Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
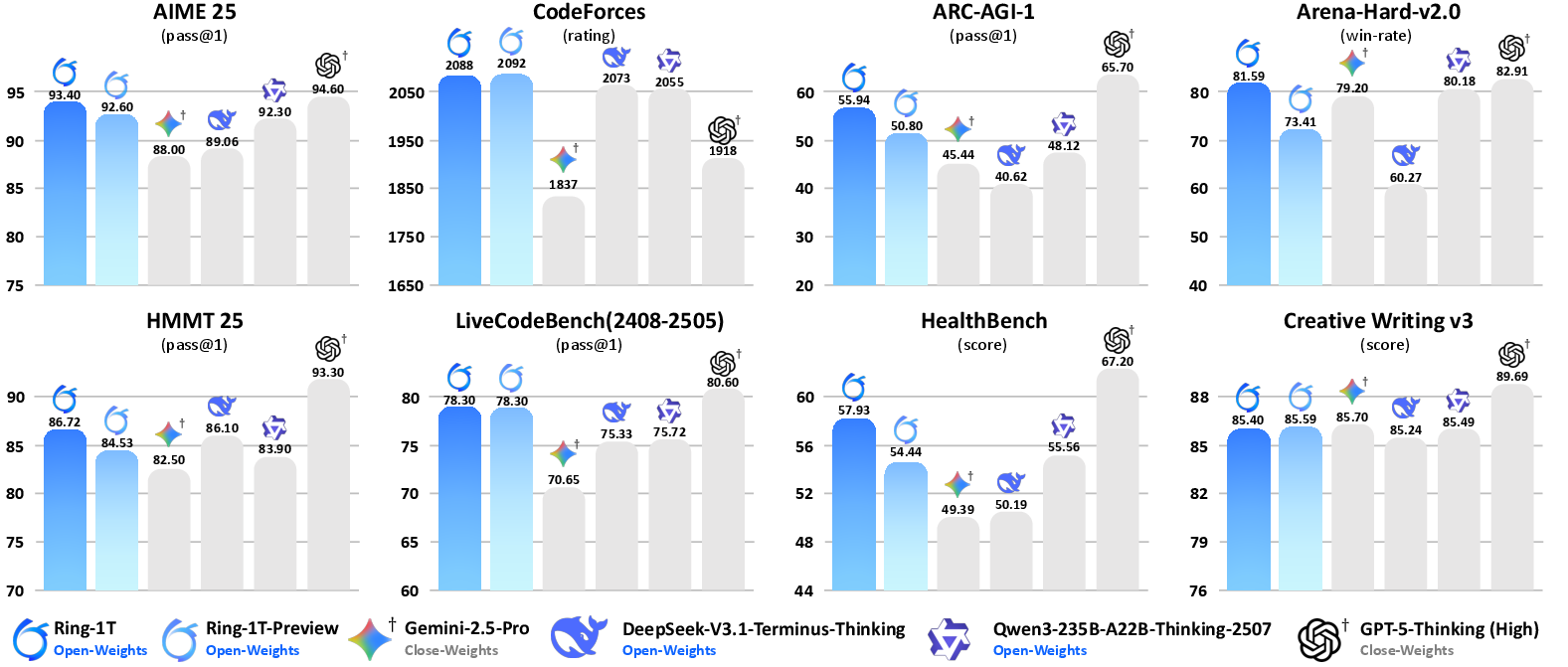
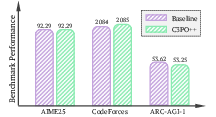
Abstract: We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy explanation of “Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model”
1. What is this paper about?
This paper introduces Ring-1T, an open-source “thinking” AI model with a huge size: 1 trillion total parameters. It’s designed to solve tough problems by thinking step by step in natural language. The team explains how they trained such a massive model using reinforcement learning (RL), fixed big stability and speed problems, and shows that the model performs extremely well on hard math, coding, and logic tests.
2. What questions were they trying to answer?
- Can we build and train a 1-trillion-parameter model that reasons well, not just memorizes facts?
- How do we keep training stable when the model is so large and uses “experts” inside it?
- How can we make training fast, even when the model produces very long step-by-step answers?
- Does this model actually beat other models on real tests like AIME (math), CodeForces (coding), and ARC-AGI (logic)?
3. How did they do it?
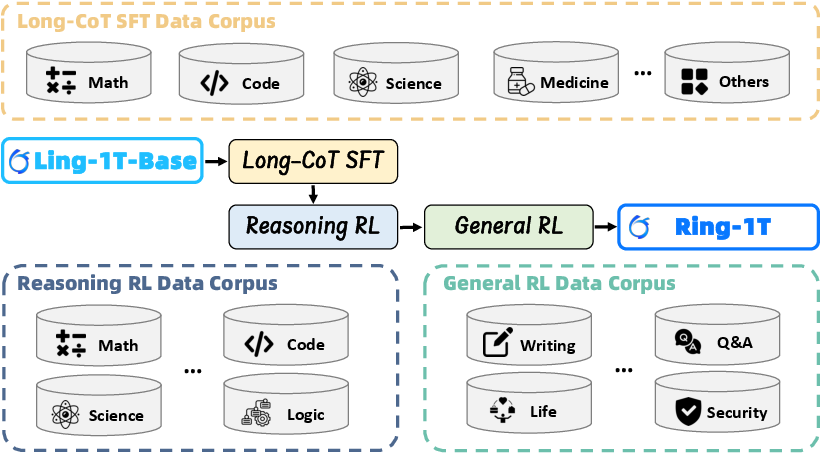
They used a three-stage training process and created new tools to make it work at “trillion scale.”
