Harmony: Harmonizing Audio and Video Generation through Cross-Task Synergy
Abstract: The synthesis of synchronized audio-visual content is a key challenge in generative AI, with open-source models facing challenges in robust audio-video alignment. Our analysis reveals that this issue is rooted in three fundamental challenges of the joint diffusion process: (1) Correspondence Drift, where concurrently evolving noisy latents impede stable learning of alignment; (2) inefficient global attention mechanisms that fail to capture fine-grained temporal cues; and (3) the intra-modal bias of conventional Classifier-Free Guidance (CFG), which enhances conditionality but not cross-modal synchronization. To overcome these challenges, we introduce Harmony, a novel framework that mechanistically enforces audio-visual synchronization. We first propose a Cross-Task Synergy training paradigm to mitigate drift by leveraging strong supervisory signals from audio-driven video and video-driven audio generation tasks. Then, we design a Global-Local Decoupled Interaction Module for efficient and precise temporal-style alignment. Finally, we present a novel Synchronization-Enhanced CFG (SyncCFG) that explicitly isolates and amplifies the alignment signal during inference. Extensive experiments demonstrate that Harmony establishes a new state-of-the-art, significantly outperforming existing methods in both generation fidelity and, critically, in achieving fine-grained audio-visual synchronization.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Harmony, an AI system that can create videos and audio together so they match perfectly. Think of a music video where the singer’s lip movements line up exactly with the words, or a scene where the sound of a door slam happens at the exact moment the door shuts. Harmony focuses on making this kind of precise audio-video synchronization work reliably in open-source models.
What is the paper trying to find out?
The researchers asked:
- Why do many open-source AI models struggle to keep sound and video in sync?
- How can we train and design a model so that audio and video match both in timing (like lip-sync) and overall style (like mood and ambience)?
- Can we build a single, general system that creates speech and environmental sounds along with video, all in harmony?
How did they do it? Methods explained simply
To understand the methods, it helps to know a few basic ideas:
- Diffusion model: Imagine starting with a very noisy, blurry TV picture and slowly cleaning it up step by step until a clear video appears. The same happens for audio. The model “denoises” both at the same time.
- Latent: A compressed version of audio or video that the model works with internally (like a hidden representation).
