AA-Omniscience: Evaluating Cross-Domain Knowledge Reliability in Large Language Models
Abstract: Existing LLM evaluations primarily measure general capabilities, yet reliable use of these models across a range of domains demands factual accuracy and recognition of knowledge gaps. We introduce AA-Omniscience, a benchmark designed to measure both factual recall and knowledge calibration across 6,000 questions. Questions are derived from authoritative academic and industry sources, and cover 42 economically relevant topics within six different domains. The evaluation measures a model's Omniscience Index, a bounded metric (-100 to 100) measuring factual recall that jointly penalizes hallucinations and rewards abstention when uncertain, with 0 equating to a model that answers questions correctly as much as it does incorrectly. Among evaluated models, Claude 4.1 Opus attains the highest score (4.8), making it one of only three models to score above zero. These results reveal persistent factuality and calibration weaknesses across frontier models. Performance also varies by domain, with the models from three different research labs leading across the six domains. This performance variability suggests models should be chosen according to the demands of the use case rather than general performance for tasks where knowledge is important.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new test, called AA-Omniscience, to check how trustworthy LLMs are when answering factual questions across many real-world subjects. It doesn’t just measure how often a model is right—it also measures whether the model knows when it doesn’t know and should say “I’m not sure.” The main score, the Omniscience Index, rewards correct answers and penalizes wrong guesses, while giving neutral credit if the model abstains when uncertain.
What questions did the researchers ask?
The researchers focused on simple, important ideas:
- Do LLMs remember facts well across many areas like business, law, health, and science?
- Can models avoid “hallucinating” (making up wrong facts) by admitting uncertainty?
- Which models are most reliable for knowledge-heavy tasks, and does this vary by domain (subject area)?
- Does a model’s general intelligence, size, and cost predict how trustworthy its factual answers are?
How did they do the study?
Here’s how they built and ran the test, explained in everyday terms:
Building the question set
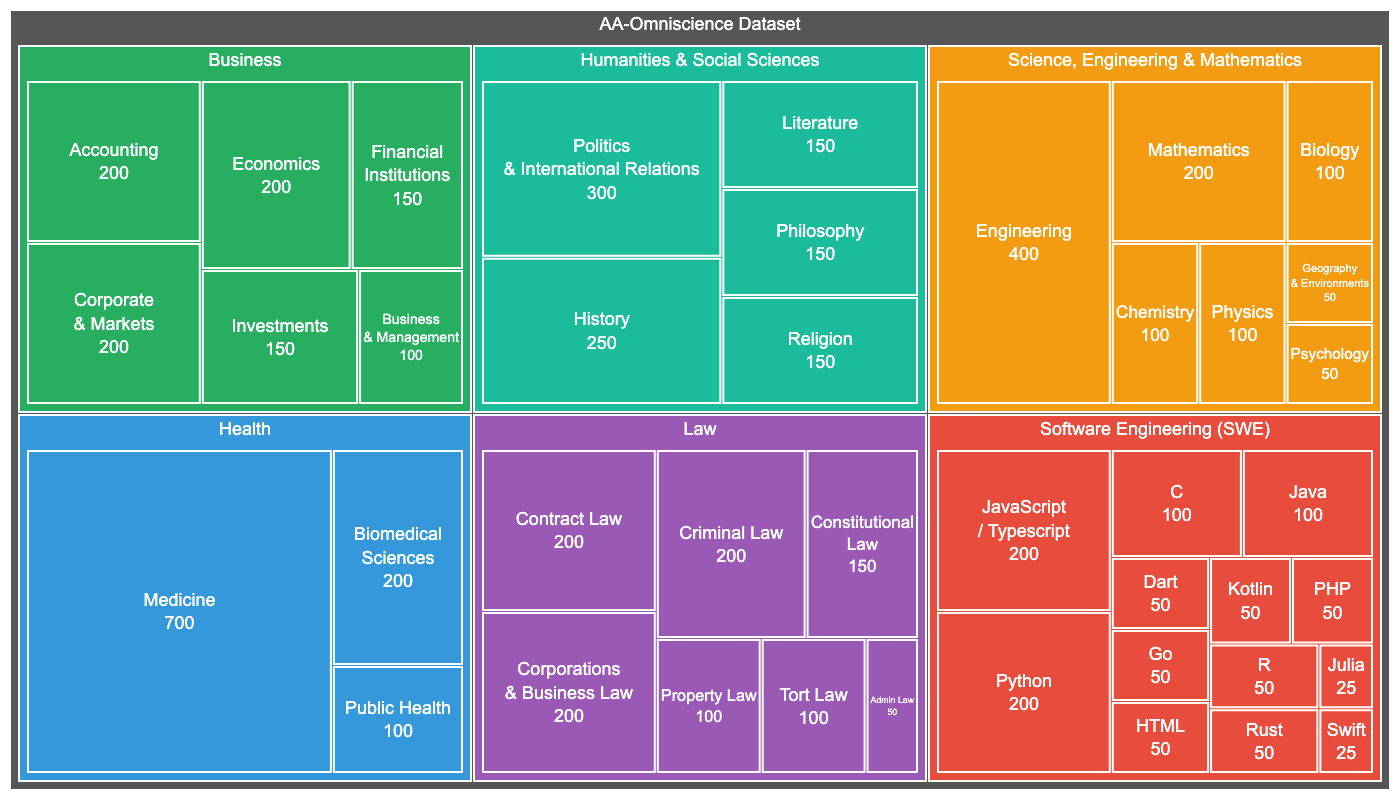
- The test includes 6,000 questions across 6 domains and 42 topics that matter to real jobs and industries (for example, Business, Law, Health, Software Engineering, and STEM).
- Questions come from reliable, up-to-date sources like official documents and respected publications.
- An automated “question generation agent” creates and improves questions to make sure they are:
- Difficult enough to challenge expert-level knowledge.
- Clear (unambiguous) with one correct answer.
- Precise (answers are short: names, numbers, dates).
- About the topic itself, not obscure details like page numbers.
How models answered and were graded
- Models got no extra tools (like web search) and no extra context—only the question—so the test measured their built-in knowledge.
- Before answering, models were told it’s better to abstain than to guess wrong.
- An independent grader model (Gemini 2.5 Flash Preview with reasoning) marked answers as:
- Correct
- Partially correct
- Incorrect
- Not attempted (e.g., “I don’t know”)
The score they used: Omniscience Index
Think of the Omniscience Index (OI) like a school test where:
- You gain points for correct answers.
- You lose the same amount of points for wrong answers.
- You get zero points for leaving a question blank when you don’t know.
In simple form:
- OI goes from −100 to 100.
- 100 means always correct.
- 0 means either you balanced correct and incorrect answers, or you abstained from everything.
- Negative scores mean you gave more wrong answers than right ones.
The exact formula is:
They also looked at:
- Accuracy: the percent of questions answered correctly.
