The Markovian Thinker
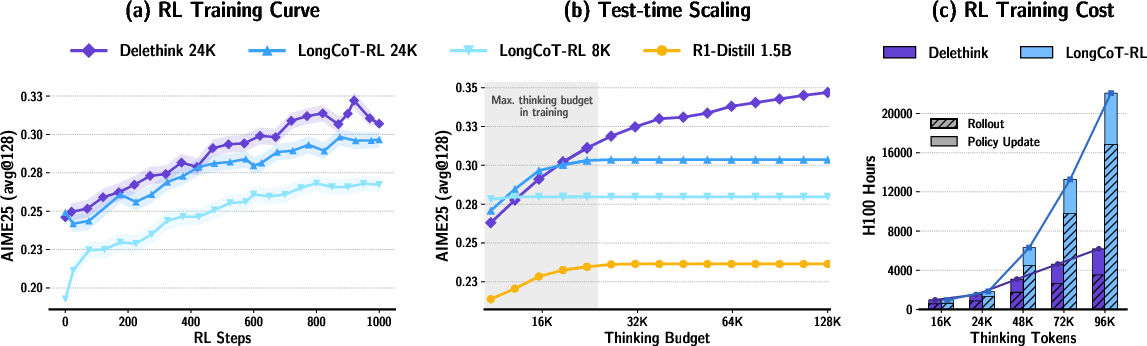
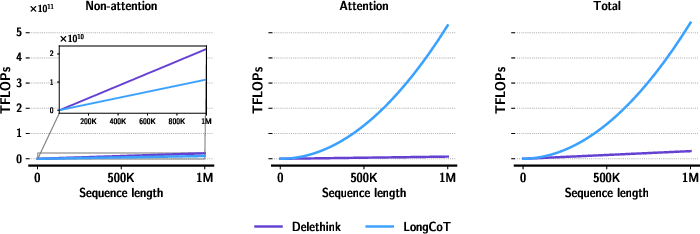
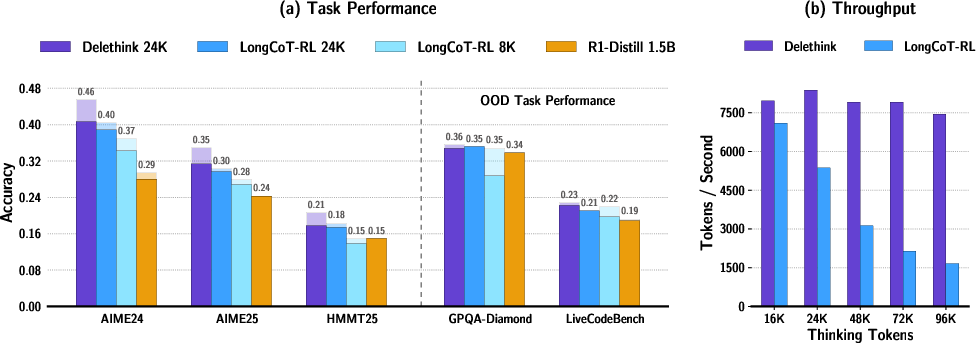
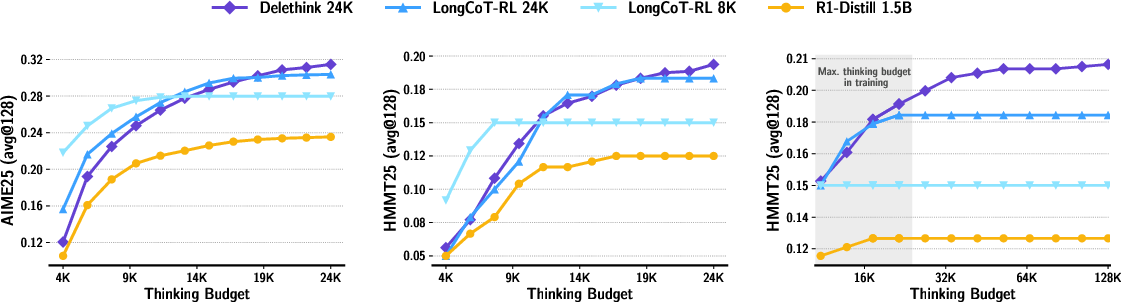
Abstract: Reinforcement learning (RL) has recently become a strong recipe for training reasoning LLMs that produce long chains of thought (LongCoT). Yet the standard RL "thinking environment", where the state is the prompt plus all prior reasoning tokens, makes the state unbounded and forces attention-based policies to pay quadratic compute as thoughts lengthen. We revisit the environment itself. We propose Markovian Thinking, a paradigm in which the policy advances reasoning while conditioning on a constant-size state, decoupling thinking length from context size. As an immediate consequence this yields linear compute with constant memory. We instantiate this idea with Delethink, an RL environment that structures reasoning into fixed-size chunks. Within each chunk, the model thinks as usual; at the boundary, the environment resets the context and reinitializes the prompt with a short carryover. Through RL, the policy learns to write a textual state near the end of each chunk sufficient for seamless continuation of reasoning after reset. Trained in this environment, an R1-Distill 1.5B model reasons in 8K-token chunks yet thinks up to 24K tokens, matching or surpassing LongCoT-RL trained with a 24K budget. With test-time scaling, Delethink continues to improve where LongCoT plateaus. The effect of linear compute is substantial: we empirically estimate at 96K average thinking length LongCoT-RL costs 27 H100-months vs. 7 for Delethink. Analysis at RL initialization shows off-the-shelf reasoning models (1.5B-120B) often sample Markovian traces zero-shot across diverse benchmarks, providing positive samples that make RL effective at scale. Our results show that redesigning the thinking environment is a powerful lever: it enables very long reasoning without quadratic overhead and opens a path toward efficient, scalable reasoning LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1. What is this paper about?
