- The paper presents a structured affordance forecasting framework that bridges semantic VLM embeddings with low-level robotic controls using a Mixture-of-Transformer architecture.
- It demonstrates superior performance with a 95.8% success rate on LIBERO and robust real-world task execution even in visually complex scenarios.
- Architectural insights reveal that progressive curriculum training and subgoal token representations enhance data efficiency and out-of-distribution generalization.
AffordanceVLA: Affordance-Centric Vision-Language-Action Architectures for Robust Robotic Manipulation
AffordanceVLA proposes a structured approach to bridging the representational gap between high-level, pretrained vision-LLMs (VLMs) and the embodied action spaces required for physical robot manipulation. Direct mappings from semantic VLM embeddings to low-level control policies typically encounter failures due to semantic-physical space misalignment and the lack of task-centric grounding, especially under visual distractors and complex spatial reasoning demands. AffordanceVLA addresses these challenges by introducing structured affordance forecasting as an intermediate supervisory representation, coupling perception, language, and action through three components: Which2Act (object-centric grounding), Where2Act (2D interaction localization), and How2Act (3D spatial/geometric reasoning).
Model Architecture: Structured Affordance Forecasting and MoT Paradigm
The framework instantiates a Mixture-of-Transformer (MoT) architecture, decoupling the VLA pipeline into three specialized experts: Understanding, Affordance Generation, and Action. Information propagates through a unidirectional Understanding–Affordance–Action (UAA) attention mechanism to prohibit downstream leakage while ensuring progressive semantic-physical grounding. Each expert is optimized for its representational role: Understanding aligns and fuses visual and linguistic cues, Affordance Generation predicts structured subgoal queries, and Action synthesizes the low-level control trajectory conditioned on the semantic and affordance priors.
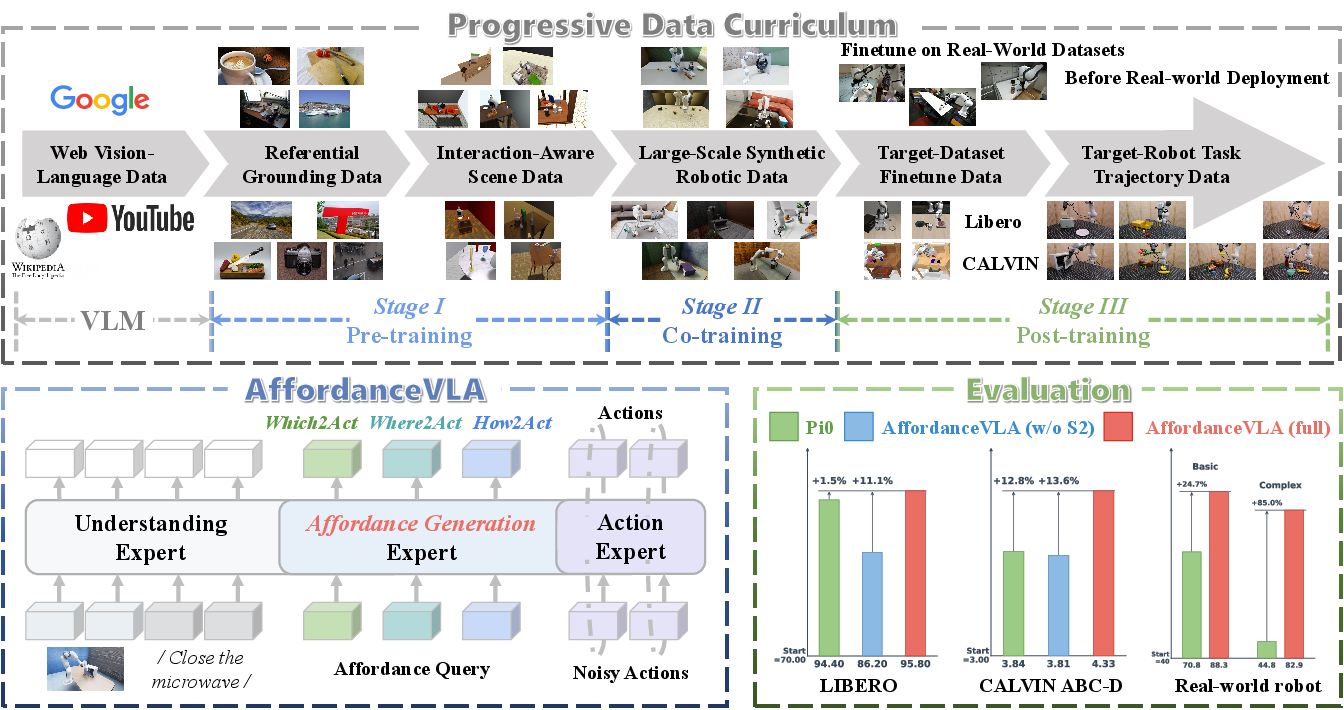
Figure 1: AffordanceVLA employs three specialized experts and leverages structured affordance forecasting (Which2Act, Where2Act, How2Act) for robust perception-action mapping, with progressive curriculum training for simulation and real-world tasks.