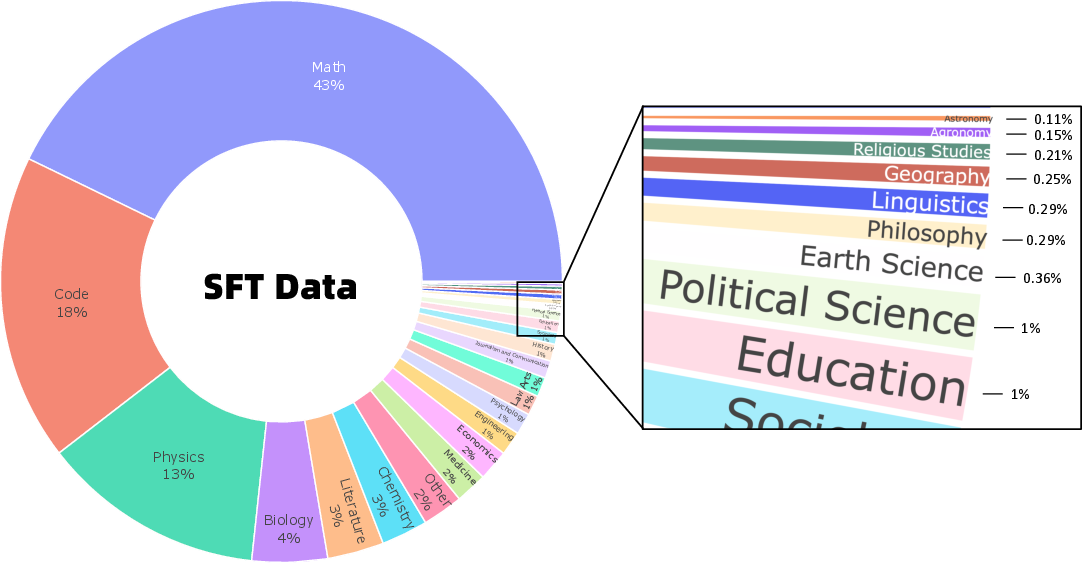
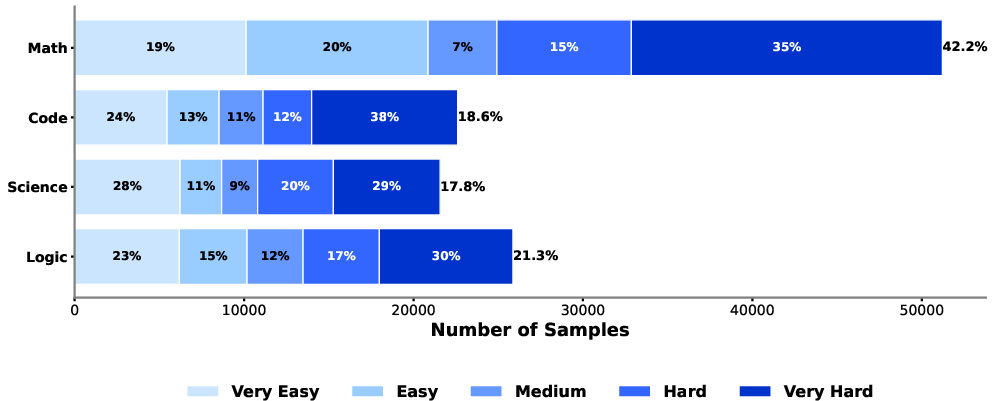
- Long-CoT SFT (Supervised Fine-Tuning): First, they taught the model how to think in long chain-of-thoughts (like showing your work in math). They used high-quality problems from math, science, and code, cleaned carefully to remove duplicates, harmful content, and anything that overlaps with test sets.
- RLVR (Reinforcement Learning from Verifiable Rewards): Next, they used RL on tasks with clear ways to check if answers are right (like running code tests or checking a math solution). Think of RL like practice where the model tries answers and gets a score, then changes its “settings” (parameters) to do better next time.
- RLHF (Reinforcement Learning from Human Feedback): Finally, they trained the model to better follow instructions, be helpful, safe, and write well, using human preferences.
To make trillion-scale training possible, they introduced three key ideas. Here are the three innovations, with simple analogies:
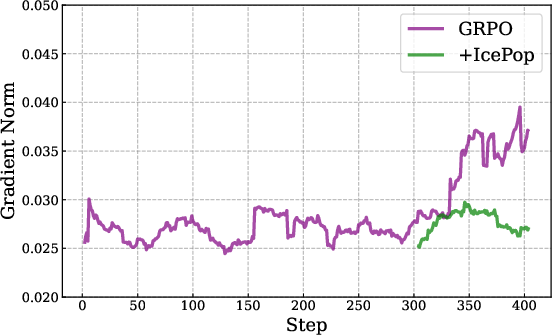
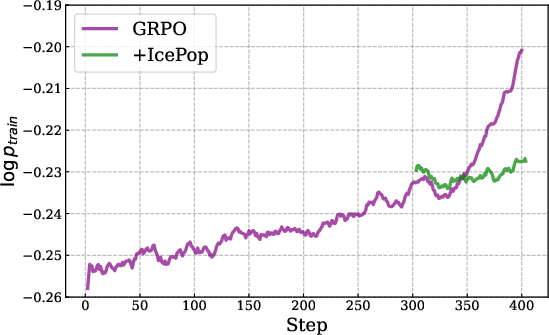
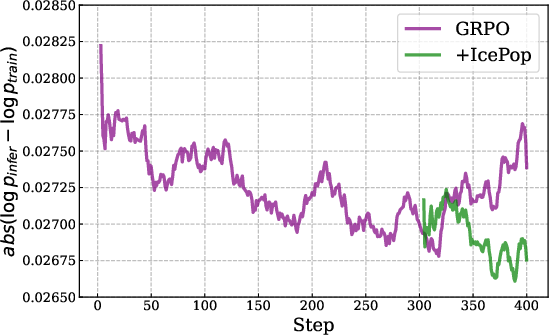
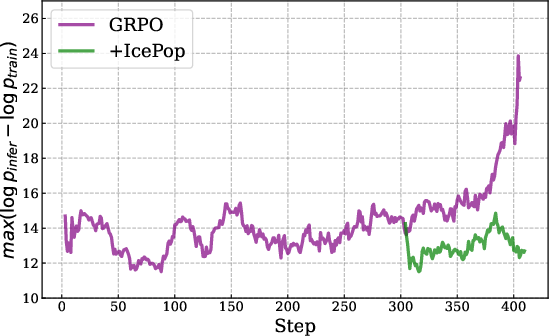
