Modeling Language as a Sequence of Thoughts
Abstract: Transformer LLMs can generate strikingly natural text by modeling language as a sequence of tokens. Yet, by relying primarily on surface-level co-occurrence statistics, they fail to form globally consistent latent representations of entities and events, lack of which contributes to brittleness in relational direction (e.g., reversal curse), contextualization errors, and data inefficiency. On the other hand, cognitive science shows that human comprehension involves converting the input linguistic stream into compact, event-like representations that persist in memory while verbatim form is short-lived. Motivated by this view, we introduce Thought Gestalt (TG) model, a recurrent Transformer that models language at two levels of abstraction - tokens and sentence-level "thought" states. TG generates the tokens of one sentence at a time while cross-attending to a memory of prior sentence representations. In TG, token and sentence representations are generated using the same set of model parameters and trained with a single objective, the next-token cross-entropy: by retaining the computation graph of sentence representations written to memory, gradients from future token losses flow backward through cross-attention to optimize the parameters generating earlier sentence vectors. In scaling experiments, TG consistently improves efficiency over matched GPT-2 runs, among other baselines, with scaling fits indicating GPT-2 requires ~5-8% more data and ~33-42% more parameters to match TG's loss. TG also reduces errors on relational direction generalization on a father-son reversal curse probe.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: What if a LLM didn’t just read text word-by-word, but also built and remembered the “thoughts” behind each sentence, like how people do when they read a story?
The authors introduce a new model called Thought Gestalt (TG). Instead of handling language purely as a stream of tokens (tiny pieces of text like words or word parts), TG treats each sentence as a “thought,” makes a compact summary of that thought, and stores it in memory. It then uses those remembered thoughts to understand and generate future sentences more reliably.
What questions did the researchers ask?
They focused on problems that happen when LLMs only learn from surface patterns of words:
- Can a model be more data-efficient (learn well from less training)?
- Can it build a consistent “situation model” of what’s going on (who did what, when, and why), not just copy word patterns?
- Can it avoid common mistakes like the “reversal curse”? For example, if the model sees “The son of Michael is John,” can it also understand the reverse: “The father of John is Michael”?
