Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
Abstract: We study parallel test-time scaling for long-horizon agentic tasks such as agentic search and deep research, where multiple rollouts are generated in parallel and aggregated into a final response. While such scaling has proven effective for chain-of-thought reasoning, agentic tasks pose unique challenges: trajectories are long, multi-turn, and tool-augmented, and outputs are often open-ended. Aggregating only final answers discards rich information from trajectories, while concatenating all trajectories exceeds the model's context window. To address this, we propose AggAgent, an aggregation agent that treats parallel trajectories as an environment. We equip it with lightweight tools to inspect candidate solutions and search across trajectories, enabling it to navigate and synthesize information on demand. Across six benchmarks and three model families (GLM-4.7, Qwen3.5, MiniMax-M2.5), AggAgent outperforms all existing aggregation methods-by up to 5.3% absolute on average and 10.3% on two deep research tasks-while adding minimal overhead, as the aggregation cost remains bounded by a single agentic rollout. Our findings establish agentic aggregation as an effective and cost-efficient approach to parallel test-time scaling.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI agents better at long, multi-step tasks like doing deep web research, writing detailed reports, or solving complex problems with tools. The idea is simple: let the AI try several times in parallel, then smartly combine those tries to get a better final answer. The authors introduce a new “combiner” agent, called AggAgent, that can read and compare those tries efficiently and produce a higher-quality result without costing too much extra time or money.
What questions are the researchers asking?
They focus on two main questions:
- If we let an AI make several independent attempts at a hard, many-step task at the same time, what is the best way to combine those attempts?
- Can we combine them in a way that uses all the useful details (not just the final answers), stays within the model’s limited reading ability (its “attention span”), and doesn’t become too slow or expensive?
How did they approach the problem?
First, some quick translations:
- Parallel test-time scaling: Asking the AI to try multiple times simultaneously (like having 8 different “threads” of work).
- Long-horizon agentic tasks: Jobs that take many steps, often using tools (like a web browser) and producing long, open-ended answers.
- Trajectories or rollouts: The full “diary” of each attempt—each step of thinking, tool use, and observations, plus the final answer.
Why combining is hard:
- Just voting on the final answers throws away tons of evidence inside those diaries.
- Turning the entire diaries into one giant text for the AI to read is impossible—the text is too long to fit into the model’s context window (its reading limit).
- Summarizing each diary first can lose important information and costs a lot of extra AI calls.
What AggAgent does:
- Think of AggAgent as a careful editor or librarian. It treats the set of diaries (trajectories) as a library it can search.
- Instead of loading everything at once, it uses small, targeted “tools” to pull exactly what it needs:
- get_solution: See the final answers from each attempt (to spot agreement and disagreements).
- search_trajectory: Keyword search inside one diary (to find relevant parts fast).
- get_segment: Read a specific section of a diary (to verify a claim in full detail).
- finish: Submit the final combined answer and the reason.
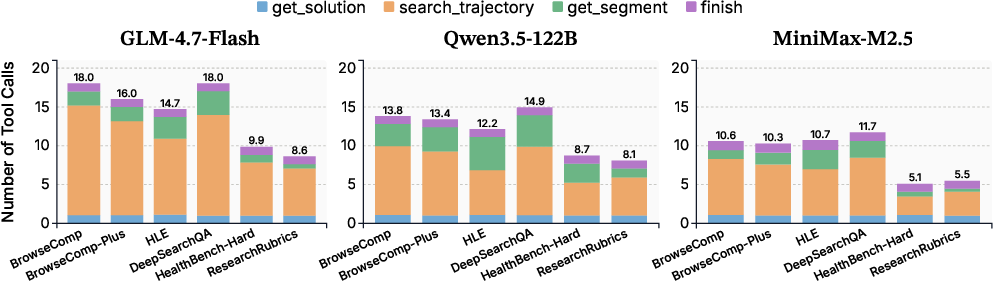
- This is a “coarse-to-fine” strategy: skim for signals, then zoom in only where needed. It keeps costs low and avoids losing information.
They compared AggAgent to common baselines:
- Majority voting, confidence-based picking, or choosing the shortest attempt (fast but shallow—they ignore the detailed evidence).
- Solution Aggregation (combine only final answers) and Summary Aggregation (summarize each diary first, then combine). These use AI reasoning but either miss evidence (solutions only) or lose detail and cost more (summaries).
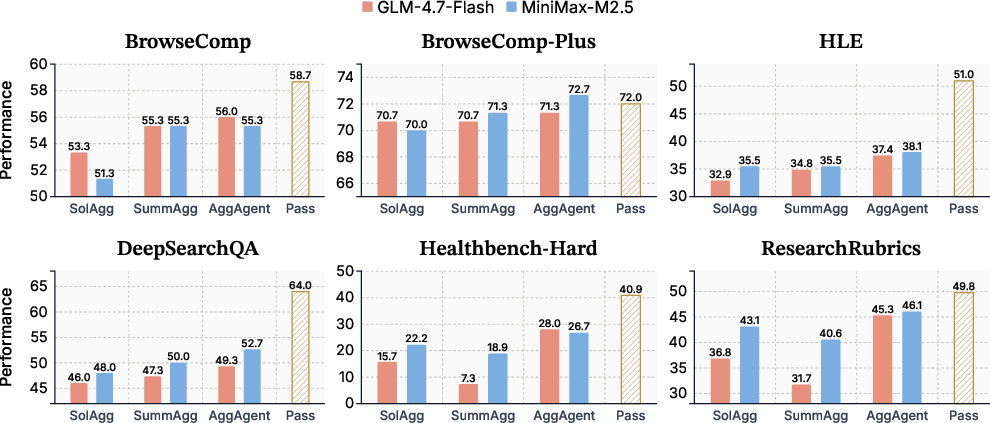
They tested across six challenging benchmarks (hard web search, multi-answer questions, medical and research reports) and three different AI model families, making 8 parallel attempts per question.