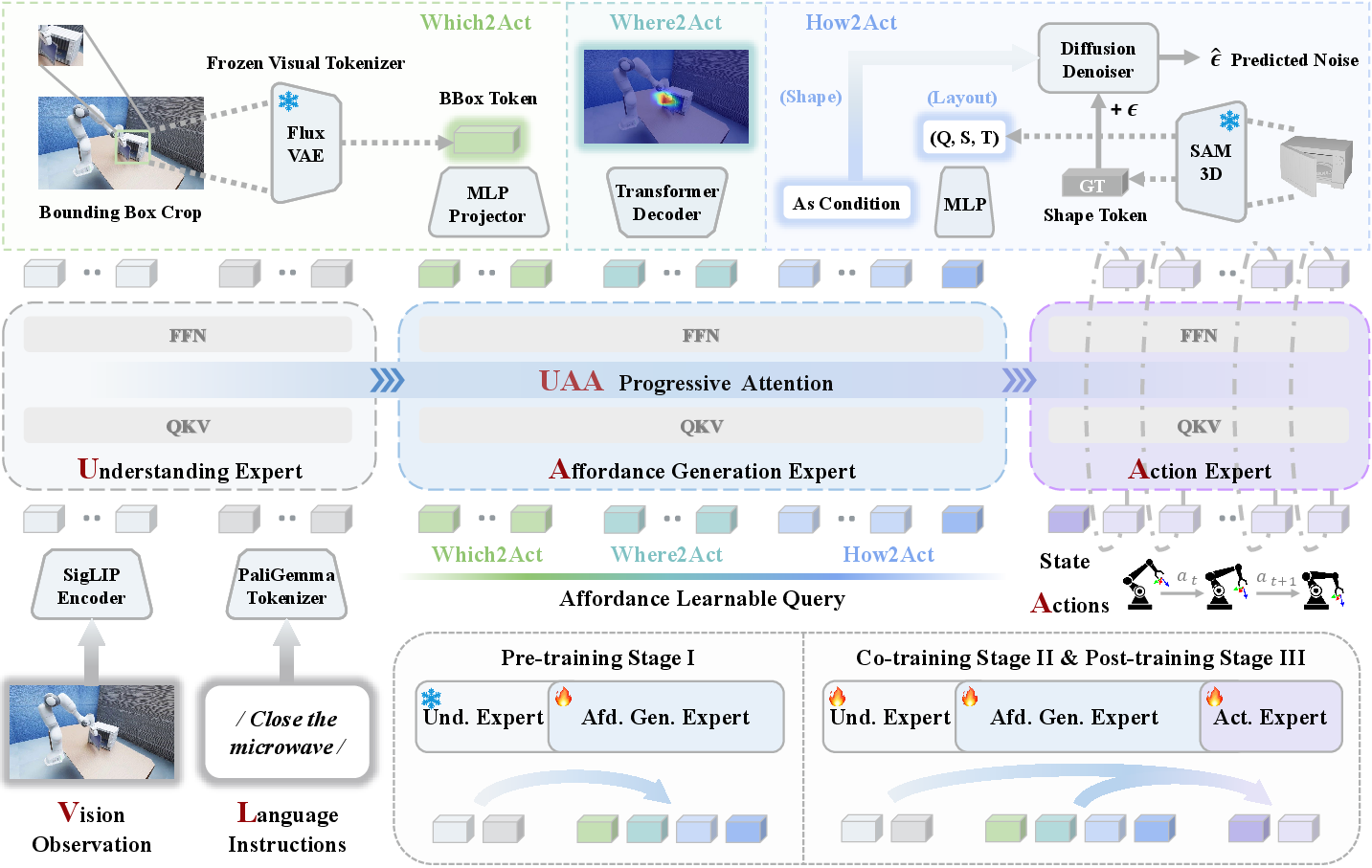
Figure 2: Pipeline visualization: Understanding extracts fused semantics; Affordance Generation decodes them into Which/Where/How affordance tokens; Action Expert synthesizes control under affordance and semantics.
