Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
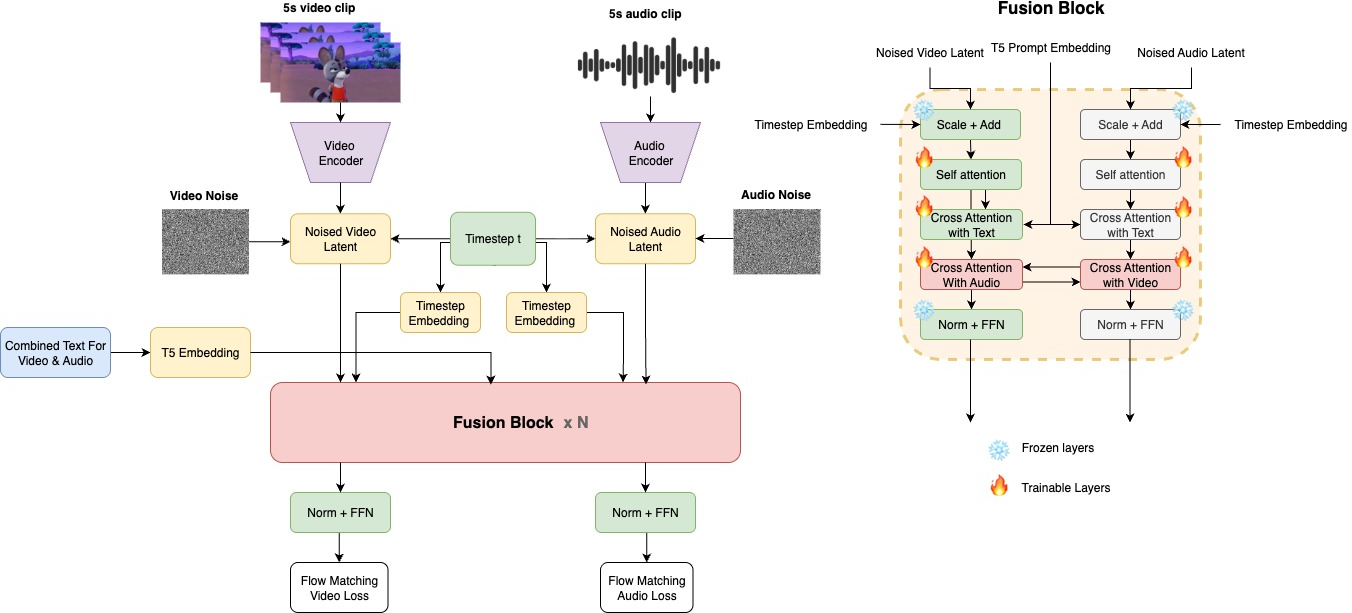
Abstract: Audio-video generation has often relied on complex multi-stage architectures or sequential synthesis of sound and visuals. We introduce Ovi, a unified paradigm for audio-video generation that models the two modalities as a single generative process. By using blockwise cross-modal fusion of twin-DiT modules, Ovi achieves natural synchronization and removes the need for separate pipelines or post hoc alignment. To facilitate fine-grained multimodal fusion modeling, we initialize an audio tower with an architecture identical to that of a strong pretrained video model. Trained from scratch on hundreds of thousands of hours of raw audio, the audio tower learns to generate realistic sound effects, as well as speech that conveys rich speaker identity and emotion. Fusion is obtained by jointly training the identical video and audio towers via blockwise exchange of timing (via scaled-RoPE embeddings) and semantics (through bidirectional cross-attention) on a vast video corpus. Our model enables cinematic storytelling with natural speech and accurate, context-matched sound effects, producing movie-grade video clips. All the demos, code and model weights are published at https://aaxwaz.github.io/Ovi














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Ovi, a new AI system that can make short movie clips with both video and sound at the same time. Instead of first making a silent video and then adding audio (or the other way around), Ovi creates both together in one go, so the lips, footsteps, explosions, music, and everything else line up naturally.
What are the main goals?
The researchers wanted to:
- Build one unified model that generates video and audio together, so they stay perfectly in sync (like a band playing in time).
- Keep the quality high for both visuals and sound (clear video, natural speech, realistic sound effects).
- Avoid complicated multi-step pipelines and “fix-it-later” tricks like post-processing lip-sync.
- Make the system easy to control with a single text prompt that describes both what you see and what you hear.
How does Ovi work? (Simple explanation)
Think of Ovi as two identical “brains” that learn together:
- One brain focuses on video (pictures over time).
- The other brain focuses on audio (sound over time).
- They have the same shape and size internally, like twin musicians reading the same sheet music. The “sheet music” is your text prompt.
Here are the key ideas, explained with everyday analogies:
- Twin backbones: The audio and video parts of Ovi are built the same way, so neither is weaker or mismatched. This makes it easier for them to “talk” to each other.
- Block-by-block conversation (cross-attention): After every thinking step (block), the audio brain looks at what the video brain is doing, and the video brain looks at the audio brain. Imagine two dancers who keep checking each other’s moves so they stay in sync.
- One prompt for both: A single text prompt (processed by a frozen LLM called T5) describes the scene and the sounds. Both the video and audio brains read this same prompt. This makes the story coherent—what you see supports what you hear, and vice versa.
