MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Abstract: We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces MiroThinker v1.0, a powerful open-source “research agent.” Think of it like a supercharged digital assistant that doesn’t just write text—it plans, browses the web, runs code, checks facts, and keeps working through a problem step by step. The paper’s big idea is “interactive scaling,” which means training the model to handle more and deeper back-and-forth interactions with tools and the outside world, not just making the model bigger or giving it a longer memory.
Key Questions the Paper Tries to Answer
- How can we make open-source AI agents better at real research tasks, like finding reliable information, testing ideas, and combining evidence?
- Beyond making models larger or giving them more memory, does increasing the number and depth of interactions (like more searches, more code runs, more checks) reliably improve performance?
- Can an open-source agent approach the performance of leading commercial systems by scaling along three dimensions: model size, context length (memory), and interaction depth?
How MiroThinker Works and How It Was Built
The agent’s “think–act–observe” loop
MiroThinker follows a ReAct workflow. Imagine a curious student solving a big project:
- Think: Plan the next step.
- Act: Use a tool (like searching the web or running code).
- Observe: Read the result and decide what to do next. It repeats this loop many times until it has enough evidence to write a final answer.
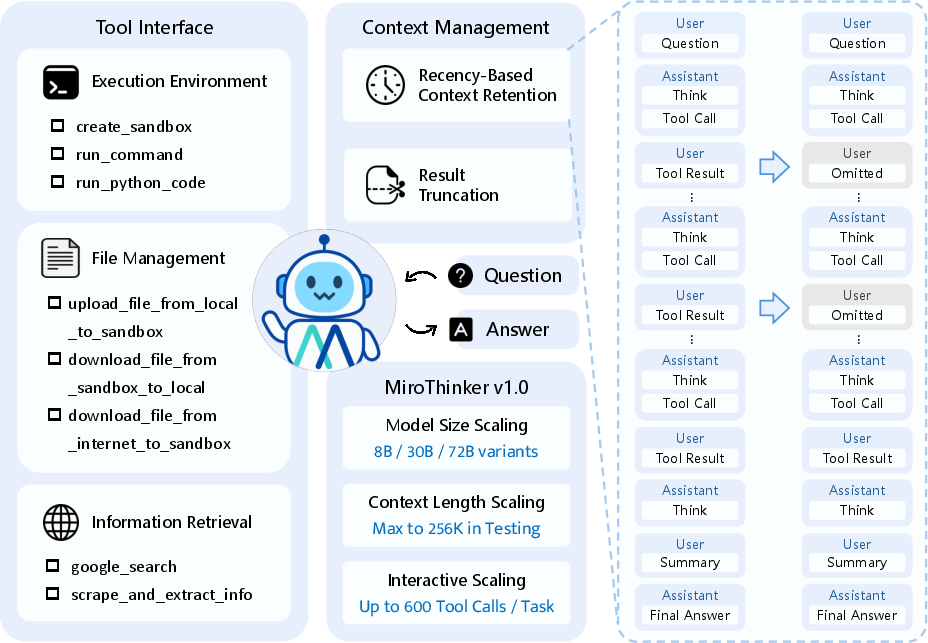
The tools it uses
To go beyond simple text, MiroThinker can:
- Run code safely in a sandboxed Linux environment using
run_commandorrun_python_code. - Move files in and out of the sandbox (upload, download).
- Search the web with
google_search. - Extract key info from pages with
scrape_and_extract_info(this condenses long pages into the important parts).
This turns the model into a practical research assistant that can gather, test, and verify information.
Managing memory so long tasks don’t overflow
The model has a very large “context window” (like a memory backpack) of 256K tokens, but it still needs to be smart about what to keep:
- It focuses on recent tool results and hides older ones (recency-based retention), while keeping the full trail of thoughts and actions.
- If a tool returns something extremely long, it trims it and marks it as “[Result truncated]”.
These simple rules let MiroThinker make up to 600 tool calls for a single task without running out of space.
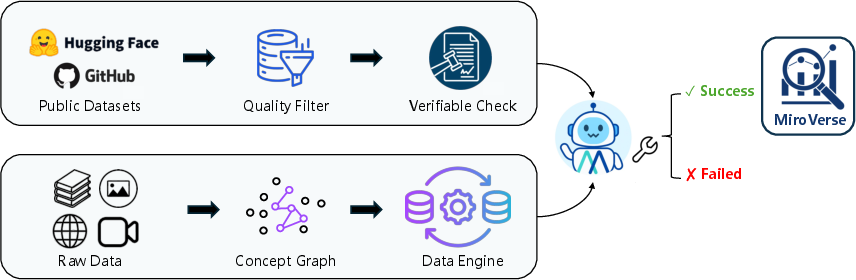
The data used to teach it
To train good research skills, the team created a large dataset:
- Multi-document QA: They built questions that require reading and connecting facts across multiple linked documents (like a mini web of Wikipedia pages), then added clever “obfuscations” so the model has to reason rather than just lookup exact matches.