- Can we improve long-range understanding by summarizing sentences into stable thought-like units and reusing them as memory?
How did they study it?
They built TG, a recurrent Transformer that works at two levels: tokens and sentence-level “thoughts.” Think of it like reading a story one sentence at a time, making a brief note of each sentence’s main idea, and keeping those notes handy while you read the next sentence.
Here’s the basic idea in everyday terms:
- Step-by-step reading: The model reads and generates one sentence at a time.
- Thought summaries: At the end of each sentence, it creates a single vector (a compact summary) that captures the sentence’s overall meaning—the “gestalt.”
- Memory of thoughts: It stores these sentence summaries in a memory, ordered by time.
- Looking back: When generating the next sentence, the model “cross-attends” to this memory (like flipping through your notes to recall earlier parts of the story).
- Single training goal: TG is trained only to predict the next token. There’s no extra sentence-level training task. Importantly, the training feedback (gradients) flows through the memory, so mistakes in later sentences help improve the way earlier sentence summaries are made.
- Keeping training stable: They use practical tricks, such as:
- A “curriculum” that starts with shorter runs of sentences and gradually increases, so the model doesn’t get overwhelmed early on.
- Making the start-of-sentence token carry the previous sentence’s summary, so the first word has helpful context.
- Down-weighting the loss for very frequent and easy-to-predict markers like end-of-sentence (EOS), so learning focuses on harder, meaningful tokens.
If “attention” sounds technical, you can imagine it like this: while writing the next sentence, the model glances back at neatly summarized flashcards (the sentence memories) to stay consistent about characters, events, and facts.
What did they find?
The TG model performed better than a standard GPT-2-style model in several ways:
- It needed less data to reach the same accuracy:
- About 5–8% fewer training tokens.
- It needed fewer parameters (smaller models) to reach the same accuracy:
- About 33–42% fewer parameters.
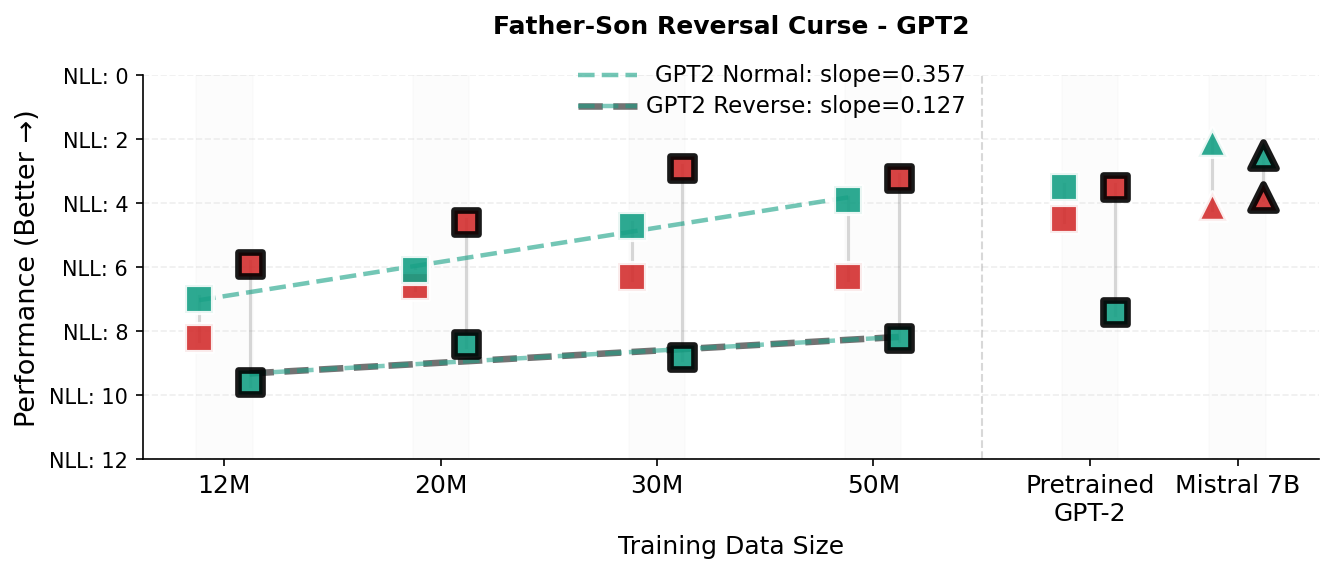
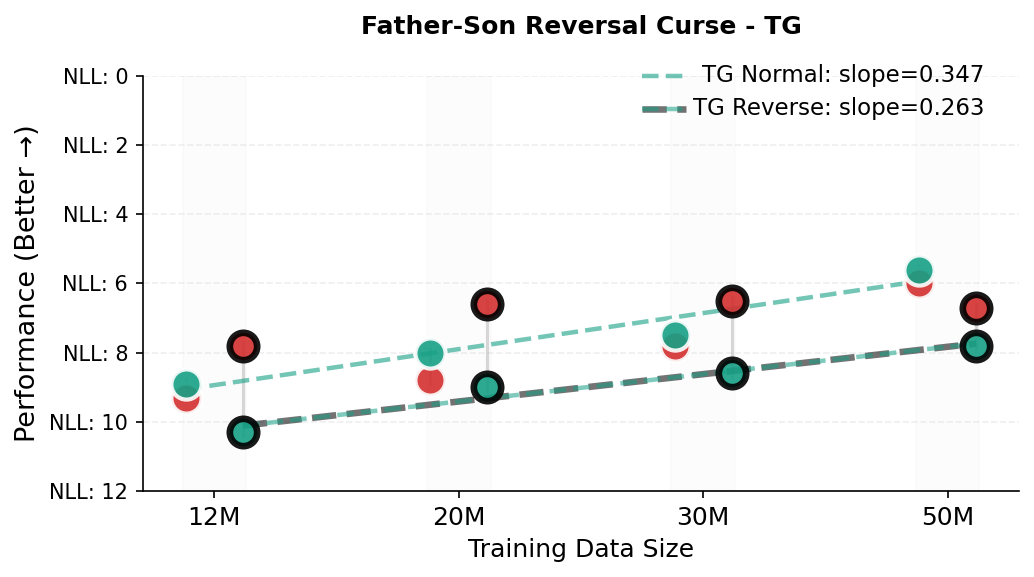
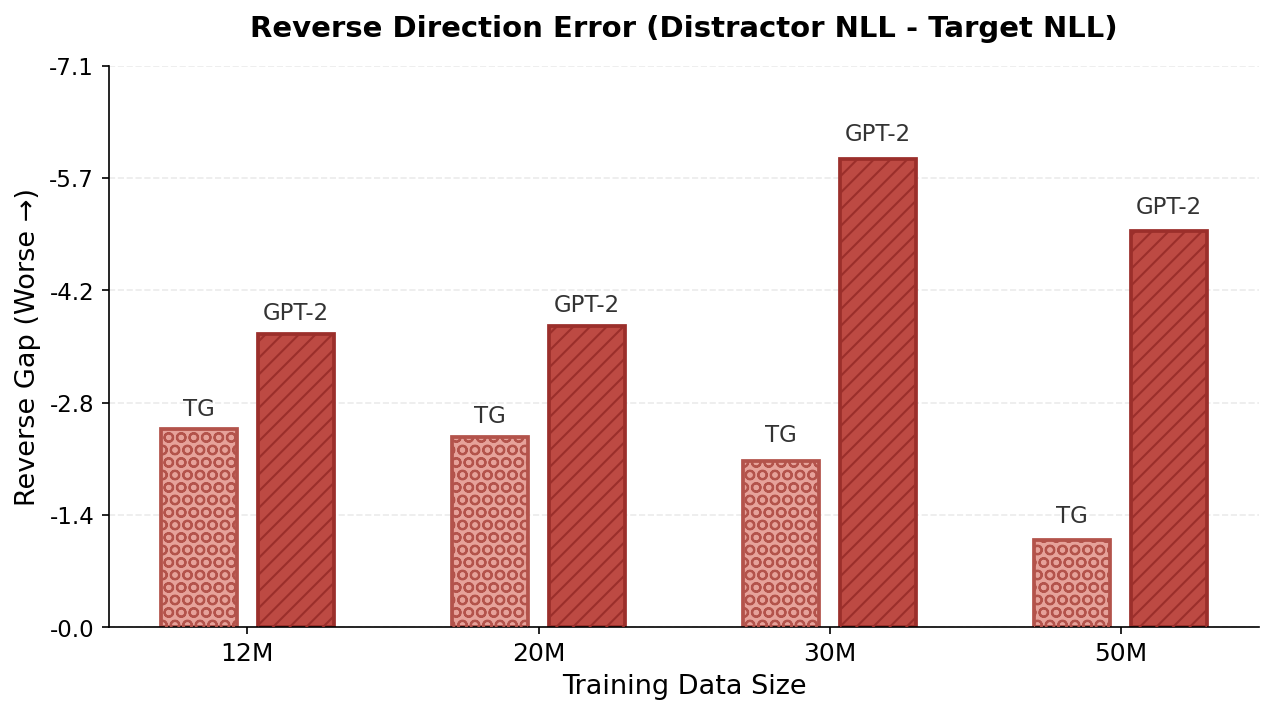
- It made fewer “direction” mistakes in relationships (reversal curse):
- In a father–son test, TG more quickly learned that “The father of John is Michael” follows from “The son of Michael is John,” while standard models struggled because they often treat “A is B” as unrelated to “B is A.”
- It beat several baselines:
- Just adding sentence markers to GPT-2 helped a bit, but not as much as TG.
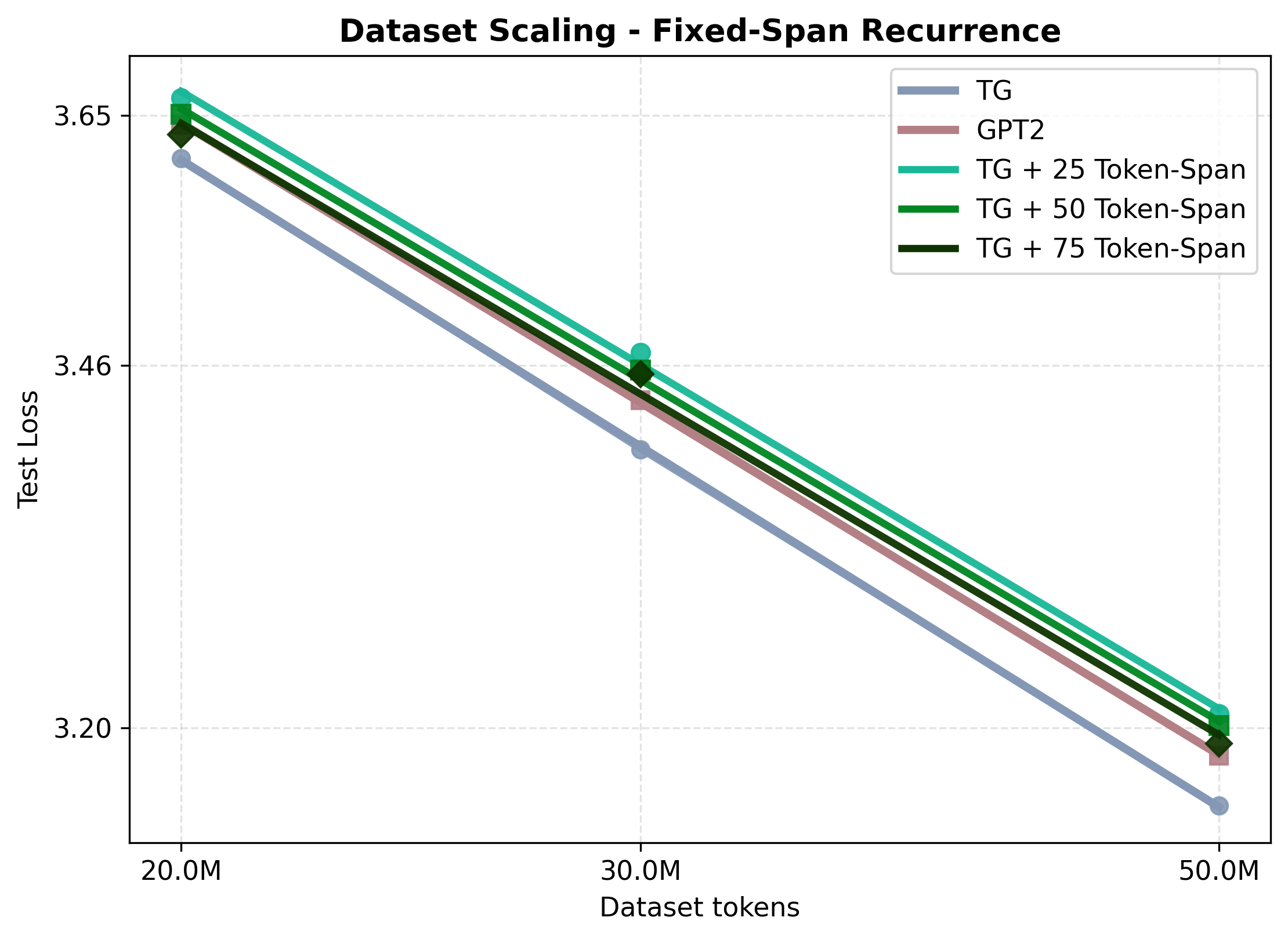
- Replacing sentences with fixed-size token chunks (ignoring real sentence boundaries) was worse than TG.
