SwiftVLA: Unlocking Spatiotemporal Dynamics for Lightweight VLA Models at Minimal Overhead
Abstract: Vision-Language-Action (VLA) models built on pretrained Vision-LLMs (VLMs) show strong potential but are limited in practicality due to their large parameter counts. To mitigate this issue, using a lightweight VLM has been explored, but it compromises spatiotemporal reasoning. Although some methods suggest that incorporating additional 3D inputs can help, they usually rely on large VLMs to fuse 3D and 2D inputs and still lack temporal understanding. Therefore, we propose SwiftVLA, an architecture that enhances a compact model with 4D understanding while preserving design efficiency. Specifically, our approach features a pretrained 4D visual geometry transformer with a temporal cache that extracts 4D features from 2D images. Then, to enhance the VLM's ability to exploit both 2D images and 4D features, we introduce Fusion Tokens, a set of learnable tokens trained with a future prediction objective to generate unified representations for action generation. Finally, we introduce a mask-and-reconstruct strategy that masks 4D inputs to the VLM and trains the VLA to reconstruct them, enabling the VLM to learn effective 4D representations and allowing the 4D branch to be dropped at inference with minimal performance loss. Experiments in real and simulated environments show that SwiftVLA outperforms lightweight baselines and rivals VLAs up to 7 times larger, achieving comparable performance on edge devices while being 18 times faster and reducing memory footprint by 12 times.
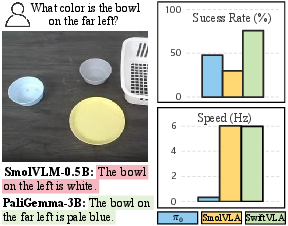


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SwiftVLA: A simple explanation
1. What is this paper about?
This paper is about teaching small, fast robot brains to understand the world in space and time almost as well as much bigger, slower ones. The authors build a system called SwiftVLA that helps compact robots “see” 3D scenes as they change over time (that’s “4D”: 3D plus time) using only normal camera images. The trick is to learn from rich 4D clues during training, but keep the robot fast and light when it’s actually working.
2. What questions are the researchers asking?
They focus on three big questions:
- How can small vision–language–action (VLA) models get strong 3D-and-time understanding without becoming huge and slow?
- Can we turn regular 2D camera frames into useful 4D information without adding extra sensors like depth cameras or LiDAR?
- Is it possible to train with extra 4D help but run the robot later without that extra cost, with almost no loss in performance?
3. How does SwiftVLA work? (In everyday language)
Think of a robot that reads an instruction (“stack the bowls”), looks through cameras, and then moves its arm. A smart robot needs to know where things are in 3D and how they move over time.
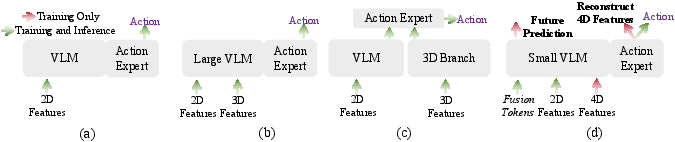
SwiftVLA adds three key ideas:
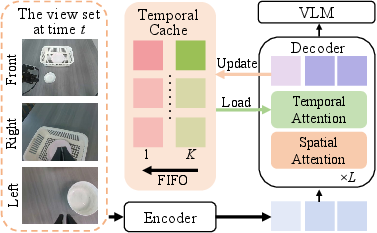
- A 4D builder with a short-term memory:
- From standard camera images, a pretrained “4D visual geometry transformer” builds a moving 3D picture of the scene (that’s the 4D feature).
- It uses a “temporal cache,” which is like a short-term memory, to remember what it saw in recent frames. This gives the robot context about how things are changing.
- Importantly, this needs no extra sensors—just the cameras you already have.
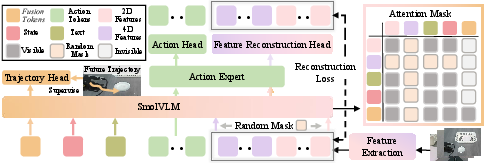
- Fusion Tokens: the glue that makes signals work together
- The robot has different signals: 2D image features, the new 4D features, language instructions, and its own state (like the arm’s position).
