Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
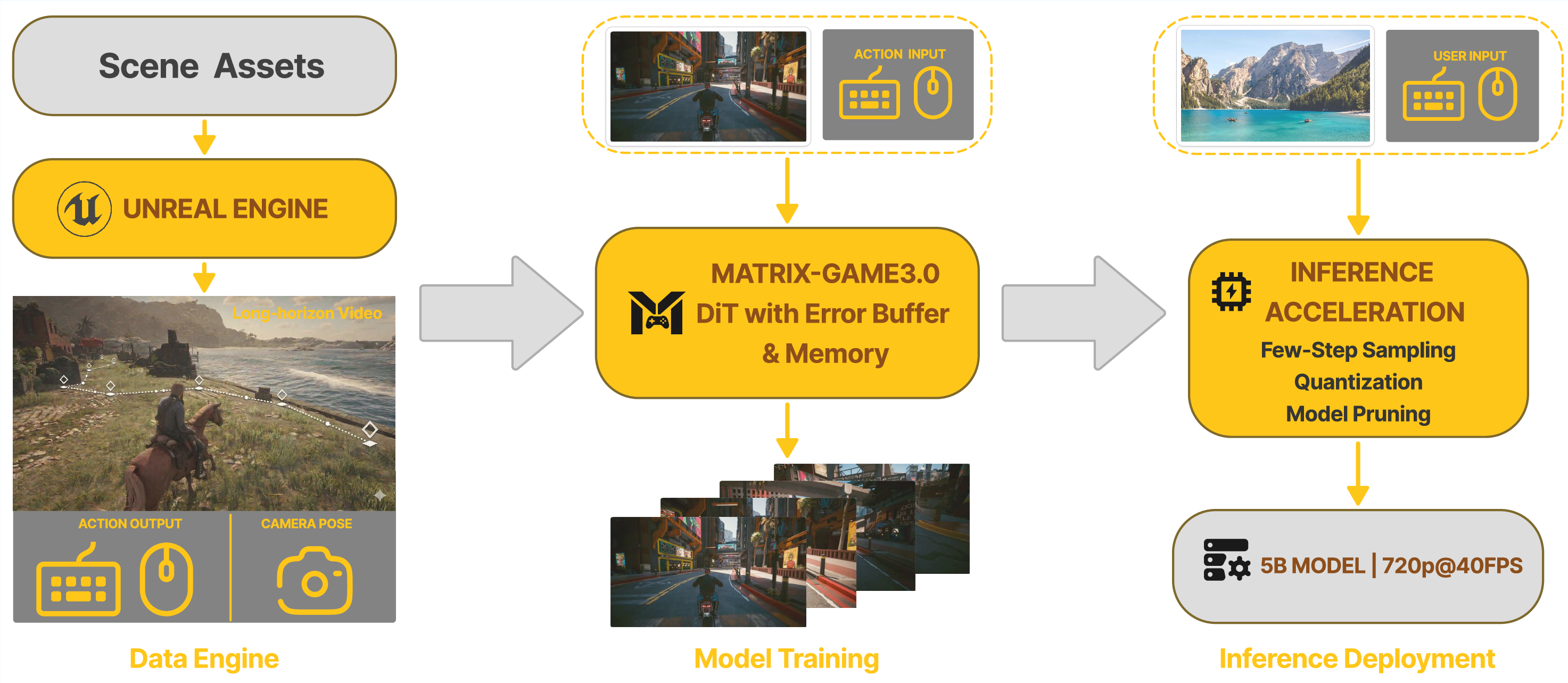
Abstract: With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
First 10 authors:







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces Matrix-Game 3.0, an AI system that can create and “run” a virtual world like a video game in real time. You can press keys or move a mouse, and the world responds instantly with smooth, high-quality video that stays consistent for a long time (minutes). Think of it as a super-fast, interactive movie maker that remembers what happened before, so things don’t randomly change or “glitch” as you play.
What questions does the paper try to answer?
- How can we make an AI “world model” that reacts to your actions instantly (real-time) while keeping the world stable and consistent for a long time?
- How can we give the AI a good memory so it remembers what it showed before (so objects, places, and characters don’t morph or disappear)?
- How can we make this work at high resolution (720p) and fast speed (up to 40 frames per second) without huge delays?
- What kind of training data and tricks help the AI manage both action control and long-term memory?