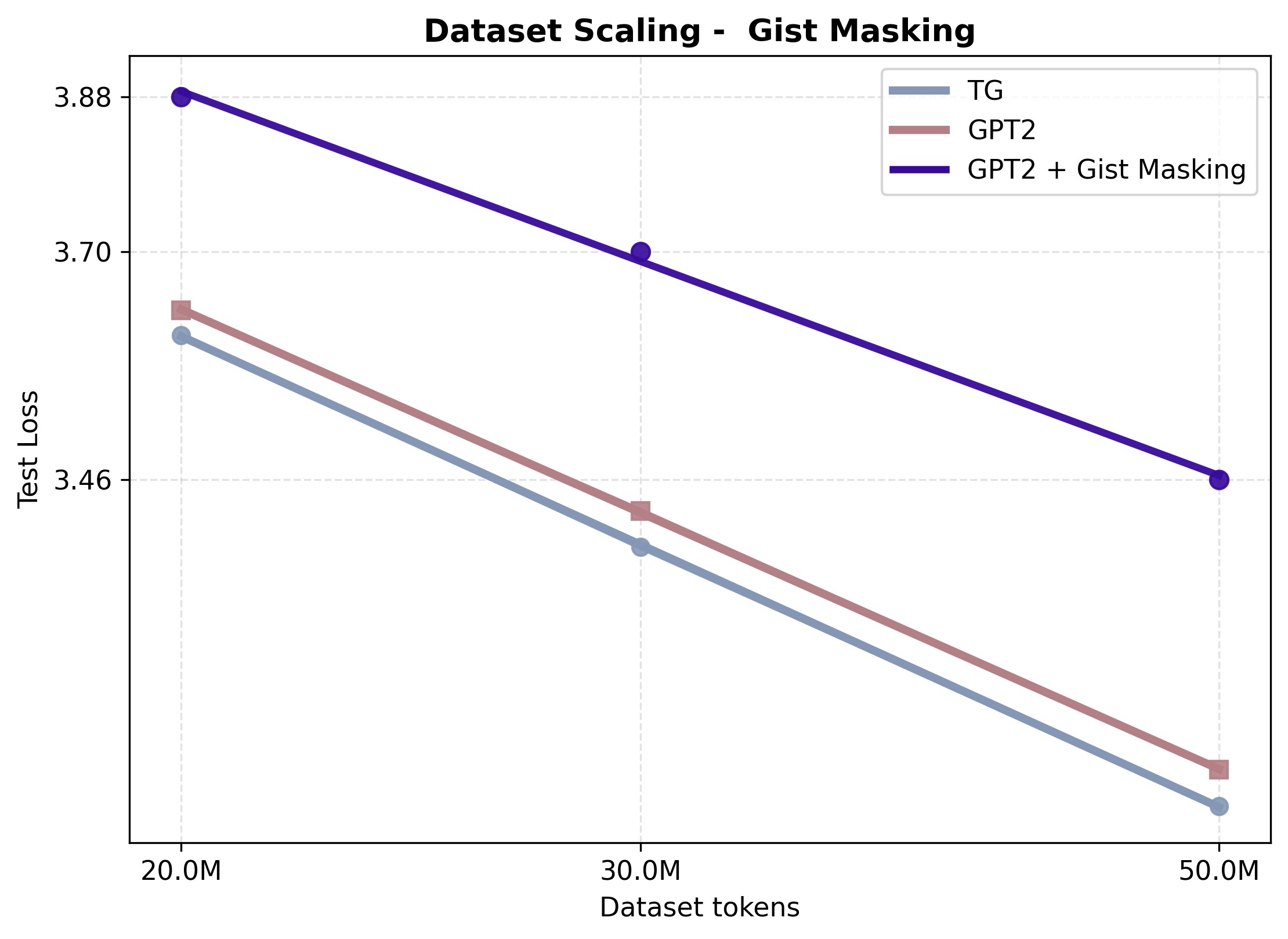
- Using “gist tokens” in-context (without the stable external memory and recurrence) performed much worse; summaries have to be fully contextualized and reused reliably across layers, not formed on the fly alongside all tokens.
They also ran ablation tests (turning features on/off) and found:
- The biggest factor: allowing training feedback to flow through the memory is essential. If they “detach” the sentence summaries, performance drops a lot.
- Adding more capacity (more attention within each layer) can further help.
- Helpful extras—like seeding the start of a sentence with the previous summary, and the sentence-length curriculum—give small but steady gains.
Why does this matter?
- It makes models more like human readers: Humans don’t remember every word; we remember the events, people, and how things connect. TG tries to do the same by storing sentence-level thoughts.
- Better understanding with less data: If models can learn and reuse compact, meaningful summaries, they may need fewer examples to learn well.
- Fewer silly mistakes: By relying on thought-level memory (not just word order), models can better understand relationships and facts over long passages.
- A path to stronger long-term memory: Thought-aligned chunks (like sentences) are natural units to store and retrieve later, which could improve long-context tasks such as analyzing entire documents or multi-step reasoning.
In short, TG shows that teaching models to remember and use sentence-level “thoughts” can make language understanding more stable, more efficient, and more human-like.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete, unresolved issues and open questions that emerge from the paper’s design, experiments, and claims.
- External validity at scale: Does TG’s advantage (2–4% PPL, 5–8% data efficiency; 1.33–1.42× parameter efficiency) persist at larger model sizes (hundreds of millions to multi‑billion params) and training corpora (hundreds of billions to trillions of tokens)?
- Domain generalization: How does TG perform beyond Wikipedia (e.g., books, news, web, code, conversational dialogue, scientific text) and under domain shift?
- Multilingual applicability: Can TG’s sentence‑aligned memory and segmentation pipeline transfer to languages with different punctuation conventions and sentence boundary ambiguity? What adjustments are needed for languages without clear sentence markers?
- Dependence on sentence segmentation: How sensitive are results to the specific sentence splitter (SaT Capped), its hyperparameters (e.g., L=64 cap), and segmentation errors? What happens if segmentation quality degrades?
- Thought vs. sentence boundaries: Since sentences are only proxies for thoughts/events, can TG learn or adapt boundaries (e.g., learned event segmentation, discourse units, paragraphs) and does this improve performance relative to sentence‑based segmentation?
- Maximum sentence length cap (L=64): What is the effect of truncating or splitting long sentences on semantic integrity and downstream performance? How should L be chosen or adapted dynamically?
- Memory capacity (M=40) design: What are the accuracy–compute trade‑offs of increasing M, and is there an optimal M for different data/model sizes and domains?
- Memory retrieval mechanism: Would content‑based or hybrid (content+recency) retrieval outperform the current recency‑only memory of last M sentence vectors?
- Memory selectivity and sparsity: Can TG learn to store or drop sentences selectively (e.g., learned write gating, utility estimation) to manage memory load and reduce compute?
- Memory representations: Are single vectors per sentence sufficient? Would richer per‑sentence representations (e.g., multiple slots, key–value disentanglement, entity‑centric factors) yield better generalization?
- Positional encoding for memory: How do alternative sentence‑index encodings (e.g., ALiBi, rotary) or injecting position into values/queries affect robustness and scaling?
- Cross‑attention placement and cost: What is the best layerwise pattern (e.g., only upper layers vs all layers) to balance compute with gains? What is the latency and memory footprint overhead at inference for varying M and number of cross‑attention blocks?
- Gradient flow through memory at scale: How do training stability, memory consumption, and convergence behave as the backprop depth (stream length S) increases? Are there vanishing/exploding gradient issues with long streams?
- Curriculum schedule sensitivity: How sensitive are results to the chunk‑size curriculum (initial S=30, +12 every 5 epochs)? Are there better curricula, adaptive schedules, or alternative stabilization strategies?
- Training efficiency reporting: Wall‑clock comparisons, FLOPs/token, and energy/compute cost vs perplexity were not reported; what is TG’s true end‑to‑end efficiency relative to strong baselines under matched hardware?
- Inference throughput and caching: How does TG’s memory cross‑attention interact with KV caching and streaming decoding in long generations? What are the best caching strategies for sentence memory across layers?
- EOS down‑weighting: How robust is the chosen reweighting (1.0→0.05 after epoch 1) across datasets and scales? Does it inadvertently impair boundary learning or generation quality?
- Context seeding via previous sentence rep: What is the effect of this design on error propagation and exposure bias across multiple sentences? What is the best strategy for the first sentence in a document (no prior seed)?
- Choice of sentence representation layer (ℓs=7): Beyond a single ablation to the last layer, what is the optimal layer or multi‑layer aggregation strategy (e.g., learned pooling, attention over layers)?
- Sentence head design: Would deeper or structured sentence heads (e.g., bottleneck MLPs, multi‑head pooling, contrastive pretext layers) improve the semantic quality of gestalts without auxiliary losses?
- Probing the gestalt representations: What information do sentence vectors actually capture (entities, coreference links, temporal/causal structure)? Are they robust across paraphrases and adversarial perturbations?
- Downstream evaluation breadth: How does TG affect tasks beyond language modeling (e.g., QA, open‑domain factuality, long‑context reasoning, summarization, multi‑hop, narrative coherence, coreference, temporal/causal reasoning)?
- Long‑context capabilities: With M tuned to approximate ~1k tokens, can TG scale to 8k–128k contexts? How does it compare to long‑context baselines (e.g., Transformer‑XL, RMT, Memorizing Transformers, Hyena/Mamba) on long‑range tasks?
- Fairness of gisting comparison: The gist baseline here uses a single <EOS> token per sentence as the compression point. Would stronger gisting variants (multiple learned gists, layerwise accumulation, training schedules) reduce the gap to TG?
- Stronger baselines: How does TG compare to modern recurrent/memory architectures (Transformer‑XL variants, Compressive Transformers without/with reconstruction, RWKV, Mamba) under matched budgets?
- Retrieval‑augmented extensions: Can TG’s sentence vectors serve as natural retrieval units for long‑term memory or external kNN stores? How do retrieval indexing and chunking strategies interact with TG?
- Reversal‑curse generality: Does TG’s improvement extend beyond father–son to a broader set of asymmetric relations (capital–country, hypernymy, birth‑place), symmetric/antisymmetric constraints, and multi‑hop relational inference?
- Normal vs reversed trade‑off: TG shows a slight deficit in “copy‑paste” (normal) completion early on; can one eliminate this gap without losing reversal robustness (e.g., via training schedules or architectural tweaks)?