What did they find?
AggAgent consistently beat all the baselines across tasks and models. In plain terms:
- It improved average performance more than the other ways of combining, by up to about 5 percentage points on average and about 10 points on deep research tasks.
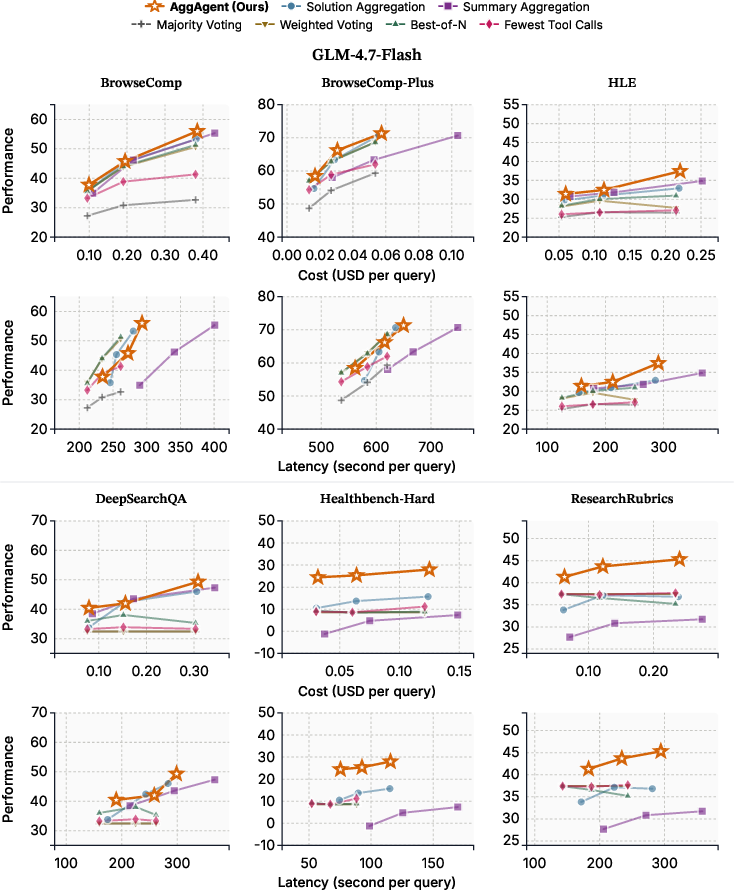
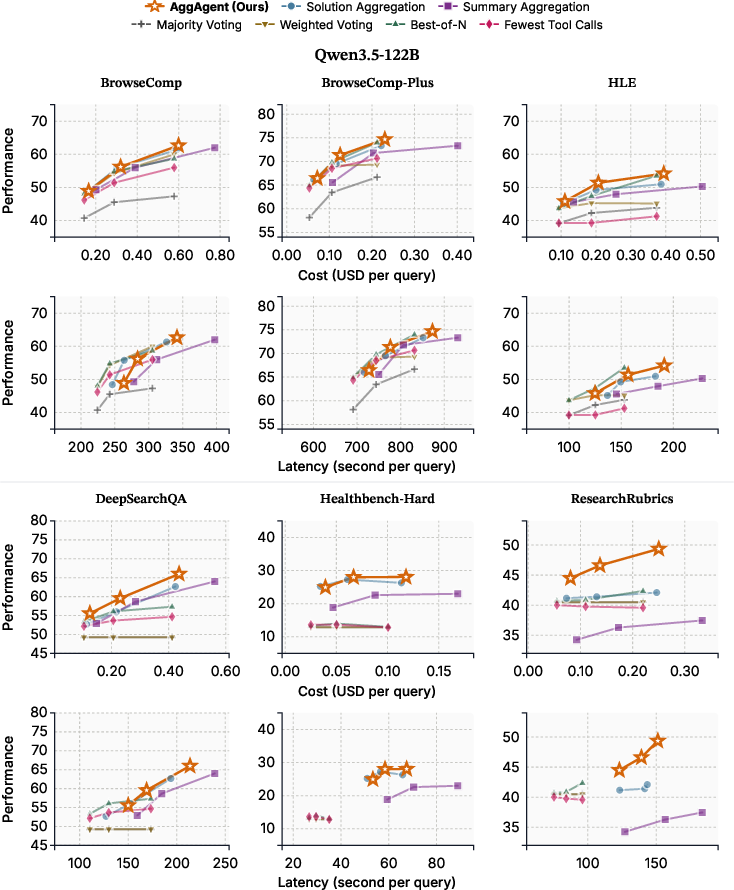
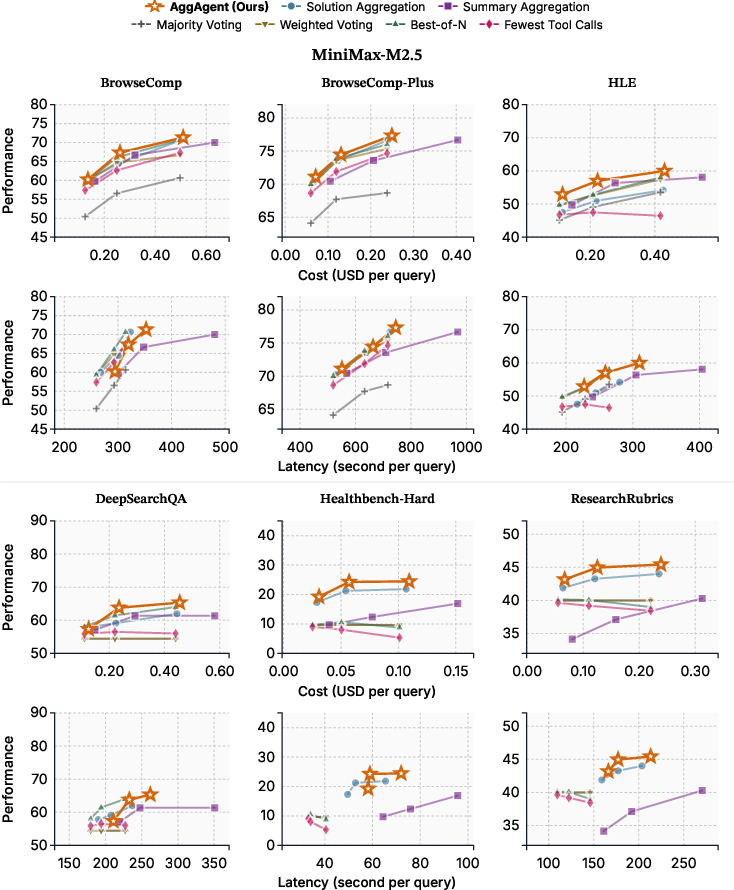
- It did this with very small extra cost—about 5–6% overhead compared with just running the 8 attempts. By contrast, the “summarize then combine” approach cost about 41% extra.
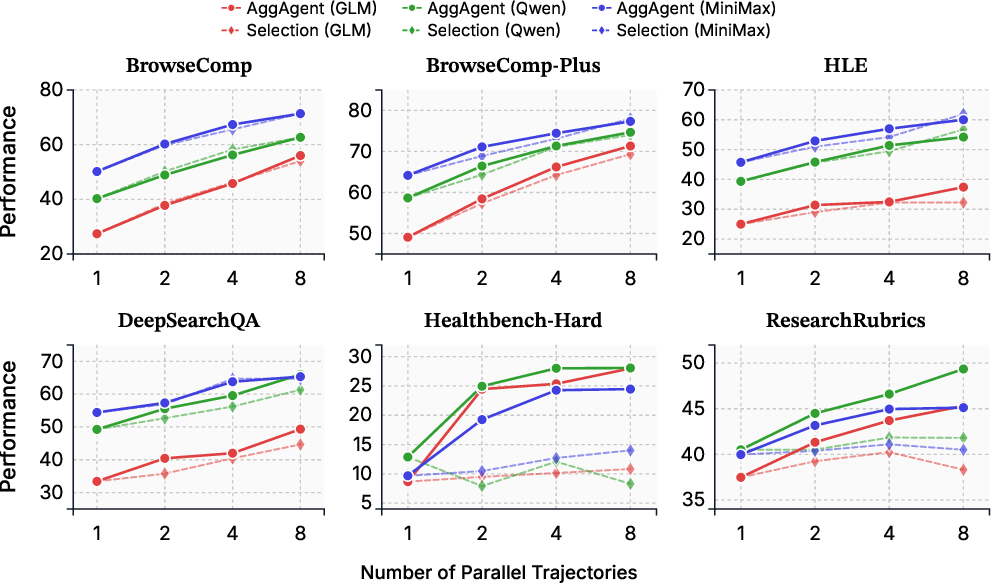
- Sometimes AggAgent even produced better answers than picking the best single attempt among the 8, which means it truly synthesized information across attempts.
- Using a stronger AI model as the aggregator (the combiner) and weaker models for the parallel attempts worked even better—like having a skilled editor review work from several junior researchers.
- “Synthesis” (building a new, combined answer) was usually better than “selection” (choosing one best attempt), especially for long, open-ended research where different attempts each have good parts.
- Tool usage patterns showed a smart workflow: mostly using search_trajectory to find key spots, and only using get_segment when a deeper read was necessary.
A few simple numbers to remember:
- Performance gain over the strongest baseline: up to about +5.3 points on average; up to +10.3 on deep research.
- Extra cost overhead at K=8: about 5.7% for AggAgent vs about 41% for summary-based combining.