- “Fusion Tokens” are small learnable helpers inside the model that pull these signals together. They’re trained to predict the robot hand’s near-future path (its end-effector trajectory), so they learn to fuse information in a way that directly helps with action.
- Mask-and-reconstruct training: a game of hide-and-seek
- During training, the system sometimes hides (masks) either the 2D or the 4D information.
- The model has to both plan the action and “rebuild” the missing features from what’s left.
- This forces the robot to understand the geometry and motion well, and to connect the dots between different types of information.
- After training, you can turn off the 4D branch to run faster. Because the model learned to “rebuild” 4D ideas from 2D images, it keeps most of its 4D smarts without the extra cost.
Behind the scenes, SwiftVLA uses a compact vision–LLM (a lightweight VLM) and an “action expert” that produces smooth, continuous robot motions. You can think of the action expert like a tool that cleans up noisy guesses to produce precise movements.
4. What did they find, and why is it important?
In tests with both simulators and real robots (tasks like cleaning a desk, throwing a bottle into a bin, and stacking bowls), SwiftVLA:
- Beats other small/budget models by a clear margin.
- Matches or comes close to the performance of much larger models (up to 7 times bigger).
- On a small computer (NVIDIA Jetson Orin), it runs about 18 times faster and uses about 12 times less memory than a strong large baseline, while keeping similar success rates.
Why this matters:
- Small, fast, and accurate models are crucial for real robots that need to react in real time, especially on affordable hardware.
- Better 3D-plus-time understanding means more precise grasping, fewer collisions, and higher success on tricky tasks.
5. What’s the bigger impact?
SwiftVLA shows a practical path to “learn heavy, run light”:
- Train with rich 4D signals and special tricks (Fusion Tokens and hide-and-seek reconstruction) to build deep spatial and temporal understanding.
- Then deploy a slim version that needs only regular images, making it cheap, fast, and easier to use in homes, warehouses, and other real-world places.
- This approach could help many small robots become safer and more reliable at tasks that require careful 3D reasoning over time, without needing expensive hardware or huge models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the paper, framed to guide future research:
- Sensitivity to 4D feature quality and domain shift: How performance depends on the pretrained 4D visual geometry transformer (StreamVGGT) under varying scene types, lighting, textureless surfaces, and motion blur, and whether domain-adapting or fine-tuning the 4D extractor would materially change results.
- Camera configuration dependence: The method assumes multi-view inputs (left/right/front) and only feeds the front-view 4D features to the VLM; the impact of single-camera setups, miscalibration, varying camera baselines, or different view counts is not quantified.
- Conditions for safe 4D-drop at inference: Clear criteria for when discarding 4D inputs yields “minimal performance loss” are not established; failure modes and tasks where 4D inputs remain necessary at deployment are not systematically characterized.
- Training cost and efficiency: The computational and memory overhead introduced by the 4D extractor, mask-and-reconstruct objectives, and trajectory supervision during training are not reported (e.g., training time, GPU hours, energy), leaving unclear whether gains in inference efficiency offset training costs.
- Robustness to partial observability and sensor noise: The approach’s behavior under occlusions, missing frames, asynchronous cameras, rolling-shutter artifacts, or adversarial lighting is untested; resilience of the temporal cache and masked training to such degradations is unknown.
- Temporal cache design limits: Only short FIFO windows and a small set of K values are explored; longer-horizon memory needs, non-FIFO or learned memory mechanisms, and robustness to variable frame rates or action delays remain open.
- Fusion Tokens design space: The number, dimensionality, placement, and attention patterns of Fusion Tokens—and their effect on latency and representation quality—are not ablated; comparative baselines (e.g., adapters, FiLM, low-rank fusion, or gating) are missing.
- Supervision choice for Fusion Tokens: Using only end-effector future trajectory as supervision may bias representations; the value of alternative or additional signals (e.g., contact events, success metrics, affordances, 3D consistency constraints) is unexplored.
- Mask-and-reconstruct strategy details: The mask ratio, schedule, and token selection policy (structured vs. random, temporal vs. spatial) are not fully ablated; comparisons to other distillation/alignment strategies (e.g., contrastive, teacher–student, feature matching at multiple layers) are absent.
