- The paper introduces certainty-forcing distillation to transform sequential token certainty into a parallel process, addressing a key bottleneck in dLLMs.
- It employs semi-autoregressive masking and temperature-scaled entropy minimization to enforce high token confidence, achieving up to 10.5x speedup on benchmarks like GSM8K and MBPP.
- Experimental results demonstrate that dParallel maintains accuracy while reducing inference steps, highlighting its potential for efficient, real-time language model deployment.
dParallel: Learnable Parallel Decoding for dLLMs
Introduction and Motivation
Diffusion LLMs (dLLMs) have emerged as a compelling alternative to autoregressive LLMs, leveraging bidirectional attention and masked token prediction to enable parallel, random-order text generation. Despite their theoretical potential for highly parallel decoding, open-source dLLMs such as LLaDA and Dream have not realized substantial inference speedups, as they require a number of decoding steps proportional to sequence length to maintain output quality. The core bottleneck is identified as the sequential convergence of token certainty: although dLLMs predict all masked tokens in parallel, high-confidence predictions propagate left-to-right, limiting the number of tokens that can be reliably committed per step.
Certainty Dynamics and Bottleneck Analysis
Empirical analysis reveals that token-level certainty is strongly correlated with prediction accuracy, and that certainty propagates sequentially during the decoding process. At each step, only a small subset of tokens adjacent to known context reach high confidence, while the majority remain uncertain until further context is available. This sequential propagation is visualized in the confidence trajectories of individual tokens, which converge to high certainty in a staggered order.
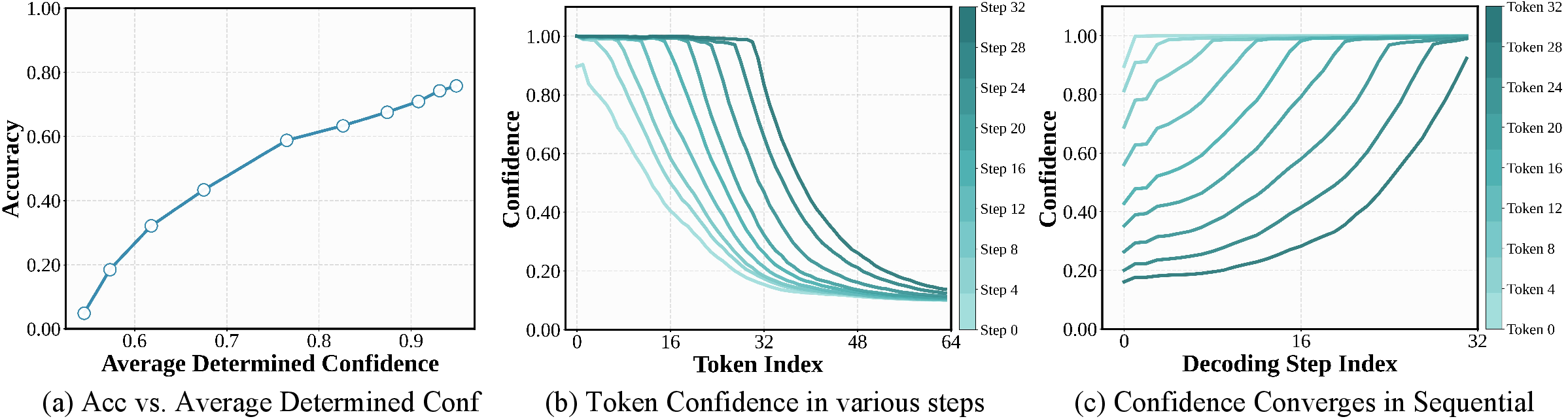
Figure 1: (a) Token confidence correlates with accuracy; (b) confidence propagates sequentially; (c) individual token confidence trajectories.
This dynamic forms the fundamental bottleneck to parallel decoding: committing multiple tokens in parallel at low confidence leads to cascading errors and degraded performance. Existing training paradigms, such as teacher forcing and diffusion forcing, focus on trajectory alignment and do not address the certainty dynamics required for parallelism.
