The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
Abstract: Diffusion LLMs (dLLMs) break the rigid left-to-right constraint of traditional LLMs, enabling token generation in arbitrary orders. Intuitively, this flexibility implies a solution space that strictly supersets the fixed autoregressive trajectory, theoretically unlocking superior reasoning potential for general tasks like mathematics and coding. Consequently, numerous works have leveraged reinforcement learning (RL) to elicit the reasoning capability of dLLMs. In this paper, we reveal a counter-intuitive reality: arbitrary order generation, in its current form, narrows rather than expands the reasoning boundary of dLLMs. We find that dLLMs tend to exploit this order flexibility to bypass high-uncertainty tokens that are crucial for exploration, leading to a premature collapse of the solution space. This observation motivates a rethink of RL approaches for dLLMs, where considerable complexities, such as handling combinatorial trajectories and intractable likelihoods, are often devoted to preserving this flexibility. We demonstrate that effective reasoning can be better elicited by intentionally forgoing arbitrary order and applying standard Group Relative Policy Optimization (GRPO) instead. Our approach, JustGRPO, is minimalist yet surprisingly effective (e.g., 89.1% accuracy on GSM8K) while fully retaining the parallel decoding ability of dLLMs. Project page: https://nzl-thu.github.io/the-flexibility-trap

