- The paper introduces thought templates as modular, reusable reasoning patterns that structure multi-hop inference in long-context language models.
- It proposes an iterative update mechanism that refines templates using textual gradient feedback to correct model errors.
- Empirical evaluations across multiple QA datasets demonstrate significant performance gains and improved transferability over existing methods.
Reusable Reasoning for Long-Context LLMs via Thought Templates
Motivation and Problem Setting
The paper addresses a critical limitation in Long-Context LLMs (LCLMs): while these models can ingest hundreds of thousands of tokens, simply increasing the volume of accessible documents does not guarantee improved multi-hop reasoning. The bottleneck shifts from evidence retrieval to the structuring and composition of reasoning over abundant knowledge. Existing paradigms such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) prompting are either susceptible to cascading retrieval errors or lack explicit, reusable strategies for integrating evidence across multiple steps. The authors propose that LCLMs require not just more facts, but structured, reusable reasoning patterns to guide inference.
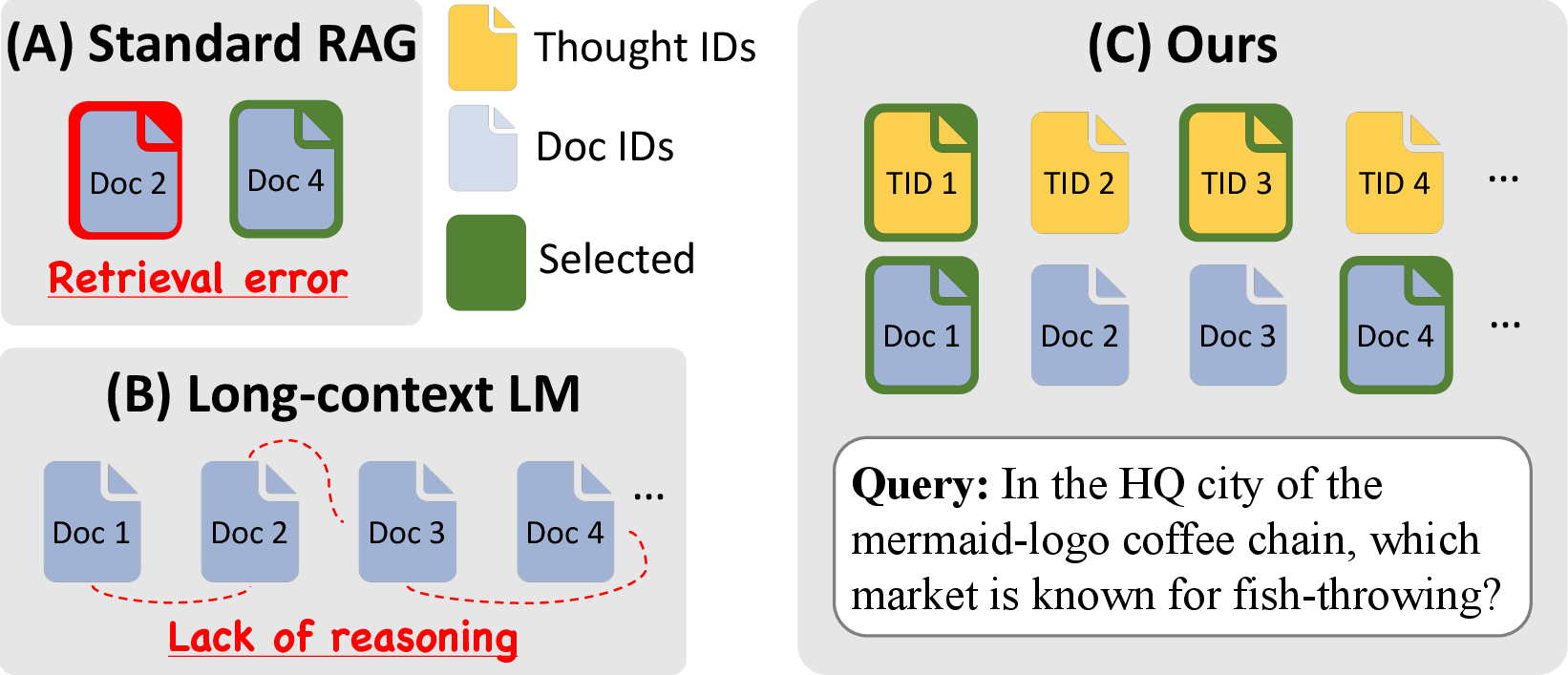
Figure 1: Thoughts and facts in LCLM, compared to transitional RAG and simple stuffing in LCLM.
