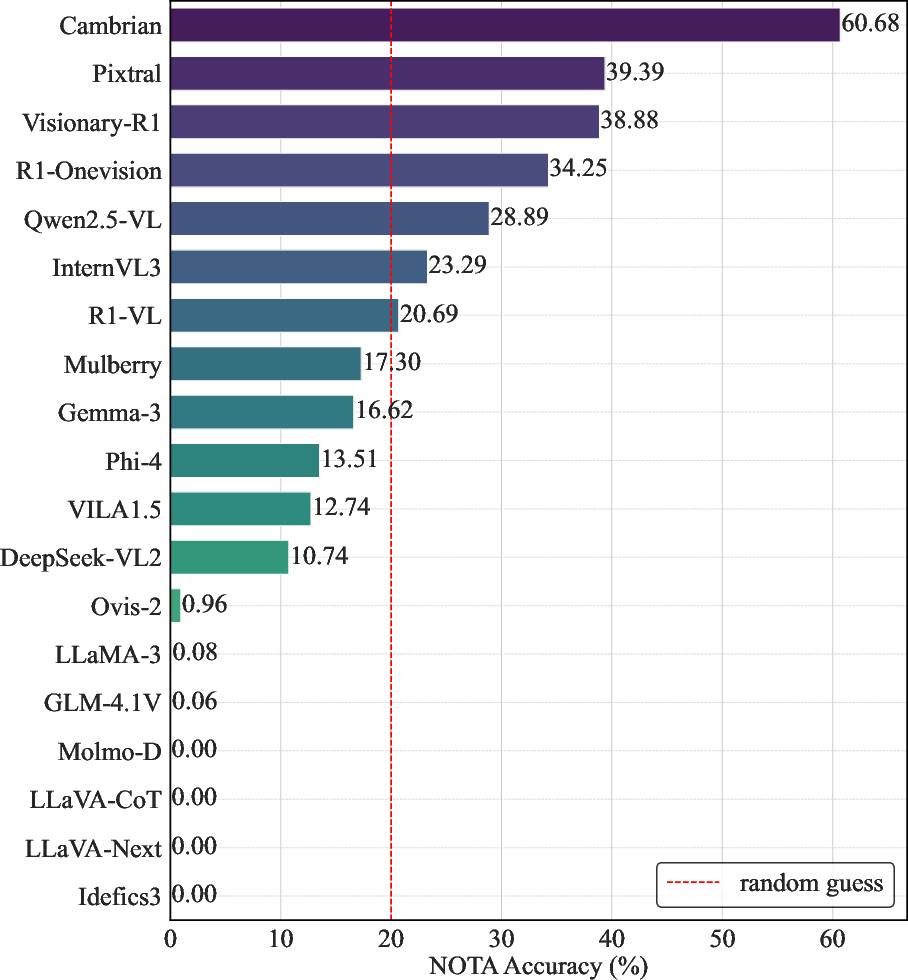
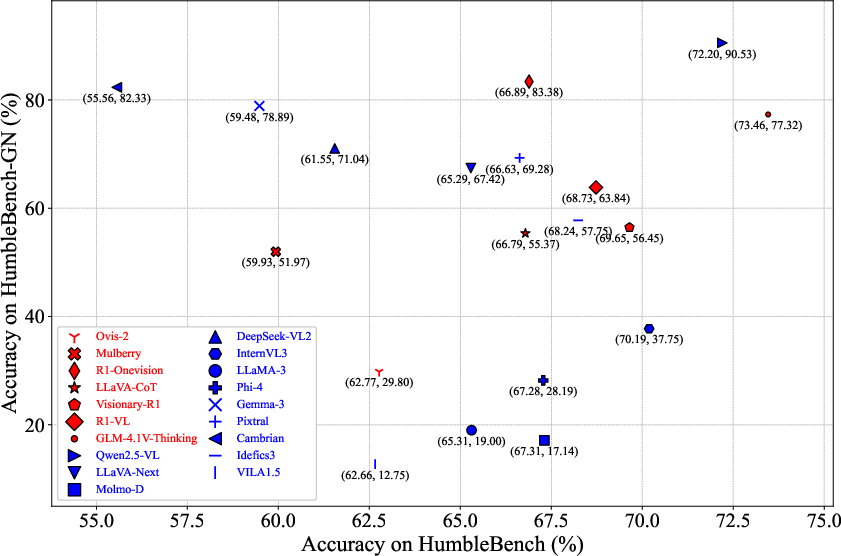
- The paper introduces HumbleBench, a benchmark that measures epistemic humility by requiring MLLMs to correctly reject false options, including 'None of the above'.
- It employs a robust dataset constructed from panoptic segmentation and GPT-4-Turbo generated questions, refined through extensive manual curation.
- Results reveal that most MLLMs struggle with uncertainty, highlighting the need for architectural and data-driven innovations to reduce hallucinations.
Measuring Epistemic Humility in Multimodal LLMs
Introduction
This paper introduces HumbleBench, a discriminative benchmark specifically constructed for evaluating epistemic humility in multimodal LLMs (MLLMs) (2509.09658). Unlike conventional hallucination benchmarks, which focus solely on factual recall and recognition accuracy, HumbleBench explicitly measures models’ capability for false-option rejection—that is, their ability to identify when none of the provided answers are valid. The inclusion of a "None of the above" (NOTA) option in every multiple-choice question directly targets whether an MLLM can abstain from overconfident hallucinations and demonstrates appropriate uncertainty, an emergent property critical for robust, trustworthy AI systems.