How did they do it? (Methods explained simply)
To build a fast, stable, memory‑able world model, the team improved three areas: data, the core model, and how it runs in real time.
1) A huge, smart data engine
They trained the model on lots of high-quality, labeled video from three sources:
- Unreal Engine (UE5) scenes they controlled precisely. This is like filming your own game, where every frame has exact camera position, player movements, and actions recorded.
- Big commercial games (like GTA V and others), captured automatically using a recording system that logs what the camera and player are doing.
- Real-world videos (homes, streets, cities, drone footage), re-annotated so the camera positions are consistent.
Each training clip includes:
- Video: what you see
- Pose (camera position and angle): where the “camera” is and where it’s pointing
- Action: what the player did (keys, mouse)
- Prompt/text: scene descriptions
This “quadruplet” helps the model learn cause-and-effect: “If I press W, the view moves forward like this.”
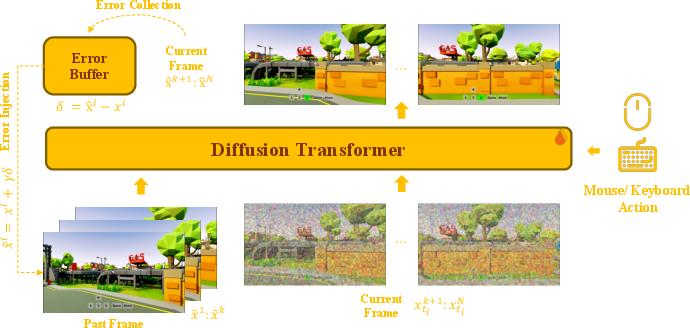
2) A model that corrects itself and remembers
- Self-correction: The model is trained to notice its own small mistakes and fix them over time. Imagine drawing a picture, checking where it’s slightly off, and adjusting as you go—that’s what the model practices. The authors keep a “mistake buffer” and re-inject small errors during training so the model learns how to stay steady during long runs.
- Action-aware control: Keyboard and mouse inputs are directly fed into the model, so actions like turning the camera or moving forward are accurately reflected in the video.
- Camera-aware memory: When generating new frames, the model looks back to earlier frames that match the current camera view. It picks the most relevant past frames (like finding past photos taken from a similar angle) and uses that as “memory” to keep objects and layouts consistent.
- Unified attention: Instead of treating memory as a separate channel, the model mixes current frames, recent frames, and memory frames together in one attention space. That’s like letting all clues talk to each other directly, making the output more coherent.
- Geometry hints: The model is told exactly how the current camera and past memory cameras are related (like “you’re now standing 2 meters to the left and looking slightly up”), so it can align the world correctly across views.
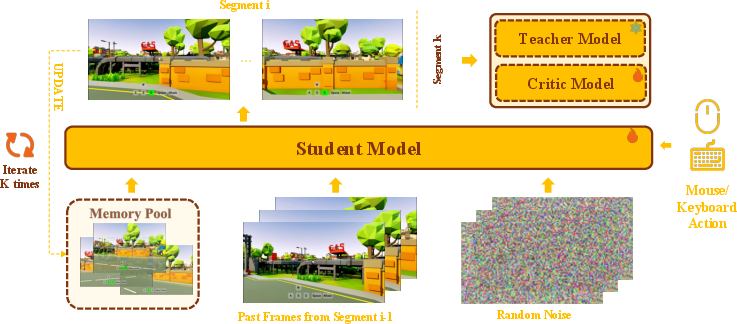
3) Teach a faster student to act like the big model
Big models are accurate but slow. So the team uses “distillation,” where a smaller/faster model learns to imitate a larger model. They do this over multiple segments, just like the model will run in the real world—rolling forward chunk by chunk—so training matches real use. This reduces error buildup and keeps results stable.
4) Speeding up real-time performance
- Quantization: They run parts of the model with lower-precision numbers (INT8) where it won’t hurt quality much, making it faster.
- Lighter video decoder: They streamline the part that turns the model’s compressed “video latents” into real images, speeding this up 2.6× to 5.2×.
- Fast memory lookup on GPU: Selecting relevant memory frames (based on camera overlap) is done on the graphics card for speed.
- Asynchronous pipeline across multiple GPUs: Different parts of the process run in parallel so the system keeps up with 40 FPS at 720p using a 5-billion-parameter model.