Certainty-Forcing Distillation: Methodology
To address the sequential certainty bottleneck, the paper introduces certainty-forcing distillation, a training strategy that directly leverages token certainty as a signal. The approach involves self-distilling a pretrained dLLM along its original semi-autoregressive generation trajectory, while simultaneously minimizing predictive entropy over correctly predicted masked tokens to enforce high certainty. The training objective combines a cross-entropy consistency loss with a certainty-forcing entropy loss, applied only to tokens predicted correctly by the student model.
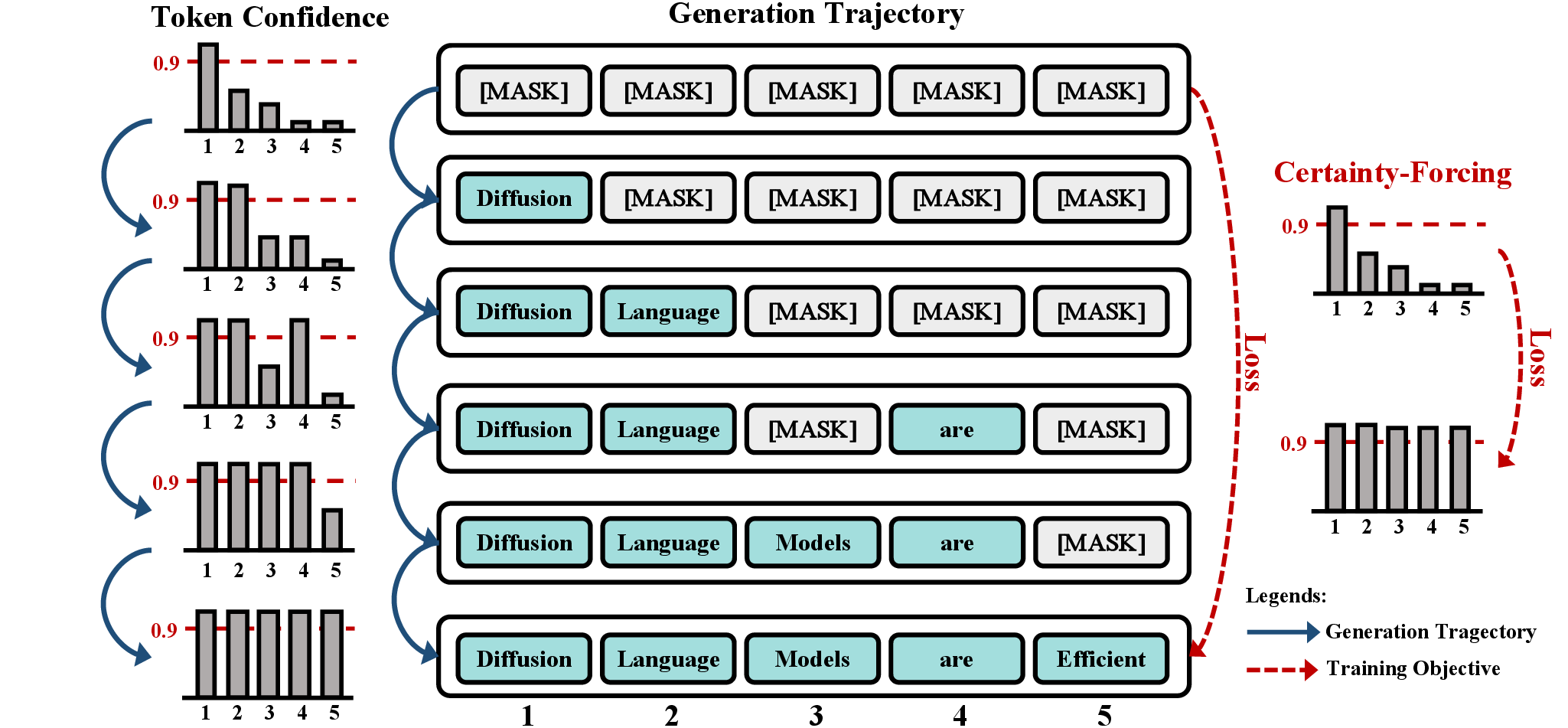
Figure 2: Certainty-forcing distillation enforces parallel certainty along the original generation trajectory.