- Attention: A way for the model to “focus” on the most relevant parts of audio or video (like paying attention to the singer’s mouth when syncing speech).
- Guidance (CFG): A technique that nudges the model to follow certain instructions more strongly (like turning up a “follow the prompt” dial).
First, the paper explains why syncing is so hard:
- Correspondence Drift: At the start, both audio and video are very noisy. It’s like trying to match two dancers in the dark—both are moving unpredictably, so learning perfect timing is unstable.
- One-size-fits-all attention: Many models use a single global attention mechanism, which tries to handle both big-picture style (mood, emotion) and tiny timing details (lip movements) at once. That often causes a trade-off where neither is perfect.
- Guidance that misses the point: Standard guidance makes the model follow text prompts better, but doesn’t specifically improve how sound and video match each other.
To fix this, Harmony introduces three key ideas:
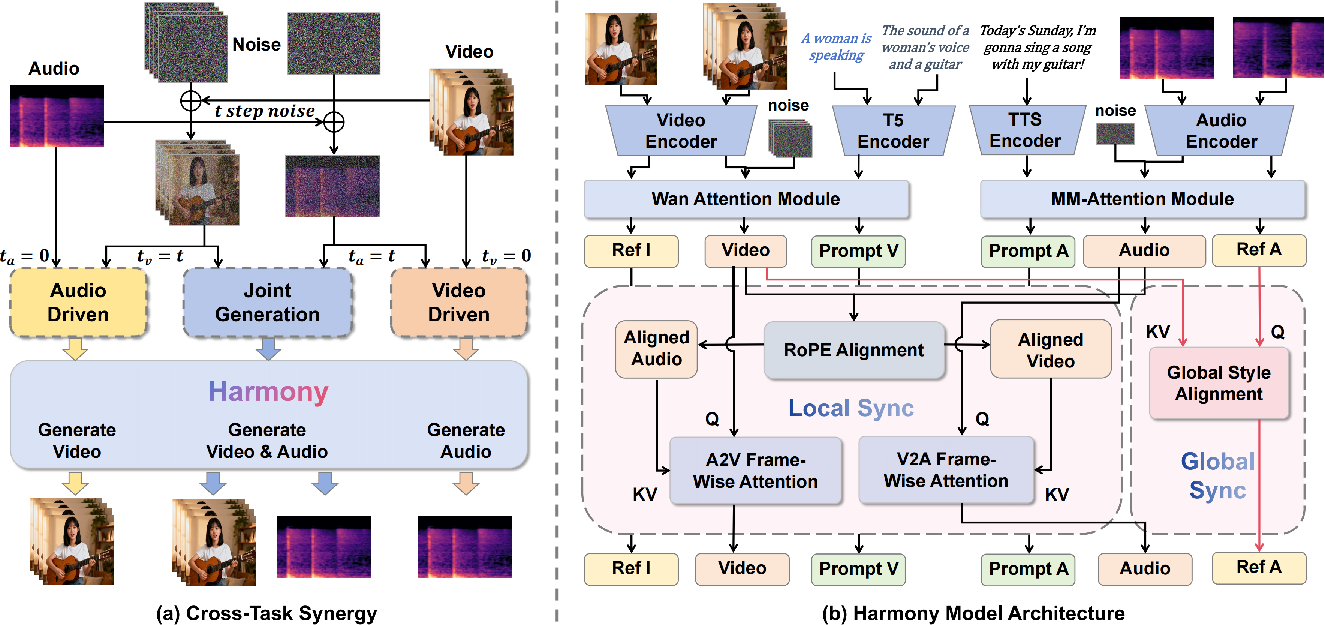
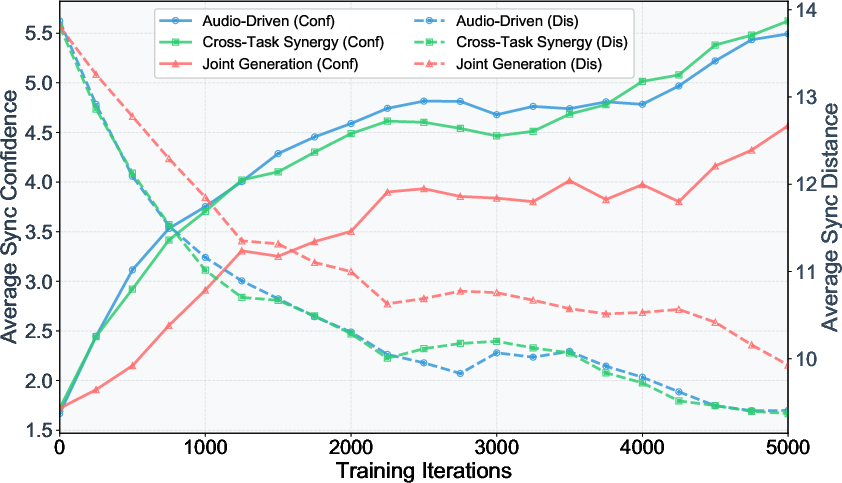
- Cross-Task Synergy: The model is trained on three related tasks together: 1) Joint audio-video generation (make both at once), 2) Audio-driven video (make the video based on clean audio), 3) Video-driven audio (make the audio based on clean video).
The trick is that tasks 2 and 3 give strong, clear signals because one side (audio or video) is clean, not noisy. It’s like practicing dance with a metronome: the clear beat helps the dancers learn perfect timing, which then improves their performance when they dance freely.
- Global-Local Decoupled Interaction: The model separates two kinds of “attention”:
- Local, frame-wise attention for precise timing: It aligns small moments, like each mouth frame to the exact speech sound. Harmony adds a timing alignment step so the audio and video timelines match even if they have different speeds. You can think of it as stretching one timeline so both follow the same beat.
- Global style alignment for overall mood: The model shares big-picture style (like emotion, ambience, timbre) through a dedicated pathway so style stays consistent without messing up the tight timing.
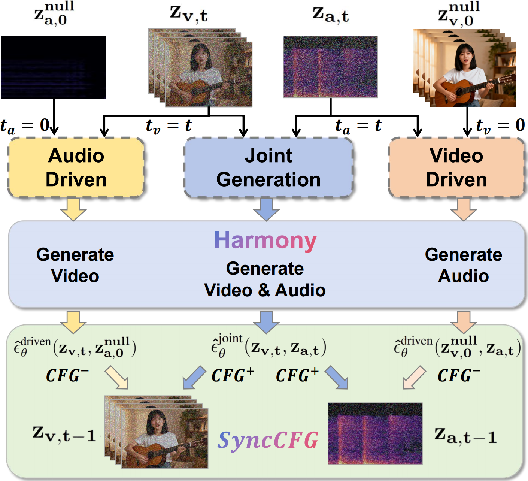
- Synchronization-Enhanced CFG (SyncCFG): Instead of just turning up the “follow the prompt” dial, SyncCFG turns up the “stay in sync” dial. How? By comparing the normal generation to special “negative anchors”:
- For video: Compare motion to a “silent audio” baseline (what the video would look like if there were no sound—e.g., a still face). The difference highlights audio-driven motion (like mouth movements), which the model then amplifies.
