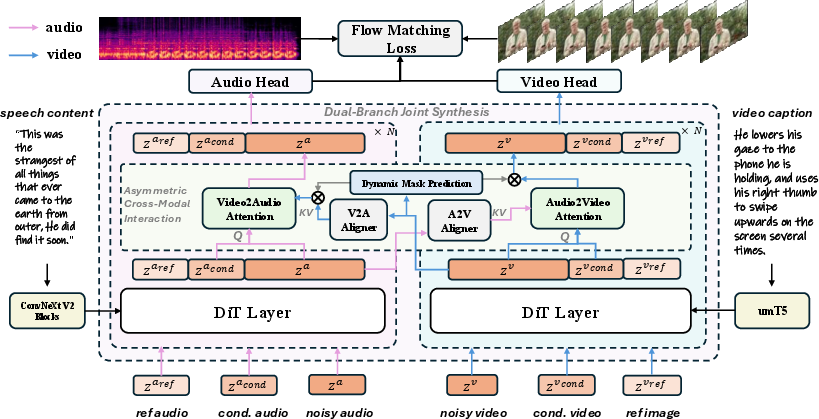
Two-branch generator (two coordinated “artists”)
- The model has two matching “branches”: one for video and one for audio.
- Both branches use a modern technique called a Diffusion Transformer (DiT). You can imagine diffusion like starting with static noise and then carefully “cleaning” it step by step until a clear video or audio emerges.
- Because the two branches are designed similarly, it’s easier for them to share a common “language” (a shared plan or blueprint) while creating content together.
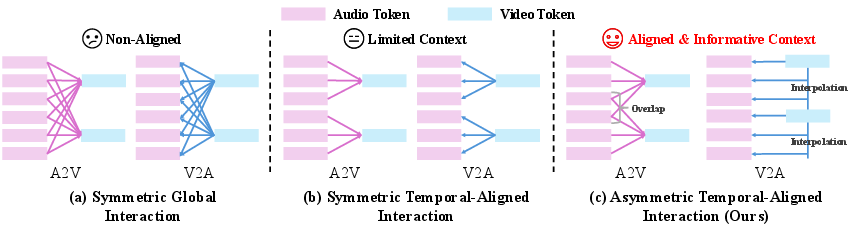
Asymmetric cross-talk (they share info differently each way)
- Audio helps video: The video branch asks the audio branch for hints about what the mouth should do right now, plus a little before and after (because speech sounds flow smoothly). This ensures better lip sync and expressions that match the spoken words.
- Video helps audio: The audio branch asks the video branch for the person’s identity and emotion cues (who is speaking, what feeling they show). It blends information from the current and next video moment so the voice changes smoothly with the visual mood.
In simple terms: the two branches “look over each other’s shoulder,” but each side looks at what it needs most.
Face-Aware Modulation (shine the spotlight where it matters)
- The model learns a soft “face mask” that highlights the face region.
- Early on, it strongly focuses on the face so lip and expression sync improve quickly, without messing up the background.
- Over time, the model relaxes that focus a bit so the rest of the scene can also match the audio’s emotion and rhythm.
Imagine a director saying, “Focus on the actor’s face first—later we’ll match the body and background too.”
Modality-Aware Guidance (turn up the “work together” rule)
- A common trick called “guidance” helps models follow instructions better. Here, they tweak it to specifically boost the “match each other” signal between audio and video.
- This makes emotions stronger and movements more natural, so the voice and visuals feel like they truly belong together.
Training and supported tasks
- Training happens in stages: first audio alone (to make a strong voice), then audio+video together, then multi-task training.
- The same model can do several tasks:
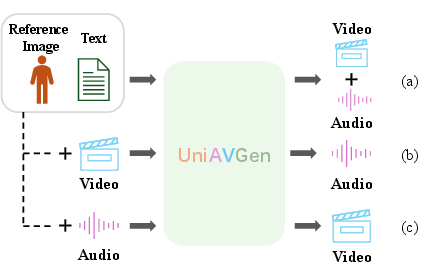
- Create both audio and video from a text prompt and a reference image.
- Dub a silent video (create matching speech).