This paper is about teaching AI LLMs to “think” for a long time without slowing down too much. Today, many models solve hard problems by writing long chains of thoughts before giving an answer. But the usual way of doing this gets very slow and expensive as the thoughts get longer. The authors introduce a new way, called Markovian Thinking, that lets the model think for a very long time while keeping the cost much lower.
2. What questions are they asking?
- Can we redesign the “thinking setup” so that a model can think longer without getting much slower?
- Can a model learn to carry its plan forward using only a short reminder, instead of re-reading everything it wrote before?
- Will this new setup keep accuracy high (or even improve it) while using less computer power?
- Do current models already show signs of this behavior naturally?
3. How did they do it? (Methods explained simply)
Think of the model’s reasoning like writing in a very long notebook:
- Old way (LongCoT): The model keeps everything it has written on one never-ending page. Each new sentence has to “look back” at the entire page. The longer the page, the slower things get—slowing down faster than just “more lines,” because checking all pairs of lines takes a lot of work.
- New way (Markovian Thinking with “Delethink”): The model writes in pages (chunks) of the same size. At the end of each page, it writes a short summary—like a sticky note with the key points. Then it starts a fresh page using only the original question plus that short sticky note. It does not carry over the full previous page, just the summary.
Key idea: The model learns (using reinforcement learning, a training method where the model gets rewards for good outcomes) to write the right kind of short summary at each page end so it can pick up smoothly on the next page. Because it only needs to read a fixed-size page plus a short summary, the amount of work grows in a straight line with the number of pages instead of exploding.
Simple analogy:
- LongCoT = one giant scroll you reread constantly.
- Delethink = a notebook with pages; you only need the question and a sticky-note summary to continue.
“Markovian” here means the model only needs what’s in the current state (the question + short carryover), not the entire past, to keep reasoning correctly.