- For audio: Compare sound to a “static video” baseline (a scene with no motion). The difference highlights motion-driven sounds (like footsteps), which the model then amplifies.
Together, these three ideas teach the model both the tiny timing and the big-picture style, and give it a clear signal to keep sound and video in lockstep.
What did they find?
Harmony set a new state-of-the-art on their benchmark, Harmony-Bench, which tests:
- Ambient sounds with video,
- Speech with video (lip-sync),
- Complex scenes combining speech and environmental audio.
Key results:
- Much better timing: Harmony scored highest on sync metrics (like lip-sync quality and timing accuracy), meaning it aligns sound and video more precisely than other open-source methods.
- Strong quality: It produced high-quality video and audio, including natural human speech and realistic environmental sounds.
- Versatility: It handles joint generation, audio-driven video, and video-driven audio, and works across different styles, from talking heads to music performance.
Why does this matter?
Harmony helps close the gap between open-source and proprietary AI systems for making complete, immersive media—videos that look and sound right together. This could improve:
- Content creation: More realistic music videos, short films, and social media clips.
- Digital avatars and games: Characters who speak and move in perfect sync.
- Education and accessibility: Tools that generate clear, synchronized audio-visual content for learning or captioning.
- Open research: A stronger foundation for others to build well-synchronized, multi-modal models.
In short, Harmony shows that you can get better sync not just by making models bigger, but by training them smarter and designing them to handle timing and style separately, then guiding them to keep audio and video truly in harmony.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues, uncertainties, and missing explorations that remain after this paper. Each item is phrased to be concrete and actionable for future research.
- Formalization of Correspondence Drift: The paper motivates “Correspondence Drift” empirically but does not provide a formal definition, diagnostic metric, or controlled analysis (e.g., how drift varies with noise schedules, coupling strategies, or denoising timesteps). A quantitative framework to measure and compare drift across model variants and schedulers is missing.
- Theoretical understanding of cross-task synergy: Cross-task synergy is shown to help empirically, but there is no theoretical analysis of why and when uni-directional tasks should optimally regularize the joint task, nor a treatment of potential negative transfer (e.g., when auxiliary tasks bias the joint model).
- Hyperparameter sensitivity and training schedules: The effects of λv, λa (task weights), attention window sizes, RoPE scaling factors, and guidance strengths sv, sa are not systematically ablated. Clear guidance on stable ranges, sensitivity curves, and schedules is absent.
- Null/negative anchors in SyncCFG are under-specified: How “mute-audio” and “static-video” latents are constructed at inference time (e.g., distributional assumptions, conditioning content, temporal statistics) is unclear. Failure modes when scenes have inherent motion unrelated to audio (e.g., wind, background crowd) or sounds that should not produce visible motion (e.g., off-screen audio) are not analyzed.
- Over-synchronization risk with SyncCFG: The method may force visual motion inappropriately or suppress legitimate motion when audio is weak/noisy. No safeguards, calibration strategies, or diagnostics (e.g., detecting when audio should not cause motion) are provided.
- Handling multiple concurrent sources: The approach is demonstrated qualitatively on multi-person scenes but lacks quantitative evaluation for overlapping speakers, multiple instruments, or mixed environmental events. Source selection, diarization, and mixture disentanglement are not addressed.
- Spatial and multichannel audio: The audio branch appears to operate on mono latents; there is no treatment of stereo/spatial audio, audio panning, or audio-visual spatial localization (e.g., mapping sound source location to camera pose, 3D scene context).
- Long-duration scalability and efficiency: There is no complexity analysis or empirical scaling study for long videos (e.g., minutes), high frame rates, and high-sample-rate audio. Memory, latency, and throughput, as well as strategies for chunked or streaming generation, remain unaddressed.
