- The paper demonstrates that F-CoT restructures inputs by separating fact extraction and reasoning, achieving a 2–3× token reduction while maintaining accuracy.
- It employs a two-stage prompting protocol—context extraction followed by focused reasoning—to minimize overthinking and improve inference efficiency.
- Empirical results on mathematical benchmarks confirm drastic token savings, practical cost reductions, and potential for scalable LLM deployment.
Introduction and Motivation
The paper explores inference efficiency in LLMs tackling complex reasoning tasks, primarily in mathematical domains. Traditional chain-of-thought (CoT) prompting improves interpretability and accuracy but incurs high computational and time costs due to lengthy reasoning traces. Existing methods to mitigate inference cost focus on altering model behavior—rewards for brevity, fine-tuning, or explicit instructions to reduce output verbosity. In contrast, this study advances an input-centric, training-free approach: Focused Chain-of-Thought (F-CoT), which restructures the input representation by explicitly separating relevant information extraction from downstream reasoning.
F-CoT operationalizes principles from cognitive psychology, especially the Active Control of Thought (ACT) framework, emphasizing sequential and resource-efficient problem solving via distinct information extraction and reasoning phases. The hypothesis is that explicitly structured input blocks sharpen attention, minimize overthinking, and reduce extraneous token generation, thus enhancing inference efficiency without diminishing final reasoning correctness.
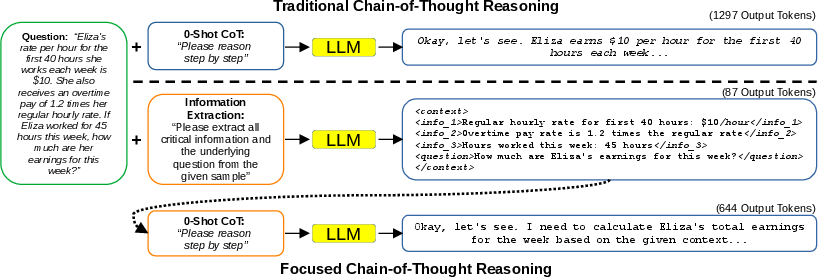
Figure 1: The F-CoT process: extraction of key facts into an XML context block, followed by focused reasoning that yields significantly shorter traces compared to standard CoT prompting.
Methods: Structured Reasoning Pipeline and Implementation
F-CoT utilizes a two-stage prompting protocol:
- Context Extraction: The LLM receives a prompt instructing it to extract all information pertinent to the question into a compact, structured format (e.g., XML-like blocks with enumerated facts and the formal question). This can be either manually provided by the user or automatically generated—possibly by a distinct, larger LLM.
- Reasoning over Context: The LLM is then prompted to perform stepwise reasoning solely with this compact context, explicitly citing relevant information blocks. The original verbose natural-language question is omitted.
The framework supports both user-defined contexts and automatic extraction through two-step LLM prompting. Empirically, structured formats (XML, enumerated lists) are effective not due to their syntax but their focus and compactness. The abstraction is robust—other schema can also be used for context—but stronger structure further decreases average output length.
Experimental Evaluation and Results
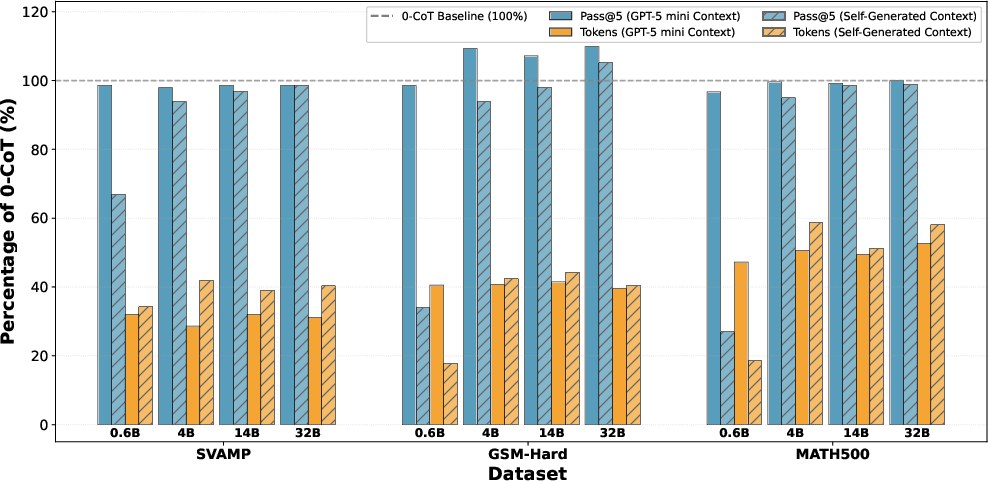
Experiments focus on arithmetic and mathematical benchmarks (SVAMP, GSM-Hard, MATH-500, AIME) using Qwen3 models (0.6B to 32B) and GPT-5 mini for context extraction. Performance is measured via Pass@5 score and average token length per problem, comparing F-CoT with standard zero-shot CoT and other prompting approaches (Plan-and-Solve, CoRe).
