Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
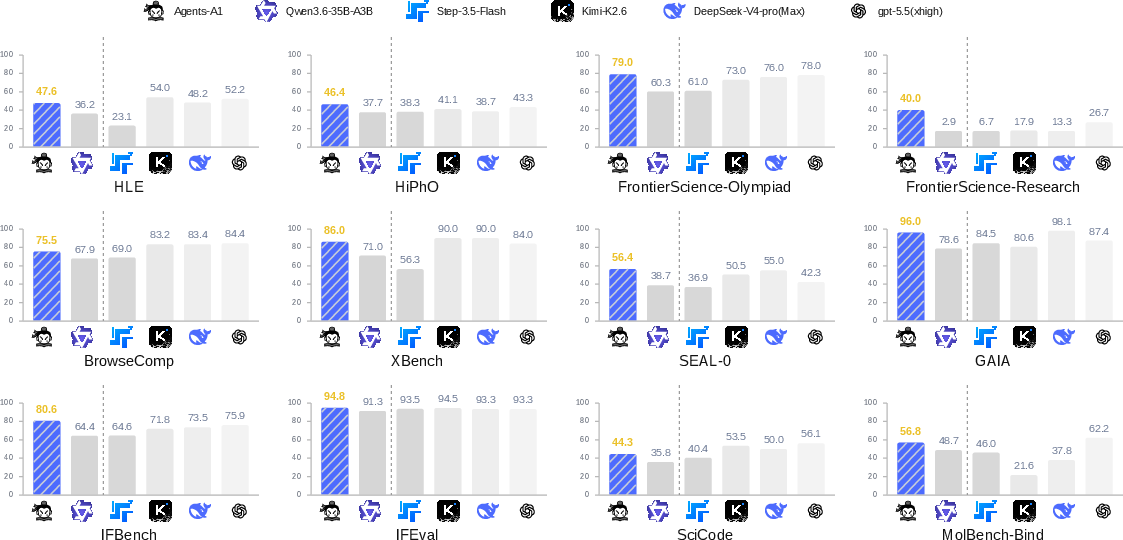
Abstract: We introduce Agents-A1, a 35B Mixture-of-Experts Agentic Model that reaches trillion-parameter-level performance by scaling the agent horizon. We investigate agent-horizon scaling from two perspectives: scaling long-horizon trajectories and scaling heterogeneous agent abilities. To support this goal, we build a long-horizon knowledge-action infrastructure that connects external knowledge, actions, observations, and verifier outcomes, producing agentic trajectories with an average length of 45K tokens. Based on this, we train Agents-A1 with a three-stage recipe. First, we perform full-domain supervised fine-tuning to align the base model with broad agentic behaviors. Second, we train domain-level teacher models to capture specialized expertise in each domain. Third, we propose a multi-teacher domain-routed on-policy distillation with salient vocabulary alignment to improve knowledge transfer efficiency across different domains, unifying six heterogeneous domains into one deployable student model. Agents-A1 achieves strong and broad performance for long-horizon agent benchmarks. Compared with 1T-parameter model such as Kimi-K2.6 and DeepSeek-V4-pro, Agents-A1 achieves leading results on SEAL-0 (56.4), IFBench (80.6), HiPhO (46.4), FrontierScience-Olympiad (79.0), and MolBench-Bind (56.8), and remains highly competitive on SciCode (44.3), HLE (47.6) and BrowseComp (75.5). We hope this work provides the community with a practical path for scaling the horizon using a 35B agent that can reach or match the performance of 1T models on long-horizon tasks.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Agents-A1, an AI “agent” that’s good at solving long, complicated tasks by planning many steps ahead and using tools like web search, code execution, and document reading. Instead of making the AI much bigger (with more parameters), the authors show you can make it much smarter at long tasks by improving how far it can plan and how well it learns from real actions and feedback. Their 35-billion-parameter model matches or beats the performance of some models with around a trillion parameters on tests that require long, careful reasoning.
The big questions the authors asked
- Can a smaller AI agent (35B) reach the performance of much larger ones (≈1T) on tasks that need many steps, planning, and tool use?
- What kind of training “world” (data and environment) does an AI need to really learn long, reliable decision-making?
- How can we combine many different skills (like searching the web, writing and running code, following strict instructions, doing science problems) into one model without the skills clashing?
How they did it (methods)
The authors’ approach has two main ideas: build the right practice world, then teach the model in three stages.