- Make video driven by a given audio clip (match facial movements and emotion).
- Continue an existing audio-video pair smoothly.
What did they find, and why is it important?
The main takeaways are:
- Better lip sync: Mouth movements match the spoken words more precisely.
- Stronger voice–identity match: The voice (timbre) matches the person on screen.
- Emotion alignment: The mood in the audio matches facial expressions and body movement.
- Works across tasks: One model handles joint generation, dubbing, and audio-driven video.
- Efficient training: It reaches strong performance with far fewer training samples than some competitors (about 1.3 million vs. over 30 million).
Why this matters: When audio and video truly match, the result feels more real and engaging. This is crucial for making convincing talking avatars, dubbing videos in different languages, and creating high-quality social or educational content.
What is the impact of this research?
- Practical uses: Better dubbing for movies and lessons, more lifelike digital presenters, and smoother video creation tools.
- Fewer separate models needed: A single, unified system can handle multiple audio-video tasks, saving time and resources.
- Stronger alignment with less data: This can make advanced generation more accessible and efficient.
As with any powerful media technology, creators and platforms should use it responsibly—especially for consent, authenticity, and avoiding misuse. Overall, UniAVGen pushes joint audio-video generation forward by making it more synchronized, expressive, and versatile.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be specific and actionable for future research:
- Data transparency and reproducibility:
- Lack of detailed disclosure of the internal joint audio–video dataset (size, source, demographics, licensing, consent, and privacy protections), hindering reproducibility and bias auditing.
- Unclear whether the Wan video backbone used was pre-trained or fine-tuned on overlapping content, and what pretraining data could cause distribution advantages versus baselines.
- No release or specification of the exact audio-to-waveform pipeline (vocoder model, training data, post-processing), making audio fidelity results difficult to reproduce.
- Evaluation methodology and metrics:
- Timbre consistency and emotion consistency rely on Gemini-2.5-Pro scoring; no standardized, open, reproducible metric or human listening test protocols (e.g., MOS, ABX, speaker embedding cosine distance, emotion classifier agreement) are provided.
- No statistical analysis (variance, confidence intervals, significance tests) for reported metrics; performance differences may be within noise.
- The custom 100-sample test set (half AIGC/anime) is not publicly available and is not a standard benchmark; domain coverage and difficulty are not quantified.
- Lip-sync evaluation uses SyncNet confidence only; lacks phoneme-level alignment metrics or frame-level asynchrony distribution analysis.
- Model design details and ablations:
- Asymmetric Cross-Modal Interaction (ATI) hyperparameters (e.g., audio context window size w, audio-to-video token mapping factor k) are not specified or ablated for sensitivity and robustness.
- No analysis of training stability and convergence with ATI versus symmetric/global interaction beyond early training (only 10k steps reported in ablations).
- Modality-Aware CFG (MA-CFG) is shown only qualitatively; quantitative gains, sensitivity to guidance strengths s_v and s_a, effects on diversity, and failure modes (e.g., over-amplified emotion or motion) are not studied.
- Face-Aware Modulation (FAM) depends on RetinaFace-based supervision; reliability on non-human faces (anime, stylized characters), profile views, occlusions, and multi-person scenes is not evaluated.
- Zero-initialization of cross-modal output matrices (W_oa, W_ov) is not ablated; alternative initializations or scheduling strategies could affect convergence and alignment.
- Scope and generalization:
- Focus is limited to single-speaker human speech; multi-speaker dialogues, overlapping speech, and multi-face scenes (speaker selection, diarization, turn-taking) are unaddressed.
- Cross-lingual and multilingual generalization is unclear (audio branch trained on English subset of Emilia); performance on other languages, code-switching, and language-specific phoneme inventories is unknown.
- Non-speech audio (ambient sounds, foley, music) in joint generation is not supported or evaluated; applicability to broader AV domains remains open.
- Robustness to difficult conditions (fast speech, whispering, strong background noise, extreme head poses, occlusions, rapid motion, low-light) is not systematically measured.
- Long-duration generation and continuation quality (drift, identity preservation, prosody consistency across minutes) are not analyzed.
