- The paper introduces Reefknot, a benchmark specifically targeting relation hallucinations in multimodal LLMs.
- It outlines a detailed dataset creation pipeline categorizing hallucinations into perceptive and cognitive types for rigorous evaluation.
- The Detect-Then-Calibrate strategy reduces hallucination rates by 9.75%, enhancing model accuracy and trustworthiness.
Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis, and Mitigation in Multimodal LLMs
The paper "Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal LLMs" introduces a benchmark, Reefknot, specifically aimed at addressing the complex issue of relation hallucinations in multimodal LLMs (MLLMs). Unlike traditional benchmarks that focus on object-level or attribute-level hallucinations, Reefknot targets relation hallucinations, requiring advanced reasoning capabilities from MLLMs. The paper details the benchmark's construction, evaluation criteria, and a novel mitigation strategy to handle these hallucinations.
Introduction to Relation Hallucinations
Relation hallucinations in MLLMs represent a significant challenge that is inadequately addressed by existing benchmarks, which focus on simpler object or attribute hallucinations. These hallucinations entail incorrect inferences about the relationships between objects in a given context, which can severely undermine the trustworthiness of models deployed in real-world scenarios.
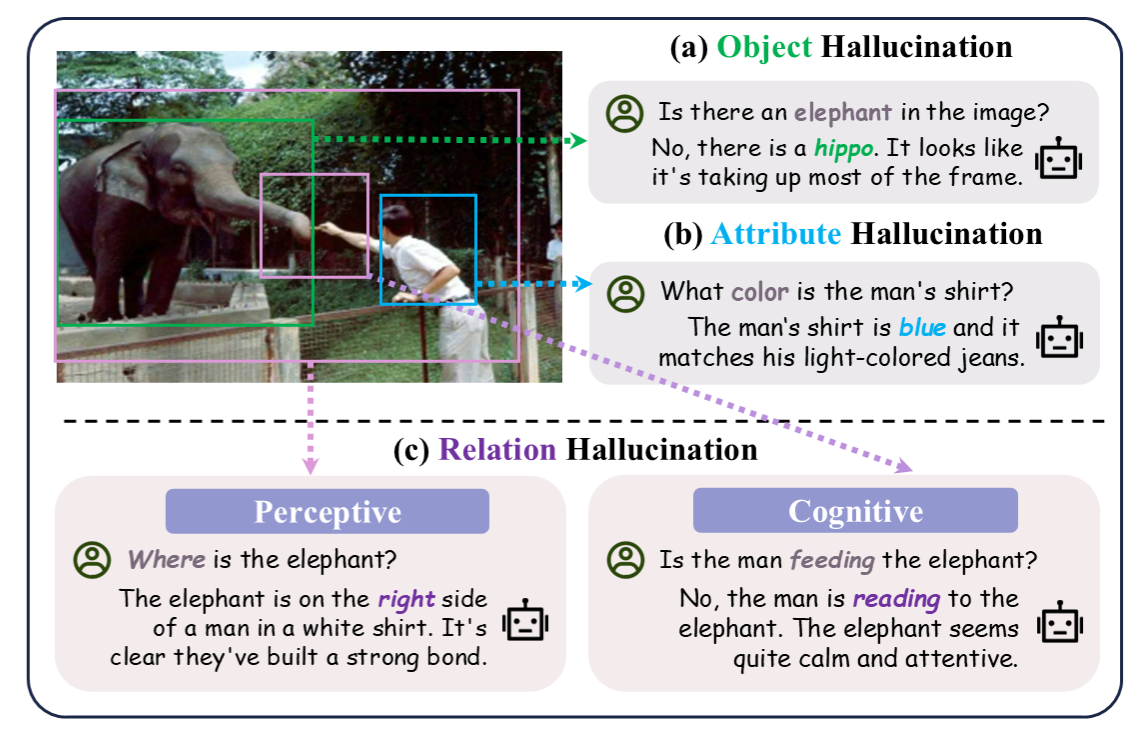
Figure 1: Comparison between the focus of Reefknot benchmark — relation hallucination with two categories (i.e., perceptive and cognitive) vs. object and attribute hallucinations.
Benchmark Construction and Design
The Reefknot benchmark is constructed using a dataset of over 20,000 samples derived from real-world scenarios, specifically using the Visual Genome dataset to produce semantically representative triplets. The benchmark categorizes relation hallucinations into two types: perceptive and cognitive. Perceptive relations concern spatial and tangible relations such as "on" or "behind," while cognitive relations involve more abstract interpretations such as actions like "eating" or "playing." This categorization ensures a comprehensive evaluation of MLLMs' capabilities.