- Extent of geometry learned by the VLM: Reconstruction is performed in feature space, but there is no direct evaluation that the VLM internalizes geometry (e.g., probing depth/normal estimation, 3D consistency checks, spatial question answering beyond tasks).
- Multi-view 4D integration: Only the front-view 4D features are consumed by the VLM, with left/right used for cache updates; whether fusing multi-view 4D features at the VLM improves robustness/accuracy is not evaluated.
- Task and embodiment generalization: Generalization to unseen tasks, compositional language instructions, different robot embodiments/action spaces, and varying grippers or kinematics is not assessed.
- Real-world breadth and statistical rigor: Real experiments cover a small set of tasks with limited reporting on the number of trials, variance, and statistical significance; reproducibility across environments and hardware configurations is unclear.
- Language grounding and compositionality: The approach’s instruction-following beyond fixed templates (e.g., novel verbs, multi-step language, spatial relations in text) is not evaluated.
- Action expert design trade-offs: Diffusion policy details (steps, schedulers) and their effect on latency are not reported; comparisons to non-diffusion decoders (e.g., flow matching variants, autoregressive, model predictive control) and mixed-task performance are missing.
- Data efficiency: Learning curves and sample efficiency relative to baselines (especially under low-data regimes) are not provided, despite claims of improved utility from 4D signals and mask-based distillation.
- Integration with additional modalities: How tactile/force feedback, audio, or proprioceptive histories could be fused via Fusion Tokens or the cache to further improve performance is not explored.
- Use of additional range sensors: The paper argues “no additional sensors” are needed; it remains unknown whether cheap depth sensors (e.g., stereo, RGB-D) would yield stronger or more reliable performance than monocular-derived 4D at similar cost.
- Safety and failure analyses: Aside from a qualitative comparison, there is no systematic assessment of collision rates, unexpected contacts, or safe recovery behaviors under policy errors when 4D is dropped at inference.
- Benchmarks beyond LIBERO/RoboTwin: Performance on other standard manipulation suites (e.g., CALVIN, Real-World Manipulation Benchmarks) and in highly dynamic settings (moving obstacles, human–robot interaction) is untested.
- Hyperparameter robustness: Sensitivity analysis for key choices (e.g., mask probabilities, cache size beyond small K, number of visual tokens, skipped VLM layers) is limited, leaving best-practice settings unclear.
- Interpretability of cross-modal fusion: Attention/attribution analyses showing how 2D/4D cues influence decisions are absent; this hinders diagnosing when the model is exploiting geometry vs. memorizing trajectories.
- Deployment realism on edge devices: Real-world experiments used an RTX 4090, while edge deployment metrics are reported separately on Jetson Orin; end-to-end closed-loop performance, thermal limits, and power consumption on the edge platform during real tasks are not demonstrated.
- Code/data availability and reproducibility: Complete training configurations, pretrained weights (including the 4D extractor), and datasets/splits are not fully detailed; reproducibility across labs and hardware remains an open concern.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with current capabilities described in the paper. Each bullet lists the sector, the application, emerging tools/workflows, and key dependencies/assumptions.
- Robotics/Manufacturing/Logistics: Edge-deployable pick-and-place and sorting on low-cost hardware
- What: Replace heavier VLA policies with SwiftVLA for bin picking, order sorting, kitting, and conveyor handoffs on robot arms where latency and memory constraints preclude >3B-parameter VLMs.
- Why now: SwiftVLA achieves near–large-model success rates (comparable to models up to 7× larger) while running 18× faster and using 12× less memory on a Jetson Orin; masking-and-reconstruct training enables inference without a 4D branch.
- Tools/workflow:
- Multi-view RGB setup (e.g., left/right/front webcams), ROS2 integration.
- Training pipeline: collect RGB video + language instructions + end-effector trajectories; pretrain with the mask-and-reconstruct objective and Fusion Tokens; export inference graph without 4D branch.
- Deployment: TensorRT or comparable runtime on Jetson Orin-class devices; asynchronous control loop for real-time actuation.
- Assumptions/dependencies: Access to a pretrained 4D visual geometry transformer (e.g., StreamVGGT) for training; adequate task demonstrations; stable camera mounting and calibration; safety interlocks for physical deployment.