- Document‑level coherence: Does sentence‑by‑sentence generation degrade global coherence, discourse structure, or stylistic continuity? Human or automatic discourse evaluations are needed.
- Robustness to noisy or unpunctuated text: How does TG perform on genres with unreliable punctuation (social media, speech transcripts) and on lists/tables/code where sentence segmentation is ill‑defined?
- Training–inference mismatch: Training slices streams to cap backprop depth, while validation/test are not sliced. How does this mismatch affect generalization to much longer dependencies at inference?
- Seed and variance reporting: Per‑seed variability, confidence intervals, and statistical significance of gains were not reported; how stable are TG’s improvements across random initializations?
- Tokenization issues in probes: The father–son probe assumes single‑token names; how do multi‑token entities, subword splits, and OOV names affect directionality evaluations?
- Safety and factuality: Does TG reduce hallucination, contradiction, or entity drift in longer generations? No safety/factuality metrics were reported.
- Transfer and fine‑tuning: Do sentence gestalts transfer to downstream tasks (e.g., can they be reused as features)? How does instruction‑tuning/RLHF interact with TG’s memory and representations?
- Error analysis of contextualization claims: The paper motivates TG by contextualization errors, but does not conduct targeted diagnostics (e.g., layerwise disambiguation probes, lost‑in‑the‑middle tests) to verify reduced contextualization failures.
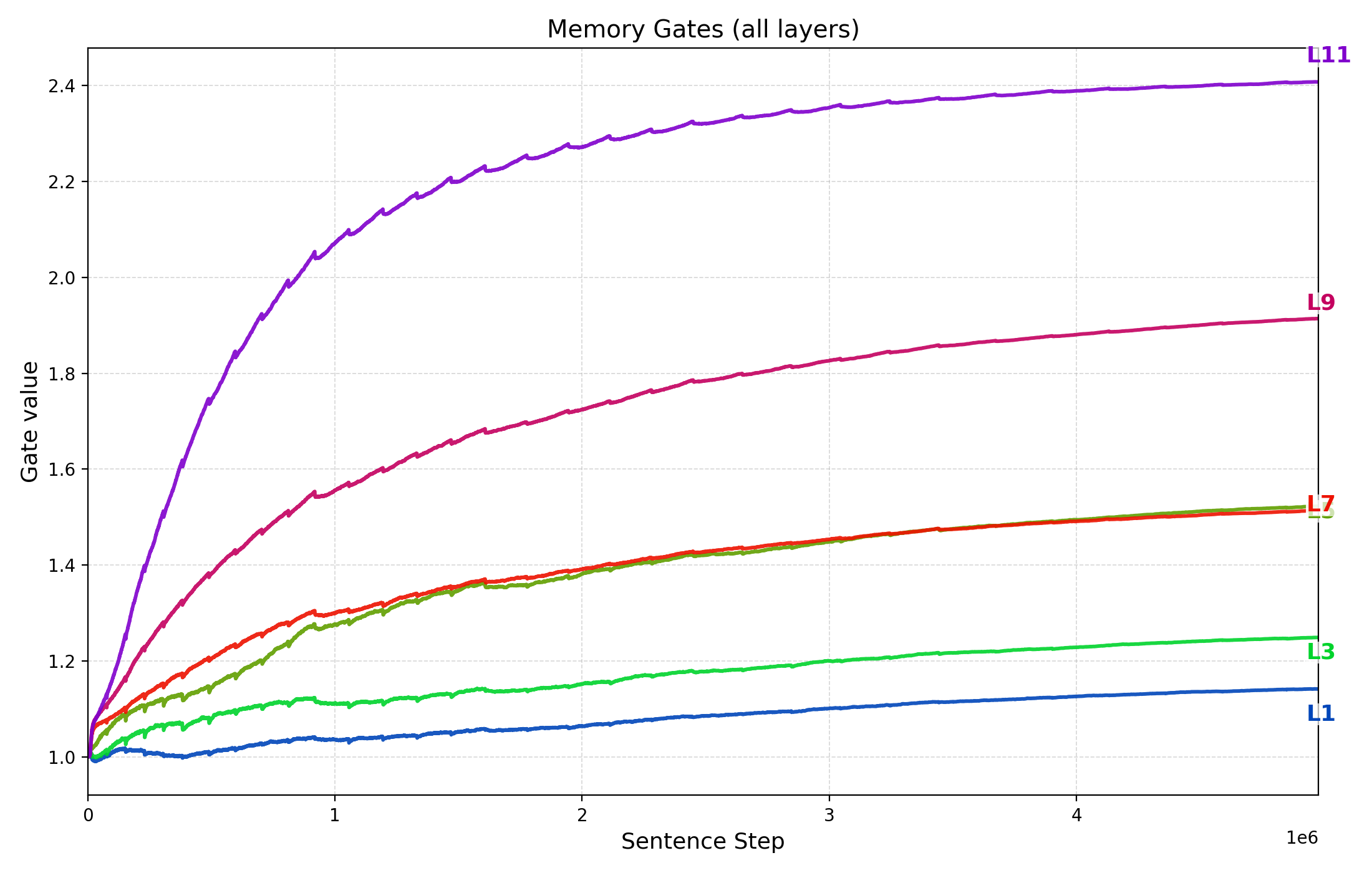
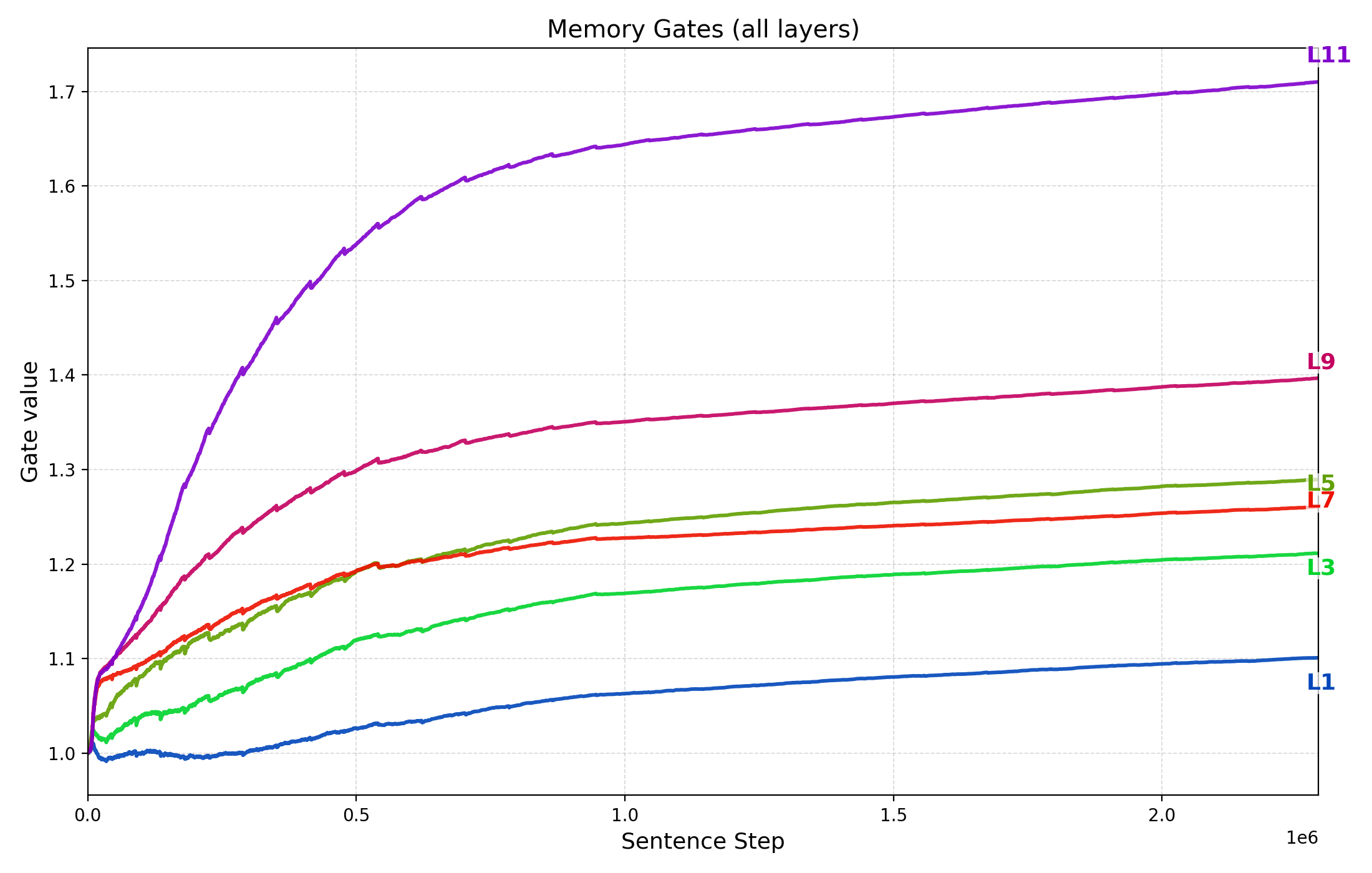
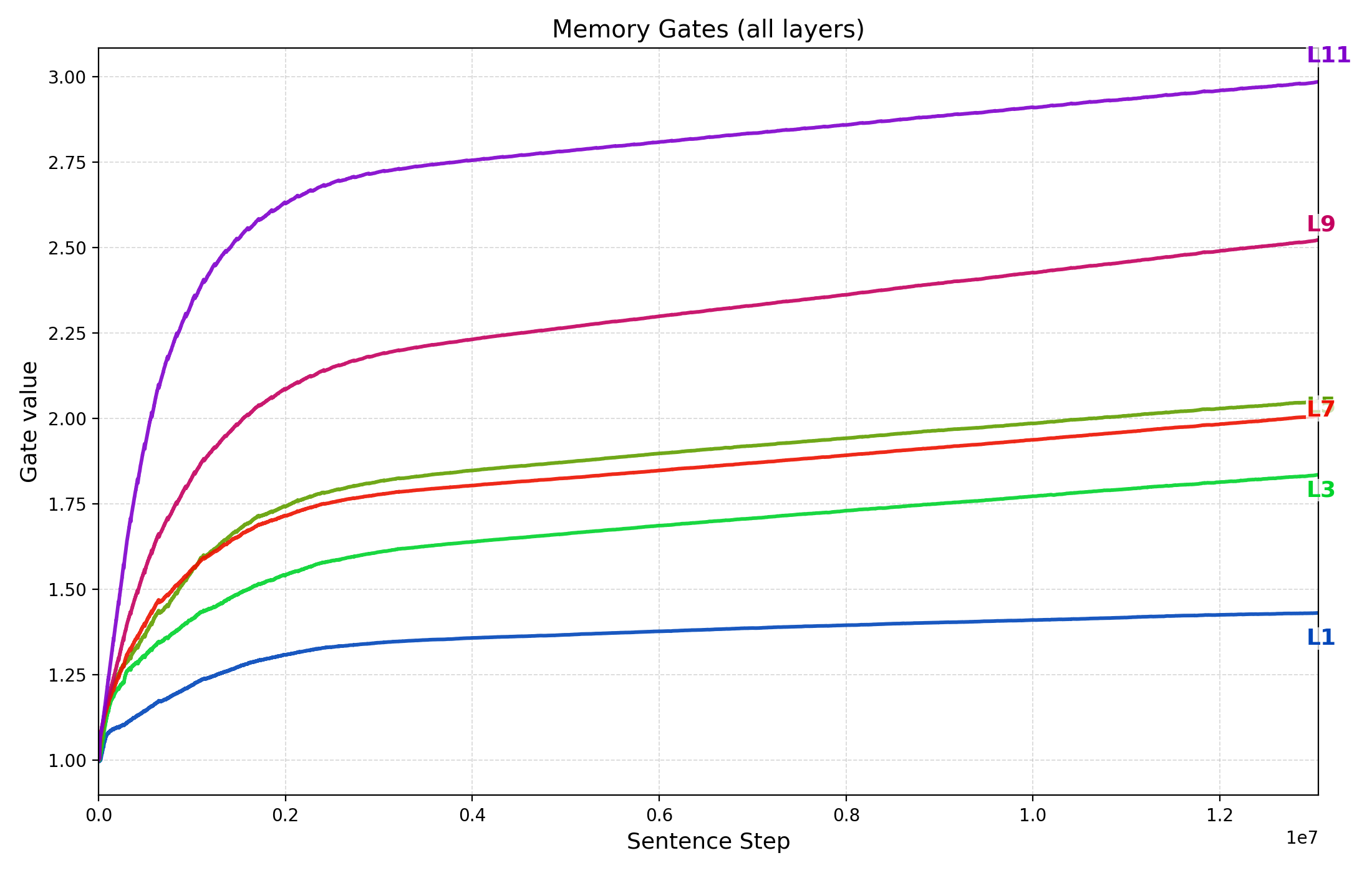
- Memory gating analysis: How do learned memory gates evolve across layers and training, and how do they correlate with performance or domain shifts?
- Open‑source reproducibility: Details on code, training scripts, and complete ablation tables (some truncated) are needed to reproduce results and verify implementation‑sensitive choices.
Glossary
- AdamW: An optimizer variant that decouples weight decay from gradient updates to improve training stability. "We optimize with AdamW (, , weight decay $0.01$) using a peak learning rate of and a cosine schedule with 2\% warmup."
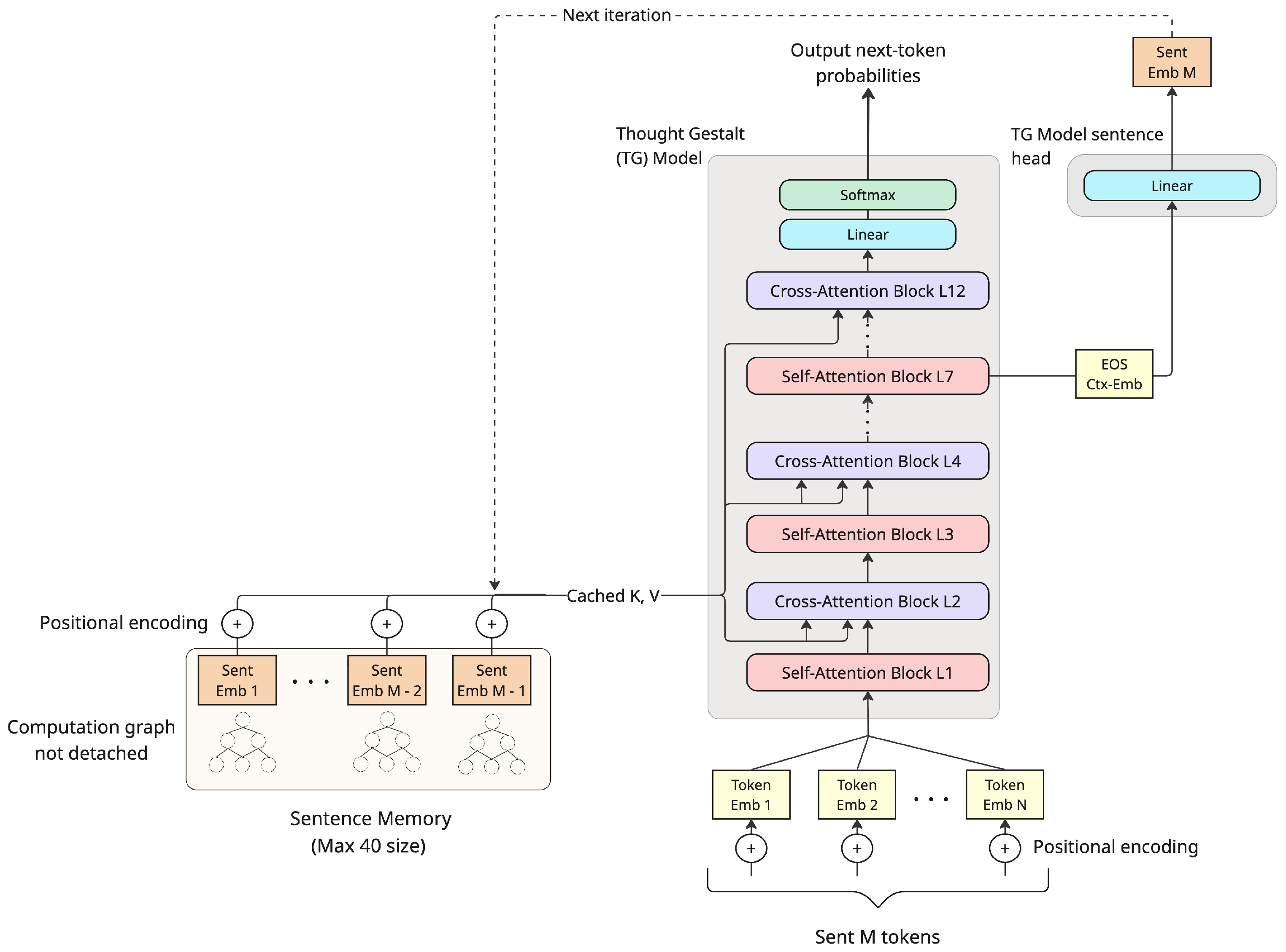
- Additive attention-bias mask: A bias added to attention scores to constrain which tokens can attend to which others. "applies an additive attention-bias mask that restricts each token to attend causally within its own sentence, while accessing previous sentences only via each sentenceâs last token, <EOS>, acting as a âgistâ token."