- Agentic trajectories: They recorded many step-by-step “think–act–observe” examples using different agent styles and tool protocols, so the model learns realistic workflows.
They also included various open QA datasets and general dialogue/reasoning data to keep the model broadly capable.
The training recipe
MiroThinker is trained in three stages, each building different skills:
- Supervised Fine-Tuning (SFT): The model copies high-quality examples to learn the basics of planning and tool use.
- Preference Optimization (DPO): The model is shown pairs of full solutions and is trained to prefer the better one (usually the one with the correct final answer and a clear, coherent trace).
- Reinforcement Learning (GRPO): The model practices in real environments with tools, gets feedback (rewards) for correctness and following instructions, and learns to explore deeper solution paths that pay off.
Together, this teaches MiroThinker not just to guess an answer but to work through problems methodically.
Main Results and Why They Matter
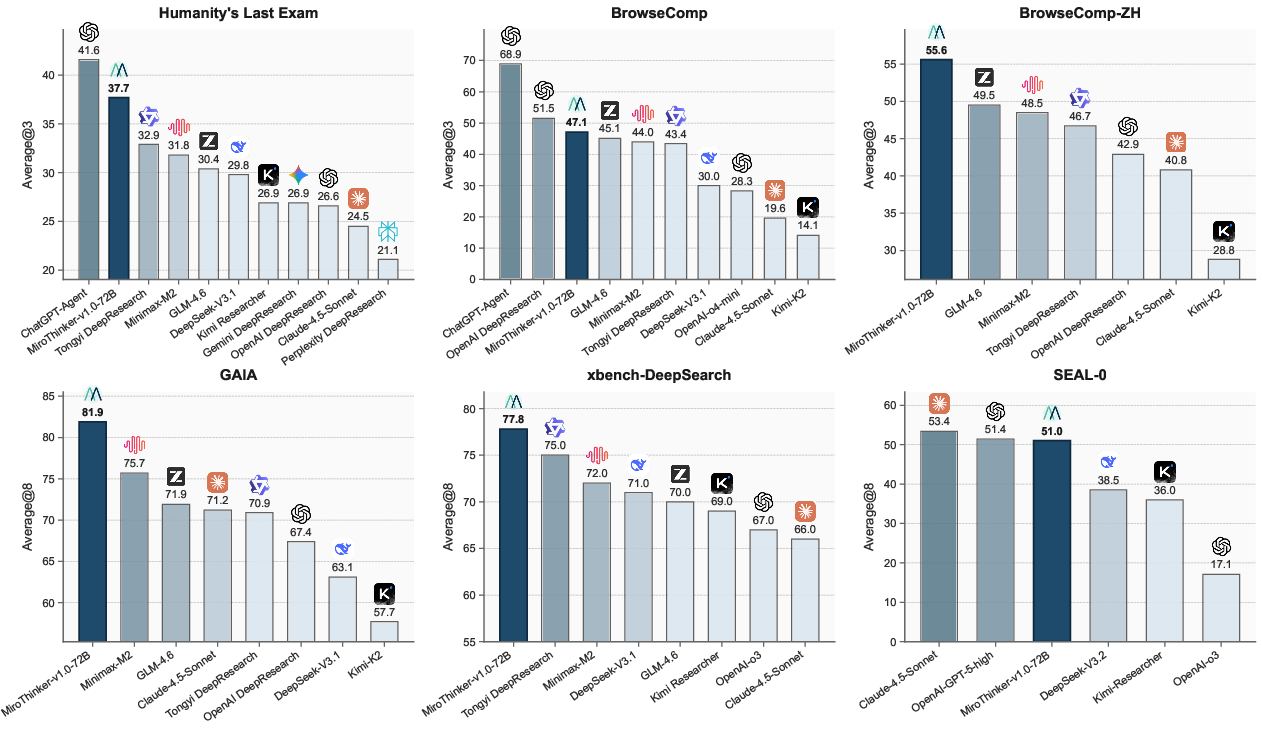
MiroThinker v1.0 performs strongly on several challenging research benchmarks. The largest version (72B) achieved:
- GAIA: 81.9% accuracy
- Humanity’s Last Exam (HLE): 37.7% accuracy
- BrowseComp: 47.1% accuracy
- BrowseComp-ZH (Chinese): 55.6% accuracy
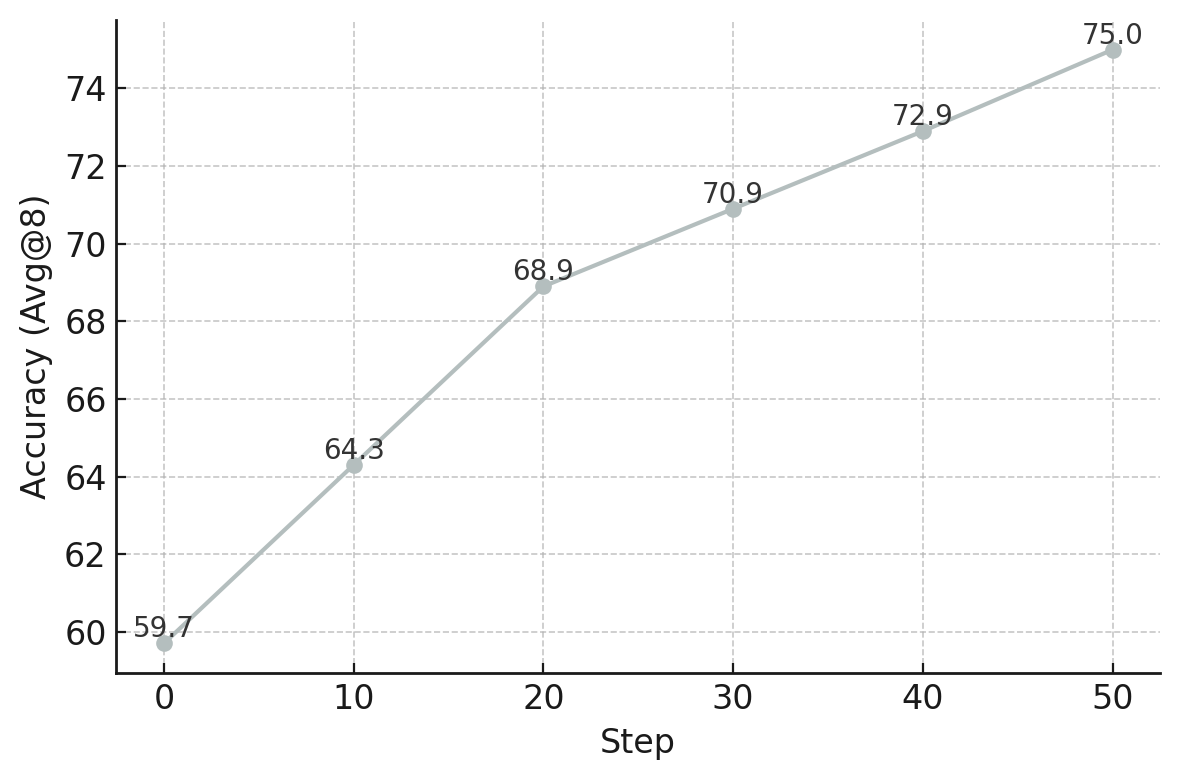
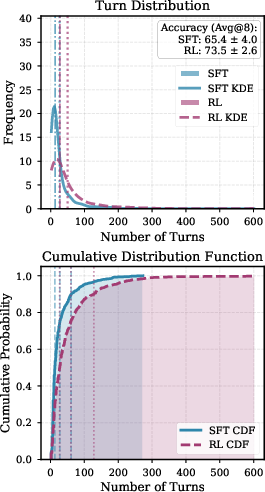