- Retail: Automated shelf restocking and facing with on-device perception
- What: SwiftVLA-driven mobile manipulators for placing products and aligning fronts (“facing”) using only RGB cameras and instruction prompts from staff or schedulers.
- Why now: The method improves spatiotemporal reasoning in small VLMs without adding depth or LiDAR, reducing BoM and energy cost while keeping latency low.
- Tools/workflow: RGB-only perception stack, instruction templates for tasks (“Place cereal boxes to the rightmost slot”), fine-tuning on store-specific layouts.
- Assumptions/dependencies: Controlled lighting and predictable shelf geometry; sufficient task demonstrations for new stores; retailer safety/compliance approvals.
- Warehousing/Micro-fulfillment: Tote-to-bin and bin-to-sorter transfers
- What: Use SwiftVLA to execute repeated transfers with robust spatial reasoning (reducing mis-grasps/collisions).
- Why now: The approach showed improved grasp precision versus smaller baselines, which directly translates into fewer faults in repetitive workflows.
- Tools/workflow: Multi-view totes cameras; scripted instruction prompts (“move item A to bin 12”).
- Assumptions/dependencies: Consistent camera/tote placement; training data for catalog items; robot-safe workspace.
- Hospitality/Facilities: Cleaning and decluttering tasks with mobile manipulators
- What: Generalize “Clean the desk” and “Stack bowls” style tasks to cafeterias, labs, and shared spaces.
- Why now: Demonstrated higher success rates and shorter paths in real-world settings compared to small baselines.
- Tools/workflow: Predefined instruction sets; curated demo trajectories; on-device inference for privacy.
- Assumptions/dependencies: Clear graspable objects; minimal clutter variability or additional fine-tuning; operator oversight for edge cases.
- Healthcare Logistics (non-clinical): Supply and linen handling in hospitals
- What: Edge-deployed robots move, sort, and place non-sterile supplies with better spatial awareness using only RGB cameras.
- Why now: On-device processing cuts network dependency and preserves privacy; compact models fit power/thermal budgets for hospital robotics.
- Tools/workflow: Instruction templates (“place gauze in drawer 2”), hospital-specific training.
- Assumptions/dependencies: Strict safety and infection-control protocols; tasks limited to non-patient-facing logistics.
- Education/Academia: Low-cost embodied AI labs and courses
- What: Teach VLA concepts and spatiotemporal fusion on affordable robotic arms using small GPUs or Jetson boards.
- Why now: 450M-parameter footprint and ~1.4GB memory usage lowers cost barriers; the paper’s training regime demonstrates how to distill 4D cues into compact policies.
- Tools/workflow: Course modules on Fusion Tokens, mask-and-reconstruct, temporal caches; assignments using multi-view webcams and open datasets; reproducible baselines like SmolVLM.
- Assumptions/dependencies: Availability of pretrained 4D feature extractor; access to small arms and cameras; adherence to lab safety.
- Software/ML Tooling: Multimodal distillation patterns for compact policies
- What: Reuse the mask-and-reconstruct objective and Fusion Tokens to improve cross-modal alignment in other small VLM applications (e.g., video-to-action in simulators, game agents).
- Why now: These components are architecture-agnostic and provide a recipe for small-model spatiotemporal grounding.
- Tools/workflow: Add learnable fusion queries; supervise them with future-trajectory or analogous task-relevant targets; apply random modality masking with reconstruction losses.
- Assumptions/dependencies: Access to task-specific future targets (e.g., trajectories) and synchronized multimodal data.
- Privacy/Sustainability (Policy stakeholders): Edge-first robotics deployments
- What: Adopt procurement guidelines that prioritize on-device inference for embodied systems to improve privacy and reduce network and energy costs.
- Why now: The paper quantifies substantial speed and memory gains for edge deployment without major performance trade-offs.
- Tools/workflow: Policy checklists (camera-only setups, inference on local hardware, retention limits); energy/performance reporting templates.
- Assumptions/dependencies: Availability of edge accelerators; compliance with local privacy laws; operator training.
Long-Term Applications
These use cases are promising but require additional research, scaling of datasets, broader validation, or hardware readiness.