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a new kind of LLM called a diffusion LLM (dLLM). Unlike traditional models that write from left to right, dLLMs can fill in words in any order. Many people assumed this extra flexibility would help the model “reason” better on hard tasks (like math and coding). The authors discovered the opposite: letting the model write in any order often hurts its reasoning. They explain why this happens and introduce a simple training method, called JustGRPO, that makes these models reason better while still keeping their speed advantages.
What questions did the researchers ask?
The paper focuses on two simple questions:
- Does letting a model write in “any order” help it solve hard problems better than writing strictly left-to-right?
- If not, can we train diffusion models in a simpler way to get strong reasoning performance without complicated tricks?
How did they study it?
Diffusion LLMs in everyday terms
Imagine writing a paragraph, but instead of starting from the first word, you start with a blank page and gradually fill in missing words. A diffusion LLM works like this: it begins with a fully masked sentence and repeatedly “unmasks” some words until the whole sentence is complete.
Two ways to “write” a sentence
- Autoregressive (AR) order: Write strictly from the first word to the last word. You must decide the next word before seeing the future words.
- Arbitrary order: Fill in whichever words feel easiest or most certain first, and leave hard words for later.
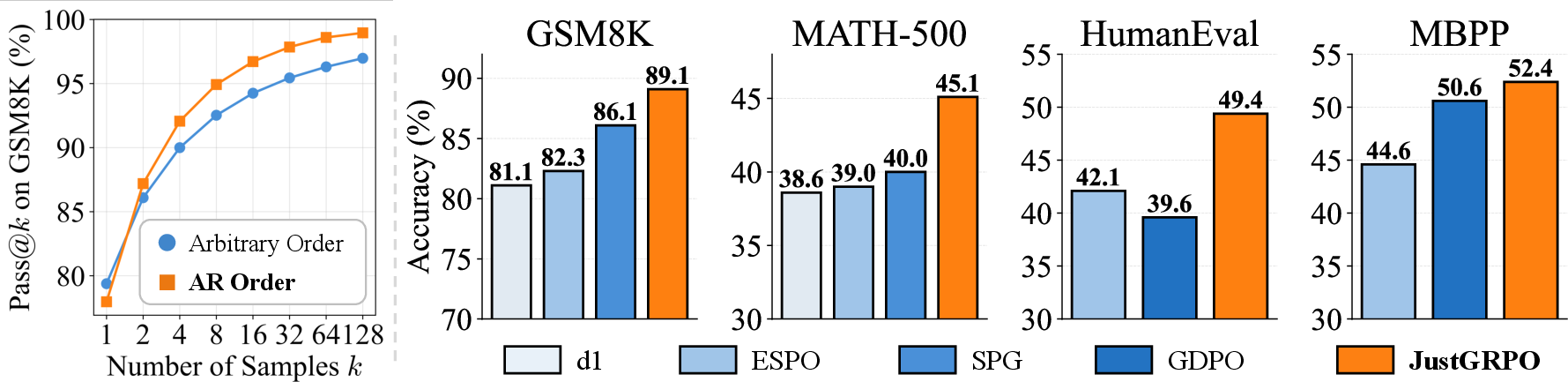
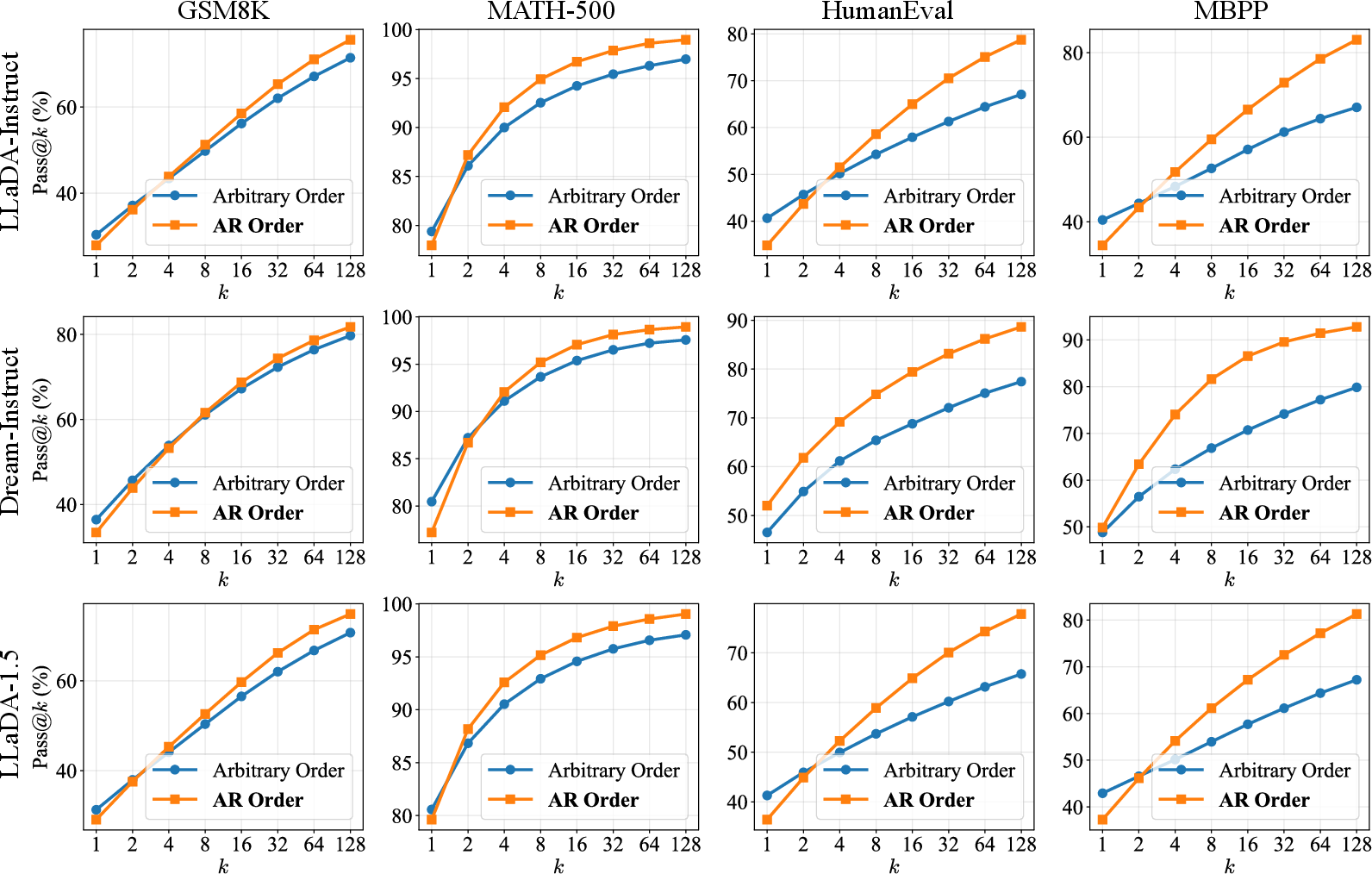
Measuring “reasoning potential” with Pass@k
The authors measured how much “solution space” a model can explore using a metric called Pass@k. Think of it like this: if you give the model k tries on a problem, what’s the chance at least one try is correct? Higher Pass@k means the model is better at exploring different possible solutions—important for learning and improvement.