Thought Template Augmented LCLMs (ToTAL): Framework Overview
ToTAL introduces "thought templates"—modular, reusable reasoning patterns distilled from prior problem-solving traces. These templates serve as epistemic scaffolds, guiding LCLMs in organizing and composing evidence for multi-hop inference. The framework consists of three main components:
- Template Construction: Templates are automatically generated from multi-hop QA datasets by prompting an LCLM with training queries, gold answers, and solution paths. Unlike prior work that retrieves a single, query-specific reasoning trace, ToTAL decomposes solutions into sub-templates, enabling compositionality and reusability across queries.
- Template Update via Textual Gradients: Initial templates may be noisy or suboptimal. ToTAL iteratively refines templates using natural-language feedback derived from model errors. Low-performing templates are identified via hit/miss statistics, and feedback is generated by an auxiliary LM, functioning as a surrogate gradient. Update actions (Keep, Fix, Add, Discard) are determined, and templates are revised accordingly.
- Inference: At test time, the LCLM is conditioned on the query, the large evidence set, and the template pool. The model selectively composes relevant templates to structure its reasoning.
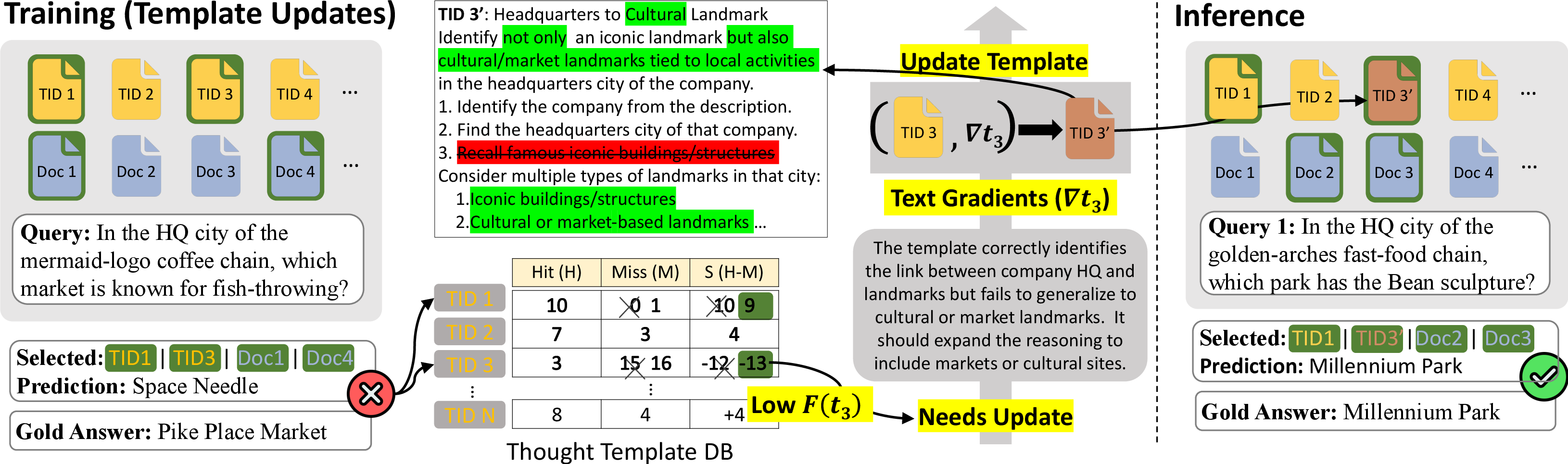
Figure 2: Illustration of training and inference stages for template updates. Low-performing templates are identified via hit/miss statistics and refined with textual gradient feedback, enabling improved performance on new queries during inference.
Empirical Evaluation
Benchmarks and Baselines
ToTAL is evaluated on four multi-hop QA datasets: MuSiQue, CRAG, FanOutQA, and Housing QA. Baselines include Naïve (no external context), CoT prompting, Corpus-in-Context (CiC, stuffing all documents), and CiC+CoT. Experiments span both retrieval-free (full corpus in context) and retrieval-augmented regimes, using proprietary (Claude, Gemini, GPT-4.1) and open-source (OSS-120B, DeepSeek-R1) LLMs.
Main Results
ToTAL consistently outperforms all baselines across datasets and LCLMs. For example, on MuSiQue with Claude, ToTAL achieves an F1 of 73.3, compared to 65.07 for CiC+CoT and 27.57 for Naïve. Gains are robust in both full-context and retrieval-augmented settings, with ToTAL providing complementary improvements over document retrieval alone.