Why is this important?
- Better answers from the same compute: AggAgent gets more value out of the attempts you already paid for, by combining them smartly rather than crudely voting or reading everything at once.
- Scales to real-life research tasks: It works well on open-ended, multi-step jobs where evidence is scattered across long diaries (like web research and medical/report writing).
- Practical system design tip: Use many cheap attempts in parallel, then a stronger model to aggregate. This is cost-efficient and improves quality.
- Opens a path for future training: The paper shows that even without special training, a carefully designed aggregator can be very effective. Training aggregators specifically could push performance even higher.
Quick analogy to tie it together
Imagine 8 students each do a long, messy research project on the same question. You could:
- Vote on their final answers (fast, but you might miss the one student who found the key evidence).
- Ask each student to summarize (costly, and important details get lost).
- Or bring in a great editor (AggAgent) who first scans their conclusions, searches their notes for key keywords, reads only the most relevant sections in full, and then writes a careful final report that uses the best parts from everyone. That’s what AggAgent does, and that’s why it works so well.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper advances aggregation for parallel long-horizon agents but leaves several concrete issues open for future work:
- Generalization to broader task families (e.g., software engineering with code execution/diffs, interactive web navigation with stateful actions, multimodal research over PDFs/images/tables) is untested.
- The approach assumes access to full internal “thinking” tokens (r_j); many deployments redact CoT logs—how much performance drops when the aggregator sees only tool actions and observations is not evaluated.
- Aggregation is strictly post-hoc; whether online aggregation (steering or early-stopping rollouts mid-flight) yields better cost–performance tradeoffs remains unexplored.
- Scaling behavior beyond K=8 is unknown; how aggregation latency and accuracy evolve for larger K or much longer trajectories (hundreds of thousands of steps) is not measured.
- The trajectory search tool relies on keyword/ROUGE-L matching; the benefits of semantic retrieval (embeddings), entity/time-indexed search, or cross-trajectory linking are not evaluated.
- Tool ablations are limited; the marginal contribution and budget sensitivity of get_solution vs search_trajectory vs get_segment are not quantified.
- The aggregator cannot call external verification tools (web search, code execution); whether lightweight external checks (e.g., verifying a citation) improve robustness is open.
- Robustness to adversarial or noisy trajectories (e.g., prompt-injected pages, confidently hallucinated evidence, or poisoned rollouts) is not systematically assessed.
- Susceptibility to over-weighting majority or high-confidence but wrong trajectories is not stress-tested; strategies for adversarial outlier filtering or calibration-aware aggregation remain open.
- The aggregator is prompt-based and training-free; benefits and risks of fine-tuning (e.g., supervised, RLHF, or tool-use policy optimization) are left for future work.
- Output design ablations are limited to synthesis vs selection; hybrid strategies (e.g., selective citation-anchored synthesis, segment-level voting, or sparse mixture-of-experts over trajectories) are not examined.
- The claimed context-cost independence from K ignores system-side indexing/search overhead; CPU/memory costs and throughput for scanning very large trajectory sets are not reported.
- Results use LLM-as-a-judge with modified prompts; the reliability of judgments (especially with negative rubrics), inter-judge agreement, and human evaluation baselines are not provided.
- Metric@K for LLM-based aggregation uses only three sampled subsets due to cost; the sensitivity of reported gains to subset selection bias is not analyzed.
- Evaluation subsets (e.g., sampled items, HLE “search-focused” subset) may bias results; cross-split, cross-domain, and larger-scale evaluations are needed.
- The approach depends on specific retrieval/crawling stacks (Serper, crawl4ai, Qwen embeddings); sensitivity to retriever/crawler choice, snippet truncation, and retrieval hyperparameters is unmeasured.
- The stronger-aggregator study is narrow (one stronger model, limited tasks); a fuller cost–benefit curve across aggregator strengths and K (including monetary/latency overheads) is missing.
- Heterogeneous rollout ensembles (mixing model families or prompts for diversity) and their interaction with AggAgent are not explored.
- Non-determinism sensitivity (temperature/top-p for rollouts and aggregator) and its effect on aggregation stability and variance is not reported.
- Failure-mode taxonomy is limited to qualitative cases; systematic analysis (e.g., where synthesis harms, where selection dominates, when search_trajectory misses evidence) is absent.
- The method reads potentially large segments repeatedly; risks of aggregator context overflow, long-range forgetting, and memory management strategies are not studied.
- Privacy/compliance implications of storing and scanning complete trajectories (including internal thoughts and scraped content) are not discussed; privacy-preserving aggregation is an open need.
- Multi-answer evaluation uses exact match; how conclusions change under partial credit (precision/recall, F1) or rubric-weighted completeness is not assessed.
- Bias and fairness are unexamined; whether the aggregator favors stylistic properties (verbosity, formatting) or particular sources/URLs is unknown.
- Security analysis is missing; the aggregator’s vulnerability to cross-trajectory prompt injection and defenses (sanitization, provenance checks, model-side guardrails) is not evaluated.
- Comparison to alternative aggregation paradigms (e.g., reward-model scoring, learned rerankers, graph/tree-structured cross-trajectory reasoning) is limited.
