- The paper demonstrates a lightweight VLA paradigm achieving SOTA performance with only a 0.5B-parameter backbone without robotic data pre-training.
- The model introduces a novel Bridge Attention mechanism that integrates raw and ActionQuery features to enhance action generation.
- Efficient training on consumer GPUs with rapid inference speeds and robust performance on benchmarks and real-world tasks highlight its practical impact.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Introduction and Motivation
The VLA-Adapter framework addresses a central challenge in Vision-Language-Action (VLA) models: efficiently bridging high-dimensional vision-language (VL) representations to the action (A) space, especially under constraints of model size and pre-training resources. Existing VLA models typically rely on large-scale Vision-LLMs (VLMs) pre-trained on extensive robotic datasets, incurring significant computational and memory costs. VLA-Adapter proposes a lightweight paradigm that achieves state-of-the-art (SOTA) performance with a 0.5B-parameter backbone, eliminating the need for robotic data pre-training and enabling rapid training on consumer-grade hardware.
Bridging Paradigms: Systematic Analysis
The paper provides a systematic analysis of bridging paradigms from VL to A, categorizing prior approaches into two main types: (1) direct use of raw VLM features (from final or intermediate layers), and (2) learnable queries (ActionQuery) as interfaces between VLM and Policy networks.
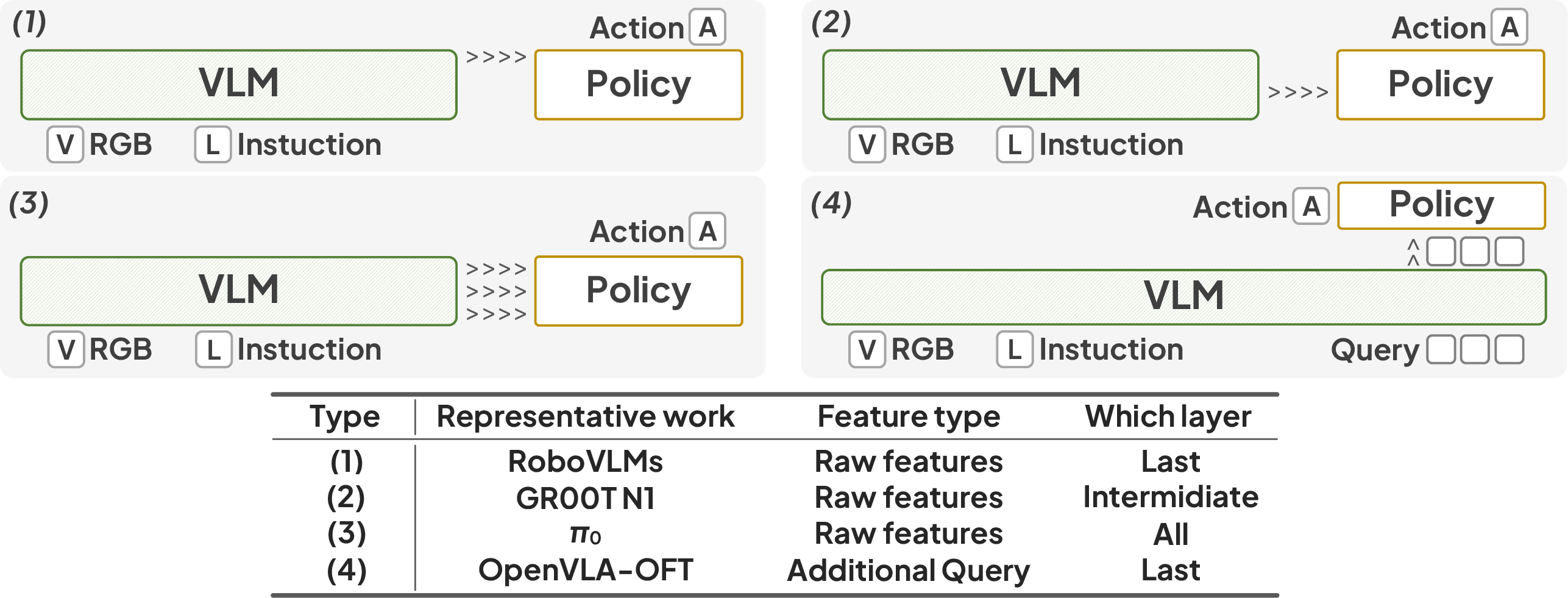
Figure 1: Existing representative bridge paradigms from VL to A.