- General-Purpose Home Assistance: Robust long-horizon household robots
- What: Extend SwiftVLA to diverse, unstructured homes for tasks spanning tidying, dish handling, laundry sorting, and flexible tool use.
- Why later: Requires broader training data, improved long-horizon planning, and safety assurance in variable environments.
- Dependencies/assumptions: Larger, curated home-robot datasets; improved failure recovery; certification pathways for domestic robotics.
- Mobile Manipulation at Scale: Navigation + manipulation with unified compact policies
- What: Integrate SwiftVLA with SLAM and navigation to enable autonomous fetching, loading, and collaborative tasks in warehouses, retail, and hospitals.
- Why later: Needs tight coupling with mapping, obstacle avoidance, and multi-sensor fusion under the same compact compute budget.
- Dependencies/assumptions: Reliable visual odometry or VIO; curriculum learning for nav-manip interplay; standardized evaluation in busy environments.
- Drone/UAV Instruction-Following: On-device, language-guided visual tasks
- What: Use mask-and-reconstruct training and Fusion Tokens to enhance small onboard models for tracking, inspection, and simple object interactions (where permissible).
- Why later: Flight constraints, safety requirements, and limited manipulative capabilities necessitate additional research and regulation alignment.
- Dependencies/assumptions: Lightweight vision stacks; stabilized camera rigs; restricted airspace compliance.
- Autonomous Driving/Driver Assistance: 4D-aware compact perception-to-action modules
- What: Apply the incremental 4D feature extraction + temporal cache to improve small-model video understanding for lane changes, merges, or driver assistance prompts.
- Why later: Requires extensive validation, sensor fusion with radar/LiDAR, and adherence to stringent safety standards.
- Dependencies/assumptions: High-quality, time-synchronized datasets; regulatory approvals; robust out-of-distribution handling.
- Surgical and Clinical Robotics: Semi-autonomous assistance with visual-language control
- What: Use 4D-aware compact VLAs for tool handling and setup assistance (not direct surgery) under clinician instruction.
- Why later: High-stakes environments demand rigorous validation, traceability, and human-in-the-loop guarantees.
- Dependencies/assumptions: Sterile-compatible hardware; formal verification and trial protocols; compliance with medical device regulations.
- Construction/Field Robotics: RGB-only spatiotemporal control for material handling and inspection
- What: Deploy compact policies for repetitive manipulation/placement and progress monitoring on sites with limited connectivity and power.
- Why later: Outdoor variability and safety risks demand more robust training and fail-safes; integration with site digital twins.
- Dependencies/assumptions: Ruggedized cameras; adaptation to lighting/weather; specialized datasets.
- Cross-Domain Multimodal Alignment: General recipe for small-model video agents
- What: Export the Fusion Tokens + future-prediction supervision and mask-and-reconstruct strategy to domains like sports analytics, industrial monitoring, or AR assistants that require action-aware video understanding.
- Why later: Requires defining appropriate future targets (beyond robot trajectories) and collecting aligned training corpora.
- Dependencies/assumptions: Domain-specific futures (e.g., predicted player paths, machine state sequences); careful evaluation metrics.
- Standardization and Policy Frameworks: Benchmarks and metrics for lightweight spatiotemporal VLAs
- What: Establish public benchmarks, efficiency KPIs (latency, memory, energy/task), and privacy-by-design requirements for instruction-following robots.
- Why later: Needs community coordination, longitudinal field data, and agreement across vendors/operators.
- Dependencies/assumptions: Shared datasets and evaluation harnesses; cross-organization working groups; regulatory liaison.
In summary, SwiftVLA enables immediate deployment of instruction-following manipulation on edge devices with only RGB cameras, introducing training-time 4D supervision (via a pretrained geometry transformer), Fusion Tokens with future-trajectory supervision, and a mask-and-reconstruct objective to distill spatiotemporal understanding into compact models. Longer-term, the same principles can underpin broader mobile manipulation, drone and driving assistance, and cross-domain small-model video agents, provided further research, datasets, and safety/regulatory frameworks.
Glossary
Below is an alphabetical list of advanced terms from the paper, each with a brief definition and a verbatim usage example.