These scores beat other open-source agents and get close to high-end commercial systems mentioned in the paper. Just as importantly, the paper shows a clear trend: when the model engages in more and deeper interactions (e.g., more tool calls, more checking, more verification steps), performance predictably improves. That’s the core of “interactive scaling” and the big takeaway: research agents get better not just by being bigger or remembering more, but by actively doing more smart steps with real-world tools.
What This Means Going Forward
- Establishes a “third axis” of scaling: Beyond model size and memory, interaction depth is a powerful way to boost research capability.
- Strengthens open-source tools: MiroThinker shows that open models can approach—and sometimes match—commercial systems on complex research tasks.
- Practical impact: Better AI research assistants could help students, journalists, scientists, and developers gather reliable information, test ideas, and explain results more transparently.
- Future improvements: The paper notes areas to refine—making tool use more efficient (fewer redundant calls), keeping reasoning clear and not overly long, avoiding mixed languages in outputs, and improving code/sandbox skills.
In short, MiroThinker v1.0 demonstrates that teaching an AI to interact more deeply and intelligently with the world—by searching, testing, and verifying—can significantly improve its research performance. This points the way to next-generation open research agents that are more accurate, reliable, and useful in real-life problem solving.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of gaps and open questions that remain unaddressed and could guide future research:
- Lack of ablation studies isolating contributions of each training stage (SFT, DPO, RL) and each component (recency-based retention, result truncation, tool interface) to overall performance.
