- The paper introduces a dual-path architecture that combines causal convolution and associative memory to achieve O(N) efficiency in sequence modeling.
- It demonstrates the efficacy of dynamic gating and residual connections in fusing local syntactic cues with global semantic context.
- Empirical results on datasets like WikiText-2 and TinyStories show improved perplexity and faster training compared to traditional Transformer models.
Gated Associative Memory: A Parallel O(N) Architecture for Efficient Sequence Modeling
Introduction
The Gated Associative Memory (GAM) architecture presents a fully parallel, non-recurrent alternative to the Transformer for sequence modeling, achieving linear computational complexity with respect to sequence length. GAM is motivated by the prohibitive O(N2) scaling of self-attention, which limits the practical sequence length for Transformer-based models. By decomposing context modeling into two parallel pathways—a causal convolution for local context and an associative memory retrieval for global context—GAM enables efficient, scalable sequence processing. The architecture is designed to maximize hardware parallelism, leveraging primitives that are well-suited to modern accelerators.
Architecture Overview
GAM is constructed as a stack of identical blocks, analogous to the Transformer, but with a fundamentally different core operation. Each GAM block processes input token embeddings through a sequence of operations: layer normalization, parallel local/global context computation, dynamic gating and fusion, residual connections, and a feed-forward network.
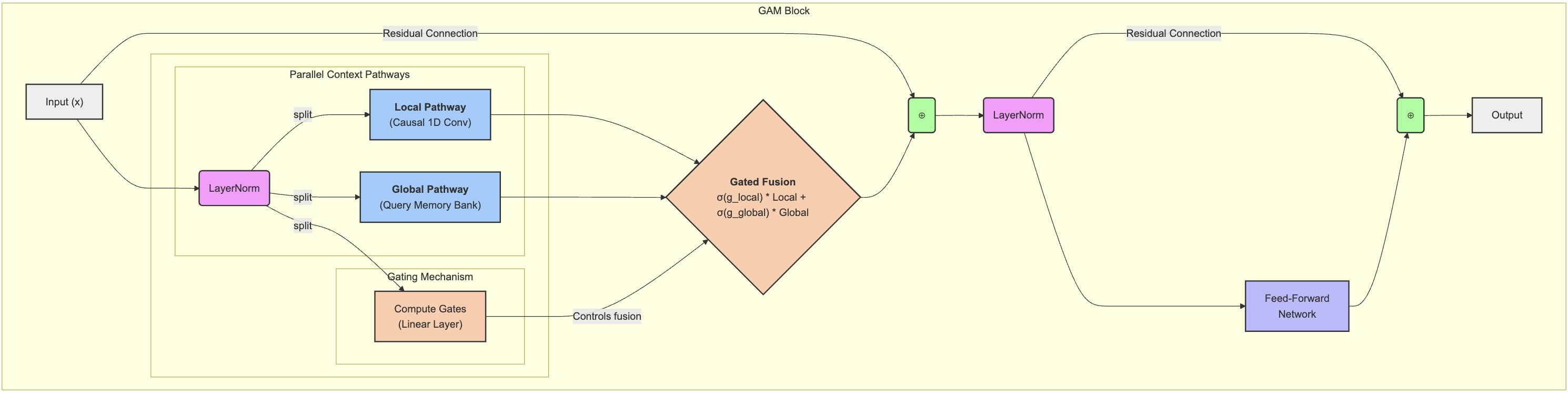
Figure 1: The GAM block architecture, illustrating the parallel computation of local and global context, dynamic gating, and residual connections.
Local Context Pathway: Causal Convolution
The local pathway employs a 1D causal convolution with kernel size k, capturing positional and syntactic dependencies within a fixed window. Depthwise convolution is used for parameter efficiency, and asymmetric padding ensures causality. The operation is highly parallelizable and scales as O(N⋅k⋅d), where N is sequence length and d is model dimension.
Global Context Pathway: Parallel Associative Memory
The global pathway utilizes a learnable memory bank M of size (num_slots, d). For each token, dot-product similarity scores are computed against all memory slots, followed by a softmax to produce retrieval weights. The global context is then a weighted sum of memory vectors, computed in parallel for all tokens. This mechanism replaces self-attention, achieving O(N) complexity with respect to sequence length.
Gating and Fusion
A learned gating mechanism dynamically fuses the local and global contexts for each token. The gate is computed via a linear projection of the input, split into local and global components, and modulated by a sigmoid activation. This enables the model to allocate attention between local syntactic cues and global semantic patterns on a per-token basis.
Computational Efficiency and Scaling
GAM's design yields significant improvements in both runtime and memory usage compared to the Transformer. Empirical scaling benchmarks demonstrate that GAM maintains linear growth in both forward-backward pass time and peak GPU memory as sequence length increases, while the Transformer exhibits quadratic scaling and fails due to out-of-memory errors at moderate sequence lengths.