Affordance Subgoal Forecasting
- Which2Act produces a visual latent for object-centric grounding, suppressing background and irrelevant entities by cropping the observation according to predicted bounding boxes.
- Where2Act generates 2D affordance maps by decoding spatial points of interaction from language-grounded visual input, using pixel-wise binary cross-entropy with segmentation-derived masks.
- How2Act bifurcates into 3D shape generation (voxel latent prediction via conditional diffusion denoising) and 10-DoF spatial layout regression (Smooth-L1 for rotation, translation, scale).
Joint optimization of these affordance tokens ensures task decomposition is not brittle nor idiosyncratic, but robustly fuses semantic understanding with actionable spatial priors. Importantly, cross-token intra-expert attention facilitates synergistic refinement, as opposed to naïve multi-tasking with supervision-density controls.
Training Methodology: Progressive Curriculum and Data-Centric Pipeline
AffordanceVLA adopts a three-stage curriculum:
- Stage I: General affordance grounding pre-training on referential/interaction-annotated VQA datasets with only the Affordance Generation Expert updated; other components remain frozen to preserve high-level semantics.
- Stage II: Full end-to-end (including the encoder) training on large-scale, high-fidelity synthetic robotic sequences (e.g., InternData-A1), with a robust automated affordance annotation pipeline to compensate for the lack of native dense affordance labels.
- Stage III: Benchmark-specific adaptation to LIBERO, CALVIN, and real-world datasets, annealing the affordance objective weighting to prioritize final control policy quality and allow adaptation to target distributions.
A notable contribution is the demonstration that architectural choices—not simply scaling dataset size—determine model performance ceilings. Ablations indicate that data scaling alone, or naïve affordance “add-ons” (static/frozen), are not substitutes for fully co-optimized, structured affordance-bridged architectures.
Experimental Analysis
Simulated and Real-World Benchmarks
On the LIBERO benchmark, AffordanceVLA (full) achieves a 95.8% average success rate, outperforming leading approaches including Pi0 and F1-VLA. The ablated variant (without Stage II co-training) drops to 86.2%, illustrating the critical role of progressive curriculum and affordance-centric alignment.
On the zero-shot CALVIN ABC→D benchmark, AffordanceVLA attains a 75.9% success rate for all 5-task chains with an average chain length of 4.33, matching or exceeding much larger generalist robot policies, and establishing the superiority of structured affordance intermediates for OOD generalization.