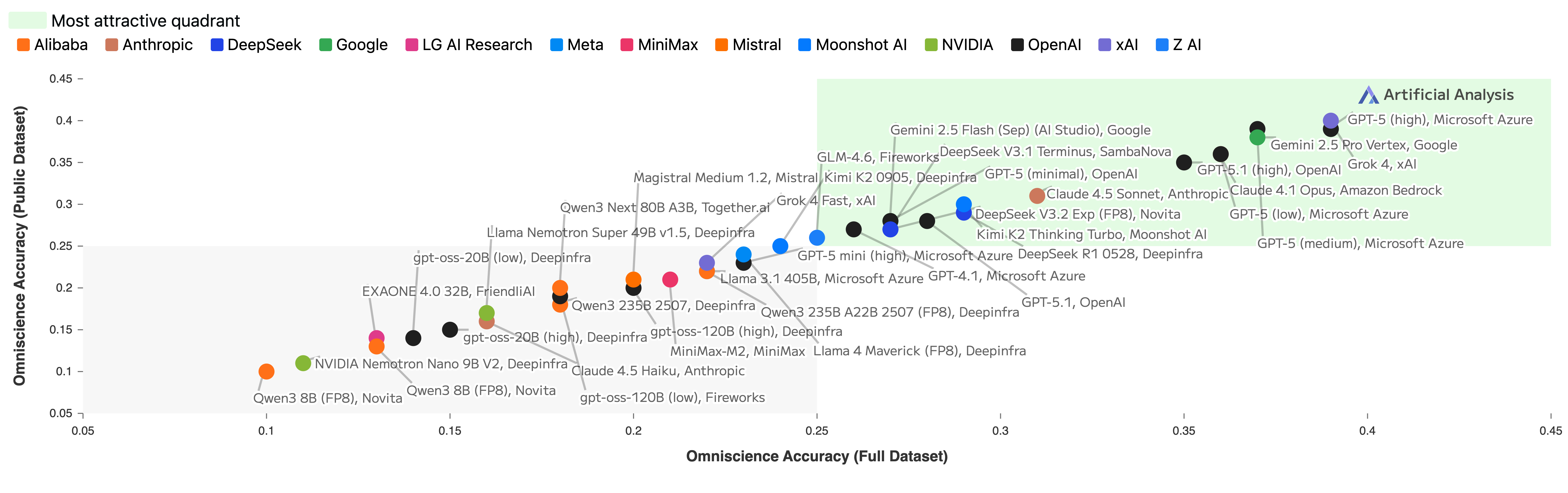
- Hallucination rate: how often a model gives a wrong answer instead of a partial answer or saying it doesn’t know.
- Cost to run: how much money it costs (in tokens/compute) to complete the whole test.
What did they find?
Here are the main results and why they matter:
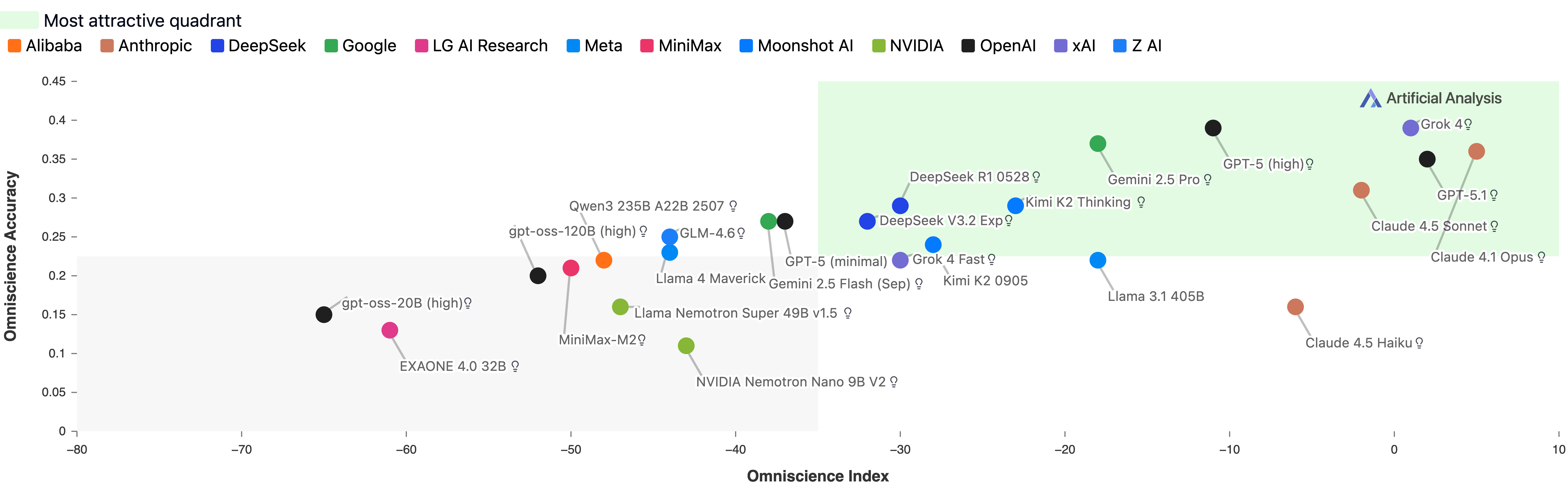
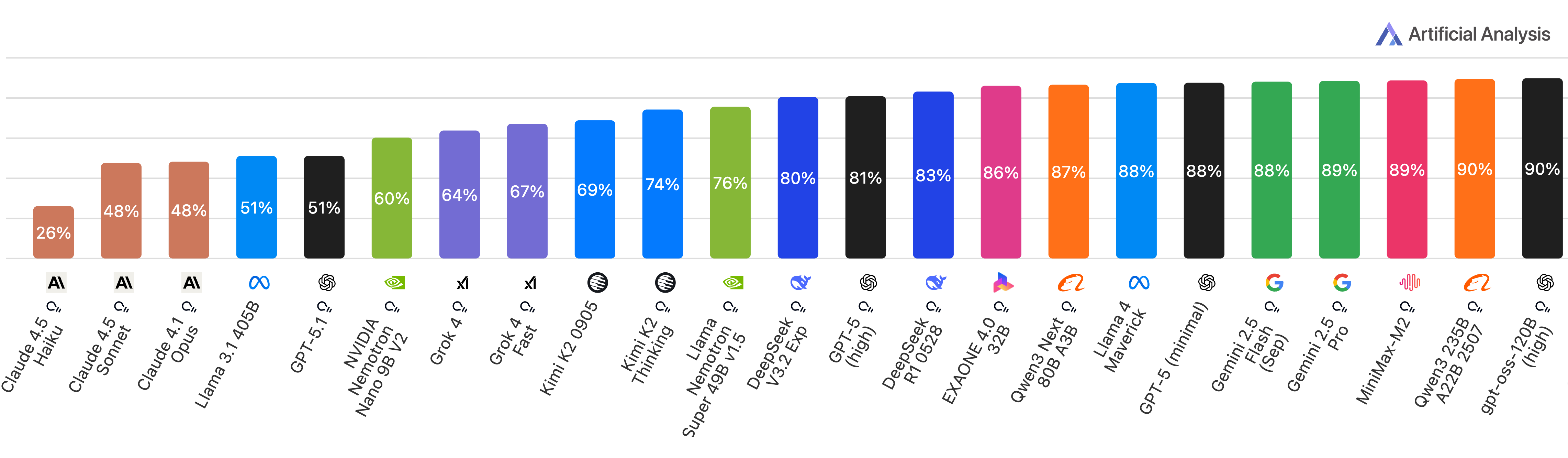
- Most models struggled to be reliably factual. Only three models scored above 0 on the Omniscience Index.
