- The paper introduces a novel reference-free framework using pixel-level visual grounding to verify and detect hallucinations in MLLMs.
- It employs the 'Verification by Vision Back' mechanism and R-Instruct data to align generated responses with corresponding visual inputs.
- The framework, validated on R²-HalBench and POPE benchmarks, outperforms state-of-the-art methods in accurate multimodal hallucination detection.
Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Introduction
The paper "Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding" (2511.12140) addresses the persistent challenge of hallucination in Multimodal LLMs (MLLMs). Despite substantial advancements in cross-modal understanding, MLLMs often generate content that conflicts with visual inputs, undermining their reliability. To confront this, the authors propose a reference-free hallucination detection framework—termed Verification by Vision Back—that leverages a pixel-level grounding approach for backward verification, aligning generated responses with visual inputs without relying on external references.
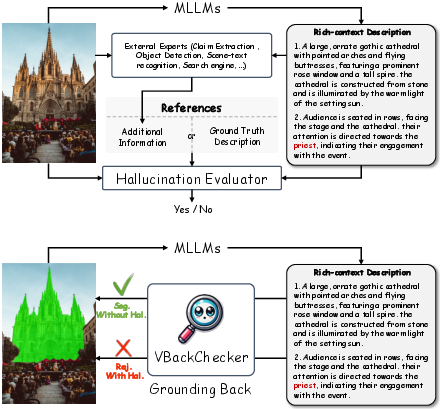
Figure 1: Illustration of our proposed VBackChecker framework highlighting its mechanism for detecting hallucinations in MLLMs.
Framework Overview
The core innovation lies in the Verification by Vision Back framework, which employs a pixel-level Grounding LLM equipped with reasoning and referring segmentation capabilities to verify the consistency of MLLM-generated responses. The method is predicated on the principle that visual grounding can effectively identify and interpret hallucinations without external validation. The framework operates by assessing whether generated descriptions can be accurately mapped back to corresponding elements in the visual input. Successful grounding indicates hallucination-free content, while a lack thereof signals discrepancies.
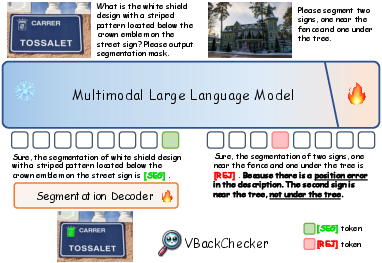
Figure 2: The framework of our proposed VBackChecker model indicating its operational processes for hallucination detection.
To support this capability, the authors introduce Rich-context Instruct Tuning data (R-Instruct), generated through an automated pipeline. This data comprises rich-context descriptions, grounding masks, and challenging negative samples, enabling the model to learn complex grounding tasks efficiently.
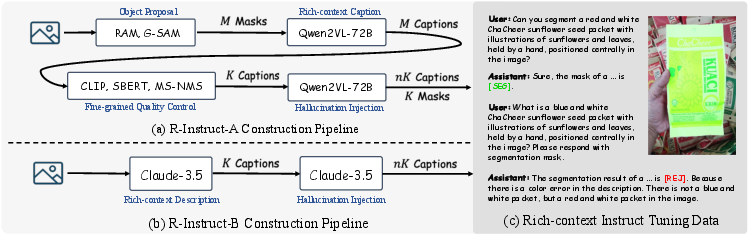
Figure 3: The Generation Pipeline of Rich-Context Instruct Tuning Data showcasing the creation of rich-context descriptions.
Methodology
The paper outlines the pixel-level grounding process facilitated by the VBackChecker framework. The model predicts either a [SEG] token for consistent, non-hallucinated content or a [REJ] token with explanations for detected hallucinations, offering interpretable outputs in both visual and language modalities. The grounding loss is optimized using Binary Cross-Entropy and DICE Loss, enhancing the rejection capabilities for rich-context queries. Further refinements in learning are achieved by placing emphasis on key decision tokens during training, ensuring the framework's robust performance across varied contexts.
Benchmark and Evaluation
A new benchmark, R²-HalBench, is established to enable rigorous evaluation of hallucination detection methods. It encompasses diverse, real-world MLLM outputs, rich-context descriptions, and detailed annotations across object-, attribute-, and relation-level hallucinations. Comparative analysis with state-of-the-art methods demonstrates that VBackChecker surpasses existing approaches in both pixel-level grounding accuracy and hallucination detection capability, showcasing a significant reduction in detected errors in real-world scenarios.

Figure 4: A comprehensive analysis of R²-HalBench, which details the model's evaluation across multiple dimensions.

Figure 5: Samples of R²-HalBench highlighting rich-context descriptions and corresponding hallucination categories.
Furthermore, VBackChecker demonstrates superior accuracy in challenging benchmarks like POPE, affirming its efficacy as a reliable multimodal hallucination checker.

Figure 6: Visualization of VBackChecker's output tokens illustrating accurate hallucination detection.
Conclusion
The work provides a significant contribution to multimodal hallucination detection by introducing a versatile, interpretable, and efficient framework that does not rely on external references. The establishment of a robust benchmark, coupled with strong empirical results, positions VBackChecker as a pivotal step forward in enhancing the reliability of MLLMs across practical applications. Future research may explore further optimizations in grounding capabilities and extend the framework to broader multimodal tasks, potentially setting new standards in AI reliability and interpretability.