- Generalization across languages and accents: While multilingual data is mentioned, there is no breakdown of performance across languages, accents, and noisy transcripts, nor evaluation of non-Latin scripts. WER is reported globally without language-wise analysis.
- Event-level timing metrics for non-speech sounds: Synchronization is primarily evaluated with lip-sync metrics; precise event-onset alignment for Foley, impacts, and instrument onsets is not measured (e.g., onset detection F1, temporal deviation distributions).
- Benchmark independence and test contamination: Harmony-Bench is authored by the paper’s team and assembled from the same data sources used for training; safeguards against test overlap, leakage, or distributional bias are not documented. Public release status, licenses, and curation protocols are unclear.
- Human evaluation: The study relies heavily on automated metrics; no controlled human judgments (e.g., MOS for A/V sync, perceptual realism, semantic coherence) or correlations between automatic metrics and human perception are reported.
- Fairness of baseline comparisons: Details about prompt design, inference budgets, fine-tuning, and data availability for baselines are sparse. Without standardized evaluation protocols and seeds, it is unclear whether differences are due to method or experimental setup.
- Robustness to noisy, mismatched, or adversarial conditions: There is no stress testing with misaligned transcripts, noisy reference audio, incorrect prompts, or domain shifts (e.g., rare sound events, abstract visuals), nor a taxonomy of failure cases.
- Applicability without reference audio/image: The model design leverages reference audio for timbre and a reference image for video identity; fallback behavior and performance when such references are unavailable or noisy is not documented.
- Controllability of synchronization strength: The system lacks user-facing controls to modulate alignment intensity (e.g., a “sync knob” to trade off style vs. timing, or deliberate desynchronization for artistic effects), and no study evaluates the controllability range.
- Impact on audio fidelity: The paper shows overall audio quality metrics but does not analyze whether SyncCFG or frame-wise attention degrade timbre, prosody, or spectral detail (e.g., high-frequency transients), especially in complex scenes.
- Architectural portability: Harmony relies on Wan2.2-5B for video and a specific audio VAE/MM-DiT stack. It is unknown whether the method transfers across other backbones (UNet-based, different DiT sizes), codecs, or VAEs without retraining instability.
- RoPE alignment assumptions: The RoPE scaling approach presumes linear time rescaling between modalities; potential inaccuracies with variable frame rates, dropped frames, time warping, or audio time-stretching are not investigated.
- Windowed local attention design: Attention window sizes, stride, and boundary handling (e.g., at clip edges) are not described or ablated. How local windows adapt to fast vs. slow motions or dense acoustic events is unknown.
- Causality vs. correlation: The method enhances correlation between sound and motion but does not explicitly encode causal structure. Scenarios where visual events precede audio (or vice versa), or where causes are off-screen, need evaluation and potential causal modeling.
- Data annotation quality and bias: Large-scale labels are generated by Gemini; the reliability, error rates, and bias profiles of these annotations, and their effect on alignment learning (especially for nuanced sound categories), are not quantitatively assessed.
- Privacy and ethics: Voice cloning, identity reproduction, and potential misuse are not discussed; no safeguards (e.g., consent protocols, watermarking, identity protection) are provided.
- Reproducibility and release details: Many crucial implementation specifics (architectural hyperparameters, loss balancers, data preprocessing, training schedules) are deferred to supplementary material; it is unclear whether code, models, Harmony-Bench, and evaluation scripts will be fully released for replication.
- Intentional asynchrony: There is no mechanism or evaluation for generating controlled asynchrony (e.g., deliberate off-beat lip movements or delayed Foley), which is important for creative and editorial workflows.
- Failure case taxonomy: The paper does not present qualitative/quantitative failure analyses (e.g., specific conditions where alignment breaks, typical artifacts introduced by SyncCFG, or mislocalized attention in complex scenes), hindering targeted method improvements.
Practical Applications
Practical Applications of Harmony’s Findings
Harmony introduces three core innovations—Cross-Task Synergy training, a Global-Local Decoupled Interaction Module (RoPE-aligned frame-wise attention + global style alignment), and Synchronization-Enhanced CFG (SyncCFG)—that materially improve fine-grained audio-video synchronization for speech, music, and environmental sounds, while supporting multiple paradigms (joint AV generation, audio-driven video, and video-driven audio). The following applications translate these contributions into concrete value across industry, academia, policy, and daily life.
Immediate Applications
These can be deployed now with standard offline inference pipelines and modest integration work.