- Applicability under tighter tool budgets (e.g., <20 tool calls) and latency constraints in production settings is not benchmarked.
- The approach assumes text-only trajectories; tool designs for structured artifacts (ASTs, diffs, tables) or multimodal content are not provided.
- Impact of diversity strategies for generating rollouts (prompt/seed/temperature diversification) on aggregation efficacy is not quantified.
Practical Applications
Overview
Based on the paper “Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks,” the core innovation—AggAgent—turns aggregation into an agentic process that interactively reads, searches, and selectively inspects parallel agent trajectories to synthesize a final answer with minimal cost overhead. This enables practical deployment wherever long-horizon agents already exist (browsing, code, research, web navigation) and wherever multiple independent runs/attempts can be generated and logged.
Below are actionable applications grouped by deployment horizon. Each entry notes sectors, potential tools/products/workflows, and key assumptions/dependencies that may affect feasibility.
Immediate Applications
These can be deployed now with off-the-shelf LLMs, standard agent frameworks (e.g., LangChain, AutoGen, OpenAI Assistants, enterprise agent scaffolds), and simple in-memory trajectory storage.
- Web research assistants and enterprise RAG synthesis
- Sectors: software, media, consulting, pharma, legal research, enterprise knowledge management
- How it uses AggAgent: Run K parallel browsing/RAG agents, then aggregate by querying trajectories (get_solution → search_trajectory → get_segment) to resolve conflicts and synthesize a final answer with verified citations
- Tools/products/workflows: “Research-Compose” module; Aggregation plugin for web-research products; orchestration that pairs many cheap rollouts with a strong aggregator
- Assumptions/dependencies: Step-level trajectory logging; tools return accurate web snippets; budget to run parallel rollouts; data governance for browsing logs
- Coding copilots, code review, and CI repair synthesis
- Sectors: software engineering, DevOps
- How it uses AggAgent: Generate K code fixes or implementations in parallel, run tests, and have AggAgent read diffs, test logs, and agent reasoning to pick or synthesize the best patch
- Tools/products/workflows: IDE extensions; CI “Best-of-K with synthesis”; auto-generated PRs that include cross-trajectory evidence
- Assumptions/dependencies: Deterministic tests/sandboxes; access to build/test logs; secure isolation for code execution
- Customer support and documentation QA
- Sectors: SaaS, telecom, e-commerce, enterprise IT
- How it uses AggAgent: Multiple answer attempts against KB articles and tickets; aggregator validates claims by reading evidence in the trajectories and yields one grounded, complete answer
- Tools/products/workflows: “KB Answer Synthesis” layer; agent logs as evidence links; escalation summaries
- Assumptions/dependencies: Reliable KB retrieval; step logs that include which sources were used; PII-compliant logging
- Market and competitive intelligence briefs
- Sectors: finance (non-trading research), strategy, sales intelligence, product marketing
- How it uses AggAgent: Parallel agents collect and reason from public sources; aggregator identifies minority-correct findings, resolves inconsistencies, and merges into one brief
- Tools/products/workflows: Competitive-brief generator; “Parallel analysts → single report” pipeline
- Assumptions/dependencies: Robust web scraping/APIs; traceability of sources for auditability
- Healthcare information and patient education (non-diagnostic)
- Sectors: healthcare education, payer/provider communications, public health
- How it uses AggAgent: For long-form informational queries (e.g., Healthbench-Hard style), aggregate across parallel research runs to ensure completeness and consistent citations
- Tools/products/workflows: Patient-education content generators; cross-checked FAQs; clinician-in-the-loop review
- Assumptions/dependencies: Strict non-diagnostic scope; medical content governance; citation enforcement and audit logs
- Education: rubric-based grading and feedback synthesis
- Sectors: EdTech, higher education
- How it uses AggAgent: Multiple feedback drafts or solution paths are generated; aggregator synthesizes detailed, rubric-aligned feedback that cites trajectory evidence
- Tools/products/workflows: LMS plugins; formative feedback assistants; multi-answer tasks handled without voting
- Assumptions/dependencies: Clear rubrics; permissioned logging; instructor review for high-stakes grading
- Security operations and incident response triage
- Sectors: cybersecurity, IT operations
- How it uses AggAgent: Run multiple playbooks or detection strategies; aggregator inspects logs, compares hypotheses, and recommends a minimal-risk triage plan
- Tools/products/workflows: “Playbook-of-K then aggregate”; incident summary with linked log segments
- Assumptions/dependencies: Read-only access to logs; human-in-the-loop approval; standardization of trajectory formats across playbooks
- Data labeling and adjudication at scale
- Sectors: ML ops, data vendors, internal AI platforms
- How it uses AggAgent: K labeling agents propose rationales; aggregator inspects evidence and either synthesizes the best label or composes a label with justification
- Tools/products/workflows: Adjudication-as-a-step in labeling pipelines; evidence-linked labels
- Assumptions/dependencies: Stored rationales and evidence; clear labeling policy; acceptance criteria for confidence thresholds
- Answer ranking and query-rewrite aggregation in search
- Sectors: consumer search, enterprise search
- How it uses AggAgent: Generate K reformulations/answers; aggregator inspects candidate answers’ trajectories to rank or synthesize the best result
- Tools/products/workflows: Search rewriter with aggregating reranker; answer selection with fine-grained evidence checking
- Assumptions/dependencies: Multiple candidates per query; token/log budgets for traces
- Asymmetric model allocation in production multi-agent systems
- Sectors: any production system with multi-agent workflows
- How it uses AggAgent: Use a stronger LLM for aggregation (orchestrator) and cheaper rollouts for parallel exploration, achieving higher quality at modest added cost
- Tools/products/workflows: Scheduler that routes aggregation to a higher-tier model; cost-aware inference planning
- Assumptions/dependencies: Access to multiple model tiers; monitoring for latency overheads; privacy controls if aggregators read all traces
Long-Term Applications
These require further research, larger-scale engineering, or regulatory approval before safe deployment.
