Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model
Abstract: Vision-language-action (VLA) models have recently shown strong potential in enabling robots to follow language instructions and execute precise actions. However, most VLAs are built upon vision-LLMs pretrained solely on 2D data, which lack accurate spatial awareness and hinder their ability to operate in the 3D physical world. Existing solutions attempt to incorporate explicit 3D sensor inputs such as depth maps or point clouds, but these approaches face challenges due to sensor noise, hardware heterogeneity, and incomplete depth coverage in existing datasets. Alternative methods that estimate 3D cues from 2D images also suffer from the limited performance of depth estimators.We propose Spatial Forcing (SF), a simple yet effective alignment strategy that implicitly forces VLA models to develop spatial comprehension capabilities without relying on explicit 3D inputs or depth estimators. SF aligns intermediate visual embeddings of VLAs with geometric representations produced by pretrained 3D foundation models. By enforcing alignment at intermediate layers, SF guides VLAs to encode richer spatial representations that enhance action precision.Extensive experiments in simulation and real-world environments demonstrate that SF achieves state-of-the-art results, surpassing both 2D- and 3D-based VLAs. SF further accelerates training by up to 3.8x and improves data efficiency across diverse robotic tasks. Project page is at https://spatial-forcing.github.io/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Spatial Forcing: Implicit Spatial Representation Alignment for Vision‑language‑action Model”
1) What is this paper about?
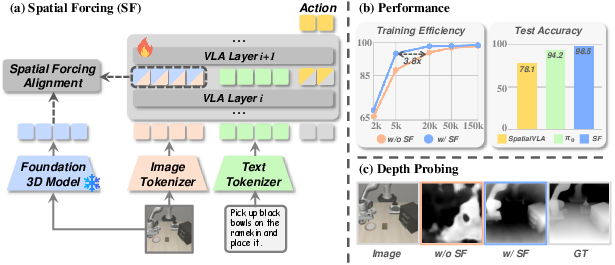
This paper is about teaching robot brains (called vision‑language‑action, or VLA, models) to understand where things are in 3D space using only regular camera images. The key idea, called Spatial Forcing (SF), helps these models “feel” depth and layout without needing extra sensors like depth cameras or lasers, and without using a separate depth‑estimation tool.
In short: SF gives robots a better sense of 3D space so they can follow instructions and move more accurately.
2) What questions are the researchers trying to answer?
The paper focuses on three easy‑to‑grasp questions:
- How can we help robot models that were trained on flat 2D images understand the real 3D world?
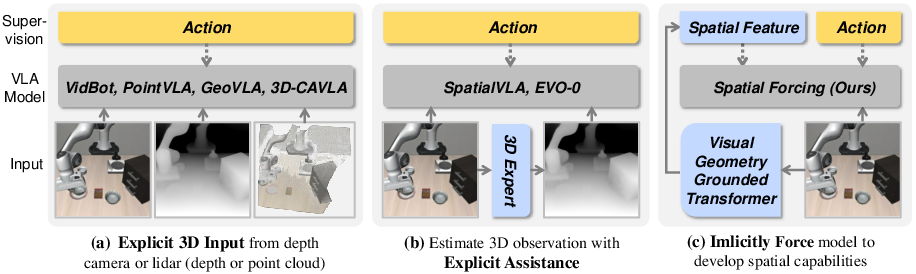
- Can we do this without extra hardware (like depth sensors) or weak add‑on tools (like imperfect depth estimators)?
- Will this make robots more accurate, faster to train, and able to learn from less data?
3) How does their method work? (With simple analogies)
Think of a VLA model like a student learning to do chores by watching videos and reading instructions. Right now, most students only see flat pictures, so they struggle with depth—like judging how far away a cup is or how high to lift it.
Spatial Forcing adds a “3D‑savvy coach” during training:
- The coach is a pretrained 3D model called VGGT. It’s very good at turning normal pictures into rich 3D clues (like where surfaces are and how far things are).
- Inside the VLA model, images get turned into many small internal signals (think: tiny puzzle pieces of what the model “sees,” often called “embeddings”).
- SF gently nudges these internal signals to match the coach’s 3D clues. It’s like aligning the student’s notes with a master teacher’s notes.
Key parts in everyday terms:
- Multi‑view images: The robot sees the scene from different cameras. Like looking around a room from a few angles.