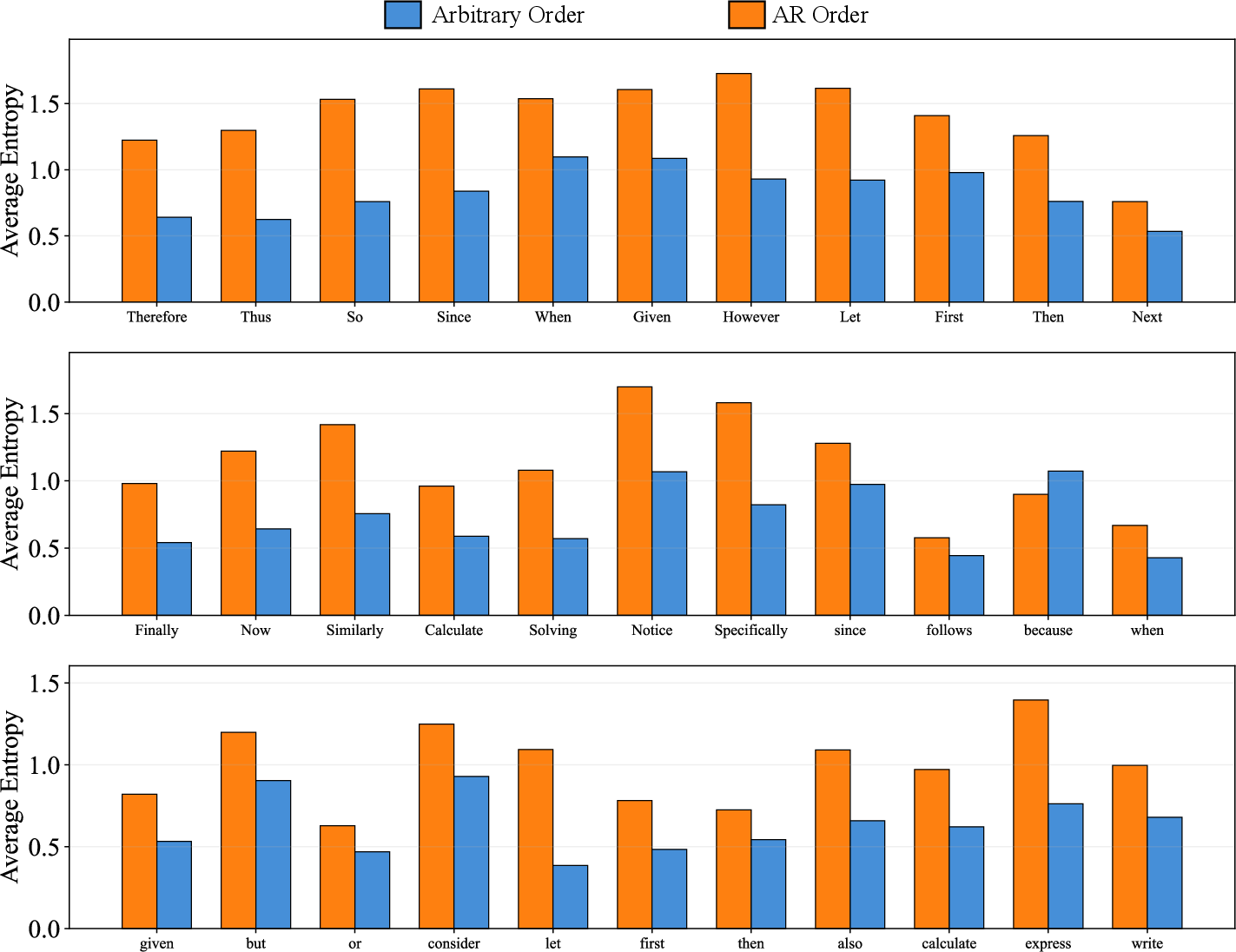
Why arbitrary order can backfire: “entropy degradation”
When solving a problem, you sometimes reach a “fork in the road” where several different next steps could make sense. These are “high-uncertainty” (or “high-entropy”) moments—like deciding whether to write “Therefore,” “However,” or “Since,” each leading to a different line of reasoning.
- In left-to-right (AR) mode, the model must choose at the fork. That forces it to explore different reasoning paths across multiple tries.
- In arbitrary order, the model often skips the hard fork and fills in easy words first. By the time it returns to the fork, the later words already lock in a specific path. The fork disappears—the model isn’t really choosing among different paths anymore; it’s just picking a connector that fits what it already wrote. This collapse of choices is what the authors call entropy degradation.
Their training idea: JustGRPO
Many recent methods tried to keep the “any order” flexibility during training with complicated reinforcement learning (RL). The authors argue this is unnecessary—and even harmful—for reasoning.
Their simple idea:
- Treat the diffusion model as if it were left-to-right during training only, so it must face the hard choices in order.
- Use a straightforward RL method called Group Relative Policy Optimization (GRPO). In plain terms: generate a small group of answers, score them (for example, by whether the math answer is correct or the code passes tests), and nudge the model toward the better answers without building complex prediction machinery.
- After training, you can still use the model’s fast, parallel “fill-in” style at test time.
What did they find?
Here are the main results and why they matter:
- Arbitrary order often looks fine on single tries, but as you let the model try more times (higher k), left-to-right decoding finds correct solutions much more often. This means it has a larger, healthier “search space” for reasoning.
- The set of solutions discovered by arbitrary order is mostly a subset of those discovered by left-to-right. In other words, arbitrary order doesn’t unlock new reasoning paths—it usually narrows them.
- The “entropy degradation” effect is real: models skip tricky, branching tokens (like “Therefore,” “Thus,” “Since”), reduce uncertainty too early, and lose diversity in reasoning paths.
