- The paper introduces TwiG, a framework integrating textual reasoning into visual generation for real-time, region-specific corrections.
- It leverages zero-shot prompting, supervised fine-tuning, and reinforcement learning to enhance attribute binding, compositional fidelity, and semantic consistency.
- The autoregressive approach improves computational efficiency and extensibility to tasks like image-to-video and text-to-3D synthesis.
Thinking-while-Generating: Interleaved Textual Reasoning in Visual Generation
Motivation and Context
Recent multimodal models have demonstrated robust visual synthesis but continue to face limitations in compositional generalization, multi-entity relations, and fine-grained adherence to complex textual instructions. The integration of textual reasoning—specifically Chain-of-Thought (CoT) approaches—has emerged as a strategy to address some of these challenges. However, prior paradigms have isolated reasoning either before generation (pre-planning) or after generation (post-refinement), resulting in coarse or inefficient guidance and limited capacity for nuanced corrective intervention.
This paper introduces "Thinking-while-Generating" (TwiG) (2511.16671), a framework for interleaving textual reasoning throughout the generative process itself, providing stepwise, on-the-fly, region-specific guidance and real-time reflection that inform and critique the unfolding visual output.
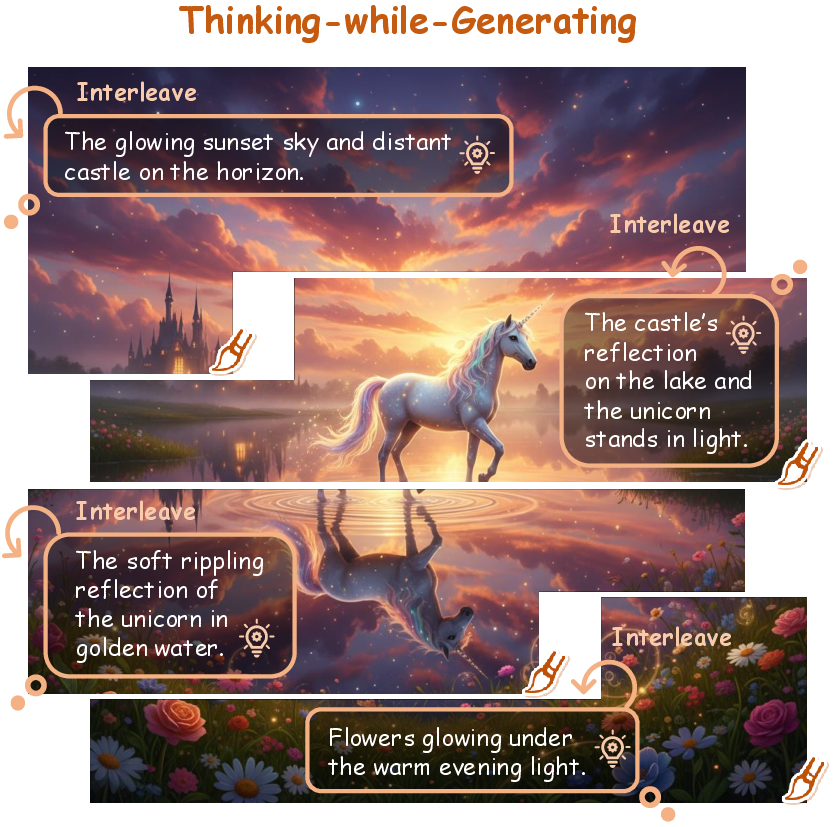
Figure 1: Interleaving Textual Reasoning throughout Visual Generation, with thoughts dynamically woven into the generation trajectory.
From Pre-/Post-Reasoning to Fully-Interleaved Guidance
The distinction between TwiG and previous methods is focal. Pre-planning approaches generate textual plans (descriptions, layouts, object attributes/relations) prior to image synthesis, which yields enhanced global coherence but is inflexible for mid-course refinement. Post-refinement techniques initiate critique and revision only after complete image synthesis, benefiting local fixes but requiring additional inference rounds and lacking fine-timed adjustment.