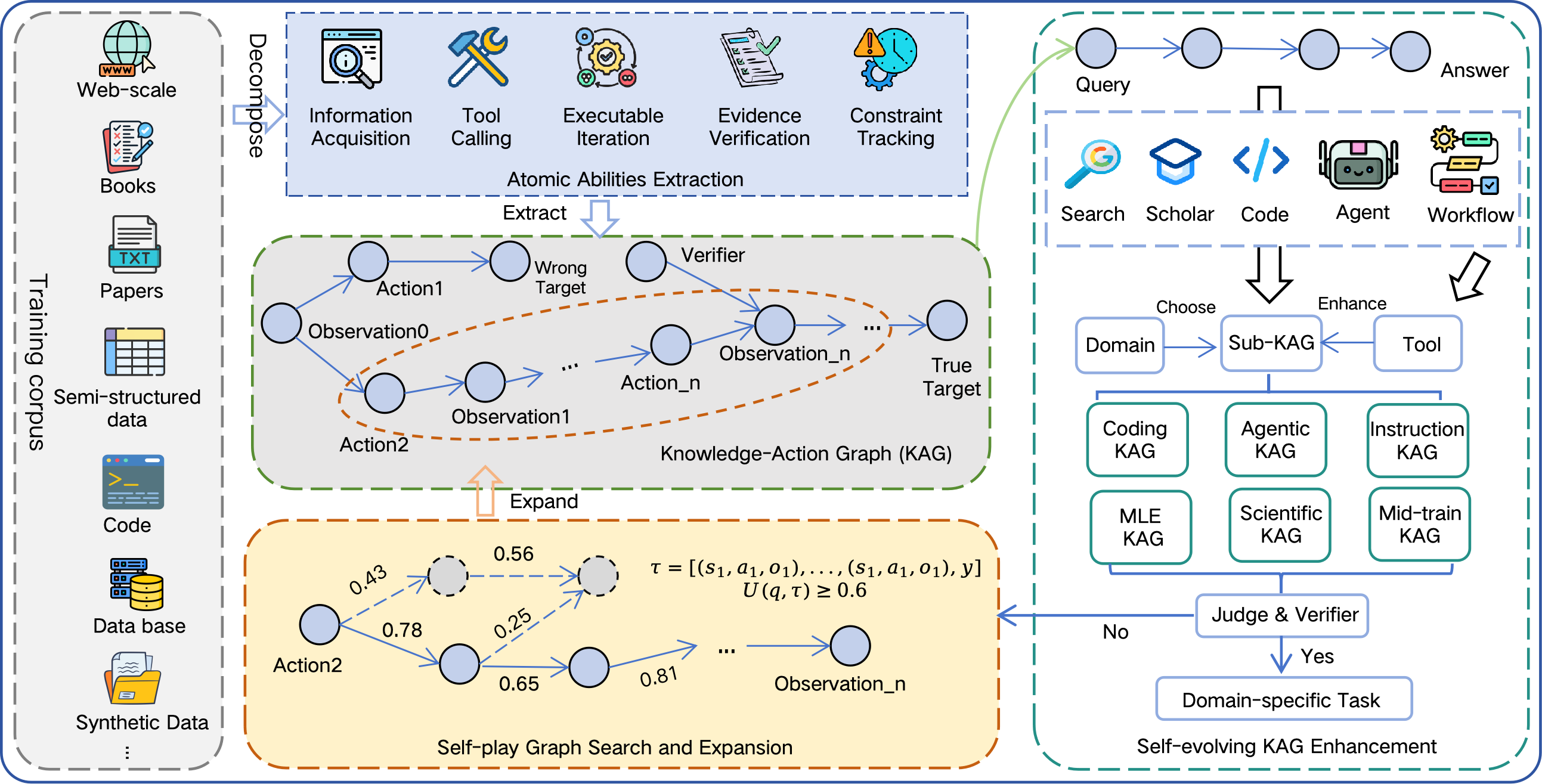
Building a “knowledge–action” world
The team created a training setup where the AI doesn’t just read text—it takes actions, observes what happens, and gets checked. Think of it like a detailed lab notebook or a game replay that records every step:
- What the agent knows so far (evidence it found)
- What action it took (searching, clicking a link, calling a tool, editing code)
- What it saw next (webpage content, tool output, error messages)
- Whether a “verifier” says the step or final answer is correct
They store this as a “Knowledge–Action Graph” (KAG). It’s like a map showing not only the final answer but the whole journey, including mistakes and fixes. This helps the agent learn how to plan, recover from errors, and verify evidence—skills that normal text datasets don’t teach well.
To make lots of good practice problems, they use a “proposer–solver–verifier” loop (self-play):
- A proposer creates tasks.
- A solver (the AI) tries to solve them using tools.
- A verifier checks if the steps and final answer are correct and non-cheaty (no shortcuts). Good tasks and solution paths are saved, bad ones are fixed or thrown out.
They build this for several domains, for example:
- Search over a wiki-like web graph to find answers via multi-hop links, keeping track of the pages and evidence used.
- Machine Learning Engineering (MLE): write, run, and improve code to get better scores on competitions, with a “tree” of code versions and results.
- Scientific reasoning: step-by-step math/physics reasoning, with and without tools (search, code, scholar).