- Alignment: During training, the model is encouraged to make its vision features point in the same “direction” as the 3D coach’s features. You can think of this as making two arrows line up so they agree.
- Where to nudge: They found it works best to apply these nudges in the deeper middle layers of the model (not the very first or very last ones). That’s where the model has learned enough visual detail but hasn’t lost important vision‑specific information.
- No extra cost later: After training, the coach is gone. The robot runs just like a normal VLA—no extra sensors, no slower speed.
A quick check they did:
- “Depth probing” test: They froze the robot’s vision features and asked a simple tool to predict depth from them. Before SF, the features didn’t know depth well. After SF, the features contained much clearer depth information—proof that the robot had learned better 3D sense.
4) What did they find, and why does it matter?
Main results:
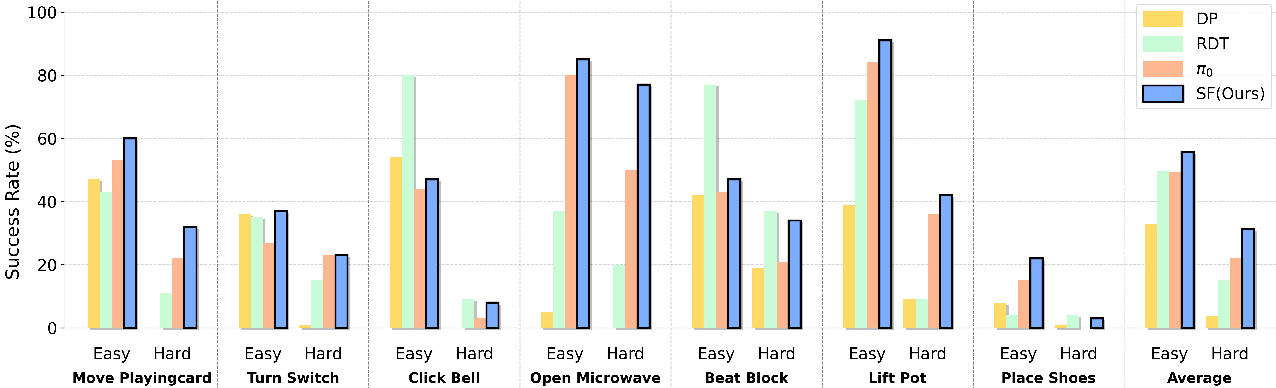
- Higher accuracy: Their method reached state‑of‑the‑art results on robot benchmarks (like LIBERO and RoboTwin), beating strong 2D methods and even rivaling or exceeding some methods that use extra 3D sensors.
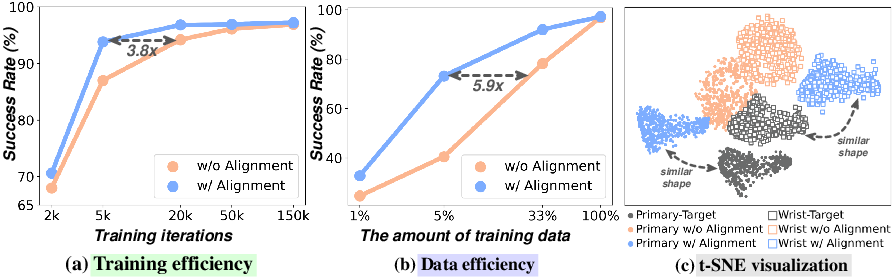
- Faster training: Up to about 3.8× faster to reach the same performance. This is like studying with a good tutor—you learn quicker.
- Better with less data: The model did well even when trained on only a small part of the dataset (for example, getting solid success with just 5% of the data). This matters because gathering robot training data is expensive and slow.
- Real‑world success: On real robots, SF helped with tricky tasks (like stacking transparent cups under different lighting and keeping a pot level with two arms), showing stronger spatial understanding and fewer “shortcut” mistakes.
Why it matters:
- Robots need good 3D understanding to manipulate objects safely and precisely. Doing this without special depth hardware makes robots cheaper and easier to deploy.
- Faster training and less data means quicker progress and lower costs for building useful robot skills.
5) What does this mean for the future?
- Easier, cheaper robots: Because SF doesn’t require extra sensors or slow add‑ons, it can be widely used on many robot systems.