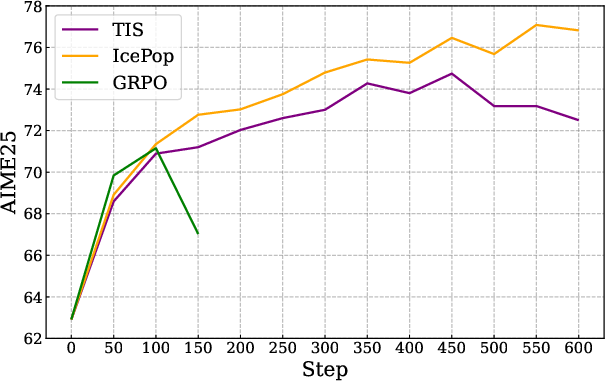
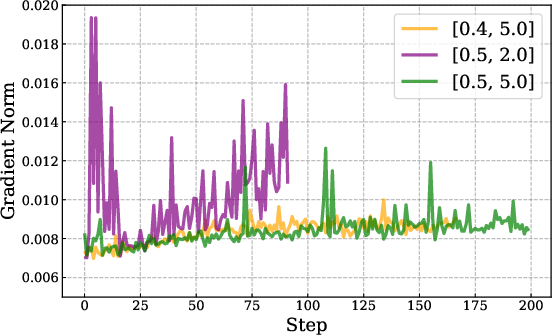
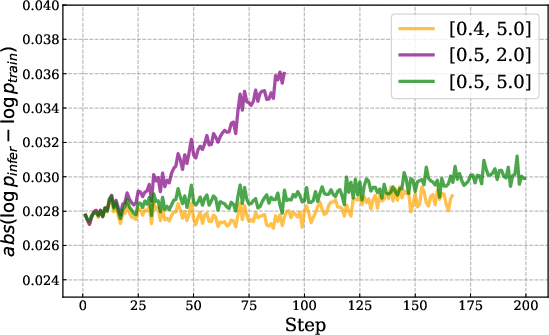
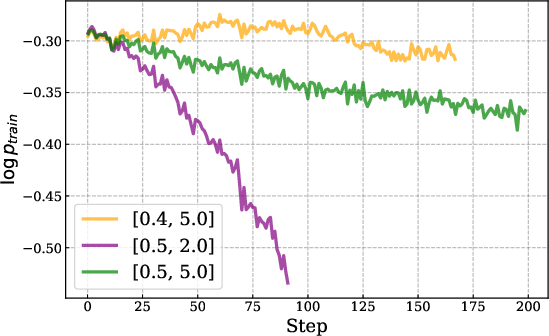
- IcePop: Keeps training stable by ignoring “noisy” parts. Imagine you’re comparing two calculators (training vs. inference) that sometimes give slightly different numbers. Over time, small differences can snowball and break things. IcePop watches each token (a token is a chunk of text like a word or part of a word) and ignores updates from tokens where the difference is too big. It also “clips” extreme changes. This stops training from going wild.
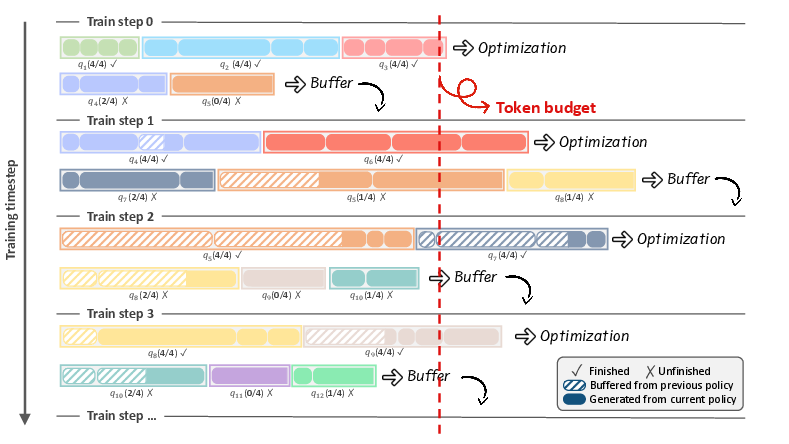
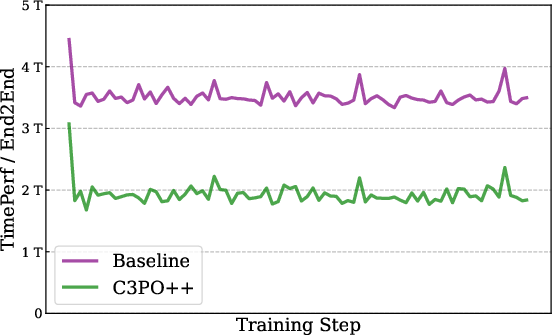
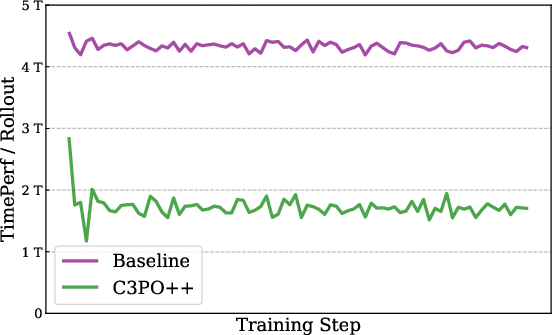
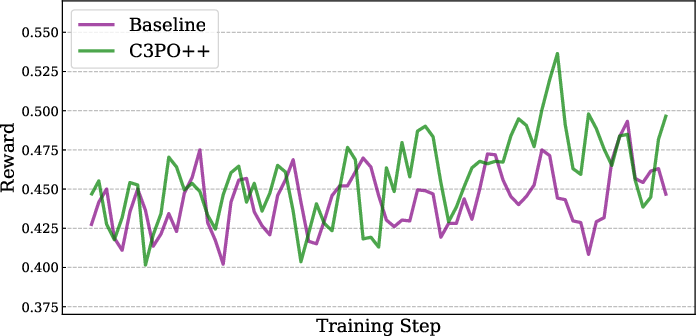
- C3PO++: Speeds up training by splitting long answers into manageable parts. Picture a class where one student is writing a very long essay and everyone else has to wait. C3PO++ sets a token “budget” per training step, saves unfinished long answers, and continues them later. That way, the computers stay busy and training goes 1.5–2.5x faster without hurting performance.