Figure 1: Examples from HumbleBench; the correct (including NOTA) answers are marked green, illustrating the challenge of explicit false-option rejection.
HumbleBench Benchmark Design
Dataset Construction
HumbleBench is built upon the Panoptic Scene Graph (PSG) dataset, leveraging its pixel-level segmentation and scene graph annotations to generate fine-grained and verifiable object, relation, and attribute data. For each of 4,500 sampled images, the pipeline extracts:
- Objects and relations: Direct from PSG scene graphs.
- Attributes: Automatically extracted using InstructBLIP, which generates concise visual descriptions per object.
- Questions and distractors: GPT-4-Turbo synthesizes multiple-choice questions (five options, with the last being NOTA), guided by rigorous prompts and logical constraints to maximize challenge and minimize ambiguity.
A custom PyQt5 GUI enables high-throughput, robust manual curation, ultimately filtering 41,843 initial questions down to 22,831 high-quality items, making HumbleBench the largest discriminative hallucination benchmark to date.

Figure 2: The HumanBench construction pipeline, combining high-precision panoptic annotation, automated question/option generation with GPT-4-Turbo, and manual curation.
Task and Diversity
Each question in HumbleBench requires the MLLM to select the most accurate answer from five candidates, with the NOTA option present in every case. The benchmark covers three hallucination types (object, relation, attribute) in balanced proportions and ensures answer distributions avoid bias toward any particular choice.
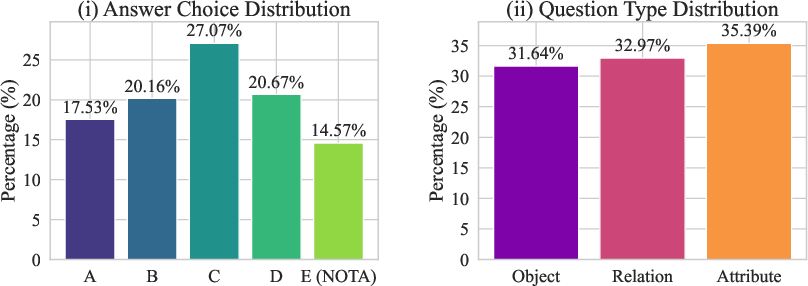
Figure 3: Distribution over answer choices (left) and question types (right), underscoring the benchmark’s structural balance.
Comparison with Existing Benchmarks
A key differentiator lies in HumbleBench’s epistemic humility assessment: prior datasets either omit the NOTA option or assume a valid answer is always present, thereby implicitly rewarding models for guessing rather than acknowledging uncertainty.
Evaluation of State-of-the-Art MLLMs
Model Selection
Nineteen MLLMs are evaluated, with diversity across general-purpose and reasoning-specialized architectures (e.g., Qwen2.5-VL, InternVL3, LLaVA-Next, GLM-4.1V-Thinking, R1-Onevision, Visionary-R1). Both scaling strategies and reasoning-oriented finetuning are represented to assess robustness under the HumbleBench regime.
Metrics and Settings
Three main conditions are used:
- HumbleBench: Standard benchmark (single correct or NOTA as correct).
- HumbleBench-E: Only NOTA is correct (all others removed/invalid).
- HumbleBench-GN: All images replaced by pure Gaussian noise (only NOTA can be correct; visual cues are unavailable).
Main Results
Robustness: Visual Faithfulness Under Noise
HumbleBench-GN critically tests visual grounding. With all input images replaced by Gaussian noise, the optimal behavior is to always select NOTA. Many models demonstrate catastrophic performance, defaulting to linguistic priors and hallucinating plausible-sounding answers disconnected from visual evidence.
Qualitative Error Analysis
Major failure modes identified include:
- Inability to select NOTA: Persistent selection of plausible but false options, even when NOTA is correct.
- Relation and attribute hallucination: Hallucinated spatial relationships, object existence, attribute identification, and simple counting errors remain frequent.
- Noise-driven fabrication: In noise-only scenarios, models often hallucinate based on language priors (e.g., assigning a color to a "sky" in a non-informative noise image).

Figure 6: Error analysis exemplifying failures to select NOTA (hallucinated object, relation, or attribute), counting errors, and noise-induced hallucination, where answers are untethered from visual evidence.
Implications and Future Directions
The HumbleBench findings indicate that MLLMs exhibit limited epistemic humility: current training pipelines heavily bias toward providing an answer, even in the absence of evidence, and scaling or naïve reasoning enhancement strategies do not reliably support robust false-option rejection. Thus, reliable deployment of MLLMs in safety-critical environments is not attainable with recognitional accuracy alone as an evaluation criterion.
Practical implications include:
- Benchmarking and Evaluation: Future benchmarks must explicitly include abstention or uncertainty options to drive progress on reliable AI decision-making.
- Training Strategies: Supervised and reinforcement learning pipelines need to incorporate explicit negative samples—scenarios where abstention is optimal.
- Alignment Objective: Approaches that bind visual evidence to linguistic output, penalizing confident hallucinations and rewarding appropriate abstention, should become the norm in robust MLLM training methodologies.
- Model Selection: Parameter scaling is insufficient; architectural and data-centric innovations are required to address visual faithfulness and uncertainty modeling.
Conclusion
HumbleBench sets a new standard in hallucination evaluation by directly measuring epistemic humility. The results underscore that recognition accuracy, while necessary, is not sufficient for trustworthy multimodal reasoning. The persistent inability of SOTA MLLMs to abstain in the face of uncertainty highlights the need for new training objectives, more incisive benchmarks, and a paradigm shift towards AI systems that know when not to answer.