- Stronger 3D skills from 2D data: SF shows a path to give 3D “sense” to models built on 2D training—useful wherever 3D data is missing or noisy.
- Better generalization: Robots may handle new rooms, lighting, and object layouts more reliably because their internal vision now encodes real 3D structure.
- A general recipe: The idea of aligning a model’s internal features with a trusted “teacher” (here, a 3D foundation model) could help other AI systems learn important skills faster and with less data.
In one line: Spatial Forcing is like giving robots a 3D‑wise tutor during training so they grow a strong sense of space—without needing special gadgets—and end up smarter, faster to train, and more data‑efficient.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide concrete follow-up research.
- Dependence on a specific 3D teacher: The approach relies on VGGT as the source of “spatial” targets; sensitivity to teacher quality, biases, and failure modes (e.g., textureless, reflective, low-light scenes) is not quantified or systematically evaluated.
- Multi-view requirement during training: The method assumes multi-view images to drive VGGT’s multi-view consistency; how SF performs with single-camera setups, sparse baselines, or unsynchronized/asynchronous views is not explored.
- Teacher-domain mismatch: The impact of domain shift between VGGT’s pretraining data and robotic manipulation domains (industrial environments, novel sensors, significant occlusions) is not analyzed.
- Computational overhead of supervision: The paper reports faster convergence in terms of iterations but does not report the wall-clock and GPU cost of running VGGT to produce supervision, nor the net training-time trade-off.
- Layer selection strategy: Alignment layer choice is empirically tuned (best at the 24th layer); there is no principled or adaptive method for selecting which layers to align, how many to align, or how to schedule alignment over training.
- Weighting of losses: The effect of the alignment weight α (and its scheduling) on stability, performance trade-offs, and over-regularization is not studied.
- Positional embedding design: The role, type, and configuration of positional embeddings added to the teacher features (beyond “helps long-horizon”) are not ablated (e.g., absolute vs. relative PE, token-temporal PE, per-view PE).
- Resolution and token mapping: The paper does not specify how patch tokens from the VLM backbone are matched to pixel-level features from VGGT (e.g., handling stride/misalignment, interpolation strategy), nor the effect of varying image/token resolutions.
- Target feature choice: Only one teacher representation (VGGT latent features) is used; comparisons to simpler targets (e.g., monocular depth, surface normals, point tracks), combinations of targets, or multi-task alignment are missing.
- Temporal/dynamic cues: Although VGGT can provide tracks, the method aligns single-frame embeddings; leveraging temporal 3D signals (point tracks, motion cues) for dynamic scenes is not explored.
- Overfitting to geometry vs. semantics: Possible trade-offs between improved 3D grounding and preserved semantic/language grounding are not quantitatively assessed (beyond a t-SNE visualization).
- Generalization to other VLA forms: Validation is limited to OpenVLA-OFT and π0; applicability to diffusion-based policies, non-autoregressive architectures, and closed-loop RL settings remains untested.
- Robustness analyses: Sensitivity to camera calibration errors, viewpoint changes, extrinsics/intrinsics drift, image noise, occlusion, and severe domain randomization is not systematically measured.
- Data sparsity and view ablations: Effect of reducing the number of views, changing view diversity, or removing wrist/auxiliary cameras is not studied.
- Failure case analysis: The paper lacks qualitative/quantitative breakdowns of typical failure modes (when SF hurts or fails vs. baseline), especially in long-horizon, cluttered, or deformable-object tasks.
- Statistical rigor: Reported improvements lack confidence intervals/variance estimates; significance testing across random seeds and task splits is missing.
- Real-world scope: Real-robot tests are on a single platform with a limited set of tasks and small demo counts; generalization across embodiments, grippers, and sensor suites is not evaluated.
- Cross-dataset generalization: Transfer to other manipulation benchmarks and real-world datasets (beyond LIBERO/RoboTwin and the presented lab tasks) is not examined.
- Safety and failure recovery: Impact of SF on safe behaviors (e.g., avoiding collisions), recovery from geometric misperception, and robustness under distribution shift is not addressed.
- Evaluation breadth: Metrics focus on success rate; auxiliary metrics (trajectory smoothness, force/contact quality, time-to-success, sample efficiency normalized by compute) are not reported.