- Safety-critical decision support (clinical, legal, aviation)
- Sectors: healthcare diagnostics, legal analysis, compliance, aerospace
- Vision: Aggregator synthesizes across multiple agentic analyses to reduce omission and improve evidence integration in high-stakes contexts
- Tools/products/workflows: Chain-of-custody logs; audit-ready synthesis with explicit uncertainty; human oversight dashboards
- Assumptions/dependencies: Rigorous validation; post-hoc interpretability; regulatory approval; robust provenance of evidence
- Cross-agent orchestration over heterogeneous environments and modalities
- Sectors: robotics, autonomous systems, digital twins, complex workflows
- Vision: Combine trajectories from browsing agents, code agents, planners, simulators, and perception modules; aggregator composes composite plans
- Tools/products/workflows: Trajectory schema standards; multi-modal search_trajectory; event-time indexing and cross-run linking
- Assumptions/dependencies: Unified trajectory format; adapters for non-text logs; strong safety layers
- Aggregator fine-tuning and learning-to-aggregate
- Sectors: AI platform providers, research labs
- Vision: Train domain-specific aggregators (via SFT/RL) on trajectory corpora to improve reliability, calibration, and tool-use strategies
- Tools/products/workflows: Datasets of trajectories with gold aggregates; reward models for evidence-grounded synthesis; offline evaluation harnesses
- Assumptions/dependencies: Data collection and labeling at scale; guardrails to avoid overfitting to superficial cues
- Aggregation-as-a-Service (AaaS) and platform integration
- Sectors: cloud AI, agent frameworks, enterprise platforms
- Vision: Managed service that ingests K trajectories and returns an aggregated, evidence-linked answer; supports arbitrary tools via adapters
- Tools/products/workflows: APIs for get_solution/search/get_segment; cost-aware routing; tenancy isolation and encryption
- Assumptions/dependencies: Standardized logging; privacy/security certifications; predictable latency SLOs
- AutoML and experiment orchestration
- Sectors: ML, data science platforms
- Vision: Generate multiple training/HP configurations; aggregator reads experiment logs, metrics, and failure traces to recommend next steps or synthesize a final report
- Tools/products/workflows: “Experiment synthesis” agent; cross-run ablation analysis; pipeline recommendations
- Assumptions/dependencies: Structured experiment metadata; reproducibility; trace storage
- Scientific literature review and meta-analysis at scale
- Sectors: academia, pharma R&D, policy research
- Vision: Multiple literature agents search and extract claims; aggregator resolves contradictions and composes rigorous reviews with source tracebacks
- Tools/products/workflows: Evidence graphs built from trajectories; contradiction detectors; long-form synthesis with rubric scoring
- Assumptions/dependencies: Reliable citation parsing; deduplication; domain expert oversight
- Energy and operations planning via multi-run synthesis
- Sectors: power grid operations, logistics, manufacturing
- Vision: Parallel optimizer/planner runs with different constraints; aggregator composes a robust plan by reconciling trade-offs discovered across runs
- Tools/products/workflows: Digital twin integrations; policy-constraint trackers; scenario synthesis dashboards
- Assumptions/dependencies: Access to simulation logs; verifiable constraints; safety cases and compliance
- Finance research and risk/compliance synthesis
- Sectors: asset management research (non-execution), enterprise risk, compliance
- Vision: Agents explore data, filings, and signals in parallel; aggregator consolidates hypotheses and flags inconsistencies with references
- Tools/products/workflows: Research memo generators; risk-control checklists; audit trails from trajectory segments
- Assumptions/dependencies: Licensed data access; strict auditability; segregation of duties; compliance approval
- Governance, auditing, and policy frameworks for agentic systems
- Sectors: regulators, enterprises with AI governance programs
- Vision: Use aggregated trajectories as auditable artifacts, enabling standardized review of complex multi-agent decisions
- Tools/products/workflows: Trajectory archival standards; policy-conformant aggregation reports; red-teaming harnesses that exploit cross-trajectory synthesis
- Assumptions/dependencies: Industry standards for logging and retention; privacy-preserving storage; alignment with audit requirements
- Robotics and autonomous planning with multi-trajectory synthesis
- Sectors: robotics, autonomous vehicles, warehousing
- Vision: Generate multiple planning rollouts (sim or real-world) and aggregate to a synthesized plan that leverages best subplans
- Tools/products/workflows: Log adapters from planners; segment-level plan comparison; failure-mode clustering and remediation
- Assumptions/dependencies: High-fidelity logs; safety validation in sim-to-real transfer; real-time constraints
Notes on Feasibility and Deployment
- Minimal integration barrier: AggAgent’s tools are lightweight and operate over in-memory trajectories—no external APIs needed for aggregation logic. If your current agents already retain step-level logs (reasoning, tool calls, observations), you can retrofit AggAgent quickly.
