- The paper introduces pseudo-trajectory distillation to align token generation order with confidence levels, advancing the accuracy–parallelism trade-off.
- It proposes the Accuracy Under Parallelism (AUP) metric for evaluating diffusion LLMs, achieving up to 10× speedup over traditional models.
- The framework employs entropy-based multi-block decoding and adaptive KV-cache management, boosting throughput by 30–35% while maintaining high accuracy.
Ultra-Fast Diffusion LLMs via Pseudo-Trajectory Distillation: An In-Depth Analysis of d3LLM
Introduction
Diffusion LLMs (dLLMs) are rapidly emerging as a viable alternative to autoregressive (AR) models, providing unique operational paradigms such as parallel decoding, error correction, and random-order generation by leveraging bidirectional attention. However, their adoption in open-source environments has been limited by an inherent trade-off between decoding accuracy and parallelism—high parallelism typically sacrifices accuracy, and vice versa. The "d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation" (2601.07568) addresses this bottleneck by introducing a principled framework that systematically improves both training and inference pipelines in dLLMs, thus extending the accuracy–parallelism frontier.
Evaluation Metric: Accuracy Under Parallelism (AUP)
The paper introduces a pivotal new metric, Accuracy Under Parallelism (AUP), designed specifically for diffusion-based models. Traditional efficiency measures (e.g., tokens per second (TPS) or tokens per forward-pass (TPF)) and performance metrics (e.g., pass@1 or solve rate) are insufficient, as they ignore the nuanced compromise between rapid parallel decoding and model output fidelity.
AUP is formulated as a weighted area under the accuracy–parallelism curve, heavily penalizing accuracy drops as parallelism increases. This construction allows for a rigorous, hardware-independent assessment of algorithmic progress in dLLMs, focusing on throughput (TPF) rather than TPS to avoid machine-dependent artifacts.
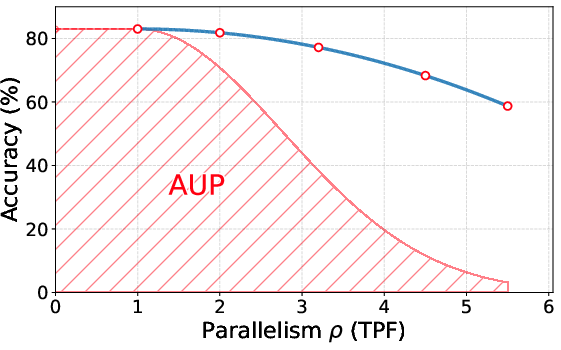
Figure 1: Visualization of the AUP metric quantifying the trade-off between accuracy and parallelism by the weighted area under the curve.
Training Paradigm: Pseudo-Trajectory Distillation
Standard dLLM training, reliant on random masking, fails to encode which tokens are confidently decodable at early stages—limiting parallelism under accuracy constraints. The d3LLM framework introduces pseudo-trajectory distillation, leveraging the teacher dLLM's own decoding trajectory rather than ground-truth token positions. This enables the student to learn not only the correct output, but also an optimal unmasking sequence reflecting high-confidence token generation.
The distillation recipe further employs curriculum learning effects:
- Progressive noise schedules, gradually increasing mask ratios to scaffold the student’s robustness.
- Progressive window sizes to accommodate extendable contexts, driving stable scaling of parallel generation.
This approach yields substantially improved parallelism, with empirical tokens-per-forward (TPF) enhancement up to 18% due to trajectory alignment and a further 12–19% via curriculum strategies.
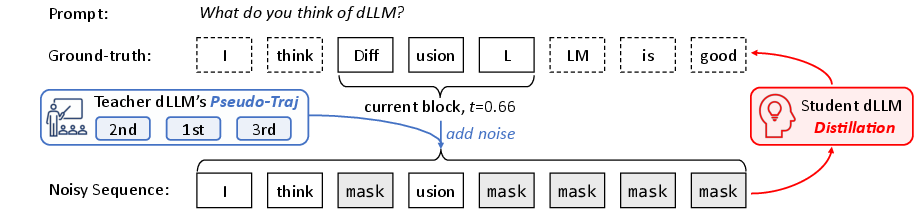
Figure 2: Schematic of pseudo-trajectory distillation, combining teacher decoding order and ground-truth to build noisy training sequences.