TwiG inverts this paradigm by co-evolving textual reasoning with visual content: as each region of the image is generated, textual thoughts are interleaved to provide localized, context-aware guidance and immediate semantic critique for the evolving canvas.
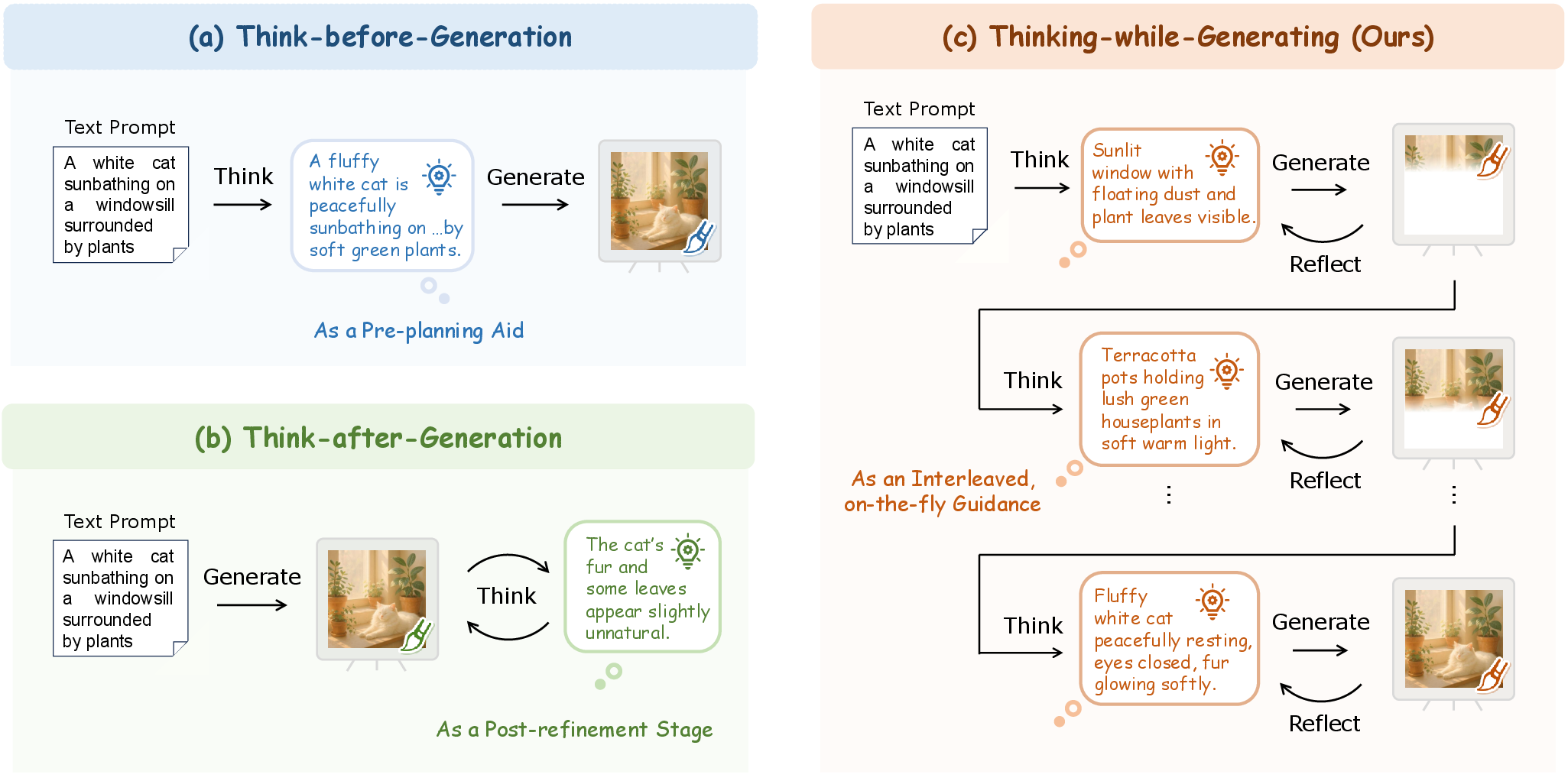
Figure 2: Comparison of where textual reasoning is applied: TwiG provides dynamic, region-wise guidance compared to think-before or think-after protocols.