- Their simple training method, JustGRPO, beats more complex diffusion-specific RL methods on key benchmarks:
- GSM8K (grade-school math word problems): about 89.1% accuracy
- MATH: about 45.1% accuracy
- Also strong on coding tests like HumanEval and MBPP
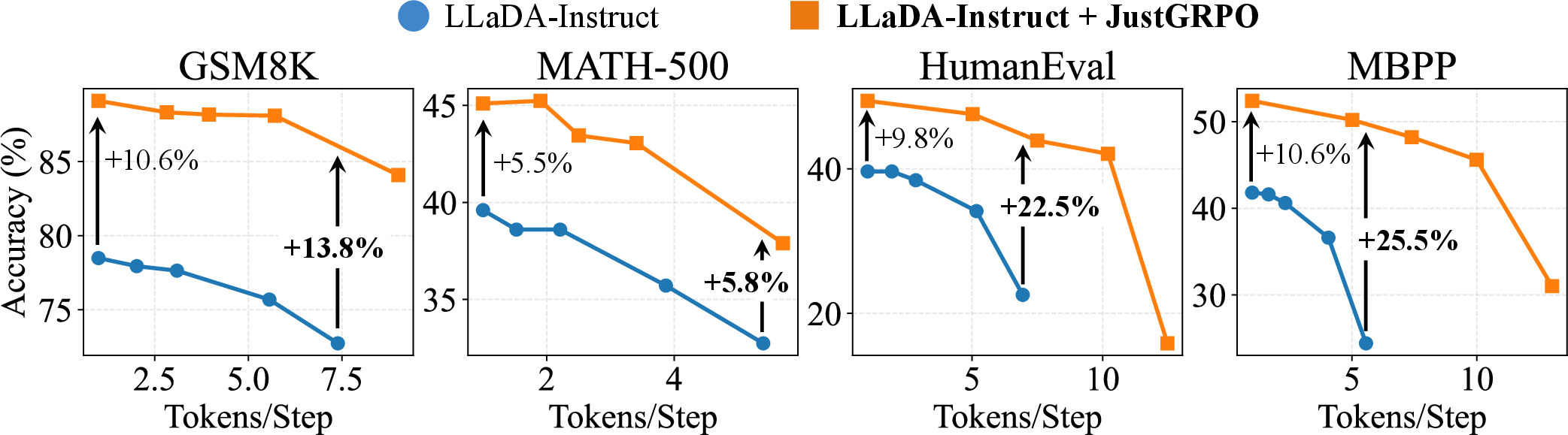
- Crucially, even though the model is trained under a left-to-right constraint, it keeps the speed benefits of diffusion models at test time, including fast, parallel decoding.
Why does this matter?
- It challenges a popular belief: more freedom in word order doesn’t automatically mean better thinking. In practice, that freedom can make the model avoid hard decisions, shrinking its ability to explore different solutions.
- It simplifies training: instead of wrestling with complex mathematics and unstable approximations to preserve “any order” during RL, you can train with a clean, left-to-right setup and still get great results.
- It preserves speed: you don’t lose the diffusion model’s parallel decoding advantage at inference time.
Takeaway
Sometimes, less flexibility leads to better thinking. For diffusion LLMs, making them decide tough steps in order during training helps them explore more reasoning paths and learn better. With JustGRPO, you get stronger reasoning performance and keep the fast decoding that makes diffusion models appealing. This suggests future LLMs might benefit from combining simple, structured training with flexible, efficient inference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unanswered questions that the paper leaves open, intended to guide future research:
- External validity across models and scales: Do the findings generalize beyond LLaDA-family dLLMs (e.g., different architectures, parameter scales, pretraining corpora, tokenizer choices), multilingual models, or multimodal diffusion LMs?
- Task coverage beyond math and coding: Does the “flexibility trap” hold for commonsense QA, multi-hop reasoning, long-form explanation, instruction following, dialog, planning, and knowledge-intensive tasks where reasoning is less verifiable?
- Length and discourse structure: How do the conclusions change for very long chains-of-thought (>1k tokens), multi-turn reasoning, or documents with complex discourse where non-left-to-right structure might be beneficial?
- Causal evidence for entropy degradation: Can controlled interventions (e.g., forcing updates at predicted fork tokens, randomizing future context) causally demonstrate that bypassing high-entropy tokens reduces solution-space coverage?
- Fork detection beyond lexical heuristics: The analysis leans on connector words (e.g., “Therefore,” “Thus”). How to identify forking tokens in code or non-English text where forks are not tied to specific lexemes? Can model-internal signals (e.g., token-level uncertainty spikes, gradient-based salience) yield a robust fork detector?
- Theory for order-induced solution-space collapse: Can we formalize the link between token-update policy, conditional entropy trajectories, and Pass@k scaling (e.g., via information-theoretic bounds or branching-process models)?
- When does arbitrary order help? Prior work suggests benefits in constraint satisfaction (e.g., Sudoku). Can we construct a taxonomy of tasks where AO is net-positive vs. net-negative, and design diagnostics that predict which regime a task belongs to?
- Train–test order mismatch: JustGRPO trains with AR but infers with parallel/AO samplers. Under what conditions does this mismatch harm performance (e.g., stylistic generation, non-reasoning tasks)? Are there tasks where AR-at-train biases degrade AO inference quality?
- Comparative baselines without RL: Would simple AR-style supervised finetuning (e.g., next-token SFT with rationale supervision) or rejection sampling already recover most of the gains attributed to JustGRPO?