Strong empirical claims:
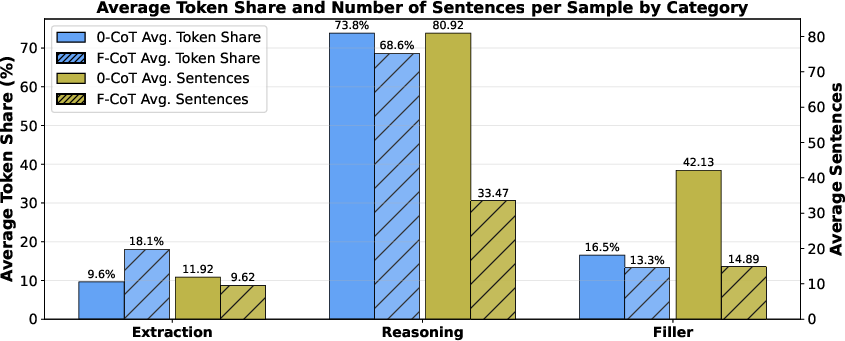
Further annotation of reasoning traces shows:
Contradictory or Bold Findings:
- Explicit instructions or fine-tuning to promote brevity are not necessary; restructuring the input alone yields substantial efficiency gains.
- Introducing structured context to already condensed mathematical problems (e.g., AIME) gives further token savings but may slightly reduce accuracy, possibly due to test set contamination or loss of implicit contextual cues.
Sensitivity and Ablation:
- Removing explicit prompt instructions or providing both the question and context slightly increases token count and accuracy, indicating robustness but optimality for F-CoT's strict context-only approach.
- Increasing the degree of input structure (numbering, formal blocks) decreases token count further without affecting accuracy.
- Context validity and extraction reliability saturate at mid-scale architecture sizes; larger models do not further improve structured extraction.
Implications and Future Directions
Practical Implications
F-CoT provides a general, training-free method to accelerate LLM inference for reasoning tasks, agnostic to underlying architecture or training protocol. It is highly practical for real-world deployment where latency and compute cost are critical, especially in agentic and math-intensive domains. The separation of extraction and reasoning phases not only improves interpretability and debugging, but also pipeline modularity for scalable LLM service ecosystems; context blocks can be reused, cached, or iteratively updated with minimal rework.
Theoretical Implications
The results suggest that LLMs overthink and attend to irrelevant aspects of raw, verbose input due to the entwined nature of extraction and reasoning in natural language. Decoupling these steps via structured input mimics resource-efficient, human-like cognitive architectures. This aligns with theories of attention and working memory, indicating possible directions for architectural or training-time modifications—training LLMs to natively process and reason over structured input formats.
Outlook and Future AI Research
Extension of F-CoT is promising for multimodal reasoning tasks, e.g., vision-LLMs, where compact, structured representations of visual facts may similarly reduce inference cost. It can be integrated with advanced test-time scaling strategies (e.g., tree-of-thought, s1 scaling) or as part of dynamic agentic context ("notepad") updating schemes. Future work may also investigate F-CoT's application in training-time interventions or direct architecture modifications to further embed efficient reasoning priors.
Conclusion
F-CoT establishes that input-centric restructuring—explicit information extraction followed by context-bound reasoning—is a powerful alternative to model-centric optimization for efficient LLM reasoning. The method achieves substantial reductions in token usage and inference latency, maintaining or exceeding baseline accuracy. The findings highlight the latent efficiency gains unlocked by structured input representation, providing new avenues for practical and theoretical advancement in scalable AI reasoning systems.