No Compute Left Behind: Rethinking Reasoning and Sampling with Masked Diffusion Models
Abstract: Masked diffusion LLMs (MDLMs) are trained to in-fill positions in randomly masked sequences, in contrast to next-token prediction models. Discussions around MDLMs focus on two benefits: (1) any-order decoding and 2) multi-token decoding. However, we observe that for math and coding tasks, any-order algorithms often underperform or behave similarly to left-to-right sampling, and standard multi-token decoding significantly degrades performance. At inference time, MDLMs compute the conditional distribution of all masked positions. A natural question is: How can we justify this additional compute when left-to-right one-token-at-a-time decoding is on par with any-order decoding algorithms? First, we propose reasoning-as-infilling. By using MDLMs to infill a reasoning template, we can structure outputs and distinguish between reasoning and answer tokens. In turn, this enables measuring answer uncertainty during reasoning, and early exits when the model converges on an answer. Next, given an answer, reasoning-as-infilling enables sampling from the MDLM posterior over reasoning traces conditioned on the answer, providing a new source of high-quality data for post-training. On GSM8k, we observe that fine-tuning LLaDA-8B Base on its posterior reasoning traces provides a performance boost on par with fine-tuning on human-written reasoning traces. Additionally, given an answer, reasoning-as-infilling provides a method for scoring the correctness of the reasoning process at intermediate steps. Second, we propose multi-token entropy decoding (MED), a simple adaptive sampler that minimizes the error incurred by decoding positions in parallel based on the conditional entropies of those positions. MED preserves performance across benchmarks and leads to 2.7x fewer steps. Our work demonstrates that the training and compute used by MDLMs unlock many new inference and post-training methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
This paper looks at a newer kind of LLM called a “Masked Diffusion LLM” (MDLM). Unlike regular models that write text one token (tiny piece of text) at a time from left to right, MDLMs are trained to fill in blanks anywhere in the text. People hoped this “fill-anywhere” ability would make MDLMs faster and smarter. But the authors discovered that, for math and coding problems, those expected benefits often don’t show up—and some common tricks can even hurt accuracy.
So they ask: if MDLMs do extra computation to predict every blank spot, how can we actually use that extra power to get real benefits? Their answer: rethink how we prompt the model and how we sample tokens, so the extra compute pays off in speed, reliability, and better training data.
What questions the paper asks
In simple terms, the paper asks:
- Do MDLMs really work better when they can fill tokens in any order?
- Can they safely fill several tokens at once to go faster, without messing up the answer?
- If not, is there a smarter way to use their special “fill-in-the-blank” superpower?
- Can we get speed-ups and better training data from MDLMs by changing how we guide and sample their outputs?
How they approached it (methods, with analogies)
To investigate, the authors ran MDLMs on math (GSM8K, MATH500) and coding (HumanEval) tasks, plus Sudoku. They compared different ways of sampling:
- Left-to-right, one token at a time (like writing a sentence normally)
- Any-order (like filling a crossword puzzle, picking whichever blank looks easiest)
- Multi-token at once (like guessing several letters at the same time)
They also introduced two simple, practical ideas that use MDLMs’ strengths:
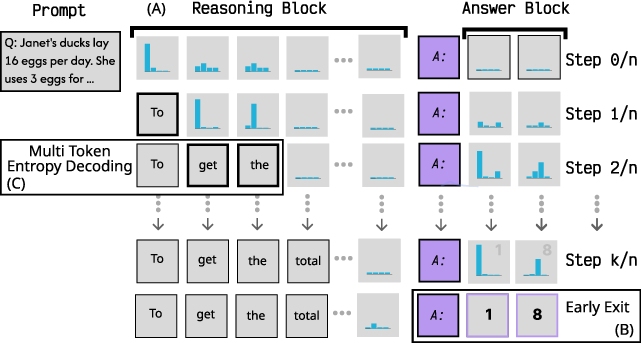
Reasoning-as-Infilling
Think of giving the model a worksheet with two parts already laid out:
- A “reasoning” area for step-by-step thinking
- An “answer” area at the end (for example, “The answer is: [ ]”)
The model fills in the blanks. Because MDLMs can estimate how confident they are about every blank at the same time, you can:
- Watch how sure the model is about its final answer while it’s still reasoning
- Stop early if the model already seems confident (saving time)
- If you already know the right answer, you can pre-fill it and ask the model to generate a matching reasoning trail—creating clean training data without a human writing it
Analogy: It’s like a student writing their work on a worksheet. The teacher can glance at the “answer box” and see how confident the student is getting, even while the student is still doing the steps. If the student is clearly sure, you can move on early. Or if you already know the correct answer, you can ask the student to show a reasonable path that leads to it—this creates good examples to study from.