- Auto-Foley and ambient sound design for silent or rough-cut videos (Media/Entertainment, Software)
- Potential tools/workflows: NLE plugins for Premiere/DaVinci/Final Cut that generate synchronized sound effects and ambience from picture lock; batch auto-Foley for catalog content; “sound passes” generation in post.
- Assumptions/dependencies: Access to the Harmony model via API or weights; SFX/style control UIs; rights-compliant usage of prompts/reference audio; GPU inference budgets; domain adaptation for specific genres.
- Lip-synced dubbing and ADR generation (Localization, Film/TV, EdTech)
- Potential tools/workflows: ADR assistant that takes transcript (Ts), reference timbre (Ar), and video to generate in-language, lip-synced audio (and optionally refine mouth motions); cross-lingual dubbing mockups; rapid previz voice passes.
- Assumptions/dependencies: High-quality transcripts; voice consent and licensing; language-specific phoneme handling; human review in final post.
- Audio-driven talking-head avatars for marketing, training, and customer service (Marketing, Enterprise CX, EdTech)
- Potential tools/workflows: Avatar SDKs for websites and help centers; training video generator from scripts and reference brand voice; creator tools for VTubers and presenters.
- Assumptions/dependencies: Reference images/identity approvals; safety/moderation guardrails; latency acceptable for near-real-time or offline use.
- Music performance visualization and social content (Music tech, Creator economy)
- Potential tools/workflows: Apps that turn user audio (instrument/voice) into synchronized performance videos; music promotion clips with beat/motion sync; instrument-specific templates.
- Assumptions/dependencies: Coverage of target instruments/styles in training data; IP clearance for music; controllability over framing and camera motion.
- Social media auto-soundtrack and meme creation (UGC platforms)
- Potential tools/workflows: One-tap “match my video to sound” or “sound to video” features; mobile filters that add synchronized SFX or voiceover to clips.
- Assumptions/dependencies: Mobile-friendly inference (possibly cloud-backed); content safety; UX for prompt/control.
- Alignment diagnostics and quality control in post-production (Software, Media ops)
- Potential tools/workflows: Harmony-Bench metrics packaged as a plugin to flag desync regions and suggest fixes; visualization of cross-modal attention to locate sound sources and lip regions.
- Assumptions/dependencies: Integration with editorial timelines; metric calibration to editorial standards; interpretable visualizations.
- Synthetic AV dataset generation for research and model training (Academia, R&D, ASR/AVSR/CV)
- Potential tools/workflows: Pipelines to generate lipreading or AV-event datasets with tightly controlled sync; stress tests for AV models; ablation-ready corpora using Harmony-Bench task templates.
- Assumptions/dependencies: Distribution shifts vs. real-world data; dataset licensing for redistribution; metadata generation and labeling.
- Accessibility-oriented content generation (Accessibility, Education)
- Potential tools/workflows: Lip-readable educational content with controllable mouth-shape clarity; speech-to-talking-head for learners relying on visual speech cues; adjustable global style for clearer articulation.
- Assumptions/dependencies: User studies to validate benefits; avoidance of uncanny valley; inclusive design and consent for likeness use.
- Rapid prototyping for game cutscenes and narrative beats (Gaming, Tools)
- Potential tools/workflows: Unity/Unreal plugins to generate synced ambience and dialogue placeholders from animatics; automatic re-soundtracking after animation edits.
- Assumptions/dependencies: Engine integration; iteration speed; style control to match artistic direction.
- Benchmarking and reproducible evaluation of AV models (Academia, Industry R&D)
- Potential tools/workflows: Harmony-Bench packaged as an open evaluation suite; standardized lip-sync and sync metrics; baselines for future AV models and ablations.
- Assumptions/dependencies: Public availability and licensing of evaluation data; reproducible reference implementations; community adoption.
Long-Term Applications
These require further research, scaling, efficiency gains, or multi-system integration (e.g., streaming, multilingual, safety frameworks).
- Real-time, cross-lingual live translation with lip re-synthesis (Communications, Media, EdTech)
- Potential tools/workflows: Live conferencing overlays that reanimate speakers’ lips to target-language speech; on-device or edge-accelerated pipelines; adaptive SyncCFG for streaming.
- Assumptions/dependencies: Low-latency diffusion or alternative real-time architectures; robust multilingual TTS; privacy and consent management.