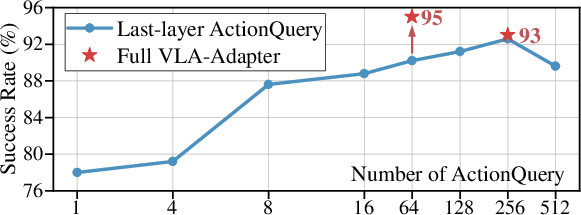
Key findings from ablation studies on the LIBERO-Long benchmark reveal:
- Middle-layer raw features (CtR) outperform deep-layer features for action generation, as they retain richer multimodal details.
- Deep-layer ActionQuery features (CtAQ) are more effective than shallow layers, due to aggregation of multimodal information during training.
- Multi-layer features (all layers) consistently outperform single-layer features, providing universality and obviating the need for layer selection.
These insights motivate the VLA-Adapter design, which leverages both all-layer raw and ActionQuery features as conditions for the Policy network.
VLA-Adapter Architecture
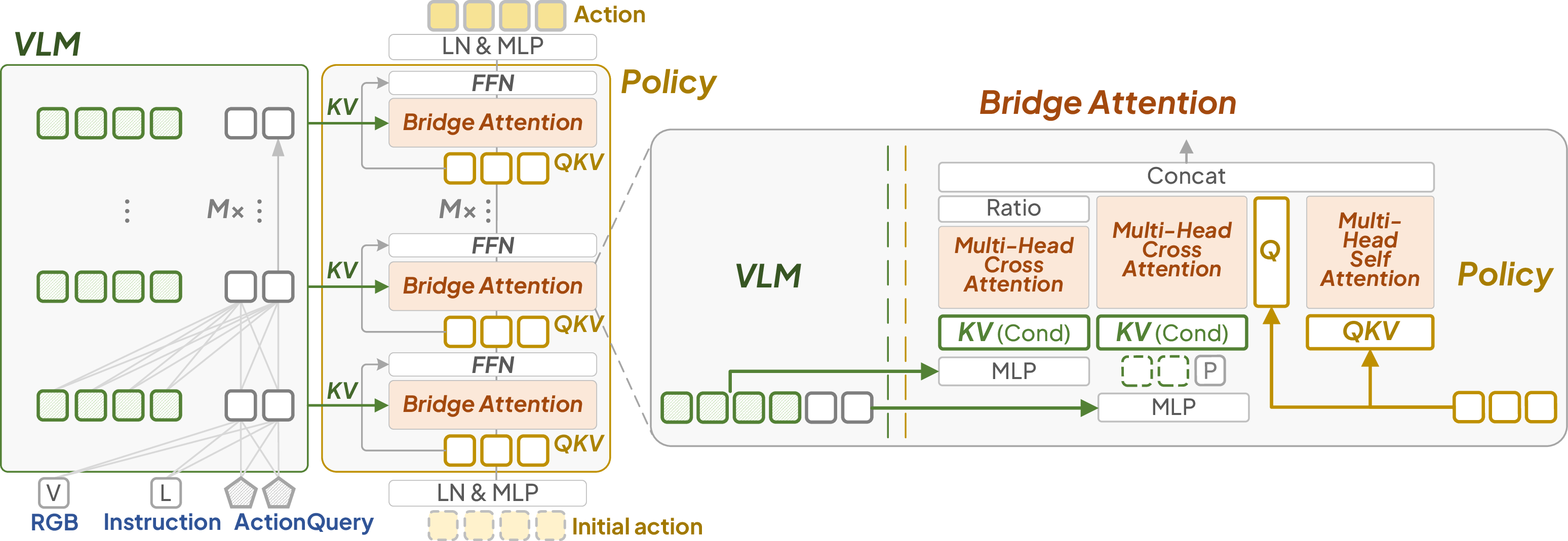
The VLA-Adapter framework consists of a compact VLM backbone (default: Prismatic VLM on Qwen2.5-0.5B), a Policy network with Bridge Attention, and a flexible conditioning mechanism.