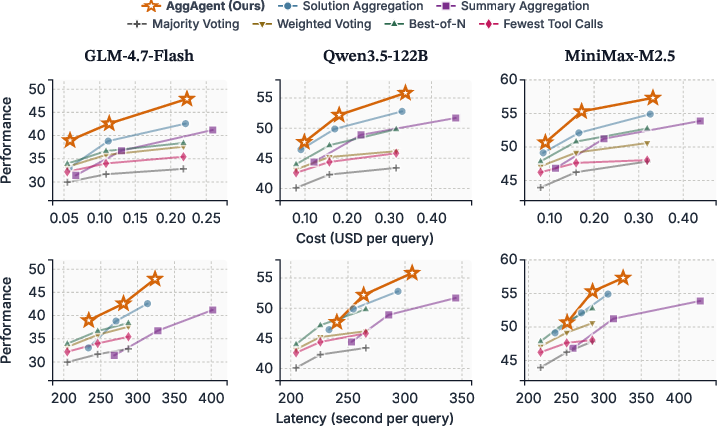
- Cost–latency profile: Aggregation overhead is comparable to a single rollout and largely independent of K, enabling parallel scaling without prohibitive cost. Asymmetric allocation (stronger aggregator, cheaper rollouts) can further optimize cost/performance.
- Calibration and evaluation: For tasks where confidence is miscalibrated or answers are long-form/multi-answer, AggAgent’s evidence-driven synthesis outperforms voting/heuristic methods. Rely on rubrics or trusted judges where ground-truth matching is difficult.
- Guardrails and oversight: For high-stakes or regulated use cases, keep humans in the loop; enforce logging, provenance, and citation checks; and adopt domain-specific templates/rubrics to constrain outputs.
Glossary
- Agent scaffold: The structural prompt or framework that organizes an agent’s behavior and tools. "We adopt Tongyi DeepResearch as the agent scaffold, use native function calling, allow at most 128K context length with 100 tool calls, and sample 8 independent trajectories."
- Agentic aggregation: An approach that treats aggregation itself as an agent interacting with trajectories to synthesize answers. "Our findings establish agentic aggregation as an effective and cost-efficient approach to parallel test-time scaling."
- Agentic mid-training: A training phase focused on improving agent-like behaviors and tool-using capabilities of LLMs. "agentic mid-training~\citep{su2025scaling}"
- Agentic RAG: Retrieval-augmented generation where the LLM actively plans and uses retrieval as part of an agentic workflow. "including agentic RAG~\citep{jin2025search, li2025search, jin2025empirical}"
- Agentic search: A problem-solving setup where an agent iteratively searches, reasons, and uses tools to find answers. "Agentic search: BrowseComp~\citep{wei2025browsecomp} consists of challenging factual questions demanding exhaustive multi-step web browsing"
- Asymmetric model allocation: Using different-strength models for different roles (e.g., stronger aggregator, weaker rollouts). "This points to asymmetric model allocation---a stronger model for aggregation, weaker models for parallel rollouts---as a practical strategy for designing multi-agent systems"
- Best-of-N (BoN): Selecting the single candidate with the highest score (e.g., confidence) among N samples. "\item Best-of-N (BoN)~\citep{cobbe2021training,uesato2022solving}: selects the solution with the highest self-reported confidence."
- Bootstrapped sampling: Resampling method used to estimate metrics by repeatedly sampling subsets. "We perform bootstrapped sampling for calculating Metric@."
- Chain-of-thought (CoT): Explicit step-by-step reasoning emitted by LLMs to improve problem-solving. "This success has largely been demonstrated in standard chain-of-thought (CoT) tasks such as mathematical reasoning and coding~\citep{qi2025learning, zhao2025majority}."
- Context folding: Techniques that compress or restructure context to extend effective reasoning horizon. "context folding~\citep{sun2025scaling, ye2026agentfold}"
- Context management: Strategies for organizing and curating information within an LLM’s context during long tasks. "through context management~\citep{wu2025resum, yen2025lost, tang2025beyond, zeng2026glm}"
- Context window: The maximum token capacity an LLM can attend to at once. "concatenating all trajectories exceeds the model's context window."
- Cross-trajectory reasoning: Reasoning that integrates evidence across multiple independent rollouts. "AggAgent (ours) navigates trajectories via tools in an agentic manner, enabling full-fidelity cross-trajectory reasoning at low cost."