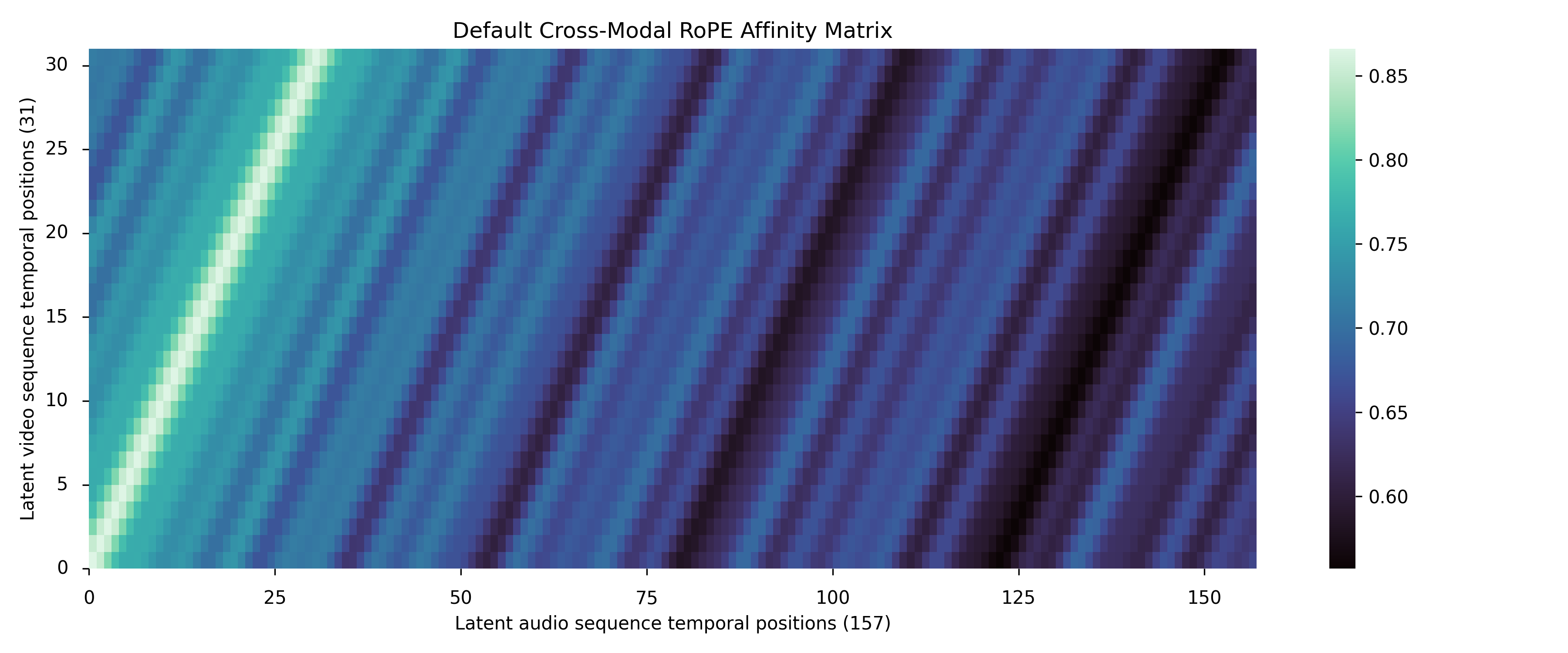
- Matching different speeds (RoPE scaling): Video and audio move at different “speeds” in time (fewer video frames than audio steps). The model adjusts their “time rulers” so their beats line up—like setting metronomes to match tempos. This helps lips match speech and actions match sound effects.
- Working in “latent” space: Instead of dealing with raw pixels and raw waveforms (which are huge), the model first compresses them into compact “sketches” (latents) that are easier to learn from. For audio, it turns the sound into a mel-spectrogram, compresses it, and later turns it back into sound with a vocoder.
- Diffusion/flow matching (learning to turn noise into content): The model learns to start from random noise and gradually shape it into realistic audio and video. You can think of it as learning the smoothest path from “static” to “movie.”
How they trained it
Training happened in two main stages:
- Teach the audio brain first
- They trained the audio part from scratch on tons of audio: mostly speech (with different voices, emotions, and accents) plus lots of sound effects (like doors closing, birds chirping).
- This teaches it to speak naturally and to produce realistic effects.
- Fine-tune both together
- They pair the audio brain with a strong video brain (from an open video model) and turn on the block-by-block conversations between them.
- They train on lots of real video+audio clips that are carefully filtered to be truly in sync (using a tool that checks lip-sync).
- During this training, both sides learn to stay in time and agree on meaning, while keeping their individual quality.
Building a high-quality dataset
To make sure training examples were good:
- They cut videos into short clips with movement and high resolution.
- They checked that speech and lip motion were in sync, removing bad clips.
- They used an AI to write detailed captions that describe both visuals and sounds (like noting when speech starts/ends, or which sounds are present).
- They resized and packaged everything consistently so the model sees clean, uniform data.
What did they find?