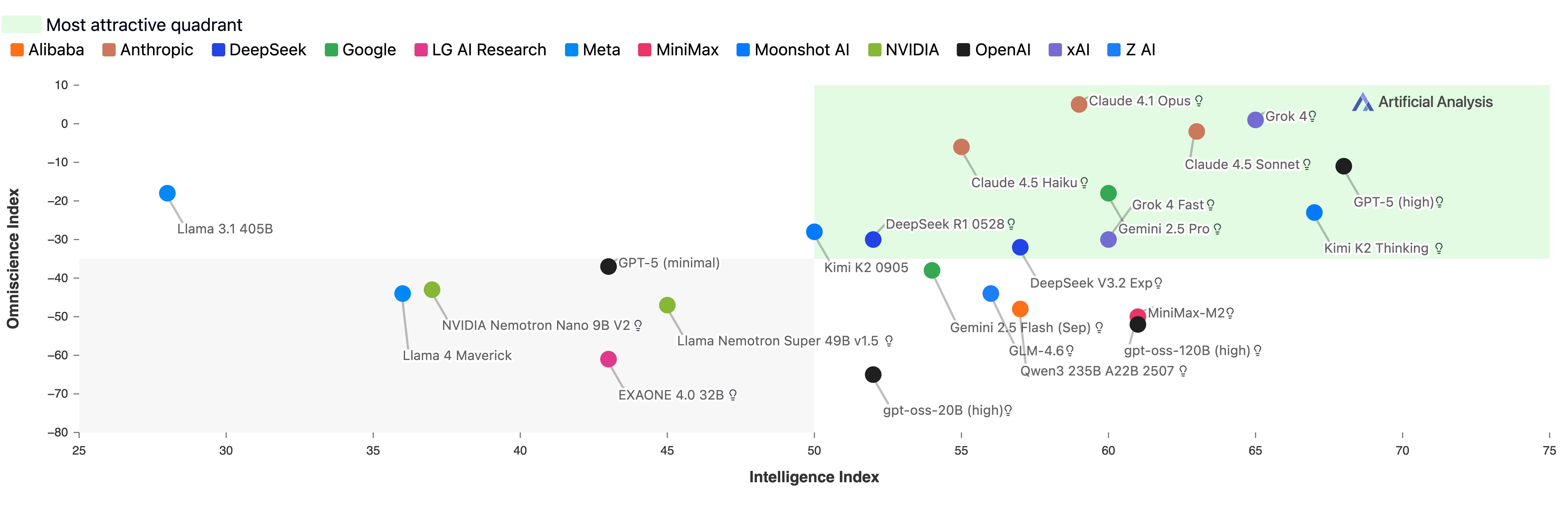
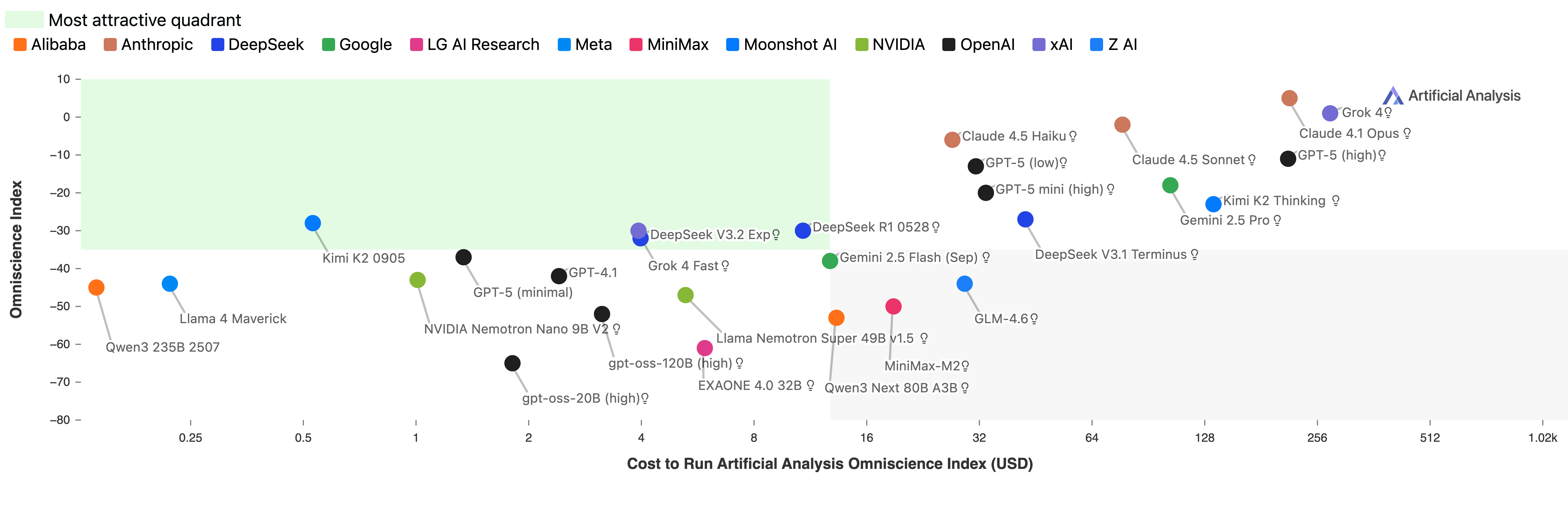
- Claude 4.1 Opus had the best overall reliability with an OI of 4.8. It wasn’t the most accurate, but it avoided guessing wrong more than others.
- High accuracy alone didn’t mean high reliability. For example, some models like Grok 4 and GPT-5 (high) were very accurate, but they also hallucinated a lot—so their reliability score was dragged down.
- Models fell into four rough “types”:
- Higher knowledge, higher reliability: decent accuracy and good at knowing when not to guess (e.g., Claude 4.1 Opus, GPT-5.1, Grok 4).
- Lower knowledge, higher reliability: not super accurate but rarely hallucinate (e.g., Claude 4.5 Haiku, Llama 3.1 405B). These are good for workflows where a model should hand off uncertain questions to tools.
- Higher knowledge, lower reliability: know a lot but still guess wrongly too often.
- Lower knowledge, lower reliability: weak accuracy and lots of wrong guesses.