- Limits of Pass@k as “reasoning potential” proxy: The argument assumes RL primarily sharpens the base distribution. When does RL reshape the distribution sufficiently to invalidate Pass@k as an upper bound (e.g., with strong exploration bonuses or curriculum)?
- Sensitivity to decoding policies and hyperparameters: Although some ablations are provided, how robust are conclusions across a broader space (e.g., beam search, nucleus sampling, diverse remasking schedules, different temperature schedules per-position)?
- Compute-normalized comparisons: Do AR and AO modes achieve comparable Pass@k under equal wall-clock or FLOPs budgets, given AO may produce candidates faster via parallelism? Are the solution-space gaps still present under compute parity?
- Parallel decoding limits: The paper shows EB-sampler results. Do conclusions hold across other parallel samplers, larger tokens-per-step, and across latency-throughput operating points typical in deployment?
- Stability and reproducibility: What is the variance across random seeds, runs, and datasets? Are the reported gains statistically significant with confidence intervals?
- Generalization across reward types: JustGRPO uses verifiable rewards. Does AR-at-train still dominate under preference-based rewards (RLAIF/RLHF), or under sparse/heuristic rewards with higher noise?
- Safety, calibration, and faithfulness: Does preserving higher entropy at forks improve calibration or reduce hallucinations? Are there trade-offs in factuality/faithfulness when applying JustGRPO beyond math/coding?
- Quality outside reasoning: Does AR-constrained RL impact general text quality (fluency, coherence, style) on standard NLG benchmarks, given the denoiser is optimized with AR credit assignment?
- Efficient AO that preserves exploration: Can we design AO token-selection policies that explicitly prioritize high-entropy/fork tokens (e.g., entropy-targeting, uncertainty budgeting, or fork-aware schedules) to avoid the flexibility trap while retaining AO’s strengths?
- Learning to schedule token updates: Instead of hard-coding AO heuristics, can we learn a policy over positions (e.g., auxiliary controller) that maximizes exploration (Pass@k) while preserving AO’s efficiency?
- Maximum-entropy or tempered AO training: Would explicit entropy regularization or tempered objectives at forking positions recover exploration under AO without collapsing solution space?
- Trajectory-likelihood tractability: Are there new formulations (e.g., invertible masks, explicit position policies, dynamic graphical models) that make AO trajectory likelihoods tractable enough for principled RL without unstable surrogates?
- Micro-level dynamics of entropy over time: A fine-grained, time-resolved study could quantify how and when entropy drops at forks under AO, and how this correlates with eventual success/failure across tasks and samplers.
- Mixture-of-orders curricula: Could hybrid training that gradually anneals from AO to AR (or vice versa), or mixes both via stochastic schedules, achieve the best of both worlds?
- Token-importance reweighting in GRPO: The paper hints at top-entropy token updates; a systematic study of token-level credit assignment (e.g., reweighting or masking gradients at forks) could improve efficiency and performance.
- Scope of evaluation datasets: Results rely on a specific suite and protocol (e.g., temperature 0 at inference for reasoning). Do the findings persist with alternative prompts, instruction styles, unit-test suites, and verification tools?
- Data leakage/contamination checks: Are the improvements robust after stringent contamination audits, especially for coding datasets and math problems with shared templates?
- KL and regularization choices: The GRPO recipe uses KL coefficient 0.0. How sensitive are outcomes to KL tuning, reference policies, or trust-region constraints—particularly for preventing over-optimization or distribution drift?
- Resource accessibility: Training used 16×H100 GPUs. What happens under constrained compute—can the method be made more sample- or memory-efficient (e.g., partial likelihoods, low-rank adapters) without losing gains?
- Beyond connector words in code: In coding, forks may relate to control-flow or API choices rather than surface tokens. Can we detect and preserve uncertainty at such structural forks (e.g., AST-level entropy) under AO?
- Broader impacts of discouraging AO: If AR-at-train becomes standard, do we risk missing genuinely non-sequential strategies that AO might unlock with better training/scheduling? What benchmarks could reliably surface such benefits?
Glossary
- Arbitrary-order generation: Generating tokens without a fixed left-to-right order, typical in diffusion LLMs to allow flexible decoding. "the implications of arbitrary-order generation remain less explored"
- Autoregressive (AR) order: A left-to-right decoding scheme where each token is generated conditioned on all previous tokens. "restricting dLLMs to standard Autoregressive (AR) order expands the reasoning solution space."
- Autoregressive factorization: Expressing the probability of a sequence as a product of conditional probabilities over tokens in order. "Autoregressive models factorize the sequence likelihood as "
- Autoregressive policy: A policy that outputs one token at a time conditioned on previous tokens and the input query. "It is typically applied to autoregressive policies ."