They also train a bigger version (around 28B parameters with Mixture-of-Experts) for even better quality and generalization, and split roles between models so one specializes in action control and another refines visual details.
What did they find, and why is it important?
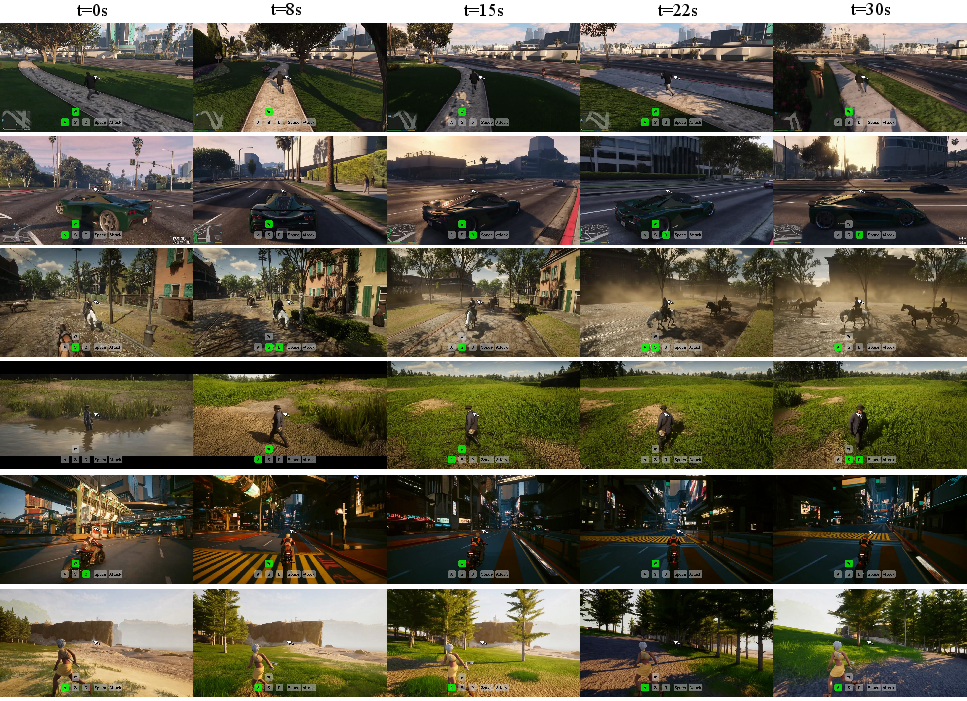
- Real-time, high quality: The system can generate at up to 40 frames per second at 720p with a 5B model—good enough for interactive experiences.
- Long-horizon consistency: It stays stable for minute-long sequences without the scene drifting or changing randomly. That’s crucial for believable worlds.
- Accurate control: Keyboard and mouse inputs produce precise, reliable changes in the video (turning, moving, interacting).
- Larger models improve robustness: Scaling up to ~28B parameters yields even better visuals, movement, and generalization across scenes.
- Practical deployment path: By combining data, self-correcting training, memory, distillation, and system-level speedups, they show a concrete way to deploy interactive “world models” at scale.
This matters because many applications—games, VR/AR, robotics, virtual filming—need fast and consistent simulations. If the world flickers or forgets where things are, it’s unusable. This work shows a way to get both speed and long-term stability.
What’s the bigger impact?
- Interactive entertainment: Imagine AI-powered game worlds that you can explore instantly, with consistent characters and locations—even if the world is being generated on the fly.
- Robotics and training: Robots could practice in stable, realistic virtual environments where the world reacts to their actions in real time.
- XR and creative tools: Artists, filmmakers, and designers could prototype scenes quickly, with reliable continuity across shots and angles.
- Research catalyst: The paper shares a blueprint—data engine, memory design, self-correction, distillation, and deployment tricks—that others can build on.
In short, Matrix-Game 3.0 brings us closer to AI systems that can run responsive, persistent worlds—fast, detailed, and consistent over long periods—opening the door to new kinds of interactive experiences and practical simulations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures concrete gaps and open questions that remain unresolved in the paper and can guide future research:
- Reproducibility and release status: Are model weights, training recipes (hyperparameters, schedules), code (including memory retrieval, distillation, acceleration stack), and the curated datasets publicly released? Without them, independent verification and extension are difficult.