- No quantitative analysis of context management hyperparameters (e.g., retention budget K=5): how does varying K affect accuracy, error rates, interaction depth, and memory of early evidence?
- Missing evaluation of selective recall for omitted tool outputs: how often is critical information lost due to recency masking, and can retrieval of earlier context be triggered reliably?
- No study of reward shaping beyond correctness and format: how do latency-, cost-, and efficiency-aware rewards change tool-use behavior, redundancy, and accuracy?
- Tool-use efficiency is not measured: absence of metrics for redundant calls, marginal contributions per call, average utility per tool invocation, and cost/latency trade-offs.
- No explicit measurement of error propagation from the web-scraping extractor LLM (e.g., Qwen3-14B): how often does extraction introduce misinformation or bias, and how can the agent detect and correct it?
- Missing comparison of interaction scaling vs. test-time scaling under controlled conditions: when does deeper interaction outperform longer CoT without tools, and where does it fail?
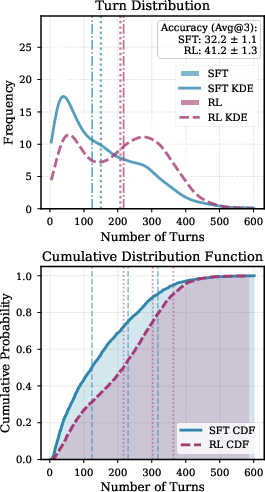
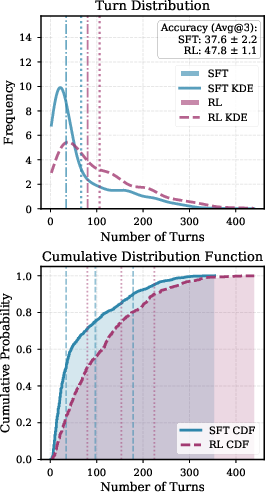
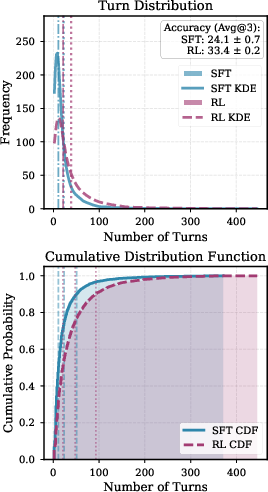
- Interactive scaling evidence is descriptive (histograms, averages) without formal scaling law characterization: what is the functional relationship between interaction depth and accuracy across tasks and model sizes?
- No cross-scale analysis of interactive scaling (8B vs. 30B vs. 72B): does interaction depth yield diminishing returns or phase shifts with model capacity?
- Unclear sample efficiency and compute cost of GRPO in long-horizon settings: how many trajectories per task are needed, and what are the compute/latency implications for training?
- Missing details on RL hyperparameters (group size G, KL penalties, reward coefficients) and their sensitivity: how do these choices affect stability and generalization?
- Dataset transparency gaps: no release or summary statistics for MiroVerse v1.0 (size, domain distribution, multi-hop depth, language mix, link density), and no human validation measures.
- Limited contamination analysis: aside from disabling HuggingFace in tools, there is no decontamination audit ensuring test sets (e.g., GAIA, BrowseComp) were not seen during SFT/DPO/RL or present in synthesized data.
- Artificiality of MultiDocQA synthesis (constraint obfuscation) not evaluated: do synthetic obfuscations reflect real-world reasoning demands, or introduce artifacts that inflate benchmark scores?
- No multilingual evaluation beyond English and Chinese: performance across other languages (e.g., Spanish, Arabic, Japanese) and non-Google search ecosystems remains unknown.
- LLM-as-a-Judge reliance introduces evaluation bias and opacity: how do results compare to human judgments and automated exact-match/verification pipelines?
- Robustness under real web conditions (CAPTCHAs, rate limits, dynamic content, region restrictions) is not assessed; tools may fail differently in production settings.
- Security and safety are not evaluated: risks from prompt injection, adversarial webpages, data exfiltration, and unsafe code execution in the sandbox remain unaddressed.
- Sandbox misuse and capability gaps are acknowledged but not quantified: frequency of timeout/errors, common failure patterns, and corrective training strategies are missing.
- No analysis of failure modes such as hallucinations, confirmation bias, or over-trusting scraped summaries; mechanisms for evidence verification and contradiction handling are undeveloped.
- Interaction cap and window trade-offs are unstudied: how do 600-turn limits and 256K context constraints interact with accuracy, latency, and cost?