Inference Optimization: Entropy-Based Multi-Block Decoding
During inference, d3LLM introduces an entropy-based multi-block decoding policy. Unlike conventional blockwise diffusion approaches, the model decodes tokens from multiple future blocks in parallel, but prioritizes those with lowest entropy (highest confidence) to mitigate error propagation.
A dynamic state machine governs each block’s transition between inactive, activated, fully-activated, completed-but-stabilizing, and fully completed. This is coupled with a key–value cache (KV-cache) management strategy:
- KV-refreshes periodically restore cached states to mitigate reliance on stale or partial context, upholding generation quality in long outputs.
- Early stopping upon EOS token generation truncates unnecessary computation, shaving additional inference latency.
The net result is a 30–35% throughput increase in TPF, especially robust in long-context scenarios.
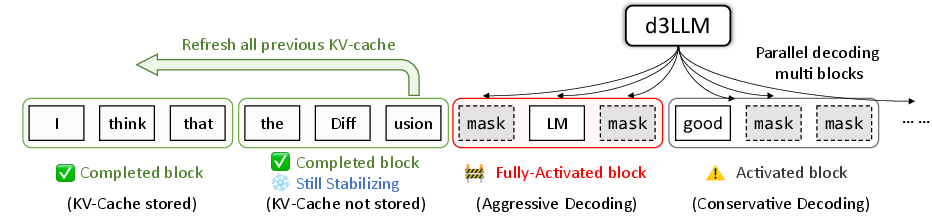
Figure 3: Multi-block decoding with entropy gating and KV-cache refresh to secure parallelism without loss in prediction accuracy.
Empirical Results: Pushing the Accuracy–Parallelism Frontier
On benchmark tasks spanning math reasoning (GSM8K-CoT, MATH), code synthesis (HumanEval, MBPP), and long-context reasoning, d3LLM outperforms contemporary dLLM baselines (LLaDA, Dream, Dream-Coder) and speculative AR models.
Strong numerical outcomes:
- Up to 10× speedup over vanilla dLLMs (e.g., LLaDA, Dream) and 5× speedup over AR baselines.
- D3LLM achieves the highest AUP scores on 9 out of 10 tasks, demonstrating its ability to maintain accuracy while aggressively scaling parallelism.
- On H100 GPUs, d3LLM-LLaDA achieves 288.9 TPS (5× AR baseline); on A100, 183.3 TPS (3.6× AR baseline), all with negligible accuracy drops.
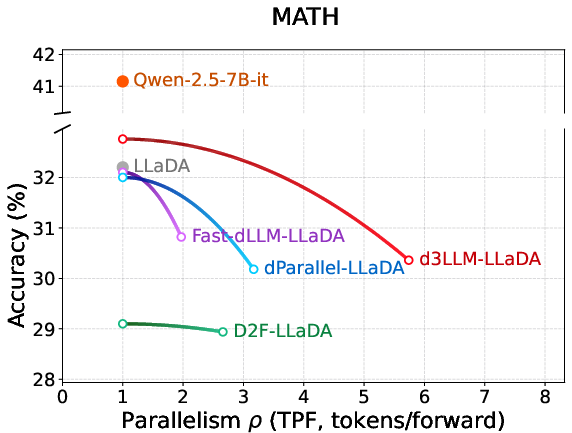
Figure 4: (a) Accuracy-parallelism curves on MATH for LLaDA-based models; (b) AUP radar chart for LLaDA methods; (c) AUP radar chart for Dream-based methods.