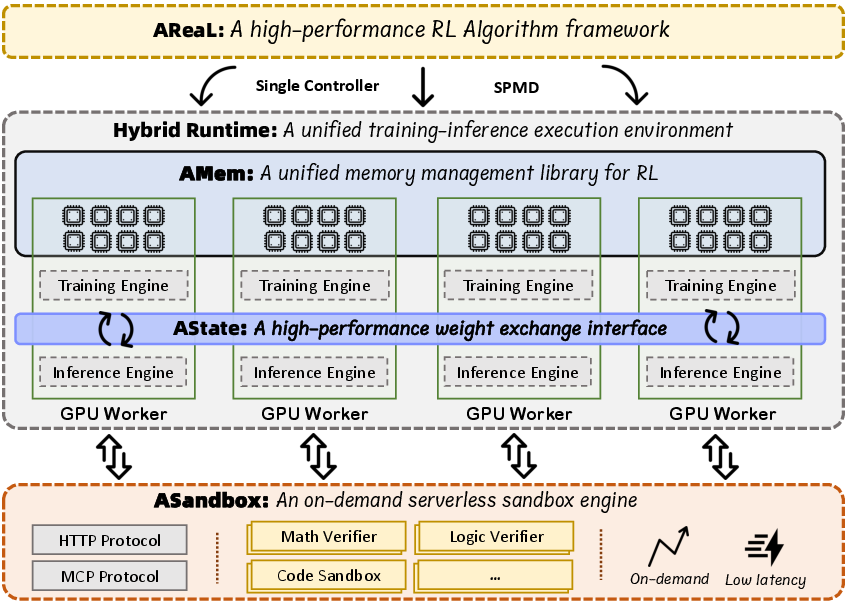
- ASystem: A high-performance RL framework to handle the giant model across thousands of GPUs. Think of it as the “control center” and “road system” that moves data efficiently. It includes:
- AState: Quickly shares updated model weights (its settings) peer-to-peer across machines so inference uses the latest version.
- AMem: Smart GPU memory management to avoid out-of-memory errors and allow bigger batches.
- ASandbox: Safe, fast mini-environments to check answers (like running code or math checks) on demand.
- AReaL: A flexible RL toolkit to run different RL algorithms at massive scale, asynchronously.
Technical terms explained simply:
- Parameter: A “setting” inside the model’s brain. More parameters mean more capacity to learn complex patterns.
- Mixture-of-Experts (MoE): Like a team of specialists inside the model. Only a few specialists “wake up” for each token, so you get huge total capacity but only use a smaller active part each time (here about 50 billion active parameters).
- Token: A piece of text, such as a word or part of a word.
- Rollout: The model’s full step-by-step answer for a question. In RL, you generate rollouts, score them, and use them to improve the model.
- Train–Inference mismatch: Training and testing sometimes use slightly different systems. If they compute probabilities differently, the model can get unstable. IcePop fixes this.
4. What did they find?
Ring-1T achieved very strong scores on challenging benchmarks, often leading among open-source models:
- Math: 93.4 on AIME-2025 and 86.72 on HMMT-2025, both high-level math competitions. The model also reached silver-medal level on IMO-2025, solving four problems in one go and almost proving a fifth—using pure natural language reasoning, no external code or math solvers.
- Coding: 2088 rating on CodeForces and top scores on LiveCodeBench-v6, beating other open models and competing with closed ones.
- Logic: 55.94 on ARC-AGI-v1, significantly ahead of many open models.
- Overall: The model shows balanced strength—great reasoning plus good alignment with human preferences (e.g., strong results on ArenaHard v2 and Creative Writing benchmarks). The new training methods improved stability and sped up training without lowering performance.
They also released the full 1-trillion-parameter MoE model publicly, which is rare for models this large.
5. Why does this matter?
- Better problem solving: The model can reason deeply in math, coding, science, and logic using natural language. That’s a big step towards more general-purpose AI that doesn’t just recall facts but works through complex tasks.
- Open access: By releasing the whole model, the community can study, improve, and build on it. This helps democratize advanced AI, not just keep it behind closed doors.
- New training tools: IcePop, C3PO++, and ASystem show how to train huge models stably and efficiently. These ideas can help future researchers push AI even further.
- Real-world impact: Strong reasoning and alignment make the model more useful in education, programming, scientific problem solving, and healthcare support—while the alignment stage helps it follow instructions safely and politely.
In short, this paper proves that trillion-scale “thinking” models can be trained reliably, run efficiently, and deliver top-notch reasoning—while sharing the model and methods so others can learn and build on them.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is phrased to be directly actionable for future research.
- Compute disclosure: No details on total training tokens, RL steps, wall-clock time, GPU count/type, memory topology, or total flops; report these to enable reproducibility and compute-optimal comparisons.
- Energy and carbon: Absent energy usage and CO2 emissions; quantify and analyze energy/performance trade-offs at trillion-scale RL.
- Data transparency: The SFT and RL datasets (queries, sources, sampling proportions) are not released/described in sufficient detail; publish data cards, licensing, and curation scripts for all domains.
- Data governance: Use of social media and user interaction data lacks licensing and privacy compliance details; provide legal review, consent, opt-out mechanisms, and provenance tracking.
- Decontamination rigor: Only exact-match/hash decontamination is described; add fuzzy/semantic decontamination and release contamination audit reports per benchmark (especially AIME/HMMT/ARC-AGI).
- Reward verifiers: The design, coverage, accuracy, and failure modes of multi-domain verifiers are unspecified; provide specs, error rates, adversarial stress tests, and anti-reward-hacking safeguards.