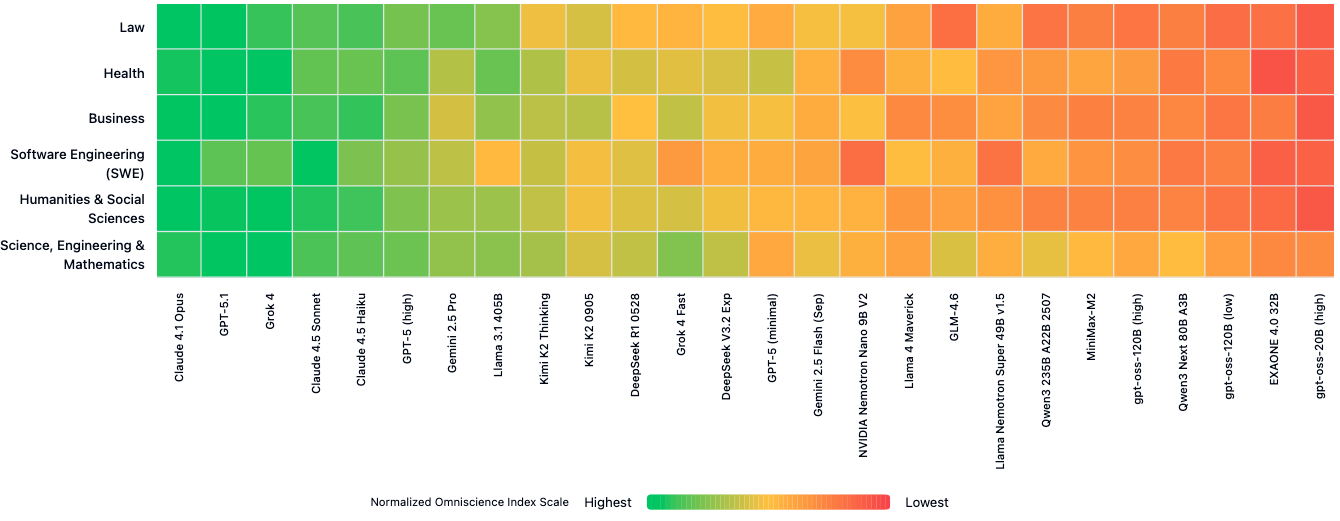
- Domain strengths differ:
- Claude 4.1 Opus led in Law, Software Engineering, and Humanities/Social Sciences.
- GPT-5.1 led in Business.
- Grok 4 led in Health and STEM.
- This means the “best” model depends on the subject you care about.
- General intelligence scores didn’t predict factual reliability. Some “smart” models hallucinated more. Meanwhile, Llama 3.1 405B did well on reliability even if others beat it on general benchmarks.
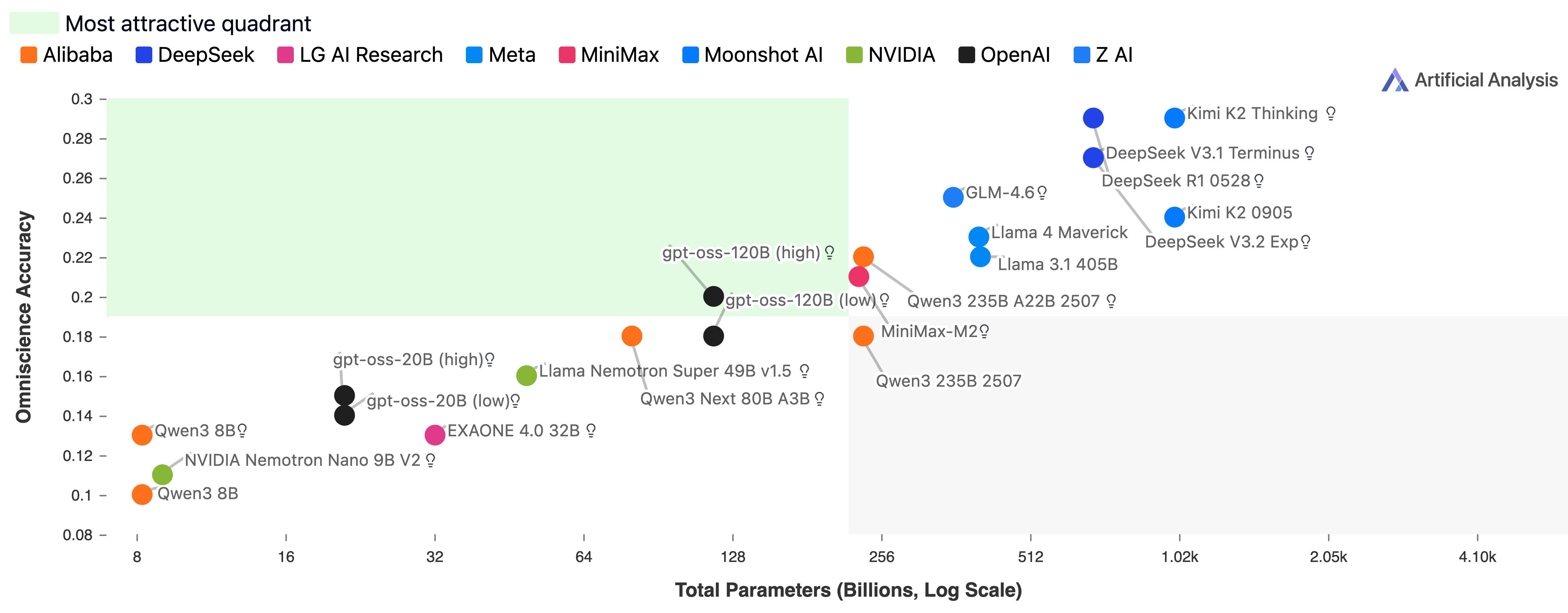
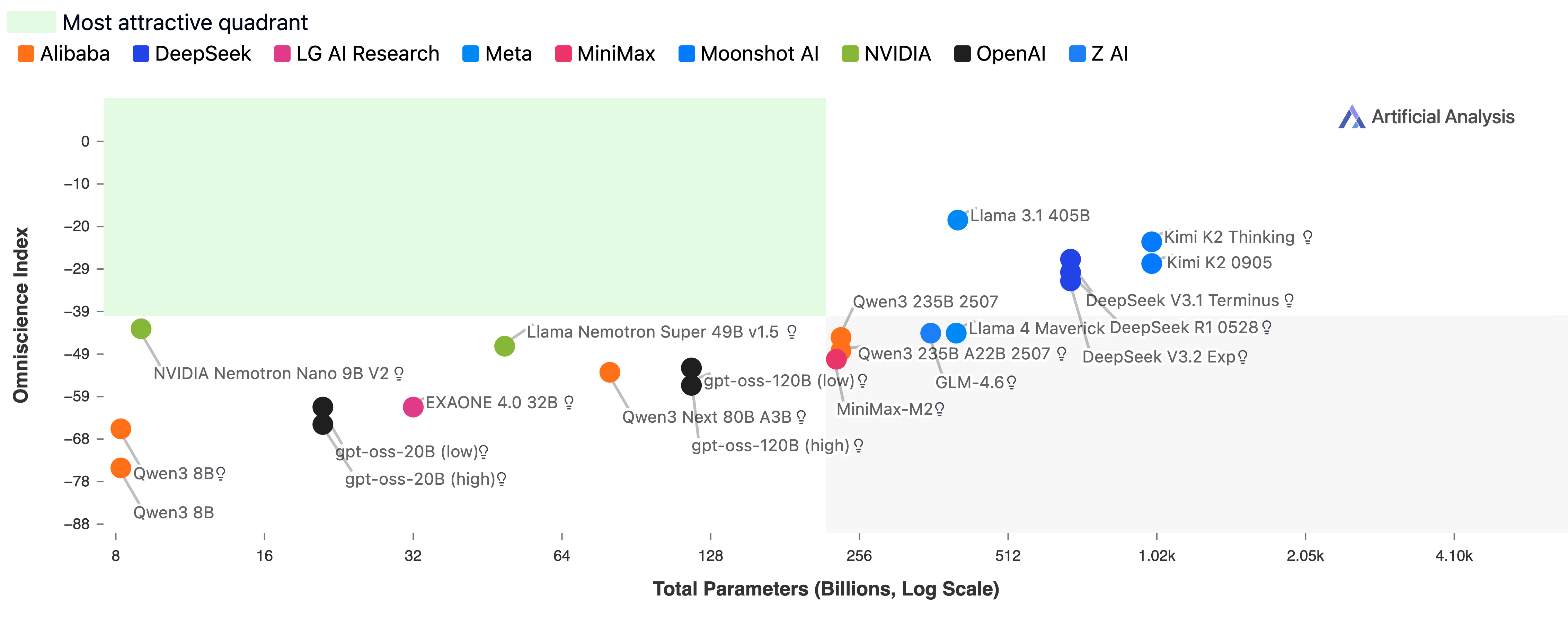
- Bigger models were generally more accurate, but not always more reliable. Some smaller models (like NVIDIA Nemotron Nano 9B V2 and Llama Nemotron Super 49B v1.5) punched above their weight on reliability.