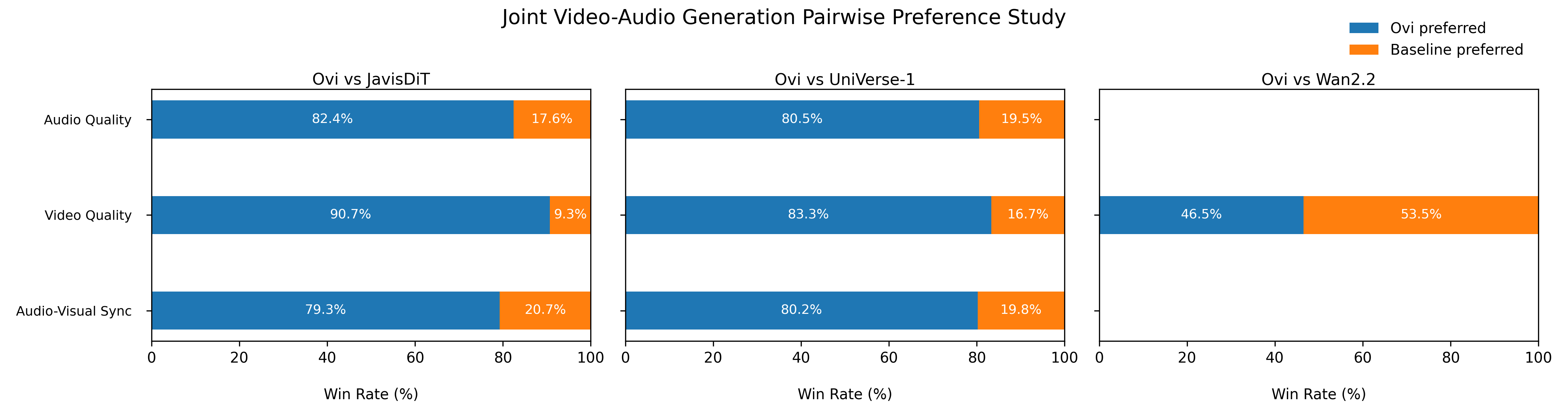
In human comparisons, people preferred Ovi over other open models in:
- Audio quality
- Video quality
- Audio–video synchronization
Even though the video quality is just slightly below the very large video-only base model (because Ovi now focuses on both audio and video together), Ovi still delivers more consistent and believable “whole” clips—where what you see matches what you hear.
They also tested the audio-only part (the audio brain) on both text-to-audio and text-to-speech tasks. It performed competitively compared to specialized models, which is impressive because it does both jobs in one model.
Why is this important?
- Natural storytelling: Movies, trailers, and shorts need both good visuals and good sound. Ovi creates both at once, which makes scenes feel more alive and believable.
- Simpler workflow: Creators don’t need a separate tool for video and another for audio, or tricky alignment steps afterward.
- General-purpose audio: It’s not just voices—it can do footsteps, animals, cars, weather, music-like elements, and more, and put them in the right spots.
What are the limits and what’s next?
- Length: Right now, Ovi focuses on short clips (about 5 seconds). Longer scenes and stories will need smart ways to chain clips together while staying consistent.
- Speed and compute: The model is big, so generating clips takes time. Future versions could be sped up using compression or distillation tricks.
- Audio fidelity: The current setup uses 16 kHz audio, which is good but not super high-resolution. Higher-quality audio could make music and subtle sounds even richer.
Bottom line
Ovi shows a clean, unified way to generate video and audio together. By building two equal “brains” that constantly talk to each other and read the same prompt, it creates clips where speech, sound effects, and visuals line up naturally—pushing open research closer to professional, movie-like results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a structured list of concrete gaps and open questions the paper leaves unresolved. Each point highlights what is missing, uncertain, or unexplored, and suggests specific directions for future research.
Data, annotations, and preprocessing
- Dataset transparency: the “internal” audio–video and audio-only corpora are not described (size breakdowns, domains, licenses, languages, speaker demographics, consent), hindering reproducibility and bias analysis.
- Captioning reliability: the MLLM-based video/audio captions (with <S>, <E>, <AUDCAP> tags) are not validated for accuracy, chronology, or hallucination rates; there is no study of how caption noise affects training and sync.
- Sync filtering scope: SyncNet thresholds are tuned for speech but not evaluated for non-speech events (e.g., impacts, footsteps); no ablation on offset/confidence cutoffs or their effect on lip-sync and action–sound alignment.
- Filtering bias: RAFT motion and aesthetic filters may systematically remove static scenes and low-motion content where audio remains critical; no analysis of downstream distribution shifts and failure modes.
- Aspect ratio handling: videos are normalized to a square 720×720 frame while “maintaining aspect ratio,” but the exact letterboxing/cropping strategy and its impact on content preservation and learned framing are not documented.
Evaluation methodology and metrics
- Lack of objective AV sync metrics: no reporting of standard synchronization measures (e.g., LSE-C/LSE-D via SyncNet, AV offset error, phoneme–viseme alignment scores).
- Missing standard video quality metrics: no FVD/KVD, VBench, or VQ/IQA metrics; the claimed slight degradation vs Wan2.2 is not quantified.
- Audio quality/generality gaps: TTS evaluation uses only WER; no MOS, naturalness, emotion/prosody, or speaker similarity metrics; T2A relies on FD/IS/CLAP but lacks task-specific SFX/music fidelity metrics.
- Human study design details: the 50-rater pairwise test lacks statistical reporting (CIs, inter-rater reliability, power analysis, trial count, randomization controls).