Multi-token Entropy Decoding (MED)
“Entropy” is a measure of uncertainty. Low entropy = the model is confident. High entropy = the model is unsure.
When MDLMs try to fill many tokens at once, they can make more mistakes because those tokens can depend on each other. MED solves this by only filling multiple tokens at once when the model is very confident about them (low entropy). If not, it fills fewer tokens. This adapts the speed to the model’s confidence.
Analogy: If you’re very sure about several blanks in a crossword, fill them all; if you’re unsure, fill one at a time.
What they found (key results and why they matter)
Here are the main takeaways, summarized in plain language:
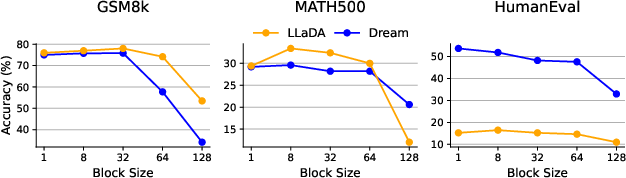
- Left-to-right is still strong: For math and coding, letting the model fill tokens in any order usually didn’t help. Left-to-right, one token at a time, was as good or better. Any-order helped mostly on Sudoku.
- Don’t fill too many tokens at once: Filling even two tokens at the same time often made accuracy drop a lot.
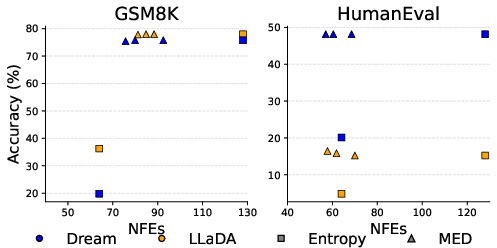