Core Architecture and Generation Pipeline
The TwiG framework is instantiated using a Unified Language and Multimodal Model (ULM, e.g., Janus-Pro), adopting an autoregressive generation paradigm. TwiG comprises three components:
- When to Think (Scheduling): Decomposes generation into K reasoning steps, partitioning the canvas spatially or temporally into regions for progressive synthesis (typically K=3 for upper background, central content, and lower background).
- What to Say (Reasoning Content): At each region, ULM generates a localized sub-caption τk considering the global prompt T, prior thoughts, and preceding visual content.
- How to Refine (Reflection): Post-generation of each region, ULM produces a critic score and a revised sub-caption as necessary, potentially triggering targeted local re-generation without requiring a full pass.
This protocol is implemented entirely within a single autoregressive generative trajectory, preserving computational efficiency and enabling precise, granular correction.
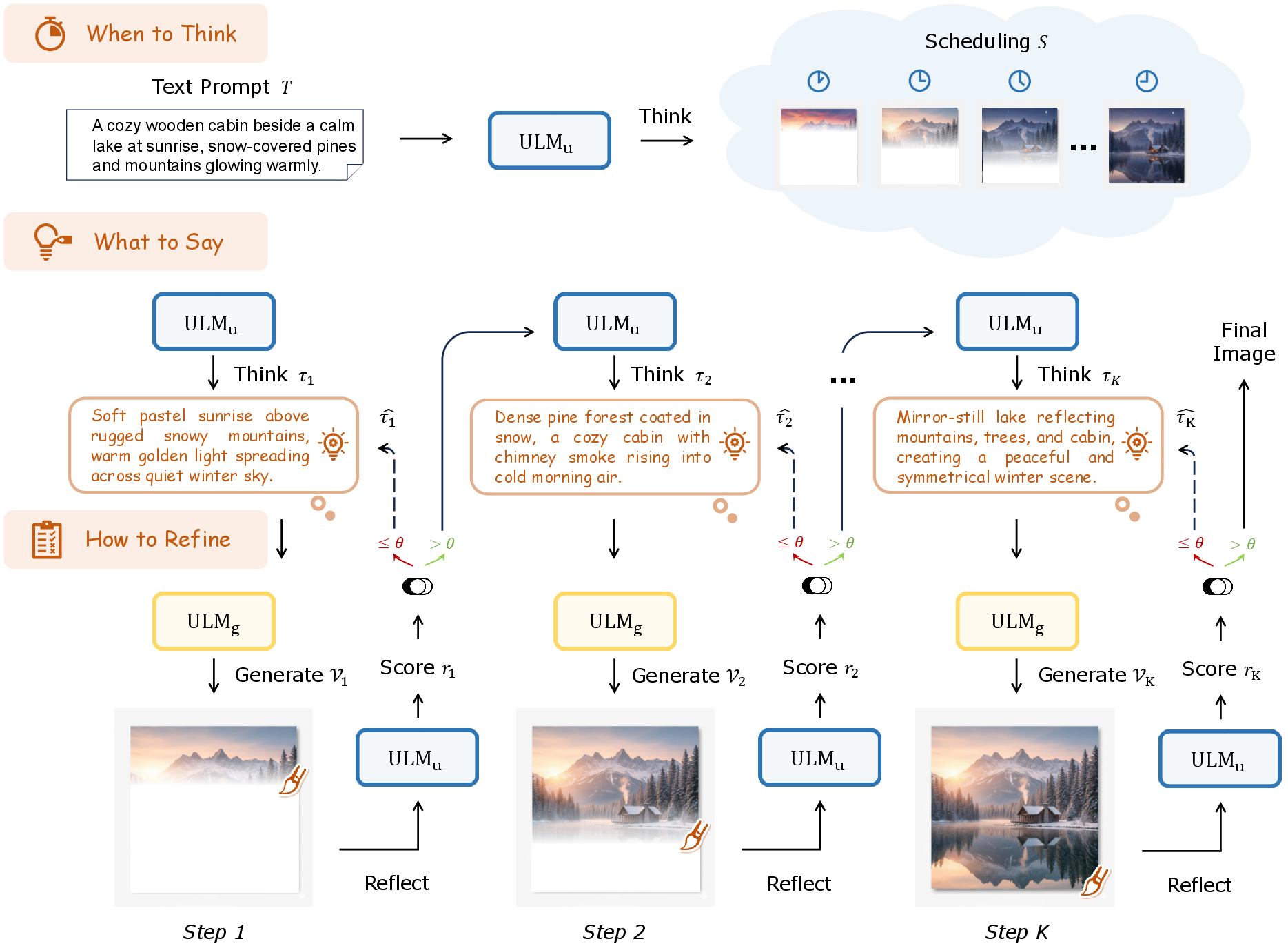
Figure 3: Overall pipeline of TwiG, detailing the interplay between reasoning schedule, fine-grained guidance, and region-level reflection for continual refinement.
Implementation Strategies
Three routes are explored:
1. Zero-Shot Prompting
Carefully designed interleave-aware prompts are used to elicit TwiG behavior from ULMs without additional training. This route exploits the latent reasoning capacity of ULMs, with prompt engineering coordinating the generation schedule, localized reasoning, and regional reflection criteria.