- Cross-model comparison: no head-to-head comparisons with closed-source frontier models (e.g., Veo3) using standardized public benchmarks or proxy tasks.
- Generalization tests: no stress tests for multi-speaker scenes, occlusion, off-screen sounds, dense action, or out-of-domain scenarios.
Architecture and training choices
- Cross-attention design ablations: no study of where/how often to place cross-modal attention, head allocation, or sparsity vs dense fusion, and their cost–quality trade-offs.
- Trainable subset selection: freezing FFNs is justified for memory, but there’s no ablation on which layers to unfreeze for best alignment/fidelity and minimal forgetting.
- Loss weighting: the choice of λ_v=0.85, λ_a=0.15 is not motivated; no sensitivity analysis of modality-weighting on sync and unimodal quality.
- Shared-t schedule and noise coupling: reliance on a shared timestep with independent noises is not compared to alternatives (e.g., coupled noise, asynchronous schedules, curriculum schedules).
- CFG and solver settings: no ablations on CFG scales per modality, joint vs per-branch guidance, or different ODE solvers/step counts for quality–speed trade-offs.
Temporal alignment and RoPE scaling
- RoPE scaling choice: the fixed 31/157 factor is derived from one setting (24 fps, 16 kHz, specific hop); no sensitivity analysis to fps, sampling rates, hop sizes, or variable-length sequences.
- Alternative alignment strategies: no comparison to learned alignment modules (e.g., alignment tokens, time-warped attention, cross-modal CTC losses) or auxiliary sync losses for impulse-like events.
- Robustness to misalignments: while strict sync filtering is used, the model’s tolerance to residual mis-sync or jitter is not quantified.
Audio representation and fidelity
- Bandwidth limitations: the 16 kHz 1D-VAE path and BigVGAN decoding are acknowledged as limiting; no experiments with higher SR, stereo/binaural, spatial cues, or music-optimized latents.
- Vocoder artifacts: no measurement of vocoder-induced degradations (noise, pre-echo, phase, timbre smearing), especially for complex music and SFX.
- End-to-end alternatives: no exploration of end-to-end waveform or codec-based latents (e.g., RVQ) and their impact on sync and timbre realism.
Control, conditioning, and usability
- Prompting protocol: the exact inference-time combined prompt format and best practices (e.g., weighting transcripts vs audio descriptions, tag usage) are not specified or evaluated.
- Controllability: no mechanisms to explicitly control voice identity, prosody, BGM vs SFX layering, loudness/ducking, or source separation; no evaluation of prompt adherence vs overconditioning.
- Multilingual support: language coverage of T5 and training data is unspecified; cross-lingual TTS quality, accent control, and code-switching are untested.
- Conditional modes: the unified generator is not evaluated for A2V/V2A/editing modes or with reference voices/images, which are common production needs.
Scalability, efficiency, and deployment
- Runtime and compute cost: no reporting of sampling latency, throughput, memory usage, energy, or hardware requirements for 720p/24fps generation.
- Distillation and streaming: one-pass streaming and distillation (e.g., DMD2) are only proposed; no implemented results or latency/quality trade-off curves.
- Longer-form generation: the chunked causal approach is suggested but untested; no study on boundary artifacts, scene transitions, or story consistency across chunks.
- Variable resolution/fps: generalization beyond 720p/24fps (e.g., 1080p, 30/60 fps, cinematic ARs) is not addressed.
Safety, ethics, and legal considerations
- Data consent and licensing: use of internal data lacks statements on consent, rights, and compliance; voice re-synthesis risks are not mitigated.
- Safety filtering: no content safety, watermarking, provenance, or misuse-prevention strategies (e.g., anti-impersonation) are described.
- Fairness and bias: no audits for demographic fairness in voice, lip-sync, or visual depictions; no bias analyses across languages, accents, or cultures.
Reproducibility and release
- Dependency on Wan2.2: training relies on a specific video backbone; availability, licensing, and replaceability with open alternatives are unclear.
- Incomplete release for training: even if code/model checkpoints are released, the lack of public data and annotation tools (e.g., the captioning MLLM setup) limits reproducibility.
- Hyperparameter and schedule details: step counts and batch sizes are given, but curriculum details, augmentation policies, and LR schedules per module are too sparse for faithful replication.