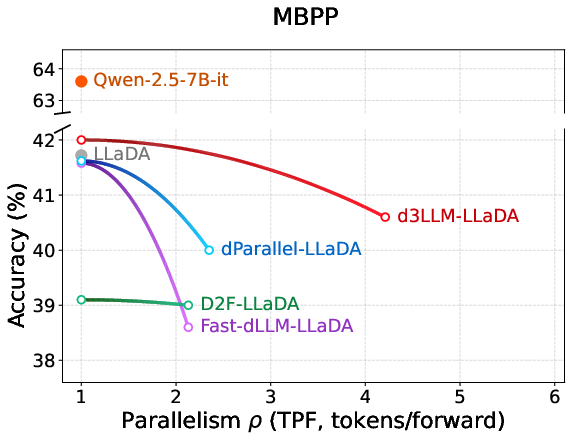
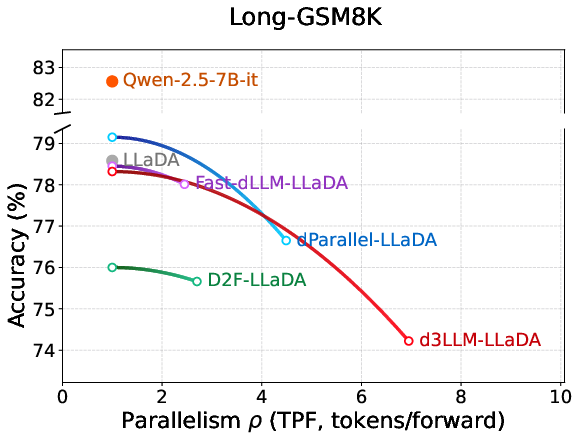
Figure 5: Exhaustive accuracy–parallelism curves for LLaDA-derived methods across major reasoning and coding tasks.
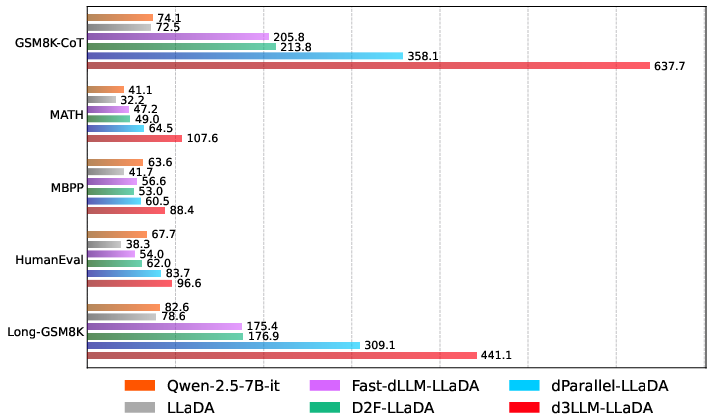
Figure 6: Histogram and radar visualization of AUP scores highlighting d3LLM's dominance.
Ablation and Hyperparameter Sensitivity
Ablation studies confirm the necessity of pseudo-trajectory distillation, curriculum noise scheduling, and adaptive window sizing for scaling parallelism without degrading accuracy. Removing any module significantly degrades AUP.
Hyperparameter sweeps show:
- Progressive (curriculum) strategies for mask ratio and window size robustly outperform fixed settings.
- Initial window size is critical for stable learning—starting too small or large leads to accuracy/parallelism instability.
Comparison with Speculative Decoding
While state-of-the-art speculative decoding (e.g., EAGLE-3) still achieves higher AUP under unconstrained FLOPs, d3LLM narrows the gap notably. Speculative methods rely on additional verification steps, which increase computational cost, whereas d3LLM provides competitive accuracy–parallelism trade-offs with minimal FLOP overhead.
Implications and Future Directions
d3LLM demonstrates that by aligning training signals with optimal token generation order—via pseudo-trajectory distillation—and employing entropy-driven, multi-block inference, diffusion LLMs can approach or surpass the efficiency of AR models with minimal loss in accuracy. The AUP metric enables fair evaluations independent of underlying hardware.
The framework is modular and transferable, suggesting that as more performant base dLLMs emerge (e.g. ReFusion, LLaDA 2.0), applying d3LLM’s recipes can further elevate efficiency. Potential future developments include integration with advanced speculative decoding, reinforcement learning for trajectory optimization, and system-level acceleration via tailored kernels and cache management.