- Clipped surrogate function: A stabilized objective used in policy optimization (e.g., PPO/GRPO) that clips probability ratios to prevent large updates. "The GRPO objective maximizes a clipped surrogate function with a KL regularization term:"
- Combinatorial explosion (of denoising trajectories): Rapid growth in the number of possible decoding paths as sequence length increases, making exact optimization intractable. "algorithms must grapple with a combinatorial explosion of denoising trajectories"
- Conditional independence properties: Structural assumptions that certain predictions are independent given others, enabling parallel decoding in diffusion models. "the model retains its conditional independence properties"
- Confidence scores: Model-estimated token confidences used to guide which tokens to unmask or update during diffusion decoding. "based on heuristics such as confidence scores"
- Credit assignment (token-level): Determining which token-level decisions contributed to observed rewards or outcomes during training. "making token-level credit assignment ambiguous"
- Diffusion LLMs (dLLMs): LLMs that generate sequences via iterative denoising, often allowing parallel and arbitrary-order decoding. "Diffusion LLMs (dLLMs) break the rigid left-to-right constraint of traditional LLMs"
- Discrete denoising process: A generation paradigm where masked tokens are progressively restored to clean tokens over multiple steps. "treating sequence generation as a discrete denoising process."
- Denoising trajectories: Specific sequences of unmasking and token updates that the diffusion sampler follows during generation. "the policy must optimize over the full combinatorial space of denoising trajectories "
- ELBO-based surrogates: Approximate objectives derived from the Evidence Lower Bound used when exact likelihoods are intractable. "forcing existing methods to rely on ELBO-based surrogates rather than the true objective"
- Entropy Bounded (EB) Sampler: A parallel decoding heuristic that constrains token-level entropy during sampling to maintain stability. "We employ the training-free Entropy Bounded (EB) Sampler to evaluate inference performance"
- Entropy degradation: The phenomenon where postponing uncertain tokens reduces their entropy when revisited, prematurely collapsing reasoning branches. "We term this phenomenon entropy degradation."
- Evidence Lower Bound (ELBO): A variational objective that lower-bounds the log-likelihood, often optimized when true likelihood is hard to compute. "rely on ELBO-based surrogates rather than the true objective"
- Forking tokens: High-impact tokens (e.g., logical connectors) at which reasoning can branch into different paths. "it typically hinges on sparse ``forking tokens''"
- Heuristic-guided policies: Sampling strategies that incorporate heuristics (e.g., confidence) to navigate decoding paths in diffusion generation. "rollout samples are produced by heuristic-guided policies "
- Importance ratio: The ratio of new to old policy probabilities for a token, used in policy gradient updates with clipping. "with the token level importance ratio $\rho_{i,k} = \frac{\pi_\theta(o_{i,k} \mid o_{i,<k}, q)}{\pi_{\theta_{\text{old}}(o_{i,k} \mid o_{i,<k}, q)}$."
- Inductive biases: Inherent preferences of a model’s architecture or training that guide its predictions toward certain structures. "generated based on its inherent inductive biases"
- Intractable likelihoods: Likelihoods that cannot be computed exactly due to summation over an exponential or factorial number of latent trajectories. "and intractable likelihoods, are often devoted to preserving this flexibility."
- KL regularization term: A Kullback–Leibler divergence penalty that keeps the learned policy close to a reference distribution during optimization. "with a KL regularization term:"
- Low-confidence remasking: A decoding heuristic that re-masks tokens with low confidence to allow re-prediction in later steps. "Arbitrary Order, which follows standard diffusion decoding with low-confidence remasking"
- Marginalization over trajectories: Summing over all possible denoising paths to compute the overall sequence likelihood. "dLLMs require marginalization over all valid denoising trajectories"
- Masked Diffusion Models (MDMs): Diffusion models that operate directly in discrete token space by masking and denoising tokens. "particularly Masked Diffusion Models (MDMs), generate sequences by iteratively denoising a masked state"
- Masking ratio: The proportion of tokens masked at a given diffusion step, often parameterized by a continuous time variable. "indexed by a continuous time variable , representing the masking ratio."
- Negative entropy sampling (Neg-Entropy): A token selection strategy prioritizing high-uncertainty positions to encourage exploration. "negative entropy sampling (Neg-Entropy)"
- Negative Evidence Lower Bound (NELBO): The negative of the ELBO; minimizing it corresponds to maximizing the ELBO during training. "minimizing the Negative Evidence Lower Bound"
- Off-policy misalignment: A discrepancy where samples are collected under one distribution while optimization targets another, biasing gradients. "a critical off-policy misalignment persists across these methods"
- Parallel decoding: Generating multiple tokens simultaneously rather than strictly sequentially, improving efficiency. "efficient parallel decoding"
- Pass@: The probability that at least one correct solution appears within k independent samples, used to gauge solution space coverage. "we employ Pass@, which measures the coverage of solution space."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setting where rewards are computed by verifiable checks (e.g., unit tests or exact answers). "we use the term RL to refer specifically to Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reasoning manifold: The learned structure of reasoning paths that remain stable under different decoding approximations. "it learns a more robust reasoning manifold"
- Sequence-level denoisers: Models that predict all masked tokens in a sequence simultaneously rather than one token at a time. "Diffusion LLMs, however, are architected as sequence-level denoisers"
- Semi-autoregressive block size: The number of tokens produced per step in semi-autoregressive decoding, trading off parallelism and control. "a semi-autoregressive block size of 32."