- Alignment stability: Risks of representation collapse, mode-locking to teacher biases, and forgetting of pre-trained VLM capabilities are not probed with quantitative diagnostics.
- Teacher alternatives and ensembles: Whether aligning to multiple 3D teachers (e.g., depth estimators, SfM/NeRF features, point-cloud encoders) improves robustness is left open.
- Semi/self-supervised variants: Possibility of using self-distilled or contrastive spatial objectives (e.g., SAM/MAE/monodepth) instead of fixed teacher alignment is not explored.
- Curriculum/scheduling: No investigation into curricula for when/how strongly to align (e.g., early vs. late training, task difficulty progression, task-conditioned α).
- Partial observability: How SF behaves under strong POMDP settings (occlusions, moving cameras/objects, latency) and whether alignment should incorporate memory/temporal aggregation is not studied.
- Language grounding stress tests: The effect of SF on compositional language understanding, ambiguous references, and out-of-distribution language instructions is not evaluated.
- Reproducibility details: Exact VGGT version/checkpoint, feature dimensionality, normalization choices, and data preprocessing required to replicate alignment are not fully specified.
- Privacy/licensing/data leakage: Potential overlap between VGGT pretraining data and evaluation environments and the implications for fair benchmarking are not discussed.
- Extensions to planning/control: Whether aligned representations benefit higher-level planning, 6-DoF grasping, pose estimation, or mapping outside the action tokenization framework remains open.
- Integration with RL: The effect of SF when combined with RL fine-tuning (on-policy or offline RL) is not investigated.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging the paper’s Spatial Forcing (SF) method to align VLA visual embeddings with spatial representations from pretrained 3D foundation models, without adding inference-time overhead.
- Robotics manufacturing and assembly (Industry)
- Use SF to fine-tune existing 2D VLA policies for precise pick-and-place, insertion, stacking, and fastening using only RGB cameras. Reduce dependence on depth sensors while maintaining spatial accuracy.
- Tools/workflows: “SF training plugin” for OpenVLA/Octo/pi0; LoRA+SF recipes; a depth-probing QA step to validate spatial understanding before deployment.
- Assumptions/dependencies: Multi-view RGB images during training; access to a pretrained 3D foundation model (VGGT or equivalent) and compute to extract supervision; stable camera placement and basic calibration.
- Warehouse bin-picking and sorting (Industry, Logistics)
- Deploy SF-enhanced policies for bin-picking in cluttered scenes and variable lighting with monocular or stereo RGB cameras; improve success rates, reduce demo count, and cut cost/time to retrain for new SKUs.
- Tools/workflows: Data-efficient fine-tuning service using SF (5–10% of typical demonstration data); “sensor-light retrofit” that removes depth/LiDAR processing stages.
- Assumptions/dependencies: Quality RGB image capture; sufficient varied demonstrations; existing VLA-compatible robot stack.
- Low-cost home service robots (Daily life, Consumer robotics)
- Upgrade camera-only home assistants to robustly grasp, place, tidy, and manipulate kitchen/household objects following natural language instructions, with improved spatial precision.
- Tools/workflows: Pretrained SF-aligned models distributed in a consumer robot SDK; quick task adaptation via few-shot demos.
- Assumptions/dependencies: Multi-view or wrist+head camera configurations; curated small demo sets per home layout.
- Hospital logistics and assistive manipulation (Healthcare)
- Use SF to improve spatial reliability of tasks like fetching supplies, opening drawers, handling transparent containers, and placing items in constrained spaces with minimal sensor complexity.
- Tools/workflows: SF fine-tuning pipeline integrated into hospital robot software; depth-probing QA for safety validation.
- Assumptions/dependencies: Controlled lighting and sterile camera placement; compliance with healthcare privacy and device certification requirements.
- Education and training kits (Education)
- Provide monocular camera-based robot kits for schools and makerspaces with SF-aligned policies that learn robust manipulation from few demos, reducing hardware complexity and cost.
- Tools/workflows: Classroom-friendly SF tutorials; “Alignment-at-layer” configuration presets (e.g., 24th layer) for typical VLM backbones.
- Assumptions/dependencies: Availability of open VLM/VLA backbones and permissive licenses; modest GPU resources for offline SF alignment.
- Cross-embodiment policy transfer (Academia, Robotics platforms)
- Improve robustness when moving VLAs between heterogeneous robots (different camera positions, grippers) by SF-aligning visual embeddings to geometry-aware representations that generalize better.