- Cross-trajectory synthesis: Composing a final solution by combining partial insights from different trajectories. "requiring cross-trajectory synthesis to assemble a complete solution"
- Deep research: Open-ended, long-form investigations requiring synthesis and rigorous evidence gathering. "We evaluate AggAgent on six agentic search and deep research benchmarks across three model families"
- Fewest Tool Calls (FewTool): A heuristic that prefers solutions produced with fewer external tool interactions. "\item Fewest Tool Calls (FewTool)~\citep{liu2025deepseek, lu2025deepdive}: selects the solution from the trajectory that required the fewest tool calls."
- Interleaved reasoning: Alternating between internal reasoning and actions/tool calls within an agent’s loop. "We enable interleaved reasoning and native function calling"
- LLM agents: Language-model-driven agents that solve tasks through iterative reasoning and tool use. "LLM agents have emerged as a powerful paradigm, extending LLMs beyond pure parametric generation to interactive problem solving in external environments."
- LLM-as-a-judge: Using an LLM to evaluate or grade model-generated outputs. "We employ LLM-as-a-judge, following the official evaluation setting."
- LLM-based aggregation: Aggregating multiple candidates or trajectories using an LLM to synthesize a final answer. "Parallel scaling with LLM-based aggregation mitigates this problem by generating multiple independent trajectories and reasoning over them to produce a final solution."
- Long-horizon: Tasks that require many steps, extended context, and sustained reasoning or interaction. "long-horizon agentic tasks (e.g., deep research, software engineering, web navigation) present a fundamentally different challenge"
- Majority Voting (MV): Selecting the most frequent answer among multiple candidates. "\item Majority Voting (MV)~\citep{wang2022self}: selects the most frequent solution."
- Native function calling: Built-in capability for LLMs to call tools or functions via structured interfaces. "use native function calling"
- Orchestrators: Stronger models that coordinate or supervise multiple sub-agents. "employing stronger models as orchestrators over multiple weaker subagents~\citep{qiao2025webresearcher, zhang2025recursive, akay2026spd}"
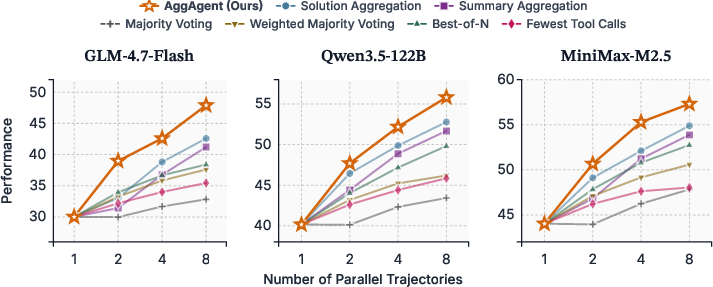
- Pareto-optimal: Achieving the best possible trade-off where improving one objective would worsen another. "AggAgent is Pareto-optimal in cost and performance (Figure~\ref{fig:eff_mini})"
- Parallel scaling: Running multiple independent rollouts concurrently to improve performance. "Parallel scaling enables simultaneous generation of multiple independent trajectories, offering a natural computational advantage~\citep{zhao2025majority}."
- Pass@K: Probability that at least one of K independent samples contains a correct solution. "when scaling from Pass@1 to Pass@8"
- ReAct: An agentic workflow interleaving reasoning (thought) and actions (tool use). "ReAct~\citep{yao2022react} has been the most prominent workflow"
- Retriever: A component that fetches relevant documents or passages for an agent. "using Qwen3-Embedding-8B as the retriever."
- Reward model: A learned model that scores candidate solutions, often used to guide selection. "While reward model scores are commonly used as the weight for CoT reasoning tasks"
- ROUGE-L: An n-gram overlap metric (Longest Common Subsequence variant) for ranking or evaluation. "ranked by ROUGE-L score~\citep{lin-2004-rouge}"
- Rollout: A single, complete execution trace (trajectory) of an agent solving a task. "multiple rollouts are generated in parallel and aggregated into a final response."
- Self-reported confidence: The model’s own declared confidence used as a selection or weighting signal. "recent works on agentic tasks have adopted the model's self-reported confidence as the weight"
- Sequential scaling: Extending an agent’s effective horizon via iterative context handling rather than parallelism. "sequential scaling to extend the effective horizon of a single agent"
- Solution Aggregation (SolAgg): Aggregating only the final answers from rollouts for synthesis. "Solution Aggregation feeds only final solutions to an LLM, discarding intermediate reasoning."
- Summary Aggregation (SummAgg): Aggregating compressed summaries of trajectories to synthesize an answer. "Summary Aggregation compresses each trajectory into a lossy summary."
- Test-time scaling: Increasing compute or samples at inference time to boost accuracy. "We study parallel test-time scaling for long-horizon agentic tasks"
- Tool call: An action where the agent invokes an external tool or API during a step. "each step consists of internal thinking , tool call , and resulting observation ."
- Trajectory: The sequence of thoughts, actions, observations, and outputs as an agent solves a problem. "The trajectories themselves are not pre-loaded into the context"
- Weighted Majority Voting (WMV): Voting where candidate answers are weighted (e.g., by confidence) before selecting a winner. "\item Weighted Majority Voting (WMV)~\citep{li-etal-2023-making,wu2024scaling}: selects the solution with the highest total weight, where each solution is weighted by self-reported confidence."
Collections
Sign up for free to add this paper to one or more collections.