4. What did they find, and why is it important?
Main results (in plain terms):
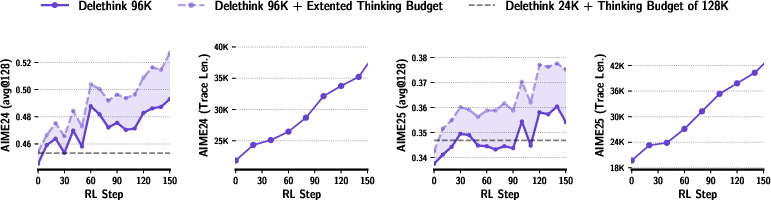
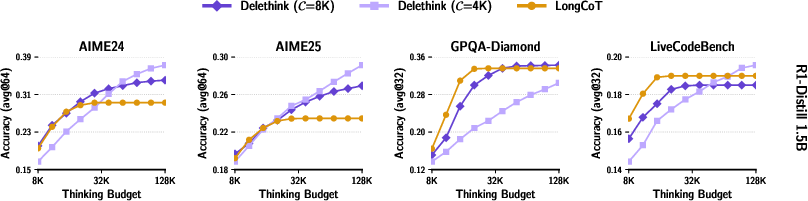
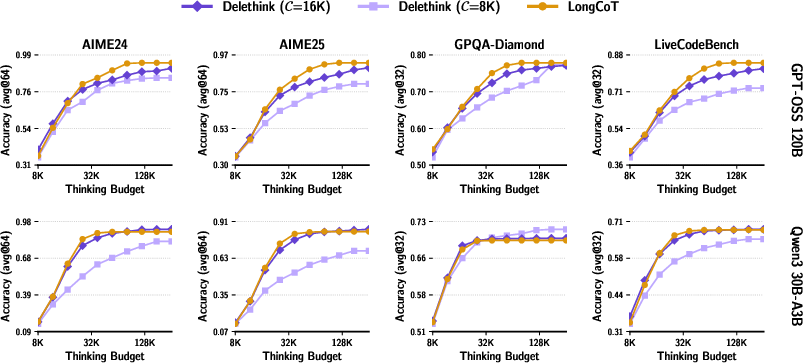
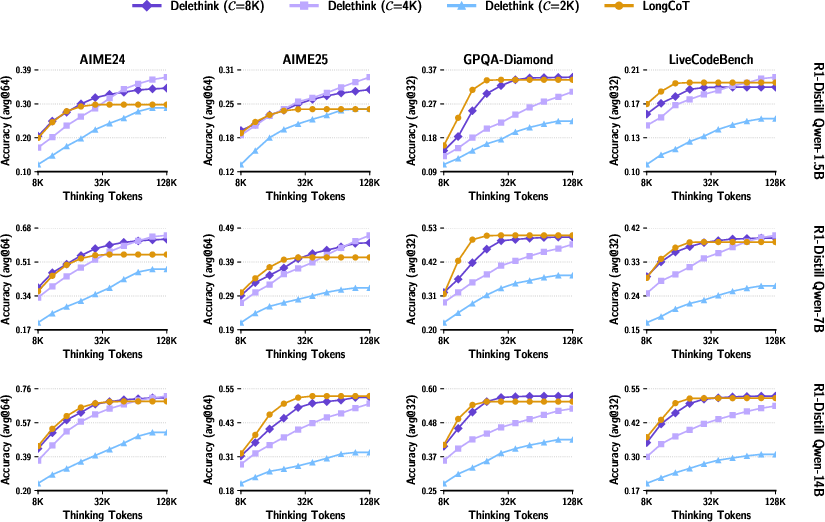
- Same or better accuracy with less compute: A model trained with Delethink (using 8K-token pages) can “think” up to 24K tokens and match or beat the usual long-thinking method that was trained to handle all 24K at once. That’s strong performance with less cost.
- Keeps improving when allowed to think longer: When you let the Delethink-trained model think for even more tokens at test time, it keeps getting better, while the old method stops improving (plateaus).
- Big speed and cost savings: For very long thinking (around 96,000 tokens), the old way was estimated to cost about 27 “H100-months” (roughly a month of work on a very powerful GPU). Delethink needed about 7 H100-months for the same job. That’s roughly a 4× reduction in cost.
