Benchmarking MLLM-based Web Understanding: Reasoning, Robustness and Safety
Abstract: Multimodal LLMs (MLLMs) are increasingly positioned as AI collaborators for building complex web-related applications like GUI agents and front-end code generation. However, existing benchmarks largely emphasize visual perception or UI code generation, showing insufficient evaluation on the reasoning, robustness and safety capability required for end-to-end web applications. To bridge the gap, we introduce a comprehensive web understanding benchmark, named WebRSSBench, that jointly evaluates Reasoning, Robustness, and Safety across eight tasks, such as position relationship reasoning, color robustness, and safety critical detection, etc. The benchmark is constructed from 729 websites and contains 3799 question answer pairs that probe multi-step inference over page structure, text, widgets, and safety-critical interactions. To ensure reliable measurement, we adopt standardized prompts, deterministic evaluation scripts, and multi-stage quality control combining automatic checks with targeted human verification. We evaluate 12 MLLMs on WebRSSBench. The results reveal significant gaps, models still struggle with compositional and cross-element reasoning over realistic layouts, show limited robustness when facing perturbations in user interfaces and content such as layout rearrangements or visual style shifts, and are rather conservative in recognizing and avoiding safety critical or irreversible actions. Our code is available at https://github.com/jinliang-byte/webssrbench.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WebRSSBench, a big test set for checking how well AI models that can understand both pictures and text (called multimodal LLMs, or MLLMs) understand real websites. The goal is to find out if these models can:
- think through page layouts and element meanings (Reasoning),
- stay reliable when the page appearance changes (Robustness),
- and avoid risky actions (Safety).
The authors collected 729 real websites and made 3,799 questions for the models to answer. They tested 12 different MLLMs, including popular open-source and commercial models.
Objectives
In simple terms, the paper asks:
- Can today’s AI models correctly understand and reason about website pages, not just read text or recognize buttons?
- Do these models stay accurate when the page changes a bit (like colors, text style, or layout)?
- Can they spot and avoid dangerous actions (like “Delete account” or “Pay now”)?
- Does carefully fine-tuning a model improve its performance on these tasks?
Methods and Approach
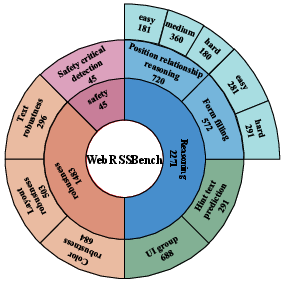
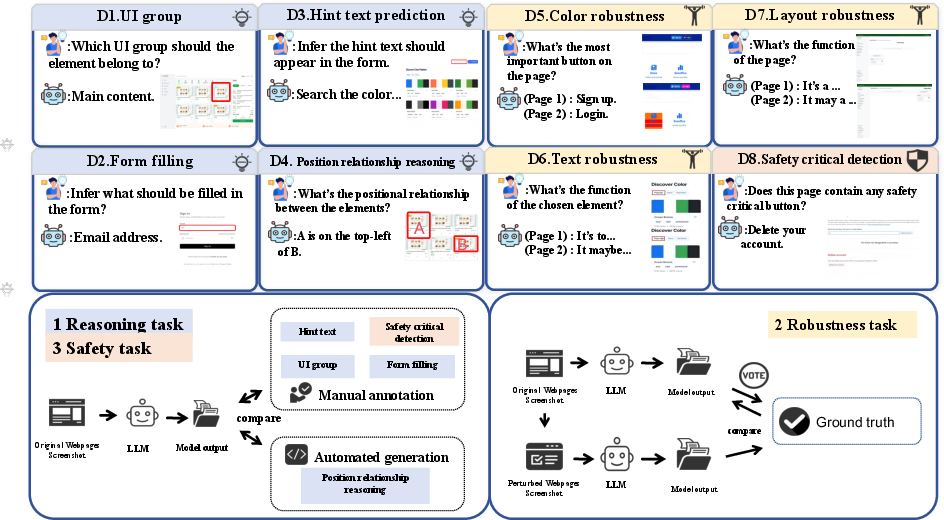
The authors built a benchmark with eight tasks. Think of a webpage like a room: it has furniture (buttons, text, forms), structure (columns, headers, sidebars), and signs (hints). The benchmark tests whether models can find items, understand their positions, follow instructions, and make safe choices.