- Semi-autoregressive decoding: A decoding method that generates tokens in chunks, blending parallelism with some ordering constraints. "semi-autoregressive decoding in blocks of 32 tokens"
- Top- margin sampling (Margin): A selection rule that uses the confidence gap between top predictions to prioritize token updates. "top- margin sampling (Margin)"
- Trajectory space: The set of all possible denoising paths the sampler can follow during diffusion generation. "For a sequence of length , the trajectory space grows as "
- Unbiased estimator: A statistical estimator whose expected value equals the parameter being estimated, ensuring no systematic error. "following the unbiased estimator formulation"
- Unmasking: The act of revealing or updating previously masked token positions during the diffusion decoding process. "iteratively unmasks a subset of tokens based on heuristics such as confidence scores"
- Localized spikes in entropy: Concentrated increases in uncertainty at specific tokens, often corresponding to reasoning branch points. "naturally manifesting as localized spikes in entropy"
Practical Applications
Below are practical, real-world applications that follow directly from the paper’s findings and methods, organized by deployment horizon. Each item notes relevant sectors, likely tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now with existing diffusion LLMs by switching RL training to JustGRPO (AR-constrained) while retaining parallel decoding at inference.
- Improved coding assistants with faster, more reliable completion
- Sector: software/devtools
- What: Train existing dLLM-based code assistants with JustGRPO using unit-test verifiable rewards; deploy parallel decoding (e.g., EB sampler) to cut latency without harming pass rates
- Tools/workflows: JustGRPO trainer; unit-test harnesses; EB sampler; pass@k dashboards; smaller semi-autoregressive block sizes; moderate temperature settings
- Assumptions/dependencies: High-quality test suites for verifiable rewards; access to model logits for entropy; sufficient compute for RL; dLLM supporting masked denoising
- Step-by-step math reasoning tutors with mobile-friendly inference
- Sector: education
- What: Use JustGRPO to raise accuracy on math tasks (e.g., GSM8K, MATH), serve answers with parallel decoding on edge or cloud
- Tools/workflows: Verifiable math-answer extractor; pass@k-driven sampling budget; EB sampler integration
- Assumptions/dependencies: Datasets with ground-truth answers; careful prompt templates; content moderation for student use
- Enterprise reasoning QA and procurement standards
- Sector: policy and enterprise AI governance
- What: Adopt pass@k as a procurement/evaluation metric for reasoning systems; require vendors to report solution coverage curves under standardized settings (temperature, block size)
- Tools/workflows: Evaluation suite with pass@k calculators; entropy/fork-token monitors; benchmark harnesses
- Assumptions/dependencies: Agreement on common benchmarks, sampling protocols, and reporting formats
- Simplified RLVR pipelines for diffusion LLMs
- Sector: ML engineering
- What: Replace diffusion-specific RL with JustGRPO to avoid intractable trajectory likelihoods; use AR masking during training for stable credit assignment
- Tools/workflows: AR-mode rollout; GRPO objective; KL regularization tuning; verifiable reward functions
- Assumptions/dependencies: Ability to construct masked AR input states; compatibility with existing training infrastructure
- Entropy-aware sampling and decoding hygiene
- Sector: ML ops/platforms
- What: Instrument decoders to detect and avoid bypassing high-entropy “forking tokens”; reduce block size, deploy neg-entropy or EB sampling to maintain exploration
- Tools/workflows: Token-level entropy trackers; fork-token lexicons; sampler configuration kits
- Assumptions/dependencies: Access to logits; observability pipelines; standardized inference heuristics
- Parallel decoding deployment with speed–accuracy tuning
- Sector: platform/infra
- What: Integrate EB sampler and parallel token steps to optimize throughput; monitor degradation curves to choose safe parallelization levels
- Tools/workflows: Sampler SDK; throughput/accuracy dashboards; A/B tests on block sizes and temperatures
- Assumptions/dependencies: Hardware capacity; concurrency constraints; workload variability
- Data pipeline validation and ETL assistants
- Sector: software/data engineering
- What: Use JustGRPO-trained dLLMs to reason through ETL transformations with unit-test style checks and schema verifiers
- Tools/workflows: Data quality tests as verifiable rewards; CI hooks; pass@k-based sampling budgets
- Assumptions/dependencies: Well-specified invariants and tests; precise task prompts
- Personal assistants for structured tasks with verifiable outcomes
- Sector: daily life
- What: Budget planning, recipe steps, and checklists where intermediate goals can be verified (e.g., calculations, list completeness)
- Tools/workflows: Built-in checkers (calculators, list verifiers); AR-trained reasoning core with parallel inference
- Assumptions/dependencies: Tasks must be decomposable with verifiable subtasks; robust guardrails for non-verifiable domains
Long-Term Applications
These require further research, scaling, or domain adaptation (e.g., limited verifiable rewards, safety constraints, or new algorithmic development).