- AutoBLEU: An automatic metric for evaluating sentence-level reconstruction quality via BLEU. "We selected this method as it achieves the highest AutoBLEU scores for sentence-level reconstruction in a similar architecture~\citep{LCM2024}."
- AutoCompressors: A method that recursively summarizes document segments into short vectors for long-range conditioning. "AutoCompressors \citep{chevalier2023autocompressors} apply a similar idea at the document level, recursively summarizing segments into short vectors that are fed back to the model, enabling long-range conditioning with only a few learned summaries."
- Block-Recurrent Transformers: Architectures that process blocks of tokens recurrently with a state carried across blocks. "Block-Recurrent Transformers apply a Transformer layer recurrently over blocks of tokens, with a recurrent state that each block attends to, combining local self-attention within a block with an RNN-like state that carries information across blocks \citep{hutchins2022blockrecurrent}."
- BOS token (<BOS>): A special start-of-sentence token used to seed generation context. "The <BOS> token enables the TG model to predict the first lexical token of a new sentence; it sets the context to a non-empty state to enable cross-attending to the sentence memory."
- Causal multi-head attention: Attention constrained to respect autoregressive order so tokens only attend to past positions. "Each self-attention block is pre-norm, causal multi-head attention with residual connections."
- Compressive Transformers: Models maintaining a two-tier memory with auxiliary reconstruction losses for older activations. "Compressive Transformers, in contrast, build a two-tier memory of recent raw activations and older compressed activations, trained with auxiliary reconstruction losses \citep{rae2019compressivetransformer}."
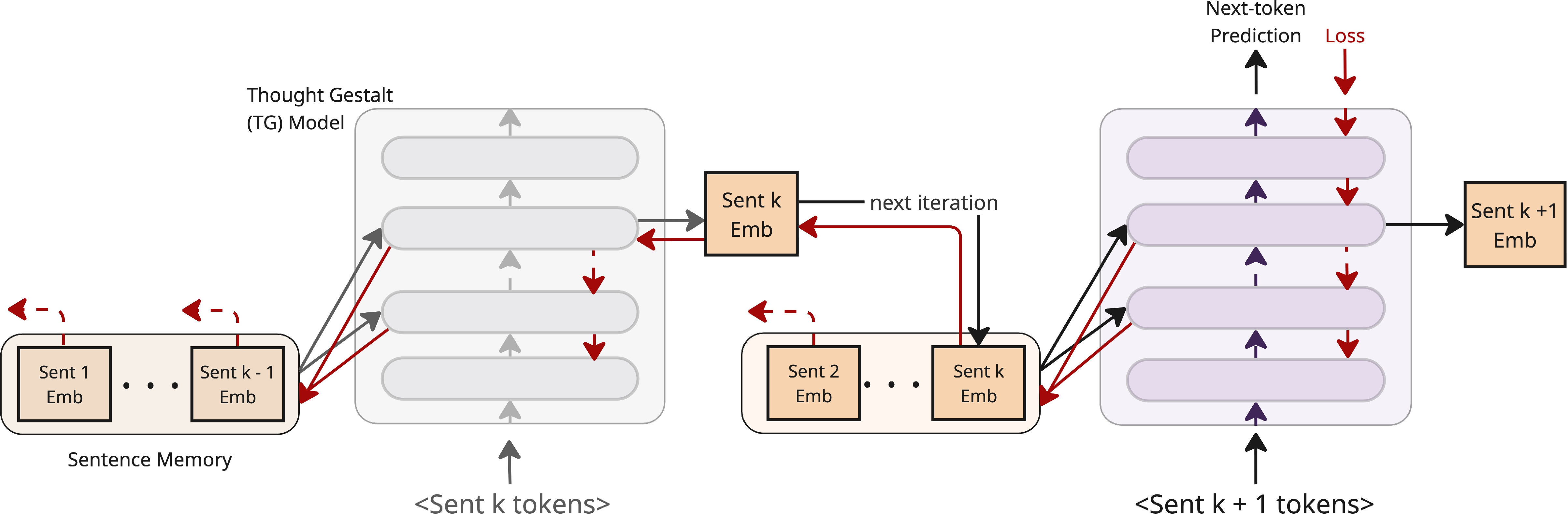
- Computation graph: The graph of operations retained for gradient backpropagation through earlier computations. "by retaining the computation graph of sentence representations written to memory, gradients from future token losses flow backward through cross-attention to optimize the parameters generating earlier sentence vectors."
- Context seeding: Initializing the start-of-sentence state with prior context rather than a static embedding. "Context seeding."
- Cosine schedule: A learning-rate schedule that varies smoothly following a cosine curve. "a cosine schedule with 2\% warmup."
- Cross-attention: Attention from current token states to external memory representations. "predicts the tokens of one sentence at a time while updating and attending to an abstracted memory of sentence representations."
- Curriculum (sentence-stream curriculum): A training scheme that gradually increases sequence length/depth to stabilize optimization. "Sentence-stream curriculum (chunk-size curriculum)."
- d_model vector: The standard Transformer hidden dimension used for representations. "Each sentence representation is a d_model vector that captures the sentenceâs holistic meaning, or "gestalt," rather than merely summing its tokens."
- Down-weighting: Reducing the contribution of frequent/easy targets in the loss to mitigate imbalance. "Down-weighting frequent boundary token (EOS)."
- End-to-end training: Training all components jointly via a single objective without auxiliary losses. "and confirm that end-to-end training of sentence representations via retaining gradient flow through memory, is essential for the observed gains (Table~\ref{tab:ablation_summary})."
- EOD marker (<EOD>): A special end-of-document token appended before EOS to signal document termination. "For the final sentence of a document, we append an additional <EOD> marker before the <EOS> to signal the end of text generation."
- EOS token (<EOS>): A special token marking sentence termination and the extraction point for sentence vectors. "The <EOS> token marks the end of sentence generation and serves as the designated position for extracting the hidden state of sentence representation, "
- External differentiable memory: A memory module whose contents are updated through backpropagation, separate from token caches. "its recurrent state resides in an external differentiable memory of sentence-level gists rather than token-level caches or memory tokens encoding arbitrary token sequences"
- Father–son reversal curse: A probe evaluating whether models can invert relational direction in context. "TG also reduces errors on relational direction generalization on a father--son reversal curse probe."
- Frequency-aware reweighting: Adjusting loss weights based on token frequency to correct imbalance. "we apply a frequency-aware reweighting of the token-level loss that down-weights <EOS> targets after an initial warm-up epoch"
- Gisting: Compressing prior context into learned summary tokens that subsequent tokens attend to. "Gisting for LLMs inserts special âgist" tokens in context after the prompt and modifies attention masks so that gist tokens attend to the full prompt, while later tokens attend only to the gists"
- Gradient truncation: Cutting off gradient flow at cached states to limit backpropagation depth. "providing segment-level recurrence but truncating gradients at the cached states"
- Kaplan-style scaling behavior: Empirical power-law relationships between loss and data/parameters. "Kaplan-style scaling behavior."
- kNN retrieval: Nearest-neighbor lookup over stored activations during inference. "can be queried with kNN retrieval at inference time, extending the effective context while keeping the memory non-differentiable \citep{wu2022memorizing}."
- Learnable memory gate: A scalar parameter that modulates cross-attention contributions from memory. "Each cross-attention block has a scalar, learnable memory gate $g_{\text{mem}^{(\ell)}$ that scales the cross-attention increment before it is added back via the residual path."
- Memorizing Transformers: Models that use an external key–value store of past activations for retrieval. "Memorizing Transformers, on the other hand, add an external key--value store of past activations that can be queried with kNN retrieval at inference time"
- Negative log-likelihood (NLL): A loss metric measuring confidence in target tokens; lower is better. "We evaluate the model distribution at the first answer position and report the negative log-likelihood (NLL; in nats) of two candidates"
- Next-token cross-entropy: The standard LM objective to predict the next token in sequence. "trained with a single objective, the next-token cross-entropy"
- Non-embedding parameters: Model parameter count excluding token embedding matrices. "(M non-embedding parameters)"
- Positional encodings (sinusoidal): Deterministic encodings injected to represent sequence positions. "denotes sinusoidal positional encodings (sentence-index positions) added to the keys only."