- Alignment granularity and temporal modeling:
- Video operates at 16 fps; the impact of frame rate on lip sync accuracy, especially for rapid phoneme transitions and plosives, is not studied.
- The V2A interpolation strategy uses adjacent frames; potential benefits of higher-order temporal context, motion cues, or phoneme-level alignment are unexplored.
- No comparison to explicit phoneme/alignment models (e.g., forced aligners) or prosody features to improve fine-grained synchrony.
- Task coverage and benchmarking:
- Claims of multi-task unification (joint generation, dubbing, audio-driven video, continuation) lack task-specific quantitative benchmarks; per-task performance trade-offs are not characterized.
- Effects of the multi-task training ratios (4:1:1:2:2) on each task’s performance are not ablated; optimal scheduling is unknown.
- Fidelity and controllability:
- Timbre control via reference audio skips cross-modal interaction; the trade-off between timbre preservation and emotion/motion alignment is not quantified.
- Lack of explicit controllability over emotion intensity, speaking rate, prosody, gaze, or body motion; interface design for fine-grained control is an open problem.
- Computational efficiency and scalability:
- Training and inference compute, memory footprint, and latency (including MA-CFG’s extra forward pass) are not reported; feasibility for real-time or edge use is unknown.
- Scalability to higher video resolutions, higher audio sampling rates (e.g., 48 kHz), and longer sequences is not evaluated; cross-modal attention’s memory/computation scaling is unquantified.
- Safety, ethics, and misuse:
- No discussion of safeguards against identity cloning, deepfake misuse, or unauthorized dubbing; absence of watermarking, audit logs, or consent verification mechanisms.
- Bias and fairness impacts (e.g., demographic performance differences, accent handling) are not audited.
- Comparative fairness:
- Two-stage baselines (OmniAvatar, Wan-S2V) may be disadvantaged by the chosen TTS and setup; experimental controls ensuring fair comparison (prompt parity, input conditioning parity, hyperparameter tuning) are not detailed.
- Representation analysis:
- The claim of a “cohesive latent space” is not empirically supported; no probing of cross-modal feature alignment (e.g., CCA, MI estimates, representational similarity analysis) across layers.
- Failure case characterization:
- No systematic catalog of failure modes (e.g., mis-synced lip movements, emotion mismatch, identity drift, background instability) or diagnostic tools to detect and mitigate them.
- Integration with speech and audio pipelines:
- The audio content encoder is described as using ConvNeXt Blocks, which is atypical for text encoding in TTS; the exact architecture for text-to-acoustic conditioning (e.g., phoneme encoders, LM features) requires clarification and comparison to standard TTS stacks.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed with the paper’s current capabilities and reported performance, together with potential tools/workflows and key assumptions or dependencies.
- Media and entertainment: emotion- and timbre-consistent dubbing and localization of video content (films, shorts, ads, trailers) using video-to-audio dubbing (Tools/Workflow: “AV Dubbing API” that ingests a silent cut, script, and optional reference voice; NLE plug‑ins for Premiere/Resolve to replace ADR passes; MA‑CFG slider to tune emotional intensity; FAM-driven stability for faces) (Assumptions/Dependencies: high-quality transcripts or scripts; rights to use the voice/image; adequate GPU inference; robust face detection for the target footage; provenance/watermarking pipeline)
- Creator economy and marketing: talking-head generation from a still image and text for social posts, product explainers, and brand avatars, including anime/AIGC styles thanks to stronger OOD generalization (Tools/Workflow: “Avatar Builder” web app—input reference image + script + target timbre sample; batch generation for campaign variants; emotion presets via MA‑CFG) (Assumptions/Dependencies: consent for likeness/voice; prompt discipline; GPU/cloud costs; platform policies on synthetic media)
- Post-production (ADR) assistance: automatic lip re‑sync and emotion-aligned re‑voicing of scenes where the original audio is noisy or inconsistent (Tools/Workflow: timeline-aware “ADR Assistant” that aligns replacement audio to actor motion via A2V/V2A aligners; quick auditioning of multiple voice styles with reference audio) (Assumptions/Dependencies: reliable face tracking; timecode‑accurate scripts; post‑production review and human sign‑off)