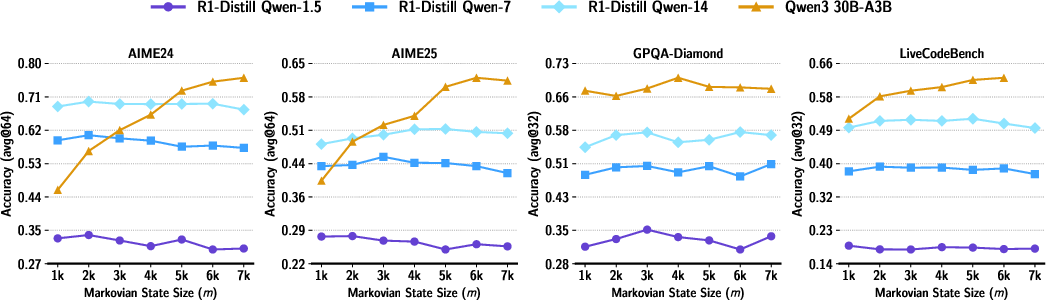
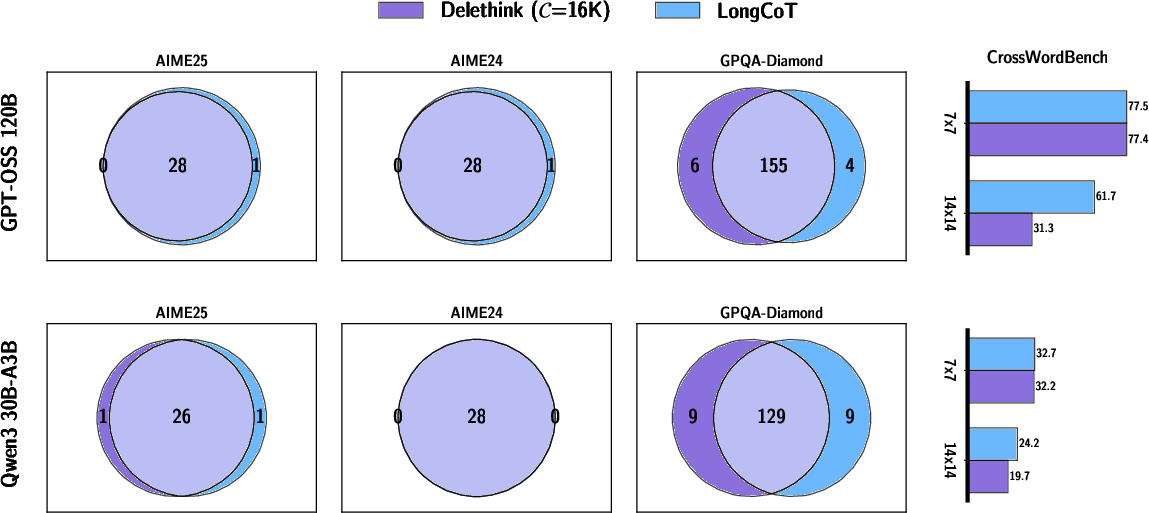
- Many models already show this behavior: Even before training with Delethink, several existing reasoning models sometimes naturally produce “Markovian” traces (they can continue well with short summaries). That makes training with Delethink easier and more effective.
Why it matters:
- Lower cost and faster training/inference means we can build smarter systems without needing huge budgets.
- Being able to think longer helps with hard tasks like math, coding, and puzzles that need many steps.
5. What’s the impact?
This work shows that changing the “thinking environment” can be just as important as changing the model itself. By decoupling “how long the model thinks” from “how much it has to re-read,” models can, in principle, think for millions of tokens without the usual slowdown. This could:
- Enable much deeper reasoning on tough problems.
- Reduce the energy and money required to train and use big models.
- Work well with future architectures built for efficiency.
- Make long, step-by-step problem solving practical for real-world uses (education, research, programming, science).
In short, the paper’s idea—think in fixed-size chunks with smart summaries—lets AI think longer, better, and cheaper.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open questions that remain unresolved and can guide future research:
- Task generality beyond math-centric evaluation:
- How well Markovian Thinking transfers to non-math domains (e.g., long-form reasoning in law, scientific QA, open-domain multi-hop retrieval, dialog planning) remains unclear.
- Evidence for GPT-OSS 120B is anecdotal in Sec. “why works”; systematic, broad benchmarks (code, planning, commonsense, long documents) are not reported.
- Limits of the Markovian assumption:
- Which tasks can/cannot be compressed into a bounded textual state without loss? Is there a principled characterization (e.g., lower bounds on necessary state size m for different problem classes)?
- Failure modes when key early information cannot be faithfully reconstructed from “last m tokens.”
- Carryover design and sufficiency:
- The choice of “last m tokens” as carryover is ad hoc; no analysis of optimal m, sensitivity, or adaptive strategies exists.
- No comparison to learned summaries, key-value compression, or structured state representations as alternatives to “last m tokens.”
- Chunking policy and boundaries:
- Chunk size C and fixed boundaries are hand-chosen; it is unknown whether dynamic chunking, learned reset points, or semantic-aligned boundaries reduce error propagation.
- Effects of placing boundaries mid-derivation/sentence are unquantified.
- Error accumulation across chunks:
- No diagnostics quantify how inconsistencies in the textual state compound with chunk count S, nor how often re-summarization self-corrects vs. drifts.
- Lack of per-boundary error analyses (e.g., accuracy drop conditional on number of resets).
- Reward design and credit assignment:
- With a terminal, trajectory-level reward, how does credit propagate across resets, especially when early chunk states cause later failures?
- Sensitivity to advantage estimators, variance reduction strategies, and the effect of per-chunk auxiliary rewards is unstudied.