- Reward hacking detection: No analysis of model exploiting verifier loopholes; introduce canary tasks and adversarial tests to quantify and mitigate reward gaming.
- RL objective details: KL coefficient set to 0.0 in both RL stages; evaluate stability, safety, and alignment impacts vs. non-zero KL and alternative regularizers (e.g., adaptive KL).
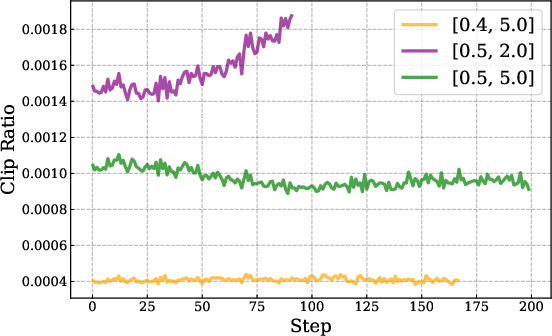
- IcePop theory: Theorem conditions, proofs, and convergence guarantees are not provided; supply formal analysis, assumptions, and bounds on discrepancy growth and masked-gradient bias.
- IcePop sensitivity: No ablations on α/β thresholds, masking rate, and clipping parameters; report sensitivity curves, masking fraction over training, and generality across tasks.
- IcePop bias/variance: Masking discards gradients—quantify introduced bias, variance reduction, and sample efficiency impacts relative to TIS/IS-corrected baselines.
- Generality beyond MoE: IcePop is motivated by MoE mismatch; test and report efficacy on dense architectures and other routing schemes to establish broader applicability.
- Exploration effects: Analyze whether token-level masking dampens exploration/diversity in long-CoT rollouts; measure entropy, novelty, and solution diversity over training.
- C3PO++ policy lag: Resuming unfinished rollouts with updated policies introduces off-policy bias; provide theoretical/empirical analysis and corrections (e.g., IS weights, policy version tracking).
- Length bias: Budget-driven partitioning risks favoring short sequences; implement and evaluate length-normalized rewards/sampling to avoid bias.
- Retention threshold σ: No guidance on σ and its trade-offs; report resume rates, purge ratios, and the effect on final performance and stability.
- Convergence under partitioning: Lacking theory on convergence and stability of dynamic partitioning; provide proofs or empirical diagnostics (e.g., effective horizon, variance of returns).
- Token budget schedule: No study of budget scheduling strategies; evaluate adaptive/annealed budgets and their impact on throughput and learning.
- System benchmarks: ASystem claims sub-second/10s sync without rigorous benchmarks; release end-to-end throughput, latency distributions, failure rates, and scalability curves across cluster sizes/topologies.
- Hardware specificity: Performance depends on RDMA/NVLink/NUMA; assess portability and performance on commodity interconnects and heterogeneous clusters.
- Fault tolerance: Provide empirical data on error rates, recovery time, checkpointing overhead, and impact on training progression.
- Determinism and reproducibility: No guarantees or measurements; report seed control, run-to-run variance, and determinism under asynchronous SPMD.
- Security of ASandbox: Side-channel risks, sandbox escape, and code/data exfiltration are unaddressed; conduct formal security audits and publish threat models and mitigations.
- Safety and red-teaming: Limited safety evaluation; perform comprehensive jailbreak, toxicity, bias/fairness, and misuse risk assessments, especially after RL without KL.
- Healthcare claims: HealthBench gains are reported without clinical validation; add expert review, error taxonomy, and harm assessment before real-world use.
- IMO evaluation protocol: Insufficient detail on judging criteria, time limits, attempts, and external assistance; release full transcripts, scoring rubric, and verification artifacts.
- Statistical rigor: Many results lack CIs, seeds, and significance tests; report variability across runs and per-benchmark sampling uncertainty (e.g., Avg@k sensitivity).
- Inference settings: Not all decoding parameters are disclosed (temperature/top-p/nucleus, stop criteria, CoT length caps); standardize and release full inference configs per benchmark.
- Cost/perf at inference: No latency, throughput, or $/query estimates with 50B active params and 128K contexts; quantify and optimize test-time compute.
- Test-time compute control: No mechanism for adaptive “thinking effort” at inference; study dynamic CoT allocation/early-exit vs. accuracy trade-offs.
- Long-context robustness: Evaluate position generalization, retrieval under noise, and degradation beyond 64K/128K with controlled probes (e.g., needle-in-a-haystack).
- Catastrophic forgetting: Post-RL knowledge retention is unmeasured; run before/after knowledge tests and domain-specific regressions.
- Multilingual coverage: Limited evidence beyond English/Chinese; assess low-resource languages and cross-lingual reasoning robustness.
- Agentic generalization: Sparse agent evaluations; expand to multi-tool, web, RAG, long-horizon tasks with standardized protocols and ablations.
- Code safety: Coding benchmarks focus on correctness; assess security properties (vulnerabilities, unsafe patterns) and introduce secure-coding verifiers.
- Overfitting risk: Large gains on competition-style math may reflect distributional specialization; perform OOD math/science evaluations and cross-year robustness tests.
- MoE internals: Missing details on number of experts, capacity factors, gating noise, load balancing losses, and expert specialization analyses; release config and interpretability studies.
- Activated vs. total parameters: No scaling-law analysis of active parameter count vs. performance; run controlled ablations (e.g., 22B/37B/50B active) to quantify returns.
- Distillation: No attempt to distill “thinking” into smaller models; evaluate supervised/RL distillation and compression of CoT.
- Reward model leakage: If language-model verifiers are used, they may share pretraining data; assess verifier contamination and cross-verifier agreement.
- Licensing and usage policy: Model license and usage restrictions are unspecified; provide clear terms, safety constraints, and deployment guidelines.
- Open-source completeness: Clarify whether full training/eval pipelines, configs, and verifier code are released; without them, results are hard to reproduce.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released Ring-1T model, its training methods (IcePop, C3PO++), and the ASystem infrastructure. Each item includes sectors, potential tools/products, and feasibility notes.