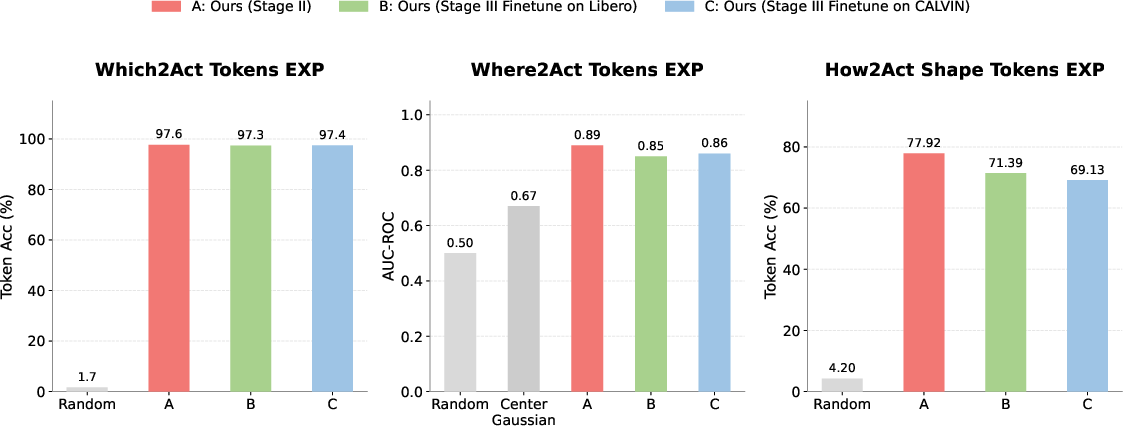
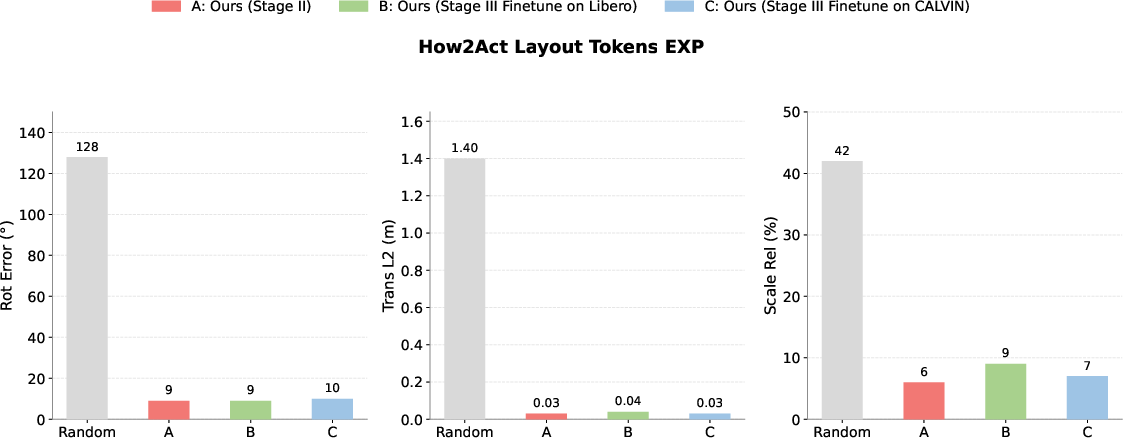
Figure 3: Quantitative validation of subgoal token representations; AffordanceVLA substantially outperforms random baselines for Which2Act, Where2Act, and How2Act.
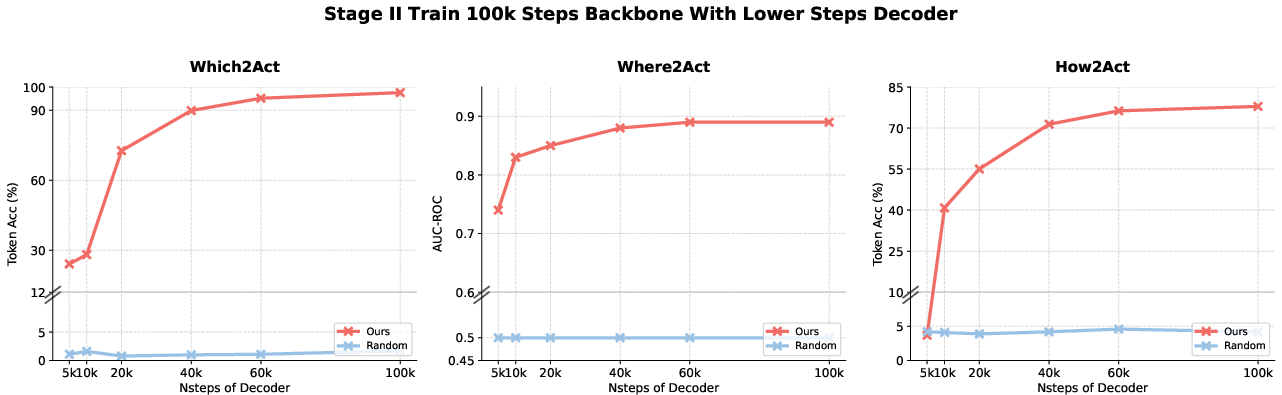
Figure 4: Backbone-disentangling experiments demonstrate robust affordance-sensitive features are learned in the backbone and not merely an overfit decoder artifact.