- Latency and operational cost of long-horizon agent runs are not reported: end-to-end inference time, tool call costs, and throughput under multi-turn workflows remain unknown.
- Recency retention vs. domain requirements: in tasks requiring long-range dependencies (e.g., legal, biomedical), does K=5 degrade performance, and can domain-adaptive retention help?
- Multi-agent inference is not evaluated: although multi-agent trajectories are synthesized (MiroFlow), the paper only reports single-agent ReAct results; benefits and coordination costs of multi-agent inference are unknown.
- Tool ecosystem breadth is narrow (search, scraping, Python, shell): effectiveness with richer tools (databases, academic APIs, code IDEs, spreadsheets, visualization) is unexplored.
- No calibration or uncertainty quantification: how can the agent express confidence, flag low-trust evidence, or abstain when information is insufficient?
- Ethical and privacy concerns of web scraping (PII handling, consent, compliance) are not addressed; governance for dataset and agent operations is absent.
- Generalization to unseen domains and temporal drift not studied: how does performance change as web content evolves or in niche domains outside training distribution?
- Benchmark coverage gaps: multimodal tasks and complex research workflows (e.g., literature synthesis with citation fidelity) are not evaluated.
- No investigation into planning strategies: does explicit planning (e.g., subgoal graphs, task decomposition) reduce redundant tool calls or improve correctness?
- Absence of interpretability diagnostics: how do internal thoughts correlate with correct/incorrect actions, and can we detect misleading reasoning trajectories early?
- Limited comparison to stronger agent frameworks: using a “simple ReAct agent” may undervalue orchestration improvements; how much additional gain is possible with richer controllers?
- Unclear reproducibility details: seeds, hardware, training time, parameter counts per variant, and exact inference settings for each benchmark run are insufficient for full replication.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released models, tools, and workflows described in the paper.
- Research automation for literature reviews and evidence synthesis
- Sector: academia, healthcare, enterprise R&D
- Use case: Systematically search, scrape, and synthesize multi-source evidence for surveys, systematic reviews, and technology landscaping.
- Workflow/tools: ReAct loop + google_search + scrape_and_extract_info with LLM-based extractors; 256K context with recency-based retention to manage hundreds of cited snippets; sandbox for reproducible data wrangling.
- Potential products: “Interactive Literature Review Copilot” that produces traceable, cite-linked summaries.
- Assumptions/Dependencies: Web access and API quotas, site scraping policies, LLM extractor accuracy, availability of compute to sustain long contexts.
- Competitive intelligence and market monitoring
- Sector: software, energy, robotics, finance
- Use case: Track competitors’ announcements, patents, pricing pages, investor decks, and regulatory filings; synthesize weekly briefings.
- Workflow/tools: Scheduled agent runs with multi-turn browsing and extraction; recency-based context retention to focus on latest signals.
- Potential products: “CI Radar” dashboards with annotated sources and tool-call traces.
- Assumptions/Dependencies: Reliable indexing and scraping; site rate limits; accuracy of source attribution; organizational data governance.
- Compliance and regulatory analysis
- Sector: finance, healthcare, energy, public sector
- Use case: Aggregate multi-document rules (e.g., SEC, FDA, ISO/IEC), compare obligations across jurisdictions, generate obligation matrices.
- Workflow/tools: MultiDocQA-style multi-hop reasoning across linked regulations; sandboxed code to parse PDFs and tables; result truncation to protect context.
- Potential products: “Compliance Copilot” generating obligation maps and audit trails.
- Assumptions/Dependencies: Correct parsing of legal texts; legal review required; reliable document sources; long-context costs.
- Due diligence and vendor/RFP evaluation
- Sector: enterprise procurement, public sector
- Use case: Cross-compare proposals, verify claims against public sources, produce decision briefs with traceable evidence.
- Workflow/tools: ReAct with hundreds of tool calls; MCP/function-calling tool orchestration; context retention to keep actions/thoughts but prune old raw outputs.
- Potential products: “RFP Analyst Agent” with explainable trajectories and scorecards.
- Assumptions/Dependencies: Access to vendor docs; fairness and bias checks; governance for scraping proprietary material.
- Data-centric research workflows in notebooks and ETL pipelines
- Sector: software, data engineering, scientific computing
- Use case: Automate reproducible data cleaning, feature exploration, and small-scale analysis in a Linux sandbox from web-sourced datasets.
- Workflow/tools: create_sandbox + run_command + run_python_code; upload/download file utilities for data movement.
- Potential products: “Agentic Notebook Runner” that produces runnable scripts and provenance logs.