- Cost matters. Better reliability often costs more to run. However, some models like Claude 4.5 Haiku delivered good reliability at a lower cost compared to pricier models.
Why does this matter?
In real life, giving a wrong answer confidently can be worse than admitting you don’t know—especially in fields like law, health, or engineering. This benchmark helps companies and researchers pick models that not only know facts but also avoid harmful mistakes. It shows that:
- You shouldn’t choose a model just because it’s “smart” in general.
- You should choose based on the specific domain and whether the model is well-calibrated (knows its limits).
- You should balance reliability with cost.
Limitations and future improvements
- The questions are in English and often based on US/UK sources, which may not cover other languages or regions well.
- The question generator uses a single model (GPT-5), which could introduce bias. Future versions may use multiple models to reduce that risk.
- The main score treats total abstention (never answering) as 0, which could rank a super-cautious model reasonably high compared to many wrong-guessing models. The authors consider tuning this penalty in future work.
Bottom line
AA-Omniscience is a new, practical way to judge LLMs by both what they know and how wisely they act when they don’t. It shows that reliable factual performance varies by model and by domain, and that avoiding hallucinations is just as important as being accurate. If you need trustworthy answers, pick your model based on the specific subject area and how well it avoids guessing wrong—not just on how “intelligent” it seems overall.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains uncertain, missing, or unexplored in the paper, framed to guide concrete future research and benchmark improvements.
- Geographic and linguistic scope: All questions are English and heavily sourced from US/UK contexts; quantify and expand non‑English, non‑Western sources, and evaluate cross‑lingual reliability and calibration.
- Reproducibility and versioning: The benchmark is “continuously updated” online; provide immutable versioned releases, changelogs, and archived model versions/prompts to support longitudinal comparability.
- Public availability and licensing: Only a public subset is released; specify what proportion is public, release full datasets where legally feasible, and document source licensing/compliance for derived questions.
- Grader reliability and bias: A single automated grader (Gemini 2.5 Flash Preview) is used; report inter‑rater agreement against human experts, cross‑validate with multiple grader models, and quantify grader–model family bias.
- Human adjudication: Provide a statistically powered human audit (e.g., stratified by domain and error type), with inter‑annotator agreement (Cohen’s kappa) and an error taxonomy for grading mistakes.
- Prompt sensitivity: Results rest on one answerer prompt; test robustness to alternative abstention prompts, output formatting instructions, and decoding settings (temperature/top‑p), reporting variance and confidence intervals.
- Determinism and runs: Only one full pass is used; expand the 10× repetition analysis beyond a “sample of models,” publish per‑model run variance, and report confidence intervals for all metrics.
- Metric definitional clarity: The hallucination rate formula i/(p+i+a) conflicts with its textual description (“proportion of questions it attempted to answer when unable to get correct”); clarify intent and correct denominator(s), e.g., i/(p+i) or i/(c+p+i), and provide sensitivity analyses.
- Treatment of PARTIAL answers: OI treats partial answers as neutral (same as abstentions) despite different practical value; analyze outcomes under alternative weightings (e.g., 0.25–0.75), and report how rankings change.
- Penalty calibration in OI: Only p=1 is studied; provide sensitivity curves for p∈[0.25,1.5], include selective risk–coverage metrics (AURC), and show robustness of conclusions to penalty choice.
- Coverage–risk trade‑offs: OI collapses coverage into a single scalar; add selective prediction curves (risk vs coverage) and report optimal operating points for different application risk profiles.
- Confidence calibration: Models are not asked to report confidence; collect calibrated confidence scores or percentile self‑ratings, compute ECE/Brier scores, and relate them to abstention behavior.
- “Refuse‑all” behavior: OI=0 equals “refuse all”; quantify the risk of strategic abstention, audit “false abstentions” (cases where the model knows but abstains), and add penalties or constraints to discourage trivial strategies.
- Domain weighting and dataset balance: Report exact per‑domain and per‑category question counts used in overall scores; assess whether uneven domain frequencies bias the aggregate OI and consider macro‑averaging.
- Normalization method transparency: The domain heatmap is “normalized” without formula; publish normalization equations and explore alternative normalizations (z‑score, min‑max, rank).
- Dataset construction bias: Difficulty filtering uses frontier model performance; evaluate risk of overfitting benchmark content to specific model idiosyncrasies and test on holdout domains not used for filtering.
- Residual ambiguity and source reliance: Automated revisions “ensure” unambiguity, yet no quantitative audit is provided; release an ambiguity/error audit and examples of borderline cases rejected/accepted.
- Contamination assessment: Because questions draw from widely available authoritative sources, assess training‑data overlap for evaluated models and quantify contamination effects on scores.