- Quantitative evaluation of long-horizon consistency: The paper claims minute-long stability but does not specify standard metrics or protocols for measuring long-term spatiotemporal consistency (e.g., identity/geometry persistence, pose-consistency error over time, drift rates) or benchmarks for interactive settings.
- Lack of ablations: The contributions (error buffer, camera-aware retrieval, relative Plücker encoding, head-wise RoPE perturbation, memory perturbation, multi-segment DMD distillation, INT8 quantization, VAE pruning) are not disentangled via systematic ablations to quantify each component’s effect on quality, stability, and speed.
- Memory capacity and policy: The memory bank growth, eviction, and update policies are not specified; how retrieval performance and FPS scale with memory size and horizon length is unquantified.
- Retrieval robustness to noise: Memory selection assumes accurate camera poses; robustness to pose noise, calibration errors, and synchronization jitter (especially in real-world or estimated-poses settings) is not evaluated.
- Occlusion- and dynamics-aware memory: The camera-overlap retrieval does not explicitly handle occlusions or moving objects; it is unclear how the method avoids reintroducing outdated object states or manages memory for dynamic scenes.
- Geometry encoding design choices: The impact of relative Plücker encoding versus alternatives (e.g., SE(3) embeddings, epipolar constraints) on stability and view-consistency is not analyzed; no ablation indicates when geometry helps versus harms.
- Temporal encoding stability: Head-wise RoPE base perturbation reduces periodic aliasing, but the trade-off between long-range attention strength and positional ambiguity is unquantified; sensitivity to perturbation scale is unknown.
- Error-aware training hyperparameters: The design and tuning of the error buffer (sampling strategy, buffer size, distribution shift over training, γ for perturbations) are not justified; stability and convergence under different settings are unclear.
- Exposure bias and extreme horizons: While self-correction and multi-segment distillation are introduced, it remains unknown how the model behaves beyond minute-long sequences (e.g., many minutes to hours), and whether drift or mode collapse emerges at extreme horizons.
- Teacher–student specifics and stability: The characteristics of the teacher used in DMD (capacity, training data, noise schedules) and the sensitivity of DMD training to segment length, number of segments, and stopping rules are not documented.
- Trade-offs in few-step distillation: The few-step scheme’s effect on high-frequency detail, motion fidelity, and control accuracy versus speed is not measured; failure modes (e.g., oversmoothing, hallucinated motion) remain unspecified.
- Real-time deployment footprint: The reported 40 FPS uses eight GPUs for the DiT and one for the VAE; it is unclear how performance degrades with fewer GPUs, on different hardware, or under tighter latency budgets (e.g., single-GPU edge deployment).
- End-to-end latency and jitter: The paper focuses on throughput (FPS) but not end-to-end input-to-photon latency, jitter under fluctuating load, or responsiveness under varying action rates—critical for interactive use.
- GPU-based memory retrieval accuracy vs. speed: The sampling-based frustum-overlap approximation lacks quantitative comparison to exact overlap in terms of ranking accuracy and its downstream effect on visual consistency and FPS at scale.
- VAE pruning artifacts: The visual and temporal artifacts introduced by 50–75% decoder pruning are not quantified (e.g., SSIM/LPIPS, temporal flicker metrics), nor is the failure behavior on high-frequency textures or fine details.
- Quantization coverage and stability: Only attention projections are quantized to INT8; potential gains and risks from quantizing FFNs, KV caches, or the VAE are unexplored, as is the sensitivity of quality to calibration schemes.
- Scaling to 28B and real-time feasibility: Although MoE-28B improves quality, its real-time viability, resource needs, and integration with the memory system and distillation pipeline are not reported.
- Viewpoint specialization transitions: Two high-noise models are trained for first- and third-person views; how the system transitions between views mid-episode, handles mixed-view sequences, or reconciles conflicts is not addressed.
- Action space limitations: Control is limited to discrete keyboard and continuous mouse signals; scalability to richer action spaces (manipulation, physics interactions, multi-agent control) and compositional actions is not explored.
- Generalization beyond games: The reliance on UE5 and AAA titles raises questions about domain transfer to real-world tasks (robotics, AR/XR), robust behavior under real sensor noise, and the role of real-world action supervision (largely missing).
- Data licensing and ethics: The legal and ethical implications of recording from commercial AAA games (rights, redistribution constraints) are not discussed; downstream restrictions may limit reproducibility and community use.