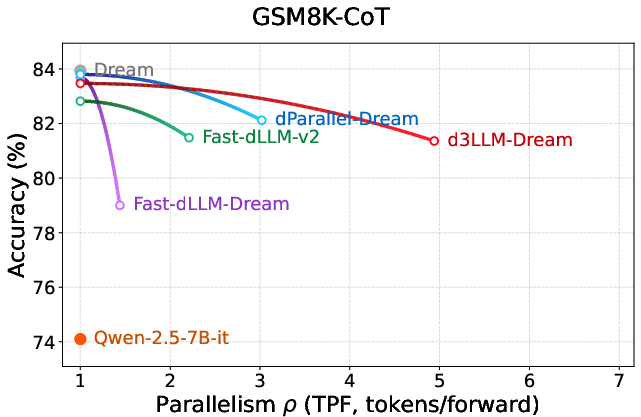
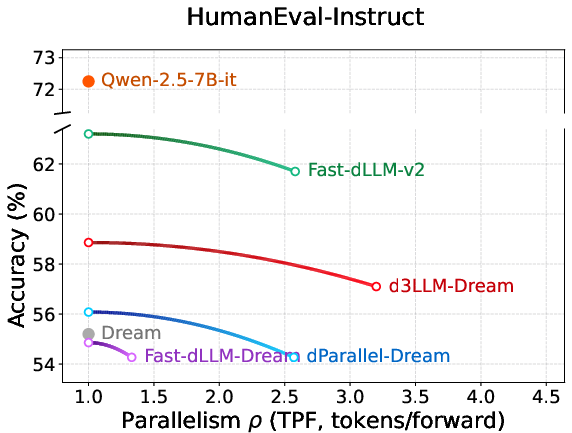
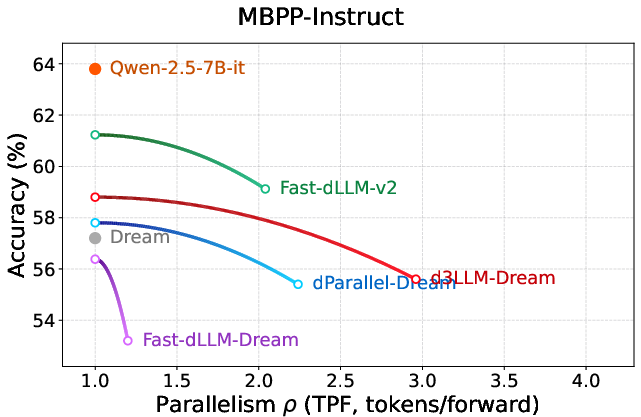
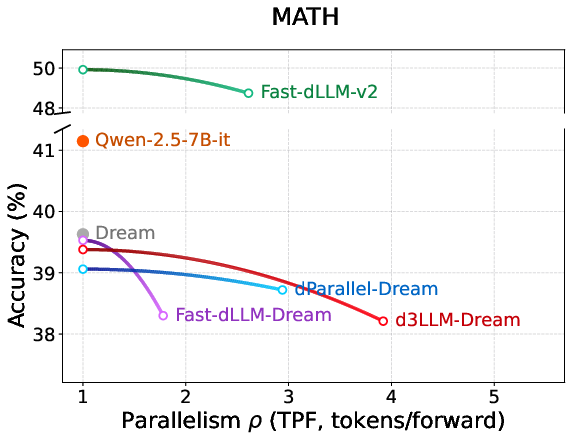
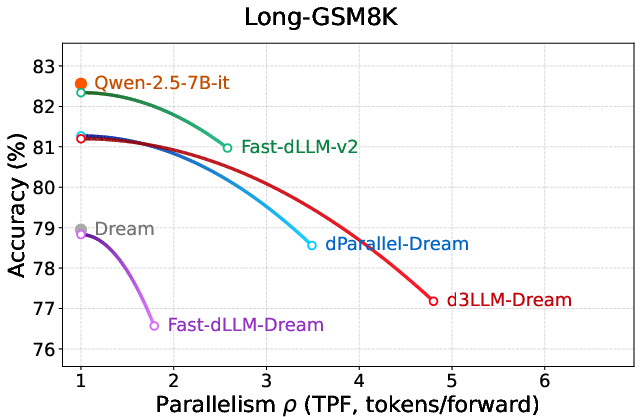
Figure 7: Parallelism–accuracy curves on Dream-based models, evidencing d3LLM's scalability across foundations.