- Pre-norm: Layer normalization applied before the attention/FFN blocks rather than after. "Each self-attention block is pre-norm"
- Recurrent Memory Transformer: An architecture with memory tokens passed and updated between segments. "Recurrent Memory Transformer adds dedicated memory tokens that are passed between segments and updated by self-attention"
- Reversal curse: The tendency of LMs to fail to infer inverse relations from one direction of training. "the reversal curse shows that models trained on "A is B" often fail to infer "B is A,""
- Role–filler propositions: Structured representations binding roles to entities within an event. "from which role–filler propositions can be decoded."
- SaT Capped: A sentence boundary detection method robust to punctuation with length capping. "and then splitting text into sentences using the âSaT Capped'' method."
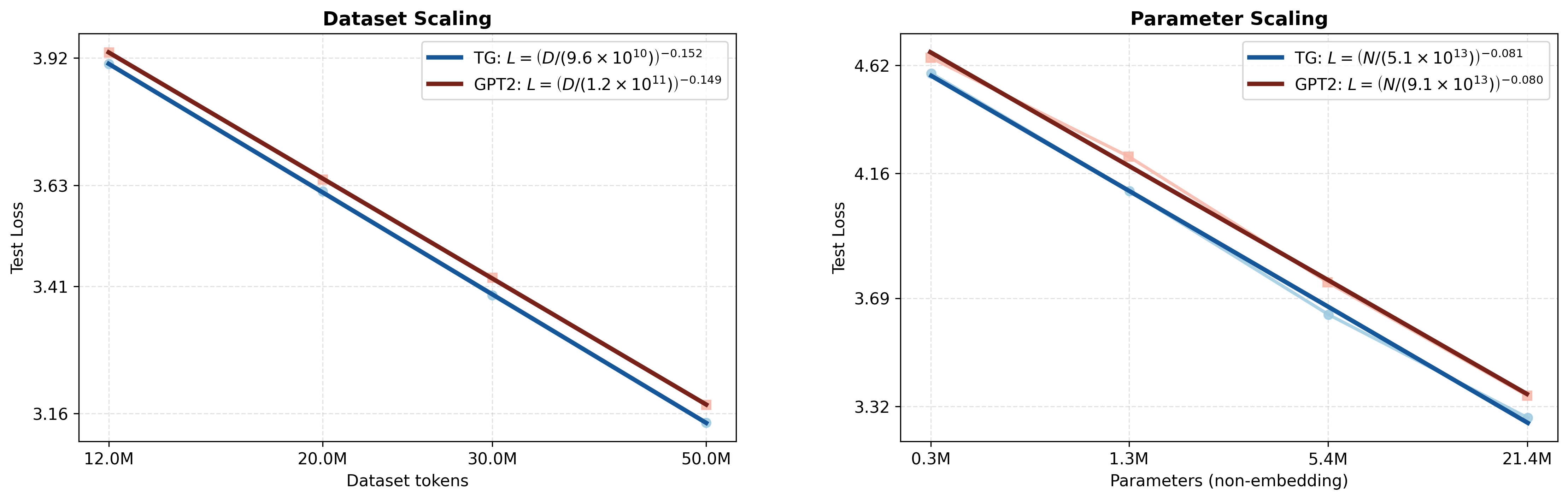
- Scaling exponent: The slope of power-law loss improvements with data/parameters in log–log space. "Fitting a power law to the test loss yields similar scaling exponents for the two models (TG: ; GPT-2: )"
- Scaling law: Empirical relationships showing loss decreases as a power of data or parameters. "We quantify the data and parameter efficiency of Thought Gestalt (TG) using the empirical scaling-law framework of \citet{kaplan2020scaling}."
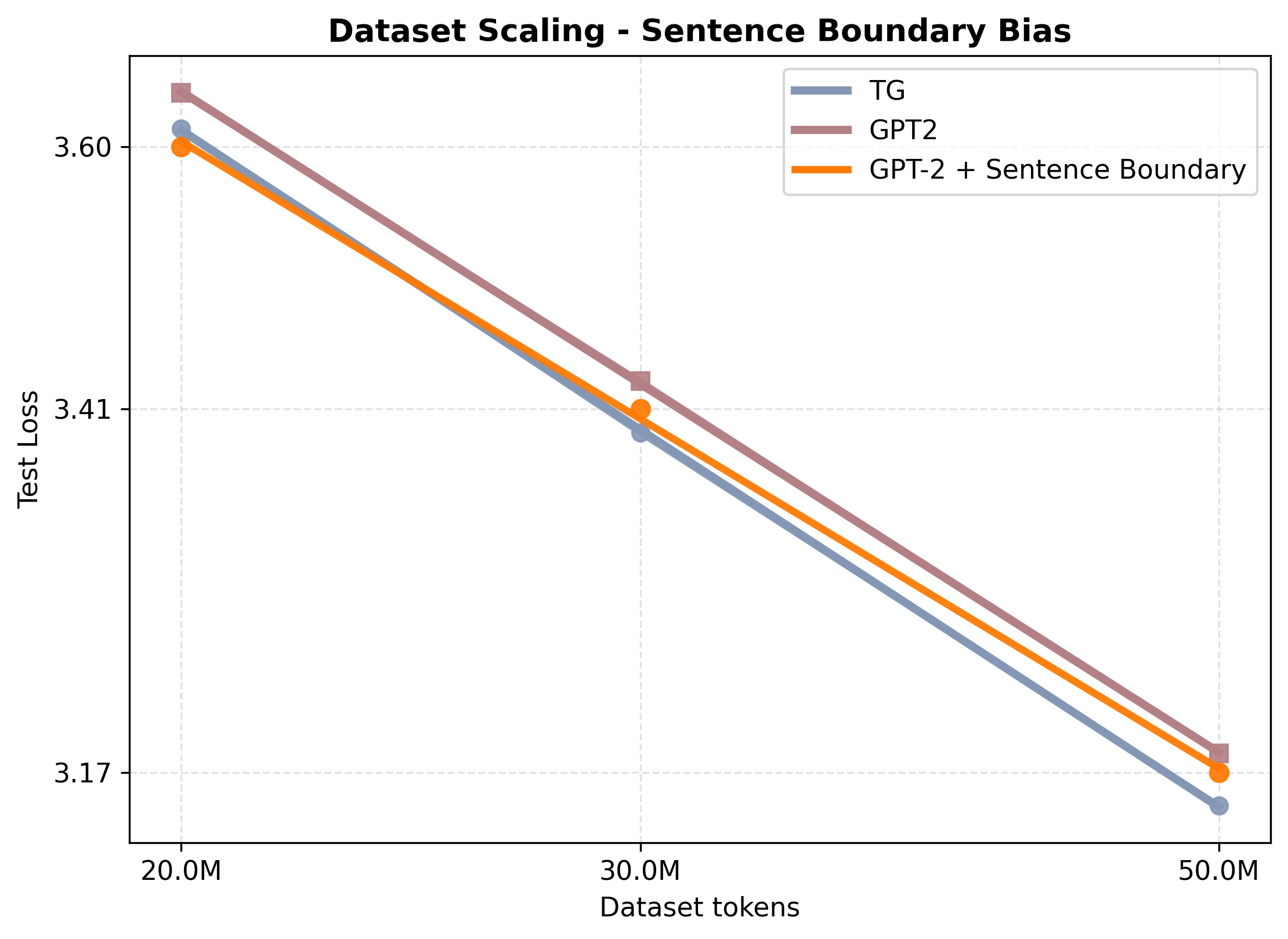
- Sentence boundary bias: Inductive bias introduced by explicitly marking sentence boundaries in token streams. "GPT-2 with Sentence Boundary Bias"
- Sentence Gestalt model: A recurrent model mapping word sequences to holistic event representations. "TG is \vspace{-0.05cm} inspired by the Sentence Gestalt model \citep{stjohn1990learning}, a recurrent network that incrementally maps a sequence of words onto a single distributed event representation"
- Sentence head: A linear projection used to extract a sentence-level vector from the EOS hidden state. "EOS at layer~7 is projected by a small linear âsentence headââ to produce the sentence vector."
- Sentence streams: Contiguous sequences of sentences used to bound gradient depth during training. "we slice training documents (not validation or test documents) into contiguous sentence streams of at most sentences."