- Comparison fairness and confounders:
- It’s unclear if Delethink’s gains stem from architectural/algorithmic advantages or simply from being able to train with larger effective batch/longer horizons due to shorter contexts.
- Details on matching KL schedules, temperatures, sampling schemes, and hyperparameters between LongCoT-RL and Delethink are insufficient for airtight causal attribution.
- Theoretical guarantees:
- No formal result shows that any LongCoT-computable solution has a bounded-state Markovian equivalent for reasonable m, nor bounds on performance loss vs. m and C.
- Absence of sample-complexity or convergence analysis tailored to chunked, resetting environments.
- Test-time scaling limits:
- While Delethink improves beyond the trained thinking budget, the point at which returns saturate or degrade (and why) is unknown.
- Robustness of very long traces (e.g., 100K–1M tokens) under distribution shift from training remains untested.
- Interplay with architecture choices:
- Claims that linear-time architectures (e.g., Mamba, linear attention) could particularly benefit are unverified; no experiments evaluate Delethink with non-quadratic sequence models.
- How recurrence/state-space models should interface with textual state resets is unexplored.
- Multi-turn, tool-use, and retrieval settings:
- How to retain tool outputs, retrieval evidence, or program states across resets is unspecified.
- Whether the textual state can faithfully “carry” external-tool context without repeated recomputation or loss is an open question.
- Multimodal applicability:
- The approach is text-only; how to compress image/audio/video features into a bounded “state” across resets is unaddressed.
- Safety, privacy, and CoT exposure:
- Forcing models to externalize internal state may increase chain-of-thought leakage; no mechanisms to control or redact sensitive state are proposed.
- Impacts on refusal behaviors and safety alignment under Markovian Thinking are unstudied.
- Latency and systems overhead:
- Frequent resets re-send the query and state; wall-clock latency, token I/O, and backend overheads vs. LongCoT are not rigorously benchmarked.
- Interaction with KV-cache reuse and streaming inference is unclear (potentially lower cache benefits due to resets).
- Interpretability of learned state:
- The content and structure of the learned “state near end-of-chunk” is not analyzed (e.g., are they concise summaries, scratchpads, or opaque markers?).
- Methods for constraining or auditing the state (format, faithfulness, verifiability) are absent.
- Robustness and calibration:
- No robustness tests under adversarial prompts, noisy inputs, or distractors evaluate whether the state maintains fidelity through resets.
- Effects on calibration and uncertainty estimates as S grows are unknown.
- Early stopping and termination behavior:
- How the model learns reliable stopping criteria under periodic resets (avoiding redundant or looping states) is not studied.
- Potential interactions with early-exit or pruning strategies in a Markovian environment are not explored.
- Data efficiency and stability:
- Whether Delethink requires fewer/more RL steps or exhibits different instability modes than LongCoT-RL is not quantified beyond coarse compute estimates.
- Ablations on group size G, iterations cap I, KL strength, and reference policy drift are missing.
- Generalization across scales:
- RL training is demonstrated at 1.5B; it is unknown whether the same training dynamics, stability, and gains hold at 7B–70B+ under realistic compute constraints.
- The observed zero-shot Markovian behavior at 120B is not accompanied by RL training at that scale.
- Alternative state-carryover mechanisms:
- No exploration of hybrid schemes (e.g., compact learned memory tokens, differentiable external memory, or lossy KV compression) vs. textual carryover.
- Potential benefits of explicitly supervised state summaries (distilled from high-quality proofs) are untested.
- Evaluation breadth and metrics:
- Evaluations emphasize accuracy; there is little on reasoning quality measures (faithfulness, step validity), human-judged coherence across boundaries, or error typology specific to resets.
- No standardized benchmarks tailored to chunked reasoning are introduced to stress-test state sufficiency.
- Reproducibility of compute claims:
- Cost estimates rely on a particular stack (VERL + SGLang) and hardware; sensitivity to implementation, kernel choices, scheduler policies, and parallelism strategy is not provided.
- Hidden constants (e.g., prompt reconstruction, logging, rollout orchestration) may affect real-world linear-vs-quadratic break-even points.
- Interaction with alignment objectives:
- Effects of KL-to-reference and instruction-following regularization on the learned state style (verbosity, redundancy, safety) are unclear.
- Potential trade-offs between compact state and alignment constraints are not examined.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s Markovian Thinking paradigm and the Delethink environment (code and weights provided in the paper).