- Pose re-annotation accuracy: While ViPE is used to unify camera poses, residual pose errors and their impact on memory-based consistency learning are not analyzed; no error bars or cross-dataset consistency checks are provided.
- Benchmarking for interactive world models: There is no standardized interactive evaluation suite (tasks, environments, telemetry) to compare memory consistency, controllability, and latency against baselines in a reproducible way.
- Robustness under adversarial or rare events: The paper does not probe failure modes under rapid camera spins, abrupt action changes, lighting/weather extremes, or long-tail environments; recovery mechanisms from severe drift are unspecified.
- Long-term object and state persistence: The ability to maintain object identities and latent states when off-screen, across re-entries, and under viewpoint changes is qualitatively suggested but lacks quantitative assessment and diagnostic tests.
- Continual/online adaptation: How the model adapts to novel environments on-the-fly, updates its memory, or avoids catastrophic interference during long sessions is not addressed.
- Energy and cost efficiency: The energy footprint and cost per hour of real-time deployment are not provided; pathways to greener, cost-effective deployment (compression/distillation targets) are uncharted.
- Multimodal extensions: Audio, tactile cues, or language-conditioned plans are not integrated; the framework’s compatibility with multimodal conditioning and their impacts on memory/latency are open.
- Safety and guardrails: There is no discussion of safety mechanisms for content generation (e.g., avoiding harmful content) or robustness against adversarial manipulations of actions/poses.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods, data engine, and inference stack, subject to the listed assumptions.
- Interactive prototyping for game scenes (gaming, software)
- Use the 720p@40 FPS real-time generator with action-conditioning to rapidly prototype playable spaces, movement feel, and camera behavior before committing assets and code.
- Potential tools/products/workflows: “Generative Graybox” plugin for Unity/Unreal that streams a Matrix-Game 3.0 server as an editable level preview; keyboard/mouse control mapped to the model’s action interface; camera-aware memory for persistent layouts during iteration.
- Assumptions/dependencies: 8–9 GPUs per concurrent session (as reported); scene content is non-deterministic and stylized vs physics-accurate; closed-source components may limit turnkey adoption.
- Dynamic background and set extension for previz (media/entertainment, VFX)
- Generate minute-long, spatially consistent previz shots from text/action scripts; re-shoot alternative camera paths while the memory mechanism preserves global layout and identity.
- Potential tools/products/workflows: NLE and DCC plugins (After Effects/Blender) to author action prompts and camera trajectories; MG-LightVAE for fast decoding in review cycles.
- Assumptions/dependencies: Content consistency is memory-anchored, not asset-bound; professional post workflows need exportable intermediate formats and deterministic seeds.
- XR “infinite world” environments (XR/VR/AR)
- Stream generative explorable worlds (first- or third-person) for VR lobbies, virtual tourism, and light exploration with persistent memory for user revisits within a session.
- Potential tools/products/workflows: Unity/Unreal XR bridge; late-stage reprojection; cloud-rendered streaming with controller-to-action mapping; camera-aware memory selection optimized for 6-DoF.
- Assumptions/dependencies: Motion-to-photon latency budgets (<20 ms) require edge/cloud orchestration; comfort and safety filters needed; first-person specialized high-noise model recommended.
- Synthetic long-horizon video data generation (AI training, computer vision)
- Create identity- and layout-consistent sequences for training tracking, re-ID, video segmentation, and long-term temporal models.
- Potential tools/products/workflows: Scripted action/camera sweeps, memory anchors for multi-view consistency, quality filters from the paper’s data pipeline; release-ready dataset cooking scripts.
- Assumptions/dependencies: Domain gap to target tasks; licensing constraints if mixing real footage styles; labels beyond pose/camera require extra tooling.
- Evaluation harness for long-horizon memory and streaming inference (academia, benchmarking)
- Use the memory-augmented DiT and multi-segment DMD distillation as strong baselines to benchmark error accumulation, retrieval strategies, and train–inference mismatch.
- Potential tools/products/workflows: Reproducible rollouts with controlled retrieval policies, error-buffer toggles, and head-wise RoPE perturbation ablations.
- Assumptions/dependencies: Availability of model checkpoints or compatible open baselines; reproducibility of data-engine recipes.
- Model acceleration as a service for video generators (software, cloud/edge)
- Apply INT8 attention quantization, MG-LightVAE decoder pruning, and GPU-based retrieval to existing video models to reach real-time or cost targets.