- Instruction following: obey strict, checkable rules (format, length, language) and find answers in long documents while ignoring distractors.
- General tool calling: solve tasks by using a chain of compatible tools in the right order, with checks that the tools were used correctly.
In short, the KAG ensures the agent learns from realistic, verifiable, multi-step practice, not just final answers.
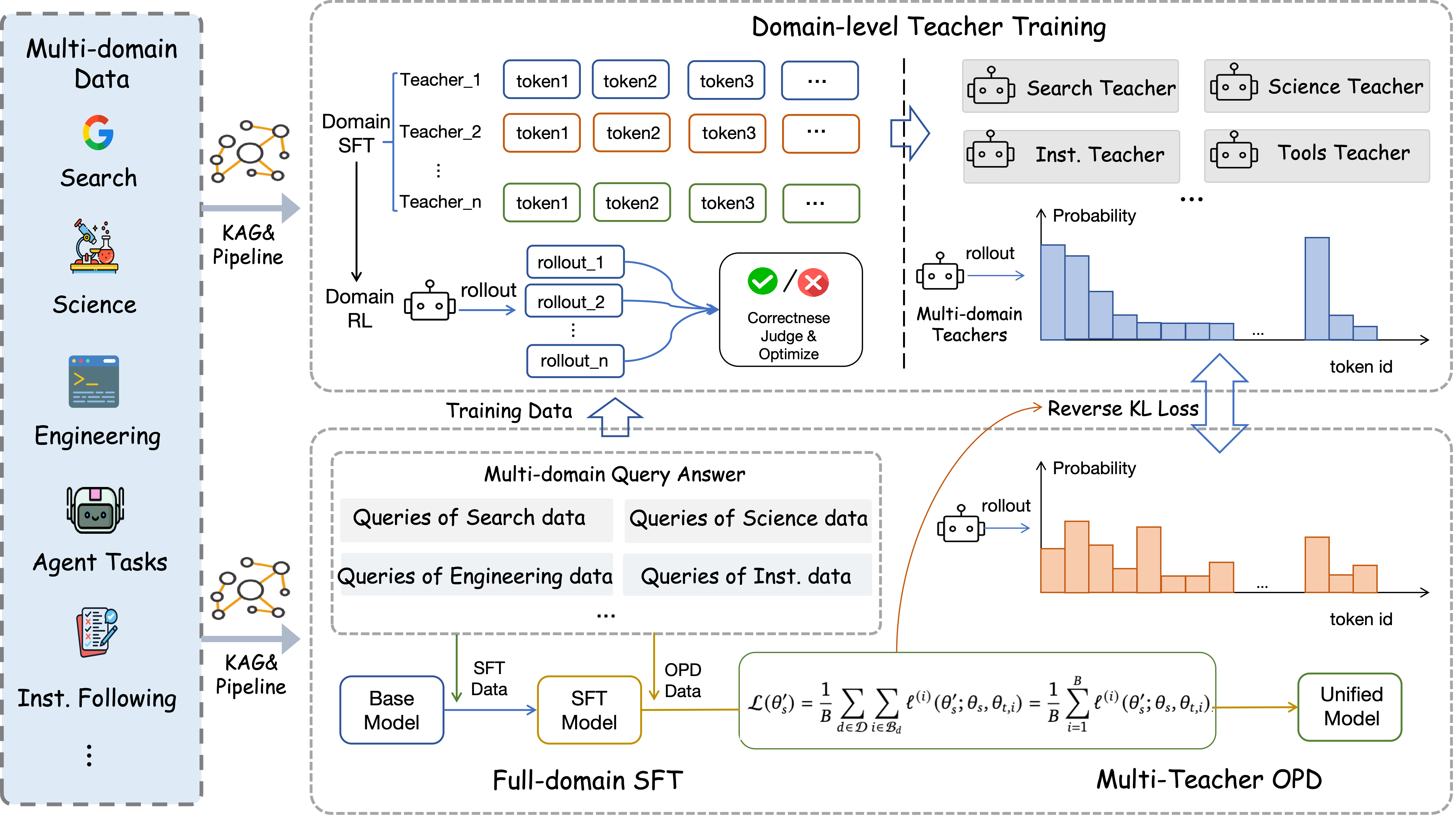
Training in three steps
The training recipe has three stages:
- Stage 1: Supervised fine-tuning (SFT) across all domains The model (a 35B Mixture-of-Experts model—think of it as a team of specialist mini-models) learns general “agent” behavior from many long trajectories (on average about 45,000 tokens each). It learns to plan, use tools, verify, and summarize.
- Stage 2: Train domain-specific “teacher” models For each domain (like web search or scientific reasoning), they specialize a teacher model. For example, the search teacher is further trained with reinforcement learning (RL), where the model gets rewards for correct answers and for efficient, non-repetitive searching.