- MED keeps speed without accuracy loss: Their adaptive method (MED) sped things up by about 2–3× while keeping accuracy almost the same. When combined with early stopping, they got about a 3.3× speed-up on GSM8K with only about a 0.1% drop in accuracy.
- Reasoning-as-Infilling unlocks new benefits:
- Early exits: By watching confidence in the “answer box” during reasoning, the model can stop early and save compute.
- Post-hoc reasoning: If you already know the right answer, you can have the model generate matching reasoning steps. The authors used these “posterior” reasoning traces to fine-tune a base model and got improvements similar to training on human-written reasoning.
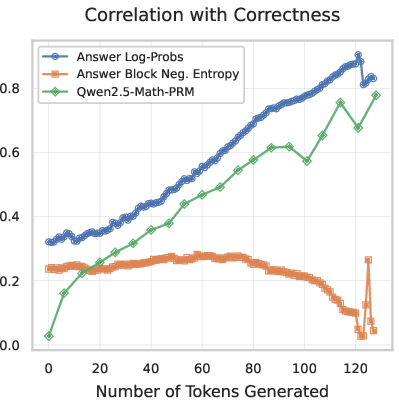
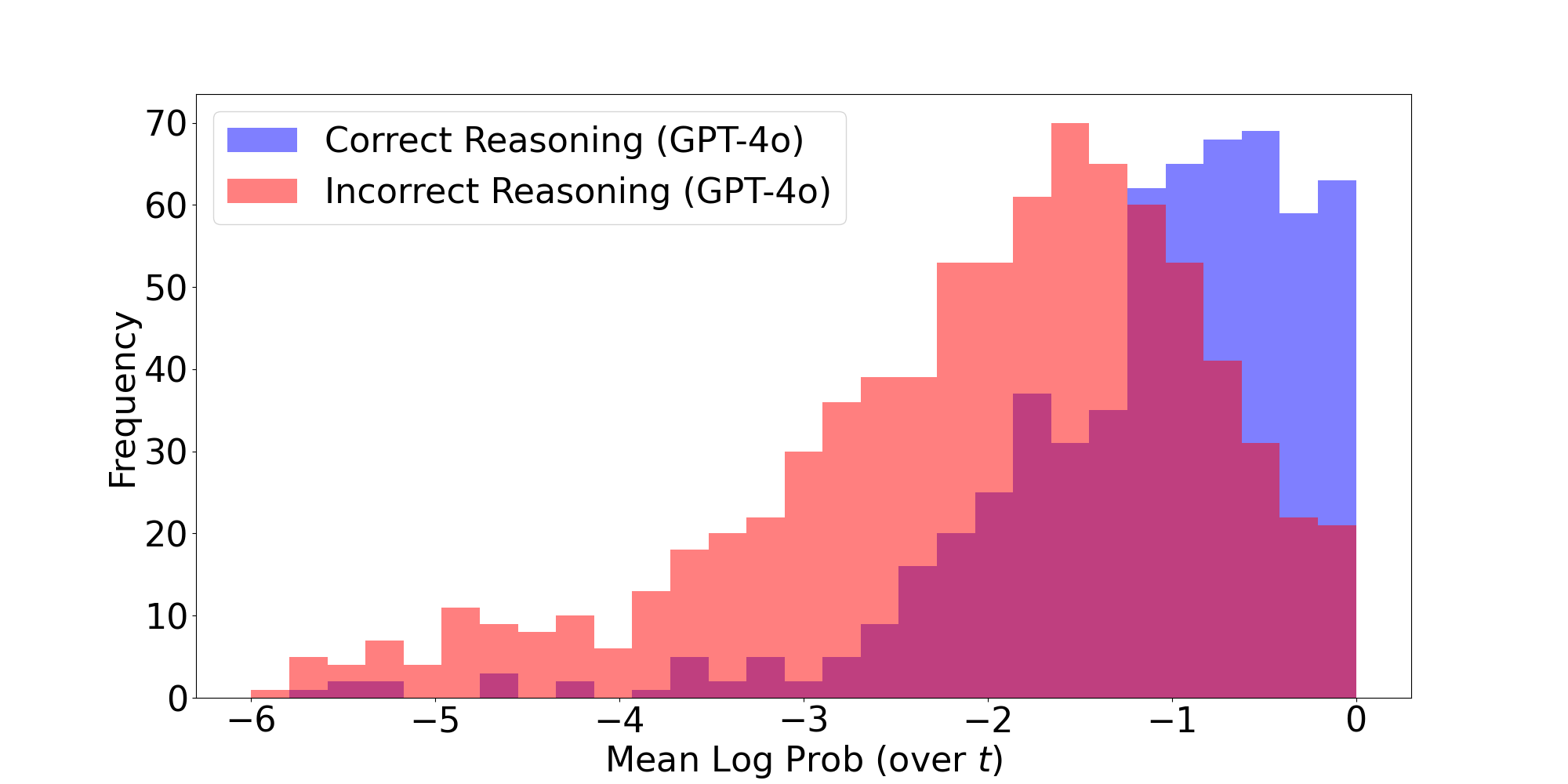
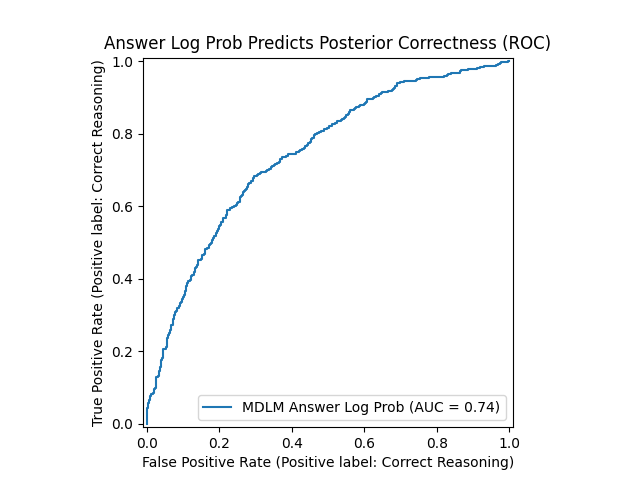
- Score reasoning mid-way: The model can score how good the current reasoning looks mid-stream—without needing a separate checker model. These scores correlated with whether the final answer would be correct.
Why this matters: These findings turn MDLMs’ extra compute—predicting all the masked positions—into practical wins: faster inference, better data for training, and new ways to guide or evaluate reasoning.