- Tools/workflows: “Cross-embodiment SF pack” with positional embeddings and multi-view consistency; platform-agnostic evaluation via LIBERO/RoboTwin-style benchmarks.
- Assumptions/dependencies: Sufficient variation in training data; consistent tokenization and action expert interface.
- Rapid task onboarding with minimal demonstrations (Industry R&D)
- Exploit SF’s data efficiency to achieve strong performance with 5–10% of the usual dataset for new manipulation tasks or product variants, accelerating deployment cycles.
- Tools/workflows: Cosine-annealing training schedules; automated success-rate tracking vs. iterations to exploit the 3.8× training speed-up reported.
- Assumptions/dependencies: Access to clean multi-view RGB datasets; correct alignment-loss weighting (α) tuned per backbone.
- Camera-only retrofits to existing robot cells (Industry)
- Remove or de-emphasize depth sensors to lower maintenance costs and failure rates (e.g., lens contamination, calibration drift) while retaining spatially precise manipulation via SF-trained policies.
- Tools/workflows: Retrofit checklist (camera placement, positional embedding configuration); safety validation via depth probing and real-world trials.
- Assumptions/dependencies: Adequate field-of-view and image quality; reliable lighting management.
- QA and diagnostics for VLA spatial competence (Academia, Software)
- Integrate the paper’s depth probing as a diagnostic to quantify spatial information in embeddings during model development or acceptance testing.
- Tools/workflows: “Depth Probing Diagnostic” module with DPT head; t-SNE visualization to confirm alignment distribution properties.
- Assumptions/dependencies: Frozen VLA backbone for probing; stable data splits to prevent overfitting the probe.
- Cloud/offline supervision extraction services (Software, MLOps)
- Provide a managed service to run VGGT (or similar) offline to generate spatial supervision signals and feed SF training pipelines for different customers/models.
- Tools/workflows: Batch supervision extraction; feature normalization adapters; dataset/version tracking.
- Assumptions/dependencies: Licensing for 3D foundation models; data transfer agreements; GPU quotas.
- Energy and cost reduction in training pipelines (Industry, Finance)
- Use SF’s faster convergence and lower data requirements to reduce compute budgets and time-to-deploy for robotic manipulation models.
- Tools/workflows: Cost-aware training dashboards; alignment vs. baseline ROI comparisons; autoscaling GPU clusters.
- Assumptions/dependencies: Comparable baseline settings; reliable metrics instrumentation.
- Standards-aligned evaluation suites (Policy, Academia)
- Adopt SF-enhanced benchmarks for spatial reasoning in VLAs (e.g., long-horizon LIBERO-Long style suites) as part of procurement and safety assessment.
- Tools/workflows: Standardized test scenarios and reporting templates; reproducible seeds.
- Assumptions/dependencies: Community consensus; unencumbered benchmark licenses.
Long-Term Applications
The following use cases require further research, scaling, or productization to realize their full potential, building on SF’s alignment paradigm and findings.
- Generalist robots operating sensor-light in diverse, dynamic environments (Robotics, Industry)
- Large-scale deployment of camera-only or camera-primary robots across factories, warehouses, and public spaces, relying on SF-style representation supervision for 3D reasoning.
- Tools/products: “SF-native” generalist VLA policies; hardware standardization around multi-view RGB rigs.
- Assumptions/dependencies: Robustness under heavy occlusions, motion blur, and extreme lighting; continual learning in the field.
- Surgical and fine-grained medical manipulation (Healthcare)
- Apply SF-extended spatial embedding alignment for ultra-precise tasks (suturing, instrument handoffs) where depth sensors are impractical or restricted.
- Tools/products: Certified medical VLA stacks with SF; high-fidelity camera rigs; specialized safety QA.
- Assumptions/dependencies: Regulatory approvals; extreme reliability; domain-specific datasets.
- Autonomous mobile manipulation in households and elder care (Daily life, Healthcare)
- Camera-first mobile robots performing cleaning, cooking prep, and assistive tasks with safe spatial awareness.
- Tools/products: Consumer-grade SF services for task updates; privacy-preserving camera processing pipelines.
- Assumptions/dependencies: On-device compute; robust navigation-manipulation coupling; user safety policies.