- Education and training: lecture translation and re‑voicing with lip-synced instructor avatars to improve engagement and comprehension (Tools/Workflow: “Lecture Localizer” service—upload lecture video + translated script; select instructor timbre; produce aligned audio-video in target language) (Assumptions/Dependencies: legally cleared instructor likeness/voice; accurate translation; cultural adaptation; institutional disclosure of synthetic content)
- Customer support and corporate communications: consistent brand spokespeople for FAQs, announcements, and onboarding content (Tools/Workflow: “Virtual Spokesperson” pipeline—template prompts for emotion and tone; company-approved timbre anchors; analytics on viewer engagement) (Assumptions/Dependencies: approvals for brand voice/face; governance of message accuracy; content provenance tagging)
- Game development: rapid creation of character dialogue cutscenes with synchronized facial expressions and speech from text (Tools/Workflow: “Cutscene Synth” tool—import character image/model sheets + script; export aligned sequences for game engines) (Assumptions/Dependencies: integration with engine timelines; style domain adaptation for specific art directions; GPU budgets in content pipelines)
- Accessibility and language learning: mouth‑shape‑accurate talking heads for pronunciation practice and emotion-curated explanations (Tools/Workflow: “Pronunciation Coach” that generates syllable-level aligned visuals; adjustable speed and expressiveness via MA‑CFG) (Assumptions/Dependencies: pedagogical validation; privacy-compliant learner data handling; adjustable latency for classroom use)
- Academic research: a reproducible, data-efficient baseline for cross-modal generation and alignment studies (Tools/Workflow: open benchmarking of A2V/V2A aligners, FAM masks, MA‑CFG; multi-task unification for controlled studies; ablation templates) (Assumptions/Dependencies: availability/licensing of code and model weights; standardized AV alignment metrics beyond lip‑sync, timbre, emotion; compute access)
- Policy and compliance operations: internal prototyping of provenance, consent management, and synthetic content disclosures for AV workflows (Tools/Workflow: “Consent Manager” to track voice/image rights; “Provenance Tagger” (e.g., C2PA-aligned) watermark insertion at render; audit logs) (Assumptions/Dependencies: organizational policies; legal review; integration with content delivery systems and platforms)
Long-Term Applications
These use cases are feasible but likely require further research, scaling, engineering, or regulatory development (e.g., real-time performance, larger-scale generalization, robust guardrails).
- Real-time cross‑lingual telepresence: live meeting avatars that preserve a speaker’s timbre and identity while translating and lip‑syncing in near real time (Potential Tools/Products: “Live Translate Avatar” integrated into Zoom/Teams; streaming DiT with incremental MA‑CFG; adaptive latency control) (Assumptions/Dependencies: streaming TTS/ASR, low‑latency AV inference on edge/cloud, jitter buffering, robust face tracking; platform acceptance)
- Virtual production with synthetic performers: scalable pipelines where dialog and performance are co‑synthesized and controlled by text, references, and direction cues (Potential Tools/Products: “Director’s Console” for scene-level blocking and emotion curves; fine-grain control over A2V/V2A alignment windows) (Assumptions/Dependencies: legal frameworks for voice/likeness rights; union agreements; scalable render farms; safety guardrails against misuse)
- Social robots and embodied AI: robots with screen faces or animatronics that speak with synchronized facial expressions and emotional nuance (Potential Tools/Products: “Robot Persona SDK” bridging UniAVGen outputs to hardware actuators and screens; emotion policy layer) (Assumptions/Dependencies: hardware constraints; real-time synthesis; human-robot interaction safety and ethics approvals)
- Healthcare and mental health support: empathetic virtual counselors and patient education avatars that adapt emotion and timing to clinical guidelines (Potential Tools/Products: “Clinical Avatar” with controlled affect ranges; audit trails and consent tracking) (Assumptions/Dependencies: clinical validation, bias/fairness audits, privacy compliance (HIPAA/GDPR), clear disclosures, crisis escalation policies)
- Advanced language learning: interactive tutors that adapt mouth shapes, prosody, and emotional delivery to learner progress, providing fine-grained feedback (Potential Tools/Products: “Adaptive Tutor” with phoneme-level visualization; reinforcement strategies using MA‑CFG) (Assumptions/Dependencies: pedagogical trials; alignment with curricula; on-device optimization for classrooms; accessibility features)