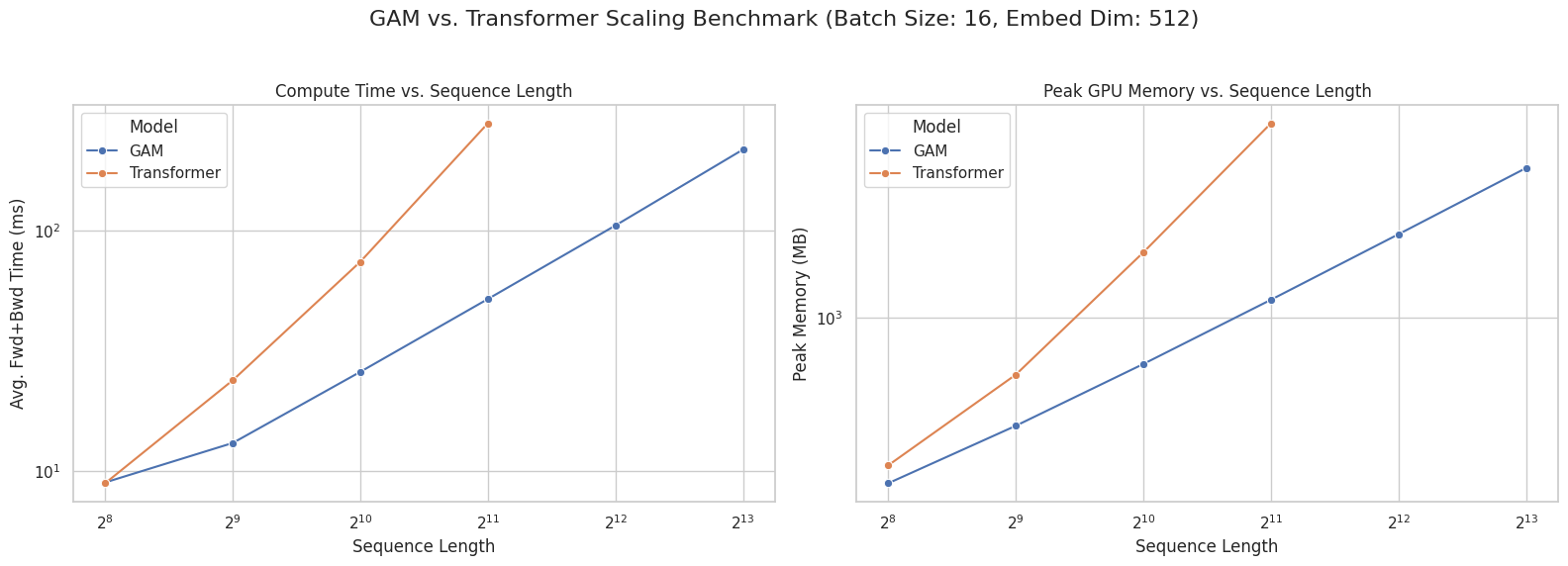
Figure 2: GAM vs. Transformer scaling comparison, showing linear scaling for GAM and quadratic scaling for the Transformer in both runtime and memory usage.
At sequence lengths beyond 2048, the Transformer is unable to process inputs due to memory constraints, whereas GAM continues to scale linearly, validating its suitability for long-context applications.
Experiments were conducted on WikiText-2 and TinyStories datasets, comparing GAM against a standard Transformer and the Mamba linear-time baseline. All models were matched in parameter count and trained under identical conditions.
GAM consistently outperformed both baselines in training speed and final validation perplexity. On WikiText-2, GAM achieved a perplexity of 882.57, compared to 918.99 for the Transformer and 1017.54 for Mamba. On TinyStories, GAM achieved 23.15 versus the Transformer's 23.55. These results indicate that GAM's parallel architecture does not compromise modeling capacity and, in fact, provides superior performance.
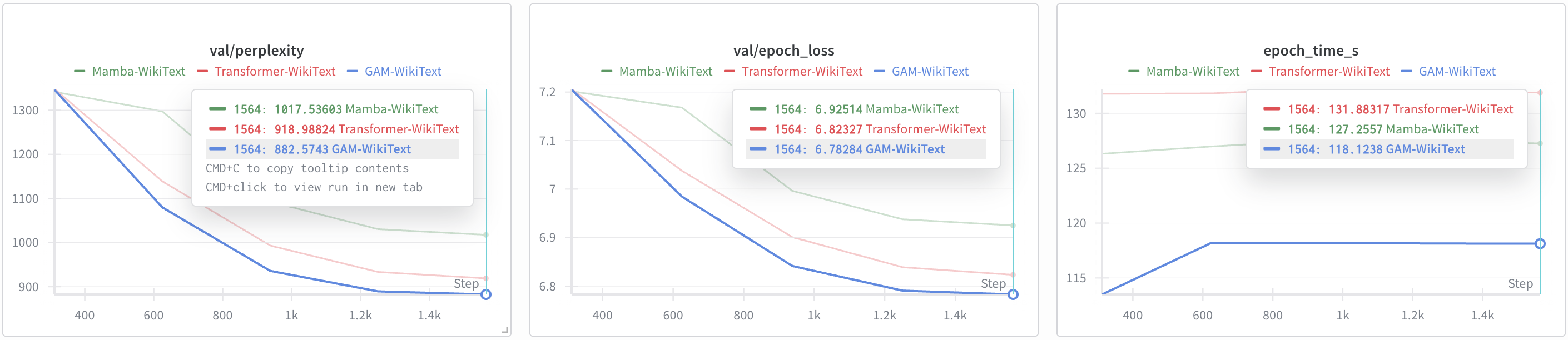
Figure 3: Training dynamics on WikiText-2, with GAM achieving lower perplexity and faster epoch times than Transformer and Mamba.