- Decoding strategies that preserve exploration without losing parallelism
- Sector: software, ML research
- What: Design fork-first or entropy-bounded decoders that maintain high entropy at logical forks while still supporting non-AR generation
- Tools/workflows: Adaptive mask schedulers; fork-aware token selection policies; entropy-preservation constraints
- Assumptions/dependencies: New theory/algorithms for balanced exploration–exploitation; robust validation beyond benchmarks
- Rehabilitating arbitrary-order generation for reasoning
- Sector: ML research
- What: Architectures or training regimes that prevent “entropy degradation” (e.g., auxiliary policies that prioritize uncertain tokens, curriculum learning at forks)
- Tools/workflows: Positional selection policies; uncertainty-aware loss functions; fork-token curricula
- Assumptions/dependencies: Stable training objectives; measurable gains over AR-constrained training; generalization to diverse tasks
- Multimodal diffusion reasoning (vision–language, robotics)
- Sector: robotics, autonomy, multimodal AI
- What: Extend JustGRPO-like AR-constrained RLVR to multimodal diffusion models for planning/sequencing tasks (e.g., kitchen assembly, warehouse flows), with simulators as verifiers
- Tools/workflows: Simulation-based verifiable rewards; multimodal fork-token detection; parallel inference on embedded hardware
- Assumptions/dependencies: High-fidelity simulators; domain-specific safety constraints; on-device compute/latency budgets
- Healthcare decision support where verifiability is partial
- Sector: healthcare
- What: Use AR-constrained training to improve clinical reasoning reliability, starting in narrow domains with clear outcome verifiers (e.g., dosage calculators, guideline matching)
- Tools/workflows: Medical guideline matchers; constrained generation; uncertainty reporting
- Assumptions/dependencies: Regulatory approval; strong guardrails; high-quality, verifiable benchmarks; avoidance of unsupported diagnostic claims
- Finance and risk analysis with backtesting rewards
- Sector: finance
- What: Reasoning agents trained with verifiable rewards via backtests (e.g., compliance checks, process risk assessments)
- Tools/workflows: Backtest harnesses; compliance rule engines; pass@k evaluation of decision trees
- Assumptions/dependencies: Robustly specified reward functions; non-stationarity in data; governance frameworks
- Educational platforms that teach with fork-awareness
- Sector: education
- What: Tutors that highlight logical forks and uncertainty, coaching students through alternate branches; analytics on entropy at key steps
- Tools/workflows: Fork visualization tools; entropy heatmaps; branch exploration exercises
- Assumptions/dependencies: Pedagogical validation; age-appropriate UX; integration into curricula
- Reasoning Potential Certification and audit standards
- Sector: policy/regulation
- What: Require vendors to publish pass@k curves, fork-entropy profiles, and speed–accuracy trade-offs as part of AI certification
- Tools/workflows: Standardized evaluation protocols; reporting schemas; independent test labs
- Assumptions/dependencies: Consensus on metrics; sector-specific benchmarks; regulatory adoption
- Entropy-aware IDEs and “Parallel Reasoning Engines”
- Sector: software/devtools
- What: IDE plugins that surface uncertain code tokens and suggest alternative branches; services that batch-parallelize reasoning steps safely
- Tools/workflows: Entropy overlays; branch explorers; managed parallel-decoding APIs
- Assumptions/dependencies: Reliable entropy estimates; developer acceptance; integration with CI/CD
- Domain-general RLVR pipelines for tasks with weak verifiers
- Sector: ML research, applied AI
- What: Methods to combine verifiable subgoals (code, math) with weak or delayed rewards (planning, dialogue) while maintaining exploration at forks
- Tools/workflows: Hybrid reward shaping; subgoal scaffolding; off-policy correction for heuristic sampling
- Assumptions/dependencies: New algorithmic advances; careful bias–variance trade-offs; task-specific ground-truth proxies
- Energy, logistics, and scheduling optimizers
- Sector: energy, operations
- What: Use AR-trained diffusion reasoners to explore scheduling options, with simulation or constraint solvers providing verifiable rewards
- Tools/workflows: Constraint satisfaction interfaces; simulators; pass@k-guided sampling budgets
- Assumptions/dependencies: High-quality simulators; well-formed constraints; alignment with domain experts
Notes on cross-cutting assumptions and dependencies:
- Verifiable rewards are central: immediate gains rely on domains with clear correctness checks (math answers, unit tests). Long-term adoption in high-stakes domains requires carefully constructed verifiers and safety guardrails.
- Pass@k is used as a proxy for reasoning potential; organizations should align on standardized sampling configurations (temperature, block size, tokens/step) to make results comparable.
- JustGRPO applies AR constraints during training only; diffusion models’ parallel decoding at inference is preserved but must be tuned (e.g., EB sampler, block sizes) to avoid accuracy degradation.
- Compute and observability are necessary: training requires GPUs; inference benefits from token-level entropy visibility to monitor and manage fork-related uncertainty.
Collections
Sign up for free to add this paper to one or more collections.