- Olympiad-level math tutoring and assessment (Education)
- Use case: Interactive tutor for AIME/HMMT/IMO-style problem solving, step-by-step solution generation, and explanation refinement.
- Tools/products: Chat-based math coach; competition practice portals; classroom assistants for advanced mathematics.
- Assumptions/dependencies: Human oversight for correctness and pedagogy; compute capacity for 128K-context sessions; content licensing and safety filters.
- Advanced code assistant with safe execution (Software)
- Use case: Iterative code generation, test synthesis, and bug fixing aligned with LiveCodeBench and Codeforces-style reasoning.
- Tools/products: IDE plugins integrating ASandbox for secure code/tests execution; CI bots for patch suggestion; pair-programmer workflows.
- Assumptions/dependencies: Secure sandbox (runsc/kata) and reliable test suites; organizational policy on AI-generated code; model license terms; cost-aware inference.
- High-quality reasoning assistant for puzzle/logical tasks (Daily Life, Education)
- Use case: Solving logic puzzles (Sudoku, Knights and Knaves, 24 Game), visual pattern reasoning, and general logic coaching.
- Tools/products: Puzzle solver apps; reasoning practice platforms; tutoring modules for logic courses.
- Assumptions/dependencies: Verifier-backed tasks where possible; user guidance to avoid over-reliance on unverified outputs.
- Draft clinical knowledge support and guideline summarization (Healthcare)
- Use case: Triage suggestion drafting, guideline summarization, and clinical education based on HealthBench-level competence.
- Tools/products: Clinician-facing literature assistants; training modules for residents; draft generation for care pathways.
- Assumptions/dependencies: Not for autonomous diagnosis or treatment decisions; stringent human-in-the-loop review; regulatory compliance and audit logging.
- Financial reasoning assistant for scenario analysis (Finance)
- Use case: Structured analysis of finance scenarios, policy memos, and risk narratives, aligned with FinanceReasoning evaluations.
- Tools/products: Spreadsheet copilots; memo drafting assistants; risk committee pre-reads.
- Assumptions/dependencies: Independent data verification; guardrails against speculative recommendations; compliance and model auditability.
- Research assistant for natural-language proof sketching and STEM reasoning (Academia)
- Use case: Drafting proof outlines, exploring solution strategies, and explaining STEM concepts in natural language.
- Tools/products: Academic writing copilots; course materials generator; brainstorming partner for problem sets.
- Assumptions/dependencies: Validation and formalization by domain experts; potential integration with formal tools (Lean/Coq) as a follow-on.
- RL training stabilization with IcePop in MoE pipelines (Academia, Software/ML Ops)
- Use case: Reduce training-inference mismatch and gradient instability in large MoE models.
- Tools/products: IcePop plugin for GRPO/ RLVR pipelines; token-level discrepancy masking workflows; training monitors for KL/mismatch metrics.
- Assumptions/dependencies: Access to both training and inference engines; calibrated α/β clipping thresholds; logging for mismatch tracking.
- Rollout efficiency improvements with C3PO++ for long CoT RL (Academia, ML Ops)
- Use case: Speed up RL rollout phases with budget-controlled dynamic partitioning; reduce long-tail stalls.
- Tools/products: Rollout scheduler integrated with token budgets; buffer-based resumption across iterations; training dashboards for throughput.
- Assumptions/dependencies: Reliable inference/training pools; careful retention policies (σ); alignment between rollout continuations and reward computation.
- Distributed RL infrastructure adoption (ASystem) for large-scale labs (Academia, Cloud/Infra)
- Use case: Run trillion-scale RL with unified training-inference runtime, fast weight sync (AState), optimized memory (AMem), and serverless evaluation (ASandbox).
- Tools/products: On-prem/cluster deployments of ASystem; peer-to-peer weight sync service; memory pooling library; sandbox FaaS cluster.
- Assumptions/dependencies: High-performance interconnects (RDMA/NCCL), NUMA-aware placement, thousands of GPUs, robust orchestration.
- Token-budgeted inference scheduling in production (Software, Platform Ops)
- Use case: Cost-aware generation control for long reasoning sessions; budget-based continuation similar to C3PO++ for chat/agent systems.
- Tools/products: Inference controller that partitions long tasks, resumes with updated policies, and enforces per-session limits.
- Assumptions/dependencies: Stateful inference management; user experience design for partial outputs/resumptions; monitoring for drift across policy updates.
Long-Term Applications
The following applications require further research, scaling, integration, or regulatory approval before broader deployment.
- High-stakes clinical decision support and care-pathway optimization (Healthcare)
- Use case: Assist clinicians with complex differential diagnoses, treatment planning, and longitudinal patient reasoning.
- Tools/products: EHR-integrated CDS modules; explainability dashboards; audit trails; verifier-backed protocols.
- Assumptions/dependencies: Prospective clinical validation; regulatory clearance; bias/hallucination mitigation; robust verifiable reward pipelines.
- Formal theorem proving and proof translation (Academia, Software)
- Use case: Bridge natural-language proofs to formal proofs; co-pilot for Lean/Isabelle/Coq with automated formalization suggestions.
- Tools/products: Proof translators; hybrid symbolic–neural verification systems; formal proof assistants augmented by Ring-1T.
- Assumptions/dependencies: Tight integration with formal languages; trusted verifiers; benchmarks beyond natural-language reasoning.
- Autonomous codebase maintenance and migration (Software)
- Use case: Large-scale refactoring, API migrations, security patching with continuous verification and safe execution.
- Tools/products: AI maintainer agents; CI/CD-integrated verification harnesses; sandbox-backed rollout gates.
- Assumptions/dependencies: High-fidelity test coverage; governance and approvals; containment of unintended changes; long-context code comprehension.
- Strategic planning and grid optimization for energy systems (Energy, Policy)
- Use case: Long-horizon reasoning for grid balancing, storage dispatch, and policy trade-off analysis.
- Tools/products: Planning copilots for utilities; simulation-integrated reasoning agents; budgeted rollout controllers for scenario exploration.