- Stage 3: Combine the skills into one student (multi-teacher distillation)
- Domain routing: each training example is guided by the teacher from its own domain, so signals don’t conflict.
- Salient Vocabulary Alignment (SVA): instead of comparing the entire vocabulary at each step, the student focuses on the teacher’s most important likely next tokens (a “local shortlist”), making learning more stable and efficient.
- Balanced updates: they normalize training so no single domain overwhelms the others.
This three-step process unifies many different, sometimes clashing skills into one deployable agent.
What they found
Agents-A1, with just 35B parameters, achieves top or leading scores on several “long-horizon” benchmarks—tests that require many steps, tool use, and careful reasoning. It beats or matches some ≈1T-parameter models (like Kimi-K2.6 and DeepSeek-V4-pro) on:
- SEAL-0 (open-ended answer finding with evidence)
- IFBench (strict instruction following)
- HiPhO (reasoning)
- FrontierScience-Olympiad (challenging science problems)
- MolBench-Bind (molecular binding reasoning)
It also performs strongly on:
- SciCode (coding)
- HLE (human-like evaluation on complex tasks)
- BrowseComp (web browsing competition)
Why this matters: It shows that “thinking longer and better” (scaling the horizon) can rival “being bigger” (scaling parameters), especially for real-world tasks where you must plan, search, verify, and adapt.
Why it matters (implications)
- A practical path to powerful agents without massive size: Smaller models can reach big-model performance if trained to plan far ahead, use tools well, and learn from step-by-step, verifiable feedback.
- More accessible and cost-effective: Training and running a 35B model is far cheaper than a 1T model, lowering barriers for labs, startups, and researchers.
- Better real-world reliability: By grounding decisions in evidence and verification, the agent is more likely to stay accurate over long tasks and recover from mistakes.
- Broad, reusable foundation: The knowledge–action infrastructure and multi-teacher distillation recipe can be reused to add new domains, tools, or skills over time.
In simple terms: the authors show that teaching an AI how to plan carefully, use tools, and check its work—over long stretches—is a powerful alternative to just making it bigger. This could make advanced AI agents more affordable, reliable, and widely available.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of the main uncertainties and omissions that future work could address:
- MoE architecture and routing are unspecified (number of experts, layer placement, gating, load balancing), making it unclear how parameter- and compute-efficiency are achieved and how inference latency scales.
- Lack of ablations quantifying the contribution of each component (KAG infrastructure, SFT, domain-level teachers, RL on search, OPD, Salient Vocabulary Alignment) to overall gains.
- No sensitivity analysis for SVA hyperparameters (e.g., top‑k size, renormalization choices) or for the domain-normalized objective (e.g., domain weighting, batch composition).
- Domain routing at inference is undefined: how tasks are assigned to teachers or routed policies when domain labels are ambiguous or multi-domain, and how the system handles unseen domains.
- On-policy distillation may amplify student errors due to conditioning teachers on student prefixes; there is no analysis of error propagation or mitigation (e.g., hybrid off-policy targets).
- SVA monitors coverage ρ but does not use it for training control (e.g., regularization, adaptive k); how low coverage affects convergence and generalization remains open.
- Comparisons to 1T-parameter baselines lack details on evaluation parity (identical tools, prompts, context lengths, temperature, decoding, retriever quality) and do not report variance or statistical significance.
- Compute/latency/memory costs for training and inference with 45K–256K contexts and many tool calls are not reported; cost–performance trade-offs and energy efficiency are unknown.
- Long-horizon robustness is unmeasured beyond final accuracy (e.g., path correctness, recovery from early mistakes, compounding errors, and efficiency metrics like tool-call count and wall-clock time).
- KAG quality and verifier trustworthiness rely on LLM judges and automatic checks; calibration, bias, false positives/negatives, and susceptibility to reward hacking are not evaluated.
- Potential data contamination/leakage between KAG-derived data (e.g., Wikipedia/web content, MLE tasks) and evaluation benchmarks is not audited; overlap checks and decontamination protocols are missing.
- Tool-sandbox safety and isolation are under-specified (resource limits, network/FS access policies, side-effect containment, dependency control), posing reproducibility and security questions.
- Generalization to unseen or changing tools/APIs and web environments (dynamic content, cookie walls, anti-bot measures) is not studied; robustness to schema drift remains unclear.
- The “read_page” step relies on LLM summarization; the impact of summarizer quality and information loss on downstream performance is unquantified.
- Context management strategy (KV-cache policies, compaction/summarization criteria, retrieval vs. full-context usage) and its effect on accuracy over very long horizons are not detailed.
- Handling of tool failures (timeouts, malformed returns, partial data) and fallback policies (retries, backoff, degraded modes) at inference time are not specified.