- Interactive embodied avatars in AR/VR with perfectly aligned AV (XR, Robotics)
- Potential tools/workflows: Virtual guides/companions with synchronized speech and motion; environment-aware sound generation that reacts to user actions; co-creative world-building.
- Assumptions/dependencies: Motion capture or pose tracking integration; real-time generative pipelines; safety systems to prevent misuse.
- Broadcast-quality end-to-end generative scenes from scripts (Film/TV, Advertising)
- Potential tools/workflows: Script-to-AV pipelines producing storyboards, animatics, and near-final sequences with synchronized dialogue and soundscapes; granular controls for directors.
- Assumptions/dependencies: Creative controllability, style consistency at scale, rights/union/regulatory frameworks for synthetic performers and voices.
- Telepresence and customer service agents with dynamic, context-aware soundscapes (Enterprise CX)
- Potential tools/workflows: Agents that adapt audiovisual delivery to environment or user context (e.g., quieter ambience at night, expressive tone for empathy).
- Assumptions/dependencies: Context sensing; brand safety and compliance; robust guardrails for hallucination and bias.
- Multimodal robotics and embodied AI training via procedurally generated AV stimuli (Robotics, Autonomy)
- Potential tools/workflows: Curriculum learning datasets with synchronized motion-sound events to train cross-modal perception and anticipation; simulation-in-the-loop training.
- Assumptions/dependencies: Sufficient realism to transfer to the physical world; coverage of edge cases; safety evaluation.
- Clinical speech therapy and rehabilitation with adaptive AV feedback (Healthcare)
- Potential tools/workflows: Tools that generate target mouth-shape videos aligned to therapeutic audio cues; patient-specific pacing and articulation coaching with measurable sync metrics.
- Assumptions/dependencies: Clinical trials for efficacy; regulatory approval; accessibility accommodations and clinician oversight.
- AV integrity and provenance tooling to counter deepfakes (Policy, Trust & Safety)
- Potential tools/workflows: Desynchronization detectors and benchmarks derived from Harmony-Bench to flag suspicious content; standardized sync metrics in provenance reports.
- Assumptions/dependencies: Adversarial robustness; integration with watermarking/provenance (e.g., C2PA); policy alignment and minimum disclosure standards.
- Smart classrooms and automated instructional media (Education)
- Potential tools/workflows: Script-to-lesson AV generation with clear articulation and synchronized demonstrations; multilingual variants with lip-consistent dubbing.
- Assumptions/dependencies: Pedagogical validation; teacher-in-the-loop editing; age-appropriate safety controls.
- On-device or edge deployment for consumer devices (Consumer, Mobile)
- Potential tools/workflows: Lightweight Harmony variants for phones/AR glasses enabling private, low-latency AV generation (e.g., assistive overlays).
- Assumptions/dependencies: Model compression/quantization; hardware acceleration; battery and thermal limits.
- Multisensory simulation for transportation and safety training (Transportation, Public Safety)
- Potential tools/workflows: Scenario generation with synchronized visual hazards and audio cues (sirens, tire skids) for training drivers, pilots, or first responders.
- Assumptions/dependencies: High-fidelity simulation requirements; validation against real-world incident data; liability considerations.
Notes on Feasibility and Dependencies
- Model access and licensing: Practical deployment depends on the availability of Harmony weights or API access and the licensing of training/evaluation datasets (Harmony-Bench).
- Compute and latency: Current diffusion-based pipelines favor offline/batch workflows; real-time use cases require research on streaming inference, distillation, or alternative architectures.
- Controllability: Production settings will need robust controls (phoneme timing, emphasis, ambience levels, timbre/style locks) and editing interfaces beyond basic prompting.
- Safety and compliance: Voice/timbre cloning requires explicit consent; synthetic likenesses must adhere to platform and legal policies; content provenance and disclosure are recommended.
- Domain adaptation: Specialized sectors (medical, industrial, certain musical instruments) may require fine-tuning or curated prompts/reference material for optimal fidelity.
Glossary
- AudioBox-Aesthetics (PQ, PC, CE, CU): A suite of automated audio quality and aesthetics metrics used to evaluate generated audio. "AudioBox-Aesthetics (PQ, PC, CE, CU)"
- Audio-driven video generation: A generation paradigm where video is conditioned on and synchronized to an input audio stream. "audio-driven video and video-driven audio generation tasks"
- Audio-to-Video (A2V): A cross-modal interaction direction where audio features guide or align the video features at specific time frames. "Taking A2V as an example"
- Classifier-Free Guidance (CFG): A guidance technique for diffusion models that combines conditional and unconditional predictions to strengthen adherence to conditioning signals. "the intra-modal bias of conventional Classifier-Free Guidance (CFG), which enhances conditionality but not cross-modal synchronization."