Analysis and interpretation
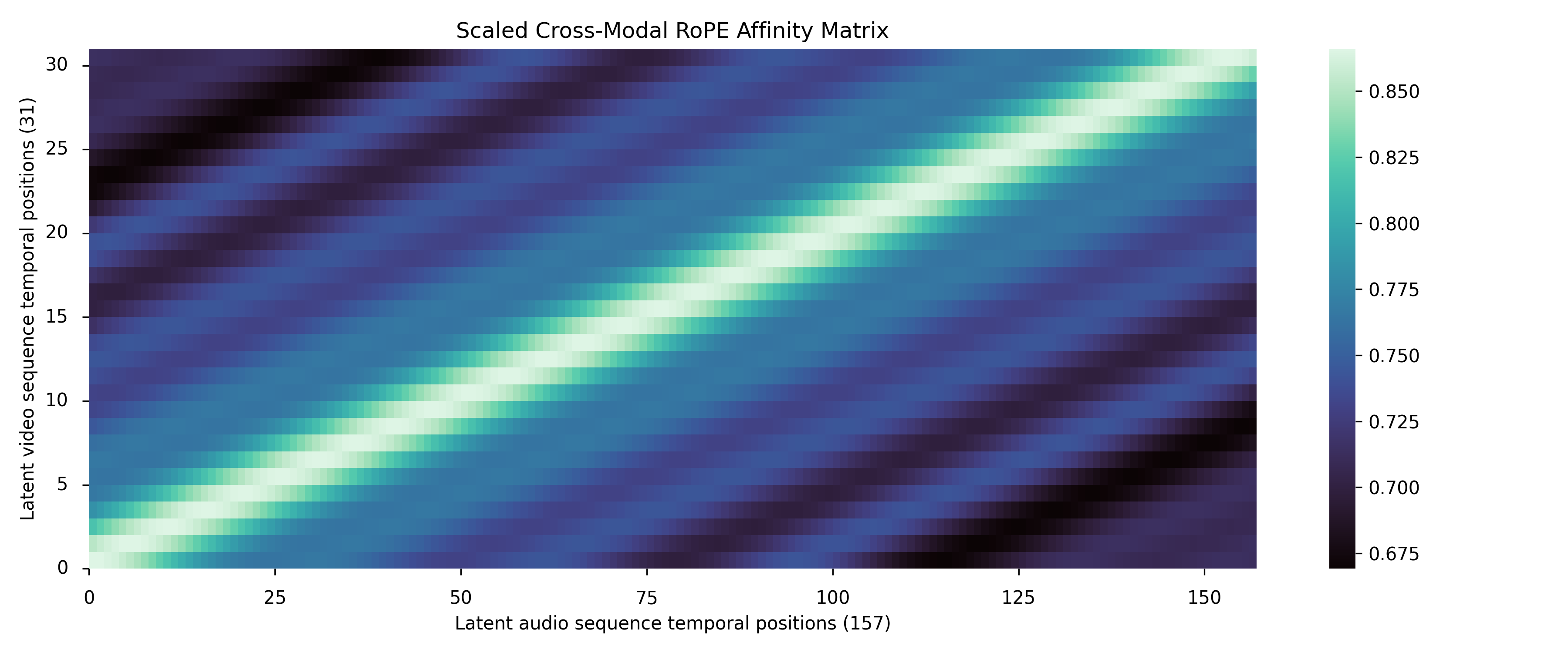
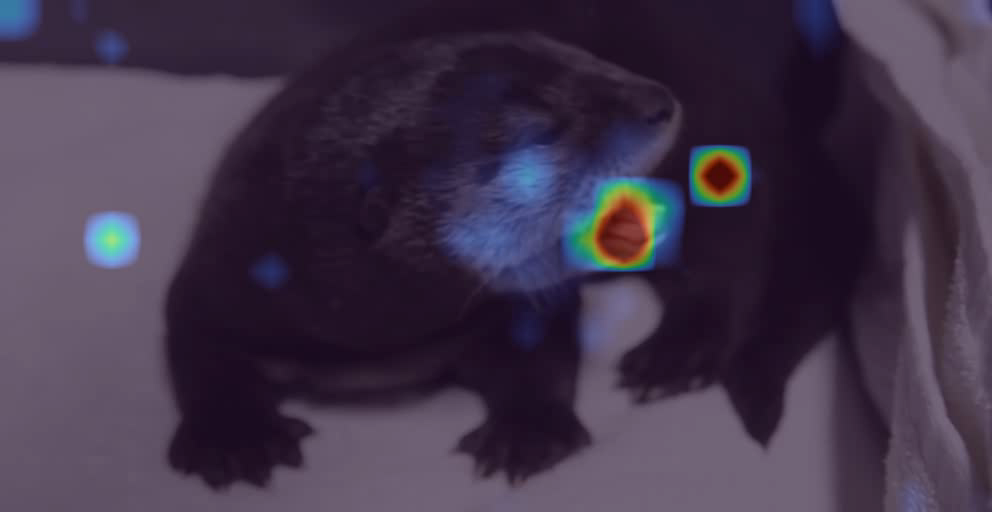
- Attention diagnostics: the qualitative cross-attention heatmaps are not linked to quantitative alignment metrics or layer-wise causal analyses.
- Failure mode taxonomy: no systematic characterization of typical errors (e.g., off-by-one phoneme lips, off-screen source mismatch, gender/identity mismatches) or their frequencies.
- Scaling laws: no study of how data/model/compute scaling affects synchronization quality, modality balance, or degradation vs the base video model.
These gaps suggest clear, actionable next steps: introduce objective AV sync metrics; conduct ablations on cross-modal fusion, loss weights, and RoPE scaling; expand audio bandwidth and spatialization; document data composition and ethics; measure runtime and distill; and systematize controllability, multilingual support, and longer-form generation.
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases that leverage Ovi’s unified, one-pass audio–video generation, its twin-DiT fusion architecture, scaled RoPE timing alignment, and the paper’s data/annotation pipeline. Each item includes sector linkage and feasibility notes.
- Cinematic previsualization and storyboarding
- Sector: media and entertainment, advertising
- Use case: Generate 5-second animatics with synchronized VO, SFX, and scene-appropriate ambience directly from a combined text prompt (including speech and audio tags).