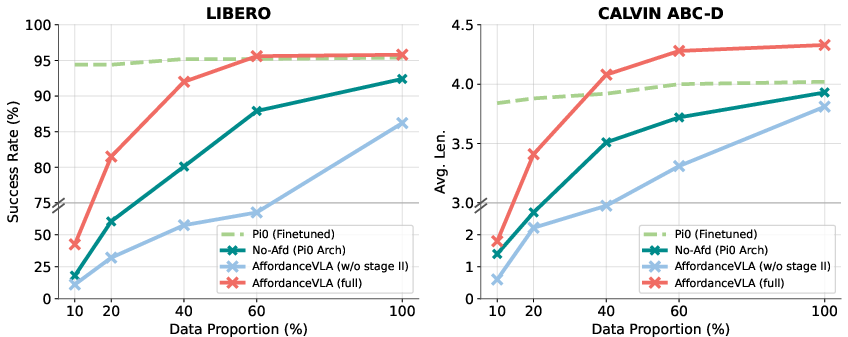
Figure 5: Data efficiency curves: AffordanceVLA surpasses Pi0's performance using just 40% of the downstream fine-tuning data, illustrating the synergy of architecture and structured supervision.
Real-World Generalization
On real-world robotics tasks, including visually confounded scenarios (e.g., visually indistinguishable “pick” vs. “close” tasks in drawers and toasters), AffordanceVLA achieves an average of 88.3% success on basic tasks and 82.9% in complex, multi-step sequences, dominating action-only VLA baselines. The model demonstrates reliable instruction-following, robust recovery from physical disturbances, and reduced redundant action attempts.

Figure 6: Qualitative visualization of basic and complex real-world tasks, including affordance heatmaps for precise manipulation and sequential execution.

Figure 7: Vision-language-aligned affordance maps dynamically adjust to instruction semantics even under constant visual stimuli.

Figure 8: Visualization of the “Clean all the rubbish” task; the model continuously generates subgoal sequences, enabling robust multi-stage interaction and disturbance recovery.
Implications and Theoretical Perspective
AffordanceVLA advances the understanding that the spatial and operational misalignment between VLMs and robotic action spaces cannot be bridged by increased data or generic supervision alone. Properly structured, jointly refined affordance representations (object, region, geometry) serve as semantic anchors, retaining high-level instruction-following capabilities while encoding actionable physical priors. This paradigm provides a foundation for future extensions into longer-horizon reasoning (memory augmentation), bimanual, and deformable object interaction, and offers a blueprint for scaling robot generalists without exacerbated sample complexity.
Further, empirical findings reinforce hypotheses that naïvely pushing low-level action losses into VLM backbones erodes instruction-following capacity, and intermediate affordance supervision insulates and preserves semantic alignment.
Conclusion
AffordanceVLA demonstrates that structured affordance forecasting, mediated by a Mixture-of-Transformer architecture and progressive curriculum, yields robust, scalable, and highly generalizable perception–action mappings for robotics. By realigning representation, architecture, and data, the method decisively outcompetes both action-only and naïve multi-tasking approaches. Its architectural insights extend naturally to future work targeting explicit temporal modeling, compositional planning, and broader task-generalization in open-world environments.
Reference: "AffordanceVLA: A Vision-Language-Action Model Empowering Action Generation through Affordance-Aware Understanding" (2606.06155)