- Cost-reduced RL fine-tuning for reasoning LLMs (software/AI platforms)
- Train math/coding reasoners with linear compute and constant memory by replacing LongCoT environments with Delethink in RLVR pipelines.
- Tools/Workflows: Integrate Delethink step (Algorithm 1) into existing verl/SGLang, vLLM, or Ray training stacks; introduce a “Markovian RL” flag in training configs.
- Assumptions/Dependencies: Verifiable reward functions; appropriate chunk size C and carryover m; reference policy and KL regularization remain stable.
- Sliding-window “Markovian inference mode” for existing LLMs (software, cloud AI)
- Serve long chains of thought by chunking generation and carrying over only the last m tokens; exploit observed zero-shot Markovian traces in off-the-shelf models.
- Tools/Workflows: Inference server middleware that resets context at chunk boundaries and preserves a small carryover; cost-based billing per chunk.
- Assumptions/Dependencies: Tasks tolerate local, textual state handoff; small m preserves coherence for that domain.
- Enterprise copilots with bounded-memory long reasoning (enterprise software)
- Conduct extended analyses (e.g., compliance checks, multi-step report synthesis, strategy plans) with predictable compute and memory.
- Tools/Workflows: “State budgeter” that enforces a carryover quota; chunked trace logging for auditability and post-mortems.
- Assumptions/Dependencies: Users allow chain-of-thought storage when appropriate; summaries must capture critical requirements at each boundary.
- Code generation and refactoring at scale (software engineering)
- Break multi-file refactors and complex bug traces into chunks with explicit textual state; reduce KV-cache growth and costs in CI/CD agents.
- Tools/Workflows: IDE plugin that inserts “state notes” at chunk ends; CI bots that checkpoint reasoning before tool calls.
- Assumptions/Dependencies: High-fidelity state messages near boundaries; integration with repository context and tests.
- Retrieval-augmented “state carryover” (RAG + reasoning)
- Combine small textual carryover with retrieval of previously emitted state notes for longer-horizon tasks without expanding context.
- Tools/Workflows: Lightweight ephemeral memory store indexed by task/thread; retrieval hooks only for past state notes, not full histories.
- Assumptions/Dependencies: Retrieval quality; guardrails to avoid reintroducing quadratic context.
- Cost-aware long-form analysis for finance and legal (finance, legal tech)
- Run deep diligence or contract review in bounded chunks; produce auditable, sectioned rationales.
- Tools/Workflows: “Markovian trace inspector” that highlights state transitions and checks for missing obligations across chunks.
- Assumptions/Dependencies: Coverage risks if crucial early facts aren’t summarized into the carryover; validation workflows required.
- Education and tutoring with stepwise scaffolding (education)
- Tutors show solutions in chunks, teaching students to summarize state; lowers infra costs for long derivations.
- Tools/Workflows: Classroom dashboards that visualize per-chunk reasoning and state notes.
- Assumptions/Dependencies: Rewards/verifiers for correctness; pedagogical guardrails for chain-of-thought disclosure.
- Energy- and cost-efficient cloud offerings (cloud/ML ops)
- Offer a “Markovian Thinking API” tier with lower GPU-time/carbon per long-reasoning session.
- Tools/Workflows: Usage meters per chunk instead of per token; autoscalers tuned for linear scaling.
- Assumptions/Dependencies: Serving stack supports reset-and-carryover; observability of chunk boundaries.
- Safer long-horizon interactions via state budgeting (AI safety/compliance)
- Reduce propagation of prompt injections and sensitive data by limiting carryover; inspect each state handoff for policy violations.
- Tools/Workflows: “State budget policy” that caps m and scans carryover text; chunk-level compliance checks.
- Assumptions/Dependencies: Safety filters strong enough; some tasks may need retrieval of vetted state to avoid information loss.
- On-device or low-memory deployments for extended planning (mobile/edge, robotics prototyping)
- Execute long reasoning on constrained devices by chunking and re-prompting with small carryover.
- Tools/Workflows: Mobile inference wrappers with sliding-window generation; robot planners that serialize objectives into compact textual state.
- Assumptions/Dependencies: Latency budget accommodates chunk boundaries; careful choice of C and m for task complexity.
Long-Term Applications
These concepts require further research, scaling, or validation (e.g., safety and regulatory testing), but are enabled by the paper’s paradigm.