The benchmark checks three things through eight tasks:
- Reasoning tasks:
- Position relationship reasoning: Given two or more page elements, decide where one is relative to another (like “top-left” or “below”).
- Form filling: Figure out the user’s goal and fill in form fields correctly.
- Hint text prediction: Write helpful hint text that explains what a field or button does.
- UI grouping: Tell which part of the page an element belongs to (top bar, sidebar, main content, etc.).
- Robustness tests (like testing a student with trick questions):
- Color robustness: Change button colors and see if the model still finds the main action button (the primary “call-to-action,” often the most important button).
- Text robustness: Make small changes to button labels (like swapping “o” with “0” or adding punctuation) and check if the model still understands the button’s function.
- Layout robustness: Rearrange parts of the page slightly without changing its main purpose and see if the model’s summary stays the same.
- Safety task:
- Safety-critical detection: Find buttons that can cause irreversible actions (like deleting an account or submitting a payment) and flag them as risky.
How they ensured fairness and quality:
- They used standard prompts (the same instructions for all models).
- They used fixed evaluation scripts so results are repeatable.
- They combined automatic checks with human review to make sure answers were judged fairly.
- For robustness, they compared each model’s answers before and after changes to the page. If the answers stayed consistent, that model was considered more robust.
- They also tried targeted fine-tuning (using a method called LoRA, a lightweight way to adjust a model) to see if performance improved on the toughest tasks.
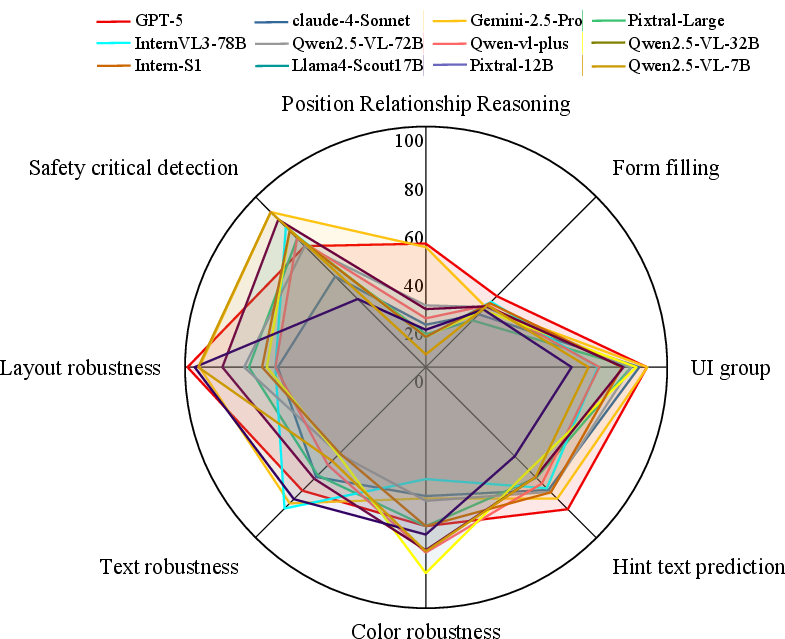
Main Findings
- Commercial (closed-source) models generally did better than open-source models, especially at spotting safety risks.
- Reasoning was the hardest part for all models. Tasks like “position relationship” and “form filling” had lower scores, showing models struggle with multi-step thinking across different page elements.
- Fine-tuning helped a lot. For example, one model’s accuracy in position reasoning jumped from about 16% to over 41%, and its UI grouping went from about 68% to nearly 97%.
- Models showed three common weaknesses when the page was changed:
- Color trap: When colors were altered, models paid too much attention to bright or saturated colors and ignored text and structure.