- SimCSE: A contrastive sentence embedding method aligning different views of the same sentence. "Contrastive methods such as SimCSE \citep{gao2021simcse} and related sentence-embedding models"
- Token-span recurrence: Processing fixed-length token windows as units for recurrence rather than sentences. "Fixed Token-Span Recurrence, which replaces TG's sentence-level processing with fixed-length token windows"
- Transformer-XL: A Transformer variant that caches past hidden states to extend context via recurrence. "Transformer-XL caches hidden states from previous segments and lets the current segment attend to them"
- Weight decay: L2-like regularization applied to weights to reduce overfitting. "weight decay $0.01$"
- WikiText-103: A benchmark corpus used for LLM pretraining and evaluation. "All models are pre-trained on fixed subsets of the WikiText-103 training split"
Practical Applications
Below is a synthesized map of practical, real-world applications that follow from the paper’s findings and innovations around the Thought Gestalt (TG) model. Each item notes sectors, possible tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- TG-based pretraining for small–mid-size LMs (compute- and data-constrained settings)
- Sectors: software/AI, energy
- Tools/workflows: Replace GPT-2–style baselines with TG for domain or general pretraining at 107–108 parameter scales; integrate TG’s sentence-memory and training schedules to reduce tokens/parameters needed for a given loss (paper reports ~5–8% fewer tokens, ~33–42% fewer params for matched loss in tested regimes).
- Assumptions/dependencies: Gains shown on WikiText-103 at ≤~85M params and ≤50M tokens; benefits must be re-validated on larger corpora and different domains; training requires retaining gradients through memory (higher memory footprint).
- Domain-specific models where labeled or unlabeled data is scarce
- Sectors: healthcare (clinical notes), legal (contracts), finance (filings), scientific literature
- Tools/workflows: Pretrain or continue-pretrain TG on niche text; sentence-level gestalts can improve sample efficiency and cross-sentence coherence for summarization and QA in specialized domains.
- Assumptions/dependencies: Robust sentence segmentation in the domain/language; careful evaluation for safety and domain-specific accuracy.
- More faithful relation extraction/knowledge graph population
- Sectors: software (knowledge graphs), finance/compliance, pharma/biomedicine
- Tools/workflows: Use TG for IE pipelines to reduce directionality errors (e.g., A-owns-B vs. B-owns-A) via improved directional generalization (paper’s father–son probe).
- Assumptions/dependencies: Benchmarked on a controlled probe; needs validation on open-domain IE; depends on data preprocessing quality and fine-tuning.
- Long-document generation and editing with better cross-sentence consistency
- Sectors: media/publishing, enterprise documentation, technical writing
- Tools/products: Document assistants that draft sections sentence-by-sentence while maintaining a coherent “thought” memory to reduce contextualization errors and contradictions.
- Assumptions/dependencies: Tested perplexity gains, not full-fledged document-level quality metrics; inference-time latency and memory management must be engineered.
- Customer support and internal enterprise chat with stronger cross-turn memory
- Sectors: customer service, CRM
- Tools/products: TG-backed chat that carries sentence-level memory across turns for better reference resolution and consistent answers.
- Assumptions/dependencies: Integration with session memory stores; verify behavior with multi-turn benchmarks; ensure privacy controls for persisted memories.
- Practical training heuristics transferable to non-TG models
- Sectors: software/AI
- Tools/workflows:
- Sentence boundary bias: Explicit <BOS>/<EOS> markers in GPT-style models to yield easy low-data gains.
- EOS down-weighting: Reduce over-weighting of frequent, easy boundary tokens.
- Stream-length curriculum: Start with shorter sentence streams and grow them to stabilize long-range credit assignment.
- Assumptions/dependencies: These are low-cost changes but need tuning per dataset; benefits may diminish at larger scales.
- Robust sentence segmentation for NLP pipelines
- Sectors: data engineering, analytics, RAG pipelines
- Tools/workflows: Adopt SaT Capped (or similar) sentence splitting for noisy text; improves preparation for any sentence-aware model or task.
- Assumptions/dependencies: Domain/language adaptation of segmentation; handling of very long sentences or atypical punctuation.
- Edge and on-device text assistants at smaller model sizes
- Sectors: mobile, embedded systems
- Tools/products: TG-based email reply, note summarizers, or offline assistants where parameter efficiency translates to smaller memory footprints.
- Assumptions/dependencies: Re-validate efficiency under on-device constraints; ensure inference-time optimizations for sentence-by-sentence decoding and memory cross-attention.
Long-Term Applications
- Compute- and energy-efficient foundation-model pretraining
- Sectors: software/AI, energy, sustainability policy
- Tools/products: Next-generation large LMs that integrate TG’s two-level abstraction to reduce tokens/parameters required for target loss; lower energy per point of performance.
- Assumptions/dependencies: Unproven at multi-billion-parameter scales; requires engineering for distributed training with gradient-through-memory; rigorous third-party validation of energy savings.
- Retrieval-augmented “thought” memory
- Sectors: enterprise search/RAG, productivity software
- Tools/products: Index and retrieve sentence-level gestalts as durable memory units (e.g., caching document “thoughts” for faster, more consistent QA); semantic cache APIs that return TG sentence vectors instead of raw token chunks.
- Assumptions/dependencies: Build retrieval stacks tailored to sentence-gestalt vectors; evaluate vs. chunk-level retrieval baselines; memory store design and privacy.
- Safer, more consistent long-form generation (reduced hallucinations and contradictions)
- Sectors: policy, media, education
- Tools/products: Story, report, and policy drafting assistants that maintain internal situation models, improving global consistency and factual alignment over long contexts.
- Assumptions/dependencies: Requires benchmarks for factual consistency and hallucination under TG; alignment/safety systems should be layered on top.
- Event- and situation-modeling for reasoning agents
- Sectors: robotics, software agents, process automation
- Tools/products: Agents that interpret instructions as event-level states (who did what to whom, when), enabling better multi-step planning and execution across sentences.
- Assumptions/dependencies: Integration with planners and controllers; tests on embodied tasks; latency constraints for real-time control.
- Advanced educational tutoring and reading comprehension
- Sectors: education/EdTech
- Tools/products: Tutors that build situation models of narrative or expository text, enabling nuanced comprehension questions and causal/temporal reasoning across sentences or paragraphs.
- Assumptions/dependencies: Age-appropriate content controls; explainability requirements; pedagogical validation.
- Healthcare summarization and longitudinal patient timelines
- Sectors: healthcare
- Tools/products: Summarizers that construct reliable cross-note timelines, capturing actor–action–object relations (e.g., “who prescribed what to whom”) with correct directionality; clinical decision support inputs.
- Assumptions/dependencies: Clinical validation and regulatory approval; robust sentence segmentation for clinical text; strict PHI/privacy and auditability.
- Legal and financial analytics with directionally correct obligations/ownership
- Sectors: legal, finance
- Tools/products: Contract analysis and risk tools that extract obligations, liens, and ownership with reduced reversal errors; improved compliance monitoring.
- Assumptions/dependencies: Domain-specific fine-tuning; rigorous accuracy and liability assessments; evaluation on long, complex contracts.
- Persistent, cross-session “thought” memory for personal/enterprise assistants
- Sectors: productivity, CRM
- Tools/products: Assistants that store and reuse sentence-level memories to remain consistent across days/weeks (e.g., preferences, project states).
- Assumptions/dependencies: Memory governance (retention, redaction, consent), vector store design for sentence gestalts, drift and staleness management.
- Low-resource and multilingual modeling
- Sectors: global development, localization
- Tools/products: TG-based training for languages with limited data, leveraging TG’s sample efficiency and sentence-level organization for better generalization.
- Assumptions/dependencies: High-quality sentence boundary detection across scripts; adaptation to languages with different sentence boundary conventions.
- Policy and standards: benchmarks and procurement criteria for long-context reasoning
- Sectors: government, standards bodies
- Tools/workflows: Incorporate reversal-direction probes and long-context consistency evaluations into standard benchmarks and procurement guidelines to encourage architectures that form stable, higher-level states.
- Assumptions/dependencies: Community consensus on metrics; test suites spanning diverse domains and languages.
- Cognitive-inspired knowledge systems (event schemas, causal models)
- Sectors: research, knowledge management
- Tools/products: Systems that induce event schemas and causal graphs from text using TG’s sentence-level representations as building blocks, improving interpretability and downstream reasoning.
- Assumptions/dependencies: Methods to decode/inspect “gestalts” reliably; evaluation protocols for causal/temporal inference; integration with symbolic stores.
Notes on feasibility across applications:
- Architectural changes: Many applications require adopting TG’s recurrent memory and cross-attention; this means engineering support for retained computation graphs and memory capacity tuning.
- Segmentation quality: TG assumes sentence boundaries approximate “thought” boundaries; performance may hinge on robust segmentation in noisy or multilingual settings.
- Scale and generality: Reported gains are at moderate scales; replication at web-scale and on varied tasks (code, math, multimodal) remains open.
- Inference trade-offs: TG’s per-sentence processing and memory attention may change latency/throughput characteristics; careful optimization and caching are needed for production.
Collections
Sign up for free to add this paper to one or more collections.