- Tools/products/workflows: “Ovi Studio” plugin for After Effects/Premiere; a prompt-to-clip storyboard tool that accepts <S>/<E>/<AUDCAP> tags; batch generation for shot exploration.
- Assumptions/dependencies: Current model supports ~5s at 720×720/24 fps; 11B parameters imply notable inference cost.
- Auto-Foley and ambient bed for existing B-roll
- Sector: post-production, social media
- Use case: Feed a short, silent clip to the audio branch (conditioned on video tokens) to synthesize scene-matched SFX and ambience (e.g., waves, footsteps, crowd noise) without manual Foley.
- Tools/products/workflows: “Ovi Foley” panel in NLEs; preset libraries (“city street,” “forest trail”) derived from audio descriptions.
- Assumptions/dependencies: Requires exposing the audio-only pathway conditioned on video latents; 16 kHz latent pipeline may flatten high-frequency detail; licensing alignment for the MMAudio VAE/BigVGAN.
- Short-form marketing content generation
- Sector: marketing, product growth, creator economy
- Use case: Generate TikTok/Reels-ready teaser clips with on-brand voice timbre, emotion, and tightly synced visuals for A/B testing.
- Tools/products/workflows: “AVFusion API” with brand voice presets; content ops dashboards to iterate prompts rapidly.
- Assumptions/dependencies: Brand safety and provenance labeling; audio bandwidth may limit high-fidelity music cues.
- Micro-learning snippets with lip-synced narration
- Sector: education, corporate training
- Use case: Produce short concept explainers with mouth movements synced to narrated text; useful for flashcards and bite-sized lessons.
- Tools/products/workflows: LMS integration; prompt templates that specify speech segments via <S>/<E> tags.
- Assumptions/dependencies: TTS WER ≈ 3–4% is generally acceptable for short, scripted lines; longer lessons will require chunking.
- Synthetic datasets for multimodal perception research
- Sector: academia, AI/ML R&D
- Use case: Generate labeled, synchronized AV pairs to train/benchmark lip-reading, AV event detection, or cross-modal retrieval.
- Tools/products/workflows: “Verse-Bench augmentation kit”; automatic alignment QA via cross-attention heatmaps and SyncNet thresholds.
- Assumptions/dependencies: Biases reflect training data composition; careful prompt design needed for distributional coverage.
- AV synchronization QA and diagnostics
- Sector: media tools, quality assurance
- Use case: Use Ovi’s cross-attention visualizations to audit lip-sync or action–sound alignment in pipelines; flag out-of-sync assets.
- Tools/products/workflows: “AttentionHeatmap QA” visualizer; thresholding based on offset ≤ 3 and confidence > 1.5 (from SyncNet).
- Assumptions/dependencies: Heuristic thresholds can be task-dependent; visual attention ≠ perfect sync—needs corroborating metrics.
- Data engineering pipeline for AV curation
- Sector: data operations, MLOps
- Use case: Adopt the paper’s multi-stage pipeline (scene detection, RAFT motion filtering, aesthetic scoring, SyncNet gating, MLLM captioning with audio tags) to curate high-synchrony corpora.
- Tools/products/workflows: “Ovi DataOps” recipes; reproducible packing (720×720, 24 fps, raw wave bytes).
- Assumptions/dependencies: Access to an MLLM for rich captions; compute budget for large-scale SyncNet inference.
- Branded voice/emotion presets for rapid creative iteration
- Sector: advertising, creator platforms
- Use case: Predefine speaker timbre, pitch, prosody, and emotion, then re-use across scenes for consistent brand identity.
- Tools/products/workflows: Prompt library manager; emotion sliders mapped to T5 conditioning attributes.
- Assumptions/dependencies: Stability of timbre across short clips; caution when implying real-person likeness (consent).
- Rapid prototyping of game cutscenes and event audio
- Sector: gaming
- Use case: Generate short cutscene moments with accurate SFX (weapon clacks, footsteps) and ambient cues for design iteration.
- Tools/products/workflows: Unreal/Unity plugin; export to engine timelines/sound cues for replacement by final assets later.
- Assumptions/dependencies: 5s limit suits moment-level prototyping; not a substitute for shipping-grade audio mastering.
- Compliance-friendly synthetic AV for internal comms
- Sector: enterprise, HR, operations
- Use case: Create short internal announcements with synthesized presenters and narration, reducing production overhead.
- Tools/products/workflows: Template-based prompt forms; watermarking and provenance metadata embedded in outputs.
- Assumptions/dependencies: Organizational policy compliance (synthetic disclosure, consent); legal review for likeness use.
- Audio description augmentation for accessibility
- Sector: accessibility, public sector
- Use case: Generate descriptive audio layers for short visual clips (e.g., describing actions for visually impaired users).
- Tools/products/workflows: “AUDCAP assist” mode driven by the MLLM-style audio descriptions.
- Assumptions/dependencies: Requires careful prompt engineering to avoid hallucinations; human-in-the-loop validation recommended.
- Content moderation aids: lip-sync integrity checks
- Sector: policy, platform trust & safety
- Use case: Apply SyncNet-like gating and attention-based indicators to detect egregiously out-of-sync or manipulated speech clips.
- Tools/products/workflows: Platform-side AV sync score; triage pipelines for human review.
- Assumptions/dependencies: Threshold tuning; false positives for artistic edits; provenance signals should accompany automated checks.