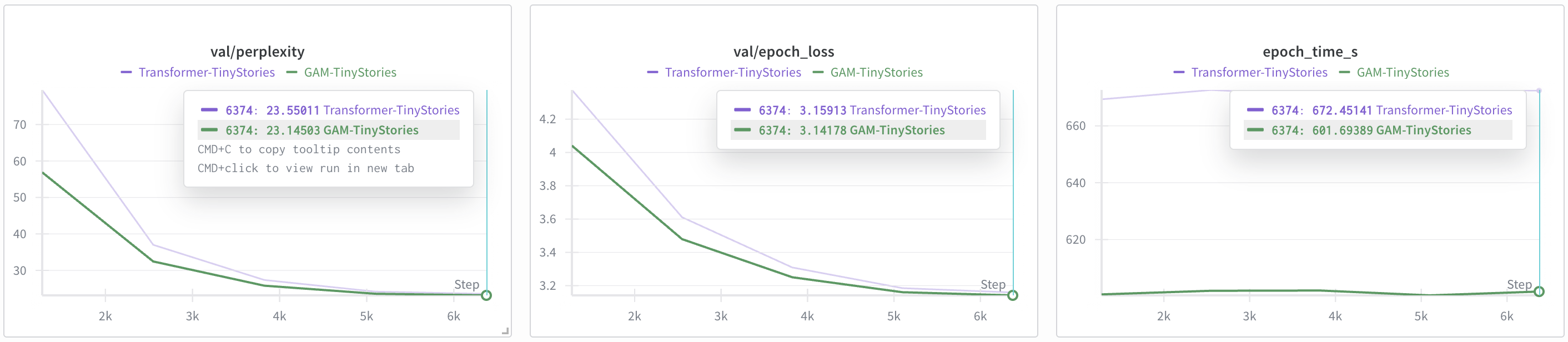
Figure 4: Training dynamics on TinyStories, with GAM demonstrating faster learning and sustained efficiency advantage over the Transformer.
Ablation Study
Ablation experiments on WikiText-2 dissected the contributions of the local pathway, global pathway, and gating mechanism. The full GAM model achieved the lowest perplexity, while removing the gating mechanism or either pathway resulted in significant degradation. The global associative memory was identified as the primary driver of performance, but the local convolution provided complementary syntactic information. The gating mechanism was essential for effective fusion, with static summation yielding suboptimal results.
Theoretical and Practical Implications
GAM demonstrates that quadratic self-attention is not a prerequisite for high-performance sequence modeling. The explicit separation of local and global context, combined with dynamic gating, provides a robust inductive bias that generalizes across diverse textual domains. GAM's linear scaling enables practical deployment in long-context scenarios, such as document summarization, genomics, and video processing, where Transformer-based models are infeasible.
The associative memory bank introduces a new paradigm for global context modeling, distinct from attention-based mechanisms. Its learnable slots may encode prototypical semantic patterns, offering interpretability and potential for further analysis.
Future Directions
Several avenues for future research are suggested by the GAM architecture:
- Long-Range Benchmarks: Evaluation on datasets with much longer sequences (e.g., Long Range Arena) to fully exploit GAM's linear scaling.
- Scaling Model Size: Training larger GAM models on extensive corpora to assess performance ceilings relative to state-of-the-art architectures.
- Memory Bank Analysis: Investigating the representations learned by the associative memory slots for interpretability and knowledge extraction.
- Task Generalization: Extending GAM to non-language domains, such as time series, audio, and multimodal data, leveraging its parallelism and context modeling capabilities.
Conclusion
The Gated Associative Memory architecture provides a fully parallel, linear-time alternative to the Transformer for sequence modeling. By combining causal convolution and associative memory retrieval, dynamically fused via learned gating, GAM achieves superior efficiency and competitive or improved accuracy on standard language modeling benchmarks. Its design principles challenge the necessity of quadratic self-attention and open new directions for scalable, interpretable sequence models in both research and practical applications.