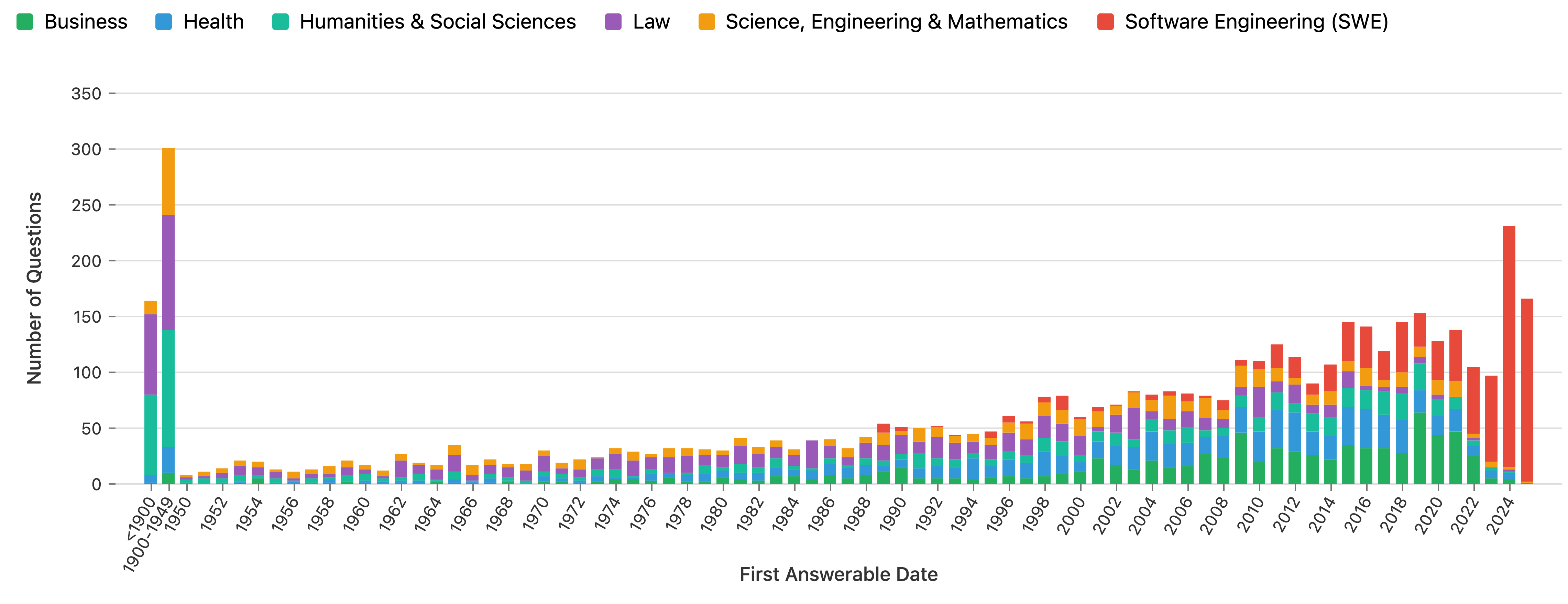
- Recency bias and cutoffs: The benchmark favors recent “first answerable” dates; publish full recency distributions by domain, and analyze performance as a function of source recency and model data cutoffs.
- External validity to tool‑use: The evaluation forbids tools/retrieval; add a parallel retrieval‑augmented track to measure knowledge+calibration under realistic tool pipelines and compare against parametric‑only scores.
- Multimodal realism: Many domains (e.g., health, engineering) require charts, code outputs, or figures; extend to multimodal Q&A and assess whether text‑only results transfer.
- Cost metric completeness: “Cost to run” excludes latency and throughput; add latency distributions, tokens/sec, and cost‑per‑correct (and cost‑per‑OI‑point), normalized for adherence to “answer‑only” formatting.
- Output normalization: Some models ignore “JUST the answer”; document normalization steps (unit handling, punctuation, casing) and quantify grading changes with/without normalization.
- Error analysis depth: Provide a fine‑grained taxonomy of errors (e.g., unit mistakes, temporal drift, acronym expansion, legal citation errors), per domain, with representative examples and actionable remediation hints.
- Domain drivers of variance: Investigate why different labs lead in different domains (e.g., training data composition, RLHF style, reasoning depth); correlate domain performance with public pretraining signals.
- Statistical significance: Report pairwise statistical tests (e.g., bootstrap on questions) for model ranking differences overall and per domain to avoid over‑interpreting small gaps.
- Open‑weights comparability: Parameter–accuracy associations are shown only for open‑weights models; add analogous analyses for closed models using proxy size estimates or compute budgets.
- Handling of hedged attempts: Clarify how “I’m not certain but…” answers with a guess are classified; standardize rules and test grader sensitivity to hedging language.
- Benchmark governance: Specify update cadence, deprecation policy, and how backward compatibility and model re‑tests are handled when the dataset changes.
- Editorial artifacts: The text contains placeholder artifacts (e.g., “{paper_content}” in domain names); audit and correct the released documentation and metadata to prevent downstream confusion.
- Law‑specific exceptions: Legal questions “may” rely on specific section references; document how jurisdictional variations and updates (amendments, overrulings) are tracked and versioned.
- Real‑world impact correlation: Validate whether OI predicts downstream task performance (e.g., legal drafting accuracy, code change correctness, clinical info accuracy) in human‑rated studies.
- Security and adversarial robustness: Assess robustness to adversarially phrased questions, distractors, and near‑duplicate traps, and report differential impacts on hallucination vs abstention.
- Ethical/risk weighting: Explore domain‑risk‑weighted metrics (e.g., larger penalties for incorrect medical/legal answers) and examine how rankings shift under safety‑aware scoring.
- Question generation transparency: Release the question‑generation prompts/workflow, filtering criteria thresholds, and duplicate‑elimination process to enable independent reproduction and critique.
- Vendor accounting consistency: Reasoning token accounting varies by provider; document token measurement methodology and cross‑vendor harmonization to ensure cost comparability.
- Model list completeness: Clarify inclusion criteria for the 36 models, coverage of major labs, and whether fine‑tuned domain models were excluded; invite community submissions with standardized run protocols.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, drawing directly from AA-Omniscience’s benchmark design, findings, and metrics.
- Model routing by domain for enterprise workloads (industry: legal, healthcare, software, finance)
- What: Select different LLMs per domain based on AA-Omniscience’s domain heatmap (e.g., route legal Q&A to Claude 4.1 Opus; health queries to Grok 4).
- Tools/products/workflows: A “domain-aware model router” that consults per-domain Omniscience scores before dispatching requests.
- Dependencies/assumptions: Access to up-to-date AA-Omniscience domain results; task-domain mapping is correct; model versions remain stable.
- Calibration-first agent workflows that prefer abstention over guessing (industry: customer support, developer tooling; academia)
- What: Embed “answer-or-abstain” prompts and thresholds informed by the Omniscience Index and hallucination rate; trigger retrieval/tools or human review on abstentions.
- Tools/products/workflows: Orchestrators that downgrade to search/RAG when models signal uncertainty; human-in-the-loop queues triggered by abstention.
- Dependencies/assumptions: Prompt adherence to abstention instructions; reliable fallback tools or SMEs; latency/cost budget for fallbacks.
- Procurement and vendor evaluation with risk-weighted scoring (industry and government)
- What: Incorporate the Omniscience Index, hallucination rate, and domain breakdown into RFPs and vendor scorecards, rather than relying on raw accuracy or general intelligence benchmarks.