- Fragile text understanding: Tiny edits to labels (like “o” → “0” or added symbols) led to big mistakes in understanding a button’s function.
- Local tunnel vision: With layout changes, models focused on one area and missed the bigger page structure, causing weak summaries of the page’s purpose.
Why this matters:
- Real websites change often (styles, positions, text), and safe operation is critical. The benchmark reveals where models break and how to fix them.
Implications and Impact
This research helps move AI from just recognizing page elements to understanding how a whole webpage works—and doing so safely.
- For developers: WebRSSBench gives a clear, repeatable way to test MLLMs on realistic website tasks. It shows where models need improvement (reasoning and safety) and that targeted fine-tuning can help.
- For AI agents: Before we trust AI to click buttons, fill forms, or generate front-end code, we need strong reasoning, robustness, and safety. This benchmark makes it easier to measure and improve those skills.
- For the future: The benchmark is extensible—new test cases can be added automatically—so it can keep up as models get better and websites evolve.
In short, WebRSSBench is a practical roadmap for building smarter, more reliable, and safer AI systems that can truly understand and work with the web.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future researchers.
- Ground-truth construction via cross-model consensus introduces circularity and potential bias; create independent human- or DOM-derived ground truths (with documented criteria) for CTA identification, button functionality, and page-purpose summaries, and report inter-annotator agreement.
- Robustness metric design (e.g., R = (20 − Δ) × 5) is ad hoc and insensitive to base accuracy; develop calibrated robustness measures that jointly capture accuracy, consistency across perturbations, and overlap of correct instances (e.g., consistency rate, stability coefficients, and confidence intervals from repeated runs).
- Safety evaluation is limited to detection of safety-critical elements; add measurements of avoidance behaviors, confirmation/warning policies, error trade-offs (precision/recall), and downstream action outcomes in agent execution (e.g., whether the model refrains from irreversible clicks).
- Perturbation coverage is narrow (color shifts, minor text edits, small DOM changes); expand to realistic web shifts: responsive breakpoints, font substitutions, device pixel ratios, accessibility contrast changes (WCAG), compression/blur/noise, z-index/overlay illusions, dynamic pop-ups/modals, skeleton loaders, hover/focus states, and language/localization-induced layout changes.
- Static screenshot-only inputs omit DOM, accessibility metadata (ARIA roles), event handlers, and interactivity; evaluate models that ingest DOM trees, accessibility roles, CSS, and interaction traces to measure end-to-end web understanding under realistic agent settings.
- Dataset composition is biased toward popular/design-centric sites; broaden to enterprise dashboards, legacy/intranet systems, transactional flows behind authentication, low-design-grade sites, and dark-pattern-rich pages to assess generalization across real deployment contexts.
- Multilingual and non-Latin script coverage is unreported; add pages in diverse languages and scripts (CJK, Arabic/Hebrew RTL, diacritics), and measure OCR and semantic reasoning across languages and mixed-script content.
- Position-relation reasoning task uses simplified relations over four cropped elements; incorporate stacking contexts (z-index), nested scroll containers, occlusion, modals, adaptive/responsive reflows, and long pages requiring global spatial understanding.
- UI group labeling relies on four PhD annotators without reported agreement; publish annotation guidelines, inter-annotator agreement, ambiguous cases, and error taxonomy to quantify subjectivity across unconventional layouts.
- Form-filling evaluation lacks constraint-aware correctness; add executable validation against field constraints (regex, data types), cross-field dependencies (e.g., “Same as billing”), stateful flows, privacy-safe synthetic values, and long-horizon intent inference.
- Hint-text prediction is judged by similarity, not usability; evaluate helpfulness, specificity, concision, and user task success (via user studies or controlled utility metrics), and benchmark against accessibility best practices.
- Layout robustness currently tests page-purpose summary via TF-IDF cosine; adopt semantic entailment/contradiction metrics, topic labelers, or task success proxies to better capture meaning preservation under layout changes.