Semi-autoregressive forward masking is used to simulate the generation process, dividing the sequence into context, active, and future blocks, and applying masking to the active block. The certainty-forcing loss is temperature-scaled to encourage sharper distributions, and a balance hyperparameter β controls the trade-off between trajectory consistency and certainty maximization.
Experimental Results
Extensive experiments are conducted on LLaDA-8B-Instruct and Dream-7B-Instruct across GSM8K, MATH, HumanEval, and MBPP benchmarks. The method is implemented using LoRA for efficient fine-tuning, with training completed in 10 hours on eight A5000 GPUs (24 GB each). During inference, entropy-threshold semi-autoregressive remasking is used, consistent with the training objective.
dParallel achieves dramatic reductions in decoding steps while maintaining accuracy. On LLaDA-8B-Instruct, decoding steps are reduced from 256 to 30 on GSM8K (8.5× speedup, accuracy 76.1%), and from 256 to 24 on MBPP (10.5× speedup, accuracy 40.8%). Similar results are observed on Dream-7B-Instruct, with speedups up to 8.8× and negligible accuracy loss.

Figure 3: dParallel achieves highly parallel decoding, averaging over 8 tokens per step on GSM8K with preserved accuracy.
The speed–accuracy trade-off curves demonstrate that dParallel substantially outperforms confidence-threshold decoding, achieving higher accuracy at the same speedup levels.
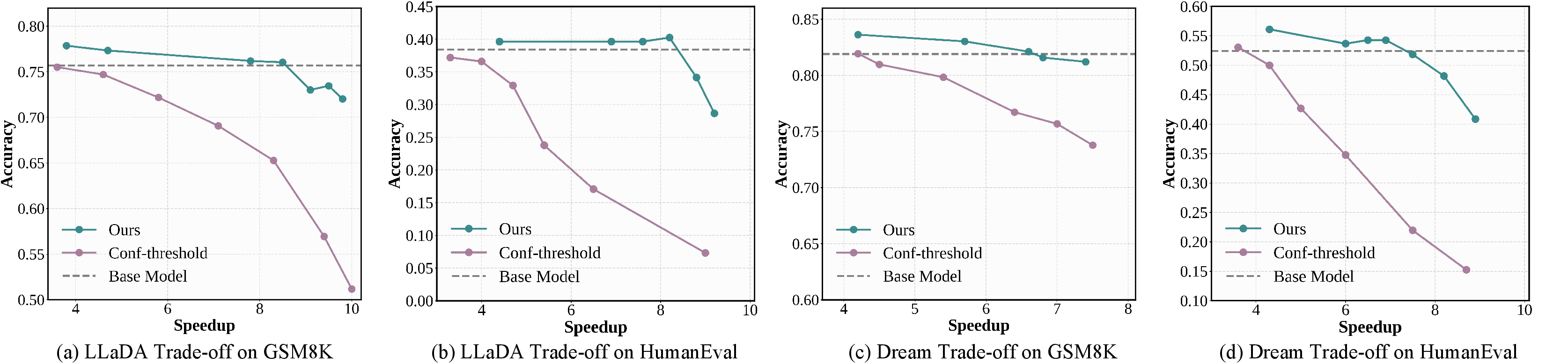
Figure 4: dParallel achieves superior speed–accuracy trade-offs compared to confidence-threshold decoding across benchmarks.
Ablation studies confirm that both the certainty-forcing loss and semi-autoregressive masking are essential for optimal performance. The optimal masking ratio during training is found to be 50%, balancing consistency and certainty signals.
