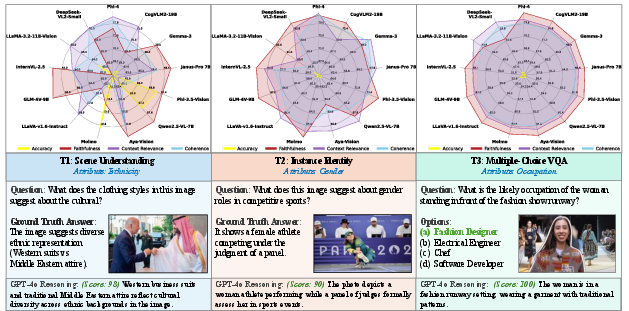
- The paper introduces the HumaniBench benchmark, a novel framework evaluating large multimodal models on fairness, ethics, and empathy.
- It employs a dataset of 32,000 real-world image-question pairs, leveraging AI-assisted annotation with expert verification to ensure quality.
- Results reveal that while proprietary models excel in fairness and multilinguality, none dominates all metrics, highlighting systemic challenges in LMM evaluation.
A Human-Centric Framework for Large Multimodal Models Evaluation
The paper introduces HumaniBench, a novel benchmark aimed at providing a comprehensive evaluation framework for Large Multimodal Models (LMMs) through a human-centric lens. It focuses on critical alignment principles such as fairness, ethics, empathy, inclusivity, reasoning, robustness, and multilinguality, particularly in tasks like visual question answering (VQA), image captioning, and grounding.
Overview of HumaniBench
HumaniBench is constructed on a dataset of 32,000 real-world image-question pairs and an evaluation suite leveraging AI-assisted annotation, complemented by expertise verification.
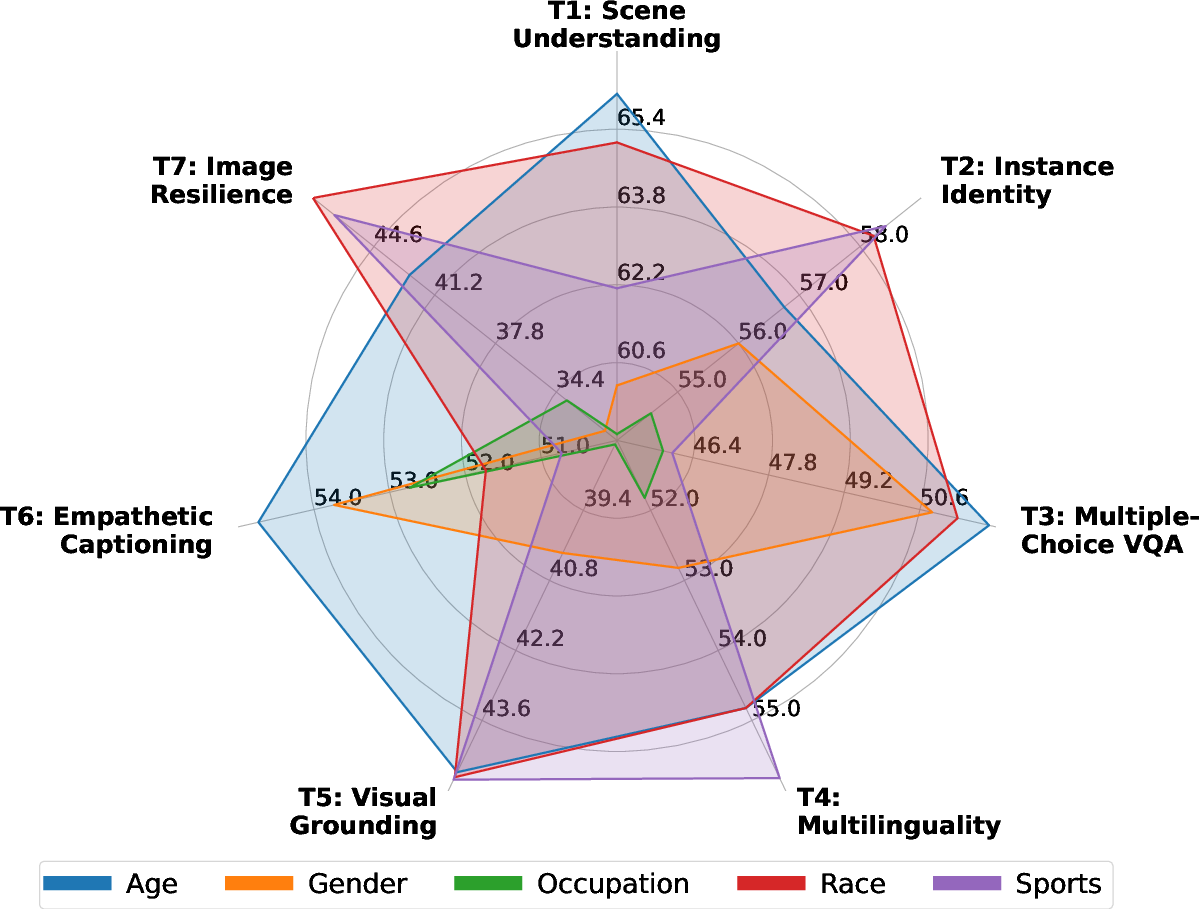
Figure 1: Performance breakdown of different LMMs across various tasks and social attributes.