- Agriculture robotics (Energy, Industry)
- Use SF to enable harvesting, pruning, and sorting with variable heights, textures, and lighting, minimizing specialized depth hardware in outdoor settings.
- Tools/products: Field-hardened multi-view camera modules; SF-adapted VLA for crop-specific tasks.
- Assumptions/dependencies: Weather resilience; domain randomization; robust generalization across cultivars.
- Construction and cobotics for assembly and inspection (Industry)
- SF-aligned VLAs for precise manipulation and inspection in partially known, changing job sites without relying on depth stacks that are fragile or costly.
- Tools/products: “Site-adaptive SF” training kits; workflow integration with BIM/AR overlays.
- Assumptions/dependencies: Safety certification; real-time hazard detection integration.
- AR/VR-guided teleoperation with geometry-aware assistance (Software, Robotics)
- Combine SF with AR cues to guide non-expert operators; spatially aware policies assist or predict actions in shared autonomy.
- Tools/products: Teleop UI with embedding-level alignment; predictive overlays of spatial relationships.
- Assumptions/dependencies: Low-latency video; robust human-in-the-loop safety mechanisms.
- Extension of SF to other modalities and tasks (Academia)
- Align intermediate representations not only to VGGT but to richer 3D signals (SDFs, mesh priors, multi-view tracks), or to audio-spatial cues.
- Tools/products: “Multi-modal SF” library; layer-wise alignment research toolkits.
- Assumptions/dependencies: Availability of high-quality cross-modal 3D datasets; theoretical frameworks for alignment stability.
- Self-supervised and online SF in the wild (Academia, MLOps)
- Replace offline supervision with on-robot self-supervision (e.g., structure-from-motion, multi-view geometry) to continually refine spatial embeddings.
- Tools/products: On-device incremental alignment modules; drift detection and correction workflows.
- Assumptions/dependencies: Reliable self-supervised signals; catastrophic forgetting management.
- Formal certification frameworks for monocular-first robots (Policy)
- Develop standards and safety tests tailored to camera-only spatial reasoning, informed by SF diagnostics and benchmarks.
- Tools/products: Certification protocols; compliance audit toolkits tied to representation-level metrics.
- Assumptions/dependencies: Multi-stakeholder consensus; liability models and risk scoring schemas.
- Sustainable AI initiatives via sensor simplification and faster training (Policy, Energy)
- Encourage policies that prioritize energy-efficient training and reduced hardware footprints; quantifying carbon savings from SF-style training speed-ups and sensor-lite designs.
- Tools/products: Sustainability reporting tools; procurement guidelines favoring RGB-based stacks when safety-equivalent.
- Assumptions/dependencies: Transparent energy accounting; validated equivalence in safety/performance.
- Cross-domain adoption beyond manipulation (Autonomous driving, Drones)
- Adapt SF to tasks where 3D perception is critical but depth sensors are limited (e.g., small drones, low-cost AV stacks), using multi-view cameras for alignment signals.
- Tools/products: Domain-specific SF backbones; simulation-to-real transfer suites.
- Assumptions/dependencies: Motion and viewpoint stability; handling high-speed dynamics.
- Representation standards and interchange formats (Academia, Software)
- Establish standardized intermediate spatial representation schemas for alignment, improving interoperability between VLM/VLA backbones and 3D foundation models.
- Tools/products: Open “Spatial Embedding Alignment” spec; adapters across model families (Prismatic, PaliGemma, etc.).
- Assumptions/dependencies: Community adoption; licensing and IP considerations for pretrained models.
Glossary
- 3D foundation model: A pretrained model that outputs 3D scene attributes or spatial features from 2D inputs. "geometric representations produced by pretrained 3D foundation models."
- action expert: A specialized module that converts token sequences into executable robotic actions. "trainable action expert (e.g. two-layer MLP or flow-matching head"
- action tokenization: Representing actions as discrete tokens so they can be generated by sequence models. "employ action tokenization and action experts to output actions."
- Alternating-Attention mechanism: An attention scheme alternating between per-frame local and global self-attention to integrate features. "employs an Alternating-Attention mechanism that interleaves frame-wise self-attention and global self-attention."