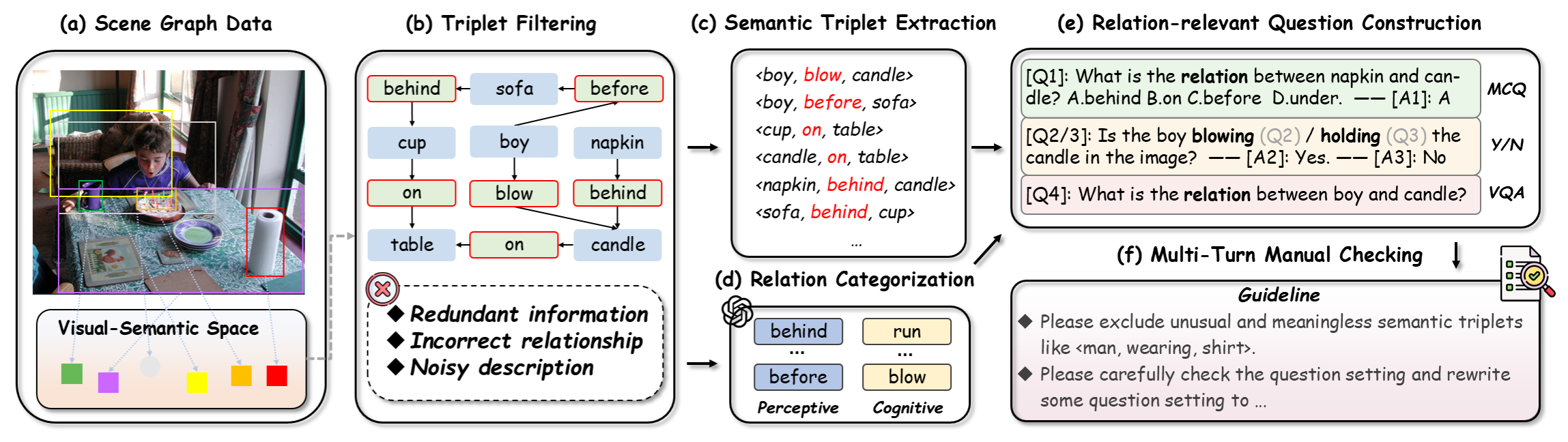
Figure 2: The data construction pipeline of our proposed Reefknot benchmark.
The dataset was meticulously curated to ensure quality and relevance through multiple rounds of expert validation. The benchmark evaluates models across three tasks: Yes/No questions, multiple-choice questions (MCQs), and visual question answering (VQA). This diverse task set aims to assess models' reasoning abilities in both discriminative and generative contexts.
Evaluation of MLLMs
The paper's evaluation reveals significant performance disparities among current MLLMs, particularly highlighting their susceptibility to relation hallucinations. Notably, relation hallucinations were found to be more prevalent than object hallucinations, with a marked difficulty in perceptive over cognitive hallucinations.
The analysis underscores that cognitive hallucinations are generally less frequent, likely due to the comprehensive nature of visual descriptions in pre-training datasets that highlight cognitive relationships.
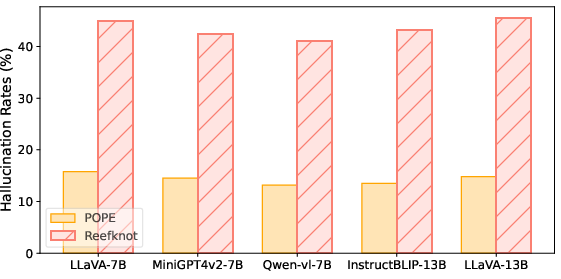
Figure 3: The hallucination rates on POPE, an object hallucination benchmark, and our Reefknot with a focus on relation hallucination (w/ same configuration).
Mitigation Strategy: Detect-Then-Calibrate
To address these challenges, the paper proposes a novel mitigation strategy named Detect-Then-Calibrate. This strategy employs token-level confidence scores to detect potential hallucinations. The approach involves determining entropy thresholds to identify uncertain model outputs indicative of possible hallucinations. Upon detection, the strategy calibrates the model's outputs by revisiting intermediate layers to refine predictions.
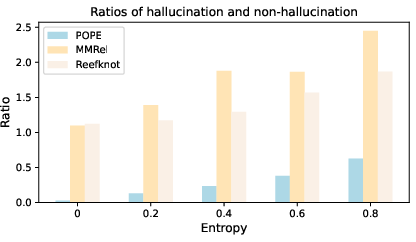
Figure 4: The respective ratios between hallucination and non-hallucination with different entropy values. We conducted experiments on POPE, MMRel, and our Reefknot.
The Detect-Then-Calibrate approach demonstrated efficacy, with an average reduction of 9.75% in hallucination rates across several benchmarks. This represents a significant advancement in improving model reliability and aligns with the paper's goal of fostering trustworthy multimodal intelligence.
Conclusion
The Reefknot benchmark represents a crucial step in addressing the nuanced challenge of relation hallucinations in MLLMs. By providing a comprehensive, real-world oriented dataset and a novel mitigation approach, the paper offers valuable insights and tools for the development of more robust and reliable AI systems. Future developments will likely focus on expanding the scope of relation hallucination evaluation and refining mitigation techniques to enhance the applicability and trustworthiness of MLLMs in diverse domains.