- Tools/products/workflows: Procurement checklists; standard evaluation templates with OI thresholds by domain.
- Dependencies/assumptions: Comparable test conditions across vendors; AA-Omniscience remains representative of target use cases.
- Cost-performance optimization dashboards (industry: FP&A for AI, platform teams)
- What: Use cost-to-run vs Omniscience Index trade-offs to select cost-efficient, reliable models for knowledge-heavy tasks (e.g., prefer Claude 4.5 Haiku in budget-constrained settings).
- Tools/products/workflows: Internal dashboards plotting OI against cost per request; autoscaling policies that switch models by task criticality and budget.
- Dependencies/assumptions: Stable pricing and token accounting; comparable verbosity settings across models.
- Internal knowledge reliability audits using the question-generation agent (industry; academia)
- What: Repurpose the automated question generation pipeline to create organization-specific factuality tests from authoritative internal documentation.
- Tools/products/workflows: “Omniscience CI” that regenerates and runs domain-relevant questions after doc updates; release gates for AI features.
- Dependencies/assumptions: Availability of authoritative internal sources; minimal bias in generation when shifting domains; reviewer bandwidth.
- Safer defaults in safety-critical settings via abstention gating (industry: healthcare, finance, energy)
- What: Enforce abstention or tool use when OI or domain reliability is below threshold; restrict free-form generation for regulated tasks.
- Tools/products/workflows: Policy rules that block direct answers for high-risk categories; automatic escalation to retrieval/checklists.
- Dependencies/assumptions: Clear risk taxonomy; auditing to verify abstentions occur; compliance sign-off.
- Product UX patterns for “I don’t know” and confidence signaling (industry; daily life tools)
- What: Add an “Abstain when unsure” mode and transparent uncertainty messaging aligned with AA-Omniscience’s calibration ethos.
- Tools/products/workflows: UI toggles; structured responses that separate “final answer” vs “abstained—need tools.”
- Dependencies/assumptions: User education; consistent model behavior under instruction; localization for non-English users.
- Curriculum and research baselines for factuality and calibration (academia)
- What: Use AA-Omniscience-Public to teach and study calibration, abstention, and cross-domain variability; benchmark new training methods or prompts.
- Tools/products/workflows: Course assignments; lab baselines; replication packages.
- Dependencies/assumptions: Continued public dataset availability; licensing alignment for classroom use.
- API governance and monitoring policies (industry; policy)
- What: Set policy thresholds on hallucination rate and Omniscience Index for production deployments; require domain-specific reliability evidence.
- Tools/products/workflows: SLOs/SQOs keyed to OI; automated alerts when release regressions exceed OI deltas.
- Dependencies/assumptions: Reliable continuous testing; policy acceptance by stakeholders.
- Developer copilots with calibration-aware fallbacks (industry: software)
- What: Use OI results for software engineering domain to route coding queries: direct answers only when confident; else open relevant docs/snippets.
- Tools/products/workflows: IDE plugins that detect uncertainty and auto-surface authoritative references.
- Dependencies/assumptions: High-quality authoritative docs; fast retrieval integration.
- Student and consumer guidance on model choice for study and research (education; daily life)
- What: Prefer models with lower hallucination rates for studying, citations, and fact-checking even if accuracy is modest.
- Tools/products/workflows: “Study mode” in apps favoring calibrated models; guidance in academic integrity policies.
- Dependencies/assumptions: Clear labeling of model reliability; user compliance.
- Benchmark-as-a-service for continuous model monitoring (industry; regulators)
- What: Use the continuously updated AA-Omniscience site as an external reference to track model drifts in knowledge reliability.
- Tools/products/workflows: Vendor monitoring feeds; quarterly reviews tied to model updates.
- Dependencies/assumptions: Ongoing maintenance and transparency of updates.
Long-Term Applications
These opportunities likely require further research, scaling, or standardization before broad deployment.
- Industry-standard certification for knowledge reliability (industry; policy)
- What: Formalize an OI-like standard with domain thresholds and audits; certification seals for sectors (e.g., legal-tech-ready, health-advice-restricted).
- Dependencies/assumptions: Multi-stakeholder consensus; robust third-party assessors; sector-specific test sets.
- Calibration-focused training objectives and architectures (industry; academia)
- What: Incorporate OI-inspired penalties into RLHF/RLAIF or supervised fine-tuning to discourage confident guessing; research architectures that natively abstain.
- Dependencies/assumptions: Access to training pipelines; evidence that OI-correlated rewards improve real tasks without overfitting.
- Multi-model, cost-aware ensembles driven by domain OI (industry: platform/AI infra)
- What: Dynamic mixtures-of-models that allocate queries using per-domain OI, hallucination rate, and cost under SLAs.
- Dependencies/assumptions: Reliable, low-latency routing; cross-vendor interoperability; billing observability.
- Sector-specific regulatory frameworks mandating abstention behavior in critical tasks (policy: healthcare, finance, energy, law)
- What: Require documented abstention triggers, logging of attempted vs abstained answers, and periodic OI audits for approved deployments.
- Dependencies/assumptions: Regulatory readiness; clear liability models; enforcement mechanisms.
- Insurance and risk pricing for AI outputs using OI (finance; insurance)
- What: Underwrite AI-assisted workflows with premiums calibrated to domain-specific hallucination rates and OI track records.
- Dependencies/assumptions: Actuarial evidence linking OI to loss events; standardized disclosures.
- Organizational “Omniscience CI/CD” platforms (industry; software)
- What: End-to-end systems that continuously generate domain questions from living knowledge bases, run evaluations, and gate model releases.
- Dependencies/assumptions: High-quality source curation; scalable question generation; change management integration.
- Global, multilingual expansion and cultural coverage (industry; academia; policy)
- What: Extend AA-Omniscience across languages and jurisdictions to support international deployments and public-sector procurement.
- Dependencies/assumptions: Multilingual authoritative sources; unbiased grading across languages; culturally aware question design.
- Freshness-aware knowledge governance using “first answerable date” (industry: media, software, finance)
- What: Prioritize updates and re-benchmarking when sources change; monitor decay in model performance as facts evolve.
- Dependencies/assumptions: Source change detection; time-stamped provenance; retraining or RAG refresh cycles.
- Education accreditation tied to model reliability thresholds (education; policy)
- What: Approve AI classroom tools only if they meet domain-specific OI minimums; integrate abstention pedagogy into curricula.
- Dependencies/assumptions: Consensus on thresholds; equitable access to compliant tools.
- Safety cases and assurance frameworks for AI systems (industry; regulators)
- What: Build safety cases where OI, hallucination rate, and refusal behavior become key evidence artifacts, especially for agentic systems.
- Dependencies/assumptions: Accepted safety engineering patterns for AI; standardized reporting formats.
- “Reliability layer” platforms for LLM apps (industry)
- What: Horizontal services that shape prompts for abstention, instrument predictions, log calibration signals, and provide per-domain reliability analytics.
- Dependencies/assumptions: Ecosystem adoption; integration into diverse app stacks; privacy/compliance.