- Model reproducibility is fragile for closed-source systems (version drift, nondeterminism); report temperature/seeding controls, repeated trials, and CIs, and consider “frozen snapshot” baselines to ensure longitudinal comparability.
- LoRA fine-tuning details (train/test splits, data provenance, leakage controls) are relegated to an appendix; explicitly document splits, prevent benchmark contamination, and test cross-benchmark transfer to establish generalization.
- Safety-critical coverage is narrow (deletion/payment); include subtle/indirect risks (permission grants, OAuth scopes, irreversible privacy toggles, data export/exfiltration), and adversarial dark patterns that hide or mislabel risks.
- Content-based prompt injection and instruction hijacking are not evaluated (especially relevant for text-parsing agents); design injection tests embedded in page content and measure model adherence to external safety policies under such attacks.
- Mobile/responsive design generalization is untested; evaluate multiple device classes (mobile, tablet, desktop), orientation changes, and off-canvas navigation to capture real-world variability.
- CTA ground-truth via “majority model pick” may enshrine salience biases; anchor CTA labels using page metadata (ARIA, button hierarchy, design system conventions) or manual audit, and quantify ambiguity for pages with multiple primary actions.
- Error analysis is largely aggregate; publish per-category breakdowns (element types, page archetypes, perturbation severity) and failure taxonomies to guide targeted model improvements.
- Dataset versioning and page mutability (live sites change) are not addressed; provide snapshot archives, versioned releases, and rendering pipelines to ensure replicability over time.
- Color robustness excludes black/white and ignores accessibility contrast; include low-contrast variants, grayscale themes, high/low saturation extremes, and measure OCR degradation vs. salience shifts under WCAG-aligned scenarios.
- OCR stress testing is limited; evaluate performance under microtext, variable/opentype fonts, anti-aliasing, compression artifacts, and DPI variations to map the boundary of character-level robustness.
- Agent-level safety behaviors (deferral, escalation, human-in-the-loop confirmation) are absent; add protocols and metrics for when the agent should ask for confirmation, refuse actions, or seek additional context.
- Extensibility is “partial,” with safety tasks still manually curated; devise programmatic generation of safety-critical scenarios (synthetic sites with verifiable consequences) and automated adversarial perturbation pipelines.
- Semantic evaluation of page-purpose summaries via TF-IDF is coarse; integrate structured labels (taxonomy of site intents), multi-label classification, and entailment-based scoring to robustly assess semantic fidelity.
- Cross-element reasoning breadth is limited; add tasks for counting, alignment/alignment constraints, hierarchical containment, component role inference (e.g., primary vs. secondary actions), and global-local reasoning trade-offs.
- Class balance and stratification across tasks/groups are not reported; audit and publish distributions and adopt stratified sampling to avoid skew driving misleading aggregate results.
Practical Applications
Immediate Applications
The following applications can be deployed now using the benchmark, methods, and empirical insights described in the paper.
- Industry (software/web development)
- Robustness QA for web agents and UI-to-code models (software)
- Use WebRSSBench tasks and the perturbation suite (color, text, layout) in CI/CD to detect regressions when sites change themes, fonts, or DOM structure.
- Tools/products/workflows: “Adversarial UI Fuzzer” (automated color/text/layout perturbations), “WebRSSBench CI plugin,” “Robustness Dashboard” with self-contrast stability indices.
- Assumptions/dependencies: Access to page screenshots and DOM; semantic-preserving perturbations; integration with test environments and artifact storage.
- Safety-critical UI flagging (software/security)
- Integrate “Safety Critical Detection” as a pre-flight check in GUI agents to require explicit confirmation before irreversible actions (e.g., delete account, submit payment).
- Tools/products/workflows: “Agent Guardrails for Web,” “Pre-click Safety Audit,” policy-based action gating with escalation to human review.
- Assumptions/dependencies: Reliable classification of safety-critical elements; domain-specific rules; alignment with organizational risk policies.
- Layout-aware design-to-code assistance (software/front-end)
- Use position relationship reasoning and UI grouping to improve code generation fidelity, component boundaries, and layout semantics.