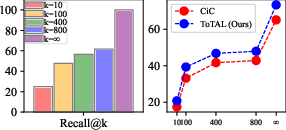
Figure 3: RAG results on MuSiQue, showing retrieval recall at different k values (left) and QA performance (F1) (right).
Template Update Ablation
Iterative template refinement via textual gradients yields clear performance improvements, with diminishing returns after two iterations, indicating convergence of the template pool.
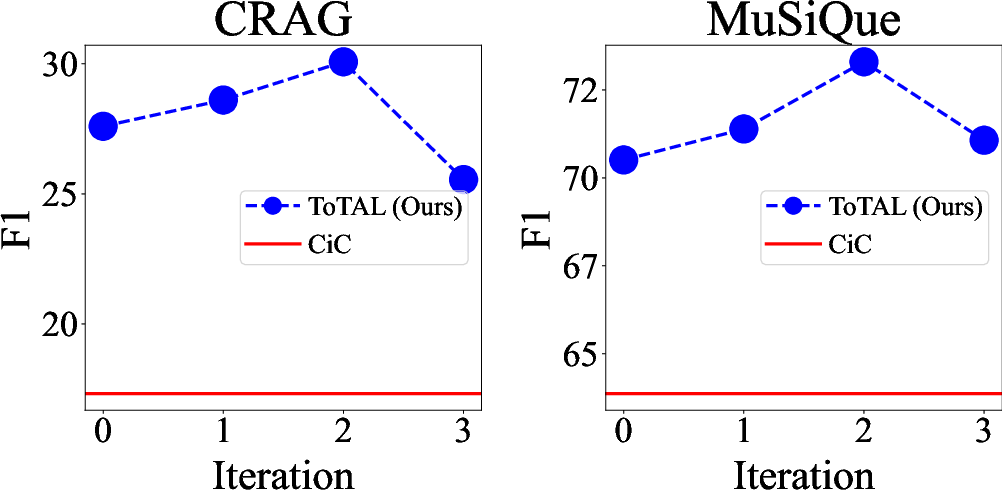
Figure 4: Iteration results of updates on CRAG and MuSiQue.
Transferability and Generalization
Templates distilled from one LCLM generalize well to others, including open-source models, demonstrating model-agnostic reasoning structures. Even templates generated and refined entirely by open-source LLMs surpass CiC baselines, though frontier models yield higher template quality.
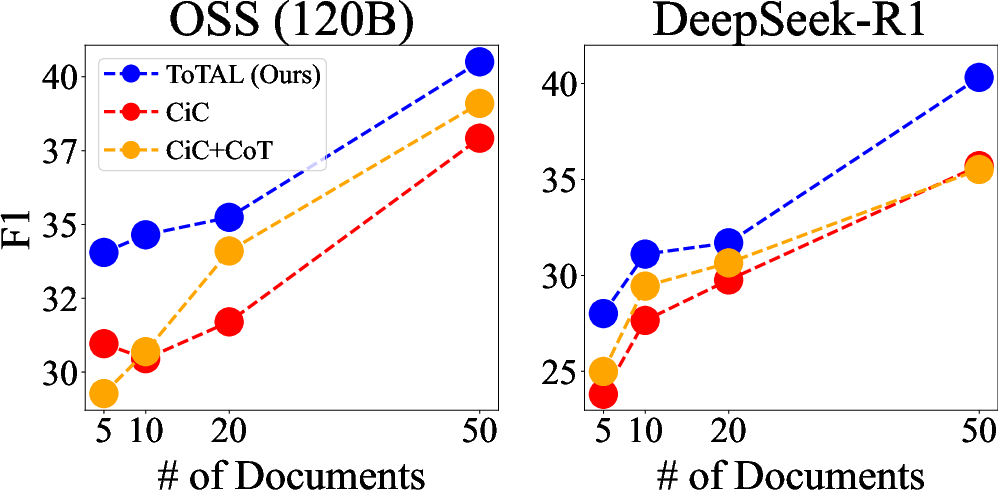
Figure 5: Generalization of templates to open-source models.
Template Quantity and Compositionality
Performance remains competitive with only the top 25% of templates, but the full set yields the best results. Removing compositionality (i.e., using holistic templates) causes a measurable drop in performance, confirming the benefit of modular, compositional design.