Long-Term Applications
These applications require further research and engineering—longer durations, causal streaming, higher-fidelity audio, safety guardrails, and scaling efficiencies.
- Long-form, multi-shot cinematic generation
- Sector: media and entertainment
- Use case: Generate minute-scale sequences with consistent characters, music themes, and narrative continuity using chunk-wise causal audio/video as proposed in the paper’s future work.
- Tools/products/workflows: “Chunked Ovi” with causal backbones; inter-shot context memory; global story controllers.
- Assumptions/dependencies: Robust chunk stitching; identity and motif persistence; significant compute and data scale.
- Real-time streaming AV generation for live experiences
- Sector: live events, gaming, interactive media
- Use case: Causal, low-latency generation for interactive shows, VTubing, or in-game dynamic scenes with on-the-fly narration and SFX.
- Tools/products/workflows: Distilled models (e.g., DMD2-style) to reduce steps; sparse, causal students; streaming inference stacks.
- Assumptions/dependencies: Tight latency budgets; robust rate control; safety filters for live content.
- Cross-lingual dubbing and ADR with lip-matched visuals
- Sector: localization, post-production
- Use case: Replace speech in a target language while adjusting mouth movements and facial expressions to match phonetics/emotion.
- Tools/products/workflows: Phoneme-aware text conditioning; face/upper-body micro-motion controls; alignment QA.
- Assumptions/dependencies: Ethical use and consent; language-specific mouth-shape modeling; higher audio bandwidth for realism.
- Virtual humans and conversational agents with scene-aware embodiment
- Sector: consumer software, customer support, education
- Use case: Chatbots that respond not only with speech but also generate matched visual scenes and gestures for richer interaction.
- Tools/products/workflows: Integrations with LLMs (T5/LLM fusion); persona presets; safety/provenance tooling.
- Assumptions/dependencies: Identity safety policies; persistent character memory; cost to serve at scale.
- Immersive education and language learning at scale
- Sector: education
- Use case: Multi-minute lessons with fine-grained lip-sync, demonstrations, and adaptive audio pacing for pronunciation training.
- Tools/products/workflows: Curriculum-aware prompt frameworks; pronunciation scoring via AV alignment metrics.
- Assumptions/dependencies: Extended-duration support; evaluation of learning outcomes; diversified, bias-aware content generation.
- High-fidelity audio and spatial realism
- Sector: music, AR/VR/XR
- Use case: Generate spatially-aware audio (binaural/ambisonic) and high bandwidth (≥48 kHz) music tied to visual events in XR experiences.
- Tools/products/workflows: Replacement of 1D-VAE with higher-bandwidth latent models; spatial audio decoders; scene geometry conditioning.
- Assumptions/dependencies: New audio latents and vocoders; visual-to-acoustic scene mapping; increased training/inference costs.
- Robotics and autonomous systems simulation
- Sector: robotics
- Use case: AV simulation suites where robots learn to associate sounds (machinery, footsteps) with visual cues and timing for perception/planning.
- Tools/products/workflows: “AVSim” asset generator; curriculum schedules for rare audio events; sensor-model conditioning.
- Assumptions/dependencies: Domain gap mitigation; realism in acoustic spaces; task-specific evaluation.
- Standardization of AV sync benchmarks and provenance
- Sector: policy, standards bodies
- Use case: Develop public benchmarks (thresholds, offsets, human PWR studies) and provenance standards for synthetic AV media.
- Tools/products/workflows: Open Verse-Bench-like suites; policy toolkits for disclosure/watermarking; content lifecycle metadata.
- Assumptions/dependencies: Multistakeholder consensus; interoperability across platforms; balancing privacy and transparency.
- Enterprise AV communications platforms
- Sector: enterprise SaaS
- Use case: Auto-generate onboarding, safety briefings, and localized training videos with consistent brand personas and synchronized narration.
- Tools/products/workflows: Role-based prompt templates; compliance auditing; governance and access controls.
- Assumptions/dependencies: Governance frameworks; regional legal considerations; scalable inference infrastructure.
- Co-creative multimodal editors
- Sector: creative software
- Use case: Timeline editors where text edits update both visuals and audio in lockstep (e.g., “make the speaker sound more excited and raise their hand”).
- Tools/products/workflows: Bidirectional attention controls exposed to users; semantic diff tools; non-destructive editing layers.
- Assumptions/dependencies: Intuitive UX for fusion controls; guardrails to prevent harmful manipulations; model interpretability features.
- AV generation for therapeutic and clinical training
- Sector: healthcare
- Use case: Controlled, ethically designed scenarios (e.g., exposure therapy environments, clinical simulation vignettes) with synchronized patient/clinician speech and situational SFX.
- Tools/products/workflows: Clinical content review pipelines; privacy-preserving persona presets; audit trails.
- Assumptions/dependencies: Medical oversight; high-fidelity audio upgrades; strict safety/provenance requirements.
- Generalized cross-modal fusion SDK
- Sector: software/ML
- Use case: Reusable fusion primitives (blockwise bidirectional attention, RoPE scaling utilities, joint ODE solvers) for teams building AV systems or extending to other modalities (e.g., text–audio–video triads).
- Tools/products/workflows: “FusionSDK” with RoPE scaling library and attention modules; reference training recipes (pretrain/fine-tune scheme).