- Potential tools/products/workflows: Drop-in quantization kernels; compiled VAE decoders; retrieval microservice using sampling-based frustum overlap.
- Assumptions/dependencies: Quality preservation depends on content domain; quantization-aware fine-tuning may be needed for third-party models.
- Live generative experiences for streamers and creators (media, creator tools)
- Drive interactive worlds on stream with chat-controlled actions; maintain continuity over minutes for narrative arcs.
- Potential tools/products/workflows: OBS plugin that routes chat commands to action tokens; scene memory bookmarks; prompt templates for episodes.
- Assumptions/dependencies: Content moderation; compute cost per concurrent audience; rights over generated styles.
- Automated game QA exploration and environment fuzzing (gaming, QA)
- Combine the navigation and memory consistency to explore edge camera paths and room transitions, surfacing visual coherence issues and map seams.
- Potential tools/products/workflows: Autonomous agent that stress-tests camera/geometry continuity; anomaly flags from temporal drift metrics.
- Assumptions/dependencies: Not a physics or logic simulator; best for visual/level-coherence diagnostics.
- Rapid curriculum creation for interactive storytelling and media studies (education)
- Generate controlled, long-horizon scenes to teach cinematography, continuity, and blocking, with reproducible camera moves and action scripts.
- Potential tools/products/workflows: Classroom kits with pre-authored prompts; action macro libraries; “memory anchors” to discuss narrative consistency.
- Assumptions/dependencies: School compute access; content safety filters for minors.
- Compliance and data-provenance audits for synthetic environments (policy, governance)
- Use the paper’s decoupled data-engine design as a reference to define provenance tracking, action–pose alignment audits, and quality filters for synthetic data releases.
- Potential tools/products/workflows: Provenance metadata schema; per-clip quality scores and motion anomaly filters; consistent pose re-annotation (e.g., ViPE).
- Assumptions/dependencies: Organizational adoption; legal review for AAA game data capture practices; watermarking requirements may be needed.
Long-Term Applications
These applications are promising but require further research, scaling, domain integration, or regulatory approval.
- Physics-grounded digital twins for industrial operations (manufacturing, energy, logistics)
- Couple the long-horizon memory world model with differentiable or symbolic physics to simulate production flows, safety procedures, and layout changes.
- Potential tools/products/workflows: Hybrid “video+state” twins with CAD and PLC interfaces; geometry-anchored memory tied to accurate kinematics.
- Assumptions/dependencies: Robust physical fidelity, multi-sensor synthesis (depth, events), and integration with enterprise systems.
- Closed-loop autonomous driving simulation with controllable agents (automotive)
- Generate long, coherent urban scenes with controllable actors for policy training and rare scenario replay.
- Potential tools/products/workflows: Action-conditioned multi-agent control; sensor stack rendering; curriculum generation for edge cases.
- Assumptions/dependencies: High physics fidelity, strict map/traffic adherence, and regulatory validation; current model is appearance- and action-consistency–oriented, not dynamics-accurate.
- Massive-scale embodied AI training via world models (robotics, AI)
- Pretrain visuomotor policies with long-horizon generative rollouts; use memory mechanisms for persistent goals and identity tracking.
- Potential tools/products/workflows: RL/CD workflows where the model supplies synthetic experience; action remapping to robot spaces; sim2real adapters.
- Assumptions/dependencies: Accurate contact dynamics, multi-view consistency, and reward grounding; extension beyond keyboard/mouse semantics.
- Edge deployment on AR glasses and mobile devices (XR/edge AI)
- Compress and distill to sub-INT8 or mixed-precision kernels for on-device interactive overlays and context-preserving AR backgrounds.
- Potential tools/products/workflows: NPU-friendly DiT variants; ultra-light VAE; retrieval on-device using IMU and SLAM signals.
- Assumptions/dependencies: Power/thermal budgets, memory limits, and robust latency; further model compression and hardware co-design.
- Long-form interactive narrative engines (gaming, media)
- Author multi-episode narratives where memory bridges sessions, characters persist, and players steer plots through actions.
- Potential tools/products/workflows: Saveable memory banks, character identity controllers, and action macro schedulers.
- Assumptions/dependencies: Multi-session memory stability, identity locking, and content-safety moderation; creator tooling maturity.
- Human-in-the-loop digital risk exercises and safety training (public safety, enterprise L&D)
- Run branching, interactive drills (e.g., evacuation, cyber ranges) with persistent scene memory and real-time feedback.