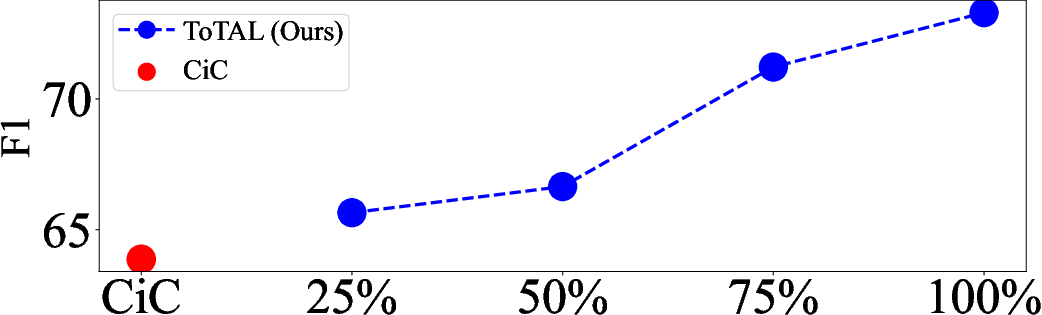
Figure 6: Varying the percentage of templates on MuSiQue.
Template–Query Clustering and Usage Analysis
TSNE visualizations show that queries and their associated templates form coherent clusters, reflecting domain-specific reasoning patterns. Template usage exhibits a long-tail distribution, with a few templates reused frequently and many invoked rarely. Co-occurrence analysis reveals stable compositional units and domain-specific template bundles, especially in legal QA.
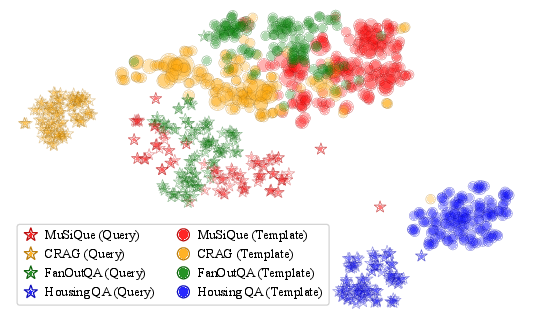
Figure 7: TSNE of the queries and templates, using embeddings from Sentence-BERT.
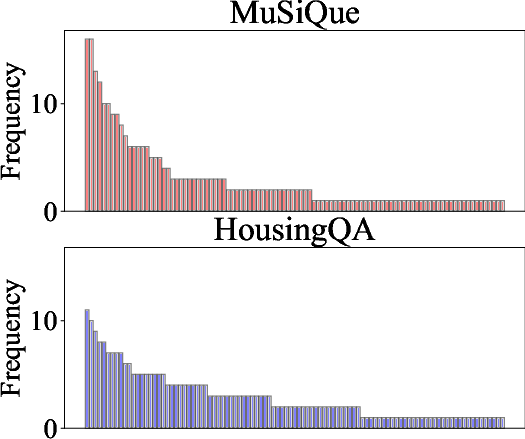
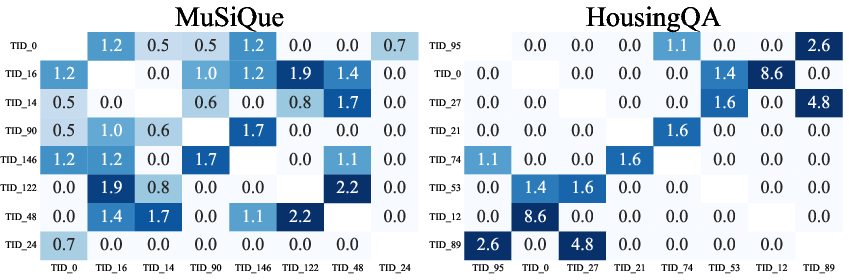
Figure 8: Template frequencies.
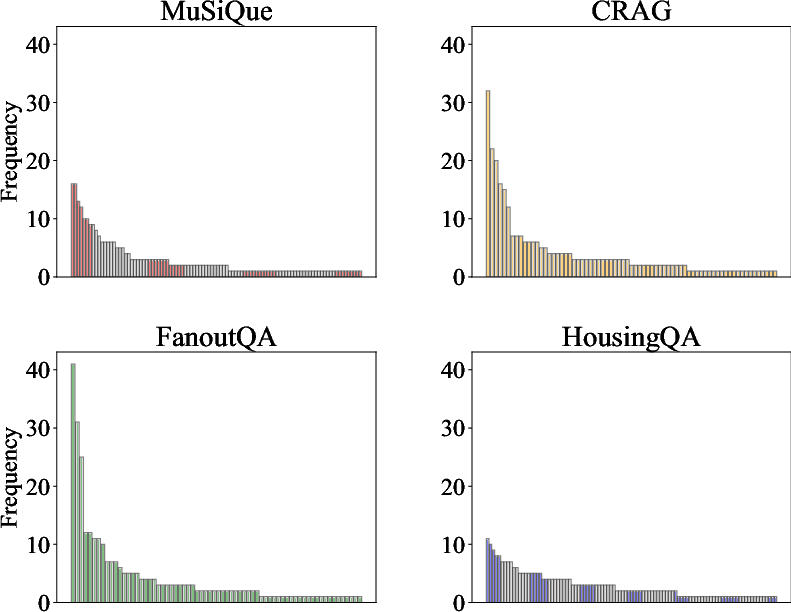
Figure 9: Histogram of template frequencies across datasets.