- Live broadcasting and news localization: simultaneous re‑voicing of anchors into multiple languages with lip‑sync and emotion consistency (Potential Tools/Products: “Broadcast Localizer” for multi‑language channels; newsroom integration) (Assumptions/Dependencies: tight latency budgets; editorial oversight; compliance with regional content rules; provenance indicators for viewers)
- On-device AV generation: mobile or edge deployment for privacy-preserving personal avatars and local content creation (Potential Tools/Products: quantized and distilled UniAVGen variants; hardware acceleration) (Assumptions/Dependencies: model compression and quantization without losing alignment quality; battery/thermal constraints; local storage policies)
- Standardization and regulation: sector-wide adoption of disclosure, watermarking, and rights management around voice and likeness in AV generation (Potential Tools/Products: “Rights Registry” for voice/face licensing; standardized emotional alignment metrics and tests; compliance dashboards) (Assumptions/Dependencies: multistakeholder policy processes; alignment with C2PA, EU/US regulations; interoperable provenance tooling)
- Creative tooling for stylized domains: robust domain adapters for anime, games, and mixed-media art that retain alignment while achieving specific aesthetics (Potential Tools/Products: “Style Adapter” libraries and fine-tuning toolkits for studios) (Assumptions/Dependencies: curated domain datasets; fine-tuning safety; IP considerations for stylized references)
Cross-cutting assumptions and dependencies that impact feasibility
- Data and rights: lawful access to training and reference data; explicit consent for voice and likeness; clear licensing and revocation mechanisms.
- Compute and latency: 7.1B-parameter joint models may require significant GPU resources; real-time scenarios need streaming architectures and optimization.
- Safety and governance: strong guardrails against impersonation and deepfakes (watermarking/provenance, consent verification, usage monitoring); transparent disclosures.
- Robustness: accurate face detection/masking (FAM) and reliable cross-modal alignment in diverse domains, lighting, occlusions; failure modes need fallback plans.
- Evaluation: standardized, open AV alignment metrics for timbre/emotion (beyond lip‑sync); human-in-the-loop QA workflows.
- Integration: APIs and plug‑ins for existing video editors, conferencing platforms, game engines, and robotics stacks; content delivery platform policies.
Glossary
- AIGC: Acronym for AI-generated content, referring to media produced by generative models. "AIGC-generated content or anime-style visuals."
- AudioBox-Aesthetics: A benchmark for assessing aesthetic and production quality of generated audio. "AudioBox-Aesthetics"
- Audio-driven video synthesis: A paradigm where audio (often speech) drives the generation of corresponding video frames. "Audio-driven video synthesis."
- Audio-to-video (A2V) aligner: A module that injects fine-grained audio cues into video features to ensure semantic synchronization. "Audio-to-video (A2V) aligner."
- Asymmetric Cross-Modal Interaction: A mechanism enabling modality-specific, temporally aligned information flow between audio and video. "Asymmetric Cross-Modal Interaction mechanism"
- Asymmetric Temporal-Aligned Interaction (ATI): A cross-modal design that aligns audio and video with modality-specific temporal strategies. "our proposed Asymmetric Temporal-Aligned Interaction as ATI."
- Classifier-Free Guidance (CFG): A guidance technique that improves conditional fidelity by mixing conditional and unconditional model outputs. "Classifier-Free Guidance (CFG) is a cornerstone technique for enhancing conditional fidelity in generative models."
- Content Usefulness (CU): An audio evaluation metric indicating how useful or informative the content is. "Content Usefulness (CU)"
- ConvNeXt: A convolutional neural network architecture used to extract features, here for speech content conditioning. "via ConvNeXt Blocks"
- Cross-attention: An attention mechanism where one modality conditions on another via key-value pairs. "its embeddings are fed into the Diffusion Transformer (DiT) through cross-attention."
- Cross-modal interaction: Information exchange between modalities (audio and video) during generation. "cross-modal interaction"
- Denoising network: The diffusion model’s core network that progressively removes noise to generate data. "the denoising network."