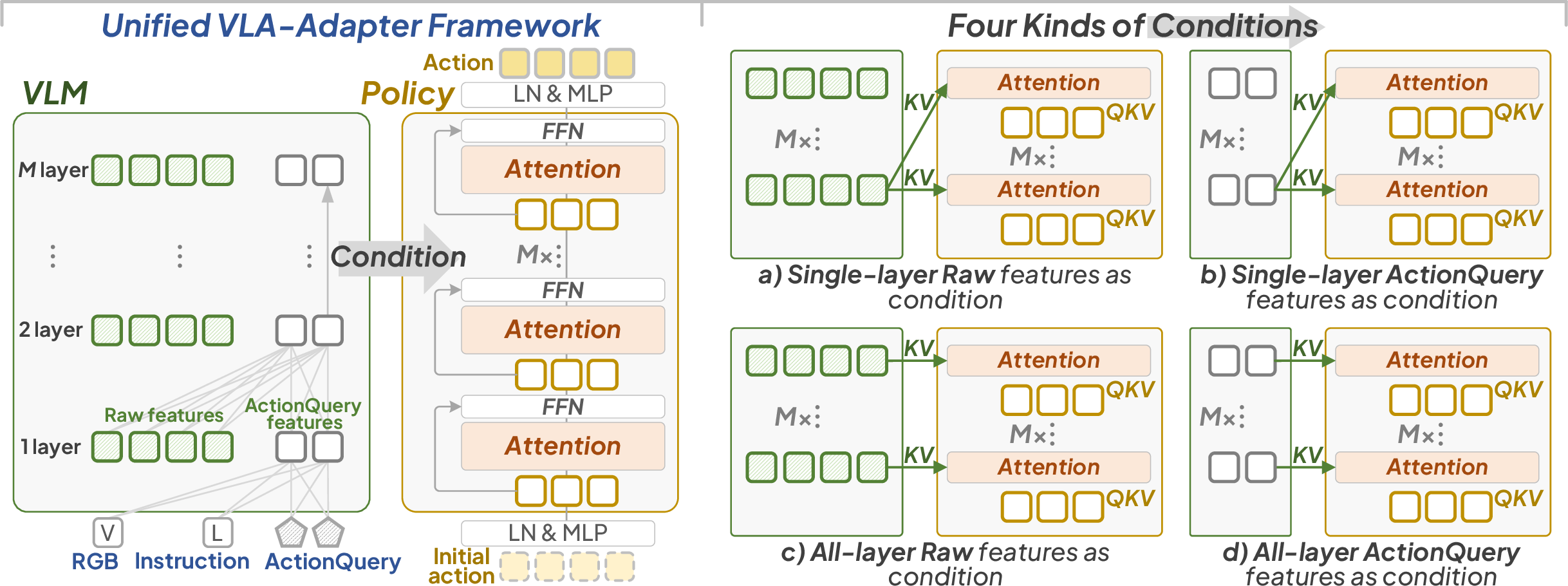
Figure 2: The proposed VLA framework. Key components include effective condition exploration and Bridge Attention design.
Bridge Attention Mechanism
The Policy network employs a novel Bridge Attention module at each layer, integrating both raw and ActionQuery features with the action latent. The architecture comprises:
This design enables selective and learnable injection of multimodal information into the action space, maximizing the utility of both raw and ActionQuery features.
Training and Implementation Details
VLA-Adapter is trained end-to-end from scratch, using AdamW optimizer and LoRA for efficient fine-tuning. The objective minimizes the L1 distance between predicted and ground-truth action trajectories. Hyperparameters are chosen for stability and efficiency (batch size 16, learning rate 1e−4, cosine annealing, 150k steps).
The framework supports both L1-based and DiT-based (Diffusion Transformer) Policy architectures. Empirical results favor the L1-based Policy for superior performance and inference speed in the fine-tuning regime.
Experimental Results
LIBERO Benchmark
VLA-Adapter achieves SOTA-level performance on the LIBERO benchmark, outperforming or matching large-scale models (OpenVLA-OFT, UnifiedVLA) with only 0.5B backbone parameters. Notably, it surpasses VLA-OS by 29.0% on LIBERO-Long and demonstrates robust performance across all task suites.