- Assumptions/Dependencies: Secure sandboxing; resource limits; correct tool-use sequencing (init sandbox before ops).
- Cross-lingual research and documentation synthesis
- Sector: education, global enterprises
- Use case: Source and reconcile English/Chinese materials to produce bilingual research summaries or FAQs.
- Workflow/tools: BrowseComp-ZH-grade performance; LLM-based extraction tuned per language; evidence-linked outputs.
- Potential products: “Bilingual Research Assistant” for global teams.
- Assumptions/Dependencies: Language mixing limitation noted; requires QA and style guides; source quality varies by language.
- Transparent research ops for classrooms and labs
- Sector: education, academia
- Use case: Teach research methods with interpretable agent trajectories showing think–act–observe cycles, citations, and tool calls.
- Workflow/tools: ReAct trace logging; retention budget to emphasize recent observations while preserving action history.
- Potential products: “Agentic Research Lab Manual” templates and grading rubrics.
- Assumptions/Dependencies: Instructor oversight; academic integrity policies; access to permitted sources.
- Open-source agent evaluation and benchmarking
- Sector: AI tooling, research ops
- Use case: Reproduce and extend evaluations across GAIA, HLE, BrowseComp; implement avg@k runs for stability.
- Workflow/tools: Provided inference settings; LLM-as-a-Judge harness; streaming rollout acceleration for high-throughput testing.
- Potential products: “Agent Benchmark Harness” CLI with fixed seeds and error bars.
- Assumptions/Dependencies: Dependence on proprietary judges (e.g., GPT-4.1, o3-mini) for some benchmarks; judge bias considerations.
- Context management plug-ins for agent frameworks
- Sector: software tools
- Use case: Retrofit existing agents with recency-based retention and result truncation to extend feasible interaction depth.
- Workflow/tools: Retain_K masking of tool responses; output length caps; integration with ReAct-style agents.
- Potential products: “Context Retainer” library for LangChain/LlamaIndex-style stacks.
- Assumptions/Dependencies: Task-types where recency bias holds; careful selection of K to avoid losing crucial earlier evidence.
Long-Term Applications
These applications leverage the paper’s concepts (interactive scaling, agentic RL, multi-hop synthesis) but require further research, scaling, or engineering to reach production-grade reliability.
- Enterprise-grade deep research platform with guardrails and SLAs
- Sector: software, enterprise AI
- Use case: End-to-end platform for agentic research across departments (legal, finance, engineering) with policy-compliant scraping, audit trails, and human-in-the-loop review.
- Workflow/tools: Interactive scaling with sustained 600+ tool calls; robust tool-use quality optimization; trajectory curation; RL-based improvement cycles.
- Potential products: “ResearchOps Platform” with role-based governance and compliance checks.
- Assumptions/Dependencies: Tool-use efficiency improvements; scalable orchestration; strong governance for scraping and data privacy; cost management for long contexts.
- Domain-specialized research agents (e.g., medical, legal) with verified evidence
- Sector: healthcare, law
- Use case: Clinical guideline synthesis, adverse event signal detection; case-law and regulation harmonization with explicit evidence chains.
- Workflow/tools: MultiDocQA-style knowledge graphs; specialized extractors; RL rewards tied to domain-specific correctness; expert review loops.
- Potential products: “Clinical Evidence Agent,” “Case-Law Navigator.”
- Assumptions/Dependencies: High-stakes verification; licensed datasets; regulatory approvals; mitigation of language mixing and overlong chain-of-thought.
- Autonomous compliance monitors and policy impact evaluators
- Sector: public policy, finance, energy
- Use case: Continuously track evolving rules, flag changes, simulate organizational impact, and suggest remediation steps with citations.
- Workflow/tools: Scheduled browsing, interactive scaling to validate updates across sources; sandboxed policy simulations.
- Potential products: “Policy Change Sentinel.”
- Assumptions/Dependencies: Reliable change detection; versioned source tracking; organizational buy-in for policy simulations; formal verification for critical decisions.
- Agentic RL training-as-a-service for research agents
- Sector: AI platforms, MLOps
- Use case: Hosted GRPO-style training pipelines with streaming rollout acceleration, trajectory filters, and LLM-based grading tailored to client domains.
- Workflow/tools: GRPO with online updates; trajectory filtering for tool failures and degeneracy; custom reward engineering.
- Potential products: “Agent RL Studio.”
- Assumptions/Dependencies: Judge reliability and cost; long-tailed rollout management; scalable environment emulation; data governance.
- High-throughput, legally compliant web research at scale
- Sector: web infrastructure, compliance tech
- Use case: Massive concurrent research tasks with tool orchestration, throttling, and adherence to robots.txt and site terms.
