- The paper introduces an action-aware memory system that unifies long-horizon navigation with fine-grained object manipulation.
- It achieves state-of-the-art performance by demonstrating over 2× improvement in semantic action fidelity on a new long-horizon benchmark.
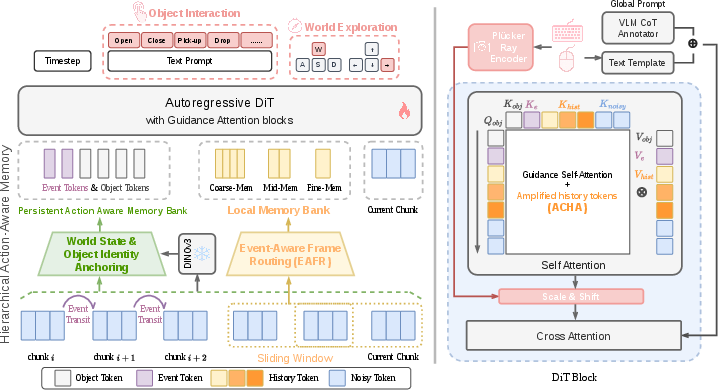
- The design leverages event-aware frame re-assignment and persistent memory to maintain object identity and enhance scene coherence.
ActWorld: A Unified Interactive World Model with Action-Aware Memory
Introduction and Motivation
ActWorld introduces a new paradigm in world modeling aiming to overcome the critical limitation of existing models that are predominantly navigation-centric, i.e., they primarily support locomotion and viewpoint control, but lack fine-grained, real-time object interaction. Prior art typically relegates object interactions to offline, language-conditioned settings, restricts them to constrained or game-like domains, or fails to provide joint support for both long-horizon navigation and mid-rollout manipulation sequences. These limitations result from dual bottlenecks: insufficient interaction-labeled data and a recency-biased memory architecture that systematically forgets the decisive frames underpinning object-centric actions.
Model Architecture
ActWorld is a chunk-autoregressive interactive world model designed to generate temporally coherent video in response to low-level (keyboard/mouse) and high-level (object interaction) actions, supporting both long-horizon navigation and continuous, real-time object manipulation.

Figure 1: ActWorld natively handles unified navigation and mid-rollout object interaction in a single rollout, under per-frame control via keyboard and mouse.
The core architectural innovation is a hierarchical action-aware memory comprising:
Conditioning is achieved using both geometric (Plücker-ray FiLM) and symbolic (frozen language encoder) pathways for camera/keyboard/mouse data, enabling granular viewpoint guidance while avoiding overfitting to discrete command templates. Semantic per-chunk captions (extracted via Chain-of-Thought reasoning from vision-LLMs) localize the model’s behavior within complex sequences—circumventing ambiguity from coarse video-level descriptions.
Dataset and Annotation Pipeline
Addressing the data bottleneck, the authors curate a 100K-clip dataset rich in annotated object-manipulation actions, spanning 40 distinct action categories with per-chunk phase segmentation. Chain-of-thought VLM prompting yields high-quality, temporally grounded chunk annotations—phase-labeled into stages such as approaching, contact, manipulating, and completing—serving both as cross-attention and as structural signals for the memory modules.
Evaluation Protocol and Benchmarks
For empirical validation, the ActWorld model is assessed on I-Bench, a new, long-horizon benchmark interleaving navigation and interaction within natural prompts, enabling quantitative measurement of both action fidelity and camera control.
Evaluation encompasses:
- VBench: Visual quality and temporal consistency metrics.
- VLM-AJ: Semantic instruction-following via large vision-LLM (VLM) judgment.
- KMF: Geometric controllability (alignment of generated navigation with commanded key/mouse trajectories).
Experimental Results
ActWorld achieves state-of-the-art results across all axes, outperforming strong baselines (Yume-1.5 (Mao et al., 26 Dec 2025), Matrix-Game 3 (Wang et al., 10 Apr 2026), Infinite-World (Wu et al., 2 Feb 2026), etc.) particularly in semantic action fidelity—demonstrating >2× improvement in Level-3 success rate (57.8% vs. 20–25% for next-best models).
Qualitative rollouts illustrate coherent chaining of complex manipulation and viewpoint sequences, maintaining object identity and interaction outcomes across long horizons—where conventional baselines either lose track of objects or drift away from the instructed trajectory.

Figure 3: Qualitative rollouts show both flexible navigation and object manipulation within single interactive sequences.

Figure 4: Comparative rollouts for long, multi-step interactions—ActWorld uniquely preserves both global scene coherence and precise manipulation sequence.
The ablation study confirms the cumulative efficacy of the memory components: EAFR and ACHA each incrementally improve instruction-following and subject consistency, while event/object persistent memory modules deliver the largest performance jump.
Practical and Theoretical Implications
By integrating high-fidelity, event-conditioned memory and object-centric persistent slots, ActWorld succeeds in bridging the navigation–interaction gap endemic to prior world models. This architecture enables a single model to maintain fine-grained state over both manipulated objects and scene geometry during unrestricted, keyboard/mouse- or prompt-driven exploration. The plug-and-play memory designs (zero-initialization invariants) allow retrofitting onto large pre-trained DiT backbones, facilitating future transfer across corpora or model families.
In practical terms, this capability is directly significant for domains requiring interactive, flexible response with persistent object awareness—such as embodied AI, open-world content creation, robotics simulation, autonomous driving, and real-time, AI-generated gameplay.
Future Directions
Potential avenues for extension include:
- Integration of multi-agent or multiplayer scenarios, leveraging persistent memory for inter-agent object tracking.
- Scaling to high-dimensional real-world scenes with open-vocabulary actions.
- Cross-modal and continuous-command conditioning, moving beyond discrete key/mouse input and integrating richer agent–environment interfaces.
- Automation of dataset annotation via more advanced, possibly self-supervised, VLM reasoning for chunk-level segmentation.
- Downstream policy learning for embodied agents leveraging ActWorld as a high-fidelity simulator with true actionability.
Conclusion
ActWorld establishes a new standard in interactive world modeling by enabling unified, real-time simulation of both navigation and fine-grained object manipulation via hierarchical, action-aware memory. It empirically resolves the architectural and memory bottlenecks concomitant with prior navigation-centric models, demonstrating that explicit event- and object-level persistent memory is both technically feasible and essential for bridging the gap between explorable and actionable virtual worlds. The approach points toward a future of world models capable of serving as dynamically interactive simulators for a broad spectrum of embodied and multi-agent AI systems.

Figure 5: Additional examples generated by ActWorld, showcasing diverse and coherent interaction behaviors over extended horizons.