- Potential tools/products/workflows: Scenario authoring with action constraints; telemetry-based debrief; adaptive difficulty using memory retrieval of prior attempts.
- Assumptions/dependencies: Domain realism, compliance requirements, and measurable learning outcomes.
- Medical and surgical training simulators with interactive video worlds (healthcare)
- Use persistent, controllable scenes for procedural rehearsal and patient interaction simulation.
- Potential tools/products/workflows: Haptic coupling, instrument-action mapping, and minute-long continuity for procedures.
- Assumptions/dependencies: Clinical realism, validated outcomes, and regulatory clearance; high-fidelity physics a must.
- Smart-city planning and crowd flow what-if analysis (civic planning)
- Simulate long-horizon pedestrian flows and camera perspectives to test signage, layouts, and evacuation plans.
- Potential tools/products/workflows: Multi-camera memory anchoring; geo-referenced prompts; controllable agent densities.
- Assumptions/dependencies: Validated crowd models, legal/privacy safeguards, and mapping to real geodata.
- Cross-modal world models (audio, language, 3D) for richer interaction (multimodal AI)
- Extend memory and DMD distillation to audio-visual and 3D tokens for synchronized soundscapes and editable scene geometry.
- Potential tools/products/workflows: Joint audio-visual DiTs; Plücker-guided 3D anchors; text-to-action instruction following.
- Assumptions/dependencies: Scalable multimodal data, stable cross-modal alignment, and efficient inference costs.
- Standards for generative interactive environments (policy, standards bodies)
- Establish norms for provenance, watermarking, user safety, and IP in live generative worlds drawing on AAA and real-world data.
- Potential tools/products/workflows: Compliance checklists; dataset licensing templates; runtime guardrails for interactive content.
- Assumptions/dependencies: Multi-stakeholder agreement (platforms, publishers, regulators), and international harmonization.
Notes on feasibility and dependencies across applications
- Compute and latency: The reported 720p@40 FPS requires 8 GPUs for DiT and 1 GPU for VAE; scaling to many concurrent users needs orchestration, batching, and further compression.
- Domain alignment: Outputs reflect data engine priors (UE scenes, AAA captures, curated real-world). High-stakes domains need tailored data and physics integration.
- IP and licensing: Automated capture from commercial games can raise rights concerns; synthetic data releases benefit from strong provenance and watermarking.
- Safety and moderation: Interactive generative worlds require content filters, action constraints, and user protections, especially in education and public deployments.
- Reproducibility and openness: Adoption speed depends on availability of weights, training code, and datasets; otherwise, reimplementation costs rise.
Glossary
- 6-DoF pose: Six degrees of freedom specifying a camera’s 3D position and orientation. "the camera's 6-DoF pose,"
- AAA titles: High-budget, high-profile commercial video games used as rich data sources. "automates capture from multiple AAA titles at terabyte scale;"
- Action-conditioned: Conditioning a model’s predictions on user or agent actions. "action-conditioned world models can be learned"
- Autoregressive: Generating future frames by conditioning on previously generated ones in sequence. "error accumulation and trainingâinference mismatch in autoregressive generation."
- Bidirectional backbone: A model that attends to context from both past and future within a window. "we adopt a bidirectional backbone with a camera-aware memory retrieval mechanism"
- Camera-aware memory retrieval: Selecting past frames for memory based on camera geometry to improve consistency. "camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency."
- Causal attention: Attention restricted to past context to enable efficient sequential generation. "causal video diffusion models introduce causal attention and KV cache reuse"
- Causal Forcing: A training approach aligning teacher and student under causal constraints for better consistency. "Causal Forcing~\cite{zhu2026causal} identifies the architectural mismatch between bidirectional teacher models and autoregressive students"
- Cross-Attention: Attention mechanism that conditions generation on external inputs (e.g., actions). "discrete keyboard actions are introduced through a dedicated Cross-Attention module"
- Diffusion Forcing: A training method that applies noise to unify next-step prediction and full-sequence diffusion. "Diffusion Forcing~\cite{chen2024diffusion} unifies next-step prediction and full-sequence diffusion"
- Diffusion Transformer (DiT): A diffusion model architecture using Transformer blocks for spatiotemporal tokens. "Diffusion Transformer (DiT)-based architectures"
- Distribution Matching Distillation (DMD): Distillation approach minimizing divergence between student and data distributions. "based on Distribution Matching Distillation (DMD)"
- DPVO: Deep Patch Visual Odometry; an algorithm estimating camera motion from video. "with relative poses estimated via DPVO~\cite{teed2023deeppatchvisualodometry}."