- Workflow/tools: MCP for dynamic tool discovery; rate-limited scraping; provenance logs; deduplication and content hashing.
- Potential products: “Compliance-first Web Research Mesh.”
- Assumptions/Dependencies: Evolving site policies; regional data regulations; robust error handling; caching to reduce load and cost.
- Provenance-rich research report generators with interactive evidence graphs
- Sector: knowledge management
- Use case: Produce reports that embed interactive graphs linking each claim to source passages, tool-call logs, and validation steps.
- Workflow/tools: ReAct traces as evidence graph nodes; context retention for compact views; UI for trajectory inspection.
- Potential products: “Traceable Report Builder.”
- Assumptions/Dependencies: UX to handle 100–600 step traces; storage and indexing; standardized citation formats.
- Advanced context management algorithms beyond recency
- Sector: AI tooling
- Use case: Content-aware retention (semantic pinning, rationale distillation, tool-output summarization) to further extend deep interactions without losing critical early evidence.
- Workflow/tools: Learned summarizers; memory modules; task-aware K budgeting.
- Potential products: “Adaptive Memory Manager.”
- Assumptions/Dependencies: Summarization fidelity; avoidance of hallucinated compression; evaluation protocols for recall.
- Agentic safety and reliability frameworks
- Sector: AI governance, safety
- Use case: Detect redundant or risky tool calls, prevent data leakage, enforce site-use policies, and rate-limit expensive interactions.
- Workflow/tools: Tool-use quality metrics; action deduplication; risk classifiers in the loop; budget-aware planners.
- Potential products: “Agent Safety Guardrail Kit.”
- Assumptions/Dependencies: Accurate risk detection; policy codification; integration with diverse toolchains; measurable impact on cost and reliability.
- Personal research assistants for complex daily tasks
- Sector: consumer software
- Use case: Transparent, evidence-based comparisons (e.g., insurance, broadband plans, university programs) with multi-source validation.
- Workflow/tools: Browse + extract + compare + cite; recency-based context to keep latest offers; mobile/UI integration.
- Potential products: “Evidence-backed Comparison Companion.”
- Assumptions/Dependencies: Data freshness; site scraping permissions; consumer trust and UX; cost controls for long interactions.
- Dataset and trajectory generators for domain agent training
- Sector: AI data tooling
- Use case: Generate high-quality multi-hop QA and agentic trajectories (like MiroVerse) for new verticals (e.g., cybersecurity, climate analytics).
- Workflow/tools: MultiDocQA graph construction; constraint obfuscation for challenging reasoning; diverse LLMs for synthesis.
- Potential products: “Agentic Data Engine.”
- Assumptions/Dependencies: Domain coverage; curation to reduce noise; licensing and IP checks; synthesis quality assurance.
Glossary
- Advantage: An RL quantity measuring how much better a trajectory’s return is compared to a baseline, used to weight policy updates. "The advantage for trajectory is computed as:"
- Agent Foundation Models (AFMs): Foundation models explicitly trained with agent-oriented abilities (planning, tool use, environment interaction). "Agent Foundation Models (AFMs) have emerged as a new paradigm of foundation models..."
- Agentic: Pertaining to autonomous, goal-directed behavior such as planning, acting, and interacting with environments. "agentic capabilitiesâthe ability to plan, reason, and act autonomously in complex environments"
- Agentic Preference Optimization: A training stage that aligns agent decision-making using preferences over full interaction traces. "Agentic Preference Optimization"
- Agentic Reinforcement Learning: RL applied to multi-turn agent–environment interactions to learn exploration and tool-use behaviors. "Agentic Reinforcement Learning"
- Agentic Supervised Fine-tuning: SFT tailored to agent behaviors, training on thought–action–observation trajectories. "Agentic Supervised Fine-tuning"
- Agentic Workflow: The structured loop of think–act–observe used by the agent during problem solving. "Agentic Workflow"
- Agentic trajectory: A recorded sequence of thoughts, actions, and observations that documents the agent’s reasoning and interactions. "an agentic trajectory example illustrates the recency-based context retention mechanism"
- avg@k: Reporting protocol that averages benchmark scores across k independent runs to reduce variance. "we conduct independent runs and report the averaged score, denoted as avg@k."