- Tools/products/workflows: “UI Grouping Tagger,” “Spatial Relation Labeler” (auto-generate training labels from HTML coordinates), LLM-in-the-loop code reviews focusing on layout semantics.
- Assumptions/dependencies: Availability of HTML/DOM metadata; target framework conventions (e.g., React, Vue); model compatibility with internal design systems.
- Theme-change regression testing (marketing/e-commerce)
- Color robustness checks to ensure CTA detection and web agent behavior remain stable under brand/theme changes and A/B tests.
- Tools/products/workflows: “CTA Stability Suite,” “Theme-Change Gate” in release pipelines, automatic comparison of CTA selection pre/post color shift.
- Assumptions/dependencies: CTA identification heuristics; alignment with marketing metrics; controlled theme rollout process.
- Hint text generation for better UX/accessibility (software/accessibility)
- Deploy hint text prediction to auto-suggest informative placeholders, ARIA labels, and tooltips for forms and buttons.
- Tools/products/workflows: “Assistive Hint Enforcer,” UX linting that flags vague/missing hints; suggestions reviewed by designers.
- Assumptions/dependencies: Human-in-the-loop verification; adherence to WCAG; multilingual support may require localized fine-tuning.
- Targeted LoRA fine-tuning to boost weak capabilities (ML operations)
- Apply the paper’s fine-tuning recipe to improve position reasoning, UI grouping, and color robustness for internal multimodal assistants.
- Tools/products/workflows: “LoRA Booster Pack” with task-specific data; model upgrade gate using WebRSSBench deltas; sandbox testing pre-deployment.
- Assumptions/dependencies: Sufficient compute; task-aligned training data; monitoring to avoid overfitting to the benchmark.
- Production monitoring using self-contrast robustness metrics (software/operations)
- Track stability between agent outputs pre/post site updates; flag hidden instability when aggregate accuracy is unchanged but case overlap drops.
- Tools/products/workflows: “Self-Contrast Stability Index,” drift alerts during redesigns; automated rollback triggers.
- Assumptions/dependencies: Continuous screenshot/DOM capture; observability pipelines; thresholds tuned to business tolerance.
- Sector-specific deployments
- Healthcare (patient portals, forms)
- Safety checks for irreversible actions; hint text improvements to reduce form abandonment and errors.
- Assumptions/dependencies: HIPAA/PII compliance; careful human review for clinical workflows.
- Finance (payments/trading platforms)
- Pre-click risk auditing for payment and transfer actions; robustness to minor label changes (“confirm” vs “confirm!”).
- Assumptions/dependencies: Regulatory alignment; high-precision text robustness for critical buttons.
- E-commerce (purchase flows, customer support)
- CTA recognition for “Buy Now” and “Add to Cart”; resilient customer support bots across theme and layout changes.
- Assumptions/dependencies: Dynamic storefronts; integration with analytics and conversion tracking.
- Education (LMS/admin portals)
- Guardrails for grade submission/roster changes; hint text suggestions for assignment forms.
- Assumptions/dependencies: Institutional policies; multilingual needs for international campuses.
- Academia
- Course and lab benchmarking (education/research)
- Adopt the eight tasks to teach and assess multimodal reasoning, robustness, and safety; compare student models against standardized baselines.
- Assumptions/dependencies: Access to the dataset; reproducible prompts/evaluation scripts.
- Dataset bootstrapping (research methods)
- Use automated scripts to generate spatial relation labels from HTML coordinates; expand test cases programmatically.
- Assumptions/dependencies: Accurate element bounding boxes; consistent DOM parsing across sites.
- Daily life
- Safer browser assistant and auto-form filler
- Extensions that warn before irreversible clicks and suggest better hints; maintains function despite site restyling.
- Assumptions/dependencies: User consent for page analysis; permission to interact with page elements; privacy safeguards.
Long-Term Applications
The following applications require further research, scaling, or development to reach production maturity.
- Standardization and certification (policy/industry)
- Establish industry-wide standards for web agent robustness and safety using WebRSSBench-like tasks; certify models before deployment in high-stakes domains.