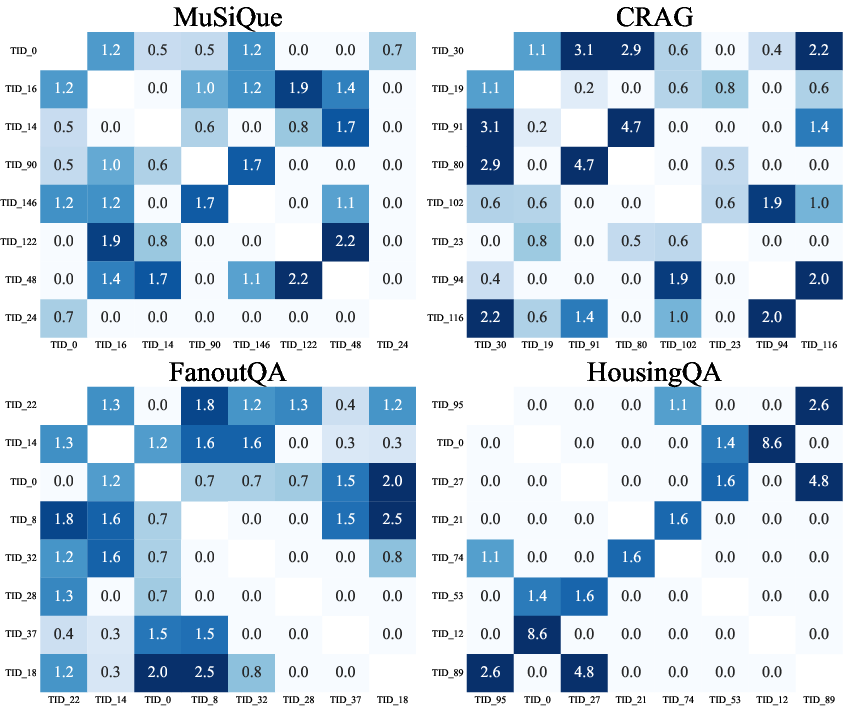
Figure 10: Template co-occurrence heatmap of lift values across datasets.
Qualitative Analysis
Case studies demonstrate that ToTAL enables LCLMs to bridge retrieved facts into coherent multi-hop explanations, decomposing queries into explicit, interpretable reasoning steps. Template refinement via textual gradients improves consistency and reliability in multi-hop chains, as shown in comparative examples.
Implementation Considerations
- Computational Requirements: Template construction and update require additional LM inference, but no model finetuning is needed. The approach is compatible with both proprietary and open-source LLMs.
- Scalability: Template pools can be pruned based on usage statistics, and compositionality enables efficient generalization.
- Deployment: Templates can be distilled and transferred across models, supporting transparent reasoning reuse and auditability.
- Limitations: The method assumes access to training queries and answers for template construction. In low-resource domains, bootstrapping or synthetic data generation may be necessary. Feedback quality depends on the auxiliary LM, and future work may explore more robust update mechanisms.
Theoretical and Practical Implications
ToTAL demonstrates that augmenting LCLMs with structured, reusable reasoning patterns substantially improves multi-hop inference, even as context windows scale. The framework decouples reasoning strategy from factual knowledge, enabling compositional, model-agnostic transfer. This approach suggests a paradigm shift: LCLMs should be equipped not only with large context windows but also with explicit, modular reasoning scaffolds. Future directions include automatic template search, meta-learning for reasoning refinement, and extension to multimodal or more structured templates.
Conclusion
The paper establishes that reusable, compositional thought templates—iteratively refined via textual gradients—significantly enhance the reasoning capabilities of LCLMs in knowledge-intensive multi-hop tasks. The approach is robust across models, domains, and retrieval regimes, and supports transparent, transferable reasoning. These findings motivate further research into modular reasoning augmentation, scalable template construction, and broader applications in agentic and multimodal AI systems.