- BrowseComp: A web-browsing benchmark for research agents evaluating multi-step retrieval and synthesis. "on the BrowseComp~\citep{wei2025browsecomp} benchmark, MiroThinker-v1.0-72B achieves 47.1\% accuracy"
- BrowseComp-ZH: The Chinese version of the BrowseComp benchmark assessing multilingual web research. "on the BrowseComp-ZH~\citep{zhou2025browsecomp_zh} benchmark"
- Constraint Obfuscation: The process of transforming facts into indirect constraints to require deeper multi-step reasoning. "Constraint Obfuscation"
- Direct Preference Optimization (DPO): A preference-based objective that trains models to favor preferred outputs while staying close to a reference. "Direct Preference Optimization (DPO)"
- FRAMES: A benchmark used to assess factual reasoning performance of agents. "FRAMES \citep{krishna2025fact}"
- GAIA: A general AI benchmark; the paper uses its text-only subset for evaluation. "On the GAIA-Text-Only benchmark~\citep{mialon2023gaia}"
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages relative to a group mean to stabilize training. "We employ Group Relative Policy Optimization (GRPO)"
- HLE (Humanity’s Last Exam): A challenging benchmark assessing broad, multi-domain reasoning ability. "Humanityâs Last Exam (HLE) \citep{phan2025hle}"
- Interactive scaling: Increasing the depth and frequency of agent–environment interactions to improve performance. "interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories."
- KL penalty: A regularization term using KL divergence that constrains the learned policy to remain close to a reference. " controls the strength of the KL penalty."
- Knowledge graph: A graph of interlinked documents or entities used to support multi-hop question synthesis. "we construct a knowledge graph by following its internal hyperlinks."
- Linux sandbox: An isolated execution environment for running shell commands and Python code safely. "We employ a Linux sandbox that provides an isolated runtime for command and code execution."
- LLM-as-a-Judge: An evaluation setup where a LLM grades the agent’s answers. "All benchmark performances are evaluated using LLM-as-a-Judge."
- LLM test-time scaling: Increasing compute or reasoning steps at inference without environment feedback; can degrade with longer chains. "Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains,"
- MCP (Model Context Protocol): A flexible protocol enabling natural, context-based tool interaction and composition. "Model Context Protocol (MCP)"
- MiroFlow Multi-Agent: A coordinated multi-agent framework producing collaborative trajectories. "MiroFlow Multi-Agent~\citep{2025miroflow}"
- MiroVerse v1.0: The synthesized dataset of agentic trajectories used to train MiroThinker. "forming the complete MiroVerse v1.0 dataset used for training MiroThinker v1.0."
- Multi-hop reasoning: Reasoning that integrates information across multiple sources or steps to reach conclusions. "complex multi-hop reasoning"
- MultiDocQA: A synthesis process that builds multi-document question–answer pairs requiring cross-document reasoning. "multi-document QA (MultiDocQA) synthesis"
- ReAct paradigm: A think–act–observe framework where reasoning alternates with tool use and observation. "MiroThinker v1.0 model is developed under the ReAct paradigm"
- Recency bias: The tendency for decisions to depend more on recent observations than distant ones. "To leverage this recency bias and improve contextual efficiency,"
- Recency-Based Context Retention: A strategy retaining only the most recent tool outputs to conserve context budget. "Recency-Based Context Retention"
- Recency-filtered history: A history representation that masks older tool responses while preserving thoughts and actions. "We construct a recency-filtered history "
- Reinforcement learning: Training via rewards from interactions, enabling exploration and adaptation in real environments. "Through reinforcement learning, the model achieves efficient interaction scaling:"
- Result Truncation: Limiting overly long tool outputs and tagging them as truncated to prevent context overflow. "Result Truncation"
- Retention budget: The fixed number of recent tool responses kept in context during reasoning. "Given a retention budget for preserved tool responses,"
- Reward function: The function combining correctness and format adherence to score trajectories during RL. "Our reward function for a trajectory given question combines multiple components:"
- Rollout trajectories: Sampled interaction traces used to update the policy in online RL. "by using rollout trajectories to update the policy model exactly once."
- SEAL-0: A benchmark used for evaluating agent performance. "SEAL-0~\cite{pham2025sealqa}"
- SFT (Supervised fine-tuning): Training the model to imitate expert trajectories in a supervised manner. "supervised fine-tuning (SFT)"
- Tool-augmented reasoning: Reasoning that integrates external tools (search, code, scraping) to gather and process evidence. "designed to advance tool-augmented reasoning and information-seeking capabilities."
- Tool invocation: The act of calling external tools via structured interfaces during agent reasoning. "two complementary tool invocation methods"
- Trajectory curation: Filtering and cleaning sampled interaction traces to ensure high-quality RL signals. "Trajectory Curation"
- WebWalkerQA: A benchmark for web-based question answering via multi-step browsing. "WebWalkerQA \citep{wu2025webwalker}"
- xBench-DeepSearch: A benchmark measuring deep search and retrieval performance. "xBench-DeepSearch \citep{chen2025xbench}"
Collections
Sign up for free to add this paper to one or more collections.