- The paper introduces dLLM-Var, a diffusion LLM architecture that natively supports variable-length generation via explicit [EOS] token prediction.
- It employs a deterministic masking strategy, multi-sample packing, and block diffusion inference to achieve up to 30.1× speedup over prior models.
- Experimental results show competitive accuracy across benchmarks and enhanced self-correction, making it practical for real-world applications.
Diffusion LLMs with Native Variable Generation Lengths: Technical Summary and Implications
Introduction and Motivation
Diffusion-based LLMs (dLLMs) have emerged as a promising alternative to autoregressive (AR) transformers, offering substantial parallelism and efficient inference. However, a critical limitation of prior dLLMs is their reliance on fixed generation lengths, which must be specified as a hyperparameter before decoding. This constraint impedes practical deployment, leading to inefficiencies, hallucinations, and inflexibility in applications where output length is unpredictable (e.g., OCR, open-ended dialogue). Block diffusion models partially address this by enabling variable-length generation, but at the cost of reduced parallelism and limited self-correction due to block-wise attention masking.

Figure 1: Overview of probabilistic modeling paradigms for text generation, contrasting AR, vanilla dLLMs, and dLLM-Var in terms of parallelism and generation length flexibility.
The paper introduces dLLM-Var, a diffusion LLM architecture and training paradigm that natively supports variable-length generation while maintaining high parallelism and full attention. The approach centers on accurate [EOS] token prediction, enabling block-wise diffusion inference with unrestricted sequence termination and efficient KV cache reuse.
Failure Modes of Prior dLLMs
Empirical analysis reveals that standard dLLMs (e.g., LLaDA Base and LLaDA Instruct) fail to generate [EOS] tokens at appropriate positions. The base model continues generating irrelevant content post-answer, while the instruction-tuned variant under pure diffusion prematurely fills trailing masks with EOS, resulting in non-informative outputs.

