- The paper introduces Evo-1, a compact VLA model that preserves semantic alignment through a novel two-stage training paradigm.
- The paper employs a cross-modulated diffusion transformer for efficient action generation, achieving state-of-the-art success rates across simulation and real-world benchmarks.
- The paper demonstrates that reduced computational overhead enables real-time deployment on consumer-grade hardware while maintaining robust performance across diverse manipulation tasks.
Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
Introduction
Evo-1 addresses the critical challenge of deploying Vision-Language-Action (VLA) models for robotic manipulation in real-world and resource-constrained settings. The model is designed to maintain strong multimodal semantic alignment while drastically reducing computational overhead and eliminating the need for large-scale robot data pretraining. Evo-1 achieves this through a compact architecture, a cross-modulated diffusion transformer for action generation, and a two-stage training paradigm that preserves the semantic integrity of the vision-language backbone. The model demonstrates state-of-the-art performance across multiple simulation and real-world benchmarks, with significant improvements in efficiency and generalization.
Architecture and Model Design
Evo-1 is structured around three principal modules: a vision-language backbone, an integration module, and a cross-modulated diffusion transformer for action generation.
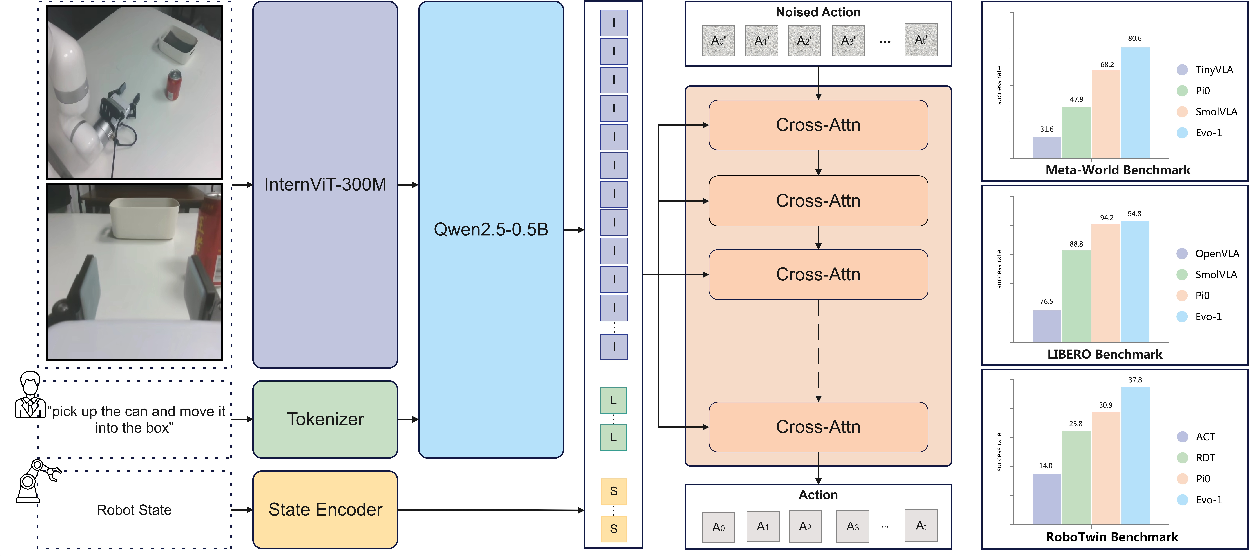
Figure 1: Architecture of Evo-1. The input RGB observations and language instructions are first encoded by a compact vision-language backbone. Their fused representations are aligned with the robot state through an optimized integration module and then processed by a cross-modulated diffusion transformer to generate actions. The right side shows results across three simulation benchmarks.
Vision-Language Backbone
The backbone leverages InternVL3-1B, a 1B-parameter model pretrained under a native multimodal paradigm, ensuring tight cross-modal alignment. The visual encoder, InternViT-300M, processes RGB observations into compact patch embeddings, while the language branch (Qwen2.5-0.5B) encodes instructions. Vision-language fusion is achieved by inserting image patch embeddings into the token sequence, enabling joint reasoning in a unified embedding space. Only the first 14 layers of the language branch are retained to maximize cross-modal alignment for visuomotor control.
Integration Module
The integration module concatenates the mid-layer fused multimodal representation with the robot's proprioceptive state, providing key-value inputs to the action expert. This design preserves the full information content of both modalities and avoids lossy projections, which is empirically shown to be critical for robust action generation.
Action generation is handled by a conditional denoising Diffusion Transformer (DiT), which predicts continuous control actions via a flow-matching paradigm. The DiT uses stacked cross-attention layers, with the noise-injected action as the query and the concatenated multimodal-state embedding as key-value. This structure enables efficient temporal reasoning and consistent motion generation, while maintaining a compact parameter count.
Two-Stage Training Paradigm
A key innovation in Evo-1 is the two-stage training procedure, designed to preserve the semantic space of the vision-language backbone:
- Stage 1: The vision-language backbone is frozen, and only the integration module and action expert are trained. This aligns the action expert with the pretrained multimodal embedding space without corrupting the backbone's representations.
- Stage 2: The entire model is fine-tuned jointly, allowing for deeper integration and adaptation to downstream tasks.
This approach is shown to maintain spatially consistent and semantically aligned attention maps, in contrast to single-stage or end-to-end training, which leads to semantic drift and degraded attention coherence.