- Error accumulation: Compounding deviations over time in autoregressive rollouts leading to drift. "error accumulation, where small prediction errors compound over time and lead to temporal drift."
- Error buffer: A stored set of residuals used to perturb inputs during training for robustness. "we maintain an error buffer during training."
- Exposure bias: Discrepancy from training on ground-truth versus generating from model outputs during inference. "to better simulate inference and reduce exposure bias."
- Few-step distillation: Compressing multi-step diffusion into a small number of steps for fast inference. "Matrix-Game 2.0~\cite{he2025matrix} adopts causal autoregressive diffusion with few-step distillation"
- Field-of-view (FOV) overlap: Geometric overlap between camera views used to select relevant memory. "according to camera pose and field-of-view overlap"
- Flow-matching objective: Training objective aligning model’s predicted velocity/flow with data transitions. "The flow-matching objective is imposed only on the current latent frames."
- Frustum-overlap score: A metric measuring 3D view overlap between camera frusta for retrieval. "the exact frustum-overlap score:"
- GPU-based memory retrieval: Performing memory selection on GPU to accelerate geometry-aware lookup. "including INT8 quantization for the DiT model, VAE pruning, and GPU-based memory retrieval."
- Heterogeneous teacherâstudent architectures: Using different model architectures for teacher and student in distillation. "heterogeneous teacherâstudent architectures."
- Image-to-video (I2V) mode: Generating a video sequence conditioned on a single image. "the model operates in an image-to-video (I2V) mode."
- INT8 quantization: Reducing weights/activations to 8-bit integers to speed up inference. "including INT8 quantization for the DiT model"
- KV cache: Cached key-value tensors for attention to reuse past computations efficiently. "causal attention and KV cache reuse"
- Latent: Compressed representation (feature space) of frames used by diffusion/VAEs. "Let denote a sequence of video latents."
- Mixture-of-Experts (MoE): Architecture combining multiple expert subnetworks routed dynamically. "we further perform scale-up training on a MoE-28B backbone"
- NavMesh: Navigation mesh used for path planning in virtual environments. "a low-level NavMesh planner computes collision-free paths."
- ODE-based distillation: Distillation leveraging ordinary differential equation solvers for diffusion trajectories. "reducing the cost of ODE-based distillation."
- Pl\"ucker-style cues: Using Plücker coordinates or related encodings to model relative camera geometry. "we explicitly encode the relative camera geometry between the current target and the selected memory through Pl\"ucker-style cues."
- Quaternion arithmetic: Using quaternion math for precise 3D rotations. "Double-precision quaternion arithmetic is used for rotation calculations"
- Reverse KL divergence: Kullback–Leibler divergence D_KL(p_gen || p_data) minimized in DMD. "minimizes the reverse KL divergence"
- Rotary positional encoding (RoPE): Technique encoding relative positions via complex rotations for attention. "Because RoPE is periodic"
- Score function: Gradient of log-density (∇ log p); used to match distributions in diffusion. "difference between two score functions"
- Self-Attention: Attention over tokens within the same sequence to capture dependencies. "continuous mouse-control signals are injected through Self-Attention"
- Self-Forcing: Training with autoregressive rollouts to align training with inference. "Self-Forcing~\cite{huang2025self} introduces autoregressive rollout during training"
- Self-Forcing++: Extension of Self-Forcing with mechanisms for longer, more stable rollouts. "Self-Forcing++~\cite{cui2025self} extends the approach"
- Sink latent: A persistent reference latent retained to stabilize global appearance over long rollouts. "we optionally retain the first latent in the sequence as a persistent sink latent."
- SVI-style: Approaches inspired by stochastic variational inference modeling errors for self-correction. "SVI-style~\cite{li2025stable} approaches explicitly model prediction errors"
- VAE (Variational Autoencoder): Generative model encoding data into a latent space and decoding back. "VAE decoding becomes a major bottleneck."
- VAE pruning: Removing parts of the VAE (e.g., decoder channels) to speed up decoding. "VAE pruning"
Collections
Sign up for free to add this paper to one or more collections.