- 3D positional encoding: A technique that injects 3D spatial coordinates into model inputs to improve geometric awareness. "introduces 3D positional encoding"
- 4D features: Learned representations that capture 3D geometry over time (space plus time). "extracts 4D features from 2D images."
- 4D visual geometry transformer: A transformer that estimates temporally enhanced 3D geometry from image sequences. "a pretrained 4D visual geometry transformer with a temporal cache"
- action expert: The policy module that predicts actions conditioned on VLM features. "the action expert is required to reconstruct the masked features"
- action latent: A latent representation produced by the policy from which actions (or diffusion noise) are decoded. "it produces an action latent"
- autoregressive generation: Sequential prediction where each output token depends on previous ones, often increasing latency. "avoid the high latency of autoregressive generation"
- conditional diffusion model: A generative model that denoises conditioned on inputs (e.g., VLM features) to produce actions. "The action expert is formulated as a conditional diffusion model."
- cross-attention: Attention mechanism that lets one set of tokens attend to another set (e.g., temporal cache or multimodal inputs). "through cross-attention, enabling the integration of temporal context."
- cross-modal integration: The process of combining information from different modalities (e.g., vision, language, proprioception). "to strengthen cross-modal integration."
- diffusion-based decoder: A decoder that generates outputs by denoising a noise vector through a diffusion process. "uses a diffusion-based decoder to directly generate continuous actions."
- diffusion policy decoder: A diffusion-based action generator that directly produces multi-step continuous action sequences. "introduces a diffusion policy decoder that directly generates continuous multi-step action sequences"
- end-effector trajectory: The time sequence of positions/orientations of a robot’s gripper/tool used for supervision or control. "decoded to predict the end-effector trajectory"
- First-In-First-Out (FIFO): A queueing strategy where the oldest entries are removed first to maintain a fixed memory size. "we adopt a First-In-First-Out (FIFO) strategy"
- Flow Matching: A method for training generative models by matching probability flows, used here for action prediction. "incorporates Flow Matching"
- Fusion Tokens: Learnable tokens introduced to help align and fuse 2D, 4D, language, and state features for action generation. "Fusion Tokens, a set of learnable tokens"
- future prediction objective: A training signal that supervises the model to predict future robot states (e.g., end-effector trajectory). "trained with a future prediction objective"
- keyframe sampling strategy: Selecting representative frames based on temporal similarity to reduce computation while preserving dynamics. "leveraging a history-similarity-based keyframe sampling strategy"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that inserts trainable low-rank adapters. "employs LoRA for parameter-efficient fine-tuning."
- pixel shuffle: An operation that rearranges pixels to reduce token count or change spatial resolution efficiently. "uses pixel shuffle to limit each frame's tokens"
- point clouds: Sets of 3D points representing scene geometry, used as auxiliary signals for spatial reasoning. "treats point clouds as auxiliary conditioning signals"
- proprioceptive state: The robot’s internal sensor readings (e.g., joint positions/velocities) used as part of the model input. "and the proprioceptive state ."
- self-attention: An attention mechanism where tokens attend to other tokens within the same sequence. "alternates between self-attention and cross-attention modules"
- SigLIP: A vision-text pretraining approach (Sigmoid loss for Language-Image Pretraining) used to encode visual features. "utilizes SigLIP to encode visual features"
- spatiotemporal decoder: A decoder that jointly models spatial and temporal dependencies to produce 4D representations. "feed the encoded features into a spatiotemporal decoder"
- spatiotemporal dynamics: The evolution of spatial configurations over time, important for reasoning about actions. "enhances spatiotemporal dynamics for small VLA models"
- spatio-temporal reasoning: The capability to reason about spatial relationships as they evolve over time. "to improve spatio-temporal reasoning."
- temporal attention: An attention mechanism focusing on dependencies across time steps. "for temporal attention."
- temporal cache: A memory structure that stores past features for reuse, providing temporal context to current predictions. "with a temporal cache"
- Vision–Language–Action (VLA) model: A model that maps visual observations and language instructions to robot actions. "VLA models"
- Vision–LLM (VLM): A model that jointly processes visual and textual inputs to produce aligned representations. "lightweight VLM"
Collections
Sign up for free to add this paper to one or more collections.