- Data and source marketplaces powering authoritative question generation (industry: data providers)
- What: Curated pipelines and licenses for authoritative sources per sector to drive robust, up-to-date evaluations and training.
- Dependencies/assumptions: Source availability and licensing; provenance and quality controls.
Notes on feasibility across applications
- Core assumptions: AA-Omniscience remains representative for target domains; grading fidelity is sufficient; OI generalizes from short-form Q&A to broader task settings when paired with abstention prompts.
- Key dependencies: Access to authoritative sources; up-to-date domain results; model stability/versioning; operational maturity for fallbacks (search, RAG, human review).
- Limitations to plan for: English and geography-heavy bias in current dataset; single-model generation bias risks; OI’s harsh penalty design may need tuning for certain deployment contexts.
Glossary
- AA-LCR: An evaluation included in the Artificial Analysis Intelligence Index suite. "AA-LCR"
- AA-Omniscience: The benchmark introduced in the paper to assess factual recall and calibration across domains. "This paper introduces AA-Omniscience, a benchmark dataset designed to measure a model's ability to both recall factual information accurately across domains and correctly abstain when its knowledge is insufficient."
- AA-Omniscience-Public: The open-sourced subset of AA-Omniscience questions for public use. "AA-Omniscience, including an open-sourced public set of questions (AA-Omniscience-Public) to facilitate further evaluation of knowledge reliability."
- Abstention: A model’s choice to not answer when uncertain to avoid incorrect outputs. "benchmarks must go beyond testing answer correctness, and also measure model calibration and abstention behavior."
- AIME 2025: An evaluation included in the Artificial Analysis Intelligence Index. "AIME 2025"
- Artificial Analysis Intelligence Index: A composite index measuring overall LLM capability across multiple evaluations. "When compared with the Artificial Analysis Intelligence Index"
- Attempt rate: The proportion of questions a model chooses to answer in the evaluation. "Across all evaluated models, the lowest attempt rate was 42%"
- Bounded metric: A metric constrained to a fixed numerical range. "a bounded metric (-100 to 100)"
- Correct given attempt: A metric that scores correctness conditional on a model attempting an answer. "unlike metrics such as correct given attempt and F-score used by previous benchmarks"
- Cost to run: The total token-based cost (including reasoning tokens) to complete the benchmark. "We therefore supplement our performance metrics with cost to run, which is the total cost (USD) associated with the input and output tokens, including reasoning tokens, required for the target model to complete AA-Omniscience"
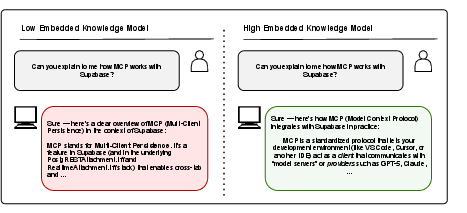
- Embedded knowledge: Knowledge stored in a model’s parameters independent of external tools. "embedded knowledge can be both competitive with, and a prerequisite for, effective tool use."
- F-score: A performance metric (harmonic mean of precision and recall) used by prior benchmarks. "correct given attempt and F-score"
- Few-shot prompts: Prompting with a small number of examples to guide generation. "generates questions using few-shot prompts with GPT-4"
- First answerable date: The earliest date when sufficient public information became available to answer a question. "We define first answerable date as the estimated month and year that the information required to answer the question was first publicly available"
- Frontier models: The most advanced, cutting-edge LLMs available. "frontier models still struggle to produce factual outputs reliably."
- Gold target: The reference answer against which predictions are graded. "Your job is to look at a question, a gold target, and a predicted answer"
- GPQA Diamond: An evaluation included in the Artificial Analysis Intelligence Index. "GPQA Diamond"
- Grading model: A model used to classify answers as correct, incorrect, partial, or not attempted. "A grading model is then used to classify each modelâs answer as either correct, partially correct, incorrect, or not answered"
- Hallucination: A confident but incorrect output from a model. "with metrics centered on overall correctness rather than hallucination or knowledge calibration."
- Hallucination rate: The proportion of attempted questions that are answered incorrectly. "we also report the hallucination rate, defined as the proportion of questions it attempted to answer when it was unable to get the answer correct."
- Humanity's Last Exam: An evaluation included in the Artificial Analysis Intelligence Index. "Humanity's Last Exam"
- IFBench: An evaluation included in the Artificial Analysis Intelligence Index. "IFBench"
- Knowledge calibration: A model’s ability to judge what it knows and abstain appropriately. "factual recall and knowledge calibration across 6,000 questions."
- LiveCodeBench: A coding evaluation included in the Artificial Analysis Intelligence Index. "LiveCodeBench"
- MMLU-Pro: A multitask language understanding evaluation included in the Artificial Analysis Intelligence Index. "MMLU-Pro"
- Miscalibration: A mismatch between model confidence and actual correctness. "Miscalibration also leads to inefficient tool use, as models may invoke tools unnecessarily and ignore them when needed."
- NOT_ATTEMPTED: A grading label for refusals or omissions when the model does not provide an answer. "assign a grade of either CORRECT, INCORRECT, PARTIAL_ANSWER, or NOT_ATTEMPTED."
- Omniscience Index (OI): The paper’s primary metric that rewards correct answers, penalizes incorrect ones, and allows abstention. "The evaluation measures a modelâs Omniscience Index, a bounded metric (-100 to 100) measuring factual recall that jointly penalizes hallucinations and rewards abstention when uncertain, with 0 equating to a model that answers questions correctly as much as it does incorrectly."
- Open weights models: Models whose parameter weights are publicly available. "Only open weights models are included."
- PARTIAL_ANSWER: A grading label for answers that are accurate but incomplete or at the wrong level of detail. "assign a grade of either CORRECT, INCORRECT, PARTIAL_ANSWER, or NOT_ATTEMPTED."
- Post-training: Training stages after initial pretraining, often involving alignment or fine-tuning. "reinforcing overconfidence during post-training."
- Question generation agent: An automated system that creates, filters, and revises benchmark questions. "The entire question set is developed, filtered, and revised using an automated question generation agent."
- Reasoning configurations: Model settings that affect reasoning behavior and verbosity. "due to differences in reasoning configurations and verbosity."
- Reasoning tokens: Tokens consumed by a model’s reasoning process, included in cost calculations. "including reasoning tokens"
- Refusal rate: The proportion of cases where the model declines to answer. "the highest model refusal rate was 58%"
- SciCode: A coding/scientific evaluation included in the Artificial Analysis Intelligence Index. "SciCode"
- Terminal-Bench Hard: A terminal-based evaluation included in the Artificial Analysis Intelligence Index. "Terminal-Bench Hard"
- Tool-use workflows: Workflows that rely on models to decide when to invoke external tools. "These models may be particularly suitable for tool-use workflows, where strong calibration enables efficient routing of queries to external tools."
- τ2-Bench Telecom: An evaluation included in the Artificial Analysis Intelligence Index. " -Bench Telecom."
Collections
Sign up for free to add this paper to one or more collections.