- Cross-domain interference and negative transfer are not analyzed; whether domain-normalized aggregation prevents catastrophic forgetting or harms rare domains is unknown.
- Multilingual capability and cross-lingual generalization are unreported (data language mix, performance across languages, tool behavior in non-English contexts).
- MLE domain reproducibility (dataset licensing, environment pinning, seeding, leakage from public Kaggle solutions) and generalization to new competitions are not assessed.
- Instruction-following verifiers focus on surface constraints; generalization to semantic, ambiguous, or conflicting constraints (and trade-offs under conflict) is untested.
- Reward shaping for search RL (free rounds K, penalty scales, repetition windows) lacks ablations; the accuracy–efficiency trade-off and potential for gaming the reward are unexamined.
- Horizon-scaling limits are unclear: behavior beyond 256K context, diminishing returns with longer trajectories, and the comparative value of horizon vs parameter scaling are unquantified.
- Alternative distillation objectives (full-vocabulary KL, temperature-scaled KD, sequence-level objectives) are not compared; convergence and stability trade-offs remain open.
- Inference-time planning/reflection routines (self-critique, verifier-guided adjustments, rollback) are not described; whether training-time verifiers are used at inference is unclear.
- Benchmark reporting lacks per-task breakdowns, multiple seeds, confidence intervals, and robustness checks (distribution shifts, OOD tasks).
- Release scope is ambiguous: availability of KAG datasets, verifiers, tool harnesses, and teacher checkpoints needed for reproducibility is not clarified.
- Safety and alignment are not addressed (harmful content handling, prompt injection, tool misuse, code execution risks, browsing safety); no red-teaming or guardrail evaluation is provided.
- Ethical/legal aspects of web data and competition data usage (licensing, consent, derivative works) are not discussed.
- Interpretability is absent: there is no analysis linking “atomic abilities” to emergent behaviors or model internals, nor diagnostics tying KAG structure to learned policies.
- Domain definitions and routing granularity are unclear (how the six domains are delineated, how overlapping tasks are handled, whether routing is token-, turn-, or task-level).
- Persistence and integrity of agent memory (write_notes/read_notes) under context compaction are not evaluated for drift, hallucinated memory, or long-run consistency.
- Adversarial/OOD robustness is untested (poisoned web pages, schema poisoning, adversarial prompts, misleading evidence); defenses and detection mechanisms are unspecified.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s released methods and demonstrated performance on long‑horizon benchmarks (SEAL‑0, IFBench, HiPhO, FrontierScience‑Olympiad, MolBench‑Bind, SciCode, HLE, BrowseComp) and the described infrastructure (Knowledge‑Action Graphs, tool sandbox, multi‑teacher on‑policy distillation with salient vocabulary alignment).
- Evidence‑grounded research assistant for long‑form investigations
- Sector: software, media, finance, policy analysis, enterprise R&D
- What it does: Conducts multi‑step web research (search, read_page, code summarization), cites provenance, integrates multi‑source evidence, and verifies findings. Useful for analyst briefings, due‑diligence reports, competitive analysis, and literature reviews.
- Tools/products/workflows: “Deep Research” copilot with KAG-based provenance; workspace plugin that attaches source chains to every claim; report templates with verifier checks (correctness, coverage).
- Assumptions/dependencies: Access to commercial search APIs and scraping/summarization stack; 256K‑token context or equivalent memory; content licensing/compliance; robust verifiers tuned to domain.
- Instruction‑following content generator with strict constraint tracking
- Sector: education, customer support, marketing, public sector communications
- What it does: Produces outputs adhering to length, format, language, keyword, and structure constraints with automatic validation (IFBench‑style capabilities).
- Tools/products/workflows: CMS integrations that prevalidate responses; “policy‑compliant drafting assistant” for templated communications.
- Assumptions/dependencies: Validator coverage for constraints; clear templates/specs; monitoring for edge cases where constraints conflict.
- Scientific reasoning and literature‑aware STEM problem solving
- Sector: academia, education, industrial R&D (materials, chemistry, physics)
- What it does: Solves math/physics problems with verifiable multi‑step derivations; invokes code, search, scholar tools for numeric/symbolic computation and literature grounding.
- Tools/products/workflows: Courseware tutor producing stepwise solutions; lab assistant drafting methods sections with cited prior art; simulation‑assisted problem solvers.
- Assumptions/dependencies: Reliable execution sandbox for code; access to scholarly APIs; human review for high‑stakes scientific claims.
- Machine Learning Engineering (AutoML‑style) agent for competition‑like tasks
- Sector: software, MLOps, data science platforms
- What it does: Iteratively authors, patches, executes, and evaluates ML pipelines in a verifiable tree (write_full_code, patch_code, execute_code, analyze, update_answer).
- Tools/products/workflows: “MLE harness” plugin for internal Kaggle‑like experiments; continuous model‑tuning assistant that documents decisions and results via KAG.