- auto-regressive: A generation process where each token is predicted conditioned on previously generated tokens. "employs multiple causal attention layers in an auto-regressive manner to generate the next tokens"
- batch normalization: A normalization layer that stabilizes and accelerates training by standardizing batch features. "batch normalization Γ followed by a two-layer MLP"
- bimanual: Involving coordinated control of two robotic arms. "RoboTwin is a real-to-sim bimanual benchmark."
- causal attention: Attention restricted to past tokens to preserve temporal causality in autoregressive models. "multiple causal attention layers"
- cosine similarity: A metric measuring alignment between vectors via the cosine of the angle between them. "we employ a cosine similarity score to maximize the alignment"
- cosine-annealing: A learning-rate scheduling strategy that follows a cosine curve over training. "we use the cosine-annealing rather than a multi-step training scheduler."
- cross-entropy loss: A standard loss for classification comparing predicted probability distributions to targets. "training loss (e.g. L1, L2, or cross-entropy loss)"
- depth estimator: A model that predicts per-pixel depth from 2D images. "limited by the performance of the depth estimator"
- depth maps: Per-pixel distance measurements from a viewpoint describing scene geometry. "depth maps or point clouds as input"
- depth probing: A diagnostic that trains a lightweight head on frozen embeddings to test encoded spatial depth. "we conduct a lightweight depth probing experiment"
- DINOv2: A self-supervised visual encoder pretrained on large-scale image data producing strong spatial features. "such as DINOv2"
- domain randomization: Training with varied environment conditions to improve robustness and generalization. "a hard setting with domain randomization, including scene clutter, diverse background textures, lighting variation, and varied tabletop heights."
- DPT head: A depth prediction transformer head used to regress depth from intermediate features. "only train a DPT head to transform the visual embeddings of VLA to depth maps."
- flow-matching head: A generative head trained via flow matching to produce target outputs (here, actions). "two-layer MLP or flow-matching head"
- lidars: Laser-based sensors that measure distances to reconstruct 3D structure. "depth cameras or lidars"
- LoRA: Low-Rank Adaptation; an efficient fine-tuning method injecting small rank updates into large models. "with LoRA on 1 NVIDIA H100"
- MLP: Multi-Layer Perceptron; a feed-forward neural network with one or more hidden layers. "two-layer MLP"
- multi-view consistency: Ensuring representations are coherent across different camera viewpoints. "To ensure multi-view consistency, we employ VGGT"
- normalized spatial representations: Spatial feature maps scaled to a standardized range for alignment or supervision. "generate normalized spatial representations"
- point clouds: Sets of 3D points capturing the geometry of a scene. "depth maps or point clouds as input"
- positional embedding: Vectors added to tokens to encode position or order information. "added with extra positional embedding E"
- Prismatic VLM: A visually conditioned LLM architecture used as the VLM backbone. "uses the Prismatic VLM pretrained on the Open-X-Embodiedment dataset as the VLM backbone"
- representation supervision: Training strategy that constrains hidden states to match target representations to improve downstream performance. "have demonstrated the effectiveness of representation supervision."
- Spatial Forcing (SF): The paper’s alignment strategy that injects spatial comprehension into VLAs without explicit 3D inputs. "We propose Spatial Forcing (SF), a simple yet effective alignment strategy"
- success rates (SR): The percentage of trials in which tasks are successfully completed, used as an evaluation metric. "We report the success rates (SR) as evaluation metrics"
- t-SNE visualization: A technique for visualizing high-dimensional data via nonlinear dimensionality reduction. "The t-SNE visualization."
- VGGT (Visual Geometry Grounded Transformer): A transformer that outputs 3D scene attributes (e.g., depth, point maps) from multi-view 2D images. "VGGT is a feed-forward model that directly outputs various 3D attributes of a scene"
- vision-language-action (VLA) models: Models that map visual observations and language instructions to robotic actions. "Vision-language-action (VLA) models have recently shown strong potential"
- vision-LLMs (VLMs): Models that jointly process images and text for semantic understanding. "vision-LLMs (VLMs)"
- visual embeddings: Hidden feature vectors derived from images used by downstream modules. "visual embeddings learned solely from 2D images do not produce meaningful spatial structures"
- visual tokens: Tokenized representations of visual inputs used as intermediate scene features in transformers. "the visual tokens as intermediate scene representations play a crucial role in generating action tokens"
Collections
Sign up for free to add this paper to one or more collections.