Figure 2: Comparison of vision-language attention maps after training. (a) Evo-1 (InternVL3-1B) yields spatially consistent and semantically aligned activations. (b) OpenVLA (Prismatic-7B) shows degraded coherence in attention maps.
Experimental Results
Simulation Benchmarks
Evo-1 is evaluated on Meta-World, LIBERO, and RoboTwin, covering both single-arm and dual-arm manipulation tasks. The model achieves:
- Meta-World: 80.6% average success rate, surpassing SmolVLA (68.2%) and π0 (47.9%) despite having only 0.77B parameters.
- LIBERO: 94.8% average success rate, outperforming π0 (94.2%) and SmolVLA (88.8%), with robust performance on long-horizon tasks.
- RoboTwin: 37.8% average success rate, exceeding the previous best of 30.9% by π0, and demonstrating strong bimanual coordination.
Real-World Experiments
Evo-1 is deployed on a 6-DoF xArm6 for four diverse manipulation tasks, including pick-and-place, pouring, hand delivery, and stacking. The model achieves a 78% average success rate, outperforming SmolVLA (50%), OpenVLA-OFT (55%), and π0 (73%).

Figure 3: Task progress of Real-World Experiments. Step-by-step sequences for the real-world tasks. Each row shows the detailed progression of a task from start to completion.
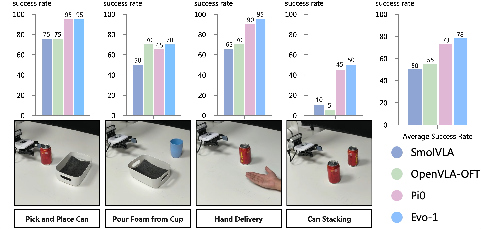
Figure 4: Results of Real-World experiments. Success rates of four real-world evaluation tasks (left four subplots) and the overall average success rate across tasks (rightmost subplot).
Inference Efficiency
Evo-1 demonstrates superior efficiency, requiring only 2.3 GB GPU memory and achieving 16.4 Hz inference frequency on an RTX 4090d, compared to 7–11 Hz for larger models. This enables real-time deployment on consumer-grade hardware without sacrificing performance.
Generalization and Robustness
Generalization is evaluated under four disturbance conditions: unseen distractor objects, background color changes, target position shifts, and target height variations.

Figure 5: Disturbance settings of generalization experiments. We evaluate model generalization under four variations: (1) unseen distractor object, (2) background color variation, (3) target position variation, and (4) target height variation.
Evo-1 consistently outperforms SmolVLA across all settings, maintaining high success rates even under significant distribution shifts.
Ablation Studies
Integration Module
Four integration strategies are compared, with Module A (mid-layer cross-attention with concatenation) yielding the best performance due to consistent propagation of multimodal information.
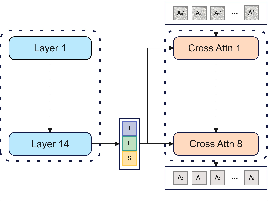
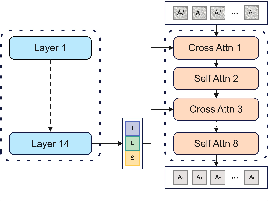
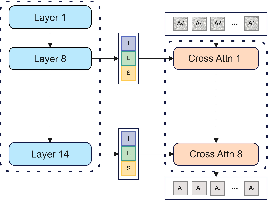
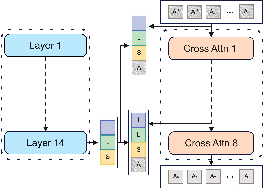
Figure 6: Module A.
Training Paradigm
The two-stage training paradigm is shown to preserve semantic attention patterns and improve generalization, as evidenced by attention map visualizations and benchmark performance.



Figure 7: Comparison of vision-language attention maps after training. (a) The single-stage paradigm shows disrupted attention with reduced semantic coherence. (b) Our two-stage paradigm preserves clear and semantically consistent focus regions.
Implications and Future Directions
Evo-1 demonstrates that lightweight VLA models can achieve state-of-the-art performance without large-scale robot data pretraining, provided that architectural and training strategies are carefully designed to preserve semantic alignment. The model's efficiency and robustness make it suitable for real-time deployment in practical robotic systems, lowering the barrier for research and industrial adoption.
Theoretically, the results suggest that preserving the semantic space of pretrained VLMs is critical for generalization in embodied tasks. Practically, the release of code, data, and model weights will facilitate further research into efficient, scalable, and generalizable VLA models.
Future work may explore further compression, hardware-specific optimizations, and extension to more complex multi-agent or multi-modal scenarios, as well as integration with online adaptation and lifelong learning frameworks.
Conclusion
Evo-1 establishes a new standard for lightweight, efficient, and semantically aligned VLA models. Through architectural innovations and a two-stage training paradigm, it achieves strong generalization and real-world applicability without reliance on large-scale robot data pretraining. The model's release is poised to accelerate progress in efficient multimodal robotic learning and deployment.