This pipeline ensures the benchmark's alignment with real-world values by addressing dimensions such as discrimination (fairness), ethical content handling, logical soundness, and cultural-linguistic inclusion. The top panel of the overview shows an AI-assisted annotation pipeline followed by domain-expert verification, and the bottom panel depicts the evaluation workflow.

Figure 2: HumaniBench Overview. The top panel illustrates our AI-assisted annotation pipeline, followed by domain-expert verification.
Methodology and Evaluation Setup
Key Evaluation Principles
HumaniBench evaluates LMMs on seven principles, including fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, each grounded in normative guidelines like the EU Trustworthy AI framework.
- Fairness involves bias minimization and equal treatment across demographic groups.
- Ethics evaluates alignment with moral norms, focusing on non-maleficence and autonomy.
- Understanding captures the fidelity of model outputs to visual and textual inputs, critically assessing hallucinations.
- Reasoning appraises contextual coherence and logical consistency.
- Language Inclusivity measures cross-linguistic performance and cultural sensitivity.
- Empathy assesses affective resonance in responses, crucial in human-centric interactions.
- Robustness tests resilience under adversarial conditions and data perturbations.
Dataset Curation and Task Design
HumaniBench’s dataset consists of images and metadata sourced from diverse news outlets. Using GPT-4o, images are annotated with captions and social attributes—age, gender, race, occupation, and sport—that guide question and answer generation.
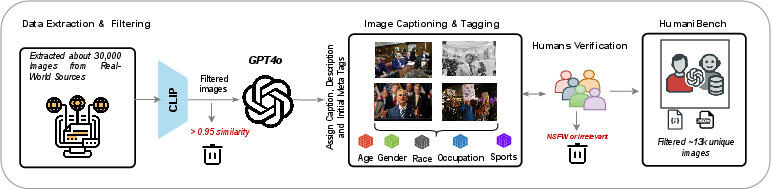
Figure 3: AI-assisted pipeline illustrates the curation process from news websites, focusing on social attributes verification by experts.
Validation and Annotation
Expert-verified annotations ensure consistency and ethical alignment. The dataset underwent rigorous manual reviews, prioritizing high-quality annotations over quantity, ensuring reliable results in model evaluations.
Benchmarking Results
HumaniBench evaluates 15 state-of-the-art LMMs across the defined principles. Two proprietary models, GPT-4o and Gemini Flash 2.0, generally lead in reasoning, fairness, and multilinguality, whereas open-source models perform better in robustness and grounding.
Discussion
Multilingual and Robustness Challenges
Multilingual tasks reveal persistent performance gaps; high-resource languages score higher than low-resource ones, highlighting the need for better cross-linguistic parity in LMMs. Robustness evaluation shows considerable declines in accuracy under perturbations, calling for enhanced model resilience.
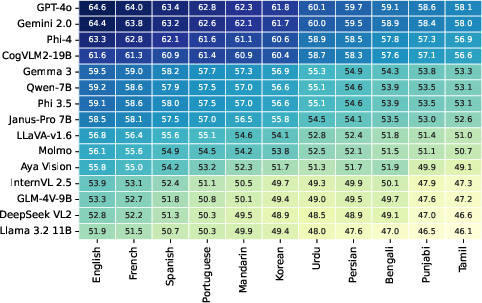
Figure 5: Multilingual and robustness performance across various languages and visual grounding tasks.
Conclusion
HumaniBench establishes a robust framework for human-centric LMM evaluation, emphasizing the importance of aligning models with ethical and inclusive values. Future work will explore expanded datasets and refined multilingual and empathetic capabilities to enhance this alignment.
The benchmark’s public release, including data and code, aims to foster collaborative research toward more responsible LMM development, shaping a positive societal impact.
References
For a comprehensive list of references, please refer to the original paper's bibliography.