- Assumptions/dependencies: Sandbox with dataset access and evaluator; graded tasks or internal metrics; governance for code execution permissions and resource usage.
- Tool‑orchestration copilot for enterprise workflows
- Sector: software, operations, BI/analytics, internal tooling
- What it does: Calls chained tools based on schema compatibility and state dependencies; tracks state updates and verifier outcomes to reach goal completion.
- Tools/products/workflows: Low‑code agent that sequences ETL, analytics queries, report generation, and notifications; “graph‑composed” workflows ensuring each step is grounded in prior state.
- Assumptions/dependencies: Stable tool schemas and state models; sandbox/tool sandboxing; domain verifiers for success criteria.
- Long‑context document QA and policy adherence checks
- Sector: legal ops (non‑advisory), compliance, procurement, HR
- What it does: Answers multi‑hop questions over long documents; applies in‑context rules and rejects distractors; produces evidence chains.
- Tools/products/workflows: “Contract navigator” for clause retrieval and checklist validation; “policy adherence checker” for procedural documents.
- Assumptions/dependencies: High‑quality document parsing and entity graphs; agreement on validators; legal review in high‑stakes settings.
- Cost‑efficient deployment for long‑horizon tasks with smaller models
- Sector: AI platforms, SaaS
- What it does: Delivers near trillion‑parameter performance on long‑horizon tasks with a 35B MoE model via horizon‑scaling, reducing inference cost/latency compared to 1T models.
- Tools/products/workflows: Model hosting with long‑context support; runtime policy enforcing tool limits and verifier feedback loops.
- Assumptions/dependencies: Hardware with sufficient memory for 35B MoE and long context; routing to teacher‑distilled student; latency budgets compatible with multi‑turn tool calls.
- Agent training and audit infrastructure for internal AI teams
- Sector: AI engineering, applied research
- What it does: Uses KAGs to create verifiable, evolvable training data; applies multi‑teacher on‑policy distillation with salient vocabulary alignment to merge domain experts into one agent.
- Tools/products/workflows: “Trajectory ledger” for tools/evidence/verification; OPD‑SVA training pipelines to consolidate departmental agents.
- Assumptions/dependencies: Availability of domain teachers; data engineering for KAG construction; MLOps capacity for OPD.
- Education: step‑by‑step STEM tutoring with verifiable reasoning
- Sector: education technology
- What it does: Provides guided solutions with intermediate checks; blends no‑tool reasoning and code‑augmented computation.
- Tools/products/workflows: Tutor chat with step validation; homework assistance that cites sources and shows derivations.
- Assumptions/dependencies: Academic integrity policies; restricted tool modes for exams; accuracy audits.
- Journalism and knowledge management with provenance
- Sector: media, knowledge operations
- What it does: Curates stories/reports with linked evidence trails; flags unverified claims via verifiers; maintains a KAG for editorial review.
- Tools/products/workflows: Newsroom research assistant; editorial dashboards showing action‑observation chains.
- Assumptions/dependencies: Editorial standards; caching strategies to reduce API costs; bias and source‑credibility checks.
Long‑Term Applications
These applications are promising but require additional research, domain‑specific tooling, scaling, or regulatory alignment before wide deployment.
- Clinical literature synthesis and decision support with audit trails
- Sector: healthcare
- What it could do: Multi‑step evidence‑backed clinical Q&A and guidelines synthesis with verifiable citations and tool‑assisted computations (dosage calculators, risk models).
- Tools/products/workflows: “Evidence copilot” integrated with clinical knowledge bases; KAG‑logged consultations for audit.
- Assumptions/dependencies: Regulatory clearance, medical device compliance; updated, licensed clinical sources; strict human‑in‑the‑loop and safety verifiers.
- Automated regulatory and policy analysis with traceability
- Sector: government, legal/compliance, energy/environment policy
- What it could do: Traverse long statutes/policies, produce impact analyses with evidence chains, and check compliance constraints across documents.
- Tools/products/workflows: Policy analysis workbench; rule‑graph validators; cross‑document constraint trackers.
- Assumptions/dependencies: Domain‑specific verifiers for legal/policy correctness; access to up‑to‑date corpora; expert oversight.
- Scientific discovery loops and closed‑loop experimentation
- Sector: academia, pharmaceuticals, materials, energy
- What it could do: Hypothesis generation → literature grounding → simulation/analysis → planning next experiments, with KAGs linking each step.
- Tools/products/workflows: Lab OS integration (ELNs, LIMS), simulation tools; verifier modules for reproducibility and methodology checks.
- Assumptions/dependencies: High‑fidelity simulators; lab equipment integration; robust safety and ethical governance.
- Production AutoML and model lifecycle management agents
- Sector: software, MLOps, finance, e‑commerce
- What it could do: Extend the MLE harness to managed AutoML: feature engineering, model selection, deployment, monitoring, and rollbacks, all with verifiable trajectories.