Certainty Convergence and Case Studies
Certainty-forcing distillation transforms the sequential convergence of token certainty into a faster, more parallel process, as visualized in the average token confidence over decoding steps.
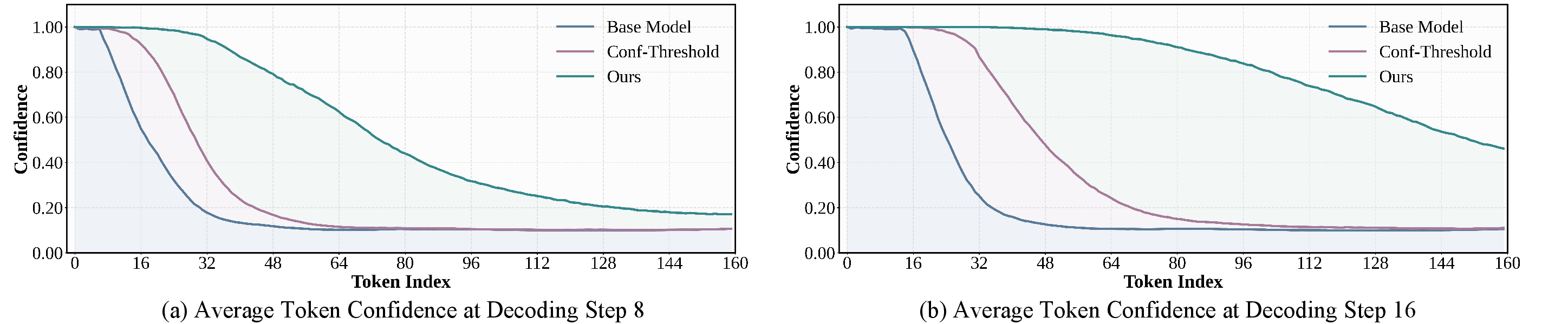
Figure 5: Certainty-forcing strategy reshapes sequential certainty convergence into parallel convergence at decoding steps 8 and 16.
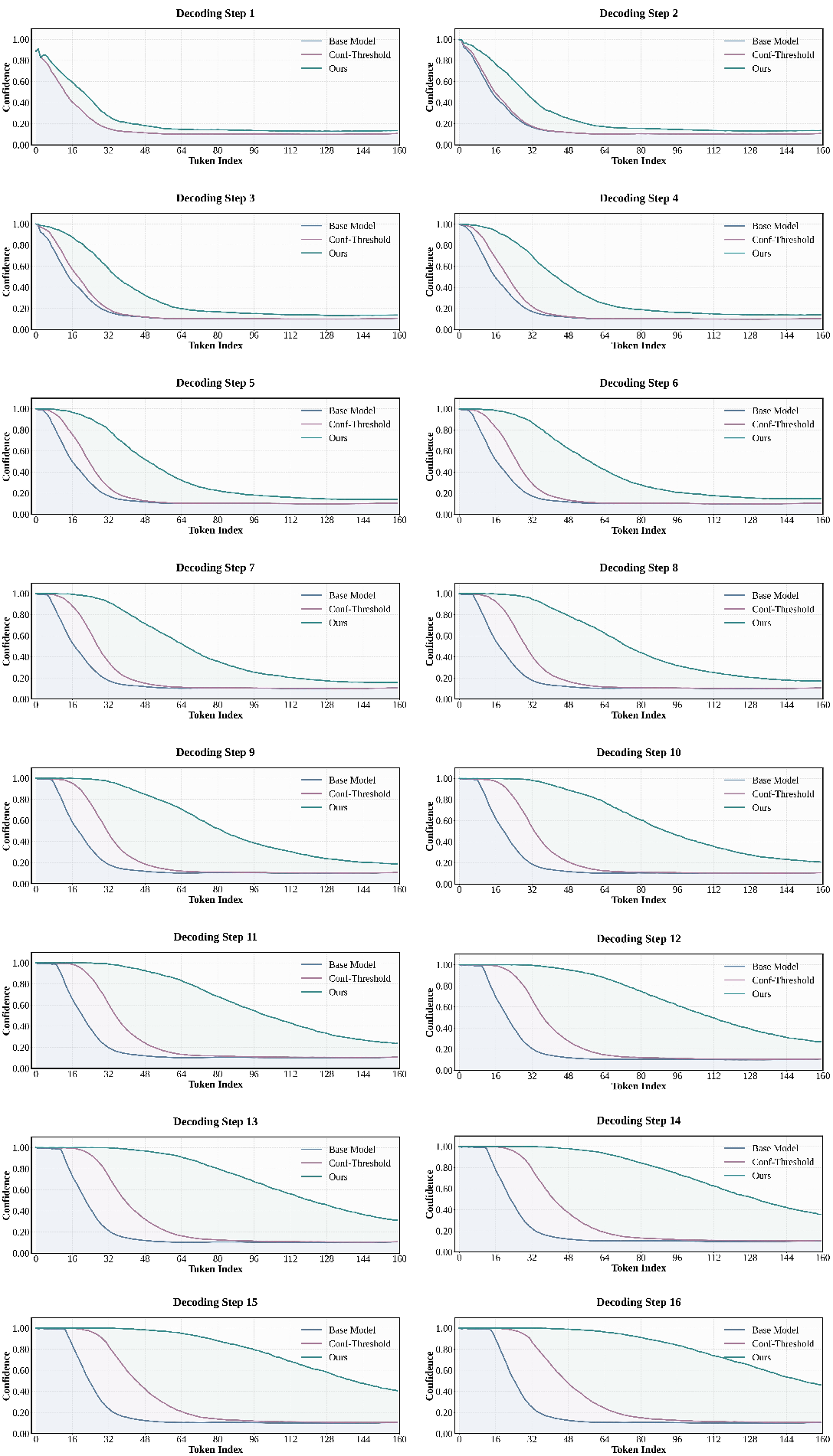
Figure 6: Certainty-forcing enables parallel certainty convergence over the first 160 tokens and 16 decoding steps.
Case studies on chain-of-thought reasoning and code generation tasks further illustrate that dParallel maintains generation quality while reducing decoding steps.

Figure 7: Chain-of-thought reasoning with dParallel on LLaDA-8B-Instruct.

Figure 8: Naive code generation with dParallel on LLaDA-8B-Instruct.

Figure 9: Instruction-based code generation with dParallel on LLaDA-8B-Instruct.
Implementation Considerations
- Resource Requirements: Certainty-forcing distillation is parameter-efficient and can be performed on consumer-grade GPUs with 24 GB memory.
- Training Strategy: LoRA is used for efficient fine-tuning; semi-autoregressive masking and entropy-threshold remasking are critical.
- Hyperparameters: Temperature T for certainty loss and balance β for loss combination require tuning; 50% masking ratio is optimal.
- Deployment: The method is compatible with existing dLLM architectures and does not require architectural changes, facilitating integration into production pipelines.
Implications and Future Directions
The certainty-forcing distillation paradigm establishes a new baseline for parallel decoding in dLLMs, demonstrating that the sequential certainty bottleneck can be overcome with targeted training. This has significant practical implications for reducing inference latency and enabling real-time applications of dLLMs. Theoretically, the work suggests that certainty dynamics are a critical factor in non-autoregressive generation models and opens avenues for further research into certainty-driven training objectives.
Future work may extend certainty-forcing strategies to pretraining, scale up training data, and explore generalization to multimodal and reasoning dLLMs. Limitations include reliance on the base model's performance; certainty-forcing does not improve weak models but unlocks parallelism in strong ones.
Conclusion
dParallel introduces a learnable approach to parallel decoding in dLLMs, leveraging certainty-forcing distillation to overcome the sequential certainty propagation bottleneck. The method achieves substantial reductions in decoding steps and inference latency while maintaining output quality, validated across multiple benchmarks and models. This work provides a foundation for future research on few-step and highly parallel dLLMs, with broad implications for efficient LLM deployment.