- Assumptions/dependencies: Domain simulators and verifiers; real data access; interdisciplinary oversight; cost-efficient inference at scale.
- Advanced financial strategy research and risk governance (Finance, Policy)
- Use case: Scenario stress testing, policy impact analysis, structured risk narratives for committees.
- Tools/products: Governance copilots; audit-ready reasoning logs with verifiable checks; multi-agent strategy sandboxes.
- Assumptions/dependencies: Model transparency requirements; regulator engagement; robust guardrails; rejection of speculative trading autonomy.
- Robotics high-level task planning and instruction synthesis (Robotics)
- Use case: Generate hierarchical plans, constraints, and task decompositions for embodied agents.
- Tools/products: Planner modules connected to perception/control stacks; long-context task memory; verifiable subtask completion checks.
- Assumptions/dependencies: Integration with robotic control systems; safety validation; multimodal extensions; cost-optimized inference.
- Personalized curriculum generation and mastery learning pathways (Education)
- Use case: Long-horizon reasoning to adapt curricula, scaffold skills, and monitor progress in advanced subjects.
- Tools/products: Learning path planners; mastery assessment engines; tutoring platforms with verifiable skill tracking.
- Assumptions/dependencies: Pedagogical validation; alignment with standards; data privacy; sustained compute budgets.
- Autonomous scientific discovery support (Academia, Industry R&D)
- Use case: Hypothesis generation, experimental design, and result interpretation with verifier-based RL to reduce error.
- Tools/products: Lab assistant agents; protocol planners; multi-agent research orchestration.
- Assumptions/dependencies: Tool integration (LIMS, instruments), formal verifiers for domain-specific correctness, human oversight.
- Cloud-scale trillion-parameter RL as a managed service (Cloud/Infra)
- Use case: ASystem productization for enterprise/lab training of 1T+ models, including AState/AMem/AReaL and serverless ASandbox.
- Tools/products: Managed RL clusters; turnkey weight sync and memory libraries; RL pipeline SaaS.
- Assumptions/dependencies: Vendor support; hardware–software co-design; SLAs for sync latency and fault tolerance; cost control.
- AI policy and benchmarking frameworks grounded in verifiable rewards (Policy)
- Use case: Standardize public-sector AI procurement/evaluation around verifiable, domain-specific benchmarks and training recipes that reduce hallucinations.
- Tools/products: Public benchmark suites (math/code/science/logical reasoning); evaluation pipelines with ASandbox; reporting standards for training-inference alignment.
- Assumptions/dependencies: Multi-stakeholder consensus; open governance; continuous benchmarking maintenance; legal compliance for data and model use.
These applications build directly on:
- Ring-1T’s state-of-the-art reasoning in math, code, logic, healthcare, and alignment.
- IcePop’s stabilization of RL in MoE settings by masking/clipping token-level mismatches.
- C3PO++’s budget-aware rollout partitioning for efficient long CoT training and inference control.
- ASystem’s unified training–inference runtime, fast weight synchronization (AState), GPU memory optimization (AMem), secure serverless evaluation (ASandbox), and scalable RL framework (AReaL).
Key cross-cutting dependencies to consider for feasibility:
- Compute and memory: Trillion-scale models and 128K contexts require substantial GPU resources and high-speed interconnects.
- Verifiers and datasets: Many applications rely on high-quality verifiable tasks and curated data; domain-specific verifiers may need to be developed.
- Safety, governance, and regulation: High-stakes domains (healthcare, finance, policy) require human oversight, auditability, and compliance.
- Cost and productization: Long-context inference and multi-agent workflows must be budgeted and scheduled; C3PO++-style budget controllers can help operationalize costs.
Glossary
- Activated parameters: The subset of model parameters actively used for processing a token in a Mixture-of-Experts model. "With approximately 50 billion activated parameters per token,"
- AdamW: An optimizer that combines Adam with decoupled weight decay for better generalization. "We employ the AdamW optimizer with hyperparameters = 0.9, = 0.999, weight decay of $0.01$, and with the MoE router bias held fixed."
- AMem: A GPU memory management library for large-scale RL that optimizes allocation and transfer to reduce OOM and improve throughput. "AMem is a GPU memory management library designed to overcome the critical memory bottleneck in large-scale RL training, like that of our 1T model."
- AReaL: An open-source reinforcement learning algorithm framework emphasizing ease of use and system flexibility. "Its reinforcement learning component, AReaL, is an open-source framework~\citep{fu2025areal} built to prioritize algorithm development by balancing ease of use with system flexibility."
- ASandbox: A serverless sandbox engine providing isolated, fast environments for executing RL-related tasks such as code and terminal interactions. "ASandbox is a serverless sandbox engine for RL, providing rapid, isolated environments for tasks like code execution and terminal simulation."
- AState: A high-performance framework for synchronizing model weights between training and inference actors in RL. "AState is a high-performance weight synchronization framework for RL."
- ASystem: A high-performance, distributed RL framework built to support trillion-parameter model training with asynchronous pipelines. "ASystem is a high-performance reinforcement learning (RL) framework designed for large-scale asynchronous training."
- AWorld: A multi-agent framework used for evaluating the model in competition-style settings. "in the IMO-2025 evaluation within AWorld~\footnote{https://github.com/inclusionAI/AWorld}, Ring-1T achieved a silver medal-level result"
- Chain-of-Thought (CoT): A technique that trains models to produce step-by-step reasoning traces in their outputs. "In this stage, we aim to endow the base model with fundamental long-chain reasoning abilities through Long Chain-of-Thought Supervised Fine-Tuning (Long-CoT SFT)."
- C3PO++: A budget-controlled rollout scheduling algorithm that partitions and resumes long trajectories across iterations to improve RL efficiency. "We introduce C3PO++, an extension of C3PO~\citep{team2025ring} that incorporates a budget-controlled rollout partition mechanism."
- Cold start: The time and process required to instantiate an execution environment from zero, crucial for fast, on-demand sandboxing. "By offering millisecond-scale cold start and high-throughput isolation, ASandbox accelerates evaluation of Ring-1T rollouts during large-scale RL training."