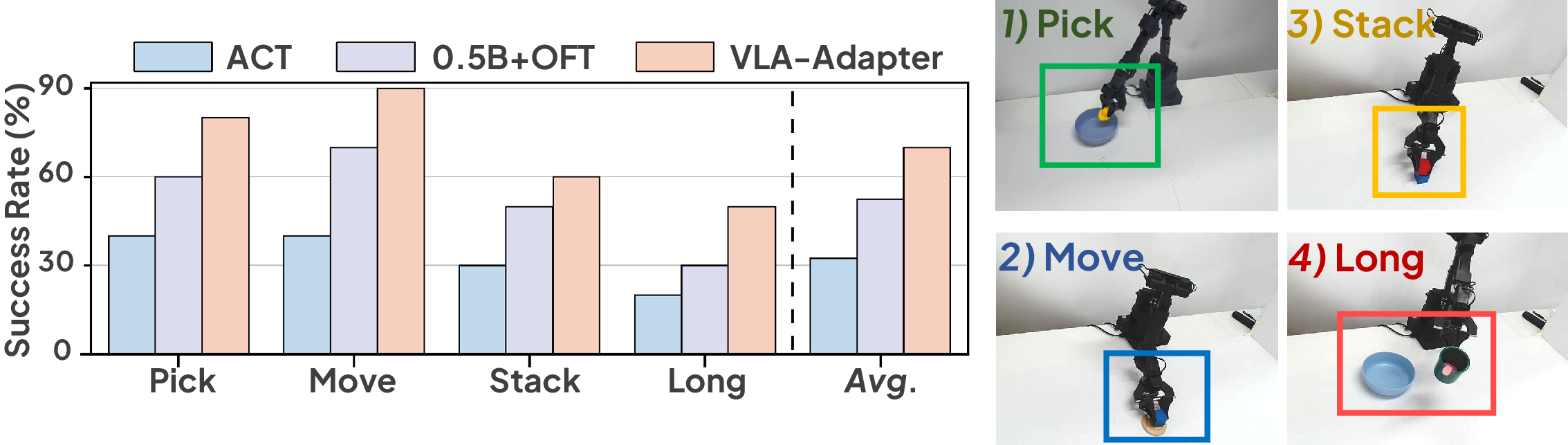
Figure 4: Comparison on real-world tasks.
CALVIN ABC→D Generalization
On the CALVIN ABC→D zero-shot generalization benchmark, VLA-Adapter attains the highest average task completion length (4.42), exceeding all baselines, including those with significantly larger backbones and those trained from scratch.

Figure 5: The example and task completion conditions on the CALVIN ABCtoD.
Real-World Robotic Tasks
VLA-Adapter is validated on a 6-DOF Synria Alicia-D robot with randomized object positions, demonstrating strong generalization and execution capabilities in both short-horizon and long-horizon manipulation tasks.
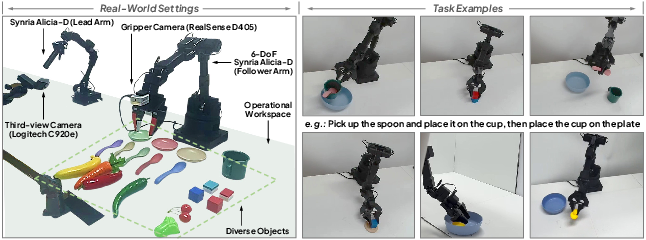
Figure 6: Real-world system Synria Alicia-D and the task examples.

Figure 7: Execution example on the real-world tasks.
Efficiency and Resource Requirements
VLA-Adapter achieves the fastest inference speed (219.2 Hz throughput, 0.0365 sec latency) among all compared methods, with low VRAM usage and rapid training (8 hours on a single consumer GPU). It remains effective even when the VLM backbone is frozen, outperforming SmolVLA and OpenVLA-OFT in this regime.

Figure 8: Execution example when the backbone is frozen.
Ablation Studies
Comprehensive ablations confirm:
Implications and Future Directions
VLA-Adapter demonstrates that high-performance VLA models can be realized without large-scale VLMs or robotic data pre-training, significantly lowering the barrier to deployment in resource-constrained settings. The paradigm enables rapid prototyping, efficient fine-tuning, and real-world applicability.
Theoretically, the systematic analysis of bridging paradigms provides a foundation for future research on multimodal representation transfer and action policy design. Practically, the framework is extensible to other embodied AI domains, including mobile robotics and humanoid control.
Future work may explore:
- Enhanced generalization via improved condition representations or hybrid pre-training strategies.
- Integration of reinforcement learning for more complex policy optimization.
- Application to broader real-world scenarios and hardware platforms.
Conclusion
VLA-Adapter introduces an effective, resource-efficient paradigm for bridging vision-language representations to action in VLA models. By leveraging both raw and ActionQuery features with a learnable Bridge Attention mechanism, it achieves SOTA performance with minimal computational overhead. The framework's scalability, efficiency, and robustness position it as a strong candidate for future embodied AI research and deployment.