What this could change (implications and impact)
- Smarter prompting for reasoning: Instead of just giving a long prompt and hoping for the best, we can structure “reason” and “answer” sections and monitor confidence in real time.
- Faster generation without big accuracy trade-offs: MED makes parallel decoding safer by only going fast when the model is confident.
- Cheaper, high-quality training data: With the answer pre-filled, MDLMs can generate good reasoning examples for fine-tuning—less reliance on expensive human-written traces or separate helper models.
- Better training signals: Because MDLMs can score intermediate steps, future training methods can use “in-progress” feedback to guide the model toward correct solutions more efficiently.
A note on limits: MDLMs currently do more work per sequence than regular left-to-right models and don’t yet benefit from common speed tricks like caching. So, while the ideas are powerful, there’s still engineering work needed to make MDLMs efficient for very long texts.
Overall, the paper suggests a shift in mindset: Instead of trying to force MDLMs to be faster left-to-right models, we should use their unique fill-in-the-blank abilities to get early exits, safe speed-ups, self-scoring reasoning, and better training data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps, uncertainties, and open questions left unresolved by the paper. Each point is framed to be actionable for future research.
- External validity: The findings are demonstrated mainly on math (GSM8K, MATH500) and coding (HumanEval) plus Sudoku; it remains unknown whether reasoning-as-infilling and MED generalize to open-ended generation, dialogue, grounded tasks, long-context question answering, and multilingual settings.
- Model coverage: Results are based on two MDLMs (Dream-7B, LLaDA-8B). How do conclusions change with larger/smaller MDLMs, different training recipes, and alternative architectures? Are the phenomena architecture-specific?
- Absolute baselines: The paper does not compare against strong next-token prediction (NTP) baselines under matched compute/inference regimes. Can MDLMs plus the proposed methods outperform or match SOTA NTP models on the same tasks with controlled hardware/time budgets?
- Any-order decoding underperformance: The paper documents that any-order decoding often underperforms left-to-right except on Sudoku, but does not diagnose why. What properties of tasks or training objectives cause this, and can training or decoding-order learning mitigate it?
- Task taxonomy: Sudoku benefits from any-order; other tasks do not. What structural characteristics (constraint satisfaction vs semantic reasoning, local vs global dependencies) predict when any-order is advantageous?
- Entropy upper bound tightness: Early exits rely on an upper bound of joint answer entropy via the sum of marginal entropies. How tight is this bound in practice across tasks/models/answer lengths, and can tighter bounds (e.g., using pairwise mutual information or structured approximations) improve reliability?
- Early-exit calibration: There is no principled method to set the exit threshold γ. How should γ be calibrated per task/model to guarantee bounded error rates on premature termination? Can PAC-style stopping guarantees or risk-controlled heuristics be developed?
- MED theoretical guarantees: The KL upper bound for MED hinges on entropy and assumes a consistent joint. Is the bound tight or loose in realistic MDLMs? Can cumulative KL be controlled over the whole sequence rather than per step?
- Consistent joint assumption: The approach assumes masked conditionals define a consistent joint distribution, yet real MDLMs may violate consistency. How large are inconsistencies in deployed MDLMs and what is their impact on MED, early exits, and posterior sampling? Can training regularizers enforce consistency?
- MED hyperparameter selection: λ and k_max are set heuristically. How can these be auto-tuned per prompt/task/model to balance speed and accuracy? What is the interaction with temperature, top-p/k, and block sizes?
- Block sizes and schedules: The effects of block any-order decoding schedules (8, 32, 64) are only lightly explored. Is there an optimal dynamic block sizing strategy or learned schedule that improves accuracy and speed jointly?
- Probability calibration: Entropy-based decisions assume well-calibrated probabilities. Are MDLMs calibrated on reasoning tasks? If not, can calibration methods (e.g., temperature scaling, isotonic regression) improve early-exit/MED reliability?
- Wall-clock and systems metrics: Gains are reported in NFEs/function calls, not end-to-end latency, throughput, memory, or energy on real hardware. How do MED/early-exit speedups translate to wall-clock time under realistic batch sizes and GPUs? What is the systems overhead of entropy computation and answer-block monitoring?
- KV caching and any-order: The paper notes lack of KV caching for any-order decoding but does not propose solutions. Can attention architectures or caching schemes be adapted to support efficient any-order infilling?