Notably, TwiG-ZS achieves substantial performance improvements over Janus-Pro-7B: e.g., Color increases from 63.59 to 73.11, Texture from 49.36 to 64.77, and Complexity from 35.59 to 48.16 on T2I-CompBench++. Ablation indicates that three-step uniform scheduling yields optimal results and a single round of regional reflection is sufficient given current ULM capabilities.
2. Supervised Fine-Tuning (SFT)
A curated dataset (TwiG-50K) is constructed with explicit supervision over nine subtasks (three for thinking, three for reflection/critique, three for region-wise generation). SFT results in consistent performance gains with improved region-wise attribute binding and spatial relationship adherence, and marked increases in output stability. Balanced task composition in SFT is necessary; oversupplying reflection data can degrade results, likely due to excessive corrective interventions reducing model focus on stable region-wise generation.
3. Reinforcement Learning (RL) with GRPO
The customized TwiG-GRPO strategy leverages Group Relative Policy Optimization to jointly reinforce all reasoning and generation passes within each rollout. An ensemble of reward models (human preference, object grounding, VQA consistency, and fine-tuned LMM alignment) yields best overall balance and mitigates reward hacking. RL notably advances performance boundaries: TwiG-RL achieves Color of 82.49, Texture of 73.19, Complexity of 53.56, outperforming strong supervised and zero-shot baselines.
Qualitative and Process Analysis

Figure 4: Qualitative comparison among TwiG variants, highlighting progressive improvements in compositional fidelity and realism.