- Diffusion Transformer (DiT): A Transformer-based architecture tailored for diffusion models. "Diffusion Transformer (DiT)"
- Dynamic Degree (DD): A video metric quantifying the motion richness or dynamism in generated clips. "Dynamic Degree (DD)"
- Dynamic mask prediction: A learnable mechanism that produces soft masks to focus interaction on salient regions (e.g., face). "Dynamic mask prediction."
- Emotion consistency (EC): A cross-modal metric measuring how well the video’s expressions align with audio emotion. "emotion consistency (EC)"
- Face-Aware Modulation (FAM): A module that biases cross-modal attention toward facial regions to improve alignment. "Face-Aware Modulation (FAM) module"
- Flow Matching paradigm: A training objective for diffusion-like models that learns a vector field guiding samples to data. "we adopt the Flow Matching paradigm"
- Imaging Quality (IQ): A video metric evaluating visual clarity and fidelity of generated frames. "Imaging Quality (IQ)"
- Layer normalization: A normalization technique applied per layer to stabilize and accelerate training. "layer normalization"
- Latent space: A compressed representation space where audio and video features interact and are synthesized. "cross-modal latent space"
- Learned affine transformation: A trainable scaling and shifting operation applied to features. "a learned affine transformation"
- Lip synchronization (LS): A metric assessing alignment between mouth movements and spoken audio. "lip synchronization (LS)"
- Mel spectrograms: Time–frequency audio representations derived from the Mel scale, used as latents for audio generation. "converted into Mel spectrograms"
- Modality decoupling: Designing pipelines where audio and video are generated separately, reducing cross-modal interplay. "modality decoupling impedes cross-modal interplay during generation"
- Modality-Aware Classifier-Free Guidance (MA-CFG): A guidance scheme that explicitly amplifies cross-modal conditioning during inference. "Modality-Aware Classifier-Free Guidance (MA-CFG), a novel strategy that explicitly amplifies cross-modal correlation signals."
- Multi-task unification: Integrating multiple related tasks (e.g., dubbing, continuation) into a single framework. "Multi-task unification"
- Out-of-distribution (OOD): Inputs outside the training domain used to test generalization. "out-of-distribution (OOD) anime image"
- Production Quality (PQ): An audio metric evaluating the technical quality and polish of generated sound. "Production Quality (PQ)"
- Subject Consistency (SC): A video metric measuring identity preservation across frames. "Subject Consistency (SC)"
- SyncNet: A model used to score lip synchronization confidence between audio and video. "SyncNet's confidence score"
- Symmetric Global Interaction (SGI): A cross-modal approach where each token attends to all tokens of the other modality. "Symmetric Global Interaction as SGI"
- Symmetric Temporal-Aligned Interaction (STI): A cross-modal design aligning tokens strictly by corresponding time intervals. "Symmetric Temporal-Aligned Interaction as STI"
- Temporal neighbor interpolation: A strategy that interpolates adjacent video frames to align with finer-grained audio tokens. "we adopt a temporal neighbor interpolation strategy."
- Text-to-Speech (TTS): Models that synthesize speech audio from text input. "Text-to-Speech (TTS) model"
- Timbre: The characteristic quality of a voice or sound that differentiates speakers or instruments. "timbre consistency"
- Timbre consistency (TC): A cross-modal metric assessing whether generated audio timbre matches the visual identity. "timbre consistency (TC)"
- umT5: A multilingual T5 variant used to encode text prompts for video conditioning. "via umT5"
- Variational Autoencoder (VAE): A probabilistic autoencoder used to compress and reconstruct video frames in latent space. "Variational Autoencoder (VAE)"
- Vector field: The function learned in flow matching that points from noise to data at each time. "predict the vector field v_t"
- VBench: A benchmark suite for evaluating multiple aspects of video generation quality. "We utilize VBench"
- Video-to-audio synthesis: Generating aligned audio tracks conditioned on silent video inputs. "Video-to-audio synthesis."
- Word Error Rate (WER): A speech recognition metric quantifying transcription errors in generated audio. "Word Error Rate (WER)"
Collections
Sign up for free to add this paper to one or more collections.