- Tools/products/workflows: “AutoMLE+Ops” agent controlling CI/CD for models with policy gates and verifiers for fairness, drift, and performance.
- Assumptions/dependencies: Enterprise MLOps integration; risk controls; domain‑specific evaluators; change‑management policies.
- Robotics and autonomous operations with long‑horizon planning
- Sector: robotics, manufacturing, logistics
- What it could do: Map the tool‑calling KAG to robotic actions and sensor states, enabling verifiable long‑horizon plans with failure recovery.
- Tools/products/workflows: Planner that composes skills via state‑transition graphs; safety verifiers for constraints and recovery policies.
- Assumptions/dependencies: Real‑time perception/control integration; rigorous safety certification; simulation‑to‑real transfer.
- Financial analysis copilots with compliance and auditability
- Sector: finance
- What it could do: Long‑form multi‑document analysis (filings, transcripts), scenario modeling via code tools, and compliance checks with audit trails.
- Tools/products/workflows: Research workstation with data vendor APIs; compliance verifiers; portfolio risk analysis notebooks linked to KAG events.
- Assumptions/dependencies: Licensed market data; strict compliance and controls; model risk management frameworks.
- Enterprise tool‑graph orchestration layer (“Agentic OS”)
- Sector: enterprise software, operations, CRM/ERP
- What it could do: Standardize tool schemas and dependency graphs across departments; route tasks through verifiable multi‑step agent workflows.
- Tools/products/workflows: Central “agent bus” with schema registry, state store, and verifier catalog; per‑domain teacher models unified via OPD‑SVA.
- Assumptions/dependencies: Organization‑wide API standardization; security and access controls; monitoring and rollback frameworks.
- KAG‑driven AI governance and audit products
- Sector: cross‑industry governance, risk, and compliance (GRC)
- What it could do: Provide regulators and internal auditors with reproducible, step‑level logs of agent decisions, evidence, and verifier outcomes for any automated process.
- Tools/products/workflows: “Trajectory auditor” dashboards, evidence replay, risk scoring, and anomaly detection over agent logs.
- Assumptions/dependencies: Standardized event schemas; data retention policies; privacy controls.
- Education at scale: personalized mastery learning with verifiers
- Sector: education
- What it could do: Adaptive curricula where each reasoning step is validated; automatic remediation plans; code‑assisted experimentation.
- Tools/products/workflows: LMS integration with per‑student KAGs; assessment verifiers; intervention recommendations.
- Assumptions/dependencies: Alignment with curricula/assessments; guardrails against over‑assistance; accessibility and fairness considerations.
- Safety‑critical multi‑agent simulation and planning
- Sector: transportation, energy grid operations, emergency response
- What it could do: Plan and evaluate multi‑step interventions in simulated environments with verifiable outcomes and counterfactuals.
- Tools/products/workflows: Simulator integrations; domain verifiers for constraints (e.g., grid stability, evacuation protocols).
- Assumptions/dependencies: High‑fidelity simulators; human oversight; regulatory approvals.
Cross‑cutting assumptions and dependencies
- Long‑context and compute: Many workflows rely on very long context windows (up to ~256K tokens) and a 35B MoE model; deployment needs GPUs/TPUs with sufficient memory and optimized serving.
- Tooling and verifiers: Effectiveness hinges on stable tool schemas, secure sandboxes for code execution, and robust verifier design per domain.
- Data governance and compliance: Web and document ingestion must respect licensing and privacy; high‑stakes domains require human‑in‑the‑loop and formal risk controls.
- Domain adaptation: Best performance requires domain‑specific teachers and careful OPD‑SVA routing; generalization depends on KAG quality and data diversity.
- Monitoring and safety: Multi‑turn agents can drift or loop; policies for tool limits, repetition penalties, and failure recovery should be enforced in production.
Glossary
- Agent horizon: The temporal extent over which an agent plans, acts, observes, and adapts across many steps. "reaches trillion-parameter-level performance by scaling the agent horizon."
- Agentic harness: A tooling framework that manages executable attempts as a tree of solution nodes for iterative agent development. "Trajectories are generated in an agentic harness that grows a tree of executable solution nodes,"
- Agentic model: A model designed to operate as an autonomous agent with planning, tool use, and iterative decision-making. "we introduce Agents-A1, a 35B MoE agentic model designed to address the key challenges mentioned above."
- Agentic trajectories: Recorded sequences of decisions, tool calls, observations, and verifications generated by an agent during long-horizon tasks. "producing agentic trajectories with an average length of 45K tokens."
- Context compaction: Summarizing earlier steps into a smaller digest to manage very long contexts during multi-turn processes. "context compaction summarizes earlier steps into a digest."