- Cosine decay scheduler: A learning rate schedule that decays the rate following a cosine curve, often used to stabilize fine-tuning. "We employed a cosine decay scheduler with 30 warmup steps"
- CUDA graphs: A CUDA feature that captures and replays GPU workloads efficiently, reducing launch overheads. "including NCCL communications and CUDA graphs;"
- Data decontamination: Removing instances from training data that overlap with evaluation benchmarks to prevent leakage and inflated scores. "Data Decontamination, where we utilized both hashing and exact string matching techniques to detect and eliminate any samples that overlap with existing benchmarks;"
- Deduplication: The process of removing repeated or near-duplicate entries from datasets to reduce bias and overfitting. "Deduplication, where we employed exact matching to remove repetitive samples;"
- Distributed Multi-path Transfer: A technique that aggregates bandwidth across multiple interconnects to accelerate distributed data transfers. "Distributed Multi-path Transfer~\cite{shen2025flexlinkboostingnvlinkbandwidth}, which aggregates bandwidth across multiple channels;"
- Function-as-a-Service (FaaS): A serverless execution model where functions are invoked on demand without managing servers. "deployable as a standalone FaaS cluster"
- GRPO: A group-relative policy optimization method used in RL to improve sample efficiency and stability. "IcePop, a variant of GRPO that suppresses unstable training updates through double-sided masking calibration."
- Hybrid Runtime: A unified execution environment that integrates training and inference for scalable RL on LLMs. "Hybrid Runtime is an integrated training-inference system designed for large-scale LLM reinforcement learning."
- Importance sampling: A correction technique that reweights samples to account for distribution mismatches between behavior and target policies. "TIS~\citep{yao2025offpolicy} with the officially recommended setting, which mitigates the training-inference mismatch issue with importance-sampling correction,"
- KL coefficient: The regularization weight applied to the Kullback–Leibler divergence term in RL to keep the current policy close to a reference. "a KL coefficient of $0.0$"
- Kubernetes: An orchestration platform used to manage containerized workloads for scalable, isolated RL task execution. "Integrated with Kubernetes and deployable as a standalone FaaS cluster, it executes RL tasks via function calls."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to a subset of expert networks, enabling larger total parameters with sparse activation. "a novel Mixture-of-Experts (MoE) thinking model"
- NUMA: Non-Uniform Memory Access; a hardware topology consideration that optimizes data movement across CPUs and GPUs. "through NUMA topology and CPU-GPU affinity awareness,"
- NCCL: NVIDIA Collective Communications Library used for efficient multi-GPU communication in distributed training. "integrating RDMA, NCCL, and shared memory"
- Peer-to-peer mechanism: Direct data transfer between nodes or processes without central coordination, reducing overhead. "a zero-redundancy peer-to-peer mechanism"
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm that optimizes models based on human preference signals. "This phase employs RLHF (Reinforcement Learning from Human Feedback) to recalibrate the model's capability distribution,"
- Reinforcement Learning from Verifiable Rewards (RLVR): An RL method that uses automatically checkable rewards via domain-specific verifiers. "The model's comprehensive reasoning performance is enhanced via RLVR (Reinforcement Learning from Verifiable Rewards)."
- Retention period: The number of iterations a partial rollout is kept and resumed before being discarded. "We denote the number of partitions a sequence has undergone as the retention period."
- Router bias (MoE): A parameter in MoE routing that influences expert selection, often held fixed to stabilize training. "with the MoE router bias held fixed."
- Sharding: Splitting data or model parameters into shards to distribute storage and computation across machines. "efficient data packing/sharding."
- Single Program, Multiple Data (SPMD): A parallel computing model where the same program runs across multiple data partitions. "SingleController + SPMD (Single Program, Multiple Data)"
- SingleController: A control-plane pattern coordinating distributed RL components, here paired with SPMD to avoid bottlenecks. "SingleController + SPMD (Single Program, Multiple Data)"
- Supervised Fine-Tuning (SFT): Post-training supervised optimization of LLMs on curated datasets for specific capabilities. "Long Chain-of-Thought Supervised Fine-Tuning (Long-CoT SFT)"
- Token budget: A cap on the total number of tokens generated per iteration to control cost and stabilize RL updates. "we regulate the rollout generation with a token budget ()"
- Training-inference mismatch: Divergence between probabilities computed by training and inference engines that destabilizes RL. "mitigates the training-inference mismatch issue"
- TIS: An off-policy correction method (referenced work) used to address training-inference mismatches via importance sampling. "TIS~\citep{yao2025offpolicy} with the officially recommended setting, which mitigates the training-inference mismatch issue with importance-sampling correction,"
- YaRN: A method for extending LLM context windows beyond their native length to handle longer inputs. "extended via YaRN \citep{peng2023yarn} for models with insufficient native context."
- Zero-redundancy: A distribution strategy that avoids sending duplicate parameter shards, reducing synchronization overhead. "a zero-redundancy peer-to-peer mechanism delivers only necessary weight shards,"
- Pass-rate filtering: A data curation strategy that selects items based on how often they are solved correctly, ensuring difficulty and quality. "Finally, we applied a Pass-rate filtering strategy to select only the highest-quality items."
- Masking (token-level): Excluding tokens from gradient computation based on probability deviation to stabilize RL updates. "Masking: We exclude tokens with excessive probability deviation from gradient computation, constraining gradient updates in a stable region."
- Dynamic routing (MoE): The mechanism that selects which experts process each token, leading to inference-training discrepancies if not aligned. "particularly pronounced in the training of MoE models with RL due to the inherent usage of the dynamic routing mechanism."
- Rollout buffer: A persisted store of partial trajectories that can be resumed across policy updates to improve throughput. "maintaining a rollout buffer across policy model versions."
- cgroups: Linux control groups used to limit and isolate resource usage of processes in containerized environments. "100ms startup via image caching, cgroups, and fork;"
Collections
Sign up for free to add this paper to one or more collections.