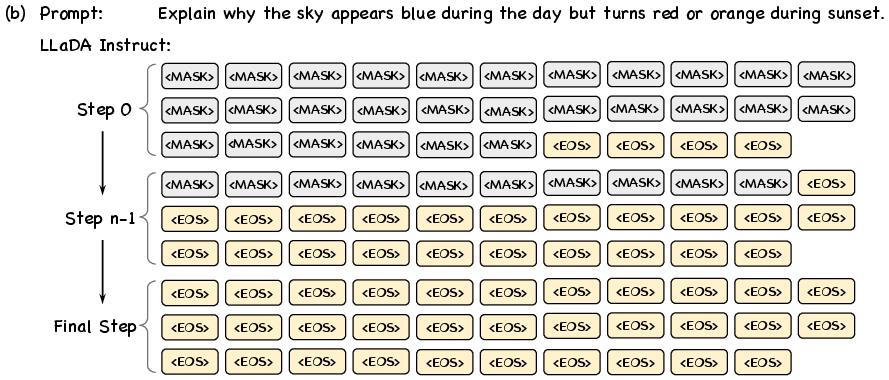
Figure 2: LLaDA Base and Instruct models exhibit failure modes in EOS prediction, either generating irrelevant content or terminating too early.
These observations underscore the necessity for a training regime that imparts semantic awareness of sequence boundaries and termination signals.
Methodology
Fixed Masking for Termination Tokens
dLLM-Var employs a deterministic noise schedule during training, wherein EOS tokens are always masked, while other tokens are masked with probability t sampled uniformly from [0,1]. This forces the model to learn to reconstruct EOS tokens contextually, rather than as a positional artifact.
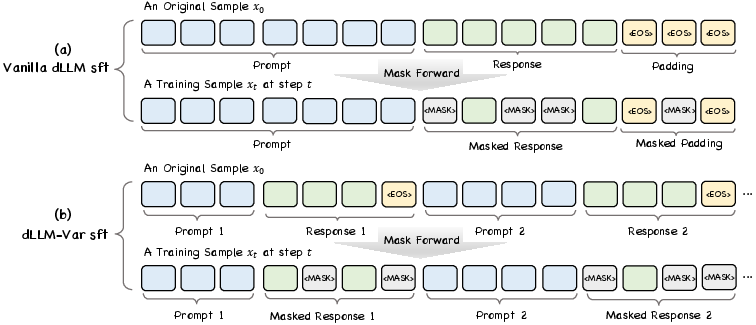
Figure 3: Masking strategy during training; prompt tokens are never masked, response tokens are masked probabilistically, and EOS is always masked.
Multi-Sample Packing with Full Attention
To further enhance EOS prediction, dLLM-Var concatenates multiple unrelated dialogue samples into a single training sequence, separated by EOS tokens, and applies full attention across the sequence. This exposes the model to diverse contexts and termination boundaries, compelling it to learn the semantic function of EOS in varied scenarios. Unlike block diffusion models, no specialized attention masks are used, preserving the model's ability to revisit and edit any token.
Block Diffusion Inference and KV Cache Reuse
During inference, dLLM-Var generates text in blocks of arbitrary size (default: 64 tokens), appending new blocks of [MASK] tokens until EOS is produced. Fully unmasked blocks and the prompt are stored in a KV cache, enabling efficient reuse and acceleration. A confidence threshold (0.9) is used to balance parallel decoding and output quality.
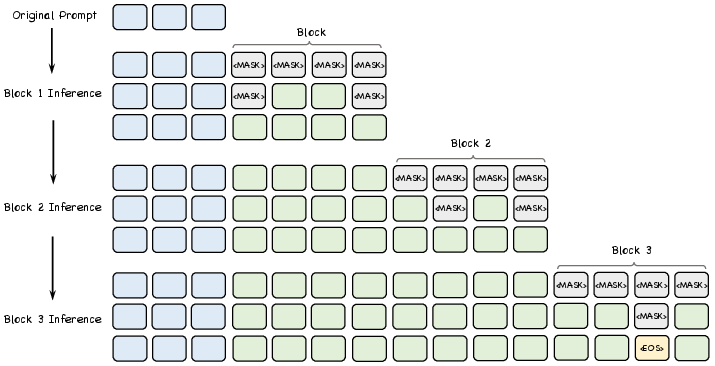
Figure 4: Inference process of dLLM-Var, illustrating block-wise generation and KV cache reuse for prompt and completed blocks.
Training and Evaluation Protocol
dLLM-Var was trained on 6.4M SFT pairs over 3 epochs using DeepSpeed ZeRO-2 across 64 GPUs, with a global batch size of 1M tokens and sample length of 8192. FP8 mixed precision was used for acceleration. Evaluation was performed with a maximum generation length of 1024, using bf16 precision and standard PyTorch code.
Figure 5: Training loss curve for dLLM-Var, indicating stable convergence.
Experimental Results
dLLM-Var achieves a 30.1× speedup over LLaDA-8B-Instruct and 2.4× faster inference than AR models (Qwen, Llama) without sacrificing accuracy. On six benchmarks (GSM8K, GPQA, BBH, MATH, HumanEval, MBPP), dLLM-Var matches or exceeds the performance of baseline dLLMs and AR models. Notably, it outperforms all baselines on BBH, GPQA, and MBPP, and maintains competitive results on GSM8K and MATH.
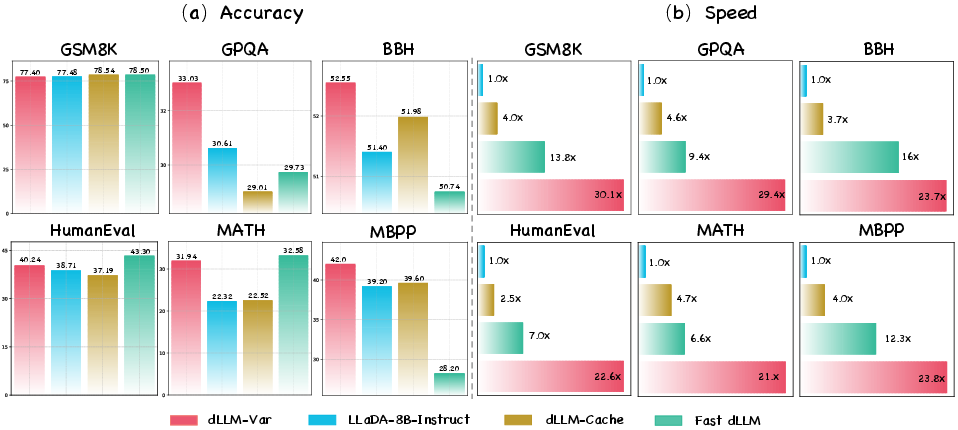
Figure 6: dLLM-Var delivers competitive accuracy and substantial speedup across six benchmarks compared to baseline methods.
Ablation studies confirm that block diffusion with full attention and native variable-length generation is superior to pure diffusion with fixed-length quotas, both in speed and accuracy.
Self-Correction and Editing Capabilities
A salient property of dLLM-Var is its ability to self-correct generated outputs. The model can revisit and amend earlier tokens, correcting both logical and grammatical errors in its own generations. This is enabled by the full attention mechanism, which is incompatible with block-wise attention masking.

Figure 7: dLLM-Var demonstrates self-correction by refining initial outputs to produce accurate and coherent answers.
Practical and Theoretical Implications
dLLM-Var advances the practical utility of diffusion LLMs by resolving the fixed-length bottleneck and enabling efficient, parallel, variable-length generation. The method's compatibility with standard KV cache mechanisms simplifies deployment and obviates the need for custom cache operators. The full attention regime not only facilitates editing and self-correction but also lays the groundwork for future research in iterative refinement and dynamic output adjustment.
From a theoretical perspective, the work demonstrates that semantic EOS prediction and multi-context training are sufficient to endow dLLMs with flexible generation capabilities, challenging the necessity of block-wise attention masking and specialized inference routines.
Future Directions
Potential avenues for further research include:
- Iterative refinement algorithms: Developing efficient strategies for selective editing of previously generated content, leveraging the full attention mechanism.
- Dynamic block sizing: Exploring adaptive block sizes during inference to optimize the trade-off between parallelism and output quality.
- Generalization to other modalities: Extending the variable-length diffusion paradigm to multimodal generative models (e.g., vision-language, code generation).
- Integration with step distillation: Employing step distillation techniques to further accelerate inference and reduce computational overhead.
Conclusion
dLLM-Var represents a significant advancement in the design and training of diffusion-based LLMs, overcoming the fixed-length constraint and unlocking efficient, parallel, variable-length generation with robust accuracy and self-correction capabilities. The approach is readily applicable to real-world scenarios and sets a foundation for future innovations in flexible, editable, and scalable generative modeling.