- Posterior reasoning faithfulness: Posterior traces conditioned on correct answers may be post-hoc rationalizations rather than faithful causal explanations. How can faithfulness be measured (e.g., interventions, counterfactuals), and can training discourage spurious rationalization?
- Human evaluation of posterior traces: Quality assessment relies on GPT-4o and a PRM; human evaluation and inter-rater reliability are missing. How do humans rate correctness, coherence, and faithfulness of posterior traces, and how do these ratings correlate with automated judges?
- Fine-tuning generalization: Posterior-trace fine-tuning shows gains on GSM8K with LoRA, but generalization to other datasets (MATH, HumanEval, MBPP, ARC) and to full fine-tuning is not tested. Are improvements robust across domains and training regimes?
- Mixing human and posterior data: The relative value of human-written vs posterior-generated reasoning traces is not ablated. What mixture ratios and sampling strategies yield the best downstream performance and robustness?
- Self-generated data risks: Training on a model’s own posterior traces may induce confirmation bias or error reinforcement. Does cross-model posterior generation (using a different MDLM) improve robustness? How does this affect out-of-distribution generalization?
- Intermediate rewards without gold answers: The proposed scoring φ(r) uses gold answer tokens; entropy-only signals are weak. Can MDLM-internal signals (e.g., mutual information, stability metrics) provide stronger unsupervised process rewards usable during training?
- RLHF/RL integration: The paper hypothesizes benefits for GRPO/RLOO but does not demonstrate integration. How should MDLM-derived process rewards and posterior sampling be incorporated into RL loops, and do they improve sample efficiency and stability?
- Stopping safety: Early exits may truncate reasoning prematurely and harm interpretability or correctness. Can conservative stopping rules, error detectors, or reflection steps reduce harmful early termination?
- Answer-block design: A fixed allocation of 10 answer tokens may be insufficient for multi-span or non-numeric answers. What are best practices to size and structure answer blocks for diverse outputs (code, proofs, multi-part answers)?
- Coding evaluation depth: HumanEval results are limited (likely pass@1), with no pass@k or runtime/error analysis. How does reasoning-as-infilling affect code generation quality, test coverage, and debugging/error correction?
- Re-masking strategies: MDLMs support re-masking/correction, but interactions with MED and early exits are not explored. Can dynamic re-masking improve accuracy without large compute overhead?
- Safety, privacy, and alignment: Using and exposing chain-of-thought raises safety/privacy concerns. How can reasoning-as-infilling be aligned with safe deployment practices (e.g., redaction, selective disclosure) while retaining performance benefits?
- Multilingual and cross-domain templates: Answer delimiters and templates are language/task-specific. How do template design choices impact performance across languages and domains, and can templates be learned rather than hand-crafted?
- Speculative decoding synergy: Combining MDLMs with NTP draft models or speculative decoding could further accelerate inference; this interaction is unexplored.
- Robustness to adversarial/noisy prompts: The stability of MED and early exits under adversarial inputs or noisy templates is unknown. Can robust decoding policies mitigate failures?
- Measurement clarity: The definition of NFEs/function calls and their relation to true compute cost is not fully specified. A standardized methodology for reporting compute, latency, and memory would improve reproducibility.
- Template sensitivity: The paper does not systematically study sensitivity to delimiter phrasing, layout, or tokenization. How do small template changes affect entropy signals, early exits, and posterior sampling quality?
- Training objective modifications: Can MDLM training be adjusted (e.g., joint-consistency loss, entropy regularization, order-robust objectives) to improve any-order performance and reduce multi-token decoding error without relying on MED?
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods (reasoning-as-infilling, entropy-based early exits, and Multi-token Entropy Decoding), with modest engineering and calibration.
- Inference acceleration for MDLMs via Multi-token Entropy Decoding (MED) and early exits
- Sector: software, AI platforms
- Tools/products/workflows: an inference runtime that wraps MDLMs (e.g., LLaDA, Dream) with ar-med/med decoders and answer-entropy–based early exit. Expect 2–3× fewer function calls and up to ~3.3× speed-ups on math/coding tasks with negligible accuracy loss.
- Assumptions/dependencies:
- Access to MDLM logits for masked positions to compute per-position entropies.
- Thresholds (λ for decoding; γ for exiting) must be tuned per task and model.
- Works best when answers are short and explicitly delimited in the template.