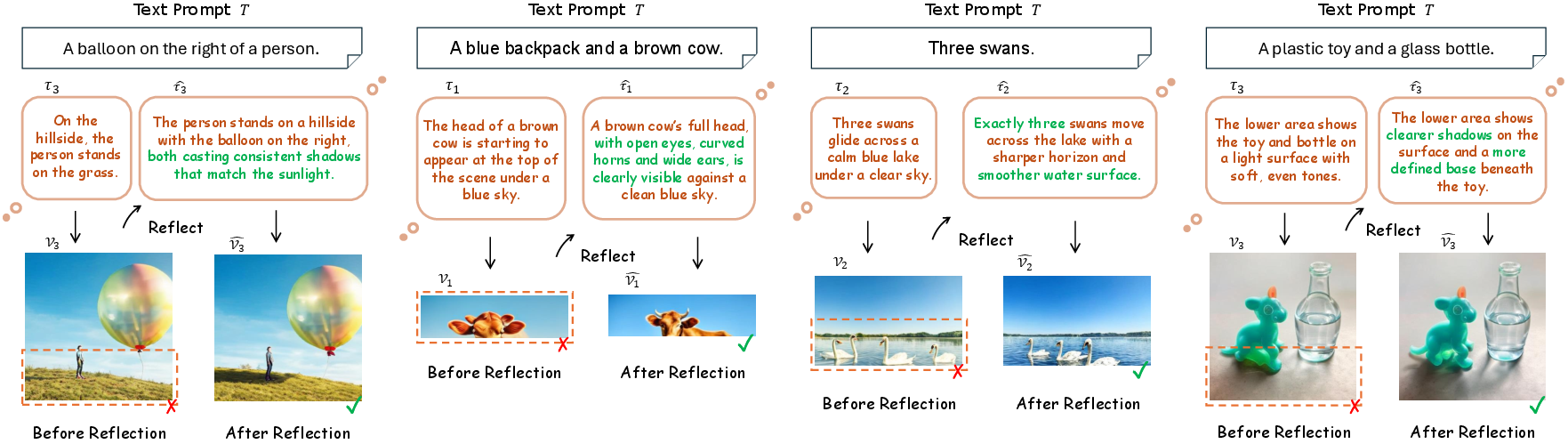
Figure 5: TwiG-RL’s reflection capacity, demonstrating improved semantic and visual consistency following targeted region-level revision.

Figure 6: Iterative TwiG-RL process, visualizing interleaved textual thoughts and visual outputs leading to refined compositional accuracy.
Empirical Results and Claims
- Superior attribute binding and compositionality: TwiG-RL outperforms baseline and prior SOTA generative models in both object-attribute and spatial relationship metrics.
- On-the-fly correction: Regional reflection substantially improves local alignment and visual consistency within a single trajectory, with minimal computational overhead.
- Implementation flexibility: The TwiG paradigm can be instantiated via prompt engineering, SFT, or RL, allowing practitioners flexibility in balancing efficiency and output quality.
- Generality: The proposed interleaved framework is compatible with multimodal, autoregressive, discrete, and diffusion-based models, and extensible to tasks beyond text-to-image such as image-to-image, text-to-video, and text-to-3D.
Implications and Future Directions
The TwiG paradigm formalizes a cross-modal reasoning protocol with granularity and temporal synchronization, bridging concepts from chain-of-thought prompting in language modeling with region-level guidance in visual synthesis.
Theoretical implications include:
- Dynamic reasoning-agent integration: TwiG aligns multimodal autoregressive policies to operate as explicit stepwise planners and critics within the synthesis loop, facilitating future advances in agentic multimodal generation.
- Curriculum learning and adaptive scheduling: The fixed-step schedule, while general, is sub-optimal; future TwiG variants may incorporate adaptive schedules informed by model-internal analysis or external utility functions, contingent on advances in multimodal planning capacity.
- Scalability and multimodal extension: RL techniques such as GRPO, coupled with ensemble reward models, are shown to be tractable and effective for incentivizing attribute and compositional reasoning, suggesting readiness for scaling to more complex modalities (video, 3D) and longer horizons.
Practical implications include enhancements in controllable image synthesis for creative, industrial, and scientific applications, bridging the gap between user intent, model reasoning capacity, and visual fidelity.
Conclusion
This work establishes the first fully interleaved textual reasoning framework for visual generation, demonstrating empirically that co-evolving textual thoughts within the synthesis trajectory yields substantial improvements in compositional accuracy, attribute binding, and semantic consistency. The integration of prompt engineering, SFT, and RL offers flexible routes for deployment, each yielding competitive gains contingent on resource and fidelity requirements. Extension to adaptive scheduling, multimodal domains, and synergistic planning remains promising for future research in generative AI systems.