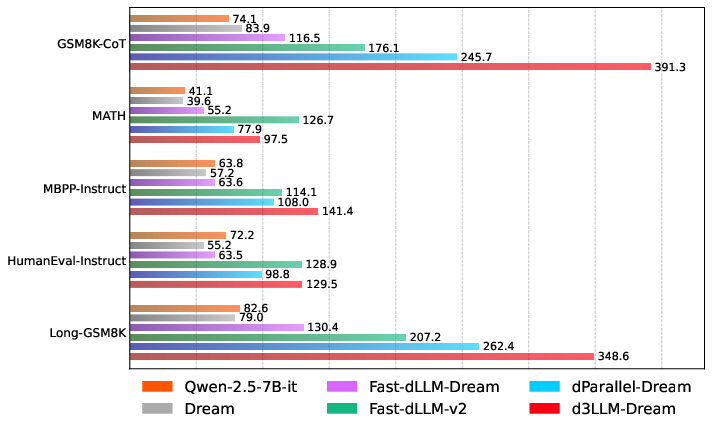
Figure 8: Radar and histogram AUP comparisons on Dream-based methods.
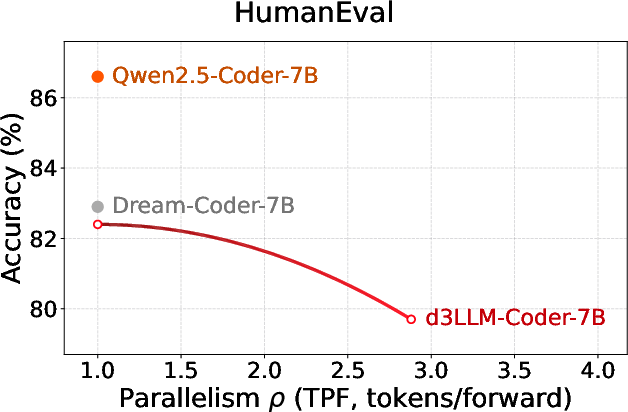
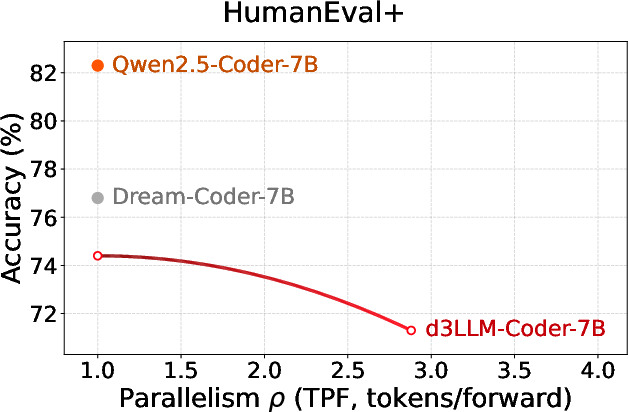
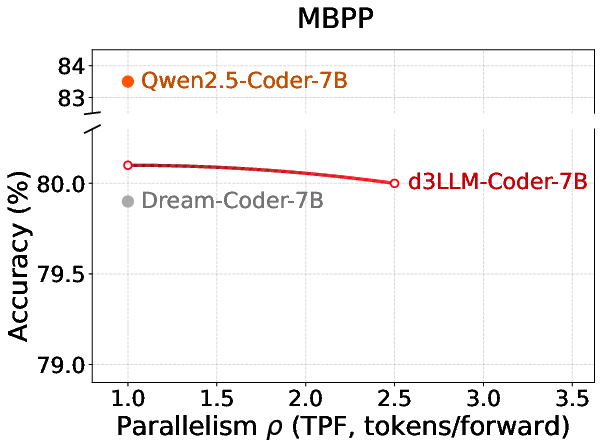
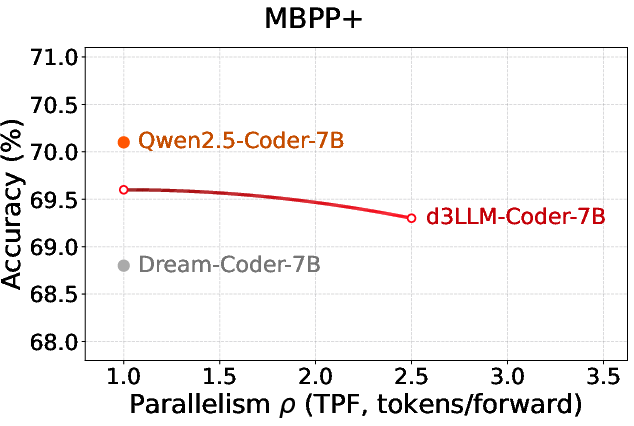
Figure 9: Coder benchmarks display accuracy–parallelism gains in d3LLM beyond AR baselines.