- Assumptions/dependencies: Compatibility with varied backbones; licensing for pretrained components; community adoption and maintenance.
Glossary
- 1D VAE: A one-dimensional Variational Autoencoder used to encode audio sequences into compact latents. "operate in a compact latent space using a pretrained 1D VAE from MMAudio~\cite{cheng2025mmaudio}."
- 3D VAE: A three-dimensional Variational Autoencoder for spatiotemporal compression of video. "pretrains a 3D VAE to achieve compression at 16x16x4"
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates to improve training stability. "We used the AdamW optimizer with parameters ."
- Audio-To-Video (A2V): The task of generating video conditioned on audio. "text-to-video (T2V), audio-to-video (A2V), and video-to-audio (V2A)"
- BigVGAN: A neural vocoder that converts spectrograms or latents into high-quality audio waveforms. "vocoded into waveforms with BigVGAN~\cite{lee2022bigvgan}."
- bf16 precision: A 16-bit floating-point format (bfloat16) used to accelerate training with minimal loss of accuracy. "All models were trained at bf16 precision leveraging DeepSpeed \citep{rasley2020deepspeed} for efficient sharded distributed Data Parallel (DP) training."
- bidirectional cross-modal attention: Attention mechanism where audio and video streams attend to each other in both directions. "via blockwise, bidirectional cross-modal attention inserted in every transformer block."
- blockwise cross-modal fusion: Integrating and exchanging information across modalities at every transformer block. "By using blockwise cross-modal fusion of twin-DiT modules, Ovi achieves natural synchronization"
- CLAP: Contrastive Language-Audio Pretraining; a metric/model assessing text–audio semantic alignment. "and CLAP evaluates textâaudio semantic alignment."
- Classifier-Free Diffusion Guidance: A method to steer diffusion sampling by mixing conditional and unconditional predictions without a separate classifier. "Classifier-Free Diffusion Guidance \citep{ho2022classifier}"
- ConvNet: A convolutional neural network architecture for processing grid-like data such as images or spectrograms. "uses a ConvNet architecture to learn a joint embedding between sound and mouth images"
- Data Parallel (DP): A distributed training strategy that replicates the model across devices and splits the data batch among them. "sharded distributed Data Parallel (DP) training."
- DeepSpeed: An optimization and distributed training library for large-scale models. "leveraging DeepSpeed \citep{rasley2020deepspeed} for efficient sharded distributed Data Parallel (DP) training."
- Diffusion Transformer (DiT): A transformer-based diffusion model operating on latent representations. "Diffusion Transformer (DiT) architecture \citep{peebles2023scalable} inside latent space with a Flow Matching \citep{lipman2022flow} loss"
- Flow Matching: A generative training objective that learns velocity fields to transport noise to data distributions. "We optimize a flow matching objective on audio latents:"
- Inception Score (IS): A metric for generative quality based on classifier confidence and diversity. "Inception Score (IS) \citep{salimans2016improved}"
- latent space: A compressed representation domain where models operate and generate. "inside latent space with a Flow Matching \citep{lipman2022flow} loss"
- mel-spectrograms: A time–frequency representation mapping to the mel scale; commonly used in audio modeling. "converted into mel-spectrograms"
- Mixture-of-Fusion network: An architecture that combines multiple modalities and signals through learned fusion mechanisms. "a Mixture-of-Fusion network that fuses text, video, instructions, and V2A-predicted energy contours"
- Multimodal LLM (MLLM): A LLM that processes and reasons over multiple modalities (e.g., audio, video, text). "We use an MLLM to provide a verbose video caption"
- ODE solver: A numerical integrator for ordinary differential equations used in deterministic diffusion sampling. "and are jointly integrated with a single ODE solver."
- Pairwise Win Rate (PWR): A human preference metric computed from pairwise comparisons of generated samples. "We report the Pairwise Win Rate (PWR)"
- RAFT (optical flow model): A deep network for dense optical flow estimation between frames. "employ the optical flow model RAFT \citep{teed2020raft} to filter out static videos"
- Rotary Positional Embeddings (RoPE): A positional encoding technique that applies rotations to attention keys/queries to encode relative positions. "we apply Rotary Positional Embeddings (RoPE) to both modalities"
- RoPE frequency scaling: Adjusting RoPE angular frequencies to align differing temporal resolutions across modalities. "scale the RoPE frequencies of the audio branch by "
- Short-Time Fourier Transform (STFT): A windowed Fourier transform for time–frequency analysis of audio signals. "transformed with Short-Time Fourier Transform (STFT)"
- SyncNet: A model for detecting audio–visual lip-sync by learning joint embeddings of sound and mouth images. "We adopt the widely-used SyncNet \citep{chung2016out} model"
- T5 encoder: The text encoder component from the T5 model used to condition both audio and video branches. "A single frozen T5 encoder conditions both branches"
- Text-To-Speech (TTS): Generating speech audio from text input. "robust text-to-speech (TTS) modeling"
- Text-To-Video (T2V): Generating video content from a text prompt. "text-to-video (T2V)"
- UniPC solver: A predictor–corrector sampler for diffusion ODEs that improves stability. "We employ the UniPC \citep{zhao2023unipc} solver"
- Video-To-Audio (V2A): Generating audio conditioned on video content. "video-to-audio (V2A)"
Collections
Sign up for free to add this paper to one or more collections.