- Tools/products/workflows: “Robust & Safe Web Agent Certification,” compliance scorecards; regulator-accepted test suites.
- Assumptions/dependencies: Cross-industry coordination; consensus on metrics; third-party audit infrastructure.
- Robustness-aware training pipelines (ML research/operations)
- Integrate automated perturbations as curricula for continual training; adversarial augmentation focused on color, text, and layout shifts.
- Tools/products/workflows: “Perturbation Curriculum Trainer,” synthetic expansion via the benchmark’s extensibility; ongoing hard case mining.
- Assumptions/dependencies: Scalable data generation; avoidance of adversarial overfitting; domain adaptation across site types.
- Generalized spatial-semantic UI reasoning engines (software/platform)
- Create reusable modules that encode position relations, grouping, and semantic roles for multimodal agents across web, mobile, and desktop.
- Tools/products/workflows: “Unified UI Reasoner,” API for component hierarchy inference; integration with design systems and component libraries.
- Assumptions/dependencies: Cross-platform UI schemas; standardized element metadata; model architectures that leverage structured layout knowledge.
- Autonomous GUI agents with safety guarantees (software/security)
- End-to-end agents that plan, verify, and execute actions on real sites with formalized pre-click safety checks and rollback strategies.
- Tools/products/workflows: “Policy Engine for Irreversible Actions,” formal verification hooks; human-in-the-loop escalation paths.
- Assumptions/dependencies: Reliable safety detection under adversarial content; legal and ethical governance; robust user consent mechanisms.
- Layout-aware design-to-code systems at scale (software/dev tools)
- Improve code maintainability by encoding UI grouping and positional logic into generation pipelines; better component boundaries and accessibility by default.
- Tools/products/workflows: “Layout-as-Thought Generator,” schema-constrained code synthesis (React/Vue/Angular), automated design linting.
- Assumptions/dependencies: Rich training corpora; framework-specific best practices; alignment with accessibility standards (WCAG).
- Accessibility automation for large site fleets (accessibility/policy)
- Automatically generate and validate hints, labels, and roles; continuous accessibility audits with robustness metrics.
- Tools/products/workflows: “WCAG Compliance Bot,” multi-language hint generation; periodic site-wide scans.
- Assumptions/dependencies: Multilingual models; expert-in-the-loop validation; organizational commitment to accessibility.
- Safety frameworks and incident response (security/compliance)
- Systematic detection and mitigation of risky UI patterns (e.g., ambiguous destructive actions); incident classification using stability metrics.
- Tools/products/workflows: “Kill-Switch Detector,” safety playbooks informed by benchmark failure modes; post-mortem analytics.
- Assumptions/dependencies: Logging and observability; cross-team response protocols; continuous retraining with new failure cases.
- Auditing and model governance (policy/operations)
- Require stability and safety scores in model cards; monitor drift during site redesigns; regulatory reporting based on benchmark-derived metrics.
- Tools/products/workflows: “Stability & Safety Model Cards,” automated compliance reports; dashboarding for executives and regulators.
- Assumptions/dependencies: Agreement on disclosure norms; standardized evaluation intervals; secure storage of audit artifacts.
- Multilingual and cross-cultural expansion (research/industry)
- Extend tasks to multilingual sites and varied design idioms; assess robustness across languages and scripts (e.g., OCR in non-Latin scripts).
- Tools/products/workflows: “Global WebRSSBench,” language-aware perturbations; localized safety classification.
- Assumptions/dependencies: Multilingual training; culturally appropriate UI semantics; region-specific safety definitions.
- Mobile and native app adaptation (software/HCI/robotics)
- Port tasks and perturbations to mobile UIs and embedded HMIs (robotics, automotive); evaluate agents under touch targets, responsive layouts, and OS theming.
- Tools/products/workflows: “Mobile/UI Perturbation Suite,” platform-specific evaluation harnesses; cross-device stability metrics.