- Million-token deliberation without quadratic overhead (software/AI research)
- Push long-horizon reasoning (theorem proving, formal verification, program synthesis) far beyond current context limits.
- Tools/Workflows: Curriculum schedules that teach robust state formation; synthetic environments with rewards for correct long-range continuation.
- Assumptions/Dependencies: Stable learning of state messages; stronger verifiers/reward models for non-verifiable domains.
- Healthcare decision support with bounded-state reasoning (healthcare)
- Clinical case analysis across lengthy records using minimal carryover and rigorously validated state notes; privacy-friendly by default.
- Tools/Workflows: EHR interfaces that render chunked rationales and require clinician sign-off per chunk; state validation against guidelines.
- Assumptions/Dependencies: Regulatory clearance; clinical safety audits; guarantees that carryover captures all critical patient context.
- Markovian Reasoning for robotics and autonomy (robotics)
- Long-horizon task planning and execution where policies persist via compact textual or latent state across planning cycles.
- Tools/Workflows: Hybrid planners that combine Delethink-style textual state with symbolic task graphs; recovery after resets/failures.
- Assumptions/Dependencies: Robustness to partial observability; integration with perception/action loops; safety and verification.
- Compute-governed and carbon-aware AI standards (policy)
- Establish benchmarks and procurement standards favoring linear-compute reasoning; define “state carryover caps” to limit data retention.
- Tools/Workflows: Compliance attestations reporting H100-months/GPU-hours saved per task; carbon budgets tied to chunked reasoning profiles.
- Assumptions/Dependencies: Agreement on measurement protocols; third-party audits.
- Architectures optimized for Markovian Thinking (ML systems)
- Co-design with state-space models or linear attention to further cut inference/memory; recurrent “reasoning cores” trained on Delethink-like environments.
- Tools/Workflows: Training recipes that align chunk boundaries with recurrent state updates; new benchmarks isolating state quality.
- Assumptions/Dependencies: Stable optimization; equivalent or better accuracy than attention-dominant stacks.
- Formal guarantees and verifiable state contracts (assurance)
- Specify and verify properties of the carryover (e.g., “must include constraints X,Y”) to ensure no critical info is dropped between chunks.
- Tools/Workflows: State contract checkers; proof-carrying state messages; conformance tests across chunk boundaries.
- Assumptions/Dependencies: Domain-specific ontologies; hybrid symbolic-LLM methods.
- Privacy-preserving, session-spanning assistants (daily life, enterprise)
- Assistants that reason over weeks/months via small, signed state snapshots rather than storing raw histories.
- Tools/Workflows: Encrypted, minimal state vaults; user controls to review/edit carried state between sessions.
- Assumptions/Dependencies: UX for state inspection; strong privacy guarantees and revocation.
- Multi-agent Markovian collaboration (agents)
- Agents exchange compact state messages to coordinate large tasks (software projects, data pipelines) without shared massive contexts.
- Tools/Workflows: Protocols for state message passing; arbitration/judging agents that validate handoffs.
- Assumptions/Dependencies: Communication reliability; standards for state schemas.
- Domain-specific “state compilers” (tooling)
- Compilers that transform intermediate reasoning into minimal, loss-aware state tailored to domains (law, finance, science).
- Tools/Workflows: Learned or rule-based reducers that emit carryover tailored to domain constraints.
- Assumptions/Dependencies: Adequate domain coverage; ability to quantify information loss vs. downstream task impact.
- Safety cases for chain-of-thought governance (policy/safety)
- Define when and how chunked CoT can be logged, displayed, or redacted; set norms for teaching vs. concealed CoT.
- Tools/Workflows: Policy templates that tie CoT visibility to user roles and risk tiers; chunk-level redaction tools.
- Assumptions/Dependencies: Cross-stakeholder consensus; alignment with jurisdictional regulations.
Notes on feasibility across applications:
- The Markovian approach assumes tasks admit a compact “textual state” that suffices for continuation; when long-range rare facts matter, retrieval or verified state augmentation may be necessary.
- Empirical gains depend on well-chosen chunk size C and carryover m; too small m risks losing critical context; too large m erodes efficiency.
- Safety-critical deployments require rigorous evaluation because chunking changes failure modes (e.g., omissions at boundaries).
- Compute savings materialize most when attention cost dominates; synergy with linear/recurrent architectures may amplify benefits over time.