- Coverage (student-side coverage): The fraction of the student’s probability mass that falls within the teacher-selected token support during alignment. "We therefore monitor the student-side coverage"
- Cross-step credit assignment: Assigning learning signal to intermediate decisions across a trajectory based on later outcomes. "enabling cross-step credit assignment and reproducible long-horizon supervision."
- Dependency graph: A graph encoding executable dependencies among tools, states, and resources used to synthesize valid multi-step tasks. "Task synthesis is formulated as constrained graph search over this dependency graph"
- Domain-aware aggregation: Combining supervision signals while accounting for per-domain balance to avoid dominance by frequent or high-loss domains. "routed teacher guidance, salient vocabulary alignment, and domain-aware aggregation,"
- Domain-normalized objective: A loss that averages within each active domain and then across domains to balance multi-domain training. "we aggregate SVA losses with a domain-normalized objective, averaging within each active domain and then across active domains,"
- Domain-routed on-policy distillation (OPD): Distilling from domain-specific teachers while supervising only on student-generated rollouts, routed by domain. "we propose a domain-routed on-policy distillation (OPD) with salient vocabulary alignment"
- Graph-compositional task synthesis: Constructing tasks by composing connected subgraphs of tool and state dependencies to ensure executability and grounding. "graph-compositional task synthesis, and solvability assessment."
- GRPO: A reinforcement learning policy optimization algorithm used to fine-tune agent behavior with reward signals. "We adopt GRPO~\citep{shao2024deepseekmath} as our RL algorithm."
- Hard domain routing: Supervising each training sample with only its corresponding domain-specific teacher rather than mixing teachers. "We use hard domain routing, where each sample is supervised only by the teacher trained for its domain,"
- Knowledge-action graph (KAG): A structured representation linking evidence, actions, observations, and verifier outcomes to capture process-level supervision. "organized into a knowledge-action graph (KAG) that records evidence, actions, observations, and verifier outcomes."
- Knowledge-action infrastructure: A system that connects external knowledge, tools, actions, and verification signals to produce verifiable long-horizon supervision. "we construct a knowledge-action infrastructure that converts heterogeneous corpora into compositional, verifiable, and self-extending supervision,"
- LLM judge: A LLM used as an evaluator to assess the correctness or quality of model outputs. "We employ an LLM judge to evaluate whether the model's final answer is correct."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to different expert subnetworks to improve efficiency and specialization. "We introduce Agents-A1, a 35B Mixture-of-Experts Agentic Model"
- Process-level supervision: Training supervision that targets intermediate reasoning and actions, not just final answers. "providing process-level supervision beyond final answers,"
- Proposer--solver--verifier game: A self-play data-generation loop where tasks are proposed, solved, and verified to expand high-quality supervision. "we expand through a proposer--solver--verifier game:"
- Reverse KL (truncated reverse KL): A divergence objective comparing student to teacher distributions, restricted to a subset of salient tokens. "The per-sample SVA objective is the truncated reverse KL over this salient support,"
- Rollout student: The student model that generates on-policy outputs used for distillation or training supervision. "a frozen rollout student samples ,"
- Routed teacher: The specific domain teacher assigned to supervise a sample based on its domain label. "the routed teacher ."
- Salient Vocabulary Alignment (SVA): Aligning student and teacher probabilities over a compact, teacher-selected set of high-probability tokens. "with salient vocabulary alignment (SVA)."
- Sample packing: Concatenating multiple short training examples into a single long sequence to improve throughput and reduce padding. "we adopt a sample packing strategy that concatenates multiple short examples into a single training sequence"
- Schema-grounded calls: Tool invocations constrained and validated by formal tool schemas during interaction. "consists of schema-grounded calls and clarification actions;"
- Self-play: Automated iterative data generation where the model (or models) interact in roles to create and verify training trajectories. "A tool-augmented self-play loop expands the KAG into domain-specific sub-KAGs"
- Sub-KAGs: Domain-specific subgraphs derived from the overall knowledge-action graph for focused training and tasks. "sub-KAGs for coding, agentic reasoning, instruction following, MLE, and scientific reasoning."
- Tool Sandbox: A controlled environment that exposes selected tools and maintains evolving state for safe, reproducible tool interactions. "Trajectory generation is performed in a Tool Sandbox,"
- Tool-augmented reasoning: Reasoning that leverages external tools (e.g., search, code, scholar) to obtain evidence or compute results. "we construct both no-tool and tool-augmented reasoning trajectories"
- Top-k valid tokens: The set of highest-probability tokens under the teacher used as the alignment support in SVA. "be the set of top- valid tokens under the routed teacher distribution."
- Verifier-guided graph search: Exploring candidate trajectories with verifier signals to select valid, grounded, and successful runs. "This process is treated as verifier-guided graph search over the trajectory space."
Collections
Sign up for free to add this paper to one or more collections.