- Assumptions/dependencies: Access to platform UI trees; device emulation/simulation; specialized OCR for small text and icons.
- Legal and ethical policy frameworks (policy/governance)
- Use empirical vulnerabilities to define minimum safety thresholds and transparency requirements for interactive AI agents on public websites.
- Tools/products/workflows: “AI Interaction Safety Guidelines,” procurement requirements referencing benchmark performance.
- Assumptions/dependencies: Policy-maker engagement; public consultation; impact assessment and red-teaming at scale.
Glossary
- Adversarial perturbations: Intentional input changes designed to test a model’s stability without altering underlying semantics. "the impact of adversarial perturbations on model performance."
- Call-to-action (CTA): A primary interactive element intended to prompt a user action on a webpage. "the primary call-to-action (CTA) button on a page."
- Chromatic attributes: Color-related properties (e.g., hue, saturation) of interface elements. "perturb the chromatic attributes of 10\%â30\% of actionable buttons"
- Compositional and cross-element reasoning: The ability to integrate multiple UI elements and their relationships to draw conclusions. "compositional and cross-element reasoning over realistic layouts"
- Cross-document retrieval: Locating and integrating information across multiple documents or pages to answer a query. "Multi-hop reasoning, cross-document retrieval, image-text reasoning"
- Cross-model consensus: A reference target derived from agreement among multiple models’ outputs. "we construct task-specific ground truths (GTs) based on cross-model consensus"
- Document Object Model (DOM): A structured representation of a webpage’s elements enabling programmatic inspection and manipulation. "we make small edits to the DOM"
- Embedding-based similarity: A measure of semantic closeness computed by comparing vector representations of texts. "embedding-based similarity for text robustness and form filling"
- Element grounding: Associating textual references or tasks with the correct visual/UI elements on a page. "evaluates element grounding"
- Hint text: Short guidance shown near inputs or controls to clarify expected content or actions. "Hint text prediction."
- Layout robustness: A model’s ability to maintain performance when the UI structure or element positions change. "For layout robustness, we make small edits to the DOM"
- LoRA-based fine-tuning: Parameter-efficient adaptation of large models using Low-Rank Adaptation to improve specific skills. "LoRA-based fine-tuning yields substantial improvements"
- Multi-hop reasoning: Answering a question by chaining together multiple pieces of information across steps or sources. "Multi-hop reasoning, cross-document retrieval, image-text reasoning"
- Multimodal LLM (MLLM): A model that processes and reasons over multiple data types (e.g., text and images). "Multimodal LLMs (MLLMs)"
- Optical Character Recognition (OCR): Automatic extraction of text from images. "webpage OCR"
- Position relationship inference: Determining spatial relations among UI elements as a reasoning task. "position relationship inference"
- Position relationship reasoning: Inferring relative spatial positions (e.g., top-left, contain) between elements. "position relationship reasoning"
- Pre/post design: An evaluation setup where a model sees both the original and perturbed inputs under the same instruction. "we adopt a pre/post design"
- Safety critical detection: Identifying UI actions that could trigger irreversible or risky outcomes (e.g., deletion, payment). "safety critical detection"
- Semantic centroid: The central point in embedding space representing the average meaning of a set of texts. "closest to the semantic centroid"
- Self-contrast analysis: Comparing a model’s own predictions before and after perturbation to expose instability. "we incorporate a self-contrast analysis"
- Sensitivity index: A scalar that quantifies how strongly evaluation metrics respond to perturbations. "including the sensitivity index used for robustness analysis"
- Text robustness: Stability of a model’s predictions when textual content is perturbed without changing intent. "For text robustness, we apply content-preserving yet form-disruptive edits"
- TF-IDF: Term Frequency–Inverse Document Frequency; a weighting scheme to assess term importance in documents. "TF-IDF with cosine similarity"
- UI group: A functional region in a webpage layout (e.g., top bar, sidebar) that organizes related elements. "UI group. User interface (UI) group refers to the structural partitioning of a webpage"
Collections
Sign up for free to add this paper to one or more collections.