Glossary
- Advantage estimator: A method to compute per-trajectory or per-token advantages for credit assignment in policy-gradient RL. "off-the-shelf advantage estimator"
- Attention-based policies: Policies implemented with self-attention that read growing contexts, incurring quadratic costs with length. "For attention-based policies this entails prohibitive, quadratic growth of compute throughout."
- Attention-sink tokens: Special tokens retained in streaming contexts to stabilize attention quality. "preserves a small set of attention-sink tokens to stabilize quality under sliding windows."
- Autoregressively: Generating each token conditioned on previously generated tokens in sequence. "autoregressively: "
- Carryover: A brief portion of prior reasoning copied into the next chunk to maintain continuity. "a short carryover from the previous chunk."
- Chain-of-thought (LongCoT): Extended intermediate reasoning before answering, represented by many “thinking tokens.” "long chains of thought (LongCoT)"
- Chunked: Organizing generation into fixed-size segments to bound context. "chunked, markovian process"
- Constant memory: Memory usage that does not grow with the total thinking length. "linear compute with constant memory"
- Constant-size state: A bounded input state fed to the policy regardless of total reasoning length. "conditioning on a constant-size state"
- Expected return: The RL objective of maximizing the expectation of rewards over trajectories. "maximize expected return"
- FLOP: The count of floating-point operations used as a compute metric. "FLOP"
- H100-months: A compute cost unit estimating wall-clock usage of NVIDIA H100 GPUs. "LongCoT-RL costs 27 H100-months vs.\ 7 for Delethink."
- In-distribution: Behavior occurring within the distribution the model commonly exhibits or is trained on. "has strong support for Markovian Thinking in-distribution"
- KL coefficient: The scalar weight on the KL regularization term in the RL objective. " is the KL coefficient"
- KL penalty: Regularization via the Kullback–Leibler divergence to keep the policy close to a reference. "a KL penalty against a reference model"
- Linear attention: Attention variants whose time/memory scale linearly with sequence length. "kernel-based linear attention"
- Linear compute: Total computation that grows linearly with thinking length. "yields linear compute with constant memory"
- LongCoT environment: An RL thinking setup where the context grows by concatenating all prior reasoning tokens. "the LongCoT environment concatenates tokens indefinitely"
- Markov property: The property that the future depends only on the current state, not the full history. "satisfies the Markov property"
- Markovian Decision Process (MDP): The formal RL framework defining states, actions, and transitions for language generation. "language-generation Markovian Decision Process (MDP)"
- Markovian Thinker: A policy trained to maintain a textual state and reason across chunks with bounded context. "We call such a policy a Markovian Thinker."
- Markovian Thinking: A paradigm where reasoning advances while conditioning on a bounded state. "We propose Markovian Thinking, a paradigm"
- Policy-gradient updates: RL optimization that updates the policy using gradients of expected returns. "applying policy-gradient updates"
- Reference model: The fixed model used as the target in KL regularization. "against a reference model"
- Reference policy: The baseline distribution the trained policy is regularized toward via KL. " is the reference policy"
- Reinforcement Learning from Verifiable Rewards (RLVR): An RL formulation where rewards are derived from automatically checkable signals. "We adopt the RLVR formulation"
- Self-attention: The transformer mechanism computing token interactions via attention over the sequence. "replaces self-attention with state-space models"
- Sequential sampling: An evaluation procedure reporting performance when outputs are sampled sequentially. "reported using sequential sampling"
- Sliding windows: A moving context window used to bound attention during long generation. "under sliding windows"
- State-space models: Sequence models with recurrent state updates enabling linear-time, constant-memory generation. "state-space models"
- Test-time compute: The amount of computation used during inference rather than training. "test-time compute (reported using sequential sampling)"
- Test-time scaling: Increasing inference-time thinking or compute budget to boost accuracy. "With test-time scaling, Delethink continues to improve"
- Token-by-token generation MDP: An MDP where each action is the next token and the state is the prompt plus generated tokens so far. "token-by-token generation MDP (as used in standard LongCoT RLVR)"
- Trajectory-level reward: A reward assigned to the entire generated sequence rather than individual steps. "trajectory-level reward function (verifiable rewards in our case)"
- Verifiable rewards: Rewards computed by checking outputs with automatic or programmatic criteria. "verifiable rewards in our case"
- Zero-shot: Achieving behavior without additional training or specialized prompts. "samples Markovian traces zero-shot"
Collections
Sign up for free to add this paper to one or more collections.