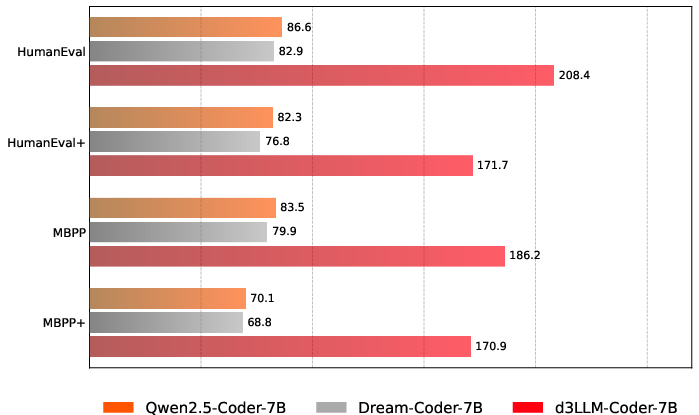
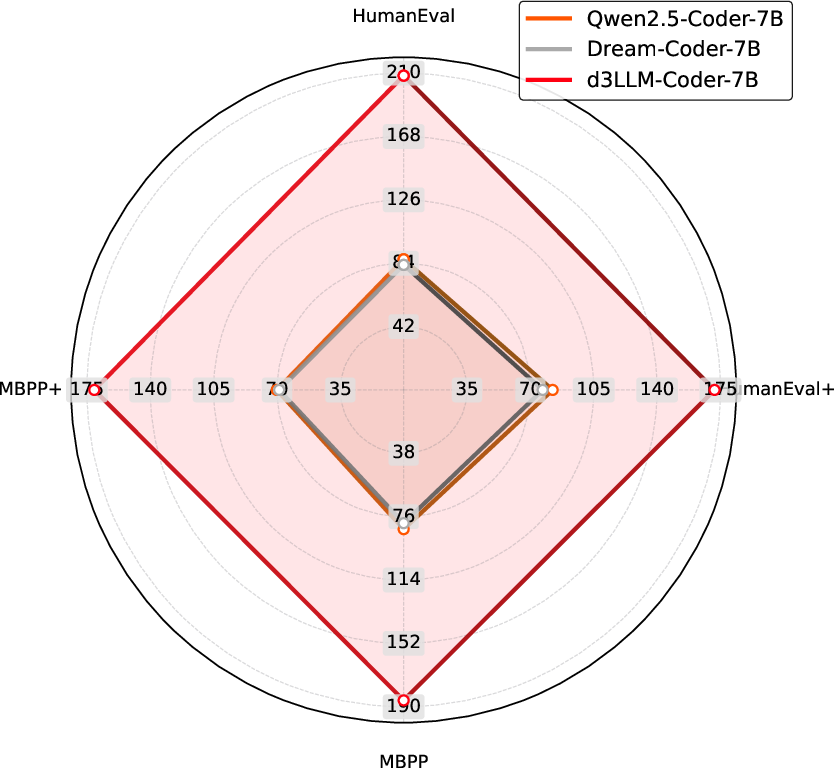
Figure 10: Coder AUP histogram/radar visualizations demonstrating balanced performance.
Conclusion
d3LLM presents a robust, scalable approach for ultra-fast inference in diffusion LLMs by reconciling the trade-off between accuracy and parallelism. Its pseudo-trajectory distillation and entropy-based multi-block inference deliver strong empirical speedups with negligible loss of prediction quality. The AUP metric sets a new standard for dLLM evaluation. As the ecosystem of diffusion LLMs matures, d3LLM’s design principles and analytic tools are poised for widespread adoption and extension, informing the next generation of efficient, scalable LLMs.