- Correspondence Drift: An instability in joint diffusion training where the optimal mapping between concurrently denoised audio and video latents shifts over time, impeding alignment. "a phenomenon we term Correspondence Drift"
- Cross-Task Synergy: A training paradigm that co-trains joint generation with auxiliary uni-directional tasks to provide strong alignment supervision. "We first propose a Cross-Task Synergy training paradigm to mitigate drift"
- DeSync: A metric estimating temporal misalignment between audio and video streams. "temporal misalignment (DeSync via Synchformer)"
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion model denoising and generation. "Diffusion Transformers (DiT)"
- DINOv3: A self-supervised visual representation model used here to measure identity consistency across frames. "Identity Consistency (DINOv3)"
- Global cross-attention: An attention mechanism that attends over the entire sequence to integrate information across modalities globally. "a single, monolithic mechanism like global cross-attention"
- Global Style Alignment: A module that propagates holistic style or tone across modalities to ensure consistent global characteristics. "a dedicated Global Style Alignment module"
- Global-Local Decoupled Interaction Module: An interaction design that separates global style propagation from local frame-level synchronization to avoid conflict. "we design a Global-Local Decoupled Interaction Module for efficient and precise temporal-style alignment."
- Guidance vector: The direction computed by contrasting conditional and negative-anchor predictions to steer the denoising toward desired properties. "explicitly isolate and amplify the guidance vector corresponding to audio-visual alignment."
- IB-A Score: An audio metric reflecting intelligibility or aesthetic aspects in audio evaluations. "IB-A Score."
- IB-score: An overall audio-visual consistency metric assessing coherence between modalities. "overall consistency (IB-score)."
- Latent Diffusion Model: A diffusion framework operating in a compressed latent space rather than pixel or waveform space. "dual-stream Latent Diffusion Model."
- Multi-Modal Diffusion Transformer (MM-DiT): A diffusion transformer variant designed to process and align multiple modalities jointly. "Multi-Modal Diffusion Transformer (MM-DiT)"
- MUSIQ: An image quality assessment metric used to evaluate visual fidelity of generated video frames. "Imaging Quality (MUSIQ)"
- Negative Anchor: A carefully chosen baseline input (e.g., mute audio or static video) used to isolate synchronization-related changes for guidance. "design a more meaningful Negative Anchor"
- RAFT: An optical flow model used to quantify motion dynamics in video (e.g., Dynamic Degree). "Dynamic Degree (RAFT)"
- Rotary Positional Embeddings (RoPE): A positional encoding scheme that uses rotations in embedding space, enabling flexible alignment of temporal indices. "Rotary Positional Embeddings (RoPE)"
- RoPE-Aligned Frame-wise Attention: A localized cross-attention strategy that aligns audio and video timelines by scaling RoPE indices for precise frame-level synchronization. "a RoPE-Aligned Frame-wise Attention module"
- Sync-C: A lip-sync metric indicating the strength or correctness of audio-visual alignment. "lip-sync metrics (Sync-C, Sync-D)"
- Sync-D: A lip-sync metric quantifying deviation or delay in audio-visual synchronization. "lip-sync metrics (Sync-C, Sync-D)"
- Synchronization-Enhanced CFG (SyncCFG): A guidance method that uses negative anchors to explicitly amplify audio-video synchronization during inference. "Synchronization-Enhanced CFG (SyncCFG)"
- Timbre disentanglement: A finetuning strategy to separate and control speaker identity or vocal timbre independently from other audio attributes. "timbre disentanglement finetuning using multi-utterance speech data"
- Video-driven audio generation: A generation paradigm where audio is conditioned on and synchronized to an input video stream. "audio-driven video and video-driven audio generation tasks"
- Video-to-Audio (V2A): A cross-modal interaction direction where video features guide or align the audio features at specific time frames. "The Video-to-Audio (V2A) frame-wise alignment operates analogously."
- WER (Whisper-large-v3): Word Error Rate measured by the Whisper-large-v3 ASR model to assess speech intelligibility. "WER (Whisper-large-v3)"
Collections
Sign up for free to add this paper to one or more collections.