- Reasoning-as-infilling templates for controlled, cost-aware generation
- Sector: education (math tutoring), software engineering (code assistants), enterprise support
- Tools/products/workflows: template libraries that pre-allocate “reasoning block” and “answer block,” expose answer confidence live, and stop when the answer converges. Integrates with chat UIs to show certainty bars and control reasoning length/budget.
- Assumptions/dependencies:
- The task must have a clearly parseable answer delimiter (e.g., “The answer is: …”).
- Template design affects performance; best practices should be codified and tested per domain.
- Posterior reasoning trace generation for data augmentation and fine-tuning
- Sector: ML Ops, model training, academia
- Tools/products/workflows: “Posterior Reasoning Data Factory” that takes existing Q–A pairs, infills the answer, and samples reasoning traces from the MDLM posterior for supervised fine-tuning (LoRA or full fine-tuning). Achieves gains on par with human CoT data (e.g., +14.9% on GSM8K with LLaDA-8B Base).
- Assumptions/dependencies:
- Ground-truth answers available; MDLMs can infill posterior traces reliably.
- Quality controls (filtering) are needed; posterior traces may contain spurious steps.
- In-model step-level scoring without external PRMs
- Sector: ML training, evaluation tooling
- Tools/products/workflows: use answer-token log probabilities and answer-block entropy as process rewards to steer sampling (e.g., GRPO, RLOO) and to filter low-quality synthetic chains before training. Reduces reliance on external PRMs and costly verifiers.
- Assumptions/dependencies:
- For strongest signals, ground-truth answers must be known. Without labels, entropy bounds provide weaker—but useful—signals.
- Reward shaping needs careful calibration to avoid gaming.
- Controllable generation and structured infilling across positions
- Sector: software development, content generation
- Tools/products/workflows: infill code bodies conditioned on predefined signatures or test specs; reserve answer blocks in reports (e.g., TL;DR sections) and generate reasoning separately for auditability.
- Assumptions/dependencies:
- MDLM must support arbitrary-position infilling; templates should reflect domain conventions.
- Deployment guidelines and benchmarks for MDLM decoding
- Sector: industry policy, platform governance
- Tools/products/workflows: internal standards recommending left-to-right or block any-order decoding (with small blocks), discouraging naïve fixed multi-token parallel decoding (k≥2) because of accuracy degradation; add MED/ar-med as preferred strategies.
- Assumptions/dependencies:
- Benchmark suites (e.g., math, coding) available to track accuracy, NFEs, and KL vs single-token baselines.
- Cost-optimized tutoring and study tools with answer certainty
- Sector: daily life, education
- Tools/products/workflows: math solvers that expose answer confidence during reasoning, terminate early when confident, and optionally show step scoring for learning feedback.
- Assumptions/dependencies:
- Works best on short-form problems with definitive answers; user experience must make uncertainty understandable.
- Quality-aware code assistants
- Sector: software
- Tools/products/workflows: assistants that show reasoning, confidence on final output tokens (e.g., function name/return value), and stop early to save tokens when the output is stable.
- Assumptions/dependencies:
- Requires integration into IDEs; must be paired with unit tests or linters for safety.
Long-Term Applications
The following applications require additional research, scaling, or engineering changes (e.g., more efficient MDLM architectures, longer contexts, domain calibration, compliance).
- PRM-less self-improvement training loops
- Sector: ML training platforms
- Tools/products/workflows: end-to-end training frameworks that use internal answer-probability signals for dense, step-level rewards instead of external PRMs; combine posterior sampling, entropy gating, and self-scoring to create closed-loop improvement.
- Assumptions/dependencies:
- Stable reward signals across domains; mitigation of reward hacking.
- Robust generalization beyond math/coding.
- Domain-specific posterior reasoning engines (legal, medical, financial)
- Sector: healthcare, legal, finance
- Tools/products/workflows: generate posterior reasoning traces conditioned on known outcomes (e.g., confirmed diagnoses, court decisions, or trade outcomes) to build explainable domain models and curated training corpora.
- Assumptions/dependencies:
- Expert verification and strict governance; high-stakes domains require human-in-the-loop validation.
- Domain MDLMs trained on specialized corpora; privacy and compliance frameworks.
- MDLM architecture and hardware advances for long contexts
- Sector: AI infrastructure
- Tools/products/workflows: MDLM-specific caching for any-order decoding, memory-efficient attention, and accelerators that reduce the O(L²) prediction overhead to unlock long-chain reasoning.
- Assumptions/dependencies:
- New model designs (e.g., hybrid AR/MDLM), compiler/runtime support, and hardware co-design.
- Hybrid decoding orchestrators (NTP + MDLM)
- Sector: AI platforms
- Tools/products/workflows: product-of-experts or adaptive schemes that combine NTP speed with MDLM infilling control; automatically switch modes based on entropy or uncertainty signals to balance performance and cost.
- Assumptions/dependencies:
- Reliable calibration across models; robust rejection-sampling or fusion strategies.
- Verified reasoning pipelines for compliance and audit
- Sector: regulated industries (finance, healthcare, public sector)
- Tools/products/workflows: store posterior-conditioned reasoning that is consistent with final answers; produce audit trails for decisions, with uncertainty profiles at intermediate steps.
- Assumptions/dependencies:
- Strong governance; traceability requirements; domain ontologies to structure templates and answers.
- Adaptive curriculum and instruction via entropy scheduling
- Sector: education technology
- Tools/products/workflows: student-facing systems that adjust reasoning length and difficulty based on model and learner uncertainty, providing tailored step-by-step explanations and stopping when confident or when confusion is detected.
- Assumptions/dependencies:
- Reliable mapping from model uncertainty to pedagogical decisions; careful UX to avoid overconfidence.
- Agent planning with posterior infilling
- Sector: robotics, operations, energy
- Tools/products/workflows: represent plans as masked sequences; condition on end-goals to sample plausible step chains from the posterior; use entropy to branch or terminate planning. Potential for energy grid operations (scenario planning) and logistics.
- Assumptions/dependencies:
- Domain representations must be tokenized appropriately; safety constraints and validation layers needed.
- Tool-use and retrieval orchestration guided by answer uncertainty
- Sector: AI agents, enterprise automation
- Tools/products/workflows: when answer entropy is high, trigger external solvers, retrieval, or human escalation; when low, proceed without costly calls. Reduces latency and spend in agent pipelines.
- Assumptions/dependencies:
- Calibrated uncertainty thresholds; robust fallbacks and monitoring.
- Large-scale synthetic corpora with aligned reasoning
- Sector: model training (academia, industry)
- Tools/products/workflows: generate massive posterior-aligned reasoning datasets across domains to train smaller, specialized MDLMs or to distill reasoning into faster NTP models.
- Assumptions/dependencies:
- Quality assurance pipelines (filtering, deduplication); bias and error mitigation.
- MDLM-specific benchmarking standards
- Sector: policy, industry consortia
- Tools/products/workflows: publish benchmarks and metrics tailored to MDLMs (NFEs, entropy profiles, KL to single-token baselines, early-exit performance) to guide procurement and deployment decisions.
- Assumptions/dependencies:
- Broad community adoption; shared datasets and reporting protocols.
Glossary
- Answer delimiter: A user-specified marker in the output template that separates the reasoning block from the answer block. "Here the answer delimiter is a user-specified choice (e.g. "The answer is: " for math tasks, or function definitions for a coding task)."
- Any-order auto-regressive model: An auto-regressive model that can decode tokens in an arbitrary order rather than strictly left-to-right. "Notably, an \gls{mdlm} can also be viewed as any-order auto-regressive model \citep{uria2014deep,ou2024your}"
- Any-order decoding: Sampling strategy that selects the next positions to unmask based on a criterion (e.g., entropy), not constrained to left-to-right order. "Does any-order decoding help for text?"
- ar-med: An auto-regressive variant of Multi-token Entropy Decoding that decodes a contiguous left-to-right group of low-entropy positions. "ar-med: We decode at most tokens in a contiguous left-to-right order"
- Auto-regressive: A generation process where each token is produced conditioned on previously generated tokens, typically left-to-right. "The resulting LLM is sampled auto-regressively left-to-right, one token at a time."
- Block-sampling: A decoding approach that defines fixed-length blocks along the sequence and decodes within each block, potentially in arbitrary order. "Additionally, block-sampling \citep{sahoo2024simple,nie2025largelanguagediffusionmodels,arriola2025blockdiffusioninterpolatingautoregressive} approaches define a left-to-right sequence of fixed length blocks and decode within each block in an arbitrary order."
- Early exits: A strategy to terminate generation early when the model is sufficiently confident in the answer, reducing inference cost. "This provides several benefits, like B) enabling early exits or post-hoc reasoning given a pre-filled answer."
- Entropy-bound sampler (EB): An adaptive multi-token decoder that selects positions to decode based on an entropy budget to control error. "propose entropy-bound (eb) sampler, an adaptive multi-token decoder"
- Entropy decoding: A policy that selects which masked positions to decode next based on their entropy (uncertainty). "entropy decoding with a fixed number of tokens ."
- Entropy upper bound: A computable upper bound on the joint entropy of answer tokens, used to decide when to exit early. "we skip filling in the remaining reasoning tokens if the answer-entropy upper bound falls below a user-specified threshold "
- GRPO: Group Relative Policy Optimization, a reinforcement-learning-style preference optimization method for fine-tuning LLMs. "Existing fine-tuning algorithms, such as grpo \citep{shao2024deepseekmath} and rloo \citep{ahmadian2024back}, do not make use of posterior samples"
- Kullback–Leibler divergence (KL divergence): A measure of how one probability distribution differs from another; used to quantify error from parallel decoding. "we also measure the \gls{kl} divergence between the likelihoods of the single-token decoding scheme with the multi-token decoding schemes."
- kv-caching: A transformer inference optimization that caches attention key-value states to accelerate generation. "propose accelerating inference with \glspl{mdlm} using kv-caching and parallel decoding."
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method that adds trainable low-rank matrices to weight updates. "We post-train the LLaDA-8B Base model using LoRA \citep{hu2022lora}."
- Masked Diffusion LLM (MDLM): A generative model trained to in-fill randomly masked positions in sequences, providing conditional distributions for all masked tokens. "\Glspl{mdlm} are trained to in-fill positions in randomly masked sequences, in contrast to traditional \gls{ntp} models."
- Maximum marginal log-likelihood: A training objective that maximizes the log-likelihood of observed outputs marginalized over latent structures (e.g., reasoning traces). "maximum marginal log-likelihood training \citep{phan2023training,pml2Book}"
- Multi-token decoding: Decoding multiple masked positions in parallel, which can introduce errors if independence assumptions are violated. "standard multi-token decoding significantly degrades performance."
- Multi-token Entropy Decoding (MED): An adaptive decoder that only decodes multiple positions when their entropies are below a threshold to control deviation from the joint model. "Second, we propose \gls{med}, a simple adaptive sampler that minimizes the error incurred by decoding positions in parallel"
- Number of Function Evaluations (NFEs): A count of model calls during sampling; used as a proxy for inference cost. "we measure the task accuracy and the number of function evaluations (nfes)"
- Posterior inference: Inference performed conditioned on observed outputs (e.g., the answer), to sample latent structures like reasoning traces. "We perform posterior inference on the $1419$ training samples"
- Posterior reasoning traces: Reasoning sequences sampled from the model’s posterior distribution conditioned on the given answer. "fine-tuning LLaDA-8B Base on its posterior reasoning traces provides a performance boost"
- Process Reward Model (PRM): A learned model that assigns step-wise rewards to intermediate reasoning steps, used to guide generation and training. "These intermediate rewards are generally provided by an external pre-trained process reward model (PRM)"
- Reasoning-as-infilling: A prompting framework that pre-fills a template separating reasoning from answer tokens, enabling new controls and signals during generation. "First, we propose reasoning-as-infilling."
- Rejection sampling: A sampling scheme that draws candidate outputs from a proposal model and accepts them based on a target model’s criteria. "using smaller draft models for generation and then rejection sampling can also enable parallel decoding"
- RLOO: REINFORCE Leave-One-Out, a preference-optimization/fine-tuning method using leave-one-out baselines for variance reduction. "Existing fine-tuning algorithms, such as grpo \citep{shao2024deepseekmath} and rloo \citep{ahmadian2024back}, do not make use of posterior samples"
- Speculative decoding: A strategy to accelerate generation by predicting multiple tokens ahead (or with a draft model) and validating them. "enable parallel multi-token decoding, or speculative decoding, without making use of another model."
- STaR: Self-Taught Reasoner; a fine-tuning method that trains on reasoning traces sampled conditioned on correct answers. "including with STaR \citep{zelikman2022star}"
Collections
Sign